用于渲染声学信号的方法和装置及计算机可读记录介质与流程
本发明涉及用于渲染信号的方法和设备,更具体地,涉及当输入声道的高度高于或低于根据标准布局的高度时,通过修改高度平移系数或高度滤波器系数来进一步精确表示声像的位置和音色的渲染方法和设备。
背景技术:
3D音频是指通过不仅再现音高和音色还再现方向或距离而使收听者具有沉浸感的并且向其添加空间信息的音频,其中空间信息使没有位于发生音频源的空间中的收听者具有方向感知、距离感知和空间感知。
当例如22.2声道信号的声道信号被渲染到5.1声道信号时,可以通过使用二维(2D)输出声道来再现三维(3D)音频,然而,当输入声道的高角度不同于标准高角度时,如果通过使用根据标准高角度确定的渲染参数来渲染输入信号,则在声像中可能发生失真。
技术实现要素:
技术问题
如上所述,当例如22.2声道信号的多声道信号被渲染到5.1声道信号时,可以通过使用二维(2D)输出声道来再现三维(3D)环绕声音,然而,当输入声道的高角度不同于标准高角度时,如果通过使用根据标准高角度确定的渲染参数来渲染输入信号,则在声像中可能发生失真。
为了解决根据现有技术的上述问题,提供本发明以使得即使输入声道的高度(elevation)高于或低于标准高度也会减少声像的失真。
技术方案
为了实现该目的,本发明包括以下实施方式。
根据本发明的实施方式,提供了渲染音频信号的方法,该方法包括:接收多声道信号,其中所述多声道信号包括要转换成多个输出声道的多个输入声道;对前高处(frontal height)输入声道添加预定延迟,以允许多个输出声道以参考高角度提供升高的声像;基于所添加的延迟,修改对于前高处输入声道的高度渲染参数;以及通过基于经修改的高度渲染参数生成相对于前高处输入声道延迟的、经高度渲染的环绕输出声道来防止前后混淆(front-back confusion)。
多个输出声道可以是水平声道。
高度渲染参数可包括平移增益和高度滤波器系数中的至少一个。
前高处输入声道可包括CH_U_L030、CH_U_R030、CH_U_L045、CH_U_R045和CH_U_000声道中的至少一个。
环绕输出声道可包括CH_M_L110和CH_M_R110声道中的至少一个。
可以基于采样率来确定预定延迟。
根据本发明的另一实施方式,提供了用于渲染音频信号的设备,该设备包括接收单元、渲染单元和输出单元,其中,接收单元配置为接收包括要转换成多个输出声道的多个输入声道的多声道信号;渲染单元配置为对前高处输入声道添加预定延迟以允许多个输出声道以参考高角度提供升高的声像,并且基于所添加的延迟修改对于前高处输入声道的高度渲染参数;输出单元配置为通过基于经修改的高度渲染参数生成相对于前高处输入声道延迟的、经高度渲染的环绕输出声道来防止前后混淆。
多个输出声道可以是水平声道。
高度渲染参数可包括平移增益和高度滤波器系数中的至少一个。
前高处输入声道可包括CH_U_L030、CH_U_R030、CH_U_L045、CH_U_R045和CH_U_000声道中的至少一个。
前高处声道可包括CH_U_L030、CH_U_R030、CH_U_L045、CH_U_R045和CH_U_000声道中的至少一个。
可以基于采样率来确定预定延迟。
根据本发明的另一实施方式,提供了渲染音频信号的方法,该方法包括:接收包括要转换成多个输出声道的多个输入声道的多声道信号;获得对于高处输入声道的高度渲染参数,以允许多个输出声道以参考高角度提供升高的声像;以及更新对于具有预定高角度而不是参考高角度的高处输入声道的高度渲染参数,其中更新高度渲染参数包括更新用于将处于顶部前中央(top front center)处的高处输入声道平移到环绕输出声道的高度平移增益。
多个输出声道可以是水平声道(horizontal channel)。
高度渲染参数可包括高度平移增益和高度滤波器系数中的至少一个。
更新高度渲染参数可包括:基于参考高角度和预定高角度来更新高度平移增益。
当预定高角度小于参考高角度时,将应用于具有预定高角度的输出声道的同侧输出声道的经更新的高度平移增益之中的、经更新的高度平移增益可以大于更新前的高度平移增益,以及分别应用于多个输入声道的更新的高度平移增益的平方的总和可以是1。
当预定高角度大于参考高角度时,将应用于具有预定高角度的输出声道的同侧输出声道的经更新的高度平移增益之中的、经更新的高度平移增益可以小于更新前的高度平移增益,以及分别应用于多个输入声道的更新的高度平移增益的平方的总和可以是1。
根据本发明的另一实施方式,提供了用于渲染音频信号的设备,该设备包括接收单元和渲染单元,其中,接收单元配置为接收包括要转换成多个输出声道的多个输入声道的多声道信号;渲染单元配置为获得对于高处输入声道的高度渲染参数以允许多个输出声道以参考高角度提供升高的声像,并且更新对于具有预定高角度而不是参考高角度的高处输入声道的高度渲染参数,其中更新的高度渲染参数包括用于将处于顶部前中央处的高处输入声道平移到环绕输出声道的高度平移增益。
多个输出声道可以是水平声道。
高度渲染参数可包括高度平移增益和高度滤波器系数中的至少一个。
更新的高度渲染参数可包括基于参考高角度和预定高角度更新的高度平移增益。
当预定高角度小于参考高角度时,将应用于具有预定高角度的输出声道的同侧输出声道的经更新的高度平移增益之中的、经更新的高度平移增益可以大于更新前的高度平移增益,以及分别应用于多个输入声道的经更新的高度平移增益的平方的总和可以是1。
当预定高角度大于参考高角度时,将应用于具有预定高角度的输出声道的同侧输出声道的经更新的高度平移增益之中的、经更新的高度平移增益可以小于未更新的高度平移增益,以及分别应用于多个输入声道的经更新的高度平移增益的平方的总和可以是1。
根据本发明的另一实施方式,提供了渲染音频信号的方法,该方法包括:接收包括要转换成多个输出声道的多个输入声道的多声道信号;获得对于高处输入声道的高度渲染参数,以允许多个输出声道以参考高角度提供升高的声像;以及更新对于具有预定高角度而不是参考高角度的高处输入声道的高度渲染参数,其中更新高度渲染参数包括基于高处输入声道的位置获得相对于包括低频带的频率范围更新的高度平移增益。
经更新的高度平移增益可以是相对于后高处输入声道的平移增益。
多个输出声道可以是水平声道。
高度渲染参数可包括高度平移增益和高度滤波器系数中的至少一个。
更新高度渲染参数可包括基于参考高角度和预定高角度对高度滤波器系数应用权重。
当预定高角度小于参考高角度时,可将权重确定为使得可以平滑地展现高度滤波器特性;而当预定高角度大于参考高角度时,可将权重确定为使得可以尖锐地展现高度滤波器特性。
更新高度渲染参数可包括:基于参考高角度和预定高角度来更新高程平移增益。
当预定高角度小于参考高角度时,将应用于具有预定高角度的输出声道的同侧输出声道的经更新的高度平移增益之中的、经更新的高度平移增益可以大于更新前的高度平移增益,以及分别应用于多个输入声道的经更新的高度平移增益的平方的总和可以是1。
当预定高角度大于参考高角度时,将应用于具有预定高角度的输出声道的同侧输出声道的经更新的高度平移增益之中的、经更新的高度平移增益可以小于更新前的高度平移增益,以及分别应用于多个输入声道的经更新的高度平移增益的平方的总和可以是1。
根据本发明的另一实施方式,提供了用于渲染音频信号的设备,该设备包括接收单元和渲染单元,其中,接收单元配置为接收包括要转换成多个输出声道的多个输入声道的多声道信号;渲染单元配置为获得对于高处输入声道的高度渲染参数以允许多个输出声道以参考高角度提供升高的声像,并且更新对于具有预定高角度而不是参考高角度的高处输入声道的高度渲染参数,其中经更新的高度渲染参数包括基于高处输入声道的位置获得相对于包括低频带的频率范围更新的高度平移增益。
更新的高度平移增益可以是相对于后高处输入声道的平移增益。
多个输出声道可以是水平声道。
高度渲染参数可包括高度平移增益和高度滤波器系数中的至少一个。
更新的高度渲染参数可包括基于参考高角度和预定高角度对其应用权重的高度滤波器系数。
当预定高角度小于参考高角度时,可将权重确定为使得可以平滑地展现高度滤波器特性;而当预定高角度大于参考高角度时,可将权重确定为使得可以尖锐地展现高度滤波器特性。
更新的高度渲染参数可包括基于参考高角度和预定高角度更新的高度平移增益。
当预定高角度小于参考高角度时,将应用于具有预定高角度的输出声道的同侧输出声道的经更新的高度平移增益之中的、经更新的高度平移增益可以大于更新前的高度平移增益,以及分别应用于多个输入声道的经更新的高度平移增益的平方的总和可以是1。
当预定高角度大于参考高角度时,将应用于具有预定高角度的输出声道的同侧输出声道的多个更新的高度平移增益之中的、经更新的高度平移增益可以小于更新前的高度平移增益,以及分别应用于多个输入声道的经更新的高度平移增益的平方的总和可以是1。
根据本发明的另一实施方式,提供了用于执行上述方法的程序以及其上记录有所述程序的计算机可读记录介质。
另外,提供了另一方法、另一系统以及其上记录有用于执行该方法的计算机程序的计算机可读记录介质。
技术效果
根据本发明,可以以即使输入声道的高度高于或低于标准高度也会减小声像的失真的方式来渲染3D音频信号。另外,根据本发明,可以防止由于环绕输出声道引起的前后混淆现象。
附图说明
图1是示出根据实施方式的3D音频再现设备的内部结构的框图。
图2是示出根据实施方式的3D音频再现设备中的渲染器的配置的框图。
图3示出根据实施方式当多个输入声道缩混到多个输出声道时的声道的布局。
图4示出根据实施方式输出声道的标准布局和布置布局之间发生位置偏差的示例中的平移单元。
图5是示出根据实施方式的3D音频再现设备中的解码器和3D音频渲染器的配置的框图。
图6至图8示出根据实施方式根据声道布局中上层的高度的上层声道布局。
图9至图11示出根据实施方式根据声道高度的声像变化和高度滤波器变化。
图12是根据实施方式渲染3D音频信号的方法的流程图。
图13示出根据实施方式当输入声道的高角度等于或大于阈值时左右声像反转的现象。
图14示出根据实施方式的水平声道和前高处声道。
图15示出根据实施方式的前高处声道的感知百分比。
图16是根据实施方式的防止前后混淆的方法的流程图。
图17示出根据实施方式当向环绕输出声道添加延迟时的水平声道和前高处声道。
图18示出根据实施方式的水平声道和顶部前中央(TFC)声道。
具体实施方式
为了实现该目的,本发明包括以下实施方式。
根据实施方式,提供了渲染音频信号的方法,该方法包括:接收包括要转换到多个输出声道的多个输入声道的多声道信号;对前高处输入声道添加预定延迟,以允许多个输出声道以参考高角度提供升高的声像;基于所添加的延迟,修改对于前高处输入声道的高度渲染参数;以及通过基于经修改的高度渲染参数生成相对于前高处输入声道延迟的、经高度渲染的环绕输出声道,来防止前后混淆。
本发明的实施方式
本发明的详细描述参考示出本发明具体实施方式的附图。提供这些实施方式以使得本公开将是彻底和完整的,并且将向本领域普通技术人员充分地传达本发明的构思。应当理解,本发明各实施方式彼此不同,并且不相互排斥。
例如,在不脱离本发明的精神和范围的情况下,从一实施方式到另一实施方式,说明书中描述的具体形状、具体结构和具体特征可以发生改变。此外,应当理解,在不脱离本发明的精神和范围的情况下,可以改变每个实施方式中的每个元件的位置或布局。因此,详细描述应当仅以描述性意义考虑,而不是出于限制的目的,而且本发明的范围不是由本发明的详细描述而是由所附权利要求限定,所述范围内的所有差异将被解释为包括在本发明中。
在说明书通篇中,附图中相同的附图标记表示相同或相似的元件。在下面的描述和附图中,不详细描述公知的功能或结构,因为它们将以不必要的细节混淆本发明。此外,在说明书通篇中,附图中相同的附图标记表示相同或相似的元件。
在下文中,将通过参考附图解释本发明的示例性实施方式来详细描述本发明。然而,本发明可以以许多不同的形式实施,并且不应被解释为限于本文所阐述的实施方式;相反,提供这些实施方式使得本公开将是彻底和完整的,并且将向本领域的普通技术人员充分地传达本发明的构思。
在说明书通篇中,当元件被称为“连接到”或“联接”另一元件时,它可以“直接连接到或联接”所述另一元件,或者它可以通过具有介于其间的中间元件“电连接到或联接”所述另一元件。此外,当部件“包括”或“包含”元件时,除非存在与其相反的特定描述,否则该部件还可包括其它元件,而不排除其它元件。
在下文中,将参考附图描述本发明的示例性实施方式。
图1是示出根据实施方式的3D音频再现设备的内部结构的框图。
根据实施方式的3D音频再现设备100可以输出多声道音频信号,在多声道音频信号中向用于再现的多个输出声道混合多个输入声道。这里,如果输出声道的数量少于输入声道的数量,则输入声道被缩混(downmixing)以与输出声道的数量对应。
3D音频是指通过不仅再现音高和音色还再现方向或距离而使收听者具有沉浸感的并且向其添加空间信息的音频,其中空间信息使没有位于发生音频源的空间中的收听者具有方向感知、距离感知和空间感知。
在下面的描述中,音频信号的输出声道可以指通过其输出音频的扬声器的数量。输出声道数量越多,通过其输出音频的扬声器的数量越多。根据实施方式的3D音频再现设备100可以将多声道(multi-channel)音频信号渲染并混合到用于再现的输出声道,使得具有大量输入声道的多声道音频信号可以在其中输出声道数量少的环境中输出和再现。在这点上,多声道音频信号可包括能够输出升高的声音(elevated sound)的声道。
能够输出升高的声音的声道可以指示能够经由位于收听者的头部上方的扬声器输出音频信号的声道,以使得收听者感觉升高。水平声道可以指示能够经由相对于收听者位于水平面上的扬声器输出音频信号的声道。
上述输出声道数量少的环境可以指示不包括能够输出升高的声音的输出声道并且可以经由布置在水平面上的扬声器输出音频的环境。
此外,在下面的描述中,水平声道可以指示包括要经由位于水平面上的扬声器输出的音频信号的声道。头顶声道(overhead channel)可以指示包括要经由没有位于水平面上而是位于升高的平面上以输出升高的声音的扬声器输出的音频信号的声道。
参考图1,根据实施方式的3D音频再现设备100可包括音频内核110、渲染器120、混合器130和后处理单元140。
根据实施方式,3D音频再现设备100可以输出可以将多声道输入音频信号渲染、混合并输出到用于再现的输出声道。例如,多声道输入音频信号可以是22.2声道信号,并且用于再现的输出声道可以是5.1或7.1声道。3D音频再现设备100可以通过设置这样的输出声道来执行渲染,其中所述声道将分别映射到多声道输入音频信号的声道;而且3D音频再现设备100可以通过混合这样的声道的信号来混合经渲染的音频信号,其中所述声道分别映射到用于再现并输出最终信号的声道。
以比特流的形式向音频内核110输入经编码的音频信号,以及音频内核110选择适合于经编码的音频信号的格式的解码器并对所输入的音频信号解码。
渲染器120可以根据声道和频率将多声道输入音频信号渲染到多声道输出声道。渲染器120可以根据头顶声道和水平声道对每个信号执行三维(3D)渲染和二维(2D)渲染。将参考图2详细描述渲染器的配置和渲染方法。
混合器130可以通过渲染器120混合分别映射到水平声道的声道的信号,并且可以输出最终信号。混合器130可以根据每个预定周期混合声道的信号。例如,混合器130可以根据一个帧混合每个声道的信号。
根据实施方式的混合器130可以基于分别渲染到用于再现的声道的信号的功率值来执行混合。换句话说,混合器130可以基于分别渲染到用于再现的声道的信号的功率值来确定最终信号的振幅或要应用于最终信号的增益。
后处理单元140根据每个再现设备(扬声器、耳机等)相对于多频带信号执行动态范围控制并对来自混合器130的输出信号进行双耳化(binauralizing)。从后处理单元140输出的输出音频信号可以经由例如扬声器的设备输出,并且可以在每个配置元件的处理之后以2D或3D方式再现。
针对其音频解码器的配置示出根据图1所示的实施方式的3D音频再现设备100,并且跳过另外的配置。
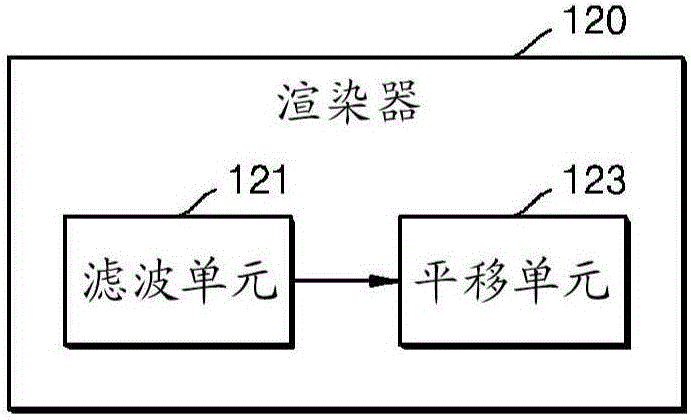
图2是示出根据实施方式的3D音频再现设备中的渲染器的配置的框图。
渲染器120包括滤波单元121和平移单元123。
滤波单元121可以根据位置来补偿解码的音频信号的音色等,并且可以通过使用头部相关变换函数(HRTF,Head-Related Transfer Function)滤波器来对输入的音频信号进行滤波。
为了在头顶声道上执行3D渲染,滤波单元121可以通过根据频率使用不同的方法渲染已经通过HRTF滤波器的头顶声道。
HRTF滤波器根据这样的现象使3D音频可识别,在该现象中,不仅例如两耳之间的耳间水平差(ILD,Interaural Level Differences)、相对于音频到达时间的两耳之间的耳间时间差(ITD,Interaural Time Differences)等简单的路径差,而且例如头部表面处的衍射、由于耳垂引起的反射等复杂的路径特性都根据音频到达的方向而改变。HRTF滤波器可以通过改变音频信号的音质来处理包括在头顶声道中的音频信号,以使3D音频可识别。
平移单元123获得要应用于每个频带和每个声道的平移系数并应用平移系数,以相对于每个输出声道平移所输入的音频信号。对音频信号执行平移意味着控制应用于每个输出声道的信号的振幅,以在两个输出声道之间的特定位置处渲染音频源。平移系数可以被称为平移增益。
平移单元123可以通过使用添加到最近声道方法对头顶声道信号中的低频信号执行渲染,并且可以通过使用多声道平移(Multichannel panning)方法对高频信号执行渲染。根据多声道平移方法,将对多声道音频信号的每个声道的信号应用增益值,使得每个信号可以被渲染到至少一个水平声道,其中所述增益值设置为在要被渲染到每个声道信号的声道中是不同的。应用了增益值的每个声道的信号可以通过混合来合成,并且可以作为最终信号输出。
低频信号是高度衍射的,即使多声道音频信号的声道没有根据多声道平移方法划分并且渲染到几个声道,而是仅渲染到一个声道,低频信号也可以具有由收听者类似地识别的音质。因此,根据实施方式的3D音频再现设备100可以通过使用添加到最近声道方法来渲染低频信号,因此可以防止当几个声道混合为一个输出声道时可能发生的音质恶化。也就是说,当几个声道混合为一个输出声道时,音质可能由于声道信号之间的干扰而被放大或减小因此可能恶化,并且在这点上,可以通过将一个声道混合到一个输出声道来防止音质恶化。
根据添加到最近声道方法,多声道音频信号的声道可以不被渲染到几个声道,而是可以将每个声道渲染到用于再现的声道之中的最近的声道。
另外,3D音频再现设备100可以通过根据频率使用不同的方法来执行渲染而在没有音质恶化的情况下扩展最佳收听点(sweet spot)。也就是说,根据添加到最近声道方法渲染高度衍射的低频信号,使得可以防止当多个声道混合为一个输出声道时发生的音质恶化。最佳收听点是指收听者可以在没有失真的情况下最佳地收听3D音频的预定范围。
当最佳收听点大时,收听者可以在没有失真的情况下在大范围中最佳地收听3D音频而,并且当收听者没有位于最佳收听点时,收听者可能听到其中音质或声像失真的音频。
图3示出根据实施方式当多个输入声道缩混到多个输出声道时的声道的布局。
已经开发了一种技术来为3D音频提供3D环绕图像,以提供与现实相同或被进一步夸大的现场和沉浸感,例如3D图像。3D音频是指相对于声音具有高度和空间感知的音频信号,并且需要至少两个扬声器即输出声道来以再现3D音频。另外,除了使用HRTF的双耳3D音频之外,需要大量的输出声道以进一步精确地实现相对于声音的高度、方向感知和空间感知。
因此,随后是具有2声道输出的立体声系统,提供和开发了各种多声道系统,例如5.1声道系统、Auro 3D系统、Holman 10.2声道系统、ETRI/三星10.2声道系统、NHK 22.2声道系统等。
图3示出经由5.1声道输出系统再现22.2声道3D音频信号的示例。
5.1声道系统是5声道环绕多声道声音系统的通用名称,并且通常作为室内家庭影院和用于剧院的声音系统来传播和使用。所有5.1声道包括前左(FL,Front Left)声道、中央(C,Center)声道、右前声道(FR,Frong Right)声道、环绕左(SL,Surround Left)声道和环绕右(SR,Surround Right)声道。如图3所示,由于来自5.1声道的输出都存在于同一平面上,因此5.1声道系统以物理方式对应于2D系统,并且为了使5.1声道系统再现3D音频信号,必须执行渲染过程以将3D效果应用于要再现的信号。
5.1声道系统广泛地用于各种领域,包括电影、DVD视频、DVD音频、超级音频光盘(SACD)、数字广播等。然而,即使5.1声道系统与立体声系统相比提供了改进的空间感知,5.1声道系统在形成更大的听觉空间方面仍然具有许多限制。特别地,最佳收听点狭窄地形成,并且不能提供具有高角度(elevation angle)的垂直声像,使得5.1声道系统可能不适于例如剧院的大规模听觉空间。
由NHK提出的22.2声道系统包括如图3所示的三层输出声道。上层310包括VOG(Voice of God)、T0、T180、TL45、TL90、TL135、TR45、TR90和TR45声道。这里,每个声道的名称前面的索引T是指上层,索引L或R是指左侧或右侧,以及后面的数字是指自中央声道的方位角。上层通常称为顶层。
VOG声道是在收听者的头部上方的声道,具有90度的高角度,并且不具有方位角。当VOG声道的位置稍微改变时,VOG声道具有方位角并且具有不是90度的高角度,并且在这种情况下,VOG声道可能不再是VOG声道。
除了5.1声道的输出声道之外,中间层320处于与5.1声道相同的平面上,并且包括ML60、ML90、ML135、MR60、MR90和MR135声道。这里,每个声道的名称的前面的索引M是指中间层,以及后面的数字是指相对于中央声道的方位角。
下层330包括L0、LL45和LR45声道。这里,每个声道的名称的前面的索引L是指下层,以及后面的数字是指相对于中央声道的方位角。
在22.2声道中,中间层被称为水平声道,以及方位角为0度或180度的VOG、T0、T180、T180、M180、L和C声道被称为垂直声道。
当经由5.1声道系统再现22.2声道输入信号时,最一般的方案是通过使用缩混公式将信号分配给声道。可替代地,通过执行渲染以提供虚拟高度,5.1声道系统可以再现具有高度的音频信号。
图4示出根据实施方式在标准布局和输出声道的布置布局之间发生位置偏差的示例中的平移单元。
当通过使用数量少于输入信号的声道数量的输出声道来再现多声道输入音频信号时,原始声像可能失真,并且为了补偿失真,正在研究各种技术。
一般渲染技术被设计为在假设扬声器即输出声道根据标准布局布置的情况下执行渲染。然而,当输出声道没有被布置为精确地匹配标准布局时,出现声像的位置的失真和音质的失真。
声像的失真广泛地包括在相对低水平中不敏感的高度的失真、相位角的失真等。然而,由于双耳位于左侧和右侧的人体的物理特性,如果左中右侧的声像改变,则可以敏感地感知声像的失真。特别地,可以进一步敏感地感知前侧的声像。
因此,如图3所示,当经由5.1声道实现22.2声道时,特别要求不改变位于0度或180度处的VOG、T0、T180、T180、M180、L和C声道的声像,而不是左声道和右声道。
当平移音频输入信号时,基本上执行两个过程。第一过程对应于初始化过程,其中根据输出声道的标准布局计算相对于输入多声道信号的平移系数。在第二过程中,基于实际布置输出声道的布局来修改所计算的系数。在执行平移系数修改过程之后,可以在更准确的位置呈现输出信号的声像。
因此,为了供平移单元123执行处理,除了音频输入信号之外,还需要关于输出声道的标准布局的信息和关于输出声道的布置布局的信息。在从L声道和R声道渲染C声道的情况下,音频输入信号指示要经由C声道再现的输入信号,而音频输出信号指示根据布置布局从L声道和R声道输出的修改的平移信道。
当在标准布局和输出声道的布置布局之间存在高度偏差(elevation deviation)时,仅考虑方位偏差(azimuth deviation)的2D平移方法不能补偿由于高度偏差引起的效应。因此,如果在标准布局和输出声道的布置布局之间存在高度偏差,则必须通过使用图4的高度效应补偿单元124来补偿由于高度偏差引起的高度增加效果。
图5是示出根据实施方式的3D音频再现设备中的解码器和3D音频渲染器的配置的框图。
参考图5,针对解码器110和3D音频渲染器120的配置示出根据实施方式的3D音频再现设备100,并且省略其它配置。
输入到3D音频再现设备100的音频信号是以比特流形式输入的编码信号。解码器110选择适合于经编码的音频信号的格式的解码器,对所输入的音频信号解码,并向3D音频渲染器120发送经解码的音频信号。
3D音频渲染器120包括被配置为获得和更新滤波器系数和平移系数的初始化单元125以及被配置为执行滤波和平移的渲染单元127。
渲染单元127对从解码器110发送的音频信号执行滤波和平移。滤波单元1271处理关于音频的位置的信息并且因此使所渲染的音频信号在期望的位置再现,以及平移单元1272处理关于音频的音质的信息并且因此使所渲染的音频信号具有映射到期望位置的音质。
滤波单元1271和平移单元1272执行与参考图2描述的滤波单元121和平移单元123的功能相似的功能。然而,图2的滤波单元121和平移单元123以简单的形式显示,其中可以省略用于获得滤波器系数和平移系数的初始化单元等。
这里,从初始化单元125提供用于执行滤波的滤波器系数和用于执行平移的平移系数。初始化单元125包括高度渲染参数获取单元1251和高度渲染参数更新单元1252。
高度渲染参数获取单元1251通过使用输出声道即扬声器的配置和布置来获得高度渲染参数的初始值。这里,可以基于根据标准布局的输出声道的配置和根据高度渲染设置的输入声道的配置或者根据读取输入/输出声道之间的映射关系预先存储的初始值来计算高度渲染参数的初始值。高度渲染参数可包括将由高度渲染参数获取单元1251使用的滤波器系数或者将由高度渲染参数更新单元1252使用的平移系数。
然而,如上所述,用于渲染高度的高度设置值可能相对于输入声道的设置具有偏差。在这种情况下,如果使用固定的高度设置值,则难以通过使用不同于输入声道的输出声道来实现用于类似地三维再现原始3D音频信号的虚拟渲染的目的。
例如,当高度太高时,声像较小并且音质恶化;而当高度太低时,难以感觉到虚拟渲染的效果。因此,需要根据用户的设置或适合于输入声道的虚拟渲染水平来调整高度。
高度渲染参数更新单元1252基于输入声道的高度信息或用户设置的高度来更新由高度渲染参数获取单元1251获得的高度渲染参数的初始值。这里,如果输出声道的扬声器布局相对于标准布局具有偏差,则可以添加用于补偿由于差异而产生的影响的过程。输出声道的偏差可包括根据高角度或方位角之间的差异的偏差信息。
由渲染单元127使用由初始化单元125获得和更新的高度渲染参数而过滤和平移的输出音频信号分别经由对应于输出声道的扬声器再现。
图6至图8示出根据实施方式根据声道布局中上层的高度的上层声道布局。
当假设输入声道信号是22.2声道3D音频信号并且根据图3所示的布局来布置时,根据高角度,输入声道的上层具有图4所示的布局。这里,假设高角度为0度、25度、35度和45度,并且省略了对应于高角度90度的VOG声道。具有0度高角度的上层声道存在于水平面(中间层320)上。
图6示出上层声道的主视图布局。
参考图6,八个上层声道中的每一个具有45度的方位角差,因此,当在相对于垂直声道轴的前侧观看上层声道时,在除了TL90声道和TR90声道之外的六个声道中,每两个声道即TL45声道和TL135声道、T0声道和T180声道以及TR45声道和TR135声道重叠。这与图8相比更加明显。
图7示出上层声道的俯视图布局。图8示出上层声道的3D视图布局。可以看出,八个上层声道以规则的间隔布置并且每个具有45度的方位角差。
当经由高角度渲染以3D音频再现的内容被固定为具有35度的高角度时,可以对所有输入音频信号执行具有35度高角度的高度渲染,使得将实现最佳结果。
然而,可以根据多条内容而将高角度不同地应用于内容的3D音频,并且如图6至图8所示,根据每个声道的高度,声道的位置和距离变化,以及由于方差引起的信号特性也变化。
因此,当以固定高角度执行虚拟渲染时,出现声像的失真,并且为了实现最佳渲染性能,需要考虑输入3D音频信号的高角度即输入声道的高角度来执行渲染。
图9至图11示出根据实施方式根据声道的高度的声像的变化以及高度滤波器的变化。
图9示出当高处声道的高度分别为0度、35度和45度时的声道的位置。图9是在收听者的后面得到的,并且所示的声道中的每一个是ML90声道或TL90声道。当高角度为0度时,声道存在于水平面上并且对应于ML90声道,以及当高角度为35度和45度时,声道是上层声道并且对应于TL90声道。
图10示出当从如图9所示定位的各个声道输出音频信号时,收听者的左耳和右耳之间的信号差异。
当音频信号从不具有高角度的ML90输出时,理论上,仅经由左耳感知音频信号并且不经由右耳感知音频信号。
然而,随着高度增加,经由左耳和右耳感知的音频信号之间的差异减小,并且当声道的高角度增加并因此变为90度时,声道变为在收听者的头部上方的VOG声道,因此,双耳感知到相同的音频信号。
因此,相对于由双耳根据高角度感知的音频信号的变化如图7B所示。
对于在高角度为0度时经由左耳感知的音频信号,仅左耳感知音频信号而右耳不感知音频信号。在这种情况下,耳间水平差(ILD)和耳间时间差(ITD)是最大的,并且收听者感知音频信号作为存在于左水平平面声道上的ML90声道的声像。
对于当高角度为35度时经由左耳和右耳感知的音频信号以及当高角度为45度时经由左耳和右耳感知的音频信号之间的差异,随着高角度增加,经由左耳和右耳感知的音频信号之间的差异减小,并且由于差异的影响,收听者可以感觉到输出音频信号中的高度差异。
与来自具有45度高角度的声道的输出信号相比,来自具有35度高角度的声道的输出信号的特征在于声像大、最大收听位置大以及音质自然;而与来自具有35度高角度的声道的输出信号相比,来自具有45度高角度的声道的输出信号的特征在于声像小、最大收听位置小以及提供强烈沉浸感的声场感觉。
如上所述,随着高角度增加,高度也增加,使得沉浸感觉变强,但是音频信号的宽度减小。这是因为,随着高角度增加,声道的物理位置变得更靠近并且因此靠近收听者。
因此,下面确定根据高角度的方差的平移系数的更新。随着高角度增加,更新平移系数以使声像变大;而随着高角度的减小,更新平移系数以使声像变小。
例如,假设对于虚拟渲染基本设置的高角度是45度,并且通过将高角度减小到35度来执行虚拟渲染。在这种情况下,要应用于要渲染的虚拟声道和同侧(ipsilateral)输出声道的渲染平移系数增加,并且通过功率归一化(power normalization)来确定要应用于剩余声道的平移系数。
对于更具体的描述,假设22.2输入多声道信号将经由5.1输出声道(扬声器)再现。在这种情况下,从22.2输入声道中应用虚拟渲染并且具有高角度的输入声道是CH_U_000(T0)、CH_U_L45(TL45)、CH_U_R45(TR45)、CH_U_L90(TL90)、CH_U_R90(TR90)、CH_U_L135(TL135)、CH_U_R135(TR135)、CH_U_180(T180)和CH_T_000(VOG)九个声道,以及5.1输出声道是存在于水平面上的CH_M_000、CH_M_L030、CH_M_R030、CH_M_L110、CH_R_110五个声道(低音扬声器声道(woofer channel)除外)。
以这种方式,在通过使用5.1个输出声道来渲染CH_U_L45声道的情况下,当基本设置的高角度是45度并且尝试将高角度减小到35度时,将要应用于作为CH_U_L45声道的同侧输出声道的CH_M_L030和CH_M_L110的平移系数更新以增加3dB,并且剩余三个声道的平移系数被更新以被减少,使得满足这里,N指示用于渲染随机虚拟声道的输出声道的数量,以及gi指示要应用于每个输出声道的平移系数。
必须对每个高处输入声道执行该过程。
另一方面,假设基本设置的高角度对于虚拟渲染是45度,并且通过将高角度增加到55度来执行虚拟渲染。在这种情况下,要应用于要渲染的虚拟声道和同侧输出声道的渲染平移系数减小,并且通过功率归一化(power normalization)来确定要应用于剩余声道的平移系数。
当通过使用5.1输出声道来渲染CH_U_L45声道时,如果基本设置的高角度从45度增加到55度,则将要应用于作为CH_U_L45声道的同侧输出声道的CH_M_L030和CH_M_L110的平移系数更新以减少3dB,并且剩余三个声道的平移系数被更新以被增加,使得满足这里,N指示用于渲染随机虚拟声道的输出声道的数量,以及gi指示要应用于每个输出声道的平移系数。
然而,当以上述方式增加高度时,需要不会因平移系数的更新而反转左右声像,并且这将参照图8进行描述。
在下文中,将参照图11描述更新音色滤波器系数的方法。
图11示出当声道的高角度为35度以及高角度为45度时根据频率的音色滤波器的特性。
如图11所示,显而易见,与高角度为35度的声道的音色滤波器相比,在高角度为45度的声道的音色滤波器中,由于高角度而具备的特性是显著的。
在执行虚拟渲染以具有大于参考高角度的高角度的情况下,当对参考高角度执行渲染时,在其幅度需要增加的频带(其中原始滤波器系数大于1)中发生更多的增加(更新的滤波器系数增加到大于1),而在其幅度(magnitude)需要减小的频带(其中原始滤波器系数小于1)中发生更多的减小(更新的滤波器系数减小到小于1)。
当滤波器幅度特性以分贝标度表示时,如图11所示,在输出信号的幅度需要增加的频带中示出具有正值的音色滤波器,而在输出信号的幅度需要减小的频带中示出具有负值的音色滤波器。另外,如图11而明显,随着高角度减小,滤波器幅度的形状变得平坦。
当通过使用水平平面声道虚拟地渲染高处声道时,随着高角度减小,高处声道具有与水平面的信号类似的音色;而随着高角度增加,在高角度方面的改变是显著的,以使得随着高角度增加,根据音色滤波器的效应增加从而使得由于高角度的增加而引起的高度效应被加强。另一方面,随着高角度减小,根据音色滤波器的效应减小使得可以减小高度效应。
因此,通过使用基本设置的高角度和基于实际渲染的高角度的权重来更新原始滤波器系数,而执行根据高角度的改变的滤波器系数的更新。
在基本设置的用于虚拟渲染的高角度是45度并且通过执行渲染到比基本高角度低35度来减小高度的情况下,确定对应于图11的45度滤波器的系数为初始值,并且需要将其更新为与35度滤波器相对应的系数。
因此,在试图通过执行渲染到比作为基本高角度的45度高角度低的35度来减小高度的情况下,必须更新滤波器系数,使得可以将根据频带的滤波器的谷和底修改为比45度的滤波器的谷和底更加平滑。
另一方面,在基本设置的高角度为45度并且通过执行渲染到比基本高角度高的55度来增加高度的情况下,必须更新滤波器系数,使得可以将根据频带的滤波器的谷和底修改为比45度的滤波器的谷和底更尖锐。
图12是根据实施方式的渲染3D音频信号的方法的流程图。
渲染器接收包括多个输入声道的多声道音频信号(1210)。输入多声道音频信号经由渲染被转换到多个输出声道信号,并且在输出声道的数量小于输入声道的数量的缩混示例中,具有22.2声道的输入信号被转换到具有5.1声道的输出声道。
以这种方式,当通过使用2D输出声道来渲染3D音频输入信号时,在水平面上对输入声道应用一般渲染,并且对各自具有高角度的高处声道应用虚拟渲染以向其应用高度。
为了执行渲染,需要将在滤波中使用的滤波器系数和在平移中使用的平移系数。这里,在初始化过程中,根据输出声道的标准布局和用于虚拟渲染的基本设置的高角度获得渲染参数(1220)。基本设置的高角度可以根据渲染器来不同地确定,但是当以固定的高角度执行虚拟渲染时,根据用户的偏好或输入信号的特性,虚拟渲染的满意度和效果可能减小。
因此,当输出声道的配置相对于输出声道的标准布局具有偏差时,或者当要执行虚拟渲染的高度不同于渲染器的基本设置的高角度时,更新渲染参数(1230)。
这里,更新的渲染参数可包括通过向滤波器系数的初始值添加基于高角度偏差确定的权重而更新的滤波器系数,或者可包括通过根据将输入声道的高角度与基本设置的高角度进行比较的结果来增加或减少平移系数的初始值而更新的平移系数。
已经参照图9至图11描述了更新滤波器系数和平移系数的详细方法,并且因此省略说明。在这点上,可以另外修改或扩展更新的滤波器系数和更新的平移系数,并且稍后将详细提供其描述。
如果输出声道的扬声器布局相对于标准布局具有偏差,则可以添加用于补偿由于偏差而引起的效应的过程,但是这里省略其详细方法的描述。输出声道的偏差可包括根据高角度或方位角之间的差异的偏差信息。
图13示出根据实施方式当输入声道的高角度等于或大于阈值时左右声像反转的现象。
人根据到达人的双耳的声音的时间差、水平差和频率差来区分声像的位置。当到达双耳的信号的特性之间的差异大时,人可以容易地定位位置,并且即使发生小的误差,也不会发生相对于声像的前后混淆或左右混淆。然而,位于头部的右后侧或右前侧的虚拟音频源具有非常小的时间差和非常小的水平差,使得人必须仅通过使用频率之间的差异来定位位置。
如图10中的那样,在图13中,方形声道是在收听者后侧的CH_U_L90声道。这里,当CH_U_L90的高角度是φ时,随着φ增加,到达收听者的左耳和右耳的音频信号的ILD和ITD减小,并且由双耳感知的音频信号具有类似的声像。高角度φ的最大值为90度,并且当φ为90度时,CH_U_L90变为存在于收听者头部上方的VOG声道,因此,经由双耳感知相同的音频信号。
如图13的左图所示,如果φ具有非常大的值,则增加高度使得收听者可以感觉到提供强烈的沉浸感的声场感。然而,当高度增加时,声像变小并且最佳收听点变小,使得即使收听者的位置稍微改变或者声道稍微移动,也可能相对于声像发生左右反转现象。
图13的右图示出当收听者稍微向左移动时收听者和声道的位置。这是由于声道的高角度φ具有大的值而偏高地形成高度的情况,因此,即使收听者稍微移动,左右声道的相对位置也显著改变,并且在最坏的情况下,虽然是左侧声道,但到达右耳的信号被更显著地感知,使得可发生如图13所示的声像的左右反转。
在渲染过程中,比起应用高度更重要的是保持声像的左右平衡以及定位声像的左右位置,因此,为了防止上述现象,可能需要将用于虚拟渲染的高角度限制在预定范围内。
因此,在当增加高角度以实现高于用于渲染的基本设置的高角度的高度时减小平移系数的情况下,需要将平移系数的最小阈值设置为不等于或低于预定值。
例如,即使60度的渲染高度增加到等于或大于60度,当通过强制地应用相对于60度的阈值高角度更新的平移系数来执行平移时,可以防止声像的左右反转现象。
当通过使用虚拟渲染来生成3D音频时,由于环绕声道的再现分量,可能发生音频信号的前后混淆现象。前后混淆现象是指难以确定3D音频中的虚拟音频源存在于前侧还是后侧的现象。
参考图13,假设收听者移动,然而,对于本领域的普通技术人员明显的是,随着声像增加,即使收听者不移动,也存在由于每个人的听觉器官的特性而发生左右混乱或前后混淆的很大可能。
在下文中,将详细描述初始化和更新高度渲染参数即高度平移系数和高度滤波器系数的方法。
当高处输入声道iin的高角度elv大于35度时,如果iin是前声道(方位角在-90度至+90度之间),则根据公式1至公式3来确定更新的高度滤波器系数
【公式1】
【公式2】
【公式3】
另一方面,当高处输入声道iin的高角度elv大于35度时,如果iin是后声道(方位角在-180度至-90度之间或90度至180度之间),则根据公式4至公式6确定更新的高度滤波器系数
【公式4】
【公式5】
【公式6】
其中,fk是第k频带的归一化中心频率,fs是采样频率,以及是在参考高角度处的高度滤波器系数的初始值。
当用于高度渲染的高角度不是参考高角度时,必须更新相对于除了TBC声道(CH_U_180)和VOG声道(CH_T_000)之外的高处输入声道的高度平移系数。
当参考高角度是35度并且iin是TFC声道(CH_U_000)时,根据公式7和公式8来分别确定更新的高度平移系数GvH,5(iin)和GvH,6(iin)。
【公式7】
GvH,5(iin)=10(0.25×min(max(elv-35,0),25))/20×GvH0,5(iin)
【公式8】
GvH,6(iin)=10(0.25×min(max(elv-35,0),25))/20×GvH0,6(iin)
其中,GvH0,5(iin)是用于通过使用35度的参考高角度来虚拟渲染TFC声道的SL输出声道的平移系数,以及GvH0,6(iin)是用于通过使用35度的参考高角度来虚拟渲染TFC声道的SR输出声道的平移系数。
对于TFC声道,不可能调整左右声道增益以控制高度,因此,调节相对于作为前声道的后声道的SL声道和SR声道的增益的比率以控制高度。以下提供详细描述。
对于除了TFC声道之外的其它声道,当高处输入声道的高角度大于35度的参考高角度时,输入声道的同侧(ipsilateral)声道的增益减小,并且输入声道的对侧(contralateral)声道的增益由于gI(elv)和gC(elv)之间的增益差而增加。
例如,当输入声道为CH_U_L045声道时,输入声道的同侧输出声道为CH_M_L030和CH_M_L110,输入声道的对侧输出声道为CH_M_R030和CH_M_R110。
下文中,将详细描述当输入声道是侧声道、前声道或后声道时,从其获得gI(elv)和gC(elv)以及更新高度平移增益的方法。
当具有高角度e1v的输入声道是侧声道(方位角在-110度至-70度之间或70度至110度之间)时,根据公式9和公式10分别确定gI(elv)和gC(elv)。
【公式9】
gI(elv)=10(-0.05522×min(max(elv-35,0),25))/20
【公式10】
gC(elv)=10(0.41879×min(max(elv-35,0),25))/20
当具有高角度e1v的输入声道是前声道(方位角在-70度到+70度之间)或后声道(方位角在-180度到-110度之间或110度至180度之间)时,根据公式11和公式12分别确定gI(elv)和gC(elv)。
【公式11】
gI(elv)=10(-0.047401×min(max(elv-35,0),25))/20
【公式12】
gC(elv)=10(0.14985×min(max(elv-35,0),25))/20
基于通过使用公式9至公式12计算的gI(elv)和gC(elv),可以更新高度平移系数。
根据公式13和公式14分别确定相对于输入声道的同侧输出声道的更新的高度平移系数GvH,I(iin)和相对于输入声道的对侧输出声道的更新的高度平移系数GvH,C(iin)。
【公式13】
GvH,I(iin)=gI(elv)×GvH0,I(iin)
【公式14】
GvH,C(iin)=gC(elv)×GvH0,C(iin)
为了恒定地保持输出信号的能量水平,根据公式15和公式16归一化通过使用公式13和公式14获得的平移系数。
【公式15】
【公式16】
以这种方式,执行功率归一化过程使得输入声道的平移系数的平方的总和变为1,并且通过这样做,更新平移系数之前的输出信号的能量水平以及更新平移系数之后的输出信号的能量水平可以同等地保持。
在GvH,I(iin)和GvH,C(iin)中,索引H指示仅在高频域中更新的高度平移系数。公式13和公式14的更新的高度平移系数仅应用于高频带,2.8kHz至10kHz频带。然而,当针对环绕声道更新高度平移系数时,高度平转系数不仅针对高频带还针对低频带更新。
当具有高角度elv的输入声道是环绕声道(方位角在-160度至-110度之间或110度至160度之间)时,根据公式17和公式18分别确定相对于在2.8kHz或更低的低频带中的输入声道的同侧输出声道的更新的高度平移系数GvL,I(iin)和相对于输入声道的对侧输出声道的更新的高度平移系数GvL,C(iin)。
【公式17】
GvL,I(iin)=gI(elv)×GvL0,I(iin)
【公式18】
GvL,C(iin)=gC(elv)×GvL0,C(iin)
如在高频带中,为了使低频带的更新的高度平移增益恒定地保持输出信号的能量水平,根据公式19和公式20功率归一化通过使用公式15和公式16获得的平移系数。
【公式19】
【公式20】
以这种方式,执行功率归一化过程使得输入声道的平移系数的平方的总和变为1,并且通过这样做,更新平移系数之前的输出信号的能量水平以及更新平移系数之后的输出信号的能量水平可以同等地保持。
图14至图17是用于描述根据实施方式的防止声像的前后混淆的方法的图。
图14示出根据实施方式的水平声道和前高处声道。
参考图14所示的实施方式,假设输出声道是5.0声道(现在示出低音扬声器声道)并且前高处输入声道被渲染到水平输出声道。5.0声道存在于水平面1410上并且包括前中央(FC)声道、左前(FL)声道、右前(FR)声道、左环绕(SL)声道和右环绕(SR)声道。
前高处声道是对应于图14的上层1420的声道,并且在图14所示的实施方式中,前高处声道包括顶部前中央(TFC)声道、顶部前左(TFL)声道和顶部右前(TFR)声道。
当假设在图14所示的实施方式中输入声道是22.2声道时,24个声道的输入信号被渲染(缩混)以生成5个声道的输出信号。这里,分别对应于24个声道的输入信号的分量根据渲染规则分布在5个声道输出信号中。因此,输出声道,即前中央(FC)声道、左前(FL)声道、右前(FR)声道、左环绕(SL)声道和右环绕(SR)声道分别包括对应于输入信号的分量。
在这点上,可以根据声道布局不同地确定前高处声道的数量、水平声道的数量、方位角和高处声道的高角度。当输入声道是22.2声道或22.0声道时,前高处声道可包括CH_U_L030、CH_U_R030、CH_U_L045、CH_U_R045和CH_U_000中的至少一个。当输出声道是5.0声道或5.1声道时,环绕声道可包括CH_M_L110和CH_M_R110中的至少一个。
然而,对于本领域的普通技术人员明显的是,即使输入和输出多声道与标准布局不匹配,也可以根据每个声道的高角度和方位角不同地配置多声道布局。
当通过使用水平输出声道虚拟渲染高处输入声道信号时,环绕输出声道用于通过向声音应用高度来增加声像的高度。因此,当来自水平高处输入声道的信号被虚拟渲染到作为水平声道的5.0输出声道时,可以通过来自作为环绕输出声道的SL声道和SR声道的输出信号来应用和调整高度。
然而,由于HRTF对于每个人是唯一的,所以可能发生前后混淆现象,其中,根据收听者的HRTF特性,被虚拟渲染到前高处声道的信号被感知为它在后侧发声。
图15示出根据实施方式的前高处声道的感知百分比。
图15示出当通过使用水平输出声道虚拟地渲染前高处声道即TFR声道时用户定位声像的位置(前和后)的百分比。参考图15,由用户识别的高度对应于高处声道1420并且圆的尺寸与可能性的值成比例。
参考图15,尽管大多数用户将声像定位在右侧45度处,该处是经虚拟渲染的声道的位置,但是许多用户将声像定位在另一位置而不是45度。如上所述,发生这种现象是由于HRTF特性在个人方面不同,可以看出某个用户甚至将声像定位在右侧比90度进一步延伸的后侧处。
HRTF指示音频从头部附近的空间中的点处的音频源到鼓膜的传递路径,其在数学上表达为传递函数。HRTF根据音频源相对于头部中央的位置以及头部或耳廓的尺寸或形状而显著变化。为了准确地描绘虚拟音频源,目标人物的HRTF必须被单独测量和使用,这实际上是不可能的。因此,通常,使用通过在类似于人体的人体模型的鼓膜位置处布置麦克风测量的非个体化HRTF。
当通过使用非个体化HRTF再现虚拟音频源时,如果人的头部或耳廓与人体模型或虚拟头麦克风系统(dummy head microphone system)不匹配,则会发生与声像定位有关的各种问题。可以通过考虑人的头部尺寸来补偿水平面上的定位度的偏差,但是由于耳廓的尺寸或形状在个人方面不同,所以难以补偿高度的偏差或者前后混淆现象。
如上所述,每个人根据头部的尺寸或形状具有他/她自己的HRTF,然而,实际上难以向人们分别应用不同的HRTF。因此,使用非个体化的HRTF,即公共的HRTF,并且在这种情况下,可能发生前后混淆现象。
这里,当向环绕输出声道信号添加预定的时间延迟时,可以防止前后混淆现象。
声音不是由每个人同等地感知,并且根据周围环境或收听者的心理状态而不同地感知。这是因为在声音传递的空间中的物理事件由收听者以主观和感觉方式感知。由收听者根据主观或心理因素感知的音频信号被称为心理声学。心理声学不仅受到包括声压、频率、时间等的物理变量的影响,而且还受到包括响度、音调、音色、关于声音的经验等主观变量的影响。
心理声学根据情况可以具有许多效应,并且例如可包括掩蔽效应、鸡尾酒会效应、方向感知效应、距离感知效应和优先效应(precedence effect)。基于心理声学的技术被用于各种领域以向收听者提供更合适的音频信号。
优先效应也被称为哈斯效应(Hass effect),其中当由1ms到30ms的时间延迟顺序生成不同的声音时,收听者可以感知到声音是在生成首先到达的声音的位置中生成的。然而,如果两个声音的生成时间之间的时间延迟等于或大于50ms,则两个声音在不同方向上被感知。
例如,当定位声像时,如果右声道的输出信号被延迟,则声像向左移动,并且因此被感知为在右侧再现的信号,并且该现象被称为优先效应或哈斯效应。
环绕输出声道用于向声像添加高度,并且如图15所示,由于环绕输出声道信号的影响,发生前后混淆现象从而使得一些收听者可能感知到前声道信号来自后侧。
通过使用上述优先效应,可以解决上面的问题。当向环绕输出声道信号添加预定时间延迟以再现前高处输入声道时,与来自相对于前面以-90度至+90度存在并且作为用于再现前高处输入声道信号的输出信号中的前输出声道的信号相比,来自相对于前面以-180度至-90度或+90度至+180度存在的环绕输出声道的信号被延迟地再现。
因此,即使来自前输入声道的音频信号可能被感知为其是在后侧再现的,由于收听者的独特的HRTF,音频信号被感知为其是在首先根据优先效应再现音频信号的前侧再现的。
图16是根据实施方式的防止前后混淆的方法的流程图。
渲染器接收包括多个输入声道的多声道音频信号(1610)。输入多声道音频信号通过渲染被转换为多个输出声道信号,并且在输出声道的数量少于输入声道的数量的缩混示例中,具有22.2声道的输入信号被转换为具有5.1声道或5.0声道的输出信号。
以这种方式,当通过使用2D输出声道来渲染3D音频输入信号时,在水平面上向输入声道应用一般渲染,并且向每个具有高角度的高处声道应用虚拟渲染以向其应用高度。
为了执行渲染,需要将在滤波中使用的滤波器系数和在平移中使用的平移系数。这里,在初始化过程中,根据输出声道的标准布局和用于虚拟渲染的基本设置的高角度获得渲染参数。可以根据渲染器不同地确定基本设置的高角度,并且当根据用户的偏好或输入信号的特性设置预定高角度而不是基本设置的高角度时,可以改进虚拟渲染的满意度和效果。
为了防止由于环绕声道引起的前后混淆,相对于前高处声道向环绕输出声道添加时间延迟(1620)。
当向环绕输出声道信号添加预定时间延迟以再现前高处输入声道时,与来自相对于前面以-90度至+90度存在并且作为用于再现前高处输入声道信号的输出信号中的前输出声道的信号相比,来自相对于前面以-180度至-90度或+90度至+180度存在的环绕输出声道的信号被延迟地再现。
因此,即使来自前输入声道的音频信号可能被感知为其是在后侧再现的,由于收听者的独特的HRTF,音频信号被感知为其是在首先根据优先效应再现音频信号的前侧再现的。
如上所述,为了通过相对于前高处声道延迟环绕输出声道来再现前高处声道,渲染器基于添加到环绕输出声道的延迟来改变高度渲染参数(1630)。
当高度渲染参数改变时,渲染器基于经改变的高度渲染参数生成经高度渲染的环绕输出声道(1640)。更详细地,通过将改变的高度渲染参数应用于高处输入声道信号来执行渲染,使得生成环绕输出声道信号。以这种方式,基于改变的高度渲染参数相对于前高处输入声道延迟的经高度渲染的环绕输出声道可以防止由于环绕输出声道引起的前后混淆。
应用于环绕输出声道的时间延迟在距离方面优选为约2.7ms和约91.5cm,其对应于128个样本,即48kHz中的两个正交镜像滤波器(QMF,Quadrature Mirror Filter)样本。然而,为了防止前后混淆,添加到环绕输出声道的延迟可以根据采样率和再现环境而变化。
这里,当输出声道的配置相对于输出声道的标准布局具有偏差时,或者当要执行虚拟渲染的高度不同于渲染器的基本设置的高角度时,渲染参数被更新。更新的渲染参数可包括通过向滤波器系数的初始值添加基于高角度偏差确定的权重而更新的滤波器系数,或者可包括通过根据输入声道的高角度与基本设定高角度的比较结果增加或减小平移系数的初始值来更新的平移系数。
如果存在待进行空间高度渲染的前高处输入声道,则向输入QMF样本添加前输入声道的延迟QMF样本,并且缩混矩阵被扩展到改变的系数。
下面详细描述向前高处输入声道添加时间延迟并改变渲染(缩混)矩阵的方法。
当输入声道的数量是Nin时,对于来自【1Nin】声道中的第i个输入声道,如果第i个输入声道是高处输入声道CH_U_L030、CH_U_L045、CH_U_R030、CH_U_R045和CH_U_000中的一个,则根据公式21和公式22确定输入声道的QMF样本延迟(delay)和延迟的QMF样本。
【公式21】
delay=round(fs*0.003/64)
【公式22】
其中,fs指示采样频率,以及指示第k个频带的第n个QMF子带样本。应用于环绕输出声道的时间延迟在距离方面优选为约2.7ms和约91.5cm,其对应于128个样本,即48kHz中的两个QMF样本。然而,为了防止前后混淆,添加到环绕输出声道的延迟可以根据采样率和再现环境而变化。
根据公式23至公式25确定改变的渲染(缩混)矩阵。
【公式23】
【公式24】
MDMX2=[MDMX2[00...0]T]
【公式25】
Nin=Nin+1
其中,MDMX指示用于高度渲染的缩混矩阵,MDMX2指示用于一般渲染的缩混矩阵,以及Nout指示输出声道的数量。
为了完成每个输入声道的缩混矩阵,Nin增加1并且重复公式3和公式4的过程。为了获得关于一个输入声道的缩混矩阵,需要获得用于输出声道的缩混参数。
如下确定第j个输出声道相对于第i个输入声道的缩混参数。
当输出声道的数量为Nout时,相对于【1Nout】声道中的第j个输出声道,如果第j个输出声道是环绕声道CH_M_L110和CH_M_R110中的一个,则根据公式26确定应用于输出声道的缩混参数。
【公式26】
MDMX,j,i=0
当输出声道的数量为Nout时,相对于【1Nout】中的第j个输出声道,如果第j个输出声道不是环绕声道CH_M_L110或CH_M_R110,则根据公式27确定应用于输出声道的缩混参数。
【公式27】
MDMX,j,Nin=0
这里,如果输出声道的扬声器布局相对于标准布局具有偏差,则可以添加用于补偿由于差异而引起的效应的过程,但是省略其详细描述。输出声道的偏差可包括根据高角度或方位角之间的差异的偏差信息。
图17示出根据实施方式当向环绕输出声道添加延迟时的水平声道和前高处声道。
在图17的实施方式中,类似于图14的实施方式,假设输出声道是5.0声道(现在示出低音扬声器声道)并且前高处输入声道被渲染到水平输出声道。5.0声道存在于水平面1410上并且包括前中央(FC)声道、左前(FL)声道、右前(FR)声道、左环绕(SL)声道和右环绕(SR)声道。
前高处声道是对应于图14的上层1420的声道,并且在图14所示的实施方式中,前高处声道包括顶部前中央(TFC)声道、顶部前左(TFL)声道和顶部右前(TFR)声道。
在图17的实施方式中,类似于图14的实施方式,当假设输入声道是22.2声道时,24个声道的输入信号被渲染(缩混)以生成5个声道的输出信号。这里,分别对应于24个声道的输入信号的分量根据渲染规则分布在5个声道输出信号中。因此,输出声道,即FC声道、FL声道、FR声道、SL声道和SR声道分别包括对应于输入信号的分量。
在这点上,可以根据声道布局不同地确定前高处声道的数量、水平声道的数量、方位角和高处声道的高角度。当输入声道是22.2声道或22.0声道时,前高处声道可包括CH_U_L030、CH_U_R030、CH_U_L045、CH_U_R045和CH_U_000中的至少一个。当输出声道是5.0声道或5.1声道时,环绕声道可包括CH_M_L110和CH_M_R110中的至少一个。
然而,对于本领域的普通技术人员明显的是,即使输入和输出多声道与标准布局不匹配,也可以根据每个声道的高角度和方位角不同地配置多声道布局。
这里,为了防止由于SL声道和SR声道引起的前后混淆现象,向经由环绕输出声道渲染的前高处输入声道添加预定的延迟。基于改变的高度渲染参数,相对于前高处输入声道延迟的经高度渲染的环绕输出声道可以防止由于环绕输出声道而引起的前后混淆。
获得基于延迟添加的音频信号和添加的延迟而改变的高度渲染参数的方法在公式1至公式7中示出。如图16的实施方式中详细描述的,在图17的实施方式中省略对其的详细描述。
应用于环绕输出声道的时间延迟在距离方面优选为约2.7ms和约91.5cm,其对应于128个样本,即48kHz中的两个QMF样本。然而,为了防止前后混淆,添加到环绕输出声道的延迟可以根据采样率和再现环境而变化。
图18示出根据实施方式的水平声道和顶部前中央(TFC)声道。
根据图18所示的实施方式,假设输出声道是5.0声道(现在示出低音扬声器声道)并且顶部前中央(TFC)声道被渲染到水平输出声道。5.0声道存在于水平面1810上并且包括前中央(FC)声道、左前(FL)声道、右前(FR)声道、左环绕(SL)声道和右环绕(SR)声道。TFC声道对应于图18的上层1820,以及假设TFC声道具有0方位角并且位于预定高角度。
如上所述,当渲染音频信号时防止声像左右反转是非常重要的。为了将具有高角度的高处输入声道渲染到水平输出声道,需要执行虚拟渲染,并且通过渲染将多声道输入声道信号平移为多声道输出信号。
对于以特定高度提供升高的感觉的虚拟渲染,确定平移系数和滤波器系数,并且在这点上,对于TFT声道输入信号,声像必须位于收听者前面即在中央,因此,确定FL声道和FR声道的平移系数以使TFC声道的声像位于中央。
在输出声道的布局与标准布局匹配的情况下,FL声道和FR声道的平移系数必须相同,并且SL声道和SR声道的平移系数也必须相同。
如上所述,由于用于渲染TFC输入声道的左右声道的平移系数必须相同,所以不可调整左右声道的平移系数来调整TFC输入声道的高度。因此,调整前后声道中的平移系数以通过渲染TFC输入声道来应用升高的感觉。
当参考高角度为35度并且要渲染的TFC输入声道的高角度为elv时,根据公式28和公式29分别确定用于将TFC输入声道虚拟渲染到高角度elv的SL声道和SR声道的平移系数。
【公式28】
GvH,5(iin)=10(0.25×min(max(elv-35,0),25))/20×GvH0,5(iin)
【公式29】
GvH,6(iin)=10(0.25×min(max(clv-35,0),25))/20×GvH0,6(iin)
其中,GvH0,5(iin)是用于在参考高角度为35度处执行虚拟渲染的SL声道的平移系数,并且GvH0,6(iin)是用于在参考高角度为35度处执行虚拟渲染的SR声道的平移系数。iin是关于高处输入声道的索引,以及公式28和公式29各自指示当高处输入声道是TFC声道时,平移系数的初始值和更新的平移系数之间的关系。
这里,为了恒定地保持输出信号的能量水平,通过使用公式28和公式29获得的平移系数不是无变量地使用,而是通过使用公式30和公式31被功率归一化然后被使用。
【公式30】
【公式31】
以这种方式,执行功率归一化过程使得输入声道的平移系数的平方的总和变为1,并且通过这样做,更新平移系数之前的输出信号的能量水平以及更新平移系数之后的输出信号的能量水平可以同等地保持。
根据本发明的实施方式还可以实施为在各种计算机配置元件中执行的编程命令,并且然后可以被记录到计算机可读记录介质。计算机可读记录介质可包括编程命令、数据文件、数据结构等中的一者或多者。记录到计算机可读记录介质的编程命令可以针对本发明专门设计或配置,或者可以是计算机软件领域的普通技术人员公知的。计算机可读记录介质的示例包括:磁介质,包括硬盘、磁带和软盘;光介质,包括CD-ROM和DVD;磁光介质,包括光磁盘以及设计为在只读存储器(ROM)、随机存取存储器(RAM)、闪存等中存储和执行编程命令的硬件设备。编程命令的示例不仅包括由编译器生成的机器代码,还包括要通过使用解释器在计算机中执行的大代码。硬件设备可以配置为用作一个或多个软件模块以执行本发明的操作,反之软件模块可以配置为用作一个或多个硬件设备以执行本发明的操作。
虽然已经参考本发明的非显而易见的特征具体描述了详细描述,但是本领域普通技术人员将理解,在不脱离所附权利要求的精神和范围的情况下,在上述设备和方法的形式和细节中可以进行各种删除、替代和改变。
因此,本发明的范围不是由详细描述而是由所附权利要求限定,而且处于所述范围内的所有差异将解释为包括在本发明中。
- 还没有人留言评论。精彩留言会获得点赞!