一种基于Kohonen神经网络的最佳攻击路径规划方法与流程
本发明涉及一种基于kohonen神经网络的最佳攻击路径规划方法,属于信息安全
技术领域:
。
背景技术:
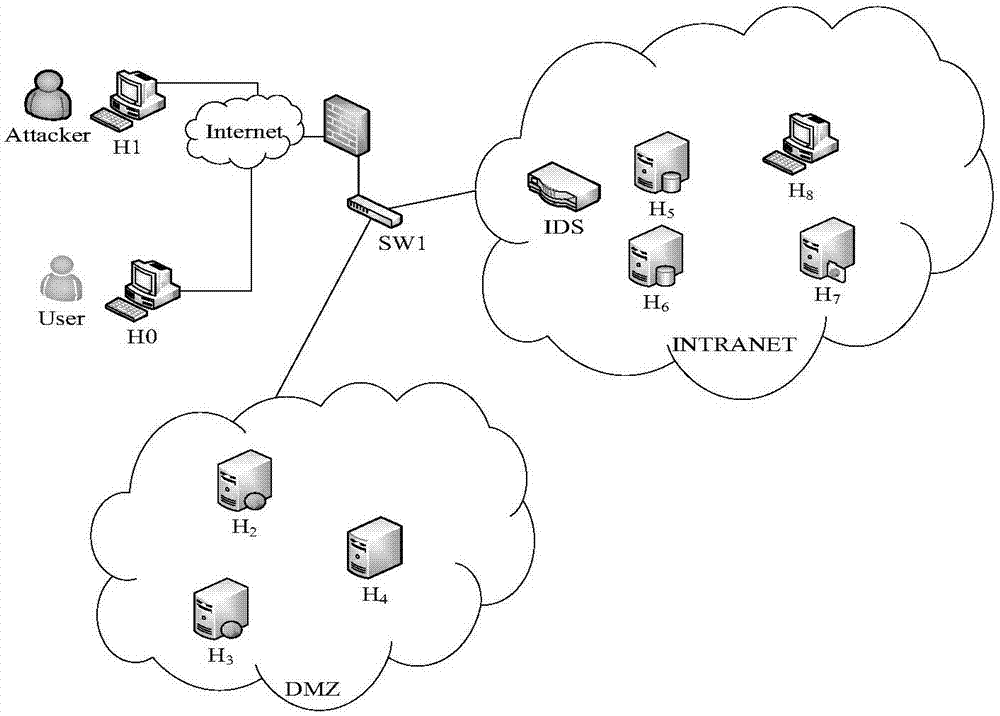
:在对信息系统网络进行渗透时,攻击者都希望选择代价小而回报大的攻击路径,其中,攻击回报与攻击代价只比最大的攻击路径为最佳攻击路径,目前的获取最佳攻击路径的方法主要是基于攻击图来获取所有的源节点与目标节点间的攻击路径后,再选取这些路径中的一条作为最佳攻击路径。目前,比较常用的网络攻击图有:基于脆弱性的网络攻击图以及基于网络状态的攻击图。基于上述两种攻击图的攻击路径或保护路径的生成方法存在的问题是:①生成速度慢;②为了解决状态爆炸的问题,采用限定攻击路径的方式,导致攻击路径包含不全等问题。为了解决上述问题对产生最佳攻击路径的影响,印度科学家nirnayghosh,sauravnanda,s.k.ghosh在2010年提出了基于最小攻击图(minimalattackgraph)并使用蚁群算法来对攻击路径进行优化以选取最佳攻击路径的方法。但是此方法由于算法开销太大,当面对大规模计算机机群时,即时使用最小攻击图,也无法快速拟合出最佳攻击路径。网络攻击图的定义:攻击图g=(n,e),n是一组节点,e是一组边。n∈n,n为节点,n是一个权限(privilege)节点或者漏洞利用(vulnerabilityexploit)节点。e为边,e∈e,e是一个二元素元组<sourcenode,targetnode>。sourcenode和targetnode代表了边e的源节点(source)和目标节点(target)。技术实现要素:本发明的目的是提出一种基于kohonen神经网络的最佳攻击路径规划方法,通过生成一个k-攻击图,解决已有的最佳攻击路径规划方法中存在的生成速度慢以及状态爆炸或者攻击路径并非收敛到最优等问题。本发明的目的是通过以下技术方案实现的。本发明的一种基于kohonen神经网络的最佳攻击路径规划方法,具体操作为:步骤一、获取网络结构。步骤1.1:获取网络系统中各主机的软件应用,建立软件应用与主机对应表。所述网络系统包括内部网络和“非军事化区”(demilitarizedzone,dmz)。所述软件应用与主机对应表包含:软件应用名称和主机名称。步骤1.2:获取网络系统中各主机之间以及网络系统中各主机与网络系统外部的攻击者主机之间的会话链接,建立主机间会话链接表。所述主机间会话链接表包括:源主机名和目标主机名。步骤二、收集网络系统中主机及漏洞信息。具体为:步骤2.1:收集cve数据库中的漏洞id,并将漏洞id转换成七元组向量,用符号xm表示第m个漏洞的七元组向量;xm=<s,c,i,u,co,av,au>其中,s为cvss漏洞评分;c,i,u分别为漏洞对信息系统的机密性、完整性和可用性影响评分;co是利用漏洞的攻击复杂度评分;av是漏洞攻击向量评分;au代表攻击是否需要身份认证。步骤2.2:收集漏洞被利用后产生的概率最大的攻击结果,并用二元组向量表示。所述二元组向量用符号ym表示,ym=<category,pr>。其中,category表示漏洞被利用后,获取漏洞所在主机的权限评分,pr表示攻击成功率。所述主机的权限评分是根据主机的权限对主机的机密性、完整性和可用性影响,由人为预先设定。步骤三、建立kohonen神经网络模型。所述kohonen神经网络模型为3层神经网络,分别是:输入层、kohonen层和输出层。其中,输入层包括7个输入节点;输出层包括2个输出节点;kohonen层包括15-25个节点。步骤四、训练kohonen神经网络模型,得到训练好的kohonen神经网络模型。具体为:步骤4.1:设置kohonen神经网络模型的参数,包括:kohonen层的最大学习率,用符号δmax表示,δmax∈(0,1);输出层的最小学习率,用符号δmin表示;δmin∈(0,1);最大邻域,用符号rmax表示,rmax∈(1,2);最小邻域,用符号rmin表示,rmin∈(0,1)。步骤4.2:为kohonen神经网络模型各节点之间的权值设置初始值。具体为:用符号ωij表示输入层节点到kohonen层节点间的权值,用符号ωjk表示kohonen层节点到输出层节点间的权值,i∈[1,7],j∈[1,n],k∈[1,2],n为kohonen层节点的个数。随机设置ωij和ωjk的值,满足ωij∈(0,1),ωjk∈(0,1)。步骤4.3:设置总迭代次数,用符号maxgen表示,maxgen≥5000。设置当前迭代次数,用符号l表示,l的初始值为1。将七元组向量xm=<s,c,i,u,co,av,au>作为输入数据,s,c,i,u,co,av,au分别对应一个输入节点;将二元组向量ym=<category,pr>作为输出数据,category,pr分别对应一个输出节点。步骤4.4:通过自适应函数来对邻域进行调整。自适应函数如公式(1)所示。其中,r为kohonen层的最佳输出节点的邻域半径;所述最佳输出节点通过步骤4.5得到。步骤4.5:通过公式(2)寻找kohonen层的最佳输出节点。posc=mindj(2)其中,posc表示kohonen层的最佳输出节点;dj表示输入层的第i个输入节点与kohonen层的第j个节点之间的欧氏距离,dj通过公式(3)计算得到。其中,xi表示输入层的第i个输入节点的值。步骤4.6:通过公式(4)寻找posc的邻域节点。nc(t)=(t|find(norm(post,posc)<r)(4)其中,nc(t)表示posc的邻域节点;post表示kohonen层除了posc以外的任一节点;norm(post,posc)表示posc和post之间欧几里得距离;(t|find(norm(post,posc)<r)表示将所有满足norm(post,posc)<r的节点作为posc的邻域节点。步骤4.7:通过公式(5)和(6)对kohonen层的最佳输出节点posc和posc的邻域节点以及对应的输出层节点进行权值修正。ωij=ωij+δmax(xi-ωij)(5)ωjk=ωjk+δmin(yk-ωjk)(6)其中,yk为输出层第k个输出节点的输出值。步骤4.8:使迭代次数l的值自增1,然后重复执行步骤4.2至步骤4.8的操作,直到迭代次数l与maxgen的值相等,结束操作。通过以上步骤的操作,得到训练好的kohonen神经网络模型。步骤五、使用训练好的kohonen神经网络模型,对实验数据进行预测,得到输出向量ym。步骤5.1:收集网络系统中主机存在的漏洞,构造漏洞信息表。所述漏洞信息表包括:漏洞id、主机名称、软件应用名称、主机权重。然后,利用漏洞id得到七元组向量,用符号xn表示第n个漏洞的七元组向量;xn=<s,c,i,u,co,av,au>。所述主机权重是根据主机所在位置及提供的服务,由人为设定的值。步骤5.2:将七元组向量xn=<s,c,i,u,co,av,au>作为输入数据输入训练好的kohonen神经网络模型,s,c,i,u,co,av,au分别对应一个输入节点;步骤5.3:运行训练好的kohonen神经网络模型,得到的输出结果为二元组向量,用符号yn表示,yn=<category,pr>。七元组向量xn与二元组向量yn一一对应。步骤六、构造k-攻击图。步骤6.1:使用步骤五中所述漏洞信息表和二元组向量yn构造漏洞利用表。所述漏洞利用表包括:漏洞id、主机名称、主机操作系统、主机权重、攻击结果(category)和攻击成功率(pr)。然后,在k-攻击图上显示漏洞利用表中全部信息。步骤6.2:根据主机间会话链接表,在k-攻击图上绘制从源主机到目的主机之间的有向边,在有向边上标注攻击成功率(pr)。同时,在每个节点上标注:节点类型、主机名称、攻击结果(category)、主机应用名称和漏洞id。所述节点类型包括:权限(privilege)节点和漏洞利用(vulnerabilityexploit)节点。通过上述步骤的操作,完成k-攻击图。步骤七、根据k-攻击图构造概率矩阵以及最佳原子攻击矩阵。步骤7.1:通过公式(7),计算漏洞利用表中漏洞的权重。其中,wv表示漏洞利用表中第v个漏洞的权重;d表示包含漏洞v的主机的个数;wg为包含漏洞v的第g个主机的权重,g为正整数;f为主机g的第f种权限,f∈[1,h],h为主机g的权限数量;表示利用漏洞v获取主机g的第f种权限对应的评分值;wp为网络系统中的第p台主机权重,从主机权重表中获取,p∈[1,e];e为网络系统中主机的个数。步骤7.2:根据公式(8),构造概率矩阵。其中,pvi′j′表示主机i′利用主机j′中漏洞v的概率,1≤i′,j′≤t,t为网络系统中主机个数与网络系统外部的攻击者主机个数之和;cli′j′表示主机i′与主机j′之间的连通情况,cli′j′∈[0,1],0表示第i′台主机与第j′台主机之间处于未连通状态;1表示第i′台主机与第j′台主机之间处于连通状态;wi′为主机i′的主机权重;wj′为主机j′的主机权重。步骤7.3:从主机i′利用主机j′的各个漏洞的概率中,挑选出最大值,用符号p′ij′表示,然后用p′ij′构成最佳原子攻击矩阵。步骤八、得到最佳攻击路径。步骤8.1:根据最佳原子攻击矩阵,遍历从源节点到目标节点的所有的可能攻击路径,并计算每条攻击路径的攻击概率,挑选出最大值,用符号vhp表示;vhp对应的攻击路径为最大概率攻击路径,用符号hp表示。步骤8.2:根据公式(9),寻找在最大概率攻击路径的邻域路径,用符号hn表示。nh(q)=(q|find(vhp-vq)<r′)(9)其中,r′为最大概率攻击路径的邻域半径,r′通过公式(10)计算得到;(q|find((vhp-vq)<r′))表示将所有满足(vhp-vq)<r′的攻击路径作为最大概率攻击路径hp的邻域路径;nh(q)表示攻击成功率在[vhp-r′,vhp]间的攻击路径,即最佳攻击路径。其中,wh为最大概率攻击路径hp中的主机权重和。本发明提出的基于kohonen神经网络的攻击路径规划方法与已有技术相比较,具有以下优点:①生成的攻击图只保留最可能的攻击节点,避免了状态爆炸问题。②泛化性能强。③最优攻击路径生成速度快。附图说明图1为本发明具体实施方式中基于kohonen神经网络的攻击路径规划方法的流程图;图2为本发明具体实施方式中的网络拓扑图;图3为本发明具体实施方式中的k-攻击图;图4为本发明具体实施方式中的攻击概率矩阵;图5为本发明具体实施方式中最优原子攻击矩阵。具体实施方式根据上述技术方案,下面结合附图和实施实例对本发明进行详细说明。使用本发明提出的基于kohonen神经网络的攻击路径规划方法寻找网络系统中的最佳攻击路径,其操作流程如图1所示,具体操作步骤如下:步骤一、获取网络结构。如图2所示,网络系统中设置了初始的防御策略:外网人员可以访问dmz区中主机h2,h3和h4的浏览器和dns域名。主机h2和h3可以访问h4中的mail服务以及h5和h6上的sql服务。主机h7为ftp服务器,除主机h8外,其它的主机只能读取和下载公开文件,不能修改文件。主机h2,h3和h4都禁止访问管理服务器h8。h8可以访问其它主机上的各种服务。步骤1.1:获取网络系统中各主机的软件应用,建立软件应用与主机名称对应表,如表1所示。表1软件应用与主机对应表软件应用名称主机名称iis7.0h2,h3bind9h4sendmail8.13h4mysql5.7h5,h6serv-u10.5h7ie6.0h8所述网络系统包括内部网络和“非军事化区”(demilitarizedzone,dmz)。所述软件应用与主机对应表包含:软件应用名称和主机名称。步骤1.2:获取网络系统中各主机之间以及网络系统中各主机与网络系统外部的攻击者主机之间的会话链接,建立主机间会话链接表,如表2所示。所述主机间会话链接表包括:源主机名和目标主机名。表2主机间会话链接表步骤二、收集网络系统中主机及漏洞信息。具体为:步骤2.1:收集cve数据库中的漏洞id,并将漏洞id转换成七元组向量,用符号xm表示第m个漏洞的七元组向量;xm=<s,c,i,u,co,av,au>其中,s为cvss漏洞评分;c,i,u分别为漏洞对信息系统的机密性、完整性和可用性影响评分;co是利用漏洞的攻击复杂度评分;av是漏洞攻击向量评分;au代表攻击是否需要身份认证。七元组向量xm根据表3确定。表3输入输出属性取值表属性可能值描述s0~10漏洞的cvss评分c无(0),部分(1),全部(2)漏洞对系统的机密性影响i无(0),部分(1),全部(2)漏洞对系统的完整性影响u无(0),部分(1),全部(2)漏洞对系统的可用性影响co低(1),中(2),高(3)利用漏洞的复杂度av本地(1),远程(2)漏洞的执行类型au无(0),一次(1),多次(2)利用漏洞需要进行身份验证的次数category取值如表5所示成功利用漏洞后获得的权限pr0~1攻击成功率步骤2.2:收集漏洞被利用后产生的概率最大的攻击结果,并用二元组向量表示。所述二元组向量用符号ym表示,ym=<category,pr>。其中,category表示漏洞被利用后,获取漏洞所在主机的权限评分,pr表示攻击成功率。pr根据表4确定。主机的权限类别包括:断开(broken)、连接(connection)、用户权限(user)、管理员权限(root)、拒绝服务攻击(dos)和摧毁(crash),主机的权限评分是根据主机的权限对主机的机密性、完整性和可用性影响,由人为预先设定,本实施例中category根据表5确定。表4攻击成功率赋值标准等级pr描述10.9不需要攻击工具,有详细的攻击方法20.7有可用的攻击工具和详细的攻击方法30.5无攻击工具但有详细的攻击方法40.3弱点信息发布,粗略说明攻击方法50.1弱点信息发布,未给出攻击方法表5主机权限评分表步骤三、建立kohonen神经网络模型。所述kohonen神经网络模型为3层神经网络,分别是:输入层、kohonen层和输出层。其中,输入层包括7个输入节点;输出层包括2个输出节点;kohonen层包括18个节点。步骤四、训练kohonen神经网络模型,得到训练好的kohonen神经网络模型。具体为:步骤4.1:设置kohonen神经网络模型的参数,包括:kohonen层的最大学习率,用符号δmax表示,δmax=0.1;输出层的最小学习率,用符号δmin表示;δmin=0.05;最大邻域,用符号rmax表示,rmax=1.5;最小邻域,用符号rmin表示,rmin=0.4。步骤4.2:为kohonen神经网络模型各节点之间的权值设置初始值。具体为:用符号ωij表示输入层节点到kohonen层节点间的权值,用符号ωjk表示kohonen层节点到输出层节点间的权值,i∈[1,7],j∈[1,n],k∈[1,2],n为kohonen层节点的个数。随机设置ωij和ωjk的值,满足ωij∈(0,1),ωjk∈(0,1)。步骤4.3:设置总迭代次数,用符号maxgen表示,maxgen=10000。设置当前迭代次数,用符号l表示,l的初始值为1。将七元组向量xm=<s,c,i,u,co,av,au>作为输入数据,s,c,i,u,co,av,au分别对应一个输入节点;将二元组向量ym=<category,pr>作为输出数据,category,pr分别对应一个输出节点。步骤4.4:通过自适应函数来对邻域进行调整。自适应函数如公式(1)所示。其中,r为kohonen层的最佳输出节点的邻域半径。步骤4.5:通过公式(2)寻找kohonen层的最佳输出节点。posc=mindj(2)其中,posc表示kohonen层的最佳输出节点;dj表示输入层的第i个输入节点与kohonen层的第j个节点之间的欧氏距离,dj通过公式(3)计算得到。其中,xi表示输入层的第i个输入节点的值。步骤4.6:通过公式(4)寻找posc的邻域节点。nc(t)=(t|find(norm(post,posc)<r)(4)其中,nc(t)表示posc的邻域节点;post表示kohonen层除了posc以外的任一节点;norm(post,posc)表示posc和post之间欧几里得距离;(t|find(norm(post,posc)<r)表示将所有满足norm(post,posc)<r的节点作为posc的邻域节点。步骤4.7:通过公式(5)和(6)对kohonen层的最佳输出节点posc和posc的邻域节点以及对应的输出层节点进行权值修正。ωij=ωij+δmax(xi-ωij)(5)ωjk=ωjk+δmin(yk-ωjk)(6)其中,yk为输出层第k个输出节点的输出值。步骤4.8:使迭代次数l的值自增1,然后重复执行步骤4.2至步骤4.8的操作,直到迭代次数l与maxgen的值相等,结束操作。通过以上步骤的操作,得到训练好的kohonen神经网络模型。步骤五、使用训练好的kohonen神经网络模型,对实验数据进行预测,得到输出向量ym。步骤5.1:收集网络系统中主机存在的漏洞,构造漏洞信息表。所述漏洞信息表包括:漏洞id(cvenumber)、主机名称(host)、软件应用名称(service)、主机权重(weight),所述主机权重是根据主机所在位置及提供的服务,由人为设定的值。本实施例中,漏洞信息表如表6所示。然后,利用漏洞id得到七元组向量,用符号xn表示第n个漏洞的七元组向量;xn=<s,c,i,u,co,av,au>。表6漏洞信息表步骤5.2:将七元组向量xn=<s,c,i,u,co,av,au>作为输入数据输入训练好的kohonen神经网络模型,s,c,i,u,co,av,au分别对应一个输入节点;步骤5.3:运行训练好的kohonen神经网络模型,得到的输出结果为二元组向量,用符号yn表示,yn=<category,pr>。七元组向量xn与二元组向量yn一一对应。步骤六、构造k-攻击图。步骤6.1:使用步骤五中所述漏洞信息表和二元组向量yn构造漏洞利用表。所述漏洞利用表包括:漏洞id(cvenumber)、主机名称(host)、软件应用名称(service)、主机权重(weight)、攻击结果(category)和攻击成功率(pr),具体如表7所示。然后,在k-攻击图上显示漏洞利用表中全部信息。表7漏洞利用表步骤6.2:根据主机间会话链接表,在k-攻击图上绘制从源主机到目的主机之间的有向边,在有向边上标注攻击成功率(pr)。同时,在每个节点上标注:节点类型、主机名称(host)、攻击结果(category)、主机应用名称(service)和漏洞id(cvenumber)。所述节点类型包括:权限(privilege)节点和漏洞利用(vulnerabilityexploit)节点。通过上述步骤的操作,完成k-攻击图,攻击图如图3所示。步骤七、根据k-攻击图构造概率矩阵以及最佳原子攻击矩阵。步骤7.1:通过公式(7),计算漏洞利用表中漏洞的权重。其中,wv表示漏洞利用表中第v个漏洞的权重;d表示包含漏洞v的主机的个数;wg为包含漏洞v的第g个主机的权重,g为正整数;f为主机g的第f种权限,f∈[1,h],h为主机g的权限数量;表示利用漏洞v获取主机g的第f种权限对应的评分值;wp为网络系统中的第p台主机权重,从主机权重表中获取,p∈[1,e];e为网络系统中主机的个数。步骤7.2:根据公式(8),构造概率矩阵。其中,pvi′j′表示主机i′利用主机j′中漏洞v的概率,1≤i′,j′≤t,t为网络系统中主机个数与网络系统外部的攻击者主机个数之和;cli′j′表示主机i′与主机j′之间的连通情况,cli′j′∈[0,1],0表示第i′台主机与第j′台主机之间处于未连通状态;1表示第i′台主机与第j′台主机之间处于连通状态;wi′为主机i′的主机权重;wj′为主机j′的主机权重。概率矩阵如图4所示。图4中,三个轴分别是:源主机名称(sourcehostname)、目标主机名称(targethostname)和概率(probability)。图4中的概率(probability)即pvi′j′。步骤7.3:从主机i′利用主机j′的各个漏洞的概率中,挑选出最大值,用符号p′ij′表示,然后用p′ij′构成最佳原子攻击矩阵。最佳原子攻击(optimalatomicattack)矩阵如图5所示。图5中,三个轴分别是:源主机名称(sourcehostname)、目标主机名称(targethostname)和概率(probability)。图5中的概率(probability)即p′ij′。步骤八、得到最佳攻击路径。步骤8.1:根据最佳原子攻击矩阵,遍历从源节点到目标节点的所有的可能攻击路径,如表8所示,并计算每条攻击路径的攻击概率,挑选出最大值,用符号vhp表示,vhp=0.5402;vhp对应的攻击路径为最大概率攻击路径,用符号hp表示,hp=no.8=(h1→h4→h6)。表6可能攻击路径序号目标节点攻击路径攻击概率1h8(h1,h8)0.13422h5(h1,h2)(h2,h3)(h3,h5)0.38333h5(h1,h2)(h2,h5)0.51874h5(h1,h3)(h3,h5)0.50365h6(h1,h2)(h2,h3)(h3,h4)(h4,h6)0.29546h6(h1,h2)(h2,h4)(h4,h6)0.42077h6(h1,h3)(h3,h4)(h4,h6)0.38868h6(h1,h4)(h4,h6)0.5402步骤8.2:根据公式(9),寻找在最大概率攻击路径的邻域路径,用符号hn表示。nh(q)=(q|find(vhp-vq)<r′)(9)其中,r′为最大概率攻击路径的邻域半径,r′通过公式(4)计算得到,r′=0.4;(q|find((vhp-vq)<r′))表示将所有满足(vhp-vq)<r′的攻击路径作为最大概率攻击路径hp的邻域路径;nh(q)表示攻击成功率在[vhp-r′,vhp]间的攻击路径,即最佳攻击路径:nh(q)=(no.3,no.4,no.8)。其中,wh为最大概率攻击路径hp中的主机权重和。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1