基于卷积神经网络和HEVC压缩域显著信息的视频压缩方法与流程
本发明涉及视频处理技术领域,更具体的说是涉及一种基于卷积神经网络和hevc压缩域显著信息的视频压缩方法。
背景技术:
目前,随着视频压缩技术的不断发展,人们对视频的高品质、高实时性要求越来越高,新一代视频编码标准hevc(highefficiencyvideocoding)应运而生,其以较高的编码性能应用于高清视频处理中。
但是,新一代视频编码标准hevc在编码性能提高的同时,编码复杂度也随之大增,这样其应用于视频压缩过程中时,其压缩效率难以保证,尤其是在高清视频应用越来越普及的情况下,因为带宽受限而出现的问题给视频压缩技术带来了巨大的挑战,现代社会对视频高清度的要求也越来越高,由最初的qcif发展至4k(分辨率为3840×2160),乃至不久后发展为8k(分辨率为7680×4320)的超高清视频,这样对视频的压缩、存储和传输都提出了更高的要求,尤其是如何能够提高压缩效率,使人眼所关注部分的画质更加清晰、真实等至关重要。现有的视频编码标准hevc已经不能满足在高质量的高清视频传输、提升人眼的主观视觉感受质量的同时,又能能够提高压缩效率,使人眼所关注部分的画质更加清晰、真实的要求。
因此,如何提供一种既能提升人眼主观视觉感知质量,又能进一步提升视频压缩效果的视频压缩方法是本领域技术人员亟需解决的问题。
技术实现要素:
有鉴于此,本发明提供了一种基于卷积神经网络和hevc压缩域显著信息的视频压缩方法,该方法将视频编码方法和人类视觉系统有机结合,可以去除更多的主观视觉感知冗余,在提升人眼的主观视觉感知质量的同时,进一步提升了视频压缩效果。
为了实现上述目的,本发明采用如下技术方案:
一种基于卷积神经网络和hevc压缩域显著信息的视频压缩方法,该方法包括以下步骤:
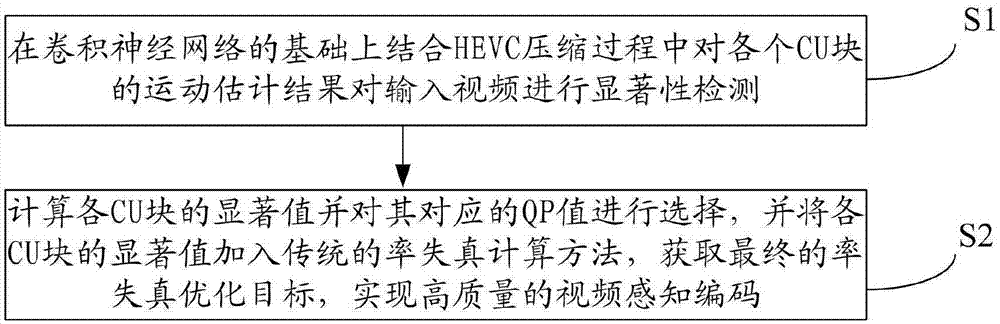
在卷积神经网络的基础上结合hevc压缩过程中对各个cu块的运动估计结果对输入视频进行显著性检测;
计算各cu块的显著值并对其对应的qp值进行选择,并将各cu块的显著值加入传统的率失真计算方法,获取最终的率失真优化目标,实现高质量的视频感知编码。
本发明的有益效果是:该方法从以注意力机制为基础的视频显著性算法和感知优先的视频压缩算法这两个方面对hevc进行改进和强化,在视频显著性方面,本方法在卷积神经网络的基础上结合hevc压缩过程中对各个cu的运动估计结果对两者进行自适应的动态融合,从而完成对输入视频的显著性检测;在感知优先的视频压缩算法方面,根据cu的显著值来选择其对应的qp,以确保具有较高显著性的cu能以较小的qp进行编码,同时将当前cu块的显著性特征纳入传统的率失真计算方法,从而达到感知优先的目的,该方法降低了视频的感知冗余从而得到较好的压缩效果。
在上述方案的基础上,对本发明的技术方案做进一步解释说明。
进一步,对输入视频进行显著性检测,具体包括以下步骤:
输入原始视频帧,根据卷积神经网络对输入视频帧进行空域显著性检测,生成空域显著性检测结果;
根据hevc压缩过程中帧间预测过程得到的运动矢量,生成时域部分的运动显著性结果;
将所述空域显著性检测结果和所述时域部分的运动显著性结果,采用熵不确定度算法进行融合。
进一步,所述卷积神经网络结构,包括:
(1)卷积层:经过卷积操作后得到表示图像局部特征的特征图,每个卷积层后加一个修正线性单元;由于图像的像素间的空间联系是局部的,只考虑像素的局部信息比考虑全局信息的复杂度低很多,经过卷积操作后可得到表示图像局部特征的特征图,在每次卷积操作之后,一般会跟随一个rectifiedlinearunit,该激活函数计算速度快,并且能有效缓解梯度消失问题;
(2)局部响应归一化层:对神经网络中间层的输出进行了平滑,输出如下:
其中,(x,y)表示像素位置,i表示通道索引,n为通道数,α,β,k,n均为自定义常数;l表示在第l个局部响应归一化层,j表示对应的通道索引;
(3)最大池化层:最大池化层用于提取局部相近的语义信息,该过程通过一个n×n的滑动窗口操作,其中窗口移动步长为n,通过计算原图像的局部被窗口所包含区域的最大值作为新的特征图对应位置的像素值;
(4)反卷积层:实现将小尺寸的特征图尺寸缩放为原图像的大小,得到最终输出。
进一步,时域部分的运动显著性结果生成过程为:从视频压缩域提取运动信息,利用hevc中进行浅层解码的过程,得到视频帧中预测单元pu的运动矢量信息,然后将运动矢量的大小作为块运动的剧烈程度重组成时域运动特征图。
进一步,根据hevc压缩过程中帧间预测过程得到的运动矢量,生成时域部分的运动显著性结果,具体包括以下步骤:
从视频压缩域提取运动信息,利用hevc中进行浅层解码的过程,得到视频帧中预测单元pu的运动矢量信息;
将所述运动矢量信息的大小作为块运动的剧烈程度重组成时域运动特征图。
进一步,根据所述时域运动特征图,采用全局运动估计算法,采用透视模型得到视频中的全局运动信息,该过程可以表述为:
式中(x,y)和(x′,y′)分别是当前帧和参考帧的对应像素点,参数集m=[m0,...,m7]代表需要估计的全局运动参数;
使用梯度下降法对该模型求解,计算可得代表摄像机运动信息的全局运动,由原始运动减去全局运动,得到相对于背景的前景运动;
根据显示运动速度的感知先验分布幂函数:
式中,v表示运动速度;k和α表示常数;
根据其自信息计算运动的时间显著性,计算公式如下:
s(t)=-logp(v)=αlogv+β
其中β=-logk,α=0.2,β=0.09,最后将其归一化到[0,1],得到时域显著性图。
进一步,将所述空域显著性检测结果和所述时域部分的运动显著性结果,采用熵不确定度算法进行融合,包括:
将计算得到所述空域显著性图和所述时域显著性图合并,获得整体的时空显著性图,使用下式计算融合后显著图:
式中,u(t)表示时域的感知不确定度;u(s)表示空域显著性的不确定度;s(t)表示运动的时间显著性;s(s)表示运动的空域显著性。
进一步,计算各cu块的显著值并对其对应的qp值进行选择,具体包括以下步骤:
计算各cu块的显著值,计算公式为:
其中,sn×n(k)表示第k个cu块的显著值,第k个cu块的大小为n*n,i表示n*n个块中从左到右的坐标,j表示从上到下的坐标。;
计算所有cu块的平均显著值,计算公式为:
其中,savg表示所有cu块的平均显著值,width表示视频帧的宽,height表示视频帧的高;
根据计算所得的当前cu块的显著值和所有cu块的平均显著值,动态调整当前帧的qp值,得到当前cu块的感知qp值。
进一步,当前cu块的感知qp值的计算公式为:
其中,qpc表示当前帧的qp值,qpk表示当前cu块的感知qp值,wk表示一个变换参数,wk的计算公式为:
其中,a、b、c均为常参数,s(k)表示第k个cu块的显著值,savg表示所有cu块的平均显著值。
进一步,获取最终的率失真优化目标,具体包括以下步骤:
获取视频中各cu块的显著值,计算感知优先失真度;
将所述感知优先失真度,加入传统的率失真计算方法,获取最终的优化目标。
进一步,计算感知优先失真度的公式如下:
ds=d×(1+sf×sd)
式中,d为hm标准的失真度计算方法;sf表示需要配置文件指定的感知优化参数;sd表示当前编码块的显著性偏差;
所述sd计算公式如下:
式中,sd取值范围为(-1,1),scu表示当前块的显著性,savg表示当前帧所有cu块的平均显著性值。
进一步,将所述感知优先失真度,加入传统的率失真计算方法,获取最终的优化目标,包括:
类比传统的率失真优化算法,拉格朗日算法改进后的目标可表示为:
min{ds+λr}
式中,ds表示当前块显著性的感知失真度;λ表示拉格朗日乘子;r表示编码比特率。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
图1附图为本发明提供的一种基于卷积神经网络和hevc压缩域显著信息的视频压缩方法的流程图;
图2附图为本发明提供的视频时空显著性检测及针对高清视频的感知压缩过程的整体实现框图;
图3附图为本发明提供的时空域显著性检测及融合部分的方法流程图;
图4附图为本发明提供的卷积神经网络各层的结构组成示意图;
图5a附图为本发明提供的空域显著性效果示例的原始画面图;
图5b附图为本发明提供的空域显著性效果示例的模型计算所得空域显著性图;
图6附图为本发明提供的运动矢量示意图;
图7a附图为本发明提供的时域显著性效果示例的原始画面图;
图7b附图为本发明提供的时域显著性效果示例的模型计算所得时域显著性图;
图8附图为本发明提供的时空融合效果图;
图9附图本发明提供的获取最终的率失真优化目标部分的方法流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
参见附图1,本发明实施例公开了一种基于卷积神经网络和hevc压缩域显著信息的视频压缩方法,该方法包括以下步骤:
s1:在卷积神经网络的基础上结合hevc压缩过程中对各个cu块的运动估计结果对输入视频进行显著性检测;
s2:计算各cu块的显著值并对其对应的qp值进行选择,并将各cu块的显著值加入传统的率失真计算方法,获取最终的率失真优化目标,实现高质量的视频感知编码。
参见附图2,本方法中视频时空显著性检测及针对高清视频的感知压缩过程的整体实现过程为:输入原始视频帧后,利用卷积神经网络对输入视频帧进行空域显著性检测,同时根据hevc压缩过程中帧间预测过程得到的运动矢量,生成时域部分的运动显著性结果,采用熵不确定度的方法对时空域显著性进行融合,从而得到针对视频的时空域显著性结果。为后续视频压缩提供了有力的保障。在视频编码部分,可对hevc标准算法进行优化,在获得了视频视觉显著性后,给予这些显著区域(统计意义上人们更倾向于关注的区域)更好的压缩质量,并且在不出现过分失真的前提下可以适当降低非显著区域的压缩质量以便降低视频码率。另外从率失真优化的核心思想出发,根据基于显著性加权的率失真优化算法,可以有效提高视频压缩的感知质量。
参见附图3,对输入视频进行显著性检测,具体包括以下步骤:
s101:输入原始视频帧,根据卷积神经网络对输入视频帧进行空域显著性检测,生成空域显著性检测结果;
s102:根据hevc压缩过程中帧间预测过程得到的运动矢量,生成时域部分的运动显著性结果;
s103:将所述空域显著性检测结果和所述时域部分的运动显著性结果,采用熵不确定度算法进行融合。
具体地,上述卷积神经网络的结构如图4所示。
该卷积神经网络各层的结构和功能如下:
(1)卷积层:由于图像的像素间的空间联系是局部的,只考虑像素的局部信息比考虑全局信息的复杂度低很多,经过卷积操作后可得到表示图像局部特征的特征图,在每次卷积操作之后,一般会跟随一个rectifiedlinearunit(relu),该激活函数计算速度快,并且能有效缓解梯度消失问题。
(2)局部响应归一化层:该层相当于对神经网络中间层的输出进行了平滑,有利于提高模型的泛化能力。该层的输出如下:
其中(x,y)表示像素位置,i表示通道索引,n为通道数,α,β,k,n均为自定义常数;l表示在第l个局部响应归一化层,j的表示对应的通道索引;
(3)最大池化层:最大池化层可提取局部相近的语义信息,该过程通过一个n×n的滑动窗口操作,其中窗口移动步长为n,通过计算原图像的局部被窗口所包含区域的最大值作为新的特征图对应位置的像素值。池化操作可以减少输出的大小,进而降低了过拟合。
(4)反卷积层:实现将小尺寸的特征图尺寸缩放为原图像的大小,得到最终输出。
比如将该上述网络在包含9000张图片的salicon数据集上进行训练,即可得到本发明所使用的空域显著性网络。
通过训练好的网络模型,对输入的三通道图像进行前向传播,即可得到最终的空域显著性图,如图5a-5b所示,该网络能有效计算画面中的显著性区域。
参照图6,即为视频帧的运动矢量示意图,但是由上述过程所得到的时域运动特征图包含了视频帧中的全部运动,而实验表明,对人眼刺激较为明显的是前景物体相对于背景物体的运动,因此,进一步地,本发明采用全局运动估计算法,采用透视模型得到视频中的全局运动信息,该过程可以表述为:
其中,(x,y)和(x′,y′)分别是当前帧和参考帧的对应像素点,参数集m=[m0,...,m7]代表需要估计的全局运动参数,可使用梯度下降法对该模型求解,计算可得代表摄像机运动信息的全局运动,由原始运动减去全局运动即可得到相对于背景的前景运动。
stocker等人已经通过一系列心理视觉实验测量了人类关于运动物体感知的先验概率,实验结果显示运动速度的感知先验分布可以通过以下幂函数计算:
其中v是运动速度,k和α表示常数;那么就可以利用其自信息计算运动的时间显著性,计算公式如下:
s(t)=-logp(v)=αlogv+β
其中β=-logk,α=0.2,β=0.09,最后将其归一化到[0,1]即可得到时域显著性图,如图7a中所示,图像是视频basketballdrive中的一帧画面,该视频中摄像机根据人物和篮球的剧烈运动进行频繁的平移旋转等操作,该图像是在摄像机进行平移时截取的;图7b图像显示了本发明所提算法计算得到的时域显著性图,由于算法中的运动信息来自于hevc编码过程中各块的运动矢量,所以运动检测结果不可避免地会出现块状结构,但仍能看出全局运动被很好地消除,并且凸显出前景物体中较为显著的运动区域。
本发明提出的这种融合规则会随着时域和空域不确定度的变化进行动态的调整,该方法与传统的固定参数的融合方法相比更为灵活,更满足对于视频的检测需求,如图8所示,(a为原始画面,b为时域显著性图,c为时域不确定图,d为空域显著性图,e为空域不确定图,f为不确定加权后的最终显著图)对于时空的特征进行有效融合,并且强化不确定度较低区域的检测结果,融合后的时空不确定图能够较好地反映人眼的显著注视区域。
为了更好的评估该算法的检测结果,本发明可选取五个评估指标比较检测结果和实际注视数据的差异,同时,将该算法与同类算法(比如savc算法)进行比较。
实验选取10个来自3个不同分辨率的视频序列进行检测,视频信息如表1所示:
表1实验所用视频序列信息
利用国际上主流的六种对显著性模型的评估策略(auc、sim、cc、nss、kl)对三种算法进行评估,其中auc值越接近1说明对图像显著部分的预测越准确,sim是衡量两个分布相似程度的一个度量,cc是用来测量显著图和注视图之间的线性关系的一种对称指标,nss是评估固定位置的平均归一化显著性,以上四个指标均是越大越好,kl则是利用一种概率解释来评估显著度和注视图,其值评估了显著图的信息丢失,相反的,kl指标的数值越低越好。
具体地,计算各cu块的显著值并对其对应的qp值进行选择,具体包括以下步骤:
计算各cu块的显著值,计算公式为:
其中,sn×n(k)表示第k个cu块的显著值,第k个cu块的大小为n*n,i表示n*n个块中从左到右的坐标,j表示从上到下的坐标。
计算所有cu块的平均显著值,计算公式为:
其中,savg表示所有cu块的平均显著值,width表示视频帧的宽,height表示视频帧的高;
根据计算所得的当前cu块的显著值和所有cu块的平均显著值,动态调整当前帧的qp值,得到当前cu块的感知qp值。
具体地,当前cu块的感知qp值的计算公式为:
其中,qpc表示当前帧的qp值,qpk表示当前cu块的感知qp值,wk表示一个变换参数,wk的计算公式为:
其中,a、b、c均为常参数,s(k)表示第k个cu块的显著值,savg表示所有cu块的平均显著值。
参见附图9,获取最终的率失真优化目标,具体包括以下步骤:
s201:获取视频中各cu块的显著值,计算感知优先失真度;
s202:将所述感知优先失真度,加入传统的率失真计算方法,获取最终的优化目标。
具体地,计算感知优先失真度的公式如下:
ds=d×(1+sf×sd)
式中,d为hm标准的失真度计算方法;sf表示需要配置文件指定的感知优化参数;sd表示当前编码块的显著性偏差;
具体地,所述sd计算公式如下:
式中,sd取值范围为(-1,1);scu表示当前块的显著性,savg表示当前帧所有cu块的平均显著性值。
具体地,将所述感知优先失真度,加入传统的率失真计算方法,获取最终的优化目标,包括:
类比传统的率失真优化算法,拉格朗日算法改进后的目标可表示为:
min{ds+λr}
式中,ds表示当前块显著性的感知失真度;λ表示拉格朗日乘子;r表示编码比特率。
本实施例结合人眼的感知特性,提出一种结合感知模型和时空显著性的率失真计算方法,采用这种改进方法可以在考虑显著性的基础上综合考量hevc中的种种编码模式,如cu划分、搜索模式等,从而从全局出发进行最优的参数选择。
类比传统的率失真优化算法,拉格朗日算法改进后的目标可表示为:
min{ds+λr}
ds作为结合当前块显著性的感知失真度,能够确保更好的感知编码质量,这种改进能够确保较低的感知失真和低比特率,这对于视频流的低带宽传输更为有利。
分别采用基于hm标准的三种方法作为基准,采用bd-ewpsnr、基于ewpsnr的bd-rate、bd-psnr和bd-ssim对实验结果进行全方面的定量比较,其中前两项指标能够直观反映出本文所提方法与基准方法在人眼感知标准下的表现优劣,后两项指标则为标准客观指标,其中psnr的计算仅仅基于误差敏感度(errorsensitivity),与感知视觉质量的匹配性不是很好,难以描述重建图像或视频的感知质量,ssim则是将与物体结构相关的亮度和对比度作为图像中的结构信息进行失真测度,能够在一定程度上反应图像整体的结构失真。四项指标中,bd-ewpsnr、bd-psnr和bd-rate均越大越好,bd-rate越小越好(均考虑符号)。评估结果如表2所示:
表2视频压缩评估结果参照表
实验结果表明,本文所提算法相对于hm标准中提出的自适应qp算法优势最大,平均bd-ewpsnr提高0.710,bd-rate降低20.332,同时相对于hm标准的率失真优化量化和多qp优化方法bd-ewpsnr也分别高出0.317和0.354,虽然本文所提方法的bd-psnr和bd-ssim均有所下降,但该下降是改善显著区域压缩效果的必然趋势,在同等码率条件下提高感知区域的压缩质量必然要以牺牲非显著区域的压缩质量为代价,并且当显著区域越小,越集中时,该趋势更为显著。
为排除显著性检测结果对于压缩效果的影响,有效比较本方法所提的压缩算法的压缩效果,采用数据库中各视频的眼动注视图进行实验,实验结果如表3所示:
表3基于眼动注视图的视频压缩质量评估结果参照表
由上表可以看出,此时本方法所提压缩算法的表现更好,可知本方法能够保证在视频客观质量不显著下降的前提下有效提高ewpsnr,相比hm标准优化方法更具有有效性和优越性,并且在人的主观感受下,我们所提出的方法有最佳的观赏效果。
对于高清视频的压缩过程来说,压缩效率也是一个不可忽视的评价因素,为衡量本发明所提算法的压缩效率,实验过程中对各种方法下的压缩时间进行记录,在anintelxeone5-1620v3cpuwith8gbramandanvidiatitanxgpu的实验条件下进行实验,将采用rdoq的hm标准方法所用时间设置为基准,可得数据如表4所示:
表4视频压缩效率对比参照表
根据实验结果可知,虽然基于hm标准的aqp方法所用时间最短,但是其压缩效果也最差,同时虽然mqp方法效果较aqp方法好,但是因为mqp算法相当于在给定的qp范围内进行穷举以得到率失真优化下效果最好的压缩结果所用的qp,所以其压缩时间最长,为标准hm的6.46倍。
定量实验结果表明,本发明所提方法在压缩效率和压缩效果上均优于hm标准算法及其所提出的各项优化方法,其中本发明所提供的方法比aqp方法的bd-ewpsnr平均高出0.71,在压缩效率上是mqp方法的2.59倍。
本实施例提供的方法利用hevc压缩域的运动矢量信息得到视频的时域显著性,利用卷积神经网络检测空域显著性,并采用熵不确定度的方法将两者融合,充分发挥时空域的不同特征特点,并利用得到的显著性结果指导hevc的压缩过程。
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的装置而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
- 还没有人留言评论。精彩留言会获得点赞!