一种快速道路孤立瓶颈路段的可变限速控制方法与流程
本发明属于智能交通和交通控制技术领域,具体涉及一种快速道路孤立瓶颈路段的可变限速控制方法。
背景技术:
可变限速控制作为一种越来越被广泛用于改善快速道路交通安全的交通控制方法,其控制效果与可变限速值确定过程所采用的算法密切相关。强化学习作为一种闭环结构,通过控制效果对控制方法的反馈调节使智能体不断学习不同交通流状态下对应的最优限速值,有效提升了可变限速控制的效果和可变限速控制限速值的合理性。因此,基于强化学习算法的快速道路孤立瓶颈路段的可变限速控制方法,通过强化学习使智能体掌握不同交通流运行状态下的最优限速值。
目前的可变限速控制方法中不同交通流状态下对应的限速值的确定依赖于工程师经验主观确定,同时可变限速控制对交通流运行的影响与期望有差异,可能导致控制方法无法达到最优控制效果。本发明提出基于强化学习的快速道路孤立瓶颈路段的可变限速控制方法,相比于以往的可变限速控制算法,本发明提出的控制算法具有依据新的交通环境与数据持续学习的能力,通过实际道路交通环境下的最优控制方法的持续更新有效提升可变限速控制效果。
技术实现要素:
本发明要解决的问题是:以往针对孤立瓶颈路段的可变限速控制方法中交通流状态和限速值之间的对应关系主要由工程师主观确定,缺乏对不同交通流状态下不同可变限速值控制效果的客观分析,缺乏不同交通流状态下不同限速值与其控制效果之间的数据信息的挖掘,导致可变限速控制中限速值的确定过程缺乏理论性,具有一定主观随意性。本发明提出一种基于强化学习的快速道路孤立瓶颈路段的可变限速控制方法,通过计算机智能体学习可变限速控制方法对交通安全与通行效率改善的影响规律,确定不同交通流状态下具有最优控制效果的可变限速控制方法。克服之前可变限速控制中限速值确定过程的主观随意性,实现根据实际效果和交通流数据对最优可变限速控制方法进行反馈调节。
本发明技术方案为:
本发明提出一种快速道路孤立瓶颈路段的可变限速控制方法,基于实测交通流数据训练智能体掌握不同交通流运行状态下的最优限速值,据此在孤立瓶颈路段上游发布当前交通流状态下的最优限速值,采集可变限速控制后的限速值与交通流数据使智能体依据新的交通环境与数据持续学习,本方法对实际中通过可变限速控制方法有效降低孤立瓶颈路段内事故风险具有重要意义。实例显示,本发明提出的可变限速控制方法有很好的控制效果,能有效降低快速道路孤立瓶颈路段的安全隐患,还能不断依据实际应用后的限速值与交通流数据持续学习最优方法。
附图说明
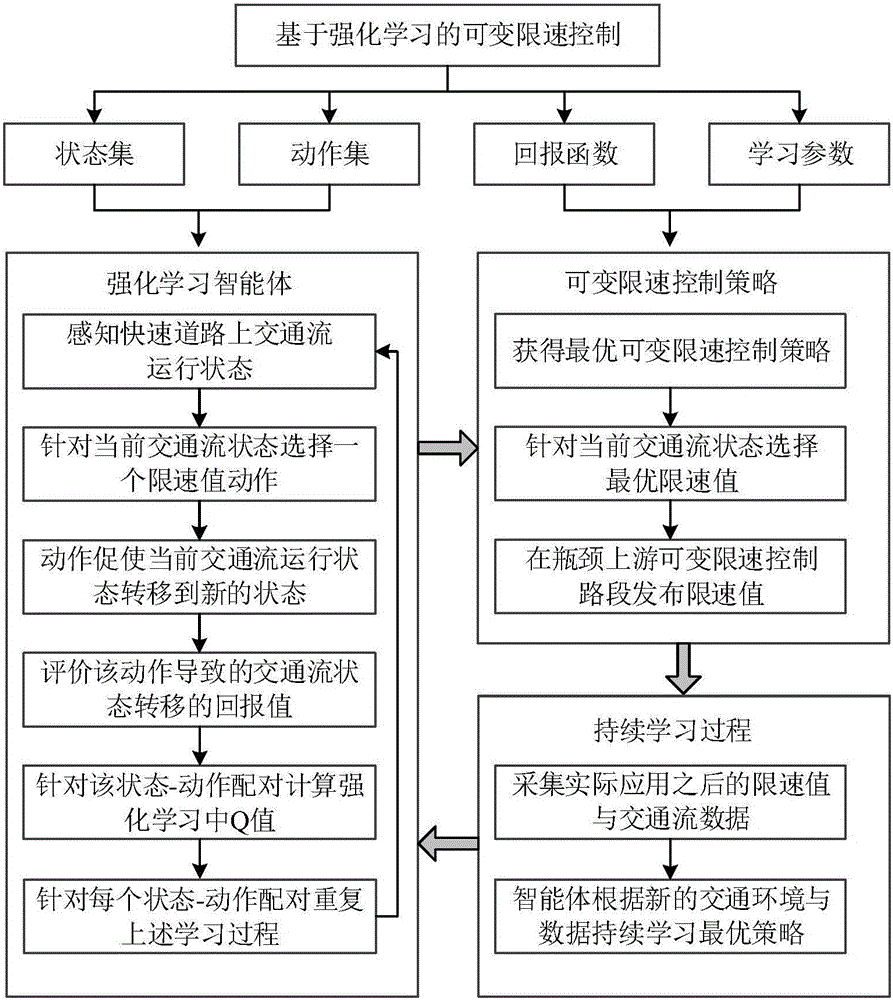
图1为快速道路孤立瓶颈路段的可变限速控制方法流程图。
图2为可变限速控制影响范围示意图。
图3为强化学习算法中交通流状态划分示意图。
图4为算例中孤立瓶颈路段示意图。
图5为算例中流量-速度分布图。
图6为无控及可变限速控制下交通流速度变化图。
具体实施方式
本发明是基于强化学习Q学习算法的基本原理和可变限速控制方法的基本流程提出针对孤立瓶颈路段上游进行可变限速控制的方法,通过交通流检测器检测孤立瓶颈路段及其上下游的交通流运行情况生成训练数据库,智能体通过离线学习掌握不同交通流状态下的最优可变限速值,在实际控制中智能体通过快速道路上实测交通流数据感知实时交通流状态,从知识库中选择当前状态对应的最优限速值对交通流进行动态调节,用控制实施后的交通流数据和限速值对智能体进行持续训练,基于强化学习的快速道路孤立瓶颈路段的可变限速控制方法的流程图如图1所示。
第一步是确定快速道路孤立瓶颈路段及其上下游范围,以合理间距设置交通流检测器,在孤立瓶颈路段上游交通流检测器位置处设置可变限速指示牌,具体获取快速道路瓶颈路段及其上下游一段时间内的真实交通流数据及可变限速控制状态数据,确定强化学习算法中的交通流状态集和动作集。由于需要了解孤立瓶颈路段及其上下游交通流信息,所以状态集应包括可变限速控制路段及其上下游三个部分,如图2中路段B、C、D所示。基于真实交通流数据绘制流量-速度分布图寻找瓶颈路段交通流的关键密度,在自由流、拥堵状态和关键密度附近分别对交通流状态进行划分获取交通流状态。由于交通流运行状态在关键密度附近变化较为敏感,故在关键密度附近1.25-2.5veh/m/ln划分交通流状态,在自由流和拥堵流中每隔5veh/m/ln划分交通流状态。强化学习算法中的交通流状态划分如图3所示,连续的交通流密度被划分为若干离散密度区间。
可变限速控制的强化学习中动作集为不同的可变限速值,限速值应在路段允许的最高和最低限速值之间,即VSL∈{Vmin,Vmax},同时考虑到驾驶员对限速值的接受情况,发布的限速值取为5或10的整数倍。大量测试可知动作集中限速值的取值范围为20mph至65mph,选取步长定为5mph,因此动作集中元素为{20mph,25mph,30mph,35mph,40mph,45mph,50mph,55mph,60mph,65mph}。
第二步是基于可变限速控制降低追尾事故风险的效果设置强化学习中的回报函数,与无控情况相比,某限速值降低路段内事故风险比例越高回报值越大;若限速值增加了路段内事故风险则在回报值中增加额外惩罚项。
首先,需要构建事故预测模型计算路段i在t时刻的事故风险R(i,t)。基于瓶颈处交通流检测器检测到的交通流数据,依据如下公式计算追尾事故风险指数RCRI:
其中,
为时间Δt内上游检测器位置平均速度,
为时间Δt内下游检测器位置平均速度,
为时间Δt内上游检测器位置平均占有率,
和分别为第j个时间Δt内上下游检测器位置车道m平均速度和上游检测器位置车道m的平均占有率;
J为一个时间段内集计交通流数据个数(J=ΔT/Δt,Δt=30s);
M为路段断面车道数。
基于公式(1)中RCRI的结果计算瓶颈所处路段i内当前时刻t的实时追尾事故风险Ri(t),计算公式如下:
其中,
P(Y=1)为追尾事故发生概率;
σ(OU)为上游检测器占有率标准差,
σ(OD)为下游检测器占有率标准差,
基于公式(2)中的实时追尾事故风险计算方法,构建如下式所示的强化学习算法的回报函数:
其中,
Reward为回报值;
PC为事故风险变化比例;
CRVSL和CRNo分别为可变限速控制和无控制下的事故风险;
R(i,k)为路段i在k时刻的事故风险;
I为路段个数;
K为仿真时间。
第三步是基于第一步中采集到的交通流和可变限速控制状态数据库训练智能体。
首先,初始化所有“状态-行为”对应的Q值为零,集计可变限速控制前后5分钟的交通流数据用于判断交通流状态转移。在Q学习每一个时间步中,基于集计的交通流数据观察当前环境状态,判断当前状态是否已执行20次动作选择,若不是,则强制智能体对每个状态尝试不同动作;若是,则采用softmax动作选择方法根据Q值确定当前状态下选择各动作的概率,方法为Q值越高动作选择中所占权重越大,该动作被选中的概率越大,具体计算公式如下:
其中,
Ps(a)为在状态s下选择行动a的概率;
T为退火温度;
Qt(s,a)为当前时刻“状态-行为”对应的Q值。
其次,做出动作选择后,基于由第二步中公式(3)计算得到的“状态-行为”的回报值,需要对各“状态-行为”组合的回报值Q进行更新,Q学习算法中按照下式调整Q值:
Qt+1(st,at)=Qt(st,at)+λt(st,at)×[Rt+1+γmaxQt(st,at)-Qt(st,at)] (7)
其中,Qt+1(st,at)为t+1时刻对应的Q值,Qt(st,at)为t时刻对应的Q值,λt(st,at)(0<λ<1)是学习速率,γ为折扣因子(0<γ<1),折衷马上获得的与延迟获得的奖励。
本专利中对公式(7)进行简化,不考虑延迟获得的奖励,综合考虑模型运行效率和仿真准确性后,本专利采用下式更新Q值:
Qt+1(st,at)=Rt+1+0.8×max Qt(st+1,at+1) (8)
其中,
Qt+1(st,at)为t+1时刻对应的Q值;
Qt(st+1,at+1)为t时刻对应的Q值;
Rt+1为t+1时刻对应的回报函数值。
更新Q值后进入下一个学习时间步,循环上述过程直到Q值收敛,则每个状态下最大Q值对应的动作即为最优控制方法。
第四步是采用第三步中得到的各状态及其最大Q值对应的动作组进行可变限速控制,基于当前交通流检测器采集到的5分钟的平均交通流密度判断单签交通流状态,采用智能体实时选择当前交通流状态下的最优限速值,将最优限速值传递至瓶颈上游可变限速控制指示牌发布限速值。
第五步是继续实时采集发布最优限速值后的交通流数据和限速值并传回控制系统,智能体依据新的交通流数据和限速值重复上述第二步到第四步持续学习最优控制方法。
下面结合附图对发明的可变限速控制方法进行了实例演示:
假设某一快速道路孤立瓶颈路段如图4所示,图中检测器2处为一处孤立瓶颈,瓶颈路段下游、上游和上上游分别设置了检测器1、3和4,在瓶颈路段检测器3处设置了可变限速控制指示牌。假设该路段一周内交通流检测器检测到的历史交通流数据如图5所示,则关键密度为30veh/m/ln左右。状态集中元素为包含路段2、3、4上交通流状态的状态向量,记为S(s2,s3,s4),动作集中元素为{20mph,25mph,30mph,35mph,40mph,45mph,50mph,55mph,60mph,65mph}。
将图5中的历史交通流数据库用于训练智能体,通过强化学习得到路段2、3、4上不同交通流状态排列组合得到的所有状态向量S对应的动作集中的最佳限速值。判断检测器2、3、4实时检测到的交通流数据对应的交通流状态s2,s3和s4,找到状态向量S(s2,s3,s4)对应的最优限速值为v,将v值传递至检测器2处的可变限速控制指示牌并发布信息“当前限速值为v,请小心驾驶”。同时,将当前时刻的最优可变限速值v和交通流状态S传回控制系统添加至训练数据库中。
在高交通需求条件下,无控制状态和采用上述基于强化学习算法的可变限速控制下的交通流速度变化如图6所示。由图可以看出,无控条件下在孤立瓶颈路段生成拥堵后,队尾车辆需从自由流速度速降至拥堵车速;而基于强化学习算法的可变限速控制使拥堵尾部的交通流速度逐步下降,平滑了交通流运行,有效降低了追尾事故的发生。
- 还没有人留言评论。精彩留言会获得点赞!