一种基于深度强化学习的非正交接入上行传输时间优化方法与流程
本发明属于通信领域,一种基于深度强化学习的非正交接入上行传输时间优化方法。
背景技术:
移动互联网业务的快速发展,对蜂窝无线接入网造成了巨大的流量压力。由于有限的无线资源,利用非正交接入技术使移动用户同时共用同一信道为无线接入提供一种有效的方法,实现在未来的5g网中超高吞吐量和大规模连接的目标。
技术实现要素:
为了克服现有技术的上行传输时间较长、所有移动用户总能量消耗较大的不足,本发明提供一种最小化上行传输时间与所有移动用户总能量消耗的基于深度强化学习的非正交接入上行传输时间优化方法,本发明针对上行传输时间过大的难点,主要考虑的是利用非正交接入技术来传输数据,研究了一种基于深度强化学习的非正交接入上行传输时间优化方法。
本发明解决其技术问题所采用的技术方案是:
一种基于深度强化学习的非正交接入上行传输时间优化方法,包括以下步骤:
(1)在基站的覆盖范围下总共有i个移动用户,移动用户用集合
在保证发送完成所有移动用户数据量的条件下,最小化上行传输时延和所有移动用户总能耗的优化问题描述为如下所示的优化问题orrcm(overallradioresourceconsumptionminimization)问题,orrcm指的是整体无线资源消耗最小化:
orrcm:
0≤t≤tmax(1-3)
variables:t
下面将问题中的各个变量做一个说明,如下:
α:上行传输时间的权重因子;
β:上行传输总能量消耗的权重因子;
t:移动用户发送数据到基站的上行传输时间,单位是秒;
w:移动用户到基站的信道带宽,单位是赫兹;
n0:信道背景噪声的频谱功率密度;
gib:移动用户i到基站的信道功率增益;
tmax:移动用户发送数据到基站的最大上行传输时间,单位是秒;
(2)orrcm问题表示如下:
orrcm:
s.t.constraint(1-1)
constraint(1-2)
variable:0≤t≤tmax
orrcm问题是在给定移动用户上传量
(3)通过强化学习算法来寻找一个最优的上行传输时间记为t*,该强化学习系统由智能体和环境所组成;所有移动用户的上行传输时间t和每个移动用户的最小发射功率
qθ(xt,a)=r(xt,a)+γmaxqθ′(xt+1,a′)(1-5)
其中,各参数定义如下:
θ:评估网络中的参数;
θ′:目标网络中的参数;
xt:在时刻t,系统所处状态;
qθ(xt,a):在状态xt下采取动作a所得到的q值;
r(xt,a):在状态xt下采取动作a所得到的奖励;
γ:奖励衰减比重;
(4)所有移动用户的上行传输时间t和每个移动用户的最小发射功率
强化学习的迭代过程为:
步骤4.1:初始化强化学习中的评估网络,目标网络和记忆库,当前系统状态为xt,t初始化为1,迭代次数k初始化为1;
步骤4.2:当k小于或等于给定迭代次数k时,随机选择一个概率p;
步骤4.3:如果p小于或等于ε;则选择评估网络所输出的动作a(t),否则随机选择一个动作;
步骤4.4:采取动作a(t)后,得到奖励r(t)和下一步状态x(t+1),并将这些信息按照格式(x(t),a(t),r(t),x(t+1))保存在记忆库中;
步骤4.5:结合目标网络的输出,计算评估网络的目标
y=r(xt,a)+γmaxqθ′(xt+1,a′);
步骤4.6:最小化误差(y-q(x(t),a(t);θ))2,同时更新评估网络的参数θ,使得其下次能预测得更准;
步骤4.7:每隔s步,将评估网络的参数赋值给目标网络,同时令k=k+1,回到步骤4.2;
步骤4.8:当k大于给定迭代次数k时,学习过程结束,得到最优的上行传输时间t*,使得有最优的整体无线资源消耗(包括上行传输时间与所有移动用户总能量消耗)。
本发明的技术构思为:首先,考虑在蜂窝无线网络中,移动用户通过非正交接入技术传输数据实现最小化上行传输时间与所有移动用户总能量消耗来获得一定的经济效益和服务质量。在此处,考虑的前提是移动用户的上传能量消耗及上行传输时间的限制。在保证发送完成所有移动用户数据量的条件下,实现最小化整体无线资源消耗。
本发明的有益效果主要表现在:1、对于上行整体而言,利用非正交接入技术大大提高了系统传输效率;2、对于移动用户而言,通过非正交接入技术获得更优质的无线网络体验质量;3、通过深度强化学习得到最优的上行传输时间t*,使得有最优的整体无线资源消耗(包括上行传输时间与所有移动用户总能量消耗)。
附图说明
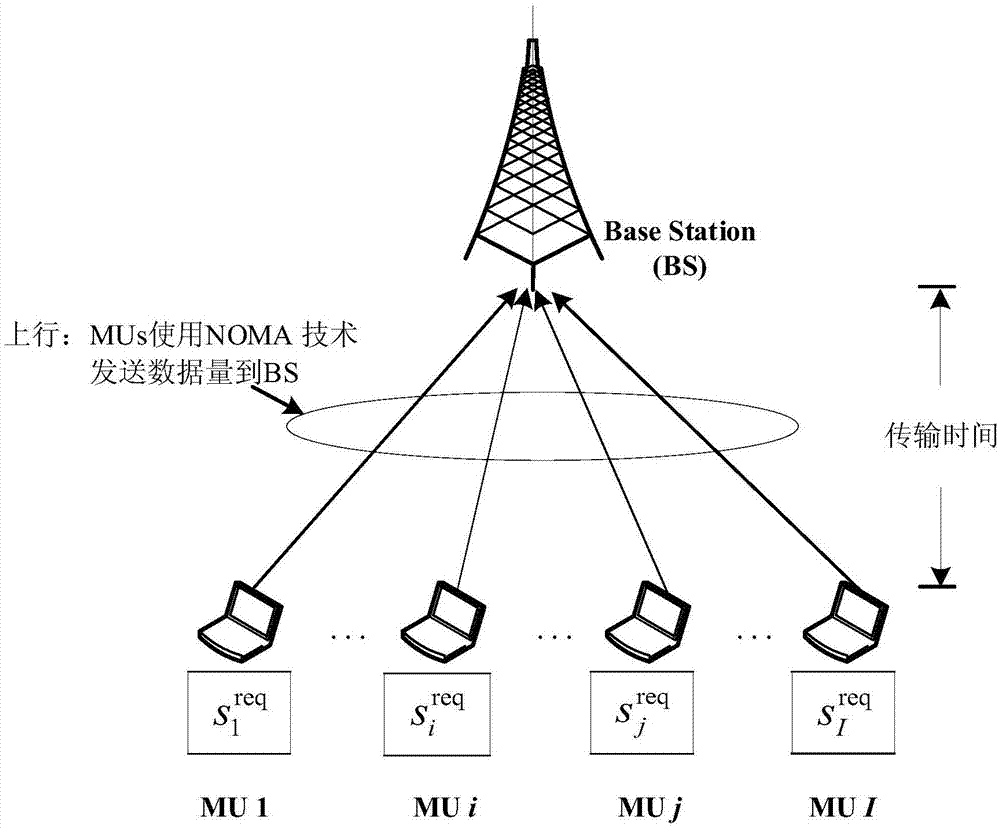
图1是无线网络中多个移动用户和基站的上行场景示意图。
图2是找到最优的上行传输时间t*的方法流程图。
具体实施方式
下面结合附图对于本发明作进一步详细描述。
参照图1和图2,一种基于深度强化学习的非正交接入上行传输时间优化方法,实行该方法能在同时保证发送完成所有移动用户数据量的条件下,使得上行传输时间与所有移动用户总能量消耗最小化,提高整个系统的无线网络体验质量。本发明可以应用于无线网络,如图1所示场景中。针对该目标设计对问题的优化方法主要包括如下步骤:
(1)在基站的覆盖范围下总共有i个移动用户,移动用户用集合
在保证发送完成所有移动用户数据量的条件下,最小化上行传输时延和所有移动用户总能耗的优化问题描述为如下所示的优化问题orrcm(overallradioresourceconsumptionminimization)问题,orrcm指的是整体无线资源消耗最小化:
orrcm:
0≤t≤tmax(1-3)
variables:t
下面将问题中的各个变量做一个说明,如下:
α:上行传输时间的权重因子;
β:上行传输总能量消耗的权重因子;
t:移动用户发送数据到基站的上行传输时间,单位是秒;
w:移动用户到基站的信道带宽,单位是赫兹;
n0:信道背景噪声的频谱功率密度;
gib:移动用户i到基站的信道功率增益;
tmax:移动用户发送数据到基站的最大上行传输时间,单位是秒;
(2)orrcm问题表示如下:
orrcm:
s.t.constraint(1-1)
constraint(1-2)
variable:0≤t≤tmax
orrcm问题是在给定移动用户上传量
(3)通过强化学习算法来寻找一个最优的上行传输时间记为t*,该强化学习系统由智能体和环境所组成;所有移动用户的上行传输时间t和每个移动用户的最小发射功率
qθ(xt,a)=r(xt,a)+γmaxqθ′(xt+1,a′)(1-5)
其中,各参数定义如下:
θ:评估网络中的参数;
θ′:目标网络中的参数;
xt:在时刻t,系统所处状态;
qθ(xt,a):在状态xt下采取动作a所得到的q值;
r(xt,a):在状态xt下采取动作a所得到的奖励;
γ:奖励衰减比重;
(4)所有移动用户的上行传输时间t和每个移动用户的最小发射功率
强化学习的迭代过程为:
步骤4.1:初始化强化学习中的评估网络,目标网络和记忆库,当前系统状态为xt,t初始化为1,迭代次数k初始化为1;
步骤4.2:当k小于或等于给定迭代次数k时,随机选择一个概率p;
步骤4.3:如果p小于或等于ε;则选择评估网络所输出的动作a(t),否则随机选择一个动作;
步骤4.4:采取动作a(t)后,得到奖励r(t)和下一步状态x(t+1),并将这些信息按照格式(x(t),a(t),r(t),x(t+1))保存在记忆库中;
步骤4.5:结合目标网络的输出,计算评估网络的目标
y=r(xt,a)+γmaxqθ′(xt+1,a′);
步骤4.6:最小化误差(y-q(x(t),a(t);θ))2,同时更新评估网络的参数θ,使得其下次能预测得更准;
步骤4.7:每隔s步,将评估网络的参数赋值给目标网络,同时令k=k+1,回到步骤4.2;
步骤4.8:当k大于给定迭代次数k时,学习过程结束,得到最优的上行传输时间t*,使得有最优的整体无线资源消耗(包括上行传输时间与所有移动用户总能量消耗)。
- 还没有人留言评论。精彩留言会获得点赞!