一种基于改进人工蜂群算法的OFDM信号峰均比降低方法与流程
本发明涉及通信
技术领域:
,更具体地,涉及ofdm时域信号峰均比(papr)的降低方法。
背景技术:
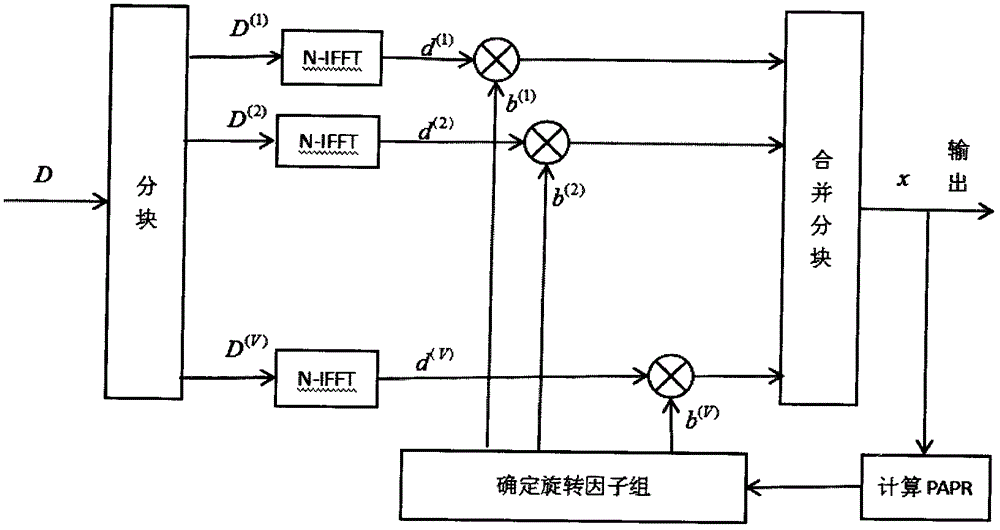
:正交频分复用(ofdm)技术作为第四代无线通信的核心技术,是一种有效对抗频率选择性衰落和窄带干扰的高速传输技术。在ofdm系统中,由于发射信号是许多调制信号的和,当每个子载波上的符号同相时,发射信号的峰值功率会比其平均功率高许多。这就要求发射端的功率放大器必须有很大的线性工作区域,导致功率放大器效率低。作为ofdm系统的主要问题之一的高峰值平均功率比问题一直是学术界的研究重点。在ofdm信号抑制papr研究领域中,部分传输序列(pts)是其中效果显著的一种方法。近年来,人工蜂群算法(abc)被用于数值优化问题与pts结合来搜索更好的相位因子组。然而,由于现有的人工蜂群=部分传输序列(abc-pts)的邻域探索策略存在解不更新的现象,导致计算冗余,影响papr抑制性能。技术实现要素:为了克服现有技术存在的不足,本发明提出了一种基于改进人工蜂群算法的ofdm信号峰均比降低方法。为了实现上述目的,本发明提出的方法具体步骤如下:a)初始化系统参数limit及最大递推数;b)随机产生大小为s的初始解ai,i=1,2,...,s,每个解代表一个食物源,也表示一个旋转因子组bi=[bi1,bi2,...,biv]t,计算每个食物源的适应度(花蜜数量),食物源适应度计算公式如下:其中f(bi)为旋转因子组bi对应的papr。将适应度较大的s/2个解作为雇佣蜂解,其余s/2作为旁观蜂解;c)对于每个雇佣蜂解bi,进行邻域解探索:在其他雇佣蜂解中随机选取一个bk作为学习对象,再随机决定学习方向和解更新的维度l,改动雇佣蜂解维度l的值得到欲探索的邻域解并计算此邻域解对应的适应度,若适应度大于雇佣蜂解,那么该雇佣蜂解更新为此邻域解;其中,步骤c)的具体求法如下:i.解更新的维度l的确定:对当前食物源bi与另一个雇佣蜂(即学习对象)的位置bk,先进行差异统计,将bi与bk相比具有相同值的维度与不同值的维度序号记录到两个集合dsame和ddif中,dsame中记录具有相同值的维度,ddif记录具有不同值的维度序号。即dsame={d1,d2,...,dm}中的任一元素dx使得ddif={d1,d2,...,dn}中的任一元素dx使得显然m+n=v。接着确定学习方向,产生一个[0,1]的伪随机数a,若a≤0.5则靠近学习对象(正向学习),否则远离学习对象(反向学习)。然后确定更新维度,若学习方向是正向学习,那么l=rand(ddif)表示在ddif中随机中随机选取一个维度l;若学习方向是方向学习,那么l=rand(dsame)10.表示在dsame中随机中随机选取一个维度l。特别的,若ddif中无元素,那么就确定为反向学习,在dsame中随选取一个维度l;若dsame中午元素,那么就确定为正向学习,在ddif中随机选取一个维度l。ii.更新策略:欲探索的新食物源位置b′i是在bi的基础上,改动维度l的值bil。如果学习方向是正向学习,那么b′il=bkl如果是反向学习,那么b′il=nrand(r,bkl)其中,nramd表示在解空间r中随机选取非bil的一个解。d)对于每个雇佣蜂解计算各自被选概率计算公式为:e)对于每个旁观蜂,根据步骤d)计算的概率通过轮盘赌的方式选择一个雇佣蜂解,自身变成这个雇佣蜂解之后,利用与步骤c)中雇佣蜂的邻域探索策略相同的方式决定探索的邻域解,计算此邻域解对应的适应度,若适应度大于雇佣蜂解那么该雇佣蜂解更新为此邻域解;f)记录最好的雇佣蜂解;g)对于每个雇佣蜂解,观察他们不曾更新的迭代次数,如果达到limit次,那么抛弃这个雇佣蜂解,在解空间内随机生成一个解替代这个雇佣蜂解;h)这个过程循环执行,直到迭代次数达到了最大递推数时算法结束;以现有的技术相比,本发明的有益效果为:本发明的邻域探索策略可以保证迭代后一代b′i与当前代bi不相同,成功避免了abc-pts的解不更新的问题。另一方面,随机决定正向学习与反向学习的做法保持了标准人工蜂群算法的探索思想。附图说明图1传统的pts的基本原理框图图2改进的abc-pts算法流程图图图3邻域解探索策略流程图图4改进的abc-pts与abc-pts的papr性能比较图5改进的abc-pts与abc-pts的平均papr收敛情况比较具体实施方式下面结合附图对本发明做进一步的描述,以便对本发明方法的技术特征及优点进行更深入的诠释。但本发明的实施方式并不限于此。本发明提供一种基于改进人工蜂群算法的ofdm信号峰均比降低方法,具体实施步骤如下:1.降低ofdm的papr的abc-pts的步骤a)首先,确定ofdm频域数据信号d={d1,d2,...,dn-1}和长度n,确定平均分割块数v,分块为{d(v)|v=1,2,...,v},其中d(v)表示第个v分块,显然,b)对每个分块进行n点的ifft计算:d(v)=ifft(d(v))c)引入复数旋转因子组b={bv|v=1,2,...,v}作为辅助信息,其中其中,k为旋转因子可选值的个数。用步骤b)得到的各个分块的时域信号d(v)分别乘以对应的旋转因子组bv后进行加和得到总的时域信号x,如图1所示,x满足:c)x的峰均比计算公式为:2.采用改进的abc-pts找到最佳旋转因子组bp,bp满足:最佳旋转因子即最优解搜索算法如图2所示:a)初始化系统参数limit及最大递推数;b)随机产生大小为s的初始解ai,i=1,2,...,s,每个解代表一个食物源,也表示一个旋转因子组bi=[bi1,bi2,...,biv]t,计算每个食物源的适应度(花蜜数量),食物源适应度计算公式如下:其中f(bi)为旋转因子组bi对应的papr。将适应度较大的s/2个解作为雇佣蜂解,其余s/2作为旁观蜂解;c)对于每个雇佣蜂解bi,进行邻域解探索:在其他雇佣蜂解中随机选取一个bk作为学习对象,再随机决定学习方向和解更新的维度l,改动雇佣蜂解维度l的值得到欲探索的邻域解并计算此邻域解对应的适应度,若适应度大于雇佣蜂解,那么该雇佣蜂解更新为此邻域解;其中,步骤c)的具体求法如图3所示:ii.解更新的维度l的确定:对当前食物源bi与另一个雇佣蜂(即学习对象)的位置bk,先进行差异统计,将bi与bk相比具有相同值的维度与不同值的维度序号记录到两个集合dsame和ddif中,dsame中记录具有相同值的维度,ddif记录具有不同值的维度序号。即dsame={d1,d2,...,dm}中的任一元素dx使得ddif={d1,d2,...,dn}中的任一元素dx使得显然m+n=v。接着确定学习方向,产生一个[0,1]的伪随机数a,若a≤0.5则靠近学习对象(正向学习),否则远离学习对象(反向学习)。然后确定更新维度,若学习方向是正向学习,那么l=rand(ddif)表示在ddif中随机中随机选取一个维度l;若学习方向是方向学习,那么l=rand(dsame)表示在dsame中随机中随机选取一个维度l。特别的,若ddif中无元素,那么就确定为反向学习,在dsame中随选取一个维度l;若dsame中午元素,那么就确定为正向学习,在ddif中随机选取一个维度l。ii.更新策略:欲探索的新食物源位置b′i是在bi的基础上,改动维度l的值bil。如果学习方向是正向学习,那么b′il=bkl如果是反向学习,那么b′il=nrand(r,bkl)其中,nramd表示在解空间r中随机选取非bil的一个解。d)对于每个雇佣蜂解计算各自被选概率计算公式为:e)对于每个旁观蜂,根据步骤d)计算的概率通过轮盘赌的方式选择一个雇佣蜂解,自身变成这个雇佣蜂解之后,利用与步骤c)中雇佣蜂的邻域探索策略相同的方式决定探索的邻域解,计算此邻域解对应的适应度,若适应度大于雇佣蜂解那么该雇佣蜂解更新为此邻域解;f)记录最好的雇佣蜂解;g)对于每个雇佣蜂,观察他们不曾更新的迭代次数,如果达到limit次,那么抛弃这个雇佣蜂解,在解空间内随机生成一个解替代这个雇佣蜂解;h)这个过程循环执行,直到迭代次数达到了最大递推数时算法结束;3.选用步骤2搜索的最好雇佣蜂解组合即最佳旋转因子组bp,得到最终进行传输的子载波数据xp,则xp满足:下面例举一个具体实施的例子,并对其进行仿真实验,首先设定如下参数:表1参数设置ofdm符号个数104ofdm子载波数n128调制方式16qam相位因子候选数k2迭代次数g30limit3种群大小s30以papr的ccdf衡量改进的abc-pts抑制papr的性能,结合表1的参数设置,改进的abc-pts和abc-pts参数设置相同,为了更客观的比较,计算机还仿真了原始的最优解(opts)以及原始信号(original)的papr的ccdf,如图4所示。当pr(papr>papr0)=10-3时,原始的ofdm信号的papr是10.54db,opts可将papr降低到5.11db,abc-pts方法可将papr降低到5.87db,而本文提出的改进的abc-pts可以将papr降低到5.60db。与原始信号相比,改进的abc-pts的papr降低了4.94db;与abc-pts相比,改进的abc-pts获得了0.27db的减少量。而在计算复杂度方面,用穷举搜索的opts的计算复杂度为kv-1=216-1=32768次搜索,改进的abc-pts复杂度和abc-pts算法相当,搜索次数为sg=30×30=900。图5给出了改进的abc-pts与abc-pts的papr性能与迭代次数的关系。纵坐标是实验10000次的papr的平均数。改进的abc-pts在迭代次数从1到30的情况下降低papr的性能都优于abc-pts。迭代20次的情况下,abc-pts平均papr是5.249db,而改进的abc-pts平均papr是5.018db,降低了0.231db。迭代50次的情况下,abc-pts平均papr是5.062db,而改进的abc-pts平均papr是4.889db,降低了0.173db。另外,改进的abc-pts在迭代50次的情况比迭代20次的情况平均papr仅仅降低了0.129db,而计算复杂度却增加了1.5倍。因此对于本发明提出的改进的abc-pts算法,递推数设置为20是一个比较合适的选择。以上所述的本发明的实施方式,并不构成对本发明保护范围的限定。任何在本发明的精神原则之内所作出的修改、等同替换和改进等,均应包含在本发明的权利要求保护范围之内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1