一种基于BERT的海运邮件命名实体识别方法
一种基于bert的海运邮件命名实体识别方法
技术领域
1.本发明涉及邮件识别领域,尤其涉及一种基于bert的海运邮件命名实体识别方法。
背景技术:
2.现有的邮件命名实体识别方法指定的规则只能满足固定格式的邮件,使识别方法召回率低,信息准确率下降,同时海运邮件每个人的写作风格不同,长短句掺杂,缩略词多,专业词汇丰富,而且每封邮件每种实体出现次数绝大数只有一到两次,所以对于这种情况现有的识别方法很难在有限的信息中很好的学到海运邮件重要信息的相关特征。
技术实现要素:
3.本发明提供一种基于bert的海运邮件命名实体识别方法,以克服现有的识别方法无法得到海运邮件重要信息的相关特征等技术问题。
4.为了实现上述目的,本发明的技术方案是:
5.一种基于bert的海运邮件命名实体识别方法,包括以下步骤:
6.步骤1、对海运邮件进行数据预处理,获得海运邮件数据集;
7.步骤2、统计海运邮件数据集中的高频词汇构建扩展词汇表;
8.步骤3、调用word2vec模型,利用word2vec模型和扩展词汇表生成扩展词向量;
9.步骤4、调用bert模型,利用bert模型和海运邮件数据集训练生成原生词向量;
10.步骤5、合并扩展词向量和原生词向量形成海运邮件词向量;
11.步骤6、基于海运邮件数据集使用bert模型训练海运邮件词向量,获得海运邮件词向量所在整句的上下文信息,即分布式特征;
12.步骤7、将分布式特征输入到神经网络中,利用神经网络中的全连接层将分布式特征映射到样本标签空间中,获得输入数据对应每个标签的归一化概率。
13.步骤8、调用条件随机场,将归一化概率输入到条件随机场中获得标签序列,所述标签序列用于标明邮件命名实体类型。
14.进一步的,步骤1中对海运邮件进行数据预处理具体为:
15.步骤1.1、对海运邮件进行文本切分,短文本相邻时进行拼接,短文本和长文本相邻时进行切分并拼接,使切分或拼接后的文本不超过预设的长度;其中超过预设长度的文本为长文本,小于预设长度的文本为短文本;
16.步骤1.2、将切分或拼接后的文本删除停用词、网址和html标签,获得海运邮件数据集。
17.进一步的,所述步骤2中通过编写脚本统计海运邮件数据集中出现频率最高的80%的词汇,生成扩展词汇表。
18.进一步的,步骤4中在bert模型中预设训练次数,将最后一次训练输出的词向量作为原生词向量。
19.进一步的,步骤6中利用bert模型计算海运邮件词向量所在整句的注意力,即上下文信息。
20.有益效果:本发明利用bert模型和注意力机制训练海运邮件词向量获得上下文信息,不需要频繁制定规则,使得在大量海运邮件中识别效果要更好;通过word2vec模型和bert模型预先获得词向量,解决了通用模型在海运邮件领域具备未登陆词的问题;调用条件随机场,通过转移矩阵学习得到前后标签之间的关联信息,即注意力,从而提高序列标注的准确性
附图说明
21.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作一简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
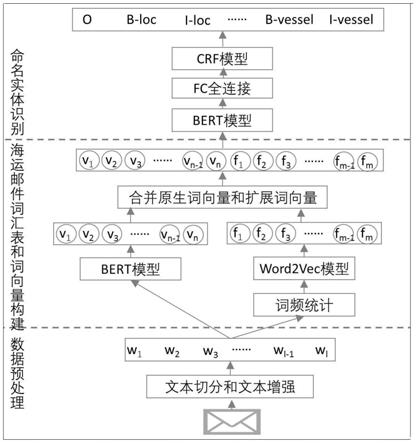
22.图1为基于bert的海运邮件命名实体识别技术框架;
23.图2为bert模型示意图;
24.图3为基于bert的海运邮件命名实体识别方法流程图。
具体实施方式
25.为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
26.本实施例提供了一种基于bert的海运邮件命名实体识别方法,如图1-3,包括以下步骤:
27.步骤1、对海运邮件进行数据预处理,获得海运邮件数据集;
28.步骤2、统计海运邮件数据集中的高频词汇构建扩展词汇表;
29.步骤3、调用word2vec模型,利用word2vec模型和扩展词汇表生成扩展词向量;
30.步骤4、调用bert模型,利用bert模型和海运邮件数据集训练生成原生词向量;
31.步骤5、合并扩展词向量和原生词向量形成海运邮件词向量;
32.步骤6、基于海运邮件数据集使用bert模型训练海运邮件词向量,获得海运邮件词向量所在整句的上下文信息,即分布式特征;
33.步骤7、将分布式特征输入到神经网络中,利用神经网络中的全连接层将分布式特征映射到样本标签空间中,获得输入数据对应每个标签的归一化概率;
34.步骤8、调用条件随机场(crf),将归一化概率输入到条件随机场中获得标签序列,所述标签序列用于标明邮件命名实体类型;因crf具有转移特性,它会考虑标签之间的上下文关联,通过函数计算自动输出一个概率最大的标注序列作为最终结果。
35.在具体实施例中,步骤1中对海运邮件进行数据预处理具体为:
36.步骤1.1、对海运邮件进行文本切分,短文本相邻时进行拼接,短文本和长文本相邻时进行切分并拼接,使切分或拼接后的文本不超过预设的长度;其中超过预设长度的文
本为长文本,小于预设长度的文本为短文本;
37.步骤1.2、将切分或拼接后的文本删除停用词、网址和html标签,获得海运邮件数据集,即文本增强。
38.在具体实施例中,所述步骤2中通过编写脚本统计海运邮件数据集中出现频率最高的80%的词汇,生成扩展词汇表。
39.在具体实施例中,步骤4中在bert模型中预设训练次数,将最后一次训练(epoch)输出的词向量作为原生词向量。
40.在具体实施例中,步骤6中利用bert模型计算整句的注意力,即上下文信息;具体的,利用bert模型学习深度的双向语言表征,通过自注意力机制,维护三个矩阵(wq,wk,wv),通过矩阵计算来获得当前词相对于整句话其他词的注意力(attention),从而得到当前词的上下文信息。
41.在具体实施过程中,如图1所示,将海运邮件通过文本切分和文本增强,获得多个海运邮件文本段,即w1、w2、w3、
…
、w
l-1
、w
l
,构成海运邮件数据集;海运邮件数据集通过高频词统计后得到m个高频词形成扩展词汇表,对扩展词汇表中每个词利用word2vec模型生成扩展词向量,即f1、f2、f3、
…
、f
m-1
、fm,通过bert模型生成n个原生词向量,即v1、v2、v3、
…
、v
n-1
、vn;合并扩展词向量和原生词向量形成海运邮件词向量;将海运邮件词向量输入到bert模型训练的上下文信息,上下文信息经过全连接层和条件随机场(crf模型)得到最终的标签序列即标明出邮件的命名实体类型,即o、b-loc、i-ioc、、
…
、b-vessel、i-vessel,标签序列可根据需求进行自定义命名。
42.在具体实施过程中,如图2所示,bert模型整体由n个相同的结构(以下称为layer)组成,每个layer由两个子结构(sub-layer)组成,分别是多头自注意力层(multi-head attention)和前馈神经网络层(feed-forward),其中每一个sub-layer都增加了残差连接和层归一化(residual connection和layer-normalization,简称add&norm),因此,每个sub-layer的输出结果如公式1为:
43.sub_layer_output=layernorm(x+(sub_layer(x)))
ꢀꢀꢀ
(1)
44.其中,sub_layer_output为子结构(sub-layer)的输出,layernorm为层归一化方法,x为当前子结构的输入,sub_layer(x)代表经过子结构计算之后的输出,对于第一个子结构,就是多头注意力之后的输出,对于第二个子结构,就是前馈神经网络后的输出。
45.当输入数据进入模型之后,首先与模型维护的三个矩阵(称为wq,wk,wv)计算得到query,key,value(以下称为q,k,v),然后多头注意力multi-head attention通过h个不同的线性变换对q,k,v进行投影并计算attention,将不同的attention结果拼接(concat)起来得到multi-head attention的输出,具体公式如下:
46.multihead(q,k,v)=concat(head1,head2,
……
,headh)woꢀꢀꢀ
(2)
[0047][0048]
其中multihead(q,k,v)为h头注意力的拼接并整理后的最终注意力。headh为第h个线性变换的注意力,wo为缩放矩阵,因为拼接(concat)后的矩阵大小过于庞大,需要整理成合适大小。headi为第i个线性变化计算的注意力,attention(q,k,v)为q,k,v自注意力机制,k
t
为矩阵k的转置,dk为海运邮件词向量维度。
[0049]
将公式2输出经过公式1计算得到第一个sub-layer-output的结果标记为o1,将o1输入feed-forward层,输出结果如公式4所示:
[0050]
feed
forward
=wo1+b
ꢀꢀꢀꢀꢀ
(4)
[0051]
其中,w为全连接层的权重矩阵,o1为第一个sub-layer-output输出,b为全连接层的偏置项。
[0052]
将公式4输出再经过公式1迭代n次,至此,得到bert模型输出。
[0053]
最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1