一种鉴权方法、装置、电子设备及存储介质与流程
本发明涉及数据加密处理技术领域,特别是涉及一种鉴权方法、装置、电子设备及存储介质。
背景技术:
随着电子设备的迅猛发展,智能魔镜设备已经逐渐普及。智能魔镜设备作为物联网设备的入口,便于接入和控制包括如门禁系统、安防系统以及健康监控系统等多种物联网设备网络,从而负责信息收集、上报和各类操控指令的下发,因此其安全性尤为重要。
为了保证物联网设备的安全性,目前常用的鉴权方式包括登录密码、指纹认证、人脸识别和声纹识别等,而由于智能魔镜设备的结构限制,需要防止过多触摸造成镜面污垢,登录密码和指纹认证的方式无法适用于魔镜设备。同时,人脸识别所采用摄像头录入方式,易给用户带来隐私泄露的风险。
技术实现要素:
本发明提供一种鉴权方法、装置、电子设备及存储介质,以解决现有技术登录密码、指纹认证、人脸识别的验证方式易给用户造成隐私泄露的问题。
为了解决上述问题,本发明实施例公开了一种鉴权方法,应用于电子设备,包括:
接收目标用户输入的目标语音数据;
从设备声纹模型库中,获取与所述目标语音数据对应的第一声纹特征参数;
采用本地存储的私钥对所述第一声纹特征参数执行第一加密处理,生成待验证数据;
将所述待验证数据发送至服务器,以由所述服务器采用与所述私钥匹配的公钥对所述待验证数据进行解密处理,得到所述第一声纹特征参数,对所述第一声纹特征参数进行鉴权,得到鉴权结果;
接收由所述服务器返回的所述鉴权结果。
可选地,所述从设备声纹模型库中,获取与所述目标语音数据对应的第一声纹特征参数的步骤,包括:
提取所述目标语音数据中的目标声纹特征参数;
将所述目标声纹特征参数与所述设备声纹模型库中的多个预存声纹特征参数进行匹配,得到至少一个匹配声纹特征参数;
获取所述目标声纹特征参数与每个所述匹配声纹特征参数对应的匹配概率值;
依据相似准则和各所述匹配概率值,从所述至少一个匹配声纹特征参数中确定出所述第一声纹特征参数。
可选地,所述采用本地存储的私钥对所述第一声纹特征参数执行第一加密处理,生成待验证数据的步骤,包括:
计算得到所述第一声纹特征参数对应的第一哈希值;
获取所述电子设备的设备标识;
获取所述第一声纹特征参数在所述设备声纹模型库中所处分组的分组标识;
采用所述私钥,对所述第一哈希值、所述设备标识和所述分组标识进行加密,生成所述待验证数据。
可选地,所述接收由所述服务器返回的所述鉴权结果的步骤,包括:
接收由所述服务器发送的采用所述公钥对鉴权结果和预置密钥进行加密的加密鉴权结果;
在所述接收由所述服务器返回的所述鉴权结果的步骤之后,还包括:
采用所述私钥对所述加密鉴权结果进行解密,得到所述预置密钥和所述鉴权结果;
在所述鉴权结果为鉴权成功的情况下,获取所述目标用户发送的数据请求;
采用所述预置密钥对所述数据请求进行加密,得到加密数据请求;
将所述加密数据请求发送至所述服务器。
为了解决上述问题,本发明实施例公开了一种鉴权方法,应用于服务器,包括:
接收由电子设备发送的经私钥加密的待验证数据;
采用与所述私钥对应的公钥,对所述待验证数据进行解密,得到待验证解密数据;
从服务器声纹模型库中,获取与所述待验证解密数据对应的第二声纹特征参数;
根据所述第二声纹特征参数对所述待验证解密数据进行鉴权处理,得到鉴权结果;
采用所述公钥对所述鉴权结果进行加密,得到加密鉴权结果;
将所述加密鉴权结果发送至所述电子设备。
可选地,在所述接收由电子设备发送的经私钥加密的待验证数据之前,还包括:
对多个用户输入的语音数据进行预处理,得到相应的音频样本;
对每个所述音频样本进行变换处理,生成每个所述语音数据对应的声纹特征参数;
基于多个所述声纹特征参数对初始高斯混合模型进行训练,生成声纹模型库;
将所述声纹模型库保存至本地,得到所述服务器声纹模型库,并将所述声纹模型库发送至所述电子设备保存,得到设备声纹模型库。
可选地,所述对多个用户输入的语音数据进行预处理,得到相应的音频样本的步骤,包括:
采集多个用户输入的语音信号;
对每个所述语音信号进行类型转换处理,得到多个语音数据;
对每个所述语音数据进行预加重处理,得到多个预加重语音数据;
采用分帧加窗技术,按照预置采样率将每个所述预加重语音数据划分为多个语音段;
获取多个语音段中的有效语音段,将所述有效语音段作为所述音频样本。
可选地,所述对每个所述音频样本进行变换处理,生成每个所述语音数据对应的声纹特征参数的步骤,包括:
针对每个所述音频样本,对所述音频样本进行傅里叶变换处理,得到所述音频样本中包含的每一帧音频信号对应的线性频谱;
对每帧音频信号对应的所述线性频谱进行取模处理,得到所述线性频谱对应的能量谱;
对所述线性频谱对应的能量谱进行尺度变换处理,得到所述线性频谱对应的变换能量谱;
对所述变换能量谱进行倒谱分析,确定所述语音数据对应的声纹特征参数。
可选地,在所述接收由电子设备发送的经私钥加密的待验证数据的步骤之前,还包括:
获取预先选择的大于设定阈值的第一素数和第二素数;
根据所述第一素数和第二素数,计算得到第一数值;
根据所述第一数值和欧拉函数,计算得到欧拉数值;
获取与所述欧拉数值互质的质数;所述质数大于1,且小于所述欧拉数值;
根据所述质数和所述欧拉数值,按照互余函数计算得到第二数值;
基于所述质数和所述第一数值,计算得到所述公钥;
基于所述第一数值和所述第二数值,计算得到所述私钥;
将所述公钥保存至本地,并将所述私钥发送至所述电子设备。
可选地,所述待验证解密数据包括第一声纹特征参数在设备声纹模型库中所处分组的分组标识、所述电子设备的设备标识和所述第一声纹特征参数对应的第一哈希值,
所述从服务器声纹模型库中,获取与所述待验证解密数据对应的第二声纹特征参数的步骤,包括:
根据所述设备标识,从所述服务器声纹模型库中查找与所述分组标识对应的第二声纹特征参数;
所述根据所述第二声纹特征参数对所述待验证解密数据进行鉴权处理,得到鉴权结果的步骤,包括:
计算得到所述第二声纹特征参数对应的第二哈希值;
将所述第二哈希值与所述第一哈希值进行比较,得到比较结果;
根据所述比较结果,确定所述鉴权结果。
可选地,所述根据所述比较结果,确定所述鉴权结果的步骤,包括:
在所述比较结果为所述第二哈希值与所述第一哈希值相同的结果时,得到鉴权成功的结果;
在所述比较结果为所述第二哈希值与所述第一哈希值不相同的结果时,得到鉴权失败的结果。
为了解决上述问题,本发明实施例公开了一种鉴权装置,应用于电子设备,包括:
目标语音数据接收器,用于接收目标用户输入的目标语音数据;
第一声纹特征获取器,用于从设备声纹模型库中,获取与所述目标语音数据对应的第一声纹特征参数;
待验证数据生成器,用于采用本地存储的私钥对所述第一声纹特征参数执行第一加密处理,生成待验证数据;
待验证数据发送器,用于将所述待验证数据发送至服务器,以由所述服务器采用与所述私钥匹配的公钥对所述待验证数据进行解密处理,得到所述第一声纹特征参数,对所述第一声纹特征参数进行鉴权,得到鉴权结果;
鉴权结果接收器,用于接收由所述服务器返回的所述鉴权结果。
可选地,所述第一声纹特征获取器包括:
目标声纹特征提取单元,用于提取所述目标语音数据中的目标声纹特征参数;
匹配声纹特征获取单元,用于将所述目标声纹特征参数与所述设备声纹模型库中的多个预存声纹特征参数进行匹配,得到至少一个匹配声纹特征参数;
匹配概率值获取单元,用于获取所述目标声纹特征参数与每个所述匹配声纹特征参数对应的匹配概率值;
第一声纹特征确定单元,用于依据相似准则和各所述匹配概率值,从所述至少一个匹配声纹特征参数中确定出所述第一声纹特征参数。
可选地,所述待验证数据生成器包括:
第一哈希值计算单元,用于计算得到所述第一声纹特征参数对应的第一哈希值;
设备标识获取单元,用于获取所述智能魔镜设备的设备标识;
分组标识获取单元,用于获取所述第一声纹特征参数在所述设备声纹模型库中所处分组的分组标识;
待验证数据生成单元,用于采用所述私钥,对所述第一哈希值、所述设备标识和所述分组标识进行加密,生成所述待验证数据。
可选地,所述鉴权结果接收器包括:
加密鉴权结果接收单元,用于接收由所述服务器发送的采用所述公钥对鉴权结果和预置密钥进行加密的加密鉴权结果;
所述装置还包括:
预置密钥获取器,用于采用所述私钥对所述加密鉴权结果进行解密,得到所述预置密钥和所述鉴权结果;
数据请求获取器,用于在所述鉴权结果为鉴权成功的情况下,获取所述目标用户发送的数据请求;
加密请求获取器,用于采用所述预置密钥对所述数据请求进行加密,得到加密数据请求;
加密请求发送器,用于将所述加密数据请求发送至所述服务器。
为了解决上述问题,本发明实施例公开了一种鉴权装置,应用于服务器,包括:
待验证数据接收器,用于接收由电子设备发送的经私钥加密的待验证数据;
解密数据获取器,用于采用与所述私钥对应的公钥,对所述待验证数据进行解密,得到待验证解密数据;
第二声纹特征获取器,用于从服务器声纹模型库中,获取与所述待验证解密数据对应的第二声纹特征参数;
鉴权结果获取器,用于根据所述第二声纹特征参数对所述待验证解密数据进行鉴权处理,得到鉴权结果;
加密加权结果获取器,用于采用所述公钥对所述鉴权结果进行加密,得到加密鉴权结果;
加密加权结果发送器,用于将所述加密鉴权结果发送至所述电子设备。
可选地,还包括:
音频样本获取器,用于对多个用户输入的语音数据进行预处理,得到相应的音频样本;
声纹特征生成器,用于对每个所述音频样本进行变换处理,生成每个所述语音数据对应的声纹特征参数;
声纹模型库生成器,用于基于多个所述声纹特征参数对初始高斯混合模型进行训练,生成声纹模型库;
设备服务器模型获取器,用于将所述声纹模型库保存至本地,得到所述服务器声纹模型库,并将所述声纹模型库发送至所述电子设备保存,得到设备声纹模型库。
可选地,所述音频样本获取器包括:
语音信号采集单元,用于采集多个用户输入的语音信号;
语音数据获取单元,用于对每个所述语音信号进行类型转换处理,得到多个语音数据;
预加重数据获取单元,用于对每个所述语音数据进行预加重处理,得到多个预加重语音数据;
语音段划分单元,用于采用分帧加窗技术,按照预置采样率将每个所述预加重语音数据划分为多个语音段;
音频样本获取单元,用于获取多个语音段中的有效语音段,将所述有效语音段作为所述音频样本。
可选地,所述声纹特征生成器包括:
线性频谱获取单元,用于针对每个所述音频样本,对所述音频样本进行傅里叶变换处理,得到所述音频样本中包含的每一帧音频信号对应的线性频谱;
能量谱获取单元,用于对每帧音频信号对应的所述线性频谱进行取模处理,得到所述线性频谱对应的能量谱;
变换能量谱获取单元,用于对所述线性频谱对应的能量谱进行尺度变换处理,得到所述线性频谱对应的变换能量谱;
声纹特征参数确定单元,用于对所述变换能量谱进行倒谱分析,确定所述语音数据对应的声纹特征参数。
可选地,还包括:
素数获取器,用于获取预先选择的大于设定阈值的第一素数和第二素数;
第一数值计算器,用于根据所述第一素数和第二素数,计算得到第一数值;
欧拉数值计算器,用于根据所述第一数值和欧拉函数,计算得到欧拉数值;
质数获取器,用于获取与所述欧拉数值互质的质数;所述质数大于1,且小于所述欧拉数值;
第二数值计算器,用于根据所述质数和所述欧拉数值,按照互余函数计算得到第二数值;
公钥计算器,用于基于所述质数和所述第一数值,计算得到所述公钥;
私钥计算器,用于基于所述第一数值和所述第二数值,计算得到所述私钥;
私钥发送器,用于将所述公钥保存至本地,并将所述私钥发送至所述智能魔镜设备。
可选地,所述待验证解密数据包括第一声纹特征参数在设备声纹模型库中所处分组的分组标识、所述智能魔镜设备的设备标识和所述第一声纹特征参数对应的第一哈希值,
所述第二声纹特征获取器包括:
第二声纹特征查找单元,用于根据所述设备标识,从所述服务器声纹模型库中查找与所述分组标识对应的第二声纹特征参数;
所述鉴权结果获取器包括:
第二哈希值计算单元,用于计算得到所述第二声纹特征参数对应的第二哈希值;
比较结果获取单元,用于将所述第二哈希值与所述第一哈希值进行比较,得到比较结果;
鉴权结果确定单元,用于根据所述比较结果,确定所述鉴权结果。
可选地,所述鉴权结果确定单元包括:
鉴权成功结果获取子单元,用于在所述比较结果为所述第二哈希值与所述第一哈希值相同的结果时,得到鉴权成功的结果;
鉴权失败结果获取子单元,用于在所述比较结果为所述第二哈希值与所述第一哈希值不相同的结果时,得到鉴权失败的结果。
为了解决上述问题,本发明实施例还公开了一种电子设备,包括:处理器、存储器以及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述程序时实现上述任一项所述的鉴权方法。
为了解决上述问题,本发明实施例还公开了计算机可读存储介质,存储有计算机指令,当所述计算机指令由电子设备的处理器执行时,使得电子设备能够执行上述任一项所述的鉴权方法。
与现有技术相比,本发明包括以下优点:
本发明实施例提供的鉴权方法、装置、电子设备及存储介质,通过接收目标用户输入的目标语音数据,从设备声纹模型库中,获取与目标语音数据对应的第一声纹特征参数,采用本地存储的私钥对第一声纹特征参数执行第一加密处理,生成待验证数据,将待验证数据发送至服务器,以由服务器采用与所述私钥匹配的公钥对待验证数据进行解密处理,得到第一声纹特征参数,对第一声纹特征参数进行鉴权,得到鉴权结果,接收由服务器返回的鉴权结果。本发明实施例声纹特征参数与公私钥相结合的鉴权方式,能够避免用户隐私泄露的风险。
附图说明
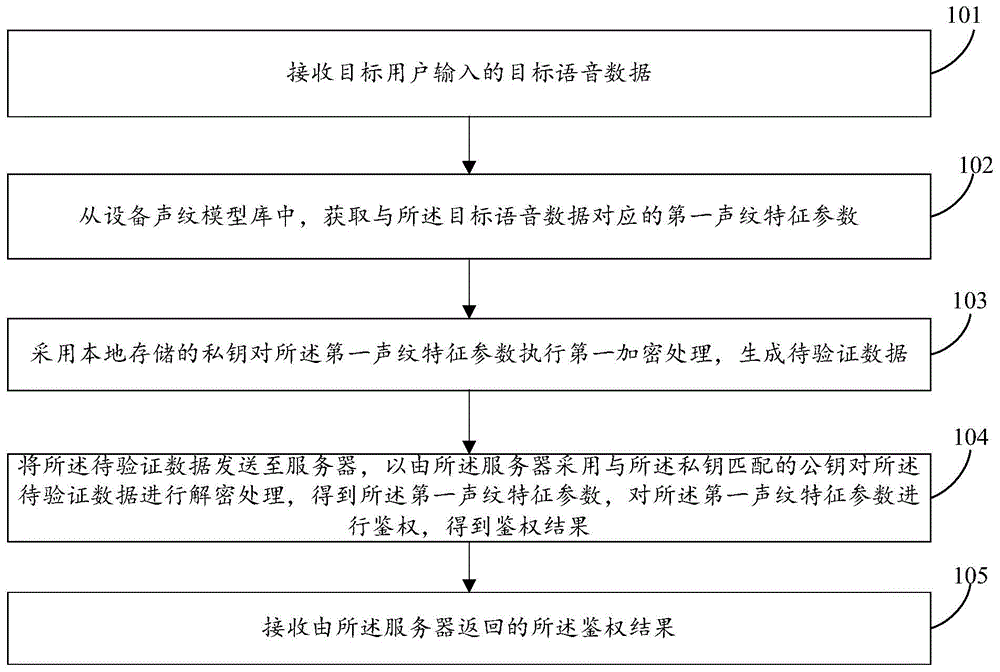
图1是本发明实施例提供的一种鉴权方法的步骤流程图;
图1a是本发明实施例提供的一种确定声纹特征参数的流程图;
图1b是本发明实施例提供的一种生成待验证数据的流程图;
图1c是本发明实施例提供的一种生成加密数据请求的流程图;
图2是本发明实施例提供的一种鉴权系统的示意图;
图3是本发明实施例提供的一种鉴权方法的步骤流程图;
图3a是本发明实施例提供的一种生成声纹模型库的流程图;
图3b是本发明实施例提供的一种确定鉴权结果的流程图;
图4是本发明实施例提供的一种鉴权装置的结构示意图;
图5是本发明实施例提供的一种鉴权装置的结构示意图。
具体实施方式
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
参照图1,示出了本发明实施例提供的一种鉴权方法的步骤流程图,该鉴权方法可以应用于电子设备,具体可以包括如下步骤:
步骤101:接收目标用户输入的目标语音数据。
在本发明实施例中,电子设备可以为智能魔镜设备,智能魔镜设备是指过在传统镜子内嵌入显示屏、传感器和操作系统,为镜子新增了镜面显示以及人镜互动的功能,从而成为了电脑、电视、手机等之外的“第四屏”。
在下述实施例中,以电子设备为智能魔镜设备为例,对本发明实施例的技术方案进行详细描述。
智能魔镜设备可以包括生活模块:天气、出行、日历、时间等;智能家居模块:开关、插座、窗帘、摄像头、门禁等;健康模块:血压、血糖、体重、睡眠等;美容模块:皮肤检测、提拉去皮等。
当然,智能魔镜设备还可以提供如健康服务、娱乐等功能,具体地,可以根据实际情况而定,本发明实施例对此不加以限制。
目标语音数据是指对采集的用户输入的语音信号进行预处理之后,得到的语音数据。
在智能魔镜设备上可以预先设置语音采集模块,语音采集模块可以为拾音头、监听头等语音信号采集设备,通过语音采集模块可以采集用户输入的语音信号,并对语音信号进行预处理过程,从而得到目标语音数据。
在接收目标用户输入的目标语音数据之后,执行步骤102。
步骤102:从设备声纹模型库中,获取与所述目标语音数据对应的第一声纹特征参数。
设备声纹模型库是指预先保存于本地系统中的,用于保存声纹特征参数的模型库,在设备声纹模型库中预先保存有已授权用户的声纹特征参数,例如,智能魔镜设备对用户a、用户b和用户c已进行授权,可以在设备声纹模型库中保存用户a、用户b和用户c分别对应的声纹特征参数。
在获取本地保存的设备声纹模型库之后,可以根据目标语音数据所对应的声纹特征参数与设备声纹模型库中的声纹特征参数进行匹配,从而得到匹配的第一声纹特征参数,具体地,结合下述具体实现方式进行详细描述。
在本发明的一种具体实现中,上述步骤102可以包括:
子步骤1021:提取所述目标语音数据中的目标声纹特征参数。
在本发明实施例中,目标声纹特征参数是指从目标语音数据中提取的声纹特征参数。
在采集到目标用户输入的目标语音数据之后,可以从目标语音数据中提取出目标声纹特征参数,并执行子步骤1022。
子步骤1022:将所述目标声纹特征参数与所述设备声纹模型库中的多个预存声纹特征参数进行匹配,得到至少一个匹配声纹特征参数。
在提取出目标声纹特征参数之后,可以将目标声纹特征参数与设备声纹模型库中的多个预存声纹特征参数进行匹配,在匹配失败时,则不再执行后续步骤。
可以理解地,本发明实施例仅考虑匹配成功的情况。
而在匹配成功时,可以获取与目标声纹特征参数匹配的至少一个匹配声纹特征参数。
在将目标声纹特征参数与设备声纹模型库中的多个预存声纹特征参数进行匹配,得到至少一个匹配声纹特征参数之后,执行子步骤1023。
子步骤1023:获取所述目标声纹特征参数与每个所述匹配声纹特征参数对应的匹配概率值。
在得到至少一个匹配声纹特征参数之后,可以获取目标声纹特征参数与每个匹配声纹特征参数对应的匹配概率值。
匹配概率值越大表示匹配度越高,而匹配概率值越小,表示匹配度越低。
而获取匹配概率值的技术已经是本领域较为成熟的技术,本发明实施例在此不再加以详细描述。
在获取目标声纹特征参数与每个匹配声纹特征参数对应的匹配概率值之后,执行子步骤1024。
子步骤1024:依据相似准则和各所述匹配概率值,从所述至少一个匹配声纹特征参数中确定出所述第一声纹特征参数。
在计算得到匹配概率值之后,可以按照相似性准则,从至少一个匹配声纹特征参数中确定出第一声纹特征参数。具体地,可以依据相似性准则决策出最优结果进行判决,判决阈值由实验方式获得最优值。
在从设备声纹模型库中获取与目标语音数据对应的第一声纹特征参数之后,执行步骤103。
步骤103:采用本地存储的私钥对所述第一声纹特征参数执行第一加密处理,生成待验证数据。
本发明实施例中,是采用rsa(rsaalgorithm,公钥加密算法)对智能魔镜设备和服务器之间传输的数据请求进行的加密处理方式,在智能魔镜设备端存储有私钥,在服务器侧存储有公钥,公钥和私钥是由服务器侧预先生成的,并由服务器保存公钥,并由智能魔镜设备保存私钥。
在得到目标用户的第一声纹特征参数之后,可以采用私钥对第一声纹特征参数进行第一加密处理,从而可以得到经过加密的待验证数据。
而对于第一声纹特征参数的加密过程可以参照下述具体实现方式的描述。
在本发明的一种具体实现中,上述步骤103可以包括:
子步骤1031:计算得到所述第一声纹特征参数对应的第一哈希值。
在本发明实施例中,第一哈希值是指对第一声纹特征参数进行计算之后得到的哈希值。
哈希值又称散列函数(或散列算法,又称哈希函数,hashfunction)是一种从任何一种数据中创建小的数字“指纹”的方法。散列函数把消息或数据压缩成摘要,使得数据量变小,将数据的格式固定下来。该函数将数据打乱混合,重新创建一个叫做散列值的指纹。
在得到第一声纹特征参数之后,可以计算得到第一声纹特征参数对应的哈希值(即第一哈希值)。
子步骤1032:获取所述电子设备的设备标识。
设备标识是指电子设备所对应的标识。
设备标识可以预先存储于智能魔镜设备对应的指定存储空间中的,在需要时,可以直接从指定存储空间中获取智能魔镜设备的设备标识。
子步骤1033:获取所述第一声纹特征参数在所述设备声纹模型库中所处分组的分组标识。
在设备声纹模型库中,不同的声纹特征参数对应于不同的分组,每个分组均对应于唯一一个分组标识,如第一声纹特征参数位于分组1,分组1的分组标识为a等。
在得到第一声纹特征参数之后,可以查找第一声纹特征参数在设备声纹模型库中所处的分组,并获取该分组的分组标识,进而,执行子步骤1034。
子步骤1034:采用所述私钥,对所述第一哈希值、所述设备标识和所述分组标识进行加密,生成所述待验证数据。
在上述步骤中,得到第一哈希值、设备标识和分组标识之后,可以采用私钥对第一哈希值、设备标识和分组标识进行加密,从而生成待验证数据。
在采用本地存储的私钥对第一声纹特征参数执行第一加密处理,生成待验证数据之后,执行步骤104。
步骤104:将所述待验证数据发送至服务器,以由所述服务器采用与所述私钥匹配的公钥对所述待验证数据进行解密处理,得到所述第一声纹特征参数,对所述第一声纹特征参数进行鉴权,得到鉴权结果。
在生成待验证数据之后,可以将待验证数据发送至服务器,服务器可以采用与私钥匹配的公钥对待验证数据进行解密处理,从而得到第一声纹特征参数,并对第一声纹特征参数进行鉴权,从而得到鉴权结果,对于解密鉴权的详细过程将在下述实施例二中进行详细描述,本发明实施例在此不再加以赘述。
在服务器得到鉴权结果之后,可以采用随机生成的预置密钥和公钥对鉴权结果进行加密,得到加密后的鉴权结果,并将加密后的鉴权结果返回至智能魔镜设备。
步骤105:接收由所述服务器返回的所述鉴权结果。
智能魔镜设备可以接收由服务器返回的鉴权结果,可以理解地,鉴权结果可以包括鉴权成功的结果和鉴权失败的结果,在鉴权成功的情况下,用户可以对与智能魔镜设备关联的物联网设备执行相应的操作,如门禁系统、安防系统以及健康监控系统等。
而在鉴权失败的情况下,表示目标用户并非授权用户,不能够对与智能魔镜设备关联的物联网设备进行控制。
在得到鉴权结果之后,可以在鉴权成功的情况下,由用户通过智能魔镜设备向服务器发送数据请求的方式,对关联的物联网设备进行控制,具体地,结合下述具体实现方式进行详细描述。
在本发明的一种具体实现方式中,上述步骤105可以包括:
子步骤s1:接收由所述服务器发送的采用所述公钥对鉴权结果和预置密钥进行加密的加密鉴权结果。
在本发明实施例中,预置密钥是指由服务器侧随机生成的密钥,例如,服务器随机生成112bit加密密钥k等。
鉴权结果是指服务器对电子设备发送的待验证数据进行鉴权之后,得到的结果,鉴权结果可以包括鉴权成功的结果和鉴权失败的结果。
在服务器随机生成预置密钥之后,可以采用预先存储的公钥对预置密钥和鉴权结果进行加密,得到加密鉴权结果,并将加密鉴权结果返回至智能魔镜设备。
智能魔镜设备接收服务器返回的加密鉴权结果,并执行下述步骤。
在上述步骤105之后,还可以包括:
步骤1051:采用所述私钥对所述加密鉴权结果进行解密,得到所述预置密钥和所述鉴权结果。
在智能魔镜设备接收服务器返回的加密鉴权结果,可以采用私钥对加密鉴权结果进行解密,从而可以解析出预置密钥和鉴权结果,并执行步骤1052。
步骤1052:在所述鉴权结果为鉴权成功的情况下,获取所述目标用户发送的数据请求。
在鉴权结果为鉴权成功的情况下,目标用户可以对与智能魔镜设备关联的物联网设备进行控制,具体地,可以生成与物联网设备对应的控制指令,如开启空调、播放音乐等指令,例如,当用户需要操作门禁和安防等物联网外设时,需念出固定解锁码,固定的读数利于声纹识别同时增加校准数据。在声纹识别授权的情况下,用户可通过点击按钮或语音控制操控门禁或安防设备的打开和关闭等。
智能魔镜设备可以接收用户输入的控制指令,并根据该控制指令生成相应的数据请求,进而,执行步骤1053。
步骤1053:采用所述预置密钥对所述数据请求进行加密,得到加密数据请求。
在得到数据请求之后,可以采用预置密钥对数据请求进行加密,从而得到加密数据请求,因rsa算法需进行取模操作,具有较低的运算速度,不适合每次均加密的情况,因此采用3des算法进行认证后的数据加密,在保证安全性的同时,提高效率。
步骤1054:将所述加密数据请求发送至所述服务器。
在得到加密数据请求之后,可以将加密数据请求发送至服务器,并由服务器根据数据请求及目标用户可操作的权限,确定是否执行相应的控制指令。
接下来结合图2对本发明实施例提供的鉴权系统进行如下描述。
参照图2,示出了本发明实施例提供的一种鉴权系统的示意图,如图2所示,鉴权系统可以包括智能魔镜设备1和服务器2,其中,智能魔镜设备1包括显示屏11、麦克风13和cpu1(centralprocessingunit,中央处理器)2,其中,智能魔镜设备1可以提供如下功能:
1、对于设备的音乐播放功能,提供歌单收藏模式,可将用户挑选的歌曲信息同步到云端服务器该用户帐号下,每次用户登录并使用音乐功能时,将通过远程加密功能获取云端服务器收藏名录;
2、魔镜设备提供显示设置等功能,可定制系统界面ui元素(位置、隐藏)和ui颜色,对于不同用户,其有自己喜好的选择,需保存在云端服务器用于登录后的动态加载;
3、因电子设备对于儿童吸引力较大,且魔镜具备音乐和视频相关播放功能,更易吸引儿童长时间使用,为保障儿童在监护人未在身旁时,无法长时间使用播放功能或操作门禁安防等安全设施,通过区分成人及儿童声纹,进行儿童锁保护,限制儿童用户的操作权限和时间;
4、tts播报:根据声纹信息,提供男性、女性、儿童不同的语音tts声调,满足个性化需求;
5、玄关镜和浴室镜通过管理员用户的声纹,可同步其他用户的声纹保存在本地,并设置权限。
其中麦克风13负责采集语音信号,显示屏11负责显示ui界面,cpu12负责设备管控,服务器2负责保存云端语音识别特征参数和用户个人信息数据。
本发明实施例采用声纹特征参数与公私钥相结合的鉴权方式,在能够避免鉴权过程中造成镜面污垢的同时,也能够避免用户隐私泄露的风险。
本发明实施例提供的鉴权方法,通过接收目标用户输入的目标语音数据,从设备声纹模型库中,获取与目标语音数据对应的第一声纹特征参数,采用本地存储的私钥对第一声纹特征参数执行第一加密处理,生成待验证数据,将待验证数据发送至服务器,以由服务器采用与所述私钥匹配的公钥对待验证数据进行解密处理,得到第一声纹特征参数,对第一声纹特征参数进行鉴权,得到鉴权结果,接收由服务器返回的鉴权结果。本发明实施例采用声纹特征参数与公私钥相结合的鉴权方式,能够避免用户隐私泄露的风险。
参照图3,示出了本发明实施例提供的一种鉴权方法的步骤流程图,该鉴权方法可以应用于服务器,具体可以包括如下步骤:
步骤201:接收由电子设备发送的经私钥加密的待验证数据。
本发明实施例是采用rsa对智能设备和服务器之间发送的鉴权数据进行的加解密处理方式,在智能魔镜设备端存储有私钥,在服务器侧存储有公钥,公钥和私钥是由服务器侧预先生成的,并由服务器保存公钥,并由智能魔镜设备保存私钥。
对于公私钥的生成方式可以参照下述具体实现方式的描述。
在本发明的一种具体实现方式中,在上述步骤201之前,还可以包括:
步骤g1:获取预先选择的大于设定阈值的第一素数和第二素数。
在本发明实施例中,素数又称质数,是指一个大于1的自然数,除了1和它本身外,不能被其他自然数整除的数。
设定阈值是指由业务人员预先设置的阈值,对于设定阈值的具体数值可以根据业务需求而定,本发明实施例对此不加以限制。
在生成公私钥时,可以预先选择两个大于设定阈值的第一素数和第二素数,即选择两个足够大的素数(第一素数和第二素数),且第一素数和第二素数是不相等的。
本发明中,第一素数可以记为p,第二素数可以记为q,在下述步骤中将会用到。
在获取预先选择的第一素数和第二素数之后,执行步骤g2。
步骤g2:根据所述第一素数和第二素数,计算得到第一数值。
在得到第一素数p和第二素数q之后,可以计算第一数值n,n=pq。
在计算得到第一数值之后,执行步骤g3。
步骤g3:根据所述第一数值和欧拉函数,计算得到欧拉数值。
在得到第一数值n之后,可以采用欧拉函数计算欧拉数值:f(n)=(p-1)(q-1),其中f(n)即为欧拉数值。
在计算得到欧拉数值之后,执行步骤g4。
步骤g4:获取与所述欧拉数值互质的质数;所述质数大于1,且小于所述欧拉数值。
在计算得到欧拉数值之后,可以获取与欧拉数值f(n)互质的质数e,并且质数e是大于1,且小于f(n)的。
在获取质数之后,执行步骤g5。
步骤g5:根据所述质数和所述欧拉数值,按照互余函数计算得到第二数值。
在得到质数e和欧拉数值f(n)之后,可以根据:de≡1modf(n),计算得到第二数值d,其中≡是数论中表示同余的符号,即公式中,≡符号的左边必须和符号右边同余,也就是两边模运算结果相同,从而计算出d的值。
步骤g6:基于所述质数和所述第一数值,计算得到所述公钥。
进而,可以根据质数e和第一数值n计算得到公钥ku,即ku=(e,n)。
步骤g7:基于所述第一数值和所述第二数值,计算得到所述私钥。
在得到第一数值n和第二数值d之后,可以根据第一数值n和第二数值d计算得到私钥kr,即kr=(d,n)。
步骤g8:将所述公钥保存至本地,并将所述私钥发送至所述电子设备。
在上述步骤中得到公钥ku和私钥kr后,可以将公钥ku保存至服务器本地,并将私钥kr发送至智能魔镜设备。
可以理解地,上述获取公私钥的过程已经是本领域较为成熟的技术,本发明实施例在此不再加以详细描述。
服务器在接收到由电子设备发送的经私钥加密的待验证数据之后,执行步骤202。
步骤202:采用与所述私钥对应的公钥,对所述待验证数据进行解密,得到待验证解密数据。
在接收到智能魔镜设备发送的待验证数据之后,可以采用与私钥对应的公钥对待验证数据进行解密,从而得到待验证解密数据。
在得到待验证解密数据之后,执行步骤203。
步骤203:从服务器声纹模型库中,获取与所述待验证解密数据对应的第二声纹特征参数。
在得到待验证解密数据中包含有第一声纹特征参数在设备声纹模型库中所处分组的分组标识、智能魔镜设备的设备标识和第一声纹特征参数对应的第一哈希值。
对于服务器声纹模型库的生成过程,可以参照下述具体实现方式的描述。
在本发明的一种具体实现中,在上述步骤201之前,还可以包括:
步骤2010:对多个用户输入的语音数据进行预处理,得到相应的音频样本。
在本发明实施例中,多个用户是指多个已授权的用户,例如,对于智能魔镜设备对用户1、用户2、…、用户n(n为大于等于1的正整数)已添加授权,则可以采用用户1、用户2、…、用户n的语音数据。可以理解地,上述步骤中提及的目标用户即为多个用户中的一个用户。
针对多个已授权用户,可以采用预先设置的语音采集设备分别采集每个用户输入的语音数据。
在采集到语音数据之后,可以分别对语音数据进行预处理,如类型转换、降噪等,具体地,结合下述具体实现方式进行详细描述。
在本发明的另一种具体实现中,上述步骤2010可以包括:
子步骤b1:采集多个用户输入的语音信号。
在本发明实施例中,可以通过智能魔镜设备上预先设置的语音采集模块采集每个用户输入的语音信号,具体地,用户可以在语音采集模块可接收语音的范围内,以口述一段话的方式,供语音采集模块采集。
在采集多个用户输入的语音信号之后,执行子步骤b2。
子步骤b2:对每个所述语音信号进行类型转换处理,得到多个语音数据。
语音数据是指语音信号经过转换处理之后,生成的数据。
在采集到每个用户的语音信号之后,可以将采集的语音信号转换为电信号,并将电信号经模数转换处理,生成语音数据文件。
在对每个语音信号进行类型转换处理,得到多个语音数据之后,执行子步骤b3。
子步骤b3:对每个所述语音数据进行预加重处理,得到多个预加重语音数据。
由于在语音信号的采集过程中,可能会混入噪声信息,需要对语音信号进行降噪的语音预处理操作。
预加重是一种在发送端对输入信号高频分量进行补偿的信号处理方式。随着信号速率的增加,信号在传输过程中受损很大,为了在接收终端能得到比较好的信号波形,就需要对受损的信号进行补偿,预加重技术的思想就是在传输线的始端增强信号的高频成分,以补偿高频分量在传输过程中的过大衰减。
预加重语音数据是指对语音数据进行预加重处理之后得到的语音数据。
在得到多个语音数据之后,可以分别对每个语音数据进行预加重处理,得到每个语音数据所对应的预加重语音数据,即对语音数据中不断衰减的高频部分进行补偿,使整段语音频谱变得更加平缓。
在对每个语音数据进行预加重处理,得到多个预加重语音数据之后,执行子步骤b4。
子步骤b4:采用分帧加窗技术,按照预置采样率将每个所述预加重语音数据划分为多个语音段。
分帧是为了将无限长的语音信号,分成一段一段的,因为语音信号具有短时平稳性,方便处理,加窗是为了使分帧后的语音信号更加平稳。窗函数主要有矩形窗和汉明窗。加窗主要是为了使时域信号似乎更好地满足fft处理的周期性要求,减少泄漏。
预置采样率是指分帧时所采用的采样率,对于预置采样率的大小可以根据业务需求而定,本发明实施例对此不加以限制。
在本发明中,可以采用分帧加窗技术,按照预置采样率(如等)将每个预加重语音数据划分为多个语音段,如采用语音16khz的采样率大小,将语音数据进行划分,得到的语音段每帧定为256采样点,即一帧时长为16ms,以满足人类语音信号的短时平稳性。
在采用分帧加窗技术,按照预置采样率将每个预加重语音数据划分为多个语音段之后,执行子步骤b5。
子步骤b5:获取多个语音段中的有效语音段,将所述有效语音段作为所述音频样本。
有效语音段是指多个语音段中有效的语音段。
在得到每个预加重语音数据对应的多个语音段之后,可以采用设立门限检测预加重语音数据的起始点和终止点,并截取出有效的语音段(即有效语音段),而去除多余的信息,实现端点检测,提高系统的识别精度。
在对多个用户输入的语音数据进行预处理,得到相应的音频样本之后,执行步骤2011。
步骤2011:对每个所述音频样本进行变换处理,生成每个所述语音数据对应的声纹特征参数。
声纹(voiceprint)是指用电声学仪器显示的携带言语信息的声波频谱。
在得到每个用户对应的音频样本之后,可以对每个音频样本进行变换处理,从而可以得到每个语音数据所对应的声纹特征参数,具体地变换处理过程可以结合下述具体实现方式进行详细描述。
在本发明的一种具体实现方式中,上述步骤2011可以包括:
子步骤c1:针对每个所述音频样本,对所述音频样本进行傅里叶变换处理,得到所述音频样本中包含的每一帧音频信号对应的线性频谱。
在本发明实施例中,傅里叶变换(fft,fouriertransform)能将满足一定条件的某个函数表示成三角函数(正弦和/或余弦函数)或者它们的积分的线性组合。
在得到音频样本之后,可以对上述采集到的音频样本采用快速傅里叶变换,具体地,可以选取基2的256点傅里叶变换方式,在经傅里叶变换处理后,可以得到音频样本中包含的每一帧音频信号对应的线性频谱。
在得到音频样本中包含的每一帧音频信号对应的线性频谱之后,执行子步骤c2。
子步骤c2:对每帧音频信号对应的所述线性频谱进行取模处理,得到所述线性频谱对应的能量谱。
在得到每帧音频信号的线性频谱之后,可以对每帧音频信号对应的线性频率进行取模处理,从而得到线性频谱所对应的能量谱,例如,每帧都由256个fft值(复数)表示,将其取模得到256个实数,即能量谱。则语音样本每帧由256个fft模值表示。
在得到线性频谱对应的能量谱之后,执行子步骤c3。
子步骤c3:对所述线性频谱对应的能量谱进行尺度变换处理,得到所述线性频谱对应的变换能量谱。
为了尽可能的模拟人耳对声音的感知,一般都是将能量谱做尺度变换,让其映射到mel频率尺度下,即对经过fft后的语音自然频谱的横轴做非线性的尺度变换得到mel频率尺度下的新能量谱(即变换能量谱)。
在得到变换能量谱之后,执行子步骤c4。
子步骤c4:对所述变换能量谱进行倒谱分析,确定所述语音数据对应的声纹特征参数。
在得到变换能量谱之后,可以对变换能量谱进行倒谱分析(如梅尔倒谱分析等),从而可以得到声纹特征参数。
在对每个音频样本进行变换处理,生成每个语音数据对应的声纹特征参数之后,执行步骤2012。
步骤2012:基于多个所述声纹特征参数对初始高斯混合模型进行训练,生成声纹模型库。
基于上述步骤2011中得到的声纹特征参数,然后依照该声纹特征参数训练语音信号的高斯混合模型(gmm),组成声纹模型库,即该模型可以用多个高斯分布的密度函数的组合来描述特征矢量在概率空间的分布情况。
步骤2013:将所述声纹模型库保存至本地,得到所述服务器声纹模型库,并将所述声纹模型库发送至所述电子设备保存,得到设备声纹模型库。
声纹模型库被分别保存在云端服务器和本地数据存储模块中,并且,保存至电子设备中的即为设备声纹模型库,在电子设备侧可以存储将使用用户预留的密码进行加密保存,防止篡改。保存至服务器本地的声纹模型库即为服务器声纹模型库。
进而,可以根据待验证解密数据从服务器声纹模型库中获取相应的第二声纹特征参数,具体地,以下述具体实现方式进行详细描述。
在本发明的一种具体实现方式中,上述步骤203可以包括:
子步骤h1:根据所述设备标识,从所述服务器声纹模型库中查找与所述分组标识对应的第二声纹特征参数。
在本发明实施例中,在得到智能魔镜设备的设备标识之后,可以根据设备标识查找与设备标识对应的多个分组,进而,可以根据第一声纹特征参数对应的分组标识获取与查找与分组标识对应的第二声纹特征参数。
在从服务器声纹模型库中获取与待验证解密数据对应的第二声纹特征参数之后,执行步骤204。
步骤204:根据所述第二声纹特征参数对所述待验证解密数据进行鉴权处理,得到鉴权结果。
在得到待验证解密数据对应的第二声纹特征参数之后,可以根据第二声纹特征参数对待验证解密数据进行鉴权处理,从而得到鉴权结果,具体地鉴权过程,可以参照下述具体实现方式的描述。
在本公开的一种具体实现中,上述步骤204可以包括:
子步骤2041:计算得到所述第二声纹特征参数对应的第二哈希值。
在本发明实施例中,第二哈希值是指对第二声纹特征参数进行计算得到的哈希值。
在得到第二声纹特征参数之后,可以对第二声纹特征参数进行计算,从而计算得到第二声纹特征参数对应的第二哈希值,进而,执行子步骤2042。
子步骤2042:将所述第二哈希值与所述第一哈希值进行比较,得到比较结果。
在得到第二哈希值之后,可以将第二哈希值与第一哈希值进行比较,以得到比较结果,其中,本发明中,比较结果可以包括相同的结果和不同的结果。
子步骤2043:根据所述比较结果,确定所述鉴权结果。
在得到第二哈希值和第一哈希值的比较结果之后,可以根据比较结果确定鉴权结果,即在第二哈希值和第一哈希值相同时,则鉴权结果为鉴权成功的结果。
而在第二哈希值和第一哈希值不相同时,则鉴权结果为鉴权失败的结果。
步骤205:采用所述公钥对所述鉴权结果进行加密,得到加密鉴权结果。
在得到鉴权结果之后,可以采用公钥对鉴权结果进行加密,从而得到加密鉴权结果。
而在鉴权结果为鉴权成功的结果时,可以由服务器随机生成一个112bit的预置密钥,采用公钥和预置密钥相结合的方式共同为鉴权结果加密,从而在后续过程中,可以直接采用预置密钥进行加密,保证数据互发过程中的数据安全性。
步骤206:将所述加密鉴权结果发送至所述电子设备。
在得到加密鉴权结果之后,可以将加密鉴权结果发送至智能魔镜设备。
进而由智能魔镜设备采用私钥进行解密,并根据解密得到的鉴权结果确定是否允许用户对与智能魔镜设备关联的物联网设备进行控制。
本发明实施例提供的鉴权方法,通过接收由智能魔镜设备发送的经私钥加密的待验证数据,采用与私钥对应的公钥,对待验证数据进行解密,得到待验证解密数据,从服务器声纹模型库中,获取与待验证解密数据对应的第二声纹特征参数,根据第二声纹特征参数对待验证解密数据进行鉴权处理,得到鉴权结果,采用公钥对所述鉴权结果进行加密,得到加密鉴权结果,将加密鉴权结果发送至电子设备。本发明实施例采用声纹特征参数与公私钥相结合的鉴权方式,能够避免用户隐私泄露的风险。
参照图4,示出了本发明实施例提供的一种鉴权装置的结构示意图,该鉴权装置可以应用电子设备,具体可以包括如下模块:
目标语音数据接收器310,用于接收目标用户输入的目标语音数据;
第一声纹特征获取器320,用于从设备声纹模型库中,获取与所述目标语音数据对应的第一声纹特征参数;
待验证数据生成器330,用于采用本地存储的私钥对所述第一声纹特征参数执行第一加密处理,生成待验证数据;
待验证数据发送器340,用于将所述待验证数据发送至服务器,以由所述服务器采用与所述私钥匹配的公钥对所述待验证数据进行解密处理,得到所述第一声纹特征参数,对所述第一声纹特征参数进行鉴权,得到鉴权结果;
鉴权结果接收器350,用于接收由所述服务器返回的所述鉴权结果。
可选地,所述第一声纹特征获取器320包括:
目标声纹特征提取单元,用于提取所述目标语音数据中的目标声纹特征参数;
匹配声纹特征获取单元,用于将所述目标声纹特征参数与所述设备声纹模型库中的多个预存声纹特征参数进行匹配,得到至少一个匹配声纹特征参数;
匹配概率值获取单元,用于获取所述目标声纹特征参数与每个所述匹配声纹特征参数对应的匹配概率值;
第一声纹特征确定单元,用于依据相似准则和各所述匹配概率值,从所述至少一个匹配声纹特征参数中确定出所述第一声纹特征参数。
可选地,所述待验证数据生成器330包括:
第一哈希值计算单元,用于计算得到所述第一声纹特征参数对应的第一哈希值;
设备标识获取单元,用于获取所述电子设备设备的设备标识;
分组标识获取单元,用于获取所述第一声纹特征参数在所述设备声纹模型库中所处分组的分组标识;
待验证数据生成单元,用于采用所述私钥,对所述第一哈希值、所述设备标识和所述分组标识进行加密,生成所述待验证数据。
可选地,所述鉴权结果接收器350包括:
加密鉴权结果接收单元,用于接收由所述服务器发送的采用所述公钥对鉴权结果和预置密钥进行加密的加密鉴权结果;
所述装置还包括:
预置密钥获取器,用于采用所述私钥对所述加密鉴权结果进行解密,得到所述预置密钥和所述鉴权结果;
数据请求获取器,用于在所述鉴权结果为鉴权成功的情况下,获取所述目标用户发送的数据请求;
加密请求获取器,用于采用所述预置密钥对所述数据请求进行加密,得到加密数据请求;
加密请求发送器,用于将所述加密数据请求发送至所述服务器。
本发明实施例提供的鉴权装置,通过接收目标用户输入的目标语音数据,从设备声纹模型库中,获取与目标语音数据对应的第一声纹特征参数,采用本地存储的私钥对第一声纹特征参数执行第一加密处理,生成待验证数据,将待验证数据发送至服务器,以由服务器采用与所述私钥匹配的公钥对待验证数据进行解密处理,得到第一声纹特征参数,对第一声纹特征参数进行鉴权,得到鉴权结果,接收由服务器返回的鉴权结果。本发明实施例采用声纹特征参数与公私钥相结合的鉴权方式,能够避免用户隐私泄露的风险。
参照图5,示出了本发明实施例提供的一种鉴权装置的结构示意图,该鉴权装置可以应用服务器,具体可以包括如下模块:
待验证数据接收器410,用于接收由电子设备发送的经私钥加密的待验证数据;
解密数据获取器420,用于采用与所述私钥对应的公钥,对所述待验证数据进行解密,得到待验证解密数据;
第二声纹特征获取器430,用于从服务器声纹模型库中,获取与所述待验证解密数据对应的第二声纹特征参数;
鉴权结果获取器440,用于根据所述第二声纹特征参数对所述待验证解密数据进行鉴权处理,得到鉴权结果;
加密加权结果获取器450,用于采用所述公钥对所述鉴权结果进行加密,得到加密鉴权结果;
加密加权结果发送器460,用于将所述加密鉴权结果发送至所述电子设备。
可选地,所述装置还包括:
音频样本获取器,用于对多个用户输入的语音数据进行预处理,得到相应的音频样本;
声纹特征生成器,用于对每个所述音频样本进行变换处理,生成每个所述语音数据对应的声纹特征参数;
声纹模型库生成器,用于基于多个所述声纹特征参数对初始高斯混合模型进行训练,生成声纹模型库;
设备服务器模型获取器,用于将所述声纹模型库保存至本地,得到所述设备声纹模型库,并将所述声纹模型库发送至服务器保存,得到服务器声纹模型库。
可选地,所述音频样本获取器包括:
语音信号采集单元,用于采集多个用户输入的语音信号;
语音数据获取单元,用于对每个所述语音信号进行类型转换处理,得到多个语音数据;
预加重数据获取单元,用于对每个所述语音数据进行预加重处理,得到多个预加重语音数据;
语音段划分单元,用于采用分帧加窗技术,按照预置采样率将每个所述预加重语音数据划分为多个语音段;
音频样本获取单元,用于获取多个语音段中的有效语音段,将所述有效语音段作为所述音频样本。
可选地,所述声纹特征生成器包括:
线性频谱获取单元,用于针对每个所述音频样本,对所述音频样本进行傅里叶变换处理,得到所述音频样本中包含的每一帧音频信号对应的线性频谱;
能量谱获取单元,用于对每帧音频信号对应的所述线性频谱进行取模处理,得到所述线性频谱对应的能量谱;
变换能量谱获取单元,用于对所述线性频谱对应的能量谱进行尺度变换处理,得到所述线性频谱对应的变换能量谱;
声纹特征参数确定单元,用于对所述变换能量谱进行倒谱分析,确定所述语音数据对应的声纹特征参数。
可选地,所述装置还包括:
素数获取器,用于获取预先选择的大于设定阈值的第一素数和第二素数;
第一数值计算器,用于根据所述第一素数和第二素数,计算得到第一数值;
欧拉数值计算器,用于根据所述第一数值和欧拉函数,计算得到欧拉数值;
质数获取器,用于获取与所述欧拉数值互质的质数;所述质数大于1,且小于所述欧拉数值;
第二数值计算器,用于根据所述质数和所述欧拉数值,按照互余函数计算得到第二数值;
公钥计算器,用于基于所述质数和所述第一数值,计算得到所述公钥;
私钥计算器,用于基于所述第一数值和所述第二数值,计算得到所述私钥;
私钥发送器,用于将所述公钥保存至本地,并将所述私钥发送至所述电子设备。
可选地,所述待验证解密数据包括第一声纹特征参数在设备声纹模型库中所处分组的分组标识、所述电子设备的设备标识和所述第一声纹特征参数对应的第一哈希值,
所述第二声纹特征获取器430包括:
第二声纹特征查找单元,用于根据所述设备标识,从所述服务器声纹模型库中查找与所述分组标识对应的第二声纹特征参数;
所述鉴权结果获取器440包括:
第二哈希值计算单元,用于计算得到所述第二声纹特征参数对应的第二哈希值;
比较结果获取单元,用于将所述第二哈希值与所述第一哈希值进行比较,得到比较结果;
鉴权结果确定单元,用于根据所述比较结果,确定所述鉴权结果。
可选地,所述鉴权结果确定单元包括:
鉴权成功结果获取子单元,用于在所述比较结果为所述第二哈希值与所述第一哈希值相同的结果时,得到鉴权成功的结果;
鉴权失败结果获取子单元,用于在所述比较结果为所述第二哈希值与所述第一哈希值不相同的结果时,得到鉴权失败的结果。
本发明实施例提供的鉴权装置,通过接收由电子设备发送的经私钥加密的待验证数据,采用与私钥对应的公钥,对待验证数据进行解密,得到待验证解密数据,从服务器声纹模型库中,获取与待验证解密数据对应的第二声纹特征参数,根据第二声纹特征参数对待验证解密数据进行鉴权处理,得到鉴权结果,采用公钥对所述鉴权结果进行加密,得到加密鉴权结果,将加密鉴权结果发送至电子设备。本发明实施例采用声纹特征参数与公私钥相结合的鉴权方式,能够避免用户隐私泄露的风险。
在本发明的另一实施例中,还提供了一种电子设备,包括:处理器、存储器以及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述程序时实现上述实施例中任一项的鉴权方法。
在本发明的另一实施例中,还提供了一种计算机可读存储介质,存储有计算机指令,当所述计算机指令由电子设备的处理器执行时,使得电子设备能够执行上述任一项所述的鉴权方法。
本说明书中的各个实施例均采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似的部分互相参见即可。
最后,还需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、商品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、商品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的过程、方法、商品或者设备中还存在另外的相同要素。
以上对本发明所提供的一种鉴权方法、一种鉴权装置、一种电子设备和一种计算机可读存储介质,进行了详细介绍,本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处,综上所述,本说明书内容不应理解为对本发明的限制。
- 还没有人留言评论。精彩留言会获得点赞!