一种电力系统多台发电机组分群方法与流程
本发明涉及电力系统及其自动化领域,具体涉及一种电力系统多台发电机组分群方法。
背景技术:
随着电网的不断发展壮大,电力系统动态行为也随之变得越来越复杂,给研究带来极大的困难。对同调机组分群的研究为我们提供了一个新的思路,根据整个系统同调机组的分群特点,可将整个系统等效为相互解耦的多个子系统,以达到简化系统的目的。除此之外,根据电网机组的分群规律,可以对扰动后的电网采取的相关稳控措施,乃至电网解列等问题的研究提供很好的的参考价值和指导意义。
目前,机组分群的方法主要有两类:基于模型参数的方法和基于摇摆曲线的方法。其中基于摇摆曲线的分群方法应用较为广泛,主要包括时域法和频域法。其主要思想是根据发电机的离线仿真轨迹进行初步预分群,再进行在线动态修正,即“离线预分群、在线动态修正”。近年来随着交叉学科的不断发展,又陆续出现了基于小波变换、人工神经网络、模糊理论及聚类分析的机群识别新方法。
技术实现要素:
有鉴于此,本发明的目的在于提供一种电力系统多台发电机组分群方法,解决了个别点偏移较大而造成分群失败的问题,并进一步对曼哈顿距离进行优化。
为实现上述目的,本发明采用如下技术方案:
一种电力系统多台发电机组分群方法,包括以下步骤:
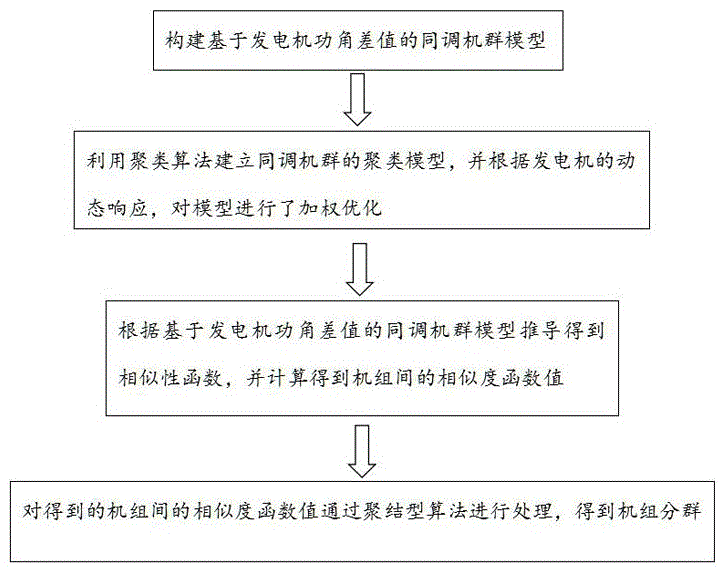
步骤s1:构建基于发电机功角差值的同调机群模型;
步骤s2:根据曼哈顿距离,并基于发电机的动态特性,对同调机群模型进行加权优化;
步骤s3:根据经过优化后的基于发电机功角差值的同调机群模型推导得到相似性函数,并计算得到机组间的相似度函数值;
步骤s4:对得到的机组间的相似度函数值通过聚结型算法进行处理,得到机组分群。
进一步的,所述步骤s1具体为:
在仿真时间t∈[0,τ]内,如果发电机i和发电机j的平均相对转子角偏差不大于给定的标准ε,则判定这2台机关于τ时间段同调,建立基于发电机功角差值的同调机群模型:
δδi=δi-δi0δδj=δj-δj0(2)
其中,t0为仿真时间初值,τ为仿真时间;δi、δj为发电机i、j的功角;δi0、δj0为功角初值;δδi、δδj为主导振荡分量;
即:davg(ij)表示的是τ时间内,两机组之间的平均功角差;若发电机i、j满足:davg(ij)<ε,则发电机i、j是同群,若一组发电机彼此之间是同群的,则这组发电机是同群的,ε为预设数值。
进一步的,所述步骤s3具体为:
步骤s31:根据曼哈顿距离,将同调机群模型模拟为dij:
其中ωk为权值,,xi,xj分别表述的是发电机i、j的功角δi、δj,k=1时,xi1,xj1分别表述的是发电机i、j的功角初值δi0、δj0,n为数据维数,具体描述为时间τ时间内发电机i、j功角的n个采样点;
步骤s32:在电力系统同调机组分群过程中,令聚类样本x为功角轨迹δ,则dij可以等效为任意两机功角轨迹的相似度函数δμij:
步骤s33:根据各待分群机组数据和基于发电机功角差值的同调机群模型,得到各待分群机组功角轨迹;
步骤s34:根据得到的各待分群机组功角轨迹,计算得到机组间的相似度函数值。
进一步的,所述权值ωk为:
式中,k=1,2,3…n,n表示t时间内采样点的个数。
本发明与现有技术相比具有以下有益效果:
1、本发明有效地解决了原方法中存在的会出现因个别点偏移较大而造成在τ时间内,dmax(ij)>ε,从而导致分群失败的问题。
2、本发明进一步地对曼哈顿距离进行优化,在基于平均功角差的同调机群模型的基础上,提出了一种加权平均的优化处理方法,解决了如果样本数据中出现个别无判定价值的突变量,运用总和来判定距离势必会造成较大误差的问题。
附图说明
图1是本发明方法流程图;
图2是本发明实施例1中树形聚类结构图;
图3是本发明实施例1中发电机功角轨迹图;
图4是本发明实施例2中树形聚类结构图;
图5是本发明实施例2中发电机功角轨迹图;
图6是本发明一实施例中采用的聚结型算法聚合过程图。
具体实施方式
下面结合附图及实施例对本发明做进一步说明。
请参照图1,本发明提供一种电力系统多台发电机组分群方法,包括以下步骤:
步骤s1:构建基于发电机功角差值的同调机群模型;
步骤s2:根据曼哈顿距离,并基于发电机的动态特性,对同调机群模型进行加权优化;
步骤s3:根据经过优化后的基于发电机功角差值的同调机群模型推导得到相似性函数,并计算得到机组间的相似度函数值;
步骤s4:对得到的机组间的相似度函数值通过聚结型算法进行处理,得到机组分群。
在本发明一实施例中,所述步骤s1具体为:
在仿真时间t∈[0,τ]内,如果发电机i和发电机j的平均相对转子角偏差不大于给定的标准ε,则判定这2台机关于τ时间段同调,建立基于发电机功角差值的同调机群模型:
δδi=δi-δi0δδj=δj-δj0(2)
其中,t0为仿真时间初值,τ为仿真时间;δi、δj为发电机i、j的功角;δi0、δj0为功角初值;δδi、δδj为主导振荡分量;
即:davg(ij)表示的是τ时间内,两机组之间的平均功角差;若发电机i、j满足:davg(ij)<ε,则发电机i、j是同群,若一组发电机彼此之间是同群的,则这组发电机是同群的,ε为预设数值。
在本发明一实施例中,所述步骤s3具体为:
步骤s31:利用聚类的方法进行机组分群,根据同调机群的模型,利用曼哈顿距离作为划分机组分群类别的评价函数进行描述,聚类过程本质上是一种求取最优解的过程,每一步骤都是通过一种快速运算使系统的目标函数达到一个极小值。目标函数则是划分类别的评价函数,通常以距离为划分的评价标准,如明可夫斯基距离(minkowskidistance)、欧氏距离、切比雪夫距离(chebychevdistance)、相关系数等。若令n为数据维数,xi、xj为2个聚类样本,则明可夫斯基距离和切比雪夫距离分别为:
式(1)中,当p=2时表示欧氏距离,p=l时表示曼哈顿距离;
根据曼哈顿距离,将同调机群模型模拟为dij:
其中ωk为权值,,xi,xj分别表述的是发电机i、j的功角δi、δj,k=1时,xi1,xj1分别表述的是发电机i、j的功角初值δi0、δj0,n为数据维数,具体描述为时间τ时间内发电机i、j功角的n个采样点;
步骤s32:在电力系统同调机组分群过程中,令聚类样本x为功角轨迹δ,则dij可以等效为任意两机功角轨迹的相似度函数δμij:
步骤s33:根据各待分群机组数据和基于发电机功角差值的同调机群模型,得到各待分群机组功角轨迹;
步骤s34:根据得到的各待分群机组功角轨迹,计算得到机组间的相似度函数值。
在本发明一实施例中,所述权值ωk为:
式中,k=1,2,3…n,n表示t时间内采样点的个数。
实施例1:
设置两条500kv线路发生三相短路故障、0.3s切除故障,同时四回线路跳闸。在τ时间内,以故障发生时刻第15周波为初始时刻t0,每15个周波(0.3s)为一个数据采样点,共有10个,即15周波处、30周波处、45周波处、60周波处、75周波处、90周波处、105周波处、120周波处、135周波处、150周波处。
以机组a和机组b为例,根据各自的功角轨迹,可计算出上述10个采样点处的功角轨迹差δδ和加权值ω,如下表所示:
表1:功角轨迹差δδab单位:度
表2:加权值ω
tab2:weightedvalueω
根据式
依此类推可以求出其他各机组之间的功角相似度函数δμij的值,如下表所示:
表3:机组的功角轨迹相似度函数δμij(1)单位:度
tab.3:thesimilarityfunctionofpowerangletrajectoryδμij(1)unit:
degrees
对所得通过功角相似度函数δμij进行聚类分析,通过层次聚类方法,聚类过程以树形聚类结构图所示如图2所示:
由此可得:各机组最初是各成一类,根据功角相似度函数δμij的大小,自下而上逐步合并。当ε取10°时,机组分为两群,其中机组a、b、c、d、f、h、k为同一个机群,机组e、g、i、j为同一个机群。
通过功角曲线图,也直观地证实了上文通过两机功角轨迹的相似度函数δμij进行聚类分群的正确性。发电机功角轨迹如图3所示:
图中列出了11个主力大电厂的发电机功角曲线,如图所示,故障发生后第15个周波,机组之间出现失步振荡,全网机组主要分为两大机群,机群之间功角差超过180°,而机群内部则在作同步振荡。通过计算得到机组分群规律如下:机组a、b、c、d、f、h、k在τ(3s)的时间段,机组之间相对功角均在ε(10°)以内,分为一群;机组e、g、i、j在τ(3s)的时间段,机组之间相对功角均在ε(10°)以内,也为一群。
实施例2:
设置双回500kv线路发生三相短路故障、0.3s切除故障,同时双回线路跳闸。计算可得各机组之间的功角相似度函数δμij的值,如下表所示:
表4:机组的功角轨迹相似度函数δμij(2)单位:度
tab.4:thesimilarityfunctionofpowerangletrajectoryδμij(2)unit:degrees
对所得通过功角相似度函数δμij进行聚类分析,通过层次聚类方法,聚类过程以树形聚类结构图如图4所示
由此可得:当ε取10°时,机组分为两群,其中机组a、b、c、d、f、h、k为同一个机群,机组e、g、i、j为同一个机群。
计算所得发电机功角轨迹曲线如图5所示。
本实施例采用的层次聚类法是聚结型算法agnes(agglomerativenesting)又称自下而上聚合层次聚类方法,其聚类过程是先将n个样本各自看成一类,并规定样本与样本之间的距离和类与类之间的距离。开始时,因每个样本自成一类,类与类之间的距离与样本之间的距离是相同的。然后,在所有的类中,选择距离最小的两个类合并成一个新类,并计算出所得新类和其它各类的距离;接着再将距离最近的两类合并,这样每次合并两类,直至将所有的样本都合并成一类为止。整个过程可表示成一个二叉层次树,其中最底层子结点表示每个样本,中间结点表示两个子类合并而成的父类。其优点是聚类算法灵活多变、聚合过程脉络清晰、可视化程度高,且聚类结果不依赖样本的初始排列,聚类结果比较稳定,不易导致类的重构。聚合过程如图6所示。
以上所述仅为本发明的较佳实施例,凡依本发明申请专利范围所做的均等变化与修饰,皆应属本发明的涵盖范围。
- 还没有人留言评论。精彩留言会获得点赞!