一种基于递归卷积神经网络进行压缩感知视频重建的方法与流程
本发明涉及视频压缩和重建领域,尤其是涉及了一种基于递归卷积神经网络进行压缩感知视频重建的方法。
背景技术:
视频压缩和重建常用于物理与生物科学的研究、视频监控、遥感技术、社交网络等领域,在物理与生物科学的研究上,高速摄像机被用来记录传统相机所不能记载的高速率事件特征,它能记录高速事件的高分辨率静止图像,例如,跟踪“可忽略的运动模糊和图像失真伪影”的爆炸气球。视频监控中,可对监控视频中感兴趣的区域进行重建,对特定人物或车牌的图像进行增强提高辨识度。但是,若帧率为10kfps的摄像机拍摄分辨率为1080P的高清视频,那么每秒可以产生大约500GB的数据,这对现有的传输和存储技术构成了巨大的挑战,如何高效地传输和存储这些大容量视频是目前研究的热点。
本发明提出了一种基于递归卷积神经网络进行压缩感知视频重建的方法,利用卷积神经网络(CNN)和递归神经网络(RNN)来提取时空特征,包括背景、对象细节、和运动信息,达到了更好的重建质量。具体地,随机编码器并行运行,利用较多的测量编码视频里的首帧,同时利用较少的测量编码剩余帧,对于每个压缩测量,有特定的CNN从中提取空间特征,长短记忆(LSTM)网络聚集了由每个CNN提取的所有特征,和隐藏状态的推断运动一起形成重建。本发明突破了将视频视为一系列独立图像的传统处理方式的局限,通过RNN将时间信息应用于重建过程,从而生成更多精确的模型,除此之外本方法还在保持较好的原始视频视觉细节的基础上,提高了压缩比并且减少了数据传输的宽带,提高了视频重建质量,支持高帧率的视频应用。
技术实现要素:
针对现有方法在高压缩比下难以保证视频重建质量的问题,本发明的目的在于提供一种基于递归卷积神经网络进行压缩感知视频重建的方法,超越了传统方法的限制,提高CS摄像机的压缩比(CR),并且提高了视频重建质量,同时减少了数据传输的带宽,使得可以支持高帧率的视频应用。
为解决上述问题,本发明提供一种基于递归卷积神经网络进行压缩感知视频重建的方法,其主要内容包括:
(一)压缩感知网络(CSNet);
(二)CSNet算法结构;
(三)卷积神经网络(CNN);
(四)长短期记忆(LSTM)网络;
(五)CSNet网络训练;
(六)压缩感知视频重建。
其中,所述的压缩感知网络(CSNet),是一种深度神经网络,可以从随机测量中了解视觉表示,用于压缩感知视频重建,是一种端到端的训练和非迭代模型,结合了卷积神经网络(CNN)和递归神经网络(RNN),从而利用时空特征进行视频重建,这个网络结构可以接收伴有多级压缩比(CR)的随机测量,分别地提供了背景信息和对象细节,达到更好的重建质量。
其中,所述的CSNet算法结构,该结构包含三个模块:用于测量的随机编码、用于视觉特征提取的CNN聚类、用于时间重建的LSTM,随机编码器并行运行,利用较多的测量编码视频里的首帧,同时利用较少的测量编码剩余帧,可以接受多级压缩比(CR)测量,通过此算法,关键帧和非关键帧(主要贡献运动信息的其余帧)分别被压缩,递归神经网络(RNN)推算出运动信息,且将这些信息与通过卷积神经系统(CNN)提取的视觉特征相结合,合成高质量的帧,高效的信息融合,能使压缩感知(CS)视频应用的保真度和压缩比(CR)之间得达到最优的平衡。
其中,所述的卷积神经网络(CNN),该网络对图像进行压缩测量和外放重建,把时间压缩和空间压缩结合在一起以最大化压缩比,设计一个较大的CNN来处理关键帧,因为关键帧含有高熵信息,同时,设计一个较小的CNN来处理非关键帧,为了减少系统的延迟以及简化网络结构,使用图像块作为输入,此时,由CNN生成的所有特征图的大小和图像块相同,特征图的数量单调下降,此网络输入是由压缩测量组成的m维向量,在CNN之前有一个全层,它使用这些测量生成一个二维特征图。
进一步地,所述的时间压缩,为获得更高的压缩比(CR),将包含T帧的每个视频补丁分成K个关键帧和(T-K)个非关键帧,关键帧经过低压缩比(CR)压缩,非关键帧经过高压缩比(CR)压缩,使得关键帧的测量信息可以再次被用来重建非关键帧,此可看作时间压缩。
其中,所述的长短期记忆(LSTM)网络,用于时间重建,为获得一个端到端训练的、以及计算有效的模型,不对原始输入进行预处理,并且利用一个LSTM网络提取重建必不可少的运动特征,从而估计视频的光流,合成的LSTM网络被用于运动外推、空间视觉特征和运动的聚集,以达到视频重建。
进一步地,所述的LSTM网络训练过程,其特征在于,在LSTM网络的训练过程中,起初的LSTM的M-输入提取处理关键帧的CNN数据,其余的(T-M)提取处理非关键帧的CNN输出,对于每个LSTM单位,它将会收到关键帧的视觉特征,这些视觉特征用于背景重建、恢复对象的当前帧、以及运动估计的最后几个帧。
其中,所述的CSNet网络训练,分为两个阶段,第一个阶段,预训练背景CNN,并且从K关键帧里提取视觉特征,第二个阶段,给模型更多的自由来提取构建对象所需的基本块,然后从零开始训练(T-M)较小CNN,这些对象CNN和预训练背景CNN通过一个合成的LSTM结合,三个网络一起训练,为减少训练所需的参数数量,只有关键帧CNN的最后几层被结合,所以这些图层的输入是特征映射而不是测量,将平均欧氏损失作为损失函数,即
此处,W和b是网络权值和偏置,xi和yi是每个图像块和它的CS测量,一个随机高斯矩阵被用于CS编码。
其中,所述的压缩感知视频重建,建立基于信息的当前帧,利用递归神经网络(RNN)提取运动特征,卷积神经网络(CNN)提取视觉特征,融合二者所提取的信息,利用LSTM网络聚集提取的所有特征,将其和隐藏状态的推断运动组合形成重建。
附图说明
图1是本发明一种基于递归卷积神经网络进行压缩感知视频重建的方法的系统流程图。
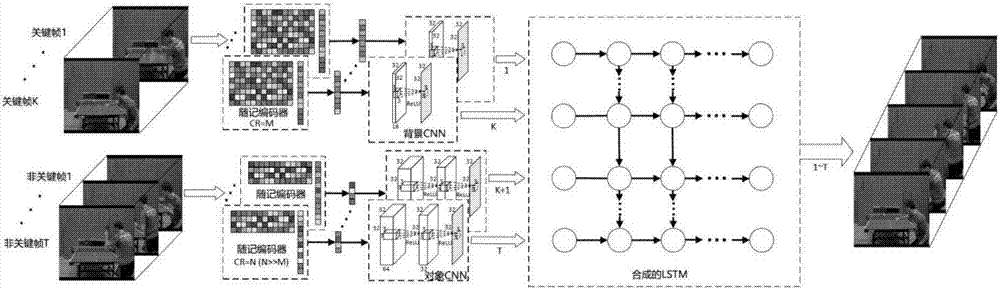
图2是本发明一种基于递归卷积神经网络进行压缩感知视频重建的方法的框架整体结构。
图3是本发明一种基于递归卷积神经网络进行压缩感知视频重建的方法的CSNet网络训练示意图。
图4是本发明一种基于递归卷积神经网络进行压缩感知视频重建的方法的压缩感知视频重建流程图。
具体实施方式
需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互结合,下面结合附图和具体实施例对本发明作进一步详细说明。
图1是本发明一种基于递归卷积神经网络进行压缩感知视频重建的方法的系统流程图。主要包括压缩感知网络(CSNet)、CSNet算法结构、卷积神经网络(CNN)、长短期记忆(LSTM)网络、CSNet网络训练、压缩感知视频重建。
其中,所述的压缩感知网络(CSNet),是一种深度神经网络,可以从随机测量中了解视觉表示,用于压缩感知视频重建,是一种端到端的训练和非迭代模型,结合了卷积神经网络(CNN)和递归神经网络(RNN),从而利用时空特征进行视频重建,这个网络结构可以接收伴有多级压缩比(CR)的随机测量,分别地提供了背景信息和对象细节,达到更好的重建质量。
其中,所述的CSNet算法结构,该结构包含三个模块:用于测量的随机编码、用于视觉特征提取的CNN聚类、用于时间重建的LSTM,随机编码器并行运行,利用较多的测量编码视频里的首帧,同时利用较少的测量编码剩余帧,可以接受多级压缩比(CR)测量,通过此算法,关键帧和非关键帧(主要贡献运动信息的其余帧)分别被压缩,递归神经网络(RNN)推算出运动信息,且将这些信息与通过卷积神经系统(CNN)提取的视觉特征相结合,合成高质量的帧,高效的信息融合,能使压缩感知(CS)视频应用的保真度和压缩比(CR)之间得达到最优的平衡。
其中,所述的卷积神经网络(CNN),该网络对图像进行压缩测量和外放重建,把时间压缩和空间压缩结合在一起以最大化压缩比,设计一个较大的CNN来处理关键帧,因为关键帧含有高熵信息,同时,设计一个较小的CNN来处理非关键帧,为了减少系统的延迟以及简化网络结构,使用图像块作为输入,此时,由CNN生成的所有特征图的大小和图像块相同,特征图的数量单调下降,此网络输入是由压缩测量组成的m维向量,在CNN之前有一个全层,它使用这些测量生成一个二维特征图。为获得更高的压缩比(CR),将包含T帧的每个视频补丁分成K个关键帧和(T-K)个非关键帧,关键帧经过低压缩比(CR)压缩,非关键帧经过高压缩比(CR)压缩,使得关键帧的测量信息可以再次被用来重建非关键帧,此可看作时间压缩。
其中,所述的长短期记忆(LSTM)网络,用于时间重建,为获得一个端到端训练的、以及计算有效的模型,不对原始输入进行预处理,并且利用一个LSTM网络提取重建必不可少的运动特征,从而估计视频的光流,合成的LSTM网络被用于运动外推、空间视觉特征和运动的聚集,以达到视频重建。在LSTM网络的训练过程中,起初的LSTM的M-输入提取处理关键帧的CNN数据,其余的(T-M)提取处理非关键帧的CNN输出,对于每个LSTM单位,它将会收到关键帧的视觉特征,这些视觉特征用于背景重建、恢复对象的当前帧、以及运动估计的最后几个帧。
其中,所述的CSNet网络训练,分为两个阶段,第一个阶段,预训练背景CNN,并且从K关键帧里提取视觉特征,第二个阶段,给模型更多的自由来提取构建对象所需的基本块,然后从零开始训练(T-M)较小CNN,这些对象CNN和预训练背景CNN通过一个合成的LSTM结合,三个网络一起训练,为减少训练所需的参数数量,只有关键帧CNN的最后几层被结合,所以这些图层的输入是特征映射而不是测量,将平均欧氏损失作为损失函数,即
此处,W和b是网络权值和偏置,xi和yi是每个图像块和它的CS测量,一个随机高斯矩阵被用于CS编码。
其中,所述的压缩感知视频重建,建立基于信息的当前帧,利用递归神经网络(RNN)提取运动特征,卷积神经网络(CNN)提取视觉特征,融合二者所提取的信息,利用LSTM网络聚集提取的所有特征,将其和隐藏状态的推断运动组合形成重建。
图2是本发明一种基于递归卷积神经网络进行压缩感知视频重建的方法的框架整体结构图。压缩视频帧通过压缩感知获得。重建是通过CSNet执行,CSNet由背景CNN、对象CNN、以及合成的LSTM组成。每T帧里,前M帧和剩余的(T-M)帧分别由低CR和高CR进行压缩。背景CNN首先被预训练,然后,剩下背景CNN层和模型的剩余部分一起训练。
图3是本发明一种基于递归卷积神经网络进行压缩感知视频重建的方法的CSNet网络训练示意图。网络训练过程分为两个阶段,其中图a为背景CNN的预训练,图b为CNN和合成的LSTM的联合训练。第一个阶段,预训练背景CNN,且从K个关键帧里提取视觉特征,如图a所示;第二个阶段,给模型更多的自由来提取构建对象所需的基本块,我们从零开始训练(T-M)小CNNs,这些对象CNN和预训练背景CNN通过一个合成的LSTM结合,三个网络一起训练,如图b所示。为减少训练所需的参数数量,只有关键帧CNN的最后几层被结合,所以层的输入是特征映射而不是测量。
图4是本发明一种基于递归卷积神经网络进行压缩感知视频重建的方法的压缩感知视频重建流程图。建立基于信息的当前帧,利用递归神经网络(RNN)提取运动特征,卷积神经网络(CNN)提取视觉特征,融合二者所提取的信息,利用LSTM网络聚集提取的所有特征,将其和隐藏状态的推断运动组合形成重建。
对于本领域技术人员,本发明不限制于上述实施例的细节,在不背离本发明的精神和范围的情况下,能够以其他具体形式实现本发明。此外,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围,这些改进和变型也应视为本发明的保护范围。因此,所附权利要求意欲解释为包括优选实施例以及落入本发明范围的所有变更和修改。
- 还没有人留言评论。精彩留言会获得点赞!