一种基于遗传算法和ANFIS相结合的网络入侵异常检测方法与流程
本发明涉及网络安全技术领域,具体一种基于遗传算法和anfis相结合的网络入侵异常检测方法。
背景技术:
随着网络技术的发展,互联网已逐渐深入各行各业,信息作为企业的核心竞争力,为企业创造经济效益的同时,信息的安全问题也日显突出。新的攻击手段层出不穷,现代黑客开始从以系统为主的攻击转向以网络为主的攻击,如网络监听、端口扫描、拒绝服务、利用匿名用户访问攻击、以及通过隐秘通道绕过防火墙的攻击方法等。目前入侵监测系统的监测技术还不够智能,现有的入侵检测系统产品多数情况下都是被动地检测已知的安全入侵方式,对于未知的入侵方式的效果微乎其微,即使具备了一定的所谓异常模式判断的入侵检测系统,对于新的攻击模式的实际应用效果依然不太明显。
技术实现要素:
针对现有技术的上述不足,本发明的目的在于提供一种运算速度快、准确率高的结合遗传算法和自适应神经模糊推理系统(anfis)的网络入侵异常检测方法,通过对数据进行特征编码、标准化操作,同时采用pca降维以及遗传算法自动选取模糊规则,有效地降低计算时间,提高anfis的分类效果。
为实现上述目的,本发明采用以下技术方案:
一种基于遗传算法和anfis相结合的网络入侵异常检测方法,包括步骤:
s1:特征编码处理:对标签型特征变量进行labelencoding编码,选取与标签编码不同数量级的数值来编码缺失值;
s2:对特征编码后的数据集进行z-score标准化处理;
s3:将标准化后的数据集进行pca降维处理;
s4:在降维后的数据集中选定训练集和测试集,从所述训练集中抽取部分样本,作为实例样本,初始化隶属度函数及各所述实例样本在每个维度上的隶属度函数的数目,结合各所述实例样本在anfis模型的输出构建适应度函数,采用遗传算法依次迭代进行选择、交叉、变异操作,选取最优规则链;
s5:将选取的最优规则链作为anfis模型推理过程中的模糊规则库,在降维后的训练集上对所述anfis模型进行训练,然后在降维后的测试集上进行验证,确定待测样本属于正常类型还是异常类型。
优选的,所述数据集为unsw-nb15网络入侵检测基准数据集。
优选的,隶属度函数为高斯分布函数。
优选的,步骤s4包括:
s401:从经步骤s3降维后的数据集中选定训练集和测试集,在所述训练集中抽取部分样本,作为实例样本;
s402:初始化隶属度函数及各所述实例样本在每个维度上的隶属度函数的数目,以每个所述实例样本在anfis模型的预测输出与期望输出之间的平均距离构建损失函数,如式(2)所示:
其中,
适应度函数如式(3)所示:
s403:初始化以下参数:规则链长度,种群大小,迭代次数,交叉概率,变异概率,每次选择操作的淘汰占比和存活占比;
s404:根据公式(2)和公式(3)计算种群的适应度集合为fit={γ1,γ2,...γm},其中γi,i=1,2,...m表示每条规则链的适应度,使用公式
s405:选取
s406:如果迭代次数为零,则完成迭代,最优规则链为步骤s405选取的第一最优规则链,记为opt,否则,迭代次数减一,进入选择操作;
s407:选择操作:按照
s408:交叉操作:按照
若种群大小为奇数,最后一条规则链不进行交叉操作;
s409:变异操作:针对每条规则链按照变异概率进行随机单点变异操作;
s410:重复步骤s404-s409,依次迭代进行选择、交叉、变异操作,直到迭代次数为零,选择出
本发明一种实施方式的有益效果:
对原始数据进行特征编码、标准化、pca降维处理,并采用遗传算法自动选取anfis模糊推理过程中的模糊规则,大大降低了模型的检测时间,提高了检测效率,结果表明,该方法能够有效地检测到异常数据,且具有较低的假阳率,极大地降低了误报情况的出现,具有较高的实用价值。
附图说明
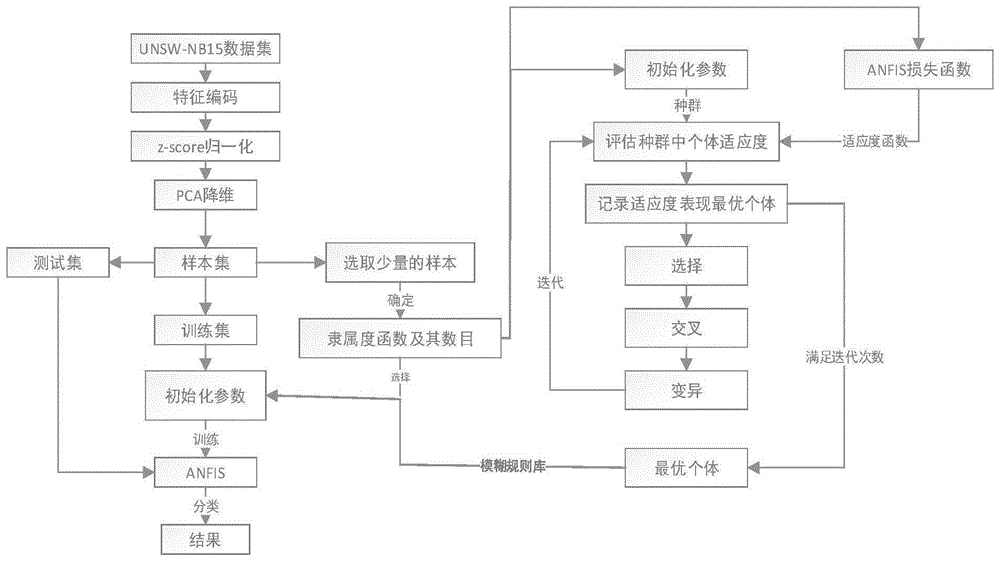
图1是本发明一种实施方式的方法流程框架图;
图2是本发明实施例针对不同主成分数选择方案进行anfis训练过程中的均方根误差变化曲线;
图3是本发明实施例使用pca将维度降为4维后的anfis测试结果图;
图4是本发明实施例使用pca将维度降为6维后的anfis测试结果图;
图5是本发明实施例使用pca将维度降为8维后的anfis测试结果图;
图6是本发明实施例使用pca将维度降为10维后的anfis测试结果图;
图7是本发明实施例针对不同的参数设定进行anfis训练后在测试集上所表现的各项评价指标的状况图。
具体实施方式
下面通过附图及具体实施方式对本发明进行详细的说明。显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。在下文对本发明的细节描述中,详尽描述了一些特定的细节部分。对本领域技术人员来说没有这些细节部分的描述也可以完全理解本发明。为了避免混淆本发明的实质,公知的方法、过程、流程、元件和电路并没有详细叙述。
本发明的网络入侵异常检测方法结合遗传算法和anfis,解决检测实时性差、检测准确率不高和假阳率过高的问题。其一种实施方式为:采用同时包含正常类型和异常类型的具有现代网络流量特征的unsw-nb15数据集,对训练集中的每个样本进行特征编码、标准化和pca降维处理,并采用遗传算法实现自动选取模糊规则,然后利用自动选取的模糊规则作为anfis模型的模糊规则库进而通过训练集来训练模型,最后借助于训练好的模型在测试集上进行测试,实现未知样本分类,以确定其属于正常类型还是异常类型。
更优选的实施方式,如图1所示,包括步骤:
步骤1:针对unsw-nb15网络入侵检测基准数据集中的标签型特征变量采用labelencoding进行编码,也就是将某一个特征变量的所有标签进行排序并用序号替代这些标签,同时,考虑到某些特征变量存在缺失值的问题,选取与该序号不同数量级的数值来编码缺失值。
步骤2:对特征编码后的数据集进行z-score标准化处理,如公式(1)所示:
其中,n表示编码后的样本数据的维度,x(i)表示特征i所对应的编码后的样本数据,
步骤3:采用pca数据降维方法对原始数据进行降维处理,设所要保留的主成分数为k,且所要采取的k个主成分的方差占比之和为主成分选择的阈值ε,选取ε范围内的主成分作为新的数据样本,则原始样本数据的维度由n降为k。
步骤4:结合遗传算法的强移植性和anfis模型的特点,采用遗传算法依次迭代进行选择、交叉、变异操作,选取最优规则链作为anfis模型推理过程中的模糊规则库,实现anfis在进行模糊推理的过程中,既能保证模型的精度,又能以较少的模糊规则替代庞大的模糊规则库,以达到降低计算资源消耗的目的。
假设基因为每条规则,个体是由规则构成的规则链,种群为规则链的集合,遗传算法遵从优胜劣汰的原则,即依赖于适应度函数作为优胜劣汰的标准,个体越优生存的可能性越大,那么具有最大生存能力的规则链即为所需的模糊规则。
结合anfis的模糊推理机制,选择高斯分布函数为数据模糊化的隶属度函数,并通过导入实例样本,以实例样本通过模型预测所产生的损失函数作为适应度函数的选择标准之一。具体的实现过程可分为以下几个步骤:
(401)从经步骤s3降维后的数据集中选定训练集和测试集,按照各类别均衡分布的原则,从所述训练集中抽取部分样本,作为实例样本;
(402)初始化隶属度函数及各所述实例样本在每个维度上的隶属度函数的数目,以每个所述实例样本在anfis模型的预测输出与期望输出之间的平均距离构建损失函数,如式(2)所示:
其中,
针对适应度函数fitness对每条规则链的评估,表现为平均距离越小,则适应度越高,这里,由于我们只关注平均距离较小的,而对过大的不给予较高的关注,但是也不能对其舍弃,因此对于平均距离过大的,只赋予其一个较小的值,保留其存在的价值;
(403)初始化以下参数:规则链长度,种群大小,迭代次数,交叉概率,变异概率,每次选择操作的淘汰占比和存活占比;
(404)根据公式(2)和公式(3)计算种群的适应度集合为fit={γ1,γ2,...γm},其中γi,i=1,2,...m表示每条规则链的适应度,使用公式
此时,如果将
(405)选取
(406)如果迭代次数为零,则完成迭代,最优规则链为步骤405选取的第一最优规则链,记为opt,否则,迭代次数减一,进入选择操作;
(407)选择操作:按照
(408)交叉操作:按照
若种群大小为奇数,最后一条规则链不进行交叉操作;
(409)变异操作:针对每条规则链按照变异概率进行随机单点变异操作,引入新的规则,提升种群的多样性,如规则链为r1r2r3r4r5,假设此条规则链已被选中作为变异操作的对象,并且变异位置为2,新规则为r6,则变异后的规则为r1r6r3r4r5;变异概率一般为0.01~0.1;
(410)重复步骤404-409,依次迭代进行选择、交叉、变异操作,直到迭代次数为零,选择出
步骤5:通过遗传算法择出的最优规则链opt作为模糊规则库,应用于anfis模型的模糊推理过程,在所述训练集上对所述anfis模型进行训练,构建一种基于简易模糊规则的anfis模型实现网络入侵异常检测,然后在所述测试集上进行验证,确定待测样本属于正常类型还是异常类型。
在实际应用中,降维的维度、训练集和测试集的样本量及其他参数值可以根据经验取值,还可以设定不同的参数组合,选取测试效果满足要求且分类效果最佳的方案作为最终的模型参数。
该方法的具体实例如下:
采用unsw-nb15数据集作为实验数据集,每条样本的特征数量为42,样本的类型分别为0和1,其中0表示正常,1表示异常。
对数据集中的proto,service,state特征进行编码,如service特征,对其每个标签的编码方式如表1所示。其中,为了区别缺失值与正常值,以一个较大的数值来编码缺失值‘-’。
表1
采用公式(1)对特征编码后的实验数据进行z-score标准化处理。
进行pca数据降维:可以分别设定不同的阈值ε,对标准化后的数据集进行降维,针对不同阈值ε进行降维所得实验数据的维度k,即保留的主成分数量,如表2所示。
表2
针对每一种降维方案,分别从降维后的训练集和测试集中相应抽取5000和3000条样本数据作为后续实验的训练集和测试集,分别记为检测训练集和检测测试集。在保证每种类型数据均衡的情况下,分别按照各类别均衡的准则从所述检测训练集中抽取1000条样本数据作为规则自动选取的实例样本,设定实例样本在每个维度上的隶属度函数为高斯分布函数,初始化各所述实例样本在每个维度上的隶属度函数的数目、规则链长度、种群大小、迭代次数;交叉概率设为0.7,变异概率设为0.1;淘汰占比为20%,存活占比为80%。然后采用本实施例的遗传算法反复迭代寻找构建模型的最优规则链,不同参数下的表现结果如表3所示。
表3
通过对比初始规则链和优化后的最优规则链(opt),发现最优规则链的长度已发生变化,显然所要优化的规则链是弹性可变的。进而,对比每种主成分选择方案下最优规则链的适应度值可以得出,随着主成分数量的增加,最优规则链的适应度亦是呈增长模式,但是此类特点并不能完全表明数据维度越高,对anfis模型精度的提升越有益处,具体的效果要根据后续实验进一步验证。
分别以不同主成分数条件下选择出的最优规则链作为anfis模糊推理过程中的模糊规则库,在所述检测训练集上对anfis模型进行训练,构建一种基于简易模糊规则的anfis模型实现网络入侵异常检测,训练好的模型在所述检测测试集上进行验证,确定待测样本属于正常类型还是异常类型,具体效果如图2-7所示。图中的training4×3表示训练过程采用主成分数为4,隶属度函数为3的方案,依次类推,同样的,testing4×3表示测试过程使用和训练过程一致的方法,两者是互为统一的关系。
如图2所示,横坐标为训练的次数,纵坐标为随着训练次数的增加,模型所对应的均方根误差。本实施例针对不同的主成分数选择方案,分别采用对应的最优规则链应用于anfis模型,并反复进行10次训练。如图2所示,随着训练次数的增加,anfis模型的均方根误差并无明显变化,也就是说在实际应用中可以通过适当减少训练次数,降低模型的训练时间,提高网络入侵异常检测的效率。当主成分数为6时,均方根误差表现最小。
如图3,图4,图5,图6所示,为不同维度下的anfis测试结果图,图中横坐标为未做标记的样本点,纵坐标为样本点对应的值,包括样本点的真实值和anfis模型的预测值。对比四种不同情况下的模型预测值与真实值的分布情况,可以看出,当维度为6时,测试效果最佳,此后随着维度的提升模型测试效果逐渐变差。不同主成分数选择方案下,模型的评价指标如图7所示,可见,维度为6所对应的方案,模型实用效果最佳,此时的准确率(accuracy)为98.4%,召回率(recall)为98%,假阳率(fpr)为1.3%,查准率(precision)为98.7%,f1得分(f1score)为98.3%。由此可见,本发明能够有效地检测到异常数据,且具有较低的假阳率,极大地降低了误报情况的出现,并且经过对模糊规则库的优化,使模型的检测时间呈数量级下降,具有较高的实用性。
以上实施例是对本发明的解释,但是,本发明并不局限于上述实施方式中的具体细节,本领域的技术人员在本发明的技术构思范围内进行的多种等同替代或简单变型方式,均应属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!