一种DSP小端模式下的高速维特比译码方法及其接收机与流程
本发明涉及一种维特比译码方法,尤其涉及一种在dsp小端模式下运行的高速维特比译码方法,同时涉及采用该高速维特比译码方法的接收机,属于无线通信
技术领域:
。
背景技术:
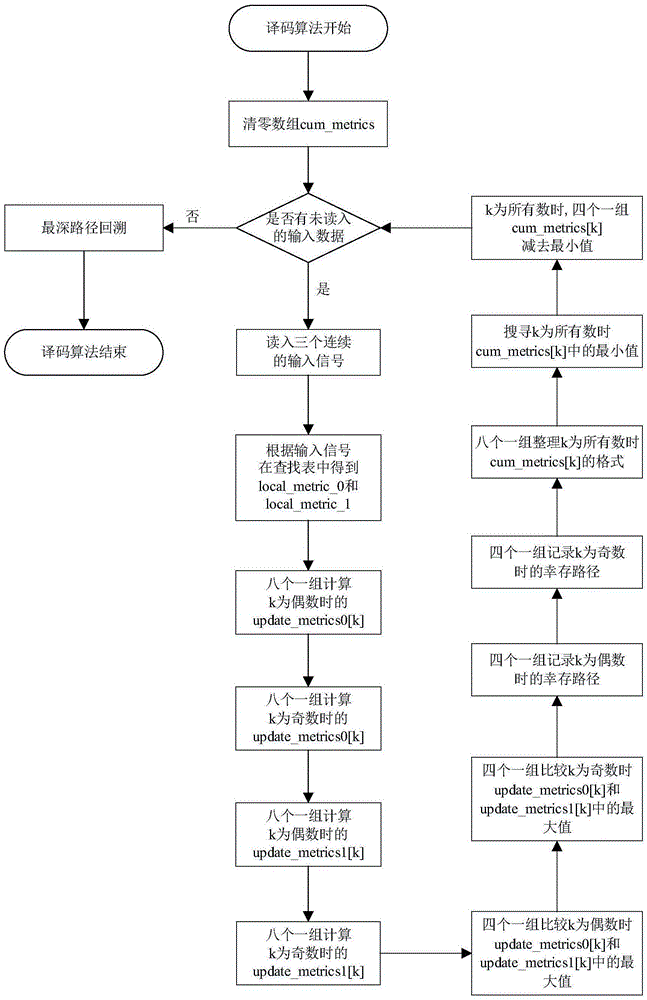
:在无线通信系统中,由于信道传输特性不理想以及噪声的存在,会导致接收端出现接收信号的错误,因此用于纠错的信道编码是极为重要的技术环节。所谓信道编码,是在发送端对原数据添加和原数据相关的冗余信息,再在接收端根据这种相关性来检测和纠正传输过程产生的差错。卷积码是一种在无线通信系统中广泛使用的信道编码技术,20世纪70年代就应用在深空和卫星通信中。其中,(3,1,7)型卷积码由于在误码性能和译码复杂度上取得了较好的折衷,许多通信系统都采用了该型卷积码,例如lte系统等。维特比(viterbi)译码是卷积码的最优译码算法,在实际中得到了广泛的应用。维特比译码包括计算路径回溯和路径度量两部分。针对路径回溯问题,在专利号为zl200910008300.3的中国发明专利中,华为公司提出了一种增强译码方法,用于降低在dsp里实现增强viterbi译码算法路径回溯过程中的运算量。该增强译码方法包括如下步骤:获取从不可靠节点开始的、并且回溯长度与预定回溯长度相等的回溯路径;将所述回溯路径转换为对应的译码结果;用所述译码结果替换最大似然译码序列中与所述回溯路径对应位置的译码结果;输出替换过译码结果的译码序列。路径度量的计算需要通过加-比-选操作来完成。通常情况下,其计算量远大于路径回溯。在申请号为us19950558745的美国专利中,提出了一种专门针对维特比译码优化的dsp设备,其主要思路是设计专用的硬件结构来提高维特比译码的速度。由于使用了专用硬件,所以无法将其应用到通用型dsp上。在申请号为us20020243567的美国专利中,提出了一种改进型dsp译码方法。其主要思路是利用专用指令如vmshl、vitsel、vitadd、vitmax、vitmin来提高译码的速度。但是,许多通用型dsp上并不提供这些专用指令,因而无法使用该方法。为了在通用型处理器上提高译码的速度,有人在x86系列处理器上将译码中的部分计算预先离线完成,用存储资源来换取译码速度的提高(参见philkarnandmatthiasp.braendli,theka9q'sfeclibrary.[online].available:https://github.com/opendigitalradio/ka9q-fec,feb.2012)。但是,该方法仅仅针对x86系列处理器实现了优化。在嵌入式系统中,dsp的使用更为广泛。dsp与x86系列处理器在结构上有较大的差异。在dsp上进行维特比译码,需要根据dsp的系统架构和指令特点优化相关的算法。技术实现要素:本发明所要解决的首要技术问题在于提供一种dsp小端模式下的高速维特比译码方法。本发明所要解决的另一技术问题在于提供一种采用上述高速维特比译码方法的接收机。为了实现上述目的,本发明采用下述的技术方案:根据本发明实施例的第一方面,提供一种高速维特比译码方法,基于c66x系列dsp核实现,其中利用c66x系列dsp核的内置函数直接指定每一步操作所使用的汇编指令。其中较优地,所述高速维特比译码方法在c66x系列dsp核的小端模式下运行。其中较优地,所述内置函数包括但不限于_amem8、_dadd、_loll、_hill、_maxu4、_cmpeq4、_packh4、_packl4、_minu4、_packlh2、_sub4。其中较优地,所述高速维特比译码方法进一步包括如下步骤:1)将累积度量数组cum_metrics清零,将已读数据计数器counter清零;2)读入三个连续的输入数据,得到路径度量的增量local_metric_0和local_metric_1在查找表lookup_0和lookup_1中的偏移量;计数器counter加3;3)k为偶数时,八个一组,利用c66x的内置函数_amem8、_dadd、_loll和_hill依次计算累计度量的可能新值update_metrics0[k];4)k为奇数时,八个一组,利用c66x的内置函数_amem8、_dadd、_loll和_hill依次计算累计度量的可能新值update_metrics0[k];5)k为偶数时,八个一组,利用c66x的内置函数_amem8、_dadd、_loll和_hill依次计算累计度量的可能新值update_metrics1[k];6)k为奇数时,八个一组,利用c66x的内置函数_amem8、_dadd、_loll和_hill依次计算累计度量的可能新值update_metrics1[k];7)k为偶数时,四个一组,利用c66x的内置函数_maxu4比较update_metrics0[k]和update_metrics1[k]中的最大值;8)k为奇数时,四个一组,利用c66x的内置函数_maxu4比较update_metrics0[k]和update_metrics1[k]中的最大值;9)k为偶数时,四个一组,利用c66x的内置函数_cmpeq4记录幸存路径;10)k为奇数时,四个一组,利用c66x的内置函数_cmpeq4记录幸存路径;11)k为所有数时,八个一组,利用c66x的内置函数_packh4和_packl4整理累积度量的格式;12)k为所有数时,利用c66x的内置函数_minu4、_packlh2、_packl4和_packh4搜索累积度量的最小值;13)k为所有数时,四个一组,利用c66x的内置函数_sub4从累积度量中减去最小值;14)k为所有数时,四个一组,存储累积度量;15)判断counter是否小于3×(n+6),其中n为卷积码编码之前的数据长度;如果是,转入步骤2),否则,进行步骤16);16)进行最深路径回溯,估计出发射数据;其中,在步骤3)至步骤14)中,k为状态索引;其中,在步骤3)和步骤5)中,“k为偶数时,八个一组”是指将状态索引k按照如下表格分组其中,在步骤4)和步骤6)中,“k为奇数时,八个一组”是指将状态索引k按照如下表格分组:组号状态索引第1组k=1,3,5,7,9,11,13,15第2组k=17,19,21,23,25,27,29,31第3组k=33,35,37,39,41,43,45,47第4组k=49,51,53,55,57,59,61,63其中,在步骤7)和步骤9)中,“k为偶数时,四个一组”是指将状态索引k按照如下表格分组:组号状态索引第1组k=0,2,4,6第2组k=8,10,12,14第3组k=16,18,20,22第4组k=24,26,28,30第5组k=32,34,36,38第6组k=40,42,44,46第7组k=48,50,52,54第8组k=56,58,60,62其中,在步骤8)和步骤10)中,“k为奇数时,四个一组”是指将状态索引k按照如下表格分组:组号状态索引第1组k=1,3,5,7第2组k=9,11,13,15第3组k=17,19,21,23第4组k=25,27,29,31第5组k=33,35,37,39第6组k=41,43,45,47第7组k=49,51,53,55第8组k=57,59,61,63其中,在步骤11)中,“k为所有数时,八个一组”是指将状态索引k按照如下表格分组:组号状态索引第1组k=0,1,2,3,4,5,6,7第2组k=8,9,10,11,12,13,14,15第3组k=16,17,18,19,20,21,22,23第4组k=24,25,26,27,28,29,30,31第5组k=32,33,34,35,36,37,38,39第6组k=40,41,42,43,44,45,46,47第7组k=48,49,50,51,52,53,54,55第8组k=56,57,58,59,60,61,62,63其中,在步骤13)和步骤14)中,“k为所有数时,四个一组”是指将状态索引k按照如下表格分组:组号状态索引组号状态索引第1组k=0,1,2,3第9组k=32,33,34,35第2组k=4,5,6,7第10组k=36,37,38,39第3组k=8,9,10,11第11组k=40,41,42,43第4组k=12,13,14,15第12组k=44,45,46,47第5组k=16,17,18,19第13组k=48,49,50,51第6组k=20,21,22,23第14组k=52,53,54,55第7组k=24,25,26,27第15组k=56,57,58,59第8组k=28,29,30,31第16组k=60,61,62,63。其中较优地,在计算update_metrics0或update_metrics1时,首先利用内置函数_amem8从内存中读取8个状态的local_metric_0[x]或local_metric_1[x],以及8个状态的cum_metrics[y];其中,y表示cum_metrics的元素索引;在计算update_metrics0的情况下,x表示local_metric_0的元素索引;在计算update_metrics1的情况下,x表示local_metric_1的元素索引,x和y的取值见下表;利用内置函数_dadd将cum_metrics与local_metric_0或local_metric_1相加,得到update_metrics0或update_metrics1;最后利用内置函数_loll取出结果的低32位,利用内置函数_hill取出结果的高32位。其中较优地,所述步骤11)中,设索引为偶数的累积度量为even,索引为奇数的累积度量为odd;对odd和even先后使用内置函数_packh4和内置函数_packl4,分别得到结果temp_a和temp_b;对结果temp_a和temp_b先后使用内置函数_packl4和内置函数_packh4,得到连续索引格式的累积度量。其中较优地,所述步骤12)中,设有4个累积度量存放在寄存器min_metric中;对min_metric和min_metric使用内置函数_packlh2,得到结果min_metric2;对min_metric和min_metric2使用内置函数_minu4,得到的结果仍然存放在寄存器min_metric中,将min_metric的值复制到寄存器min_metric2中;对min_metric和min_metric使用内置函数_packl4,得到的结果仍然存放在寄存器min_metric中;对min_metric2和min_metric2使用内置函数_packh4,得到的结果仍然存放在寄存器min_metric2中;对min_metric和min_metric2使用内置函数_minu4,得到最终结果。根据本发明实施例的第二方面,提供一种接收机,包括下变频模块、模数转换模块和数字信号处理模块,其中,所述数字信号处理模块包括c66x系列dsp核,采用上述的高速维特比译码方法进行维特比译码。与现有的dsp维特比译码技术相比较,本发明所提供的高速维特比译码方法一方面利用c66x系列dsp核的内置函数技术直接指定每一步操作所使用的汇编指令;另一方面,充分利用c66x系列dsp核的单指令流多数据流的技术特点,并综合考虑了dsp的资源限制,因而获得了较大的性能提升。附图说明图1为完成初始化之后,本发明所提供的高速维特比译码方法的运行流程图;图2为小端模式下,8个local_metric_0数据在寄存器组中的排列示意图;图3为小端模式下,8个cum_metrics数据在寄存器组中的排列示意图;图4为上述两个寄存器组相加的结果示意图;图5为经过packh4指令之后,temp_a中的数据格式示意图;图6为经过packl4指令之后,temp_b中的数据格式示意图;图7为经过packl4指令之后,cum_metrics0_3中的数据格式示意图;图8为经过packh4指令之后,cum_metrics4_7中的数据格式示意图;图9为min_metric2中的数据格式示意图;图10为min_metric中的数据格式示意图;图11为最终的min_metric中的数据格式示意图;图12为采用上述高速维特比译码方法的接收机模块示意图;图13为本发明所提供的高速维特比译码方法与浮点维特比算法的误码率性能比较示意图。具体实施方式下面结合附图和具体实施例对本发明的技术内容做进一步的详细说明。数字信号由于抗干扰能力强,已经在许多无线通信系统中得到广泛的应用。数字信号处理(digitalsignalprocessing,缩写为dsp)既可以使用普通电脑上的x86系列处理器,也可以使用专门为嵌入式系统设计的dsp处理器(digitalsignalprocessor,缩写同样为dsp)。在本发明中,如果不加说明的话,所说的dsp均指dsp处理器。ti公司(texasinstruments,美国德州仪器)是目前全球最大的dsp处理器生产商。c66x型dsp核是ti公司最新的通用型dsp核,被广泛应用在ti公司的多款dsp产品中,如tms320c6670、tms320c6672、tms320c6674、tms320c6678等。此外,c66x型dsp核还被广泛应用在新一代dsp+arm构架的keystoneii型产品族中,如tci6638k2k、tci6630k2l、66ak2g12、66ak2l06、66ak2h14等。它们采用keystone多内核架构,同时芯片内部集成了rapidio、千兆以太网和edma等外设和大量的硬件加速器,可以广泛应用在通信、雷达、声纳等领域。关于c66x系列dsp的进一步说明,可以参阅ti公司提供的一系列技术文档,例如《tms320c66xdspcpuandinstructionsetreferenceguide》(no.sprugh7,november2010)等。内置函数(intrinsics)是ti公司提供的一种编译机制。它在传统内联函数(inline)的基础上更进一步,在源代码中直接指定了所用的汇编指令。不同的处理器硬件平台有不同的内置函数,因而能够发挥出每一款处理器的最大计算性能,具有很高的效率。内置函数与汇编指令通常是一一对应的。这使得dsp工程师能够精确的控制所生成的二进制程序。使用内置函数之后,编译器只需分配所用的寄存器即可。在本发明的一个实施例中,首先提供了一种经过高度优化的(3,1,7)型卷积码维特比译码方法(简称高速维特比译码方法)。该方法根据dsp的系统架构和指令特点,一方面利用c66x系列dsp核的内置函数(intrinsics)技术直接指定每一步操作所使用的汇编指令,由编译器分配各条汇编指令所用的寄存器;另一方面,充分利用c66x系列dsp核的单指令流多数据流(simd)的技术特点,并综合考虑dsp的资源限制。与现有的维特比译码技术相比较,本高速维特比译码方法获得了较大的性能提升。本高速维特比译码方法特别适合在c66x系列dsp核的小端模式(即数据的高字节保存在内存的高地址中,数据的低字节保存在内存的低地址中)下运行。在c6678开发板上的测试表明,经过高度优化的本高速维特比译码方法的译码速度达到了ti公司官方速度的1.776倍。下面,对本高速维特比译码方法的具体实施步骤展开详细具体的说明。首先,本高速维特比译码方法需要先进行初始化,然后才能开始维特比译码。在执行步骤2)时,需要两个查找表lookup_0和lookup_1。这两个查找表在dsp上电时初始化,并存储在内存中。后面进行维特比译码时从内存中直接读取即可。由于初始化只在上电时进行一次,所以无需对初始化步骤进行优化。如图1所示,本高速维特比译码方法在完成初始化之后的具体流程包括如下步骤:1)将累积度量数组cum_metrics清零,将已读数据计数器counter清零。2)读入三个连续的输入数据。由此得到local_metric_0和local_metric_1在查找表lookup_0和lookup_1中的偏移量。表头加上这个偏移量之后便是当前输入数据所对应的local_metric_0和local_metric_1在查找表中的位置。此时,计数器counter加3。3)八个一组,依次计算状态索引k为偶数时的update_metrics0[k],k=0,2,…,62。具体地说,首先计算状态索引k=0,2,4,6,8,10,12,14;然后计算状态索引k=16,18,20,22,24,26,28,30;接下来计算状态索引k=32,34,36,38,40,42,44,46;最后计算状态索引k=48,50,52,54,56,58,60,62。4)八个一组,依次计算状态索引k为奇数时的update_metrics0[k],k=1,3,…,63,具体地说,首先计算状态索引k=1,3,5,7,9,11,13,15;然后计算状态索引k=17,19,21,23,25,27,29,31;接下来计算状态索引k=33,35,37,39,41,43,45,47;最后计算状态索引k=49,51,53,55,57,59,61,63。5)八个一组,依次计算状态索引k为偶数时的update_metrics1[k],k=0,2,…,62,具体计算过程同步骤3)。6)八个一组,依次计算状态索引k为奇数时的update_metrics1[k],k=1,3,…,63,具体计算过程同步骤4)。7)四个一组,k为偶数时比较update_metrics0[k]和update_metrics1[k]中的最大值,k=0,2,…,62。具体地说,首先对状态索引k=0,2,4,6进行操作;然后对状态索引k=8,10,12,14进行操作;接下来对状态索引k=16,18,20,22进行操作;随后对状态索引k=24,26,28,30进行操作;紧接着对状态索引k=32,34,36,38进行操作;再然后对状态索引k=40,42,44,46进行操作;再接下来对状态索引k=48,50,52,54进行操作;最后对状态索引k=56,58,60,62进行操作。8)四个一组,k为奇数时比较update_metrics0[k]和update_metrics1[k]中的最大值,k=1,3,…,63。具体地说,首先对状态索引k=1,3,5,7进行操作;然后对状态索引k=9,11,13,15进行操作;接下来对状态索引k=17,19,21,23进行操作;随后对状态索引k=25,27,29,31进行操作;紧接着对状态索引k=33,35,37,39进行操作;再然后对状态索引k=41,43,45,47进行操作;再接下来对状态索引k=49,51,53,55进行操作;最后对状态索引k=57,59,61,63进行操作。9)四个一组,记录k为偶数时的幸存路径,k=0,2,…,62,状态索引k的分组情况同步骤7)。10)四个一组,记录k为奇数时的幸存路径,k=1,3,…,63,状态索引k的分组情况同步骤8)。11)八个一组,k为所有数时整理累积度量的格式,k=0,1,2,3,…,63,将其变成正常的连续索引格式。具体地说,首先对状态索引k=0,1,2,3,4,5,6,7进行操作;然后对状态索引k=8,9,10,11,12,13,14,15进行操作;接下来对状态索引k=16,17,18,19,20,21,22,23进行操作;随后对状态索引k=24,25,26,27,28,29,30,31进行操作;紧接着对状态索引k=32,33,34,35,36,37,38,39进行操作;再然后对状态索引k=40,41,42,43,44,45,46,47进行操作;再接下来对状态索引k=48,49,50,51,52,53,54,55进行操作;最后对状态索引k=56,57,58,59,60,61,62,63进行操作。12)搜索k为所有数时累积度量的最小值。具体搜索过程详见后文中的进一步说明。13)四个一组,k为所有数时从累积度量中减去最小值,k=0,1,2,3,…,63。具体地说,首先对状态索引k=0,1,2,3进行操作;然后对状态索引k=4,5,6,7进行操作;接下来对状态索引k=8,9,10,11进行操作;随后对状态索引k=12,13,14,15进行操作;紧接着对状态索引k=16,17,18,19进行操作;再然后对状态索引k=20,21,22,23进行操作;再接下来对状态索引k=24,25,26,27进行操作;然后对状态索引k=28,29,30,31进行操作;接下来对状态索引k=32,33,34,35进行操作;随后对状态索引k=36,37,38,39进行操作;紧接着对状态索引k=40,41,42,43进行操作;再然后对状态索引k=44,45,46,47进行操作;再接下来对状态索引k=48,49,50,51进行操作;随后对状态索引k=52,53,54,55进行操作;紧接着对状态索引k=56,57,58,59进行操作;最后对状态索引k=60,61,62,63进行操作。14)四个一组,k为所有数时存储累积度量。状态索引k的分组情况同步骤13)。15)判断是否已读入所有输入数据。假设在卷积码编码之前有n个数据。那么在经过(3,1,7)型卷积码编码之后变成了3×(n+6)个数据。如果计数器counter的值小于3×(n+6),则说明还有未读入的输入数据,转入步骤2)。否则,则往下进行步骤16)。16)进行最深路径回溯,估计出发射数据。在本高速维特比译码方法中,由于路径回溯的计算量不大,步骤16)可以采用传统的c语言来实现。下面,对本高速维特比译码方法在实施过程中的一些技术细节进行进一步说明:1.似然比的量化接收信号的似然比(llr)是维特比译码器的输入数据。与通常的维特比译码器一样,本发明的一个实施例中采用4比特量化。2.查找表的建立更新累积度量是维特比译码的关键步骤之一,其核心操作如下:local_metric_0[k]=prev_state_0[k][0]*llr[i*3]+prev_state_0[k][1]*llr[i*3+1]+prev_state_0[k][2]*llr[i*3+2];update_metrics0[k]=cum_metrics[k/2]+local_metric_0[k];local_metric_1[k]=prev_state_1[k][0]*llr[i*3]+prev_state_1[k][1]*llr[i*3+1]+prev_state_1[k][2]*llr[i*3+2];update_metrics1[k]=cum_metrics[k/2+32]+local_metric_1[k];其中,local_metric_0、local_metric_1是根据当前的输入数据计算出来的累积度量的增量;prev_state_0、prev_state_1是两组常数,其值为-1或1,可以通过(3,1,7)型卷积码的生成多项式预先计算出;k是一个索引,其值为0到63的正整数,代表了(3,1,7)型卷积码的64种译码状态;llr是似然比,即维特比译码器的输入数据;i是输入数据的索引;update_metrics0、update_metrics1是累积度量更新后的两种可能取值;cum_metrics是上次的累积度量。对于输入数据llr[i*3]、llr[i*3+1]、llr[i*3+2],将local_metric_0和local_metric_1的值事先计算好并存放在一张查找表上。进行维特比译码的时候,首先读入llr[i*3]、llr[i*3+1]和llr[i*3+2],然后据此在查找表中将local_metric_0和local_metric_1的值直接读取出来,这样就省掉了计算local_metric_0和local_metric_1的过程。(3,1,7)型卷积码有64种译码状态,所以一组输入数据llr[i*3]、llr[i*3+1]、llr[i*3+2]对应了64个local_metric_0和local_metric_1。在更新累积度量时,每次需要读取3个连续的似然比。每个似然比都是4比特量化,即有16种可能的取值。(3,1,7)型卷积码一共有64种译码状态。所以,每个查找表的大小为64×16×16×16。维特比译码算法实质上是卷积码的最大似然(ml)译码算法。查找表中存储了当前比特位上发射机发射0或发射1的概率,所以译码器需要建立两个查找表,分别对应发送信号是0和1的两种情况。设local_metric_0对应的查找表叫lookup_0,local_metric_1对应的查找表叫lookup_1。这两个查找表在dsp上电时初始化,并存储在内存中。后面进行维特比译码时从内存中直接读取即可。在本发明中,local_metric_0、local_metric_1均用8比特表示,即1个字节。c66x系列dsp的汇编指令lddw一次可以从内存读取8个字节。为了降低读取查找表的开销,本发明的实施例中将一组输入数据llr[i*3]、llr[i*3+1]、llr[i*3+2]对应的64个local_metric_0的值在内存中连续放置,这样就可以一次读取8个状态的local_metric_0。为了能够连续读取local_metric_0的值,需要按照如下规则调整查找表的存储顺序:如果k为奇数,那么local_metric_0[k]的值位于查找表的第(k-1)/2+32个位置;如果k为偶数,那么local_metric_0[k]的值位于查找表的第k/2个位置;其中,k为状态数。local_metric_1采用同样的方法处理。在dsp中,需要手工指定各个变量的存储位置。为了加快读取查找表的速度,需要将查找表放置于dsp核上自带的缓存中。考虑到两个查找表的长度比较大,本发明的实施例中将这两个查找表放置于dsp的4mb多核共享缓存中。3.基于非负数的计算c66x系列dsp核的许多simd汇编指令都只支持非负数,如计算最大值的汇编指令maxu4和计算最小值的汇编指令minu4。为了避免在计算过程中进行数据类型转化,本发明的实施例中一律使用无符号整数。但是,原始的维特比算法是按照有符号数设计的,这就需要对原始的维特比算法进行修改。在本发明的实施例中,local_metric_0和local_metric_1的表达式中,输入数据llr采用4比特量化,其值为[-8,7]。prev_state_0和prev_state_1的值是-1或1。所以local_metric_0和local_metric_1的取值范围是[-24,21]。为了将其变为非负数,可以加上一个偏置24,即local_metric_0[k]=prev_state_0[k][0]*llr[i*3]+prev_state_0[k][1]*llr[i*3+1]+prev_state_0[k][2]*llr[i*3+2]+24;local_metric_1[k]=prev_state_1[k][0]*llr[i*3]+prev_state_1[k][1]*llr[i*3+1]+prev_state_1[k][2]*llr[i*3+2]+24;为了统一起见,本发明的实施例中将输入数据llr也变为非负数。设修改后的输入数据用llr’表示,则llr’[i]=llr[i]+8因此,当使用非负数进行计算时,local_metric_0和local_metric_1的表达式如下:local_metric_0[k]=24+prev_state_0[k][0]*llr’[i*3]+prev_state_0[k][1]*llr’[i*3+1]+prev_state_0[k][2]*llr’[i*3+2]-8*(prev_state_0[k][0]+prev_state_0[k][1]+prev_state_0[k][2]);local_metric_1[k]=24+prev_state_1[k][0]*llr’[i*3]+prev_state_1[k][1]*llr’[i*3+1]+prev_state_1[k][2]*llr’[i*3+2]-8*(prev_state_1[k][0]+prev_state_1[k][1]+prev_state_1[k][2])。4.计算update_metrics建立查找表之后,就可以正式开始维特比译码。维特比译码的典型步骤可以总结为“加、比、选”。其中第一步是计算累积度量的两组可能新值update_metrics0和update_metrics1。在本发明的实施例中,cum_metrics、update_metrics0、update_metrics1均用8比特表示。c66x系列dsp核为32位dsp,每个寄存器均有32位,所以一个寄存器可以表示4个状态,实现4个状态的并行计算。具体地说,计算update_metrics0时,首先利用内置函数_amem8(对应于汇编指令lddw)从内存中分别读取8个状态的local_metric_0和cum_metrics,然后利用内置函数_dadd(对应于汇编指令dadd)将其相加,从而得到8个状态的update_metrics0。例如:对于update_metrics0[0]、update_metrics0[2]、update_metrics0[4]、update_metrics0[6]、update_metrics0[8]、update_metrics0[10]、update_metrics0[12]、update_metrics0[14],示例代码如下:uint64_tupdate0=_dadd(_amem8(&m0_ptr[x]),_amem8(&cum_metrics[y]));uint32_tupdate0_even0_6=_loll(update0);uint32_tupdate0_even8_14=_hill(update0);_amem8是ti公司提供的一个内置函数,其作用是告诉编译器使用汇编指令lddw。这条汇编指令一次从内存中读取8个字节的数据到一个寄存器组。内存地址必须是对齐的,即能够被8整除。寄存器组必须是两个连续的32位寄存器,而且必须是偶数寄存器编号小,奇数寄存器编号大,如a0和a1、b2和b3。m0_ptr是一个指向查找表lookup_0的指针,指向的是当前输入数据所对应的local_metric_0。x和y是两个与状态索引k相关的整数。在这里,x=0,y=0。根据上文中对local_metric_0存储顺序的讨论,_amem8(&m0_ptr[0])会读取如下数据到寄存器组:local_metric_0[0]、local_metric_0[2]、local_metric_0[4]、local_metric_0[6]、local_metric_0[8]、local_metric_0[10]、local_metric_0[12]、local_metric_0[14]。在小端模式下,这8个数据在寄存器组中的排列如图2所示,其中local_0是local_metric_0的简写。_amem8(&cum_metrics[0])读取cum_metrics[0]、cum_metrics[1]、cum_metrics[2]、cum_metrics[3]、cum_metrics[4]、cum_metrics[5]、cum_metrics[6]、cum_metrics[7]到寄存器组。在小端模式下,这8个数据在寄存器组中的排列如图3所示,其中cum是cum_metrics的简写。内置函数_dadd告诉编译器使用汇编指令dadd将两个寄存器组相加,每个寄存器组为64位。相加之后,得到的结果如图4所示,其中update_0是update_metrics0的简写。内置函数_dadd的结果是64位的。在c66x系列dsp核中,这个结果放在两个寄存器中。为了后续使用的方便,用内置函数_loll取出结果的低32位,命名为update0_even0_6;用内置函数_hill取出结果的高32位,命名为update0_even8_14。对于k为其它值的update_metrics0[k]以及update_metrics1[k],可以用类似的方法计算。x和y的取值见表1。表1计算update_metrics所需的x和y的值update_metrics状态索引kxyupdate_metrics00,2,4,6,8,10,12,1400update_metrics016,18,20,22,24,26,28,3012update_metrics032,34,36,38,40,42,44,4624update_metrics048,50,52,54,56,58,60,6236update_metrics01,3,5,7,9,11,13,1540update_metrics017,19,21,23,25,27,29,3152update_metrics033,35,37,39,41,43,45,4764update_metrics049,51,53,55,57,59,61,6376update_metrics10,2,4,6,8,10,12,1408update_metrics116,18,20,22,24,26,28,30110update_metrics132,34,36,38,40,42,44,46212update_metrics148,50,52,54,56,58,60,62314update_metrics11,3,5,7,9,11,13,1548update_metrics117,19,21,23,25,27,29,31510update_metrics133,35,37,39,41,43,45,47612update_metrics149,51,53,55,57,59,61,637145.比较update_metrics接下来,比较update_metrics0[k]和update_metrics1[k]中的最大值,并以此作为累积度量更新后的值。在比较的时候,可以利用内置函数_maxu4(对应于汇编指令maxu4)对4个状态的update_metrics0[k]和update_metrics1[k]进行比较。例如,当k=0,2,4,6时,示例代码如下:uint32_teven0_6=_maxu4(update0_even0_6,update1_even0_6);其中,update0_even0_6是前面求得的update_metrics0[k],k=0,2,4,6。update1_even0_6是前面求得的update_metrics1[k],k=0,2,4,6。内置函数_maxu4使用汇编指令maxu4。这条指令将32位寄存器当成是4个8比特的数据,并按照这个格式对4个数据分别求最大值[5]。even0_6是更新后的累积度量值,k=0,2,4,6。对于其它的累积度量,可以用类似的方法求得。在路径回溯时,需要知道是update_metrics0[k]还是update_metrics1[k]被选择为幸存路径。此时,可以利用内置函数_cmpeq4(对应于汇编指令cmpeq4)来比较update_metrics1[k]和max(update_metrics0[k],update_metrics1[k])是否相等。如果max(update_metrics0[k],update_metrics1[k])与update_metrics1[k]相等,则说明update_metrics1[k]比update_metrics0[k]大,否则update_metrics1[k]比update_metrics0[k]小。例如,当k=0,2,4,6时,示例代码如下:paths_ptr[0]=_cmpeq4(even0_6,update1_even0_6);其中,paths_ptr是一个指针,指向保存路径信息的数组地址。内置函数_cmpeq4使用汇编指令cmpeq4。这条指令将32位寄存器当成是4个8比特的数据,并按照这个格式对4个数据分别比较是否相等。对于其它的累积度量,可以用类似的方法求得。6.整理累积度量的格式在前面求得的累积度量中,索引为偶数的连续存放在一起,如k=0,2,4,6。索引为奇数的连续存放在一起,如k=1,3,5,7。这里将其变成正常的连续索引格式,如k=0,1,2,3,4,5,6,7。设索引为偶数的累积度量为even,索引为奇数的累积度量为odd。在整理格式的时候,对odd和even使用内置函数_packh4(对应于汇编指令packh4)和内置函数_packl4(对应于汇编指令packl4),分别得到结果temp_a和temp_b。然后,对temp_a和temp_b使用内置函数_packl4(对应于汇编指令packl4)和内置函数_packh4(对应于汇编指令packh4),得到连续索引格式的累积度量。例如,当状态索引k=0,1,2,3,4,5,6,7时,示例代码如下:uint32_ttemp_a=_packh4(odd1_7,even0_6);uint32_ttemp_b=_packl4(odd1_7,even0_6);uint32_tcum_metrics0_3=_packl4(temp_a,temp_b);uint32_tcum_metrics4_7=_packh4(temp_a,temp_b);内置函数_packh4使用汇编指令packh4,内置函数_packl4使用汇编指令packl4。这是两条专门用于整理格式的汇编指令。经过packh4指令之后,temp_a中的数据格式如图5所示。经过packl4指令之后,temp_b中的数据格式如图6所示。经过packl4指令之后,cum_metrics0_3中的数据格式如图7所示。经过packh4指令之后,cum_metrics4_7中的数据格式如图8所示。对于其它的累积度量,可以用类似的方法求得。7.防止溢出在本发明的实施例中,cum_metrics用8比特表示。为了避免累加之后超过8比特的表示范围,需要在每次更新完cum_metrics之后将其公共部分减掉。这是因为维特比译码只关注两个度量大小的比较。具体做法如下:求得64个cum_metrics中的最小值,然后给所有cum_metrics都减去最小值。调整之后,cum_metrics数组中的最小值变成了0。下面,首先寻找累积度量的最小值。由于每个寄存器中存放4个累积度量值,可以利用内置函数_minu4(对应于汇编指令minu4)对数组cum_metrics反复操作,从而将最小值的搜寻范围缩小到4个累积度量,并全部存放在一个寄存器min_metric中。例如,当状态索引k=0,1,2,3,4,5,6,7时,示例代码如下:uint32_tmin_metric=_minu4(cum_metrics0_3,cum_metrics4_7);内置函数_minu4使用汇编指令minu4。这条指令将32位寄存器当成是4个8比特的数据,并按照这个格式对4个数据分别求最小值。类似地,对其余存有累积度量的寄存器反复操作。接下来,将最小值的搜寻范围缩小到2个累积度量。在搜索的时候,对min_metric和min_metric使用内置函数_packlh2(对应于汇编指令packlh2),得到结果min_metric2。然后对min_metric和min_metric2使用内置函数_minu4(对应于汇编指令minu4),得到的结果仍然存放在寄存器min_metric中。示例代码如下:min_metric2=_packlh2(min_metric,min_metric);min_metric=_minu4(min_metric,min_metric2);内置函数_packlh2使用汇编指令packlh2,这是一条专门用于格式整理的汇编指令。min_metric2中的数据格式如图9所示,其中min0,min1,min2,min3分别是min_metric中存放的4个待搜索的累积度量值。minu4指令之后,min_metric中的数据格式如图10所示,其中min_a=min(min1,min3),min_b=min(min0,min2)。接下来,求累积度量的最小值。将min_metric的值复制到寄存器min_metric2。对min_metric和min_metric使用内置函数_packl4(对应于汇编指令packl4),得到的结果仍然存放在寄存器min_metric。对min_metric2和min_metric2使用内置函数_packh4(对应于汇编指令packh4),得到的结果仍然存放在寄存器min_metric2。对min_metric和min_metric2使用内置函数_minu4(对应于汇编指令minu4),得到累积度量的最小值。示例代码如下:min_metric2=min_metric;min_metric=_packl4(min_metric,min_metric);min_metric2=_packh4(min_metric2,min_metric2);min_metric=_minu4(min_metric,min_metric2);最终,min_metric中的数据格式如图11所示,其中minimum=min(min_a,min_b)。求得最小值之后就是调整累积度量了。这可以通过内置函数_sub4(对应于汇编指令sub4)将cum_metrics与minimum相减完成。例如,当k=0,1,2,3时,示例代码如下:cum_metrics[0]=_sub4(cum_metrics0_3,min_metric);内置函数_sub4使用汇编指令sub4。这条汇编指令将32位寄存器当成是4个8比特的数据,并按照这个格式对4个数据分别相减。对于其它的累积度量,可以用类似的方法求得。在此基础上,本发明进一步提供一种新型的接收机。在图12所示的一个实施例中,该接收机包括下变频模块、模数转换模块和数字信号处理模块。其中,无线信号通过天线输入下变频模块。在下变频模块进行处理后,由模数转换模块完成相应的模数转换操作,然后输入数字信号处理模块进行后续处理。数字信号处理模块包括c66x系列dsp核,用于完成信道估计运算、信道均衡运算以及维特比译码,其中在进行维特比译码时采用上述的高速维特比译码方法。为了验证本发明所提供的高速维特比译码方法的实际效果,发明人在c6678开发板上进行了测试。测试环境如表2所示。表2测试中各项参数的取值软件环境codecomposerstudioversion5.5.0.00077硬件环境tmdsevm6678le开发板卷积码生成多项式0133,0171,0165(八进制)码率1/3量化中的乘法系数3.5信道实数awgn信道编码前数据长度198首先测试的是误码率性能。本高速维特比译码方法对接收信号进行了4比特量化。此外,在累积度量更新的过程中,有可能会因为超出8比特的表示范围而产生溢出。这些因素都可能会造成误码率性能的下降。在图13中,将本高速维特比译码方法与最优的浮点维特比算法进行了比较。所谓浮点维特比算法,是指输入数据为双精度浮点数(double),而且在整个译码过程中都使用双精度浮点计算。从图13中可以看到,本高速维特比译码方法的误码率性能损失非常小。接下来,测量维特比译码器的运行速度,具体结果见表3。作为比较,这里还给出了ti公司的技术文档《viterbidecodingtechniquesforthetms320c55xdspgeneration》(no.spra776a,april2009)中算法的运行速度。可以看到,本高速维特比译码方法的运行速度是ti公司官方速度的1.776倍。表3维特比译码器的运行速度以上对本发明所提供的高速维特比译码方法及其接收机进行了详细的说明。对本领域的一般技术人员而言,在不背离本发明实质精神的前提下对它所做的任何显而易见的改动,都将属于本发明专利权的保护范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1