用于基于解码树的生成而对数据信号进行解码的方法和系统与流程
概括的说,本发明涉及数字通信系统,并且更具体的说,本发明涉及用于基于解码树的生成而对数据信号进行解码的方法、系统和计算机程序产品。
背景技术:
在数字通信中最相关和关键的问题之一涉及高效的解码算法的设计。为了恢复有用的和预期的信息,在接收机侧需要专门的数字处理。这适用于覆盖单个和多个传输的所有通信系统,例如多用户和多天线通信系统,如mimo(多输入多输出)。
具体地,由于其增加频谱效率和传输数据速率的潜能,多天线技术在许多无线通信系统的设计中起了基础性作用。诸如lte和wimax(ieee802.16)之类的若干无线标准具有并入的mimo通信,以增强网络性能并利用由多个天线带来的多样性。在这样的系统中,通过传输信道以编码的形式从发射机设备向接收机设备发送数字信号。接收机设备被配置成对从信道输出接收的信号进行解码以访问数据。在这样的系统中,主要的挑战是设计高效且低复杂性的检测器。
具体地,传输信道可能是嘈杂的,其可能涉及对所接收到信号的破坏。通过使用适当的解码技术来正确地对所接收到信号进行解码,可以在解码侧限制这样的破坏。已知的解码技术是最大可能性(ml)解码技术,根据该技术,接收机设备被配置成在给定所观测到接收信号的情况下,估计最可能的候选信号。
最优ml解码技术依赖于计算所发送到所有可能的信号(也称为“候选信号”),并根据选择标准而选择最可能的信号,例如在所接收的观测信号和候选信号之间的欧几里德距离。
但是,如此详尽的计算在时间和资源方面是昂贵的,且在实时应用中可能难以实现。实际上,候选者的数目,且从而解码器的复杂度,随着数字信号的长度以指数方式增加。对于实际的实现,可供替换的点阵解码算法已经被提出以在考虑解码器复杂度的同时对所接收到信号正确解码,例如球解码器(e.viterbo和j.boutros)。通用的点阵码解码器用于衰落的信道。关于信息理论ieee会议集,45(5):1639-1642,1999年7月)或schnorr-euchner解码器(c.p.schnorr和m.euchner。格基约减:改进的实际算法和解决子集和问题。在1993的数学编程的181-191页)。该类解码器特定地适配成包括单个和多个天线的无线通信和光学通信。
这样的解码算法实现最优ml标准。但是,当星座图(constellation)大小或天线数目增加时,其增加了复杂度。
在其他现有的方法中,实现了诸如zf、zf-dfe和mmse(g.cairek.r.kumar和a.l.moustakas次最优低复杂度解码器。在多输入多输出衰弱信道中线性接收器的渐近性能。2009年10月的关于信息理论的ieee会议集,55(10):4398-4418)。这样的解码器一般在呈现了受限的计算能力的实际系统中使用。
已经提出了其他的解码技术,例如顺序解码技术,其基于ml优化问题(解码树)的树表示和树搜索。在这样的解码树中,从根节点到叶节点的每一路径是可能的发送信号。存在三中主要的树搜索策略:宽度优先、深度优先和最佳优先的策略。搜索树中的节点对应于由解码的符号采用的不同值且从根节点到叶节点的每一路径是可能的发送信号。
顺序解码技术考虑了成本(或度量)约束以便通过向每一当前节点分配一成本(cost)来确定解码树内的单个候选路径,例如在所接收的信号之间的欧几里德距离和在根节点和当前节点之间的路径。搜索树不再是二进制的且包含信息符号的不同的可能值。
根据“宽度优先”树搜索策略,搜索从根节点开始并在以下级别延伸其所有的子节点。针对每一探索过的节点,搜索算法成功地延伸其所有子节点直到到达叶节点为止。利用这样的方法,在给定的级别i,在移动到树的级别i-1之前,以计算所有的线性组合s(i)=(sn,sn-1,…,si)的方式而探索所有的节点(即,在宽度意义上对整个树进行搜索)。因此,“宽度优先”策略实现了对树的详尽搜索。
另一详尽树搜索策略被称为“深度优先策略”且一般在球解码器和schnorr-euchner解码器中使用,从根节点开始并探索第一个子节点sn,然后是其最接近的子节点sn-1,并继续下去直到到达叶节点s1为止。在发现该第一路径的情况下,通过返回到树中的级别2来继续搜索并探索已经探索过的节点的邻居s2。在找到所有可能的路径之后,计算其相关的累积权重,输出最短路径。
“最佳优先策略”仍然是树搜索策略,其与宽度优先策略的最优版本对应。该搜索策略是基于仅探索相比于预定权重约束具有最小权重的路径的。从根节点开始,算法探索所有的子节点sn,并通过将其保存在堆栈中的方式仅保持具有满足约束条件权重的节点。然后,生成在堆栈中顶部节点的子节点并计算其累积权重。根据其权重来搜索探索过的节点且仅保持具有最小累积权重的节点。继续该搜索直到找到叶节点,并返回最优路径s(1)=(sn,sn-1,…,s1)为止。通过仅维持与给定成本约束条件相比具有低权重的节点,减小了搜索复杂度。
堆栈解码器最初用于对通过分立的无记忆信道发送的卷积码进行解码。后来,如在“关于信息理由的ieee会议集”arulmurugan等著的2006年3月第933-953页、第52卷中的“用于树搜索解码的统一框架:重新找到顺序解码器”中所公开的,其在mimo系统中被重新找到并被适配用于ml检测。
可以在范诺解码器(r.范诺.启发式讨论概率解码.关于信息理论的ieee会议集1963年4月第9(2)64-74页)或在堆栈解码器中实现顺序解码,传送所发送信号的硬估计,即,二进制估计,如具体在“使用堆栈的快速顺序解码算法”的论文中所描述的(f.jelinek,"ibmjournalresearchdevelopment(ibm期刊研究发展)",第13卷,第675-685页,1969年11月)。
为了根据最佳优先的树搜索策略生成解码树,堆栈解码器从根节点sroot开始,并在各级别生成与所检测的符号对应的所有子节点。进一步计算每一子节点的相应权重。然后,以其权重增加的顺序将子节点存储在堆栈中,使得在堆栈顶部中的节点具有最小的度量。然后,将该堆栈重新排序,并重复相同的处理,直到叶节点到达堆栈的顶部为止。与叶节点对应的路径代表ml解决方案。从而,堆栈解码器可以根据ml标准找到距离所接收的信号最接近的向量。
堆栈解码器具有与范诺解码器(如在f.jelinek所著的于1969年11月的“ibm期刊研究发展”第13卷第675-685页中发布的论文“使用堆栈的快速顺序解码算法”所展示的)。然而,对于增加的星座图大小和较高数量的天线而言,堆栈解码技术需要较高的计算复杂度。
为了减小该复杂度,被称为球形绑定堆栈解码器(sb-堆栈)的另一解码技术已经在2008年10月发布的关于无线和移动计算的国际会议论文集第322-327页由g.r.ben-othman、r.ouertani、和a.salah在名称为“球形绑定堆栈解码器”中提出。sb-堆栈方法将堆栈搜索策略与球形解码器搜索区域结合:在以接收的点为中心的球内部寻找ml解决方案。使用该方法,sb堆栈解码器获得了比球形解码器更低的复杂度。然而,虽然sb-堆栈解码器提供了比球形解码器更低的复杂度,但是在实际的系统中其实现需要更高的存储容量。
因此,需要具有减小的解码复杂度的最优的解码树生成方法和系统。
技术实现要素:
为了解决这些和其他问题,提供了一种在通信系统中对所接收的数据信号进行解码的方法,该方法包括:
-迭代地构造解码树,解码树的每一节点与数据信号的符号的分量对应,且与度量关联,
构造解码树的步骤针对在堆栈顶部存储的树的当前节点实现以下步骤的至少一次迭代:
–根据表示所接收的数据信号的向量生成当前节点的参考子节点,
–通过从参考节点的值减去一正整数参数而根据参考子节点生成第一邻居子节点,以及通过将该正整数参数加到该参考子节点的值而根据所述参考子节点生成第二邻居子节点;
将从该参考子节点和该第一和第二邻居子节点导出的最多三个子节点存储在堆栈中,每一子节点与包含预定度量的节点信息关联地存储在堆栈中,按照增加的度量值将堆栈中的节点排序;
–从堆栈移除当前节点;
–将堆栈的顶部节点选择为新的当前节点;
–该方法进一步包括根据在堆栈中存储的节点信息确定对数据信号的估计。
在一实施例中,所接收的数据信号与通过传输信道传输的所发送的数据信号对应,传输信道与给定维数的信道矩阵关联,且qr分解先前被应用于所述信道矩阵,其中q代表正交矩阵,且r代表上三角矩阵,其中所述生成参考子节点的步骤包括将表示所述所接收信号的所述向量投影到上三角矩阵的层上。
可以根据从根节点到当前节点的路径中包含的树节点的值来进一步生成参考子节点。
具体地,生成参考子节点的步骤可以包括根据数量
在某些实施例中,该方法可以包括根据在从根节点到当前节点的路径中包含的树中的节点的权重度量((w(sj))来确定与参考子节点(si)关联的度量(fi(si))。
具体地,与所述参考子节点(si)关联的所述度量是由根据在从所述根节点到所述当前节点的路径中包含的树中的节点的所述权重度量
或者,与所述参考子节点(si)关联的度量是由根据在从所述根节点到所述当前节点的路径中包含的树中的节点的所述权重度量
–在表示所接收的信号的向量
–预定义偏置参数b与级别j的乘积,偏置参数被预定义为实数且为正值。
在一实施例中,在堆栈中存储每一参数子节点的步骤还包括将辅助参数与中的每一节点关联地存储在所述堆栈中,辅助参数包括节点路径,且根据在堆栈中存储的节点路径确定对数据信号的估计。
选择顶部节点的步骤可以进一步包括确定在堆栈中选择的节点是否是叶节点且其中该方法包括;
–如所选择的节点不是叶节点,则执行下一次迭代,以及
–如果所选择的节点是叶节点,则终止迭代。
或者,选择顶部节点的步骤可以包括确定在堆栈中选择的节点是否为叶节点,该方法包括;
–如果所选择的节点不是叶节点,则执行下一次迭代,且
–如果所选择的节点是叶节点,则:
从堆栈移除叶节点,
将叶节点存储在辅助堆栈中,
进一步根据辅助堆栈执行对数据信号的估计。
在某些实施例中,树中每一节点的值可以与属于具有在最小阈值与最大阈值之间的预定义范围的给定星座图的符号的分量对应,且生成子节点的步骤可以包括确定所生成的最接近子节点的值的整数包含在该最小阈值和最大阈值之间,该方法进一步包括,针对三个所生成的子节点中的至少一个:
–如果所生成的最接近子节点的值的整数包含在该最小阈值和最大阈值之间,则将子节点设置成星座图范围内最接近的整数值。
此外,该方法可以包括:
–如果所生成的最接近子节点的值的整数低于在预定义的最小阈值,则将子节点值设置成等于最小的阈值;
–如果所生成的最接近子节点的值的整数高于最大阈值,则将子节点值设置成等于最大阈值。
在一应用中,通信系统可以是多天线系统且传输信道可以与给定维数维数的信道矩阵h关联,所接收的数据信号yc等于hcsc+wc,其中hc、sc和wc分别与信道矩阵h的复数值、表示所发送的数据信号的向量s的复数值、和噪声向量w的复数值对应。然后,可以所接收的数据信号先前被变形成实数值的表示,通过以下方程来定义该表示:
其中,
还提供了一种用于将所接收的信号解码的计算机程序产品,该计算机程序产品包括:
非暂时性计算机可读存储介质;以及
存储在非暂时性计算机可读存储介质上的指令,当其由处理器执行时,使得处理器:
-迭代地构造解码树,解码树的每一节点与数据信号的符号的分量对应,且与度量关联,
构造解码树的步骤针对在堆栈顶部存储的树的当前节点实现以下步骤的至少一次迭代:
–根据表示所接收的数据信号的向量生成当前节点的参考子节点,
–通过从参考节点的值(si)减去一正整数参数(p)而根据参考子节点(si)生成第一邻居子节点,以及通过将该正整数参数(p)加到该参考子节点的值(si)而根据所述参考子节点(si)生成第二邻居子节点;
-将从该参考子节点和从该第一和第二邻居子节点导出的最多三个子节点存储在堆栈中,将每一子节点与包含预定度量的节点信息关联地存所述储在堆栈中,按照增加的度量值将堆栈中的节点排序;
–从堆栈移除当前节点;
–将堆栈的顶部节点选择为新的当前节点;
进一步使得该处理器根据在堆栈中存储的节点信息确定对数据信号的估计。
提供了一种用于将所接收的信号解码的设备,该设备包括:
–至少一个处理器;以及
–存储器,其耦合到至少一个处理器并包括指令,其中,当由至少一个处理器执行上述指令时,使得设备迭代地构造解码树,解码树的每一节点与数据信号的符号的分量对应,且与度量关联,其中构造解码树的步骤针对在堆栈顶部存储的当前节点实现以下步骤的至少一次迭代
–通过从参考节点的值(si)减去一正整数参数(p)而根据参考子节点(si)生成第一邻居子节点,以及通过将该正整数参数(p)加到该参考子节点的值(si)而根据所述参考子节点(si)生成第二邻居子节点;
-将从该参考子节点和从该第一和第二邻居子节点导出的最多三个子节点存储在堆栈中,每一子节点与包含预定度量的节点信息地存储在堆栈中,按照增加的度量值而将堆栈中的节点排序;
–从堆栈移除当前节点;
–将堆栈的顶部节点选择为新的当前节点;
进一步使得该设备根据在堆栈中存储的节点信息确定对数据信号的估计。
从而,本发明的各个实施例允许在访问减少数目的节点时动态地横穿解码树。
因此,可以针对诸如mimo系统之类的线性信道实现低复杂度顺序解码。
从而,本发明的各个实施例允许动态地穿过解码树而访问减少数目的节点。
因此,可以针对诸如mimo系统之类的线性信道实现低复杂度顺序解码。
附图说明
在本申请中并入的附图构成了本说明书的一部分且示出了本发明的各个实施例,其结合具体实施方式来解释本发明的实施例。
–图1是根据本发明的某些实施例描绘解码树生成方法的流程图;
–图2是根据某些实施例的描绘确定在树的给定级别的参考子节点的步骤的流程图;
–图3是根据某些实施例的描绘确定在树的给定级别生成的参考节点的两个邻居子节点的步骤的流程图;
–图4示出了利用四维点阵解码树生成方法获得的搜索区域的示例性减小;
-图5示意性地表示了实现解码方法的示例性系统;
-图6示意性地示出了实现本发明的特定实施例的解码器的架构示例;
-图7和8是根据某些实施例的示出利用锯齿形堆栈解码器获得的总复杂度的图;以及
-图9和10根据某些实施例示出了从锯齿形堆栈解码器的仿真获得的数字结果,其中基于偏置参数来确定每一生成的子节点的度量。
具体实施方式
根据本发明的各个实施方式,提供了一种用于根据所接收的信号生成解码树的解码树生成方法和系统,其中根据最佳优先的搜索策略,从根节点到叶节点的每一路径表示可能的发送信号。可以根据最佳优先树搜索策略在解码设备中使用这样的解码树(下文中也称为“锯齿形堆栈解码器”),从而根据最大可能性(ml)标准来确定与所接收的信号最接近的向量。
解码树生成方法是基于在解码树(在下文中也被称为“搜索树”)的每一级别生成与所接收的信号对应的节点的减小集。对于增加的星座图大小和较高数量的天线,传统的堆栈解码器需要较高的计算复杂度(如在“使用堆栈的快速顺序解码算法”或“针对树搜索解码的统一框架:恢复顺序解码器”中所描述的)。根据本发明的各个实施例的树解码生成方法通过将针对每一电流节点生成的子节点的数目减小至最多三个节点来显著地减小这样的计算的复杂度。
为了获得解码树结构,解码树构造方法针对正在被处理的每一当前节点迭代地产生一组最多三个子节点,在每一次迭代中当前节点被选择作为堆栈的最高节点,并在堆栈中存储所生成的子节点。针对每一生成的子节点,可以进一步计算表示子节点成本的度量,且将该度量与子节点一起存储在堆栈中。
更具体地,解码树生成方法可以基于从所接收到向量到由信道生矩阵定义的超平面的欧几里德距离,来针对正由第一计算的“参考”子节点sn(与指定在级别i=n处的“迫零-决策反馈均衡器”点的zf-dfe点对应)来生成该组三个子节点,以及根据该参考子节点sn,通过以锯齿形围绕参考节点而确定最多两个邻居节点。
在下文对本发明的各个实施例的描述中,节点si(级别i)的子节点将被称为分量si-1(级别i-1)。根据各个实施例的解码树构造方法仅在树的每一级别处存储三个节点,包括与所接收到向量在相应的超平面(si)上的投影对应的节点和通过以锯齿形围绕参考节点si所确定的两个邻居节点(s’i=si–p和s”i=si+p),而不是如由传统的堆栈解码器所做的,在每一个树级别i存储与所接收的向量(例如,在2nqam(正交调幅)中的n个星座图点)对应的所有星座图点。考虑到经解码的符号的整型性质,分量si采用整数值且锯齿方法是基于通过从参考节点减去正参数p和/或将正参数p添加到参考节点的值来选择两个邻居的。
如在本申请中所使用的,“节点”指的是解码树数据结构的元素,其表示与诸如2qqam之类的星座图对应的接收信号的星座图点。具体地,节点包括表示所接收的数据信号的符号的分量的整数值(可以根据实值表示来表示所接收的数据信号)。在以下描述中,术语“节点”或“节点值”将类似地用于指定所接收的数据信号的符号的分量。树的第一个节点称为根节点。根据解码树生成方法,解码树的每一节点可以具有最多三个在树中位于其下的子节点,而传统的方法针对每一节点生成多个分支,或以预定的间隔选择多个子节点。没有任何子节点的节点称为“叶”节点且与树中的最低级别对应。每一节点具有最多一个在树中位于其上的父节点。根节点是树中的最高节点,其没有任何父节点。给定节点的深度(或宽度)指定了从该给定节点到解码树的根节点的路径的长度。从根节点可以到达解码树的所有节点。从而,从根节点到叶节点的每一路径表示可能的发送信号。在解码树中的节点表示符号si的不同的可能值,其中si表示所发送的信息向量的实分量和虚分量,其中i表示从n到1的整数。
参考图1,现在将描述根据某些实施例的通过解码树生成方法实现的主要步骤。解码树可以用于对所接收的数据信号进行解码,与由与信道矩阵h关联的传输信号传输的所发送的数据信号对应。
搜索树(在下文中也称为“解码树”)可以通过在预解码阶段对信道矩阵h(h=qr)的qr分解并通过将所接收的信号乘以qt来生成,其中qt表示正交阵,且r表示在解码等价系统中的生成矩阵。给定矩阵r的上三角结构,通过基于解码树的生成执行树搜索来解决ml优化问题。
解码树的生成针对在堆栈中存储的树的当前节点实现了对以下步骤的至少一次迭代。该方法首先以根节点为当前节点开始。从而,第一个当前节点是根节点(步骤101)。
针对从堆栈的顶部选择的每一当前节点,迭代步骤102至114以生成三个子节点,对于这三个子节点而言,当前节点是父节点。从而,每一次迭代与解码树的级别i(i=n至1)关联。根据在堆栈中选择的顶部节点,针对每一次新的迭代,参数i可以递减。
从而,实现解码树方法的第一次迭代以确定在第一级别i=n处根节点sroot的子节点{sn,s’n,s”n}。
实现解码树方法的随后的迭代以确定在与堆栈中的顶部节点对应的当前节点的级别i处最多三个子节点{si,s’i,s”i},其中si与参考子节点对应,且s’i和s”i与第一和第二相邻的子节点对应。
在步骤102中,根据表示所接收的数据信号的所接收的向量
应该注意的是,针对第一个级别i=n获得的参考子节点与zf-dfe点的第n个分量对应(zf-dfe是“迫零决策反馈均衡器的缩写”)。
在步骤103中,确定与所接收的向量
在步骤104中,根据预定的标准计算与节点si关联的度量fi(si)(该度量也称为“成本”)。在某些实施例中,可以根据欧几里德距离di计算度量fi(si)。更具体地,可以根据关联到分支(si+1,si)的权重度量
在步骤105中,节点si与度量fi(si)相关联地存储在堆栈中。与节点相关的另外的信息可以与每一节点相关联地存储在堆栈中。这样的节点信息可以包括例如与节点相关的辅助参数,例如在解码树中的节点路径和/或节点路径,和/或针对该节点确定的欧几里德距离。
第一和第二邻居子节点s’i=si–p和s”i=si+p(p表示预定义的整数值)可以通过在步骤106中利用锯齿形围绕参考节点si来确定。
在步骤107中,计算与节点s’i关联的度量fi(s’i)和与邻居节点s”i关联的度量fi(s”i)。
在步骤108中,在堆栈中存储邻居节点s’i和邻居节点s”i,其各自与其相应的度量fi(s’i)和fi(s”i)关联,且可能与另外的节点信息(例如,节点路径)关联。
在步骤109中,从堆栈移除当前节点。
在步骤110中,按照度量fk(sk)的增序对堆栈重新排序,以便在堆栈的顶部存储具有最低度量fi(si)的节点si。
在步骤111中,选择堆栈的顶部节点作为当前节点,以便生成其子节点。
在步骤112中,确定所选择的节点是否为叶节点。如果所选择的节点是叶节点(即,没有任何子节点),则该方法在步骤113终止。
否则,在步骤114中,将所选择的节点设置为当前节点,且可以针对新选择的节点(其表示在堆栈中具有最低度量的节点)可以重复步骤102至114,以在解码树的下一个级别j生成包括参考节点sj和两个相邻子节点s’j=sj-p和s”j=sj–p的三个子节点,其中j包含在n-1到1之间。下一个被处理的级别j取决于在堆栈中选择的顶部节点。
从而,步骤102至114的每一次迭代在堆栈中存储的根节点和新的叶节点之间提供路径。
然后,可以通过将在堆栈中存储的节点信息考虑在内来估计数据信号,上述节点信息尤其是在堆栈中存储的路径,当这样的信息。例如,根据二进制估计(硬决策),树的构造实现了步骤102至114的单次迭代,这使得能够确定与所发送数的据信号的硬估计对应的单个路径。在似然估计的情况下(软决策),解码方法可以以对数似然比(llr)值的形式传送软输出信息。在此情况下,可以执行步骤102至114的若干迭代。每一次重复传递从根节点到叶节点的不同路径。然后,可以将这些不同的路径与它们的路径一起存储在辅助堆栈中。然后,可以基于这些路径确定对信息信号的似然估计。
从而,解码树方法使得能够实现对解码树的锯齿形构造,这极大地减小了解码的复杂度。构造解码树以将节点的度量以及可能的辅助参数存储在堆栈中,这在每次节点被访问时消除了重新计算与节点相关的度量的需要。
因此,减小了搜索区域和在搜索树中节点的数量。
即使将本发明限制在这样的应用,当集成到接收机中时,本发明具有特定的优点,例如,对于在mimo(多输入多输出)信道中发送的数据解码或对于多个用户的检测。
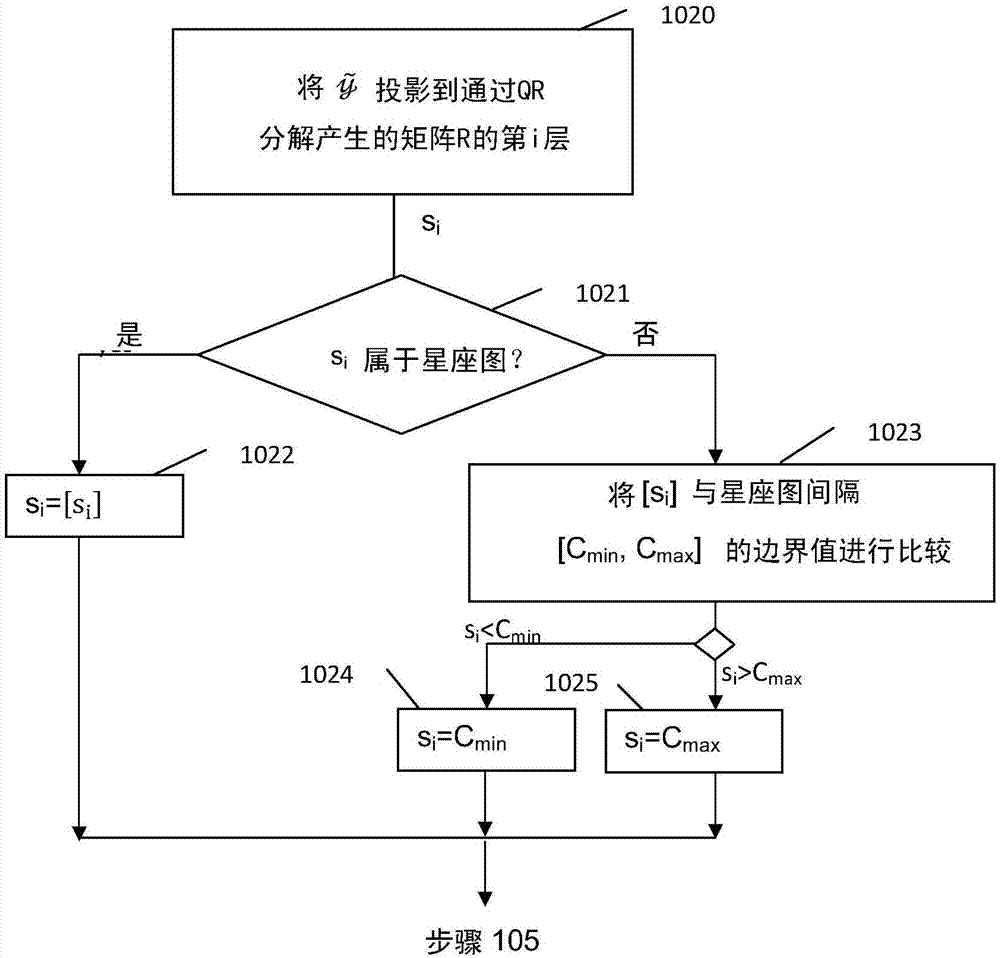
图2是描绘在树的给定级别i处确定参考子节点si(图2的步骤102)的步骤。
在步骤1020,可以通过执行所接收的向量
在某些实施例中,可以通过执行所接收的向量
此外,参考子节点的生成可以将包含在从根节点sn到当前节点si的路径中的三个节点的值考虑在内。
具体地,对于i=n(与在级别n处的子节点的生成对应的步骤102至114的第一次迭代),可以根据方程(1)确定在级别n处的第一个分量sn:
在方程(1)中,rnn表示上三角阵r的第n层(超平面),
对于解码树生成方法在级别i=n-1,…,1处的随后的迭代,可以生成分量si使得:
因此,根据与父节点和堆栈中的当前顶端节点对应的分量sn的值而计算分量sn-1。应该注意的是,由于根据节点的度量对节点进行排序,所以所选择的顶端节点可能不与zf-dfe点对应,因此,所生成的符号sn-1可能不一定与zf-dfe点的第n-1个分量对应。
解码方法可以适用于解码有限或无限的
在这样的实施例中,为了保证所估计的向量属于所考虑的星座图,在步骤1021中,每次生成子节点时(参考节点si或两个邻居节点s’i和s”i),检查与距离如在步骤1020中获得的符号si([si])最接近的整数相关的以及与边界约束cmin和cmax相关的条件。
具体地,在步骤1021中,确定如在步骤1020中确定的符号si是否属于该星座图。如果符号si属于该星座图(即cmin≤[si]≤cmax),则在步骤1022中将参考子节点si设置成离符号si(即[si])最接近的整数。
否则,如果符号si不属于该星座图(步骤1021),则在步骤1023中,将离符号[si]最接近的整数与星座图间隔[cmin,cmax]的边界值进行比较:
-如果[si]<cmin,则在步骤1024中,将参考子节点si设置成cmin;
-如果[si]>cmax,则在步骤1025中,将参考子节点si设置成cmax。
图3是根据其中星座图是有限的实施例,描绘了根据参考节点si确定邻居子节点s’i和s”i(图1的步骤106)的步骤的流程图。
在步骤1060中,根据符号si确定符号s’i=si-p和s”i=si+p,其中p指定了预定义的整数参数(也称为“锯齿”参数)。
应该注意的是,在某些应用中,可以允许“锯齿”参数p以预定的方式变化且可以根据树中的级别、和/或迭代步骤、和/或根据在通信系统中利用的不同自由度,例如空间、时间或频率而采用不同的值。
在某些实施例中,可以将参数p设置成1。这使得能够在接收机侧执行对所接收的信号的重塑(reshape),以能够执行
然而,本发明不限于参数p等于1。根据本发明的应用,可以将参数p设置成其他值。例如,如果在接收机侧不需要重塑,则路径p可以优于1(从而访问相邻的节点)。
在步骤1061中,对于符号si–p(相应地si+p),通过确定离符号[si-p](相应地[si+p])最接近的整数是否包含在cmin和cmax之间,确定si-p(相应地si+p)是否属于星座图。如果符号si-p(相应地si+p)属于星座图(步骤1062),则在步骤1062中,将子邻居节点s’i(相应地s”i)设置成符号si-p(分别地si+p)。
否则,如果符号si-p(相应地si+p)不属于星座图(步骤1063),则将符号si-p(分别地si+p)与星座图间隔[cmin,cmax]的边界值进行比较,如如下所示:
–如果[si-p]<cmin(相应地[si+p]<cmin),则在步骤1064中将参考子节点si-p(相应地si+p)设置成cmin。
–如果[si-p]>cmax(相应地[si+p]>cmax),则在步骤1065中将参考子节点si-p(分别地si+p)设置成cmax。
在将本发明应用到多天线系统以对通过多天线系统(mimo)接收的信号解码的情况下,其中nt个发射和nr个接收天线使用空间复用,被接收为复值向量的数据信号yc等于hcsc+wc,其中hc、sc和wc分别与信道矩阵h的复值对应,表示所发送的数据信号的向量s和噪声向量w。然后,可以将所接收的信号yc变形为实值表示,例如根据方程(3):
在方程(3)中,
y=hs+w(4)
在使用长度t空间-时间码的实施例中,可以以方程(1)的相同形式来写信道输出,其中通过下式给出等价信道矩阵heq:
heq=hcφ(5)
在方程(5)中,
根据(5)中获得的等价系统,可以将所接收的信号视作由h生成的且被噪声向量w扰乱的点阵的点。针对在根据最小化问题通过h生成的n维点阵中的最接近向量解决最佳ml检测:
在这样的mimo系统中,可以基于根据解码树生成方法在锯齿堆栈解码器中生成的解码树来执行树搜索。在向锯齿堆栈解码器发送信号之前,可以使用信道矩阵的qr分解来执行预编码,使得h=qr,其中q代表正交矩阵,且r代表上三角阵。在给定了q的正交的情况下,可以以下列形式重写方程(4):
然后,ml解码问题实际上为解决由下式给出的等价系统:
应该注意的是,r的三角结构,由此,将对最接近点的搜索减小到了如在图4的与4维点阵的树搜索对应的示例中描绘的顺序树搜索,即对于nt=nr=2。
在图4的示例中,树中的节点代表符号si的不同的可能值。符号si,其中i=1,…,n,表示信息向量sc的实分量和虚分量。利用两个连续的节点(si+1;si)来表示树分支。
在某些实施例中,在步骤104中,可以根据在从根节点sn到当前节点si的路径中包含的树节点的权重度量
具体地,与级别i处的参考子节点(si)(第i个解码符号)关联的度量可以被确定为累积的权重
由于节点si的累积权重
根据方程(10),可以将在树的级别j处的节点的权重度量
因此,对于节点si,可以将累积权重cw(si)确定为:
对于叶节点,累积权重cw(s1)对应于在所接收信的号
在这样的实施例中,方程(8)的ml度量最小化相当于在树中搜索具有最小累积权重的路径。
在可供替换的实施例中,可以通过将偏置参数b考虑在内来确定累积权重函数cw(si),其中b具有正实值
因此,在该可供替换的参数化方法中,可以将针对节点si的累积权重cw(si)确定为:
特别地,偏置b等于0(b=0)的应用提供了ml解决方案。可以任意地或根据方程(11)的信道方差σ2来确定偏置参数的值,如在“针对编码的mimo信道的点阵顺序解码器:性能和复杂度分析”.w.abediseid和mohamedoussamadamen.corrabs/1101.0339(2011)中描述的:
解码搜索树的这样的参数化的实施例使得能够通过考虑将偏置参数b考虑到权重函数中来获得较宽范围的解码性能(从而复杂度)。特别地,对于大于10的偏置参数的值,解码器提供了与zf-dfe检测器相同的误差性能,同时需要更低复杂度。
在软输出解码器中,可以应用解码树生成方法来执行软决策。例如,在mimo系统中的软输出解码取决于使用对数似然比(llr)值形式的后验概率技术来传递软信息。为了使解码树生成方法适应软输出检测,除了现有的主堆栈之外,还可以进一步使用第二固定大小的堆栈。当叶节点到达原始堆栈的顶部时,该方法可以返回ml解决方案并继续其处理。每次当叶节点到达堆栈的顶部时,可以将该节点存储在第二堆栈中。然后,可以使用所获得的近ml解决方案与ml方案一起来生成针对软输出检测的llr值。
虽然不限于这样的应用,但是当应用于mimo检测时,本发明具有特别的优点。实际上,可以实现锯齿堆栈解码器联合到信道输出的并行化,以便可以在通过将信道输出和所检测的符号的实部和虚部分开而获得的两个独立的子系统上同时执行根据本发明各个实施例的解码方法的步骤。此外,在这样的mimo应用中,可以实现将锯齿解码器联合到应用于诸如排序和点阵减小之类的信道矩阵的预处理技术。
mimo无线网络包括多个站,每一站包括包含如在图5中描绘的一个或多个天线的发射机和接收机。每一站可以通过无线连接与其他站通信。
mimo无线网络1可以在传输时使用空间/时间码来在信道的各个自由度上分配调制符号。
发送机2可以通过噪声mimo信道的方式向接收机3发送信号。具体地,数据发送机2可以集成到站中。发送机2可以包括例如:
–用于提供卷积码的信道编码器20,
–用于递送符号的qam调制器21;
–用于递送码字的空间/时间编码器22;
–ntx传输天线23,其中每一传输天线可以与ofdm调制器关联。
发送机2使用由信道编码器20提供的卷积码对作为输入接收到二进制信号进行编码。然后,由调制器21根据调制方案(例如,正交调幅nqam)对该信号进行调制。调制器21还可以通过相移实现调制方案,例如npsk类型的或任何调制。该调制使得生成属于一组符号si的复数符号。从而,获得经调制的符号,并然后通过空时编码器22编码以形成码字stbc,例如黄金编码(“黄金编码:利用非零决定因素的2x2全速率空时编码”,j.-c.belfiore,g.rekaya,e.viterbo,关于信息理论的ieee会议集,第51卷,第4期,第1432-1436页,2005年4月)。stbc码可以基于维数为ntx*t的复数矩阵,其中ntx是传输天线的数目且t是stbc码的时间长度,或基于空间复用(经调制的符号被直接发送到传输天线)。
从而,将所生成的码字从时域转换成频域并在ntx传输天线上分发。然后,利用相应的ofdm调制器对每一专用信号进行调制,然后通过相应的传输天线23发送,可选地,在滤波、频移和放大之后。
接收机3还可以集成到站中。接收机3可以被配置成接收在无线信道中由发送机2发送到信号y。该信道可以是嘈杂的(例如,具有遭受衰减的附加白高斯噪声(awgn)的信道。由发送机2发送到信号可以进一步受到由于多路径和/或多普勒效应导致的回声的影响。
在一个示例性的实施例中,接收机3可以包括:
–用于接收信号y的nrx个接收天线33,每一接收天线与相应的ofdm解调器关联;ofdm解调器(nrx个解调器)被配置成:将在每一接收天线观测到的所接收信号的解调并传递经解调的信号。频率/时间转换器可以用于执行传输中实现的时间/频率转换的逆操作,以及在频域传递信号;
–被配置成传递解码信号的空间/时间解码器30;
–被配置成执行与解码关联的解调的解调器31。
应该要注意的是:接收机3实现在传输中实现的处理的逆处理。因此,如果在传输中实现了单载波调制而不是多载波调制,则利用相应的单载波解调器来替代nrxofdm解调器。
本领域的技术人员容易理解本发明的各实施例受具体应用的限制。该新解码器的示例性应用包括而不限于多用户通信系统、在可于诸如wifi(ieee802.11n)、蜂窝wimax(ieee802.16e)、合作性wimax(ieee802.16j)、长期演进(lte)、先进的lte、进行中的5g标准化、以及光学通信之类的无线标准中实现的配置中进行mimo解码。
图6表示接收机3的空间/时间解码器30的示例性架构。如所示出的,时间/空间解码器30可以包括以下元素,其通过数据和地址总线64链接在一起:
–微处理器61(或cpu),其例如是数字信号处理器(dsp);
–非易失性存储器62(或rom、只读存储器);
–随机存取存储器ram63;
–接口65,用于接收来自时间/频率转换器的输入信号;
–接口66,用于向解调器31发送解码的数据。
非易失性rom存储器62可以包括,例如:
–寄存器“prog”620;
–偏置参数“b”621。
–锯齿参数“p”622。
用于实现根据本发明该实施例的方法的算法可以存储在程序620中。cpu处理器41可以被配置成将程序620下载到ram存储器并运行相应的指令。
ram存储器63可以包括:
–在寄存器630中,该程序由微处理器61运行并在空间/时间解码器30的活动模式下被下载;
–将数据输入到寄存器631中;
–寄存器632中与节点相关的数据与堆栈对应;
–在寄存器634中的似然估计或llr;
–在寄存器632中存储的数据可以包括,对解码树的节点而言,与该节点关联的度量和可选地辅助度量(从根本到所述节点的路径,和/或树中的深度)。
根据另一实施例,可以根据仅硬件配置(例如,在一个或多个具有相应存储器的fpga、asic、或vlsi集成电路)或根据使用vlsi和dsp的配置来实现解码技术。
通过仿真已经观察到,基于由根据本发明各个实施例的解码树构造方法生成的解码树的解码器(被称为“锯齿堆栈解码器”),提供了与顺序解码器、堆栈解码器和sb-堆栈解码器类似的ml性能。为了评估这样的解码器的计算复杂度,已经计算了用于预解码和搜索阶段的总的乘法次数。已经在仿真中使用了16-qam和2x2和4x4mimo方案。图7和8示出了所获得的性能,并具体示出了相对于现有解码器而言,由该解码器提供的显著的复杂度增益。对于nt=nr=2,改进的顺序解码器相对于传统的堆栈解码器提供了46%平均复杂度增益,且当nt=nr=4时,至少50%。
图9和10表示从对锯齿堆栈解码器的仿真获得的数字结果,在本发明的某些实施例中,其中基于偏置参数b确定每一生成的子节点的度量。数字结果是基于针对偏置参数b的不同值而评估符号误差率和总复杂度的。如在图7和8中描绘的,小的偏置b的值允许获得近ml性能,对于b=0,达到ml性能。当偏置增加时,以具有更差的ser性能的代价减小复杂度。对于b≥10,锯齿堆栈以高度减小的复杂度返回到zf-dfe性能。
虽然已经通过对多个示例的描述描绘了本发明的实施例,且虽然已经以可观的细节描述了这些实施例,但是申请人的意图不在于约束或在任何方面将所附权利要求的范围限制到这样的细节。对于本领域的技术人员而言,容易看到另外的优点和修改。从而,在其更广的方面,本发明不受限于所示出和描述的具体细节、代表性的方法和示例性的示例。因此,可以在不偏离申请人的一般发明概念的精神和范围的情况下,偏离这样的细节。
具体地,根据本发明的各个实施例不受限于具体的检查类型,且应用于硬和软检查。
此外,可以基于应用或软件组件来标识本申请中描述的程序代码,在上述应用或软件组件中,在本发明的特定实施例中实现上述程序代码。进一步应该理解的是,本申请中公开的各个特征、应用和设备还可以单独使用或以任何结合使用。
- 还没有人留言评论。精彩留言会获得点赞!