一种基于多域JND模型的视觉感知编码方法与流程
本发明涉及视频信息处理,尤其是涉及一种基于多域jnd模型的视觉感知编码方法。
背景技术:
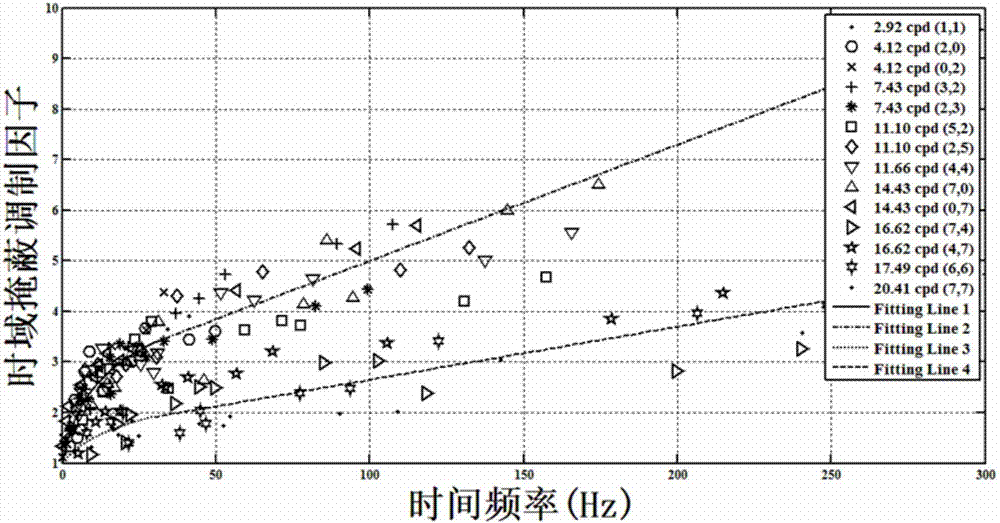
:随着多媒体技术的发展,人们对于视频分辨率的要求越来越高,2k、4k甚至8k的视频都将在不久的将来普及,为了解决这些庞大的视频数据的存储和传输需求,视频编码标准应运而生。而目前最新的视频编码技术基于香农信息论,通过搜索多种编码模式,从中寻找最优的编码方式,而这一过程需要引入大量的计算来提高精确度,但目前随着计算量的提升,其效果提升却趋于平缓,说明基于这一编码思想的编码方式已进入发展的瓶颈期,寻找一种效果和计算量之比较高的编码思想对于未来编码技术的发展显得尤为重要。由于视频的最终接收者是人(人眼),视频编码的根本目的是在保证一定视频质量的前提下尽可能地降低码率,而编码和传输人眼无法察觉的信息显然是对网络传输和存储设备的一种浪费。可以说,视频编码的最终目的是达到人眼感知的保真度而不是像素的保真度。在多年前,人们就已经开始关注人眼系统,但由于其涉及到生理学、心理学等多个学科,相应的基础理论还并不成熟,人眼的一些特性还并不能很好的解释,同时在数字信号处领域,编码压缩率还有可进一步提升的空间,因此到目前为止,所有的编码标准都没有考虑进人眼特性来提高压缩效率。但随着近年来,数字信号处理理论的约束以及人眼相关学科基础理论的发展,研究人员开始重新关注人眼系统,期望将人眼系统中的某些已经明确特性应用到视频编码中,以达到进一步压缩码率的目的。这一研究思想被称为视觉感知编码,即结合人眼视觉系统的某些特性去除视频中的视觉冗余部分,在达到视频的感知保真度的情况下,进一步压缩视频。而目前一些相关的模型也被提出,如基于人眼感知失真的最小可感知失真模型、基于人眼感兴趣区域的视觉显著性模型等。通过这些模型可以表示出人眼视觉信息处理的过程,而寻找能准确表现人眼视觉信息处理过程的模型就是目前视频编码领域所要解决的关键问题,视频编码技术也将因这一问题的解决走出目前发展的瓶颈期。文献[1](luoz,songl等,h.264/advancedvideocontrolperceptualoptimizationcodingbasedonjnd-directedcoefficientsuppression.ieeetransactionsoncircuits&systemsforvideotechnology,2013,23(6):935-948)提出了一种完整的时空频域jnd模型。在jm14.2上测试,在高效配置下节省了28.32%的码率。文献[2](baesh,kimj等,hevc-basedperceptuallyadaptivevideocodingusingadct-basedlocaldistortiondetectionprobabilitymodel.ieeetransactionsonimageprocessing,2016,25(7):3343-3357)提出了一种基于块感知失真概率的编码抑制策略,在满足感知失真概率小于50%的情况下可以进一步压缩码率。在hm11.0上测试,在low-delay配置下节省了12.10%的码率,在random-access配置下节省了9.90%的码率。技术实现要素:本发明的目的在于提供可在保证一定视频质量的前提下,进一步降低基于hevc视频编码的码率,以达到更好的适应高清视频传输和存储需求的一种基于多域jnd模型的视觉感知编码方法。本发明具体实现步骤如下:1)读入一个变换编码块,进行变换编码,判断当前块是否属于亮度分量,若属于,则执行步骤2);否则结束感知编码算法流程;2)计算每个变换系数对应的时空频多域jnd阈值;3)计算变换系数的最合适抑制值ω(i,j);4)进行变换系数幅值的抑制,按下式计算:其中c(i,j)表示原始变换系数,c*(i,j)表示经过抑制之后的变换系数;5)将抑制之后的变换系数经过量化及熵编码之后的码流大小作为新的码流大小加入率失真优化公式中,如下式表示:之后转到步骤1)。在步骤2)中,所述计算每个变换系数对应的时空频多域jnd阈值的具体方法可为:(1)计算每个变换系数的空域基本jnd阈值jbase,按下式计算:其中,jd(ω)和jv(ω)表示对角线和垂直方向的空频域基本最小可感知阈值模型,表示dct系数方向角,分别按下式计算:jd(ω)=0.0293ω2-0.1382ω+1.75jv(ω)=0.0238ω2-0.1771ω+1.75其中,ω表示位于(i,j)位置系数的空间频率,按下式计算:其中,rvd表示观察距离和图像高度的比例,pich表示图像高度所包含的像素数量;(2)计算每个变化系数的亮度自适应掩蔽调制因子mlm,按下式计算:其中μp表示变换块的平均亮度强度,m0.1(ω)和m0.9(ω)分别表示μp为0.1和0.9时的mlm,分别按下式计算:m0.1(ω)=2.468×10-4×ω2+4.466×10-3×ω+1.14m0.9(ω)=1.230×10-4×ω2+1.433×10-2×ω+1.34其中n表示dct块的大小;k为像素深度,在8bit的图像中为255;i(i,j)表示i列j行的像素强度;(3)计算每个变换系数的对比掩蔽效应调制因子mcm,按下式计算:mcm(ω,τsci)=f(ω)·τsci+1其中τsci表示变换块平均结构强度,f(ω)表示在不同τsci下mcm和ω的关系式,分别由下式计算:其中c(ω)代表空间频率为ω的dct系数值,f(ω)中的各个常量系数如下所示:0≤ω<ω0:ε=8.03,γ=4.55,η=29.37ω≥ω0:ε=31.17,γ=9.44,η=6.23;(4)计算每个变换系数的时域掩蔽调制因子mtm,按下式计算:其中ft表示时间频率,按下式计算:ft=fsx·vx+fsy·vy其中,fsx和fsy分别表示水平和垂直方向的空间频率,vx和vy分别表示物体在人眼视网膜平面上的水平和垂直运动速度,单位是度/秒,分别如下式计算:fsx=i/2nθfsy=j/2nθvτ=viτ-veτ,(τ=x,y)其中viτ和veτ分别表示物体在图像平面上的运动速度和眼球的运动速度;veτ通过如下计算:其中,gspem表示人眼运动平滑的修正值,这里设为0.84;vmin表示眼球漂移运动的最小值,这里设为0.15度/秒;vmax表示眼球扫视的最大速度,这里设为80度/秒;而物体在图像平面上的运动速度viτ表示为:viτ=fr·mvτ·θ,(τ=x,y)其中fr表示帧率,mvτ表示某个变换块的水平和垂直运动矢量,在编码过程中获得。(5)计算每个变换系数的最小可感知失真阈值jndst,按下式计算:在步骤3)中,所述计算变换系数的最合适抑制值ω(i,j)的具体方法可为:(1)初始化k=0,计算db(k),令dbx=db(k):δc(i,j)=|c(i,j)-q-1(q(c*(i,j)))|(2)判断:若dbx≥1,k=0,则直接转到步骤(5);否则转到步骤(3);(3)若k小于1,则计算db(k+0.5),然后令dby=db(k+0.5);否则计算db(k+1)然后令dby=db(k+1);(4)判断:①当dbx<1且dby≥1,按下式计算k,然后转到步骤(5);α=dby-dbx,(k=0,0.5,1,2,3)β=dbx-α·k,(k=0,0.5,1,2,3)k=(1-β)/α②当dbx=dby,取当前k作为最合适的k值,然后转到步骤(5);③当k=2时,取k=3作为最合适的k值,然后转到步骤(5);若k小于1,则将k+0.5;否则将k+1;令dbx=dby,然后执行步骤(3);(5)按下式计算每个变换系数最合适的抑制值ω(i,j):本发明适用于所有采用香农率失真优化模式选择的编码标准,对视频进行压缩时,提供一种包含视觉感知特征的编码压缩算法,其优点在于:1、相比于传统的编码方式,该算法可以有效去除视频中的人眼的感知冗余,进一步压缩码流。2、本发明可以在满足块感知失真概率小于0.5的情况下,进一步压缩码率,同时在量化参数较大时,有效改善视频的主观质量。3、可以兼容所有采用香农率失真优化模式选择的编码标准,包括最新的hevc编码标准,同时可以根据需要灵活选择jnd模型中包含的各部分。本发明提出的视觉感知编码算法,基于一种新型的时空频多域jnd模型和一种新型的编码抑制策略,从每个变换系数的jnd阈值和块感知失真概率两方面进行优化,在保证一定主观质量的前提下,使得基于hevc视频编码的码率进一步得到降低。附图说明图1为本发明时域掩蔽调制因子mtm建模示意图;图2为本发明编码抑制策略计算k值流程图;图3为本发明加入感知编码算法hevc率失真过程示意图。具体实施方式本发明提供一种基于多域jnd模型的视觉感知编码算法,包括多域jnd模型和编码抑制策略两部分。整个多域jnd模型包含时空频三部分,其中频域模型只与变换块不同位置系数的空间频率和观察视角有关,用来计算基本jnd阈值;空域模型包含亮度掩蔽调制因子和对比掩蔽调制因子两部分,其中亮度掩蔽调制因子与变换块的平均亮度和空间频率有关,用来修正人眼对于不同亮度下的失真敏感度,对比掩蔽调制因子与变换块的平均纹理强度和空间频率有关,用来修正人眼对于不同纹理背景下的失真敏感度;时域模型包含时域掩蔽调制因子这部分,与视频中物体的运动矢量、帧率以及空间频率有关,用来修正人眼对于不同物体运动强度下的失真敏感度。对于编码抑制策略,从块感知失真概率角度出发,在感知失真概率小于0.5的情况下进行变换系数幅值的抑制,可以解决两个问题:1、当变换块中某些变换系数幅值小于其对应的jnd阈值,整个变换块中的其他非零系数可以进行进一步抑制来降低码率;2、当量化参数较大时,可以改善视频的主观质量。本发明正是基于这两点,提出一种块感知失真的编码抑制策略。目前最新的hevc编码技术的压缩思想主要从视频中的时空冗余信息以及统计冗余信息入手,进行数字信号方面的压缩。这种方式主要依靠计算量来换取编码性能的提升。但由于目前信号处理方面基础理论的约束,继续采用该思想来提高编码压缩率,其性能提升速度已日趋平缓,而其计算量却在迅速提升,其性能和计算量之比正在逐渐减小。本发明提出的视觉感知编码算法结合人眼感知失真特性,达到去除视频中感知冗余信息的目的。本发明提出一种基于多域jnd模型的视觉感知编码算法,具体包括如下步骤:步骤一、读入一个变换编码块,进行变换编码,判断当前块是否属于亮度分量,如果属于,执行步骤二,否则结束感知编码算法流程。步骤二、计算每个变换系数对应的时空频多域jnd阈值,具体包括:步骤a1:计算每个变换系数的空域基本jnd阈值jbase,按下式计算:其中,jd(ω)和jv(ω)表示对角线和垂直方向的空频域基本最小可感知阈值模型,表示dct系数方向角,分别按下式计算:jd(ω)=0.0293ω2-0.1382ω+1.75jv(ω)=0.0238ω2-0.1771ω+1.75其中,ω表示位于(i,j)位置系数的空间频率,按下式计算:其中,rvd表示观察距离和图像高度的比例,pich表示图像高度所包含的像素数量。步骤a2:计算每个变化系数的亮度自适应掩蔽调制因子mlm,按下式计算:其中μp表示变换块的平均亮度强度,m0.1(ω)和m0.9(ω)分别表示μp为0.1和0.9时的mlm,分别按下式计算:m0.1(ω)=2.468×10-4×ω2+4.466×10-3×ω+1.14m0.9(ω)=1.230×10-4×ω2+1.433×10-2×ω+1.34其中n表示dct块的大小;k为像素深度,在8bit的图像中为255;i(i,j)表示i列j行的像素强度。步骤a3:计算每个变换系数的对比掩蔽效应调制因子mcm,按下式计算:mcm(ω,τsci)=f(ω)·τsci+1其中τsci表示变换块平均结构强度,f(ω)表示在不同τsci下mcm和ω的关系式,分别由下式计算:其中c(ω)代表空间频率为ω的dct系数值,f(ω)中的各个常量系数如下所示:0≤ω<ω0:ε=8.03,γ=4.55,η=29.37ω≥ω0:ε=31.17,γ=9.44,η=6.23步骤a4:计算每个变换系数的时域掩蔽调制因子mtm,按下式计算:其中ft表示时间频率,按下式计算:ft=fsx·vx+fsy·vy其中,fsx和fsy分别表示水平和垂直方向的空间频率,vx和vy分别表示物体在人眼视网膜平面上的水平和垂直运动速度,单位是度/秒,分别如下式计算:fsx=i/2nθfsy=j/2nθvτ=viτ-veτ,(τ=x,y)其中viτ和veτ分别表示物体在图像平面上的运动速度和眼球的运动速度。veτ可以通过如下计算:其中,gspem表示人眼运动平滑的修正值,这里设为0.84;vmin表示眼球漂移运动的最小值,这里设为0.15度/秒;vmax表示眼球扫视的最大速度,这里设为80度/秒。而物体在图像平面上的运动速度viτ可以表示为:viτ=fr·mvτ·θ,(τ=x,y)其中fr表示帧率,mvτ表示某个变换块的水平和垂直运动矢量,可以在编码过程中获得。步骤a5:计算每个变换系数的最小可感知失真阈值jndst,按下式计算:步骤三、计算变换系数的最合适抑制值ω(i,j),具体包括:步骤b1:初始化k=0,计算db(k),令dbx=db(k):δc(i,j)=|c(i,j)-q-1(q(c*(i,j)))|步骤b2:判断:如果dbx≥1,k=0,直接转到步骤b5;否则转到步骤b3;步骤b3:如果k小于1,计算db(k+0.5)然后令dby=db(k+0.5),否则计算db(k+1)然后令dby=db(k+1);步骤b4:判断:①当dbx<1且dby≥1,按下式计算k,然后转到步骤b5;α=dby-dbx,(k=0,0.5,1,2,3)β=dbx-α·k,(k=0,0.5,1,2,3)k=(1-β)/α②当dbx=dby,取当前kk作为最合适的kk值,然后转到步骤b5;③当k=2时,取k=3作为最合适的k值,然后转到步骤(5);若k小于1,则将k+0.5;否则将k+1;令dbx=dby,然后执行步骤b3;步骤b5:按下式计算每个变换系数最合适的抑制值ω(i,j):步骤四、进行变换系数幅值的抑制,按下式计算:其中c(i,j)表示原始变换系数,c*(i,j)表示经过抑制之后的变换系数。步骤五、将抑制之后的变换系数经过量化及熵编码之后的码流大小作为新的码流大小加入率失真优化公式中,如下式表示:之后转到步骤一。需要指出的是,本发明的步骤依据是,人眼对于不同的空间频率、不同的亮度、不同的纹理强度以及不同的物体运动强度都具有不同的敏感度,首先通过频域模型计算出一个人眼对于不同空间频率下的基本敏感度阈值,然后加入空域和时域的模型,对该基本敏感度阈值进行修正,最后可以得出包含时空频域因素的jnd阈值。此外,由于人眼观看视频并不是一个像素一个像素的看的,至少是基于某个图像块看的,因此,本发明中的编码抑制策略从块感知失真角度出发,在感知失真概率小于0.5的情况下,可以进一步抑制码率,同时,在量化参数较大的情况下可以有效改善视频的主观质量。以新一代视频编码标准hevc提供的参考软件hm16.9为基准,搭建嵌入感知编码算法的编码系统来衡量本发明方法的效果。选取6个测试序列作为测试视频场景,包括1920×1080(fullhighdefinition,fhd)和832×480(widequartervideographicsarray,wqvga)这两种分辨率,分别对应目前主流的超清和标清分辨率。1920×1080分辨率的包括“bqterrace”、“basketballdrive”和“tennis”这三个场景;832×480分辨率的包括“bqmall”、“partyscene”和“keiba”这三个场景。编码器参数设置为:randomaccess编码模式,选取量化参数qp值22,27,32,每个场景分别根据其帧率编码播放3秒钟长度的视频帧数,帧内预测周期intraperiod设置为32,其余默认设置。对于感知编码算法的性能,使用客观评价标准码率减少百分比(δr)和主观评价标准dmos(differentialmeanopinionscore)分别来评价各算法的编码压缩效果和视频主观质量,分别定义如下:δr=(rhm-rpvc)/rhm×100dmos=mospvc-moshm其中,rhm和rpvc分别代表原始hm编码器编码得出的码率和采用某种感知编码算法(包括luo、bae和本发明的算法)编码之后得出的码率。对于dmos的计算,采用双激励损伤等级(doublestimulusimpairmentscale,dsis)测试方式,该方式由国际电信联盟itu-r提出,被广泛用于视频的主观质量测试。具体的主观实验条件和评分等级如表1和表2所示。表1显示器40寸lcd电视分辨率1920x1080(全高清)测试人员数量8人(2女6男)观测距离4倍电视高度(约2m)观测时间20分钟休息间隔10分钟表2本发明方法与软件hm16.9所采用的hevc原始算法以及luo、bae的算法进行比较,结果如表3所示。表3从表3可以看出,本发明的一种基于多域jnd模型的视觉感知编码算法效果良好,luo的感知编码算法平均码率降低为12.46%,bae的感知编码算法平均码率降低为5.48%,本发明提出的感知编码算法平均码率降低为13.60%,本发明的感知算法在编码压缩率方面为三种算法中最高;此外,对于dmos,luo的算法为-0.65,bae的算法为-0.35,本发明提出的算法为-0.29,本发明的感知算法在主观质量方面为三种算法中最好。说明本发明提出的算法在码率压缩和感知质量方面要明显优于另外两种算法。经过以上的分析实验验证,可以得出以下结论:本发明提出的基于多域jnd模型的视觉感知编码算法,其理论依据正确,实际应用可行,有助于实现视频编码码率的进一步压缩。以上所述仅为本发明的较佳实施用例而已,并非用于限定本发明的保护范围。凡在本发明的精神和原则在内,所做的任何修改、等同替换以及改进等,均应包含在本发明的保护范围之内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1