数字电视节目同声翻译输出方法及系统与流程
本发明涉及数字电视领域,尤其涉及一种数字电视节目同声翻译输出方法及系统。
背景技术:
目前,数字电视机顶盒(或电视机)播放的数字电视节目声音,都是节目中对应的原始声音,使得用户能够原汁原味的观看电视节目。
但是,节目的原始声音有可能是外语发声,例如英语电视节目。外语发声的电视节目为使听不懂外语的观众能够正常观看,往往会提供双语字幕,观众如果听不懂外语,就只能依赖于看屏幕下方的中文字幕才能看懂电视节目内容,而观看下方的中文字幕,往往会顾及不到电视节目中的内容画面,这将会很大程度的影响观众的观看效果,使得观众不能很好的观看电视节目,给观众带来不便。
技术实现要素:
有鉴于此,有必要针对上述外语发声电视节目,观众观看中文字幕影响观众观看电视节目,带来不便的问题,提供一种数字电视节目同声翻译输出方法及系统。
本发明提供的一种数字电视节目同声翻译输出方法,包括如下步骤:
S10:控制音视频终端缓冲存储电视节目数据流;
S20:由缓冲存储的电视节目数据流中分别解析分离出视频数据、音频数据以及字幕数据,并在分离时标记时间戳,为三者标记上同步标签;
S30:对音频数据进行分段,并将分段后的音频数据进行解码处理,生成分段的原始PCM数据;
S40:将分段的原始PCM数据发送到云端服务器通过预设的音色数据库进行音色学习,匹配识别出音频数据的音色;
S50:将原始的PCM数据在云端服务器进行用户所需语言的文字翻译,并将翻译结果与字幕数据进行比对,采用字幕数据对翻译结果进行内容和时间的同步修正;
S60:根据识别出的音色,将修正后的翻译结果转换成相同音色的语音数据,并将语音数据按照时间戳与视频数据、字幕数据进行同步合成,合成新的节目数据流进行播放。
在其中的一个实施方式中,所述步骤S20还包括:
在获取到音频数据后,对除人声之外的环境声音进行过滤。
在其中的一个实施方式中,所述步骤S30还包括:解析字幕数据中的标点符号,获取每一个句号处的时间位置,按照句号处的时间位置对音频数据进行分段。
在其中的一个实施方式中,所述步骤S60还包括:将转换后的语音数据的振幅与原音频数据的振幅进行比对调整,使转换后语音数据的振幅与原音频数据的振幅保持一致。
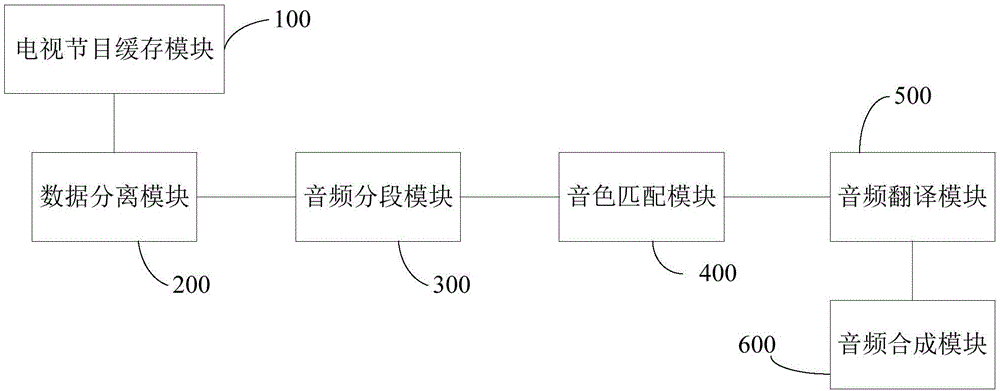
本发明提供的一种数字电视节目同声翻译输出系统,包括:
电视节目缓存模块,控制音视频终端缓冲存储电视节目数据流;
数据分离模块,由缓冲存储的电视节目数据流中分别解析分离出视频数据、音频数据以及字幕数据,并在分离时标记时间戳,为三者标记上同步标签;
音频分段模块,对音频数据进行分段,并将分段后的音频数据进行解码处理,生成分段的原始PCM数据;
音色匹配模块,将分段的原始PCM数据发送到云端服务器通过预设的音色数据库进行音色学习,匹配识别出音频数据的音色;
音频翻译模块,将原始的PCM数据在云端服务器进行用户所需语言的文字翻译,并将翻译结果与字幕数据进行比对,采用字幕数据对翻译结果进行内容和时间的同步修正;
音频合成模块,根据识别出的音色,将修正后的翻译结果转换成相同音色的语音数据,并将语音数据按照时间戳与视频数据、字幕数据进行同步合成,合成新的节目数据流进行播放。
在其中的一个实施方式中,所述数据分离模块在获取到音频数据后,对除人声之外的环境声音进行过滤。
在其中的一个实施方式中,所述音频分段模块解析字幕数据中的标点符号,获取每一个句号处的时间位置,按照句号处的时间位置对音频数据进行分段。
在其中的一个实施方式中,所述音频合成模块将转换后的语音数据的振幅与原音频数据的振幅进行比对调整,使转换后语音数据的振幅与原音频数据的振幅保持一致。
本发明数字电视节目同声翻译输出方法及系统,将缓存的电视节目数据流进行视频、音频和字幕三者的分离,然后对音频数据进行分段、音色识别和翻译处理等处理,并利用字幕数据和时间戳进行修正和同步处理,完成将原始音频数据同声翻译成用户所需语言的音频数据,进而播放给用户,使得用户能够无需观看字幕就能够听懂电视节目的音频,给用户观看电视节目带来了极大的便利,用户不会因此错过电视节目的画面内容,大大提高了用户的观看体验。
附图说明
图1是一个实施例中的数字电视节目同声翻译输出方法的流程图;
图2是一个实施例中的数字电视节目同声翻译输出系统的结构图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
图1是一个实施例中的数字电视节目同声翻译输出方法的流程图,如图1所示,该方法包括如下步骤:
S10:控制音视频终端缓冲存储电视节目数据流。
由于电视节目很多是实时节目,电视节目数据流很多是实时流,故为使得能够对电视节目进行同声翻译,该实施例中,首先需要对电视节目数据流进行缓存播放,通过缓存时间对电视节目数据流进行处理。
S20:由缓冲存储的电视节目数据流中分别解析分离出视频数据、音频数据以及字幕数据,并在分离时标记时间戳,为三者标记上同步标签。
在缓存存储电视节目数据流之后,将视频数据、音频数据以及字幕数据三者分离,以便后续进行音频转换。该实施例中,为保证分离后重组能够同步,在三者分离时标记时间戳,并为三者标记上同步标签,这样保证后续的同步性操作。
由于音频数据除包含人声之外,还包括大量的环境声音,环境声音会对人声造成干扰,故进一步的,该步骤还包括:在获取到音频数据后,对除人声之外的环境声音进行过滤。
S30:对音频数据进行分段,并将分段后的音频数据进行解码处理,生成分段的原始PCM(一种编码格式,也称为脉冲编码调制)数据。
为保证音频数据语句的完整性和合理性,需要对音频数据进行分段,分段后也便利翻译处理。分段后将音频数据解码成原始PCM数据,以便能够识别和处理。
进一步的,该步骤中对音频数据进行分段具体为:解析字幕数据中的标点符号,获取每一个句号处的时间位置,按照句号处的时间位置对音频数据进行分段,这样就按照语句的完整性和连贯性很好的对音频数据进行了分段。
S40:将分段的原始PCM数据发送到云端服务器通过预设的音色数据库进行音色学习,匹配识别出音频数据的音色。
由于音频翻译时,除音频内容外,音频的音色也是重要的参数,音色的准确翻译能够极大的保证同声翻译的效果,故该实施例中,在将音频数据转换为PCM数据后,发送到前端进行音色学习处理,利用预先设置的音色数据库来匹配PCM数据中的音色,最大可能的真实还原。预设的音色数据库通过输入不同年龄和性别的声音来构建。
S50:将原始的PCM数据在云端服务器进行用户所需语言的文字翻译,并将翻译结果与字幕数据进行比对,采用字幕数据对翻译结果进行内容和时间的同步修正。
在音色学习完毕后,由于原始的PCM数据为外语发声,故需要进行翻译,翻译成用户所需要的语言发声。首先将原始的PCM数据在云端服务器翻译成用户所需语言的文字语句,文字语句翻译完毕后,由于翻译可能存在较大的误差,故将翻译结果与字幕数据进行比对,利用字幕数据来对翻译结果进行内容修正,并且进行时间上的同步,消除翻译结果在内容和时间同步上的误差。
S60:根据识别出的音色,将修正后的翻译结果转换成相同音色的语音数据,并将语音数据按照时间戳与视频数据、字幕数据进行同步合成,合成新的节目数据流进行播放。
在文字翻译得到翻译结果并修正后,由于之前已经得到音频数据的音色数据,则结合识别出的音色,来对翻译结果进行语音合成,将修正后的翻译结果转换成相同音色的语音数据,得到翻译后的新音频数据,最后按照时间戳与视频数据、字幕数据进行同步合成,得到翻译后的节目数据流进行播放,即可完成对电视节目的同声翻译,使得用户能够听懂电视节目的音频,满足用户需求。
此外,为进一步提高同声翻译的效果,该步骤还包括:将转换后的语音数据的振幅与原音频数据的振幅进行比对调整,使转换后语音数据的振幅与原音频数据的振幅保持一致。
该数字电视节目同声翻译输出方法,将缓存的电视节目数据流进行视频、音频和字幕三者的分离,然后对音频数据进行分段、音色识别和翻译处理等处理,并利用字幕数据和时间戳进行修正和同步处理,完成将原始音频数据同声翻译成用户所需语言的音频数据,进而播放给用户,使得用户能够无需观看字幕就能够听懂电视节目的音频,给用户观看电视节目带来了极大的便利,用户不会因此错过电视节目的画面内容,大大提高了用户的观看体验。
同时,本发明还提供一种数字电视节目同声翻译输出系统,如图2所示,该系统包括:
电视节目缓存模块100,控制音视频终端缓冲存储电视节目数据流。
由于电视节目很多是实时节目,电视节目数据流很多是实时流,故为使得能够对电视节目进行同声翻译,该实施例中,电视节目缓存模块100首先需要对电视节目数据流进行缓存播放,通过缓存时间对电视节目数据流进行处理。
数据分离模块200,由缓冲存储的电视节目数据流中分别解析分离出视频数据、音频数据以及字幕数据,并在分离时标记时间戳,为三者标记上同步标签。
在缓存存储电视节目数据流之后,数据分离模块200将视频数据、音频数据以及字幕数据三者分离,以便后续进行音频转换。该实施例中,为保证分离后重组能够同步,数据分离模块200在三者分离时标记时间戳,并为三者标记上同步标签,这样保证后续的同步性操作。
由于音频数据除包含人声之外,还包括大量的环境声音,环境声音会对人声造成干扰,故进一步的,数据分离模块200在获取到音频数据后,对除人声之外的环境声音进行过滤。
音频分段模块300,对音频数据进行分段,并将分段后的音频数据进行解码处理,生成分段的原始PCM(一种编码格式,也称为脉冲编码调制)数据。
为保证音频数据语句的完整性和合理性,音频分段模块300需要对音频数据进行分段,分段后也便利翻译处理。分段后将音频数据解码成原始PCM数据,以便能够识别和处理。
进一步的,音频分段模块300解析字幕数据中的标点符号,获取每一个句号处的时间位置,按照句号处的时间位置对音频数据进行分段,这样就按照语句的完整性和连贯性很好的对音频数据进行了分段。
音色匹配模块400,将分段的原始PCM数据发送到云端服务器通过预设的音色数据库进行音色学习,匹配识别出音频数据的音色。
由于音频翻译时,除音频内容外,音频的音色也是重要的参数,音色的准确翻译能够极大的保证同声翻译的效果,故该实施例中,在将音频数据转换为PCM数据后,发送到前端进行音色学习处理,音色匹配模块400利用预先设置的音色数据库来匹配PCM数据中的音色,最大可能的真实还原。预设的音色数据库通过输入不同年龄和性别的声音来构建。
音频翻译模块500,将原始的PCM数据在云端服务器进行用户所需语言的文字翻译,并将翻译结果与字幕数据进行比对,采用字幕数据对翻译结果进行内容和时间的同步修正。
在音色学习完毕后,由于原始的PCM数据为外语发声,故需要进行翻译,翻译成用户所需要的语言发声。音频翻译模块500首先将原始的PCM数据在云端服务器翻译成用户所需语言的文字语句,文字语句翻译完毕后,由于翻译可能存在较大的误差,故将翻译结果与字幕数据进行比对,利用字幕数据来对翻译结果进行内容修正,并且进行时间上的同步,消除翻译结果在内容和时间同步上的误差。
音频合成模块600,根据识别出的音色,将修正后的翻译结果转换成相同音色的语音数据,并将语音数据按照时间戳与视频数据、字幕数据进行同步合成,合成新的节目数据流进行播放。
在文字翻译得到翻译结果并修正后,由于之前已经得到音频数据的音色数据,音频合成模块600则结合识别出的音色,来对翻译结果进行语音合成,将修正后的翻译结果转换成相同音色的语音数据,得到翻译后的新音频数据,最后按照时间戳与视频数据、字幕数据进行同步合成,得到翻译后的节目数据流进行播放,即可完成对电视节目的同声翻译,使得用户能够听懂电视节目的音频,满足用户需求。
此外,为进一步提高同声翻译的效果,音频合成模块600将转换后的语音数据的振幅与原音频数据的振幅进行比对调整,使转换后语音数据的振幅与原音频数据的振幅保持一致。
该数字电视节目同声翻译输出系统,将缓存的电视节目数据流进行视频、音频和字幕三者的分离,然后对音频数据进行分段、音色识别和翻译处理等处理,并利用字幕数据和时间戳进行修正和同步处理,完成将原始音频数据同声翻译成用户所需语言的音频数据,进而播放给用户,使得用户能够无需观看字幕就能够听懂电视节目的音频,给用户观看电视节目带来了极大的便利,用户不会因此错过电视节目的画面内容,大大提高了用户的观看体验。
本发明数字电视节目同声翻译输出方法及系统,将缓存的电视节目数据流进行视频、音频和字幕三者的分离,然后对音频数据进行分段、音色识别和翻译处理等处理,并利用字幕数据和时间戳进行修正和同步处理,完成将原始音频数据同声翻译成用户所需语言的音频数据,进而播放给用户,使得用户能够无需观看字幕就能够听懂电视节目的音频,给用户观看电视节目带来了极大的便利,用户不会因此错过电视节目的画面内容,大大提高了用户的观看体验。
以上仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!