一种数字音频剪辑高质量优化拼接方法与流程
1.本发明涉及数字音频信号处理领域,尤其是涉及一种数字音频剪辑高质量优化拼接方法。
背景技术:
2.在现代各种多媒体的软件应用中,凡是涉及音频数据pcm的数据处理,基本上都需要对音频数据进行剪辑,剪辑位置,就需要重新拼接两块非连续的音频数据。
3.原始的数字音频数据,在微观上(到采样点级),体现为连续的以不同频率不同幅度振动的波形信号和数据。如图1所示,其波形是有根据前述信号按一定趋势振荡的,不会存在两采样点间信号突然大幅度越变的情况。
4.图1为立体声音频信号波形,每一小点即为单个采样点数据,可以看到采样点之间,是有限的数据变换,正常波形下,音频音质是有保证的。
5.当剪辑时,两段非连续音频信号将拼接到一起,拼接位置两采样点信号的数据关系就存在非常的不确定性,有较大的可能发生跃变,导致播放该音频到拼接时,就有可能听到噪点,影响音频播出质量,如图2所示。
6.而一般的拼接算法,只做简单数据块合并,并未做音频质量提升算法,对音频质量要求较高的领域,就会在一定程度上影响音质。
技术实现要素:
7.本发明主要是解决现有技术所存在的音频剪辑拼合后出现噪点,影响音质的技术问题,提供一种可以避免拼接噪点出现,实现圆滑过渡的数字音频剪辑高质量优化拼接方法。
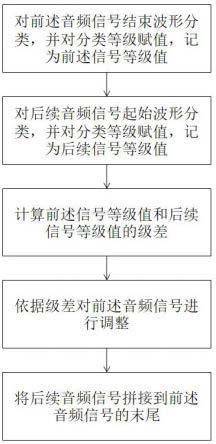
8.本发明针对上述技术问题主要是通过下述技术方案得以解决的:一种数字音频剪辑高质量优化拼接方法,包括以下步骤:s1、对前述音频信号结束波形分类,并对分类等级赋值,记为前述信号等级值;s2、对后续音频信号起始波形分类,并对分类等级赋值,记为后续信号等级值;s3、计算前述信号等级值和后续信号等级值的级差;s4、依据级差对前述音频信号进行调整;s5、将后续音频信号拼接到前述音频信号的末尾。
9.作为优选,所述步骤s1具体为:s101、如果v-1
大于或等于0,则进入步骤s102,如果v-1
小于0,则跳转到步骤s104;s102、如果v-2
、v-3
和v-4
中的最小值小于零,则前述信号等级值赋为0.5,步骤s1结束;如果v-2
、v-3
和v-4
中的最小值大于或等于零,则进入到步骤s103;s103、如果v-2
到v-11
的最大值小于v-1
,则前述信号等级值赋为1,步骤s1结束;如果v-2
到v-11
中的最大值大于或等于v-1
,则前述信号等级赋值为2,步骤s1结束;s104、如果v-2
、v-3
和v-4
中的最大值大于零,则前述信号等级值赋为-0.5,步骤s1结
束;如果v-2
、v-3
和v-4
中的最大值小于或等于零,则进入到步骤s105;s105、如果v-2
到v-11
中的最大值大于v-1
,则前述信号等级值赋为-1,步骤s1结束;如果v-2
到v-11
中的最大值小于或等于v-1
,则前述信号等级赋值为-2,步骤s1结束;v-1
是前述音频信号的最后一个采样点的采样值,v-2
是前述音频信号的倒数第二个采样点的采样值,v-3
到v-11
以此类推。例如16位精度,则采样值的范围是-32768~32768。
10.作为优选,所述步骤s2具体为:s201、如果v1大于或等于0,则进入步骤s202;如果v1小于0,则跳转到步骤s204;s102、如果v2、v3和v4中的最小值小于零,则后续信号等级值赋为0.5,步骤s2结束;如果v2、v3和v4中的最小值大于或等于零,则进入到步骤s203;s203、如果v2到v
11
的最小值大于v1,则后续信号等级值赋为1,步骤s2结束;如果v2到v
11
中的最小值小于或等于v1,则后续信号等级赋值为2,步骤s2结束;s204、如果v2、v3和v4中的最大值大于零,则后续信号等级值赋为-0.5,步骤s2结束;如果v2、v3和v4中的最大值小于或等于零,则进入到步骤s205;s205、如果v2到v
11
中的最大值小于v1,则后续信号等级值赋为-1,步骤s2结束;如果v2到v
11
中的最大值大于或等于v1,则后续信号等级赋值为-2,步骤s2结束;v1是后续音频信号的第一个采样点的采样值,v2是后续音频信号的第二个采样点的采样值,v3到v
11
以此类推。
11.作为优选,步骤s3中级差为前述信号等级值和后续信号等级值之差的绝对值。
12.作为优选,步骤s4具体为:如果级差大于等于0且小于等于1,则不对前述音频信号进行调整;如果级差大于1且小于等于2,则将前述音频信号的最后一个采样值v-1
调整为倒数第二个采样值v-2
和后续音频信号的第一个采样值v1的平均值;如果级差大于2且小于等于3,则将前述音频信号的最后一个采样值v-1
调整为倒数第二个采样值v-2
和后续音频信号的第一个采样值v1的平均值;将前述音频信号的倒数第二个采样值v-2
调整为倒数第三个采样值v-3
和后续音频信号的第一个采样值v1的平均值;将前述音频信号的倒数第三个采样值v-3
调整为倒数第四个采样值v-4
和后续音频信号的第一个采样值v1的平均值;如果级差大于3,则将前述音频信号的最后一个采样值v-1
调整为倒数第二个采样值v-2
和后续音频信号的第一个采样值v1的平均值;将前述音频信号的倒数第二个采样值v-2
调整为倒数第三个采样值v-3
和后续音频信号的第一个采样值v1的平均值;将前述音频信号的倒数第三个采样值v-3
调整为倒数第四个采样值v-4
和后续音频信号的第一个采样值v1的平均值;将前述音频信号的倒数第四个采样值v-4
调整为倒数第五个采样值v-5
和后续音频信号的第一个采样值v1的平均值;将前述音频信号的倒数第五个采样值v-5
调整为倒数第六个采样值v-6
和后续音频信号的第一个采样值v1的平均值。
13.在调整时,所基于的临近采样值均为原值,例如调整v-2
时,所用的v-3
是调整之前的原值。
14.本发明带来的实质性效果是,提高拼接点的音质,避免噪点出现,算法复杂度和时间复杂度较低,对运算资源要求不高。
附图说明
15.图1是一种正常立体声音频信号示意图;图2是一种有拼接的立体声音频信号示意图;图3是本发明的一种流程图。
具体实施方式
16.下面通过实施例,并结合附图,对本发明的技术方案作进一步具体的说明。
17.实施例:本实施例的一种数字音频剪辑高质量优化拼接方法,如图3所示,包括以下步骤:s1、对前述音频信号结束波形分类,并对分类等级赋值,记为前述信号等级值;s2、对后续音频信号起始波形分类,并对分类等级赋值,记为后续信号等级值;s3、计算前述信号等级值和后续信号等级值的级差;s4、依据级差对前述音频信号进行调整;s5、将后续音频信号拼接到前述音频信号的末尾。
18.步骤s1具体为:s101、如果v-1
大于或等于0,则进入步骤s102,如果v-1
小于0,则跳转到步骤s104;s102、如果v-2
、v-3
和v-4
中的最小值小于零(即波形为正向近0形),则前述信号等级值赋为0.5,步骤s1结束;如果v-2
、v-3
和v-4
中的最小值大于或等于零,则进入到步骤s103;s103、如果v-2
到v-11
的最大值小于v-1
(即波形为正向上升形),则前述信号等级值赋为1,步骤s1结束;如果v-2
到v-11
中的最大值大于或等于v-1
(即波形为正向下降形),则前述信号等级赋值为2,步骤s1结束;s104、如果v-2
、v-3
和v-4
中的最大值大于零(即波形为负向近0形),则前述信号等级值赋为-0.5,步骤s1结束;如果v-2
、v-3
和v-4
中的最大值小于或等于零,则进入到步骤s105;s105、如果v-2
到v-11
中的最大值大于v-1
(即波形为负向上升形),则前述信号等级值赋为-1,步骤s1结束;如果v-2
到v-11
中的最大值小于或等于v-1
(即波形为负向下降形),则前述信号等级赋值为-2,步骤s1结束;v-1
是前述音频信号的最后一个采样点的采样值,v-2
是前述音频信号的倒数第二个采样点的采样值,v-3
到v-11
以此类推。
19.步骤s2具体为:s201、如果v1大于或等于0,则进入步骤s202;如果v1小于0,则跳转到步骤s204;s102、如果v2、v3和v4中的最小值小于零(即波形为正向近0形),则后续信号等级值赋为0.5,步骤s2结束;如果v2、v3和v4中的最小值大于或等于零,则进入到步骤s203;s203、如果v2到v
11
的最小值大于v1(即波形为正向上升形),则后续信号等级值赋为1,步骤s2结束;如果v2到v
11
中的最小值小于或等于v1(即波形为正向下降形),则后续信号等级赋值为2,步骤s2结束;s204、如果v2、v3和v4中的最大值大于零(即波形为负向近0形),则后续信号等级值赋为-0.5,步骤s2结束;如果v2、v3和v4中的最大值小于或等于零,则进入到步骤s205;s205、如果v2到v
11
中的最大值小于v1(即波形为负向上升形),则后续信号等级值赋为-1,步骤s2结束;如果v2到v
11
中的最大值大于或等于v1(即波形为负向下降形),则后续
信号等级赋值为-2,步骤s2结束;v1是后续音频信号的第一个采样点的采样值,v2是后续音频信号的第二个采样点的采样值,v3到v
11
以此类推。
20.步骤s3中级差为前述信号等级值和后续信号等级值之差的绝对值。
21.步骤s4具体为:如果级差大于等于0且小于等于1,则不对前述音频信号进行调整;如果级差大于1且小于等于2,则将前述音频信号的最后一个采样值v-1
调整为倒数第二个采样值v-2
和后续音频信号的第一个采样值v1的平均值;如果级差大于2且小于等于3,则将前述音频信号的最后一个采样值v-1
调整为倒数第二个采样值v-2
和后续音频信号的第一个采样值v1的平均值;将前述音频信号的倒数第二个采样值v-2
调整为倒数第三个采样值v-3
和后续音频信号的第一个采样值v1的平均值;将前述音频信号的倒数第三个采样值v-3
调整为倒数第四个采样值v-4
和后续音频信号的第一个采样值v1的平均值;如果级差大于3,则将前述音频信号的最后一个采样值v-1
调整为倒数第二个采样值v-2
和后续音频信号的第一个采样值v1的平均值;将前述音频信号的倒数第二个采样值v-2
调整为倒数第三个采样值v-3
和后续音频信号的第一个采样值v1的平均值;将前述音频信号的倒数第三个采样值v-3
调整为倒数第四个采样值v-4
和后续音频信号的第一个采样值v1的平均值;将前述音频信号的倒数第四个采样值v-4
调整为倒数第五个采样值v-5
和后续音频信号的第一个采样值v1的平均值;将前述音频信号的倒数第五个采样值v-5
调整为倒数第六个采样值v-6
和后续音频信号的第一个采样值v1的平均值。
22.在调整时,所基于的临近采样值均为原值,例如调整v-2
时,所用的v-3
是调整之前的原值。
23.经过上述优化后,更重要的后续音频,保持不变,前续结尾波形,上述拼接算法,最大影响范围为5个采样点(按广播数字音频标准计算,5/48000=1.04毫秒),该最大调整范围不会影响音频内容的听觉感受,同时保证接续波形数据的连贯性,抑制了拼接噪声的发生。
24.本文中所描述的具体实施例仅仅是对本发明精神作举例说明。本发明所属技术领域的技术人员可以对所描述的具体实施例做各种各样的修改或补充或采用类似的方式替代,但并不会偏离本发明的精神或者超越所附权利要求书所定义的范围。
25.尽管本文较多地使用了前述音频信号、后续音频信号、级差等术语,但并不排除使用其它术语的可能性。使用这些术语仅仅是为了更方便地描述和解释本发明的本质;把它们解释成任何一种附加的限制都是与本发明精神相违背的。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1