一种基于Wi‑Fi信号空间划分的两级定位方法与流程
本发明涉及室内定位领域,尤其涉及一种将Wi-Fi信号空间划分成若干子空间并进行两阶段定位的方法。
背景技术:
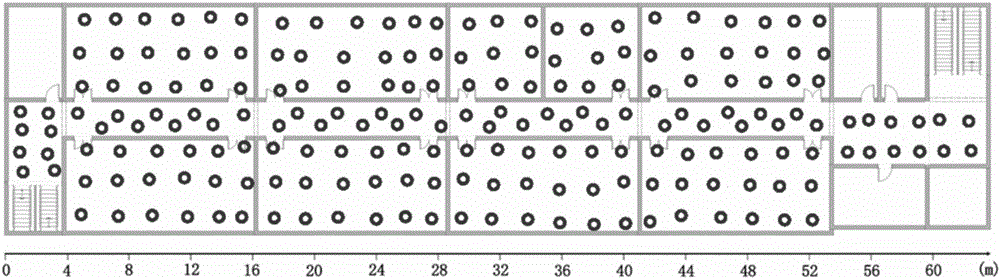
:无线局域网WLAN具有传输速率高、安装便捷等特点,使人们在日常生活工作中可以随时随地快速地接入网络。Wi-Fi指纹是指Wi-Fi无线网卡能够扫描到的周围多个Wi-Fi无线接入点和对应的信号强度。Wi-Fi无线接入点AP通常是无线路由器。将Wi-Fi指纹作为一个典型的室内定位解决方案,它不需要添加额外的硬件设备,充分利用了现有的无线网络设施,将定位系统的应用范围扩大到了楼群和室内,降低了定位成本,并且满足了用户对位置信息的及时性和就地性的需求,因此,随着无线局域网的广泛部署和普及应用,基于无线局域网的室内定位技术越来越受到重视。基于指纹地图的典型Wi-Fi室内定位方法主要包括原始数据采集、数据预处理、模型建立、指纹匹配四个步骤。采集到的原始数据包括室内各参考点的Wi-Fi信号指纹和参考点的位置坐标。对采集到的Wi-Fi信号指纹进行降噪处理后,根据特定的算法建立Wi-Fi信号指纹与位置坐标之间的依赖关系并生成指纹数据库(RadioMap)。在指纹匹配阶段,将采集的Wi-Fi信号指纹根据指纹数据库进行匹配,找出最接近的指纹样本,然后根据建立的模型计算出用户位置。现有大多数室内定位算法采用单级定位,这就需要在整个定位区域建立一个统一的信号指纹与位置坐标之间的依赖关系。由于室内区域往往较大,且布局不同,整个定位区域采用同一个依赖关系不能准确表达位置坐标与信号指纹之间的关系,也就不能准确定位。另一方面,定位精确度随着样本密度的增加而提高,对于较大的定位区域会采集大量的指纹数据,从而造成计算复杂度的增加。有算法提出按照物理空间将定位区域固定划分成若干小区域进行定位。但是这些物理小区域并不能反映实际的信号指纹分布情况,同一小区域内的信号指纹有时并不遵循相似的位置坐标和信号指纹之间的关系,从而照成定位结果出现误差。技术实现要素:本发明的目的是针对上述存在的问题,提出的一种新的让Wi-Fi指纹与位置坐标之间具有更为准确的依赖关系的定位方法。本发明为解决上述技术问题所采用的技术方案是,一种基于Wi-Fi信号空间划分的两级定位方法,包括以下步骤:1)子区域划分训练步骤:1-1)采集各参考点上的指纹数据样本,所述指纹数据样本由参考点的信号指纹与参考点位置坐标组成;所述参考点的信号指纹包括参考点上接收到的各Wi-Fi无线接入点的信号强度、各Wi-Fi无线接入点的MAC地址与服务集标识SSID;1-2)采用K-Means聚类模型将指纹数据样本分成K类,训练得到初步的K-Means聚类模型;1-3)对初步的K-Means聚类模型进行模型寻优,对初步的K-Means聚类模型迭代计算划分类别中的各点距聚类中心点距离的均值的最大值f,取迭代过程中f值最小的那次划分结果即为最优划分得到寻优后的K-Means聚类模型;1-4)将寻优后的K-Means聚类模型划分结果中每一个参考点与其邻居点进行对比,当该参考点的分类与邻居点所属的分类均不相同,则判断该参考点为离群点,将离群点重新分配到其邻居点所属分类最多的类别来进行离群点校正;所述邻居点为与当前参考点位置坐标邻近的其他参考点;1-5)将离群点校正后得到的K-Means聚类模型作为最终训练出的K-Means聚类模型,K-Means聚类模型的K个分类分别对应了K个子区域;2)两阶段训练步骤:2-1)用每个子区域的信号指纹训练出对应该子区域的一个支持向量分类器SVC模型;2-2)用支持向量回归算法SVR建立每一个子区域中参考点的信号指纹与参考点位置坐标之间函数关系,每个子区域对应一个SVR模型;3)定位步骤:3-1)收集测试点的信号指纹;3-2)粗定位阶段:根据K个子区域的SVC模型来确定测试点的信号指纹所属的子区域;3-3)精定位阶段:根据选择测试点所在的子区域的SVR模型得到测试点的位置坐标。在对子区域采用K-Means聚类进行划分后还进行了优化和离群点的处理。相比现有技术中仅对Wi-Fi指纹进行信号空间的聚类,本发明在对信号空间聚类后引入聚类优化和离群点校正,从物理空间上对聚类进行校正,即本发明对信号空间与物理空间两者进行聚类,对子区域的划分更为准确。本发明在采样空间聚类算法将较大信号空间区域划分成更小而且特征更加明显集中的子区域,然后结合SVM分类算法和SVM回归算法来建模这种未知的依赖关系,进而提高定位精度。本发明的有益效果是,通过对子区域的优化聚类,使得Wi-Fi指纹与位置坐标之间建立的依赖关系更为准确,从而提高定位精度。附图说明图1为两阶段定位流程图;图2为实施例训练数据采集点示意图;图3为实施例测试数据采集点示意图。具体实施方式训练阶段分为子区域划分与两级定位模型建立两个部分:1)根据采集到的Wi-Fi信号聚类定位区域中的各个位置参考点,聚类结果作为划分的子区域;根据Wi-Fi信号聚类定位子区域包括:利用K-Means聚类算法来划分信号空间子区域、对K-Means聚类模型进行多次寻优选出较精确的模型参数、K-Means聚类后对产生的离散点进行校正。2)计算两阶段WLAN定位模型。采用SVM分类和回归算法来实现两阶段的室内定位,第一阶段为粗定位阶段,也叫做子区域定位,每一个子区域都训练有一个SVC分类器模型,用于判定一个测试信号指纹是否是在该子区域内采集。第二阶段为精定位阶段,也叫做区域内坐标定位,采用SVR算法来建立信号指纹与位置坐标之间的函数依赖关系。对于每一个坐标维度,它们互相之间是独立的,需要训练出各自的回归问题模型。得到两个定位阶段模型之后,即可进行两级定位。根据Wi-Fi信号聚类划分子区域的方法如下:1)采集与处理AP的Wi-Fi指纹样本a)采集Wi-Fi指纹数据包括AP的信号强度、MAC地址、SSID和位置坐标,共在如图2所示的200个点进行了训练数据的采集,每个采集点旋转着朝8个方向共采集了16次Wi-Fi指纹数据,共采集到3200条Wi-Fi指纹数据作为训练数据集;b)令定位区域的AP集合为A={a1,a2,…,at},其中t表示AP的数量。采集点集合为S={s1,s2,…,sn},其中n表示参考点的数量。一个采集样本便表述为其中为在采样点si的RSSI的均值,表示采样点si的坐标值。将Wi-Fi指纹样本归一化处理为K-Means聚类算法适宜的数据形式,Wi-Fi信号强度归一化值可表示为如下公式Wiaj=r‾iaj-rminrmin-rmax]]>表示在参考点si,aj的信号指纹均值,rmin表示所有信号的强度值最小值,rmax表示表示所有信号的强度值的最大值;2)训练K-Means聚类模型,采用该模型将原始的Wi-Fi指纹样本集分成K类a)首先,将均值信号指纹集聚类为K个集合簇,每个集合即表示一个子区域,K是预先设定的值。设指纹数据集为{X1,X2,X3,…,XM},其中Xi表示参考点i的均值指纹,假设这M个指纹数据可以分成K类,则K-Means聚类问题模型化表示为:minJ=Σi=1MΣk=1Kγik||Xi-μk||2S.tγik∈{0,1}Σk=1Kγik=1,i=1,2,3,...,M]]>其中μk代表第k类的聚点,即中心点均值指纹。||Xi-μk||即表示聚类中心点均值指纹与其它信号指纹之间的距离范式,本文采用欧几里得距离来计算,公式描述为di=Σj=1t(r‾ij-rcj)2]]>其中t表示AP的数量。b)K-Means聚类的模型可以用EM算法来进行训练。首先初始化K个聚类中心μk,=1,2,3,…,K,随机从M个信号指纹空间中选出K个指纹即可。接着,E步骤:固定μk,最小化J,显然有γik=1k=argminj||Xi-μk||20otherwise,i=1,2,...,M.]]>M步骤:固定γik,最小化J,则有αJαμk=-2Σi=1Mγik(Xi-μk)=0,k=1,2,...,K,]]>μk=Σi=1MγikXiΣi=1Mγik]]>最终直至J收敛。3)评估此次聚类划分模型划分,进行模型寻优a)计算模型划分类别中的各点距中心点距离的均值的最大值fi,公式表示为dki=1nkΣj=1nk||pkj-p‾k||]]>fi=maxk=1,2,...Kdki]]>其中表示第i次K-Means聚类划分结果中第k类中各点距离中心点距离的均值,nk表示第k类中共有的点数,fi为第i次聚类划分的特征值;b)迭代n次后,fi值最小的那次划分结果即为最优划分,公式表示为Q=mini=1,2,...,nfi]]>Q为最终求得的最小聚类划分特征值;4)对Wi-Fi指纹样本划分结果产生的离散点进行校正处理a)对于每一个参考位置点,与其多个邻居点进行对比,令该参考位置点所属的子区域为d,其邻居点分别所属的子区域为(d1,d2,…dq),其中q表示邻居点的数量。如果该点没有一个邻居点所属的子区域ID与其相同,即那么此点便可认为是离群点;b)重新分配离群点到邻居点所属最多的子区域;5)K-Means聚类模型训练输出的模型,其在文件中的存储格式主要有四组数据:K、ApNum、ApMacs和ClustersCenter。其中K表示聚类个数;ApNum表示整个训练样本集中所有的AP数量;ApMacs为这些AP的MAC值列表;ClustersCenter为聚类中心,最后的K行数据,每一个聚类中心有ApNum个浮点型数据,表示各个AP对应的归一化指纹均值。基于WLAN的两阶段室内定位,两阶段定位系统流程如图1所示1)离线训练阶段a)该步骤与Wi-Fi信号聚类定位子区域中1).a)的采集方式和数据一致,令定位区域的AP集合为A={a1,a2,…,at},其中t表示AP的数量。子区域集合为D={d1,d2,...,dK},其中K表示子区域的数量。其中一个子区域中的AP集合便可表述为一个采集样本便表述为(di,(xi,yi),ri),其中di∈D表示子区域,表示信号指纹,表示AP集合Ai中APj的RSSI,j≤m≤t,(xi,yi)表示采样点的坐标值。b)核心算法SVM采用的是libSVM的实现。核函数选用的是RBF,SVC算法采用的是C-SVC。定位区域被划分为多个子区域,因而信号指纹样本相应的便被标记上其所属的子区域ID。接着,使用子区域ID和所有的信号指纹样本集对每个子区域训练一个SVM分类器。令样本集为{(di,ri)|i=1,2,…,n},其中n表示样本数量。对于每一个子区域,样本集分成两类:一类是在该子区域内采集的样本数据,标记为+1;一类不是在该子区域内采集的样本数据,标记为-1。那么训练样本可表述为{(ci,ri)|i=1,2,…,n},ci∈{-1,+1}表示该子区域的目标值;c)SVR算法采用的是ν-SVR,令r∈Rt表示一个信号指纹,SVR中的目标值c表示一个维度的坐标值。采样每个子区域内采集的信号指纹样本集为每个子区域训练各自的SVM回归模型,以建立起该子区域内信号指纹与位置坐标之间的函数依赖关系。对于每个子区域d,只有样本集{(di,(xi,yi),ri)|di=d,i=1,2,…,n}会被用于训练该子区域的回归模型。其中样本集{(di,xi,ri)|di=d,i=1,2,…,n}用于训练x轴的回归模型,其中样本集{(di,yi,ri)|di=d,i=1,2,…,n}用于训练y轴的回归模型;2)在线定位阶段a)采集实测Wi-Fi信号指纹信息,共在如图3所示的240个点进行了测试数据的采集,其中大房间采集了24个点、小房间采集了12个点、走廊区域5~11个点不等。每个采集点旋转着朝各个方向共采集了3次Wi-Fi指纹数据。数据采集用时总计约54分钟,共采集到720条Wi-Fi指纹数据作为测试数据集;b)粗定位阶段:根据K个子区域的SVC模型来确定实测的信号指纹所属的子区域ID,如果一个信号指纹属于一个子区域,那么对应于该子区域的分类器的目标值ci=+1,而其它子区域的分类器对应于该信号指纹的目标值ci=-1;c)精确定位阶段:将指纹r提交给已确定所在的子区域d的x轴回归模型以获取x坐标值,将指纹r提交给该子区域的y轴回归模型以获取y坐标值。实施例的识别精度如下表:当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1