重复场景图像分组方法与流程
本发明涉及图像编辑领域,尤其涉及一种重复场景图像分组方法。
背景技术:
字幕、音频、画面是视频数据的三个重要分支。音频独立于字幕和画面之外,而字幕通常叠加在画面的特定位置。
为了实现对字幕的自动加载,以能够根据时间确定每一个画面加载的字幕的位置和内容,现有技术中采取了字幕机以用于图像编辑中,然而,字幕机的功能仅仅限于字幕编辑本身,其智能化水平仍有上升的空间,例如,现有技术中的字幕机无法基于其加载的画面中主要人物的人种自动切换要加载的字幕内容的语言类型。
技术实现要素:
为了解决现有技术中图像编辑人员无法识别待编辑图像播放文字的技术问题,本发明提供了一种重复场景图像分组方法。
为此,本发明至少具有以下两个重要发明点:
(1)基于现场编辑人员的人种信息和图像内容中的人种信息,获取视频画面上播放的文字的语言类型和与视频画面同步播放的音频的语言类型,满足了现场编辑人员的编辑需求;
(2)对图像中的脉冲干扰和脉动干扰分别进行识别,以分别获得所述图像中的各个脉冲干扰信号和所述图像中的各个脉动干扰信号,对上述干扰信号的幅值进行比较以为所述图像选择与图像内容相适应的滤波机制,以防止图像滤波缺乏针对性。
根据本发明的一方面,提供一种重复场景图像分组方法,该方法包括运行一种重复场景图像分组平台来分组重复场景图像,所述重复场景图像分组平台包括:编辑人员识别设备,用于对视频编辑器周围进行图像拍摄,从拍摄的图像中识别出人体的轮廓,基于所述轮廓确定拍摄的图像中的人体的人种;字幕设定设备,与所述编辑人员识别设备连接,用于接收所述编辑人员识别设备输出的人种,并基于所述编辑人员识别设备输出的人种选择相应的字幕文件,所选择的字幕文件的语言类型与所述编辑人员识别设备输出的人种相符合;视频编辑器,用于接收待编辑的视频数据,从所述待编辑的视频数据中提取出多个片头图像;其中,所述视频编辑器的提取的多个片头图像的多个时间戳保持等间距时间间隔。
更具体地,在所述重复场景图像分组平台中,还包括:
时间设定设备,与所述视频编辑器连接,用于设定所述视频编辑器的提取的多个片头图像的多个时间戳之间的等间距时间间隔;重复度鉴定设备,与所述视频编辑器连接,用于接收所述多个片头图像,鉴定每一个片头图像的场景,将具有重复场景的片头图像划为一组,以获得多组片头图像,将每一组片头图像中熵值最低的图像作为目标图像,以输出多组片头图像分别对应的多个目标图像。
更具体地,在所述重复场景图像分组平台中,还包括:
图像分析设备,与所述重复度鉴定设备连接,用于接收所述目标图像,对所述目标图像中的脉冲干扰和脉动干扰分别进行识别,以分别获得所述目标图像中的各个脉冲干扰信号和所述目标图像中的各个脉动干扰信号;参考值提取设备,与所述图像分析设备连接,用于接收所述目标图像中的各个脉冲干扰信号和所述目标图像中的各个脉动干扰信号,并确定所述目标图像中的各个脉冲干扰信号的各个幅值中的最大值以作为脉冲干扰参考值,以及确定所述目标图像中的各个脉动干扰信号的各个幅值中的最大值以作为脉动干扰参考值;切换控制设备,与所述参考值提取设备连接,用于在所述脉冲干扰参考值大于等于所述脉动干扰参考值时,发出第一触发信号,以及还用于在所述脉冲干扰参考值小于所述脉动干扰参考值时,发出第二触发信号;脉冲去除设备,分别与所述图像分析设备和所述切换控制设备连接,用于在接收到所述第一触发信号时,启动对所述目标图像中每一个像素点的以下处理:将所述目标图像中每一个像素点作为处理像素点,基于所述脉冲干扰参考值确定执行中值滤波的滤波窗口的面积,采用所述滤波窗口对所述处理像素点的像素值进行滤波处理;所述脉冲去除设备还用于基于所述目标图像中每一个像素点的像素值的滤波处理结果输出相应的第一滤波图像;脉动去除设备,分别与所述图像分析设备和所述切换控制设备连接,用于在接收到所述第一触发信号时,启动对所述目标图像的加权均值滤波处理,以获得并输出相应的第二滤波图像;图像汇集设备,分别与所述脉冲去除设备和所述脉动去除设备连接,用于将所述第一滤波图像或所述第二滤波图像,并将所述第一滤波图像或所述第二滤波图像作为所述目标图像对应的汇集图像输出;电力供应设备,分别与所述切换控制设备、所述脉冲去除设备和所述脉动去除设备连接;人种判断设备,与所述图像汇集设备连接,用于接收每一个汇集图像,对每一个汇集图像执行以下操作:将所述汇集图像中景深最浅的演员所在区域从所述汇集图像中分割出来,基于各国标准人体轮廓判断与所述汇集图像中景深最浅的演员所在区域的轮廓最符合的标题人体轮廓所对应的人种以作为所述汇集图像对应的人种;人种统计设备,与所述人种判断设备连接,用于接收各个汇集图像分别对应的各个人种,基于所述各个人种判断待编辑的视频数据对应的视频人种类别;音乐设定设备,与所述人种统计设备连接,用于接收所述人种统计设备输出的人种类别,并基于所述人种统计设备输出的人种类别选择对应语言的音频文件。
更具体地,在所述重复场景图像分组平台中:在所述人种统计设备中,基于所述各个人种判断待编辑的视频数据对应的视频人种类别包括:将所述各个人种中出现频率最高的人种作为待编辑的视频数据对应的视频人种类别。
更具体地,在所述重复场景图像分组平台中:所述电力供应设备在接收到所述第一触发信号时,控制所述脉冲去除设备以使其进入运行模式,控制所述脉动去除设备以使其进入休眠模式。
更具体地,在所述重复场景图像分组平台中:所述电力供应设备在接收到所述第二触发信号时,控制所述脉动去除设备以使其进入运行模式,控制所述脉冲去除设备以使其进入休眠模式。
更具体地,在所述重复场景图像分组平台中:在所述脉冲去除设备中,所述脉冲干扰参考值越大,确定的执行中值滤波的滤波窗口的面积越大。
更具体地,在所述重复场景图像分组平台中:所述字幕文件和所述音频文件用于在所述待编辑的视频数据播放时进行同步播放。
附图说明
以下将结合附图对本发明的实施方案进行描述,其中:
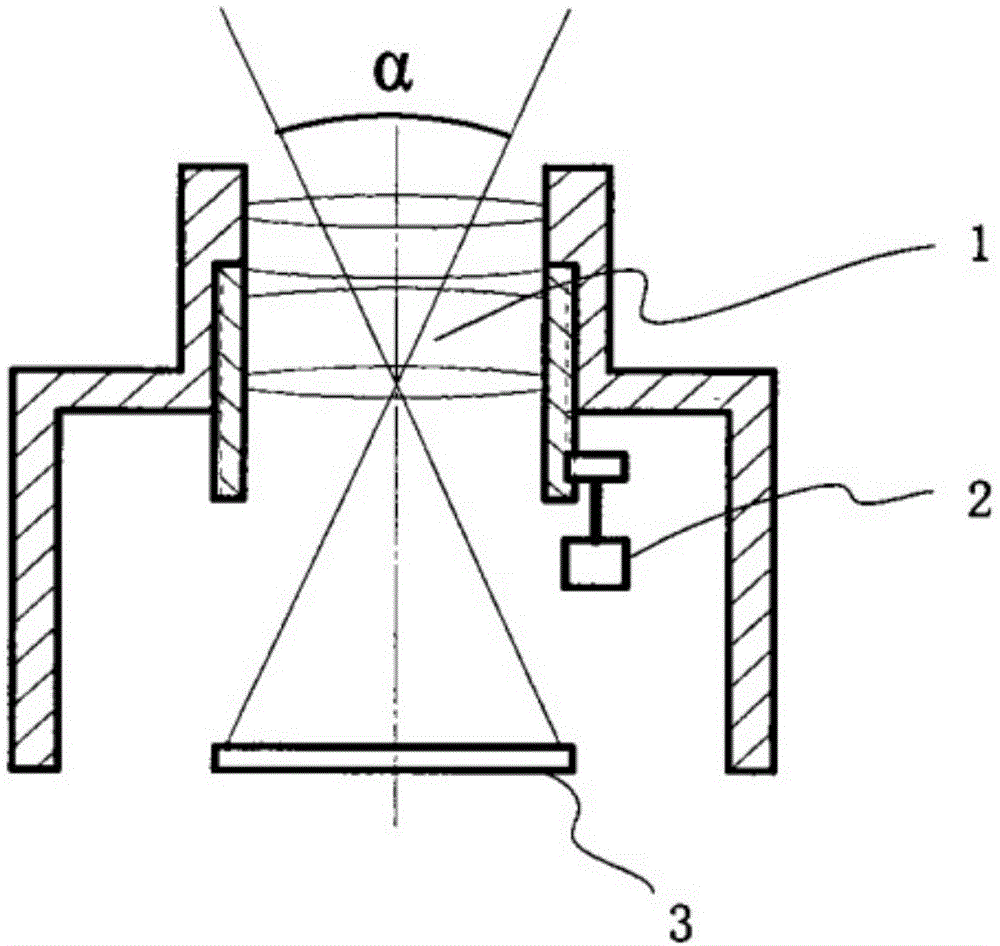
图1为根据本发明实施方案示出的重复场景图像分组平台的编辑人员识别设备内部的成像组件的结构示意图。
具体实施方式
下面将参照附图对本发明的实施方案进行详细说明。
加载在视频画面上的字幕有多种用途,例如,帮助听觉不力的人们快速及时了解到各个演员的说话内容,电视台的紧急通知或广播,以及各种台标相关的文字的叠加。
字幕机是完成视频画面上的字幕加载的专业机器,当前可以采取硬件形式或软件形式来实现。但是,在编辑的过程中,当前字幕机的执行模式无法跟上视频观众的各种智能化需求,例如,基于当前画面的人物的人种类型确定当前加载的字幕的语言类型,或者,基于当前的配乐的语言类型确定当前加载的字幕的语言类型。
为了克服上述不足,本发明搭建一种重复场景图像分组方法,该方法包括运行一种重复场景图像分组平台来分组重复场景图像。所述重复场景图像分组平台能够有效解决相应的技术问题。
图1为根据本发明实施方案示出的重复场景图像分组平台的编辑人员识别设备内部的成像组件的结构示意图。其中,1为光学透镜组件,2为固定螺栓。
根据本发明实施方案示出的重复场景图像分组平台包括:
编辑人员识别设备,用于对视频编辑器周围进行图像拍摄,从拍摄的图像中识别出人体的轮廓,基于所述轮廓确定拍摄的图像中的人体的人种;
字幕设定设备,与所述编辑人员识别设备连接,用于接收所述编辑人员识别设备输出的人种,并基于所述编辑人员识别设备输出的人种选择相应的字幕文件,所选择的字幕文件的语言类型与所述编辑人员识别设备输出的人种相符合;
视频编辑器,用于接收待编辑的视频数据,从所述待编辑的视频数据中提取出多个片头图像;
其中,所述视频编辑器的提取的多个片头图像的多个时间戳保持等间距时间间隔。
接着,继续对本发明的重复场景图像分组平台的具体结构进行进一步的说明。
在所述重复场景图像分组平台中,还包括:
时间设定设备,与所述视频编辑器连接,用于设定所述视频编辑器的提取的多个片头图像的多个时间戳之间的等间距时间间隔;
重复度鉴定设备,与所述视频编辑器连接,用于接收所述多个片头图像,鉴定每一个片头图像的场景,将具有重复场景的片头图像划为一组,以获得多组片头图像,将每一组片头图像中熵值最低的图像作为目标图像,以输出多组片头图像分别对应的多个目标图像。
在所述重复场景图像分组平台中,还包括:
图像分析设备,与所述重复度鉴定设备连接,用于接收所述目标图像,对所述目标图像中的脉冲干扰和脉动干扰分别进行识别,以分别获得所述目标图像中的各个脉冲干扰信号和所述目标图像中的各个脉动干扰信号;
参考值提取设备,与所述图像分析设备连接,用于接收所述目标图像中的各个脉冲干扰信号和所述目标图像中的各个脉动干扰信号,并确定所述目标图像中的各个脉冲干扰信号的各个幅值中的最大值以作为脉冲干扰参考值,以及确定所述目标图像中的各个脉动干扰信号的各个幅值中的最大值以作为脉动干扰参考值;
切换控制设备,与所述参考值提取设备连接,用于在所述脉冲干扰参考值大于等于所述脉动干扰参考值时,发出第一触发信号,以及还用于在所述脉冲干扰参考值小于所述脉动干扰参考值时,发出第二触发信号;
脉冲去除设备,分别与所述图像分析设备和所述切换控制设备连接,用于在接收到所述第一触发信号时,启动对所述目标图像中每一个像素点的以下处理:将所述目标图像中每一个像素点作为处理像素点,基于所述脉冲干扰参考值确定执行中值滤波的滤波窗口的面积,采用所述滤波窗口对所述处理像素点的像素值进行滤波处理;所述脉冲去除设备还用于基于所述目标图像中每一个像素点的像素值的滤波处理结果输出相应的第一滤波图像;
脉动去除设备,分别与所述图像分析设备和所述切换控制设备连接,用于在接收到所述第一触发信号时,启动对所述目标图像的加权均值滤波处理,以获得并输出相应的第二滤波图像;
图像汇集设备,分别与所述脉冲去除设备和所述脉动去除设备连接,用于将所述第一滤波图像或所述第二滤波图像,并将所述第一滤波图像或所述第二滤波图像作为所述目标图像对应的汇集图像输出;
电力供应设备,分别与所述切换控制设备、所述脉冲去除设备和所述脉动去除设备连接;
人种判断设备,与所述图像汇集设备连接,用于接收每一个汇集图像,对每一个汇集图像执行以下操作:将所述汇集图像中景深最浅的演员所在区域从所述汇集图像中分割出来,基于各国标准人体轮廓判断与所述汇集图像中景深最浅的演员所在区域的轮廓最符合的标题人体轮廓所对应的人种以作为所述汇集图像对应的人种;
人种统计设备,与所述人种判断设备连接,用于接收各个汇集图像分别对应的各个人种,基于所述各个人种判断待编辑的视频数据对应的视频人种类别;
音乐设定设备,与所述人种统计设备连接,用于接收所述人种统计设备输出的人种类别,并基于所述人种统计设备输出的人种类别选择对应语言的音频文件。
在所述重复场景图像分组平台中:在所述人种统计设备中,基于所述各个人种判断待编辑的视频数据对应的视频人种类别包括:将所述各个人种中出现频率最高的人种作为待编辑的视频数据对应的视频人种类别。
在所述重复场景图像分组平台中:所述电力供应设备在接收到所述第一触发信号时,控制所述脉冲去除设备以使其进入运行模式,控制所述脉动去除设备以使其进入休眠模式。
在所述重复场景图像分组平台中:所述电力供应设备在接收到所述第二触发信号时,控制所述脉动去除设备以使其进入运行模式,控制所述脉冲去除设备以使其进入休眠模式。
在所述重复场景图像分组平台中:在所述脉冲去除设备中,所述脉冲干扰参考值越大,确定的执行中值滤波的滤波窗口的面积越大。
在所述重复场景图像分组平台中:所述字幕文件和所述音频文件用于在所述待编辑的视频数据播放时进行同步播放。
另外,在所述重复场景图像分组平台中,还包括:ddr存储设备,与所述人种判断设备连接,用于预先存储各国标准人体轮廓,以供所述人种判断设备工作时使用。
ddr,即ddrsdram,人们习惯称为ddr。ddrsdram是doubledataratesdram的缩写,是双倍速率同步动态随机存储器的意思。ddr内存是在sdram内存基础上发展而来的,仍然沿用sdram生产体系,因此对于内存厂商而言,只需对制造普通sdram的设备稍加改进,即可实现ddr内存的生产,可有效的降低成本。
sdram在一个时钟周期内只传输一次数据,它是在时钟的上升期进行数据传输;而ddr内存则是一个时钟周期内传输两次次数据,它能够在时钟的上升期和下降期各传输一次数据,因此称为双倍速率同步动态随机存储器。ddr内存可以在与sdram相同的总线频率下达到更高的数据传输率。
采用本发明的重复场景图像分组平台,针对现有技术中图像编辑人员无法识别待编辑图像播放文字的技术问题,通过基于现场编辑人员的人种信息和图像内容中的人种信息,获取视频画面上播放的文字的语言类型和与视频画面同步播放的音频的语言类型,满足了现场编辑人员的编辑需求;更重要的是,对图像中的脉冲干扰和脉动干扰分别进行识别,以分别获得所述图像中的各个脉冲干扰信号和所述图像中的各个脉动干扰信号,对上述干扰信号的幅值进行比较以为所述图像选择与图像内容相适应的滤波机制,以防止图像滤波缺乏针对性,从而解决了上述技术问题。
可以理解的是,虽然本发明已以较佳实施例披露如上,然而上述实施例并非用以限定本发明。对于任何熟悉本领域的技术人员而言,在不脱离本发明技术方案范围情况下,都可利用上述揭示的技术内容对本发明技术方案做出许多可能的变动和修饰,或修改为等同变化的等效实施例。因此,凡是未脱离本发明技术方案的内容,依据本发明的技术实质对以上实施例所做的任何简单修改、等同变化及修饰,均仍属于本发明技术方案保护的范围内。
- 还没有人留言评论。精彩留言会获得点赞!