一种应用于宽带接入网的业务识别方法与流程
本发明属于宽带接入网技术领域,更为具体地讲,涉及一种应用于宽带接入网的业务识别方法。
背景技术:
随着宽带接入网技术的不断发展,宽带光纤接入网技术以其可用带宽大、信号质量好、支持宽带业务等优势成为目前的热门技术之一。其中PON(Passive Optical Network,无源光网络)技术因拓扑结构简单,维护费用低等特点成为当今接入网技术的主流。PON接入网技术由于带宽升级的压力,其网络设备的处理能力在短短的几年内,从1Gbps、2.5Gbps发展到了现今的10Gbps,甚至在今后几年有向40Gbps和100Gbps发展的趋势。
据中国互联网信息中心2015年的报告“第36次中国互联网发展状况调查报告[R].中国:CNNIC,2015.”显示,截至2015年6月,中国网民规模达6.68亿且互联网为用户提供的业务不断丰富,除了传统的电话、网页浏览、电子邮件等业务外还有一系列高速率、高质量业务如VoIP业务、即时通信类业务、P2P(Peer-to-Peer,点对点技术)业务、流媒体业务、网络游戏业务、网上购物、电子商务等。而以P2P下载为代表的新业务流量已经占据了整个互联网流量的70%以上,P2P业务以及各种各样的视频类业务占据了大量的带宽。
在论文“田辉,徐鹏.业务识别与控制技术及标准化进展[J].电信网技术,2007,(3):12-15”中总结了已有业务识别与控制的技术原理和缺陷,并介绍了国内外的标准化及产业推动状况。从不同应用角色看,政府、运营商、企业以及家庭用户对网络的业务控制能力提出了各自的要求:
(1)从监管者角度来说,要求网络具备不良信息的识别和控制的能力,尤其是对反动、色情、赌博、暴力等不良信息的过滤。
(2)从运营商角度来说,要求网络能够精细化运营,提供差异化的服务能力,尤其是有效遏制不良流量对网络的影响,保障电信级业务的服务质量。
(3)从企业用户角度来说,要求网络具备识别特定业务信息,并按照企业利益对信息进行处理的能力,整合复杂的IT防范设备,使得企业专注与核心业务。
(4)从家庭用户来说,结合健康上网的需求,要求网络具备个性化业务控制功能,尤其是对不良网站的屏蔽和网络游戏沉洒的防止。
所以,在宽带接入网中加入业务识别具有重要意义,在论文“陈卫,任斌,赖树明.10G EPON宽带接入网中业务识别的设计和实现[J].光通信技术,2012,6(12):16-18”和“庄稼.支持深度业务识别的10G EPON系统设计与核心模块的FPGA设计实现[D].北京:北京邮电大学,2014.”这两篇论文中讨论了业务识别在10G EPON宽带接入网中的硬件实现。
然而,传统的DPI(深度包检测,Deep Packet Inspection)业务识别技术,主要依靠前期对业务的特征字段的手工提取,才能维持准确率,虽然该方法有效,但前期的准备工作和后期的更新维护太过于费时费力。随后兴起的DFI(深度流检测,Deep Flow Inspection)业务识别技术,依靠大量提取的流特征来进一步筛选,使用传统的机器学习分类算法,大量的论文和实验证明了方法的有效性,但这种依靠经验的流特征选取方法可能会没有提取到或者丢掉不少关键特征,使得它的适应性和可移植性大打折扣,而且其分类的精细度还太过于粗颗粒,难以适应精细化的识别场景。
技术实现要素:
本发明的目的在于克服现有技术的不足,提供一种应用于宽带接入网的业务识别方法,引入深度学习中的卷积神经网络算法,实现细粒度、高精度业务识别。
为实现上述发明目的,本发明应用于宽带接入网的业务识别方法包括以下步骤:
S1:从宽带接入网不同业务的若干数据帧中筛选得到TCP和UDP协议对应的数据帧;
S2:对步骤S1筛选得到的所有数据帧,从每个数据帧中提出得到源IP地址、目的IP地址、协议类型、源端口、目的端口,构建该数据帧对应的五元组数据;
S3:根据五元组数据对数据帧进行业务流划分,建立业务流流池群,其具体方法为:依次提取出数据帧,如果该数据帧为上行数据帧,则将其五元组数据与每个业务流流池中上行业务流流池的五元组数据进行匹配,如果与某个上行业务流流池的五元组数据相同,则将该数据帧划入对应的上行业务流流池中,如果所有上行业务流流池的五元组数据都不同,则新建一个业务流流池,将该数据帧划入新建业务流流池的上行业务流流池中;如果该数据帧为下行数据帧,则将其五元组数据与每个业务流流池中下行业务流流池的五元组数据进行匹配,如果与某个下行业务流流池的五元组数据相同,则将该数据帧划入对应的下行业务流流池中,如果所有下行业务流流池的五元组数据都不同,则新建一个业务流流池,将该数据帧划入新建业务流流池的下行业务流流池中;
S4:对于业务流流池群中每个业务流流池中的每个数据帧,提取得到其IP数据包,如果该数据包字节数小于A,在数据包末尾添零至字节数A,替换原有数据帧,否则直接以该数据包替换原有数据帧;其中A大于等于IP数据包的最大长度;
S5:对业务流流池群中的每个业务流流池添加业务类别标签;
S6:构建集成卷积神经网络,包括上行一维卷积神经网络、下行一维卷积神经网络、交互一维卷积神经网络和仲裁模块,其中上行一维卷积神经网络用于对上行业务流数据包进行业务识别,下行一维卷积神经网络用于对下行业务流数据包进行业务识别,交互一维卷积神经网络用于上行、下行业务流数据包进行业务识别,仲裁模块对三个一维卷积神经网络的识别结果进行联合仲裁;每个一维卷积神经网络中,其输入层包括A个神经元,输入层、每级隐层的特征图和核均为一维结构;
S7:采用业务流流池群对集成卷积神经网络中的三个一维卷积神经网络进行分别训练,其中上行一维卷积神经网络的训练输入为业务流流池群中的每条上行业务流数据包,其期望输出为对应的业务类别标签;下行一维卷积神经网络的训练输入为业务流流池群中的每条下行业务流数据包,其期望输出为对应的业务类别标签;交互一维卷积神经网络的训练输入为业务流流池群中的每条上行业务流数据包和下行业务流数据包,其期望输出为对应的业务类别标签;
S8:在宽带接入网实际运行时,捕获得到一段TCP或UDP业务流数据帧,从该业务流中每个数据帧中提取出数据包,末尾添零至长度为A字节的业务流数据包,将这些业务流数据包划分为上行业务流数据包和下行业务流数据包,输入集成卷积神经网络中的对应一维卷积神经网络,仲裁模块根据三个一维卷积神经网络的业务识别结果综合仲裁得到最终业务识别结果,仲裁方法为:仲裁模块收集三个一维卷积神经网络的识别结果进行联合仲裁,先分别对每个一维卷积神经网络的识别结果进行统计,选择每个一维卷积神经网络中数量占该一维卷积神经网络所有识别结果数量的百分比最大的识别结果作为该一维卷积神经网络的有效识别结果;在三个有效识别结果中,如果任意两个一维卷积神经网络的有效识别结果一致时,将此有效识别结果作为最终的识别结果,否则选择百分比最大的有效识别结果作为最终的识别结果。
本发明应用于宽带接入网的业务识别方法,从宽带接入网不同业务的若干数据帧中筛选得到TCP和UDP协议对应的数据帧,根据五元组数据对数据帧进行业务流划分,建立业务流流池群,每个业务流流池群包括上行业务流流池和下行业务流流池,对每个业务流流池添加业务类别标签,然后构建集成卷积神经网络,包括上行一维卷积神经网络、下行一维卷积神经网络、交互一维卷积神经网络和仲裁模块,采用业务流流池群对三个一维卷积神经网络进行分别训练;在宽带接入网实际运行时,对捕获的数据帧标准化为业务流数据包,输入卷积神经网络,得到业务识别结果。
与传统的DPI和DFI方法相比,本发明完全不需要同DPI方法那样提取数据报文的特征关键字,也不需要同DFI方法那样依靠经验提取所谓的流特征。这样一来,就能够完全消除诸如提取特征关键字和流特征的预处理难度,还能够保证不侵犯用户的隐私,同时还能实现高识别准确率、精细化的业务识别,从而提高宽带接入网系统中的业务识别性能。
附图说明
图1是本发明应用于宽带接入网的业务识别方法的具体实施方式流程图;
图2是本实施例中筛选TCP和UDP对应数据帧的流程图;
图3是以太网协议的数据帧格式图;
图4是IPv4数据包格式图;
图5是TCP数据包结构图;
图6是UDP数据包结构图;
图7是本发明中业务流流池群的建立方法流程图;
图8是本发明中集成卷积神经网络结构图;
图9是本实施例中一维卷积神经网络结构图。
具体实施方式
下面结合附图对本发明的具体实施方式进行描述,以便本领域的技术人员更好地理解本发明。需要特别提醒注意的是,在以下的描述中,当已知功能和设计的详细描述也许会淡化本发明的主要内容时,这些描述在这里将被忽略。
实施例
图1是本发明应用于宽带接入网的业务识别方法的具体实施方式流程图。如图1所示,本发明应用于宽带接入网的业务识别方法包括以下步骤:
S101:筛选TCP和UDP对应数据帧:
从宽带接入网不同业务的若干数据帧中筛选得到TCP和UDP协议对应的数据帧。
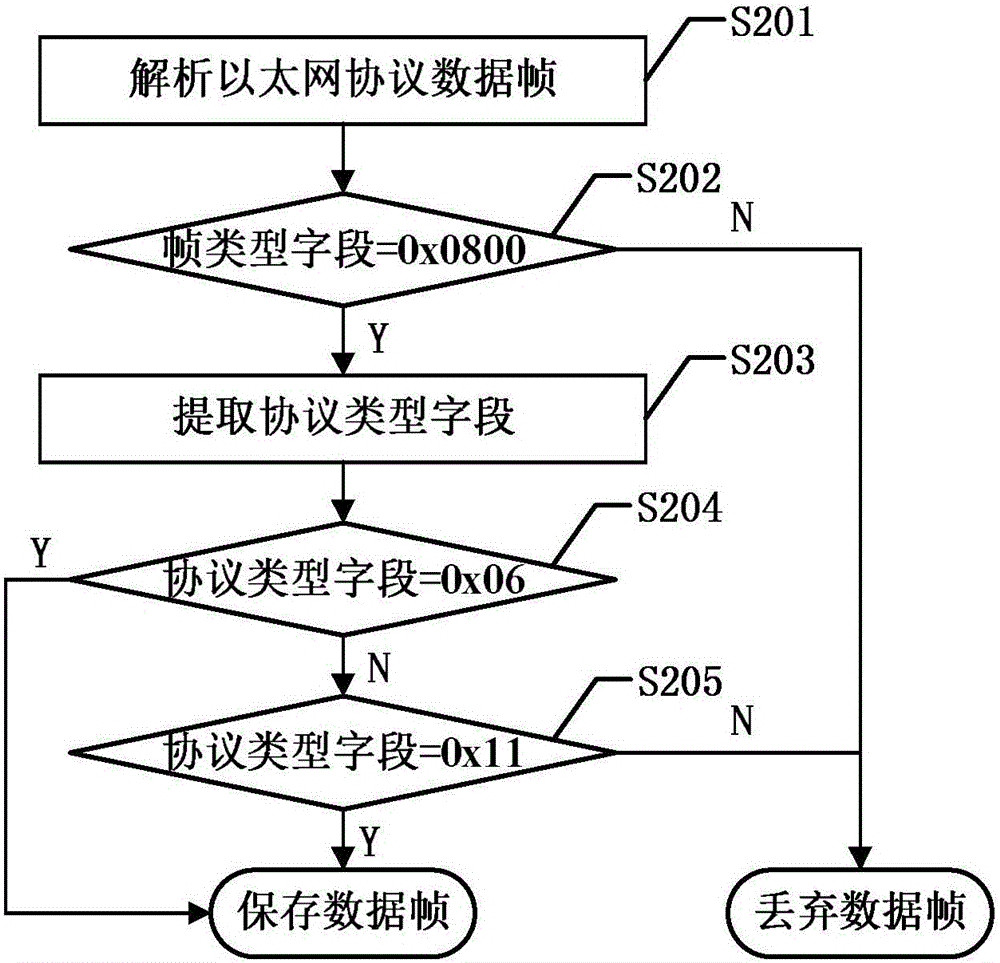
TCP和UDP协议是IP协议的上层协议,目前宽带接入网中所使用的IP协议包括IPV4和IPV6,其中最常用的是IPV4协议,因此本实施例以IPV4协议为例来说明本发明的技术方案。图2是本实施例中筛选TCP和UDP对应数据帧的流程图。如图2所示,在使用IPV4协议的宽带接入网中筛选TCP和UDP协议对应的数据帧的具体步骤包括:
S201:解析以太网协议数据帧:
获取宽带接入网的以太网协议的数据帧并进行解析,提取得到帧类型字段。图3是以太网协议的数据帧格式图。如图3所示,以太网协议数据帧由五个部分组成,分别为6个字节的源MAC地址、6个字节的目的MAC地址、2个字节的帧类型、46到1500个字节的负载数据和4个字节的帧校验序列。其中,对于2个字节的帧类型数据,0x8808代表OAM帧,0x8809代表MPCP帧,0x0806代表ARP帧,0x0836代表RARP帧,0x0800代表IPv4帧,0x08DD代表IPv6帧。
S202:判断帧类型字段是否为0x0800,如果是,则说明该数据帧为IPv4对应数据帧,保留此数据帧,进入步骤S203,否则将该数据帧丢弃,判断下一条数据帧。
S203:提取协议类型字段:
从IPv4对应数据帧中提取得到IP v4数据包,然后从IP v4数据包中提取得到协议类型字段。
图4是IPv4数据包格式图。如图4所示,IPv4数据包的协议类型字段总共1个字节,如果等于0x06则代表当前IPv4数据包的上层协议为TCP协议,且负载数据为TCP协议数据;如果等于0x11则代表当前IPv4报文的上层协议为UDP协议,且负载数据为UDP协议数据。而IPV4中还包括ICMP报文、IGMP报文等,分别对应各自的协议类型。因此,根据协议类型字段即可判定该数据帧对应的上层协议类型。
S204:判断协议类型字段是否为0x06,如果是,则说明该报文为TCP对应数据帧,保存此数据帧,否则进入步骤S205。
S205:判断协议类型字段是否为0x11,如果是,则说明该报文为UDP对应数据帧,保存此数据帧,否则将该报文丢弃,判断下一条数据帧。
采用以上步骤,就可以从宽带接入网的数据报文中提取得到TCP和UDP对应的数据帧。
S102:提取五元组数据:
一般来说,业务流的定义指的是在一段时间内具有相同五元组的报文组成的集合。五元组的定义指的是IP协议首部和TCP或者UDP首部中的源IP地址、目的IP地址、协议类型、源端口、目的端口这五个字段,即五元组={源IP地址,目的IP地址,协议类型,源端口,目的端口}。图5是TCP数据包结构图。图6是UDP数据包结构图。如图4、图5和图6所示,五元组在IP协议对应的数据帧中的位置一般来说是固定的,因此将五元组数据按照位置从步骤S101中筛选得到的TCP和UDP对应的各个数据帧中提取出来即可。
S103:建立业务流流池群:
业务流是一种双向的包含上行请求与下行应答的互动交流数据,用户向服务器发出的请求报文为上行业务流,而服务器向用户发出的应答报文为下行业务流,且上行业务流与下行业务流的五元组数据中只有源IP地址和目的IP地址相反,其他三元组相同。可见,在预设时间内,具有相同的五元组的上行IP数据报文按先后顺序汇聚成一条上行业务流,与之源IP地址和目的IP地址相反而其他三元组相同的业务流则汇聚为下行业务流,共同构成双向流集合。不同时刻捕获的五元组相同的双向业务流形成一个业务流流池,包括上行业务流池和下行业务流池。一个业务流池对应一种业务类别,且所有业务流的五元组相同。一个业务流池包含许多不同时刻收集的业务流,所有不同业务流流池构成业务流流池群。也就是说,流池群里包含许多五元组不同的流池,流池里包含五元组相同但捕获时刻不同的流。
图7是本发明中业务流流池群的建立方法流程图。如图7所示,本发明中业务流流池群的建立方法包括以下步骤:
S701:初始化参数:
初始化第1个业务流流池P1=(U1,D1),U1表示第1个业务流流池的上行业务流池,D1表示第1个业务流流池的下行业务流池,令如果第1个数据帧为上行数据帧,将第1个数据帧放入第1个上行业务流池U1,如果第1个数据帧为下行数据帧,则将第1个数据帧放入第1个下行业务流池D1。
由于上、下行帧的五元组数据之间存在对应关系,因此无论第1个数据帧是上行帧还是下行帧,U1和D1对应的五元组数据都已经确定了。
S702:令数据帧序号n=2:
S703:判断第n个数据帧是否为上行数据帧,如果是,进入步骤S704,否则进入步骤S710;
S704:令业务流池序号m=1:
S705:判断是否第n个数据帧属于上行业务流池Um,即判断第n个数据帧的五元组数据与上行业务流池Um的五元组数据相同,如果相同,则说明第n个数据帧属于上行业务流池Um,进入步骤S706,否则说明不属于,进入步骤S707。
S706:将第n个数据帧放入上行业务流池Um,进入步骤S716。
S707:判断是否m=M,M表示当前业务流池的数量,如果不是,说明还有业务流池未判断,进入步骤S708,如果是,说明现有的业务流池已经判断完毕也未找到五元组数据相同的业务流池,进入步骤S709。
S708:令m=m+1,返回步骤S705。
S709:新建业务流流池:
新建业务流流池PM+1=(UM+1,DM+1),将第n个数据帧放入上行业务流池UM+1,进入步骤S716。
S710:令业务流池序号m=1:
S711:判断是否第n个数据帧属于下行业务流池Dm,即判断第n个数据帧的五元组数据与下行业务流池Dm的五元组数据相同,如果相同,则说明第n个数据帧属于下行业务流池Dm,进入步骤S712,否则说明不属于,进入步骤S713。
S712:将第n个数据帧放入下行业务流池Dm,进入步骤S716。
S713:判断是否m=M,M表示当前业务流池的数量,如果不是,说明还有业务流池未判断,进入步骤S714,如果是,说明现有的业务流池已经判断完毕也未找到五元组数据相同的业务流池,进入步骤S715。
S714:令m=m+1,返回步骤S711。
S715:新建业务流流池:
新建业务流流池PM+1=(UM+1,DM+1),将第n个数据帧放入下行业务流池DM+1,进入步骤S716。
S716:判断是否n<N,N表示步骤S101筛选得到的数据帧总数,如果是,说明数据帧还未全部划入业务流流池,进入步骤S717,否则说明所有帧全部划入对应的业务流流池,业务流流池群建立结束。
S717:令n=n+1,返回步骤S703。
S104:标准化业务流数据:
数据帧由许多的字节构成,且每条数据帧中IP数据包的长度不一致,所以需要把业务流数据帧转换为可以被集成卷积神经网络接收的标准数据,其具体方法为:对于每个业务流流池中的每个数据帧,提取得到其IP数据包,如果该数据包字节数小于A,在数据包末尾添零至字节数A,得到标准数据包,替换原有数据报文,否则直接以该数据包替换原有数据报文。其中A大于等于IP报文字段的最大长度。以IPv4协议为例,其IP数据包在数据帧中的字节长度在[46,1500]之间,因此A≥1500。显然,采用以上方式可以使每个业务流数据包等长,从而对业务流数据进行标准化。本实施例中,设置A=1500。
S105:添加业务类别标签:
由于每个业务流流池中的数据包对应一种业务,因此对于经过步骤S104标准化处理的业务流流池群,对每个业务流流池添加业务类别标签。业务类别标签可以借助一些现有的辅助工具用人工的方式获知,由于本发明采用卷积神经网络进行业务识别,因此业务流类别标签是一个根据识别粗细度自定义比特位数的二进制数据,每一个二进制数据代表一种业务类别。
S106:构建集成卷积神经网络:
根据TCP/IP协议的有关知识,上下行数据的特征是不一样的,也就是说,上行数据有上行数据的特征,下行数据有下行数据的特征,另外需要注意的是,上行和下行是一种交互数据,也就是说上行数据和下行数据是有关联的,因此需要一种业务识别方案既能够保留这种关联性同时又能分别提取到上行业务流特征和下行业务流特征,使识别结果达到理想状态。正是基于这种需要,本发明设计了并行的集成卷积神经网络结构。
图8是本发明中集成卷积神经网络结构图。如图8所示,本发明的集成卷积神经网络包括上行一维卷积神经网络、下行一维卷积神经网络、交互一维卷积神经网络和仲裁模块,其中上行一维卷积神经网络用于对上行业务流数据包进行业务识别,下行一维卷积神经网络用于对下行业务流数据包进行业务识别,交互一维卷积神经网络用于上行、下行业务流数据包进行业务识别,仲裁模块收集三个一维卷积神经网络的识别结果进行联合仲裁,先分别对每个一维卷积神经网络的识别结果进行统计,选择每个一维卷积神经网络中数量占该一维卷积神经网络所有识别结果数量的百分比最大的识别结果作为该一维卷积神经网络的有效识别结果。在三个有效识别结果中,如果任意两个一维卷积神经网络的有效识别结果一致时,将此有效识别结果作为最终的识别结果,否则选择占对应一维卷积神经网络识别结果百分比最大的有效识别结果作为最终的识别结果。
可见,在本发明的集成卷积神经网络中,三个一维卷积神经网络是并行运行的。由于上行业务流数据包和下行业务流数据包都是采用相同的方式进行标准化,因此三个一维卷积神经网络采用相同的结构。传统的卷积神经网络针对的是图像,其输入为二维数据,而本发明所针对的业务流数据包是一维数据,如果按照传统思路,将业务流数据包转换为二维数据,由于输入数据量维度过大,传统卷积神经网络的训练需要花费大量时间,而且业务识别也并不完全等同于图像识别。因此为了提升卷积神经网络在业务识别中的应用效果,需要设计适用于一维数据的卷积神经网络。
根据本发明的业务流数据特点可知,在一维卷积神经网络中,其输入为A×1的业务流数据,在卷积神经网络第j级隐层中,其特征图大小为Pj×1,Kj根据需要设置,每级隐层核的大小为Qj×1,Qj根据需要设置。也就是说,在一维卷积神经网络中,输入、每级隐层的特征图和核均为一维结构。而其他卷积神经网络参数,例如隐层层数、每层隐层的滤波器个数等等,可以根据实际需要来设置。
图9是本实施例中一维卷积神经网络结构图。如图9所示,本发明中一维卷积神经网络包括输入层INPUT、第一卷积层C1、第一采样层S2、第二卷积层C3、第二采样层S4、第三卷积层C5、第三采样层S6和输出层OUTPUT,其中:
输入层INPUT,神经元个数为1500,即与业务流数据包的字节数一致,第个神经元对应一个字节数据。
第一卷积层C1,共有1个特征图(特征图个数可以根据需要自定义),特征图由1496个神经元构成,即特征图大小为1496*1。每个神经元指定一个大小为5的接受域,由于不考虑对输入层INPUT的边界进行拓展,则滑动窗将有1496个不同的位置,也就是C1层的大小是1496,其中1496=1500-(5-1)。
第一采样层S2,共有1个特征图(与C1相同),特征图由748个神经元构成。每个神经元具有一个大小为2的接受域,简单地说,由2个点下采样为1个点,也就是C1中不重复的2个数的加权平均。其中748=1496/2。
第二卷积层C3,共有1个特征图,特征图由744个神经元构成。每个神经元指定一个大小为5的接受域,由于不考虑对S2的边界进行拓展,则滑动窗将有744个不同的位置,也就是C3层的大小是744,其中744=748-(5-1)。
第二采样层S4,共有1个特征图(与C3相同),特征图由372个神经元构成。每个神经元具有一个大小为2的接受域,同样地,是由2个点下采样为1个点,也就是C3中不重复的2个数的加权平均。其中372=744/2。
第三卷积层C5,共有1个特征图,特征图由368个神经元构成。每个神经元指定一个大小为5的接受域,由于不考虑对S4的边界进行拓展,则滑动窗将有368个不同的位置,也就是C4层的大小是368,其中368=372-(5-1)。
第三采样层S6,共有1个特征图(与C5相同),每个特征图由184个神经元构成。每个神经元具有一个大小为2的接受域,同样地,由2个点下采样为1个点,也就是C5中不重复的2个数的加权平均。其中184=368/2。
输出层OUTPUT是一个全连接层。输出层的神经元的个数是与要识别的业务种类相同的,本实施例中假定业务类型为7种,那么输出层OUTPUT的神经元数量即为7。
S107:分别训练一维卷积神经网络:
采用业务流流池群对于集成卷积神经网络中的三个一维卷积神经网络进行分别训练,其中上行一维卷积神经网络的训练输入为业务流流池群中的每条上行业务流数据包,其期望输出为对应的业务类别标签;下行一维卷积神经网络的训练输入为业务流流池群中的每条下行业务流数据包,其期望输出为对应的业务类别标签;交互一维卷积神经网络的训练输入为业务流流池群中的每条上行业务流数据包和下行业务流数据包,其期望输出为对应的业务类别标签。
S108:业务识别:
在宽带接入网实际运行时,捕获得到一段TCP或UDP业务流数据帧,从该业务流中每个数据帧中提取出数据包,末尾添零至长度为A字节的业务流数据包,将这些业务流数据包划分为上行业务流数据包和下行业务流数据包,输入集成卷积神经网络中的对应一维卷积神经网络,仲裁模块根据三个一维卷积神经网络的业务识别结果综合仲裁得到最终业务识别结果,其仲裁方法为:仲裁模块收集三个一维卷积神经网络的识别结果,先分别对每个一维卷积神经网络的识别结果进行统计,选择每个一维卷积神经网络中数量占该一维卷积神经网络所有识别结果数量的百分比最大的识别结果作为该一维卷积神经网络的有效识别结果。在三个有效识别结果中,如果任意两个一维卷积神经网络的有效识别结果一致时,将此有效识别结果作为最终的识别结果,否则选择百分比最大的有效识别结果作为最终的识别结果。
为了验证本发明的技术效果,收集了实际宽带接入网中7种不同业务、共计139800个数据帧,从每个业务的数据帧中,划出一部分用于卷积神经网络的训练,剩下一部分用于测试,其中训练数据为130000个数据帧,测试数据为9800个数据帧。在对每个一维神经网络进行训练时,为避免过拟合现象,将对应的不同业务的所有业务流数据包按照随机顺序输入。根据实验结果统计可知,采用本发明对宽带接入网业务的识别率可达到90%以上,可见采用本发明可以实现对宽带接入网高准确率的业务识别。
尽管上面对本发明说明性的具体实施方式进行了描述,以便于本技术领域的技术人员理解本发明,但应该清楚,本发明不限于具体实施方式的范围,对本技术领域的普通技术人员来讲,只要各种变化在所附的权利要求限定和确定的本发明的精神和范围内,这些变化是显而易见的,一切利用本发明构思的发明创造均在保护之列。
- 还没有人留言评论。精彩留言会获得点赞!