基于稀疏编码的多视频摘要方法与流程
本发明涉及视频处理,具体讲,涉及基于稀疏编码的多视频摘要方法。
背景技术:
随着信息技术的快速发展,视频数据大量涌现,成为人们获取信息的重要途径之一。然而,由于视频数量的剧增,大量视频数据中出现冗余和重复的信息,这使用户快速获取所需信息变得困难。因此,在这种情况下,迫切需要一种能对同一主题下的海量视频数据进行整合、分析的技术,来满足人们想要快捷、准确地浏览视频主要信息的需求,提高人们获取信息的能力。多视频摘要技术作为解决上述问题的有效途径之一,在过去的几十年里引起了越来越多的研究人员的关注。多视频摘要技术是一种基于内容的视频数据压缩技术,旨在将同一事件下的相关主题的多个视频进行分析、整合,提取出多个视频中的主要内容,并将提取的内容按照某种逻辑关系呈现给用户。目前对于多视频摘要主要从三个方面进行分析:1)覆盖率;2)新颖性;3)重要性。覆盖率指的是所提取的视频内容能够覆盖同一主题下多个视频的主要内容。冗余性指的是去除多视频摘要中的重复的、冗余的信息。重要性指的则是根据某些先验信息提取视频集中重要的关键镜头,从而提取出多个视频中重要的内容。
尽管许多单视频摘要已经提出,但是对于多视频摘要方法的研究却较少,仍处于初步阶段。这主要有两个原因:1)一是由于同一事件下多个视频主题的多样性以及视频之间主题的交叉性。主题多样性指的是同一事件下的多个视频的信息侧重点不同,具有多个子主题。而主题交叉性是指同一事件下的视频之间内容具有交叉性,既有相似的内容,也有不同的信息内容。2)二是由于多视频数据对同一内容所表现出来的音频信息,文本信息和视觉信息可能存在较大差别。这些原因使得多视频摘要的研究难于传统的单视频摘要。
在过去的几十年中,人们针对多视频数据集的特点,提出了一些多视频摘要的方法。其中,基于复杂的图聚类的多视频摘要方法是一个比较经典的方法。该类方法通过提取视频相应脚本信息的关键词和视频的关键帧,构建复杂的图,并在此基础上利用图聚类算法实现摘要。但是该方法主要针对新闻视频,对于没有视频脚本信息的视频集该方法就失去了意义,另外由于同一主题下的多个视频包含的内容具有多样性和冗余性,仅用聚类的方法虽然满足了视频内容的最大覆盖条件,针对多视频摘要,只用视频的visual信息聚类效果较差,结合其他模态虽有一定的帮助,但复杂度较大。
多视频摘要中存在多种模态的信息,如视频的文本信息、视觉信息、音频信息等。balancedav-mmr(balancedaudiovideomaximalmarginalrelevance)是一种有效利用视频多种模态信息的多视频摘要技术,它通过分析视频的视觉信息、音频信息以及视觉信息和音频信息中的语义信息,包括音频,人脸以及时间特征等这些对于视频摘要具有重要意义的信息。该方法有效地利用了视频的多模态信息,但提取的视频摘要并未达到较好的效果。
近年来,人们提出了一些新颖的方法。其中,利用视频的视觉共现特性(visualco-occurrence)实现多视频摘要是其中一个较新颖的方法。该方法认为重要的视觉概念(concepts)往往重复出现在同一主题下的多个视频中,并根据这一特点提出了最大二元组查找算法(maximalbicliquefinding),提取多视频的稀疏共现模式,从而实现多视频摘要。但是该方法仅适用于特定的数据集,对于视频中重复性较小的视频集,该方法就失去了意义。
此外,为了利用更多的相关信息,相关研究者提出了利用手机上的gps和罗盘等传感器获取手机视频拍摄过程中的地理位置等信息,并由此辅助判断视频中的重要信息,生成多视频摘要。另外,在该领域提出了利用网页图片这一先验信息作为辅助信息,更好地实现多视频摘要。目前,由于多视频数据的复杂性,多视频摘要的研究并没有达到理想效果。因此,如何更好地利用多视频数据的信息,来更好地实现多视频摘要,成为目前相关学者研究的热点。
技术实现要素:
为克服现有技术的不足,本发明旨在提出基于稀疏编码的多视频摘要技术,实现视频的聚类即实现视频的子主题的检测,对关键镜头进行排序,实现多视频摘要。为此本发明采用的技术方案是,基于稀疏编码的多视频摘要方法,利用视频的文本信息和视觉信息构建多图模型,通过图切的方法实现视频的聚类即实现视频的子主题的检测;然后,在每一子主题下利用稀疏编码的方法,将子主题下的视频帧与基于子主题的网页图片联系起来,获取关键镜头;最后通过视频上传时间对关键镜头进行排序,从而实现多视频摘要。
利用稀疏编码的方法具体是,给定特定事件的视频帧集,x={x1,x2,…,xn}表示n帧视频帧的特征集,z={z1,z2,…,zl}表示l帧网页图像的特征集,其中xi∈rd,zi∈rd,将候选视频帧x作为基向量组,视频帧xi、基于子主题关键词搜索的网页图片zi共同作为输入向量,学习视频帧的表达分数ai,每一帧xi对应一个系数变量ai,称为第i帧的表达分数,该表达分数传达了在网页图片先验信息的辅助下,每一帧在重构主体空间的贡献大小,由此构建目标函数如下,为了保证稀疏性在目标函数中加入正则化项:
s.t.aj≥0forj∈{1,…,m},γ>0(2)
其中系数aj是第j帧的表达分数,并且所有的目标向量xi共享同一个系数向量a={a1,a2,…,an},
在一个具体实例中,构建提取关键镜头的目标函数为(2)式,然后利用坐标梯度下降算法求得稀疏向量a,具体过程如下:
首先,初始化向量a为零向量,对目标函数关于表达分数ai(i=1,2,…,n)求偏导;然后选择使偏导数最大的表达分数ai,并用软阈值(soft-thresholding)的方法更新ai,最后迭代上述过程直到成本函数的值变化小于一定的阈值或迭代次数达到一定的值,求出表达向量a;
最后,生成给定长度的摘要:假定给定第k个子主题下摘要时间长度lk,通过以下优化问题来解决:
其中sk是第k个子主题下镜头的数量,
本发明的特点及有益效果是:
本发明主要是针对现有的多视频摘要方法的缺点,设计适用于多视频数据特点的基于稀疏编码的多视频摘要的方法,使之在有效的先验信息的辅助下,充分地利用数据的特有信息。其优势主要体现在:
(1)新颖性:将多图模型应用于视频聚类,充分地利用了视频的多模态信息,更好地实现了多视频集的子主题检测。在此基础上,首次提出了利用稀疏编码的方法提取视频的关键镜头。
(2)有效性:通过实验证明了与典型的应用于单视频摘要的聚类方法和最小稀疏重构方法相比较,本发明设计的基于稀疏编码的多视频摘要方法的性能明显优于两者,因此更适合于多视频摘要问题中。
(3)实用性:简单可行,可以用在多媒体信息处理领域中。
附图说明:
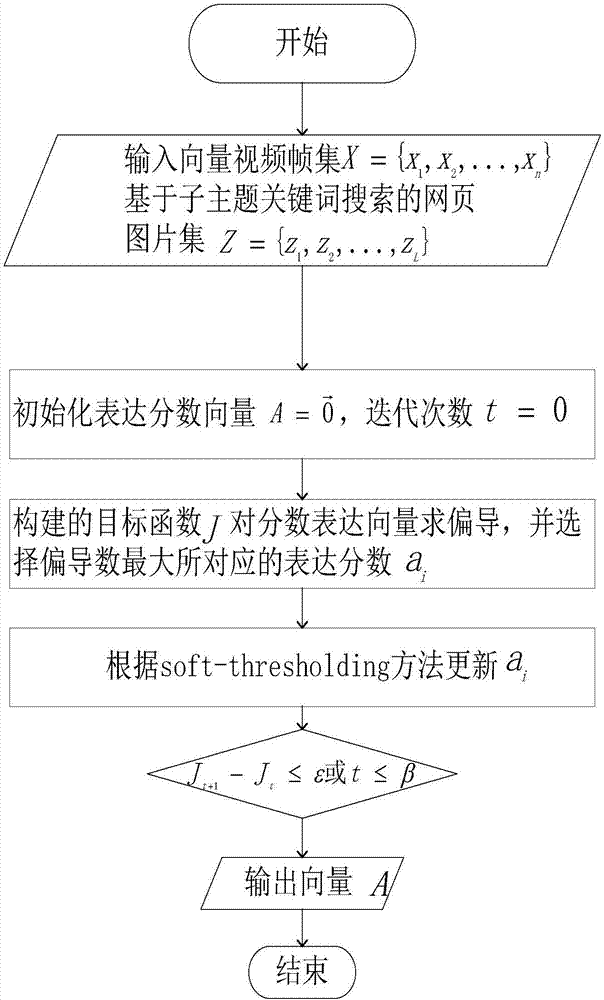
图1是本发明的提供的基于稀疏编码的视频关键镜头提取的流程图;
图2给出求解目标函数的坐标梯度下降算法的流程图;
具体实施方式
本发明针对多媒体视频数据的冗余信息、重复信息较多等特点,结合视频的视觉信息、文本信息和其它与主题相关的先验信息,利用系数编码思想对传统的多视频摘要方法进行了改进,达到了有效利用视频主题相关信息、提高用户浏览视频效率的目的。
本发明的目的在于提供一种基于稀疏编码的多视频摘要技术。根据多视频数据的特点,首先,本发明提出了利用视频的文本信息和视觉信息构建多图模型,通过图切的方法实现了视频的聚类即实现了视频的子主题的检测。然后,在每一子主题下利用稀疏编码的方法,将子主题下的视频帧与基于子主题的网页图片联系起来,获取重要的关键镜头。最后通过视频上传时间对关键镜头进行排序,从而实现多视频摘要。
本发明所提供的方法主要分为:引入网页图片作为辅助信息,设计适用于多视频摘要数据集特点的稀疏编码方法,来获取多视频的关键帧(镜头),从而实现关键帧的提取,并在此基础上利用视频的上传时间信息实现关键镜头(帧)的排序。
多视频摘要旨在将较长的视频集压缩成较短的摘要集,帮助用户快速地获取视频集的主要信息。一般同一事件的多视频集具有主题多样性、交叉性等特点,因此简单将单视频摘要的方法应用于多视频摘要中是不可行的,为此本发明提供了一种引入网页图像这一先验信息,利用稀疏编码的方法学习子主题下的视频帧与基于此子主题的网页图片的共性关系,从而提取视频中的重要帧。一般可认为基于子主题关键词的网页图片反映了该主题的重要内容,由于每幅图片是用户上传的且图片大部分来自所下载相关主题的视频,所以这些图片反映了用户的兴趣,同时图片相比于视频帧的优点在于图片以一种更富语义信息的方式从典型的视点捕捉主题,噪声较少。其方法的具体原理如下:
稀疏编码旨在选择一组基向量
其中aij表示第i个输入向量xi与第j个基向量
在本发明中,给定特定事件的视频帧集,x={x1,x2,…,xn}表示n帧视频帧的特征集,z={z1,z2,…,zl}表示l帧网页图像的特征集,其中xi∈rd,zi∈rd。多视频摘要的本质是选择一定数量的帧用来重构原来视频的主题空间。本发明结合网页图片先验信息,利用稀疏编码的思想构建目标函数,学习视频帧与基于子标题关键词搜索的网页图片的共有模式。本发明直接将该候选视频帧x作为基向量组,视频帧集xi、基于子主题关键词搜索的网页图片zi共同作为输入向量,学习视频帧的表达分数ai。每一帧xi对应一个系数变量ai,称为第i帧的表达分数,该表达分数传达了在网页图片先验信息的辅助下,每一帧在重构主体空间的贡献大小。构建目标函数如下,为了保证稀疏性在目标函数中加入正则化项:
s.t.aj≥0forj∈{1,…,m},γ>0(2)
其中系数aj是第j帧的表达分数,并且所有的目标向量xi共享同一个系数向量a={a1,a2,…,an},同时由于加入了正则化项,获得了稀疏的表达向量。
下面结合附图和具体实施例进一步详细说明本发明。
图1描述了子主题下,结合网页图像先验信息,利用稀疏编码的方法提取视频中的关键镜头的流程图。以下过程是针对一个子主题提取关键帧,同一事件的其他子主题关键镜头的提取方法相同。
首先,提取每一子主题下的视频帧和基于此子主题下的网页图像特征。在本发明中,给定特定事件下的某一子主题的视频帧集,x={x1,x2,…,xn}表示n帧视频帧特征集,用z={z1,z2,…,zl}表示l帧网页图像特征集,其中xi∈rd,zi∈rd。每一帧xi对应一个系数变量ai,称为第i帧的表达分数,代表了第i帧在重构中的作用大小。
其次,构建提取关键镜头的目标函数。基于稀疏编码的思想,本发明直接将该候选视频帧x作为基向量组,视频帧集xi、基于子主题关键词搜索的网页图片zi共同作为输入向量,学习视频帧的表达分数ai。其目标为:使输入向量xi、zi与基向量组x={x1,x2,…,xn}的重构误差同时最小,即在基于子标题的关键词搜索的网页图片信息的辅助下学习视频的重要镜头,其目标函数为(2)式,然后利用坐标梯度下降算法求得稀疏向量a,具体过程如下:
首先,初始化向量a为零向量,对目标函数关于表达分数ai(i=1,2,…,n)求偏导;然后选择使偏导数最大的表达分数ai,并用软阈值(soft-thresholding)的方法更新ai。最后迭代上述过程直到成本函数的值变化小于一定的阈值或迭代次数达到一定的值,求出表达向量a.
最后,生成给定长度的摘要。所有子主题关键镜头的提取均按照上述过程实现。假定给定第k个子主题下摘要时间长度lk,本发明可以通过以下优化问题来解决:
其中sk是第k个子主题下镜头的数量,
- 还没有人留言评论。精彩留言会获得点赞!