一种录音融合方法与流程
本发明涉及音频处理领域,具体涉及一种录音融合方法。
背景技术:
随着唱吧、全民k歌等手机软件及自助式ktv的流行,录音分享越来越普及。但一般用户反复唱同一首歌,很难录到一遍完整无瑕的演唱。经常碰到各处的抢拍、漏词、走调、甚至附近有人故意干扰、说话尖叫。因此有必要提供一种方法,帮助用户获取一个完整的效果最好的录音。
技术实现要素:
本发明的目的就是提供一种录音融合方法,其能够帮助用户获取一个完整的效果最好的录音。
为实现上述目的,本发明采用了以下技术方案:
一种录音融合方法,包括如下操作:
s1:获取同一歌曲的n次录音的录音文件,n≥2;
s2:采用同一切分方法将各个录音文件按照时序分别切分为m个唱段,m≥2,采用同一评分方法对各唱段分别进行评分,依次对相同时段的各唱段的评分进行比较并选取出评分最高的唱段;
s3:将各选取出的各评分最高的唱段按照时序进行融合拼接获取得到融合录音。
进一步的方案为:
步骤s2中录音文件切分方法为:录音文件的数据通过和原唱的对比并以最高得分唱段为中心点对齐;将对齐的录音文件的首尾不对齐的部分切除,并以不同唱段间隙中心点为分界将录音文件分成不同的唱段,这样不同的录音文件被切成了完全对齐的唱段。
步骤s3中融合拼接采用淡进淡出算法。
步骤s2中唱段评分的方法为:通过实时对比用户和原唱的每个发音基频和发音音长度来获得歌唱的匹配度,分析出用户是否走音、抢拍或漏拍,给出歌唱评分。亦即采用ktv的精确评分方法进行评分。
上述技术方案中,通过选取出各个时段评分最高的唱段,然后将各高评分的唱段进行融合拼接,从而帮助用户获取一个完整的效果最好的录音。
附图说明
图1为本发明的流程示意图;
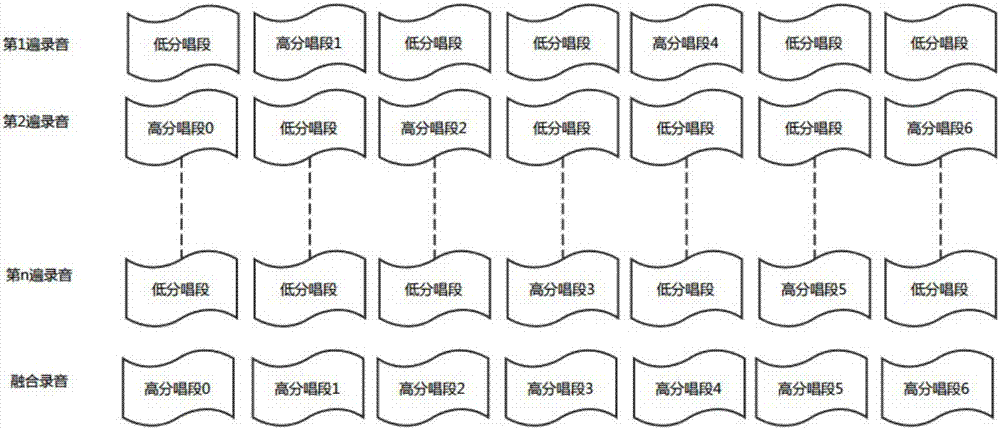
图2为录音文件切分、拼接示意图;
图3为评分方法示意图;
图4为融合拼接的示意图。
具体实施方式
为了使本发明的目的及优点更加清楚明白,以下结合实施例对本发明进行具体说明。应当理解,以下文字仅仅用以描述本发明的一种或几种具体的实施方式,并不对本发明具体请求的保护范围进行严格限定。
本发明采取的技术方案如图1、2、3、4所示,一种录音融合方法,包括如下操作:
s1:获取同一歌曲的n次录音的录音文件,n≥2;各录音文件分别记为录音1、录音1……录音n;
s2:采用同一切分方法将各个录音文件按照时序分别切分为m个唱段,m≥2,采用同一评分方法对各唱段分别进行评分,依次对相同时段的各唱段的评分进行比较并选取出评分最高的唱段;如录音1切分后的唱段依次为c11、c12……c1m;录音2切分后的唱段依次为c21、c22……c2m……录音n切分后的唱段依次为cm1、cm2……cmn;采用同样的评分方法对c11、c12……c1m、c21、c22……c2m……cm1、cm2……cmn分别进行评分,比较同一时段各唱段的评分,如c11、c21……cm1为同一时段的唱段,比较其评分选取出评分最高的记为c1-best;c12、c22……cm2为同一时段的唱段,比较其评分选取出评分最高的记为c2-best;cm1、cm2……cmn为同一时段的唱段,比较其评分选取出评分最高的记为cm-best,如图2所示;
s3:将各选取出的各评分最高的唱段按照时序进行融合拼接获取得到融合录音。亦即将步骤s2中选取出的唱段c1-best、c2-best……cm-best按照时序融合拼接获取得到录音文件。
上述技术方案中,通过选取出各个时段评分最高的唱段,然后将各高评分的唱段进行融合拼接,从而帮助用户获取一个完整的效果最好的录音。
步骤s2中唱段评分的方法为:通过实时对比用户和原唱的每个发音基频和发音音长度来获得歌唱的匹配度,分析出用户是否走音、抢拍或漏拍,给出歌唱评分。分数高代表歌唱的匹配度高、唱得好,分数低代表歌唱的匹配度低、唱得差,这个分数将在本发明中起到重要作用。
图3为一段典型的歌声(无伴奏)的分析:第一行是歌声,可以清晰的看到一段声音静息的分界点(红框),每个分界点代表一段歌词结束,歌唱者在换气或者等待第二段歌词出现;第二行是声音端点检测结果,每个小方块代表一个吐词,小方块的长短代表发音的长度,大的空隙是歌词的停顿处;第三行是每个声音的基频分析结果,基频代表了音调;这样的歌声分析我们获得了基频和发音长度两个基本参数,通过和原唱的参数的比对可以检测到歌唱者是否有抢拍、漏词、走调等问题,并给出具体的歌唱评分,而且是每个发音,每句歌词可以有单独的评分。
步骤s2具体的操作为:基于同一个mtv录音,至少需要有两个录音文件和相关的评分结果;基于同一首歌的录音一般是大致等长的,但声音不一定同步,每个录音文件的数据通过和原唱的对比并以最高得分唱段为中心点对齐;将对齐的文件首尾不对齐的部分切除,并以不同唱段间隙中心点为分界将录音数据分成不同的唱段,这样不同的录音文件被切成了完全对齐的唱段。
步骤s3中融合拼接采用淡进淡出算法,如图4所示,使用淡进淡出算法,并且只使用在唱段的间隙处,即前一唱段最后一个发音结束后,音量逐渐减少到0,后一唱段第一个发音前,音量从0逐渐增加到正常值,然后两个相加。
本发明利用了ktv的精确评分,将同一个人同一首歌的不同录音根据歌词的分界点切分成各唱段,然后将等分最高的几段拼接融合在一起,从而极大提高了唱歌的乐趣。
本发明未能详尽描述的设备、机构、组件和操作方法,本领域普通技术人员均可选用本领域常用的具有相同功能的设备、机构、组件和操作方法进行使用和实施。或者依据生活常识选用的相同设备、机构、组件和操作方法进行使用和实施。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在获知本发明中记载内容后,在不脱离本发明原理的前提下,还可以对其作出若干同等变换和替代,这些同等变换和替代也应视为属于本发明的保护范围。
技术特征:
技术总结
本发明涉及一种录音融合方法,包括获取同一歌曲的n次录音的录音文件;采用同一切分方法将各个录音文件按照时序分别切分为m个唱段,采用同一评分方法对各唱段分别进行评分,依次对相同时段的各唱段的评分进行比较并选取出评分最高的唱段;将各选取出的各评分最高的唱段按照时序进行融合拼接获取得到融合录音。上述技术方案中,通过选取出各个时段评分最高的唱段,然后将各高评分的唱段进行融合拼接,从而帮助用户获取一个完整的效果最好的录音。
技术研发人员:单花连;张文珽
受保护的技术使用者:无锡冰河计算机科技发展有限公司
技术研发日:2017.07.19
技术公布日:2017.11.17
- 还没有人留言评论。精彩留言会获得点赞!