用于图像处理的设备及方法与流程
1.本发明涉及基于图像数据的深度估算。
背景技术:
2.对于各种计算机视觉和机器人技术应用,必须了解周围的几何特性。为了捕获这种几何特性,通常执行深度估算以产生深度图(depth map)。深度图是指将摄像机到场景中各对象的距离进行编码的图像。虽然存在不同的深度估算方法,但立体视觉是一种常见方法。立体视觉使用不同机位的两个以上摄像机来拍摄场景。通过匹配各图像之间的像素并了解这些摄像机的相对位置和方向,可以测量像素从一个图像运动到另一个图像产生的相对位移或视差。然后,视差可以被转换为深度,以产生深度图像。因此,为了通过立体视觉来估算深度,必须首先估算视差。
3.标准视差估算方法依赖于两个摄像机(或两个不同位置上的同一摄像机)拍摄到的rgb图像,如图1所示。
4.图1示出了一种立体视觉系统结构,用于根据两个图像计算视差,最终计算深度。该结构包括两个摄像机102、104,用于在不同机位拍摄由球体、圆锥体和立方体组成的场景106。左侧摄像机102和右侧摄像机104分别产生左侧图像108和右侧图像110。在图1中,示出了右侧图像110中的对象叠加在左侧图像108之上,而且可以观察到,对象越靠近摄像机,位移或视差越大。通过准确地计算图像之间的像素运动,可以计算得到视差图112。视差图112表示像素在两个机位之间移动的距离。视差与深度成反比,测量对象与摄像机的距离。也就是说,视差大的对象靠近摄像机。结合摄像机的额外校准数据(例如焦距和基线,基线即摄像机之间的距离),视差图可以很容易转换为深度图,也称为深度图像。
5.在标准立体视觉应用中,图像称为rgb图像,因为每个图像坐标由红色、绿色和蓝色样本或像素组成。每个rgb图像由图像信号处理(image signal processing,isp)管道产生,isp管道存在于绝大多数商用摄像机中,以将物理光读数转换为最终观察到的rgb图像。isp管道由一系列操作组成,这些操作将摄像机中的图像传感器采集到的原始数据转换为rgb图像,如图2所示。
6.图2示出了图像信号处理(image signal processing,isp)管道中的多个操作。isp管道由大量连续的模块化操作组成,这些操作将图像传感器捕获到的原始数据202转换为rgb图像204。图2所示的isp是isp管道的一个简化示例,现代isp可以包括20个以上操作模块。
7.由于原始数据与rgb图像存在若干不同之处,所以必须仔细处理原始数据。图像传感器通常使用色彩滤波阵列(colour filter array,cfa)来捕获原始数据。图3示出了位于光敏传感器网格之上的色彩滤波阵列(colour filter array,cfa)302的示例。cfa由多个滤色镜组成,这些滤色镜只允许与特定波长或颜色对应的光线通过。使用众所周知的拜耳(bayer)滤色阵列模式,cfa由2
×
2阵列模式组成,包括2个绿色滤镜、1个红色滤镜和1个蓝色滤镜。这种阵列模式平铺在图像传感器上,从而形成由对应滤色镜组成的镶嵌图案。拜耳
阵列模式可以选择包括更多的绿色样本,因为在许多自然图像中,绿色通道捕获的光线比蓝色通道或红色通道多。但是,存在其它镶嵌颜色阵列模式可以用于将滤镜设置在色彩滤波阵列中,例如ryyb。
8.图3示出了具有色彩滤波阵列302的图像传感器304正在捕获的原始数据。在图3的右侧,示出了不同波长的光线穿过不同滤色镜的3个示例。红色、蓝色和绿色光线照射红色滤镜306,但只有箭头307表示的红色光线能够穿过滤镜306。因此,只有一个或多个被红色滤镜覆盖的光敏传感器检测到入射光。接收到的红色光线在图像传感器上产生的阵列模式显示在图像传感器网格308上。红色、蓝色和绿色光线照射绿色滤镜310,但只有箭头311表示的绿色光线能够穿过滤镜310。因此,只有一个或多个被绿色滤镜覆盖的光敏传感器能够检测到入射光。接收到的绿色光线在图像传感器上产生的阵列模式显示在图像传感器网格312上。红色、蓝色和绿色光线照射蓝色滤镜314,但只有箭头315表示的蓝色光线能够穿过滤镜314。因此,只有一个或多个被蓝色滤镜覆盖的光敏传感器检测到入射光。接收到的红色光线在图像传感器上产生的阵列模式显示在图像传感器网格316上。通过组合在各个传感器网格308、312和316上显示的所有单独的色彩阵列,产生一个具有与网格302中一样的拜耳阵列模式的完整色彩滤波阵列。
9.需要说明的是,由于存在cfa,在每个像素处,下方的光敏电传感器只接收红色、绿色或蓝色光线中的一种光线。因此,为了产生完整的rgb图像,必须内插缺失的颜色,以便每个像素具有红色、绿色和蓝色。通常,图2的isp中的去马赛克步骤206执行上述内插操作。然而,由于捕获到的原始数据中缺少三分之二的全部颜色数据,所以去马赛克成为一个难题。这个问题也认为是一个不适定的问题,因为在执行去马赛克时没有唯一的解决方法。对多个原始图像中的任何一个图像去马赛克可能会产生相同的镶嵌原始图像。也就是说,这个问题变成一个多对一问题-解决类型的问题。这个问题可以描述为非线性的,因为并不只有一个线性操作可以将初始数据转换为结果数据,并可以简单地逆变换为初始数据。典型的去马赛克方法结合了其它先验知识,以产生一个可能的技术方案,从而解决这个问题。
10.如上所述,标准立体视觉管道依赖于rgb图像来计算视差和深度。这是计算机视觉领域的一个经典问题,以前在学术文献中涉及过。从根本上说,立体视觉问题试图为一个图像中的每个点寻找在另一个图像中的匹配点或对应关系。实际上,由于多种原因,很难找到对应关系。例如,由于遮挡或不遮挡,左侧和右侧图像之间的对应关系可能不存在。当试图在图像之间进行匹配的一个或多个像素通过从不同摄像机的不同角度观看场景时隐藏的特征生成时,会发生这种情况。例如,图1场景中的立方体112在前面的右下方隐藏在左侧摄像机102捕获到的图像108中的球体114的后面。换句话说,一个点可以在一个图像中可见,但在另一个图像中不可见。因此,寻找该点的匹配点是不可能的。
11.再如,由于外观差异,匹配点同样不可能找到。例如,图像由于照明变化、镜面反射等原因存在差异。可能很难确定一个图像的视场角中存在相对另一个图像的对应点。也就是说,匹配点会根据光线从场景中的一个对象反射出的方式而改变其颜色或亮度,反射方式取决于观看该对象的角度。
12.对于一个图像中的单个点,在另一个图像中寻找对应的匹配点可能是模糊的。例如,另一个图像中存在许多可能的匹配点。同质区域尤其如此,因为同质区域缺少纹理来识别该区域内的匹配像素。几何约束通常概括为“核面几何(epipolar geometry)”。如果摄像
机之间的相对旋转和平移是已知的,则几何约束可以将(例如第一图像中的一部分与第二图像中的一部分之间的)对应关系的搜索空间从整个第二图像(二维)减小到一条称为核线的直线或曲线(一维)。然而,模糊性仍然会存在。
13.难以确定深度的另一个原因是存在透明对象。透明表面会对准确匹配带来困难,因为在像素处观察到的颜色可能来自多个三维表面。
14.因此,立体视觉仍然是一个未解决的问题,也是热门的研究领域。khamis等人于2018年在期刊eccv上发表的“stereonet:实时边缘感知深度预测的引导分层细化(stereonet:guided hierarchical refinement for real-time edge-aware depth prediction)”中论述了一种可能的方法,也称为stereonet。stereonet使用端到端深度架构进行实时立体匹配。该方法依赖于孪生神经网络(siamese network),即,使用一个共享编码器获取两个输入,以从左侧和右侧图像提取特征。初步的视差估算以非常低分辨率的匹配代价体积来计算,然后,通过使用紧凑的像素级细化网络的学习上采样函数,模型分层地重新引入高频细节。tonioni等人于2019年在期刊cvpr上发表的“实时自适应深度立体(real-time self-adaptive deep stereo)”论证了一种类似方法,这篇文章自适应地将立体视差估算调整到给定的立体视频序列。然而,上述两种方法都受到使用rgb图像作为输入时需要isp带来的限制。
15.在原始半全局匹配之后,如hirschmuller等人于2007年在ieee模式分析与机器智能期刊30(2)上发表的“基于半全局匹配和互信息的立体处理(stereo processing by semiglobal matching and mutual information)”所述,liu等人于2018在期刊国际光电技术与应用研讨会上发表的“基于改进型sgbm用于原始图像数据的新立体匹配方法(a new stereo matching method for raw image data based on improved sgbm)”中进行了进一步研究工作,这篇文章处理isp管道中间阶段的图像。在这种方法中,视差估算是在isp管道中的白平衡、颜色校正、对比度和锐度操作之前进行的。然而,如果已经执行了黑电平调整、缺陷像素校正、去马赛克等操作,则这种方法依赖于典型的视差估算方法。
16.以下研究中论述了视差估算方法的其它示例。von zitzewitz等人提交的申请号为us20120127275a1的“用于从使用立体摄像机系统记录的至少两个输入图像中确定深度信息的图像处理方法(image processing method for determining depth information from at least two input images recorded with the aid of a stereo camera system)”通过转换到签名图像、应用匹配代价以及执行统计排序,从立体图像估算视差和深度。等人提交的申请号为kr20180096980a的“使用立体摄像机进行距离估算的方法和装置(method and apparatus for distance estimation using stereo camera)”使用局部和全局图像信息来执行立体匹配。但是,这种方法中的输入图像已经去马赛克。ciurea等人提交的申请号为us8780113b1的“使用来自多个光谱波道的图像数据执行深度估算的系统和方法”描述了在不同光谱频带上对多视图立体图像执行深度估算,其中,每个像素都是独立的摄像机。但是,这种方法只适用于光场,不适用于网格传感器针孔摄像机。
17.希望开发一种视差和深度估算方法,以最大限度地减少因isp操作而带来的处理,但不会降低得到的深度图的质量。
技术实现要素:
18.根据一方面,提供了一种用于对第一和第二图像执行深度估算的设备。所述第一和第二图像是用具有色彩滤波阵列的一个或多个摄像机捕获到的,每个图像包括多个颜色通道,每个颜色通道对应于色彩滤波阵列的相应颜色通道,所述设备用于通过从所述第一和第二图像的颜色通道估算视差,执行深度估算。
19.所述设备可以用于:识别所述第一和第二图像的重叠部分并根据所述识别执行深度估算。这样,所述第一和第二图像可以提供一个常见对象的透视图或立体视图。
20.所述第一和第二图像可以是从空间偏移位置捕获到的,例如,是由位于通用平台上的两台间隔开的摄像机捕获到的,或者是由从一个位置移动到另一个位置的一台摄像机捕获到的。这样可以有助于捕获提供有用深度信息的图像。
21.所述多个颜色通道可以包括对应于不同颜色的至少两个颜色通道。这样,每个图像可以为彩色图像。所述多个颜色通道可以是在穿过滤色镜之后由光敏传感器捕获到的颜色通道。
22.所述多个颜色通道可以包括对应于相同颜色的至少两个颜色通道。所述颜色可以是绿色或黄色。当图像传感器根据拜耳阵列模式设置时,上述颜色通道可以自然地出现。
23.所述设备可以用于通过从每个图像的所述两个颜色通道估算视差,执行深度估算。这样可以提供一种有效的深度估算方法。
24.所述设备可以用于在没有对所述多个颜色通道执行非线性操作的情况下,从所述多个颜色通道估算视差。所述设备可以包括一种图像信号处理器,所述设备可以用于在没有通过所述图像信号处理器处理所述多个颜色通道的情况下,从所述多个颜色通道估算视差。所述设备可以用于在没有将所述多个颜色通道转换到rgb颜色空间的情况下,从所述多个颜色通道估算视差。例如,当所述被处理的多个颜色通道是由图像传感器捕获到的颜色通道时,这些特征可以实现更好的深度估算。
25.所述多个摄像机可以为间隔开的摄像机,包括在所述设备中并用于捕获有重叠视角场的图像。这样可以自然地捕获重叠图像。
26.所述设备可以用于通过以下步骤执行深度估算:对于所述第一和第二图像的每个颜色通道,估算这些颜色通道之间的差异的匹配代价体积;对于所述第一和第二图像的每个颜色通道,根据所述匹配代价体积估算视差。这样可以提供一种高效处理机制。
27.所述设备可以用于通过以下步骤执行深度估算:估算所述第一和第二图像的所有颜色通道之间的差异的公共匹配代价体积;根据所述公共匹配代价体积估算视差。这样可以提供一种高效处理机制。
28.所述设备可以用于通过空间变化的加权函数,对所述或每个估算出的视差进行加权。所述权重可以用于帮助深度估算。
29.所述空间变化的加权机制可以用于使用与一个通道相关的多个权重,其中,所述多个权重是通过机器学习算法根据另一个通道中的视差学习到的。这样可以通过使用多个颜色通道之间的信息,实现更好的深度估算。
30.所述设备可以用于通过经过训练的机器学习算法,执行深度估算。这样可以高效地实现上述处理。
31.根据第二方面,提供了一种训练机器学习算法以对第一和第二图像执行深度估算
的方法。所述第一和第二图像是用具有色彩滤波阵列的一个或多个摄像机捕获到的,所述方法包括:配置所述算法的第一实例,以接收多个颜色通道并通过从所述第一和第二图像的颜色通道估算视差,执行深度估算,其中,每个颜色通道对应于所述色彩滤波阵列的相应颜色通道;将所述算法的所述第一实例的输出与预期输出进行比较;根据所述比较的结果,形成所述算法的第二实例。
32.所述算法是一种端到端可训练算法。这样可以有助于高效训练所述算法。
33.所述方法可以包括:接收彩色图像训练数据;根据所述训练数据,通过程序控制计算机估算所述多个颜色通道;将所述估算出的多个颜色通道作为输入提供给所述算法的所述第一实例。这样可以从前一处理图像(例如,rgb格式的图像)估算颜色通道数据。
34.所述算法的所述第一实例用于通过以下步骤执行深度估算:对于所述第一和第二图像的每个颜色通道,估算这些颜色通道之间的差异的匹配代价体积;对于所述第一和第二图像的每个颜色通道,根据所述匹配代价体积估算视差。这样可以提供一种高效处理机制。
35.所述方法设备的所述第一实例可以用于通过以下步骤执行深度估算:估算所述第一和第二图像的所有颜色通道之间的差异的公共匹配代价体积;根据所述公共匹配代价体积估算视差。这样可以提供一种高效处理机制。
附图说明
36.下面结合附图通过示例的方式对本发明进行描述。在附图中:
37.图1示出了一种典型的立体视觉结构,用于根据两个图像计算视差和深度;
38.图2示出了典型的图像信号处理(image signal processing,isp)管道中的多个操作;
39.图3示出了具有色彩滤波阵列的图像传感器正在捕获原始数据;
40.图4示出了以原始立体图像作为输入进行深度估算的深度学习管道;
41.图5a示出了一个提出的架构选项,产生在分离原始数据之后获得的单独匹配代价体积;
42.图5b示出了一个提出的架构选项,产生融合匹配代价体积估算;
43.图6示出了分离模块的一种可能架构设计;
44.图7示出了编码器模块的一种可能架构设计;
45.图8示出了匹配代价体积生成器模块的一种可能架构设计;
46.图9示出了解码器/引导上采样器模块的一种可能架构设计;
47.图10示出了深度细化模块的一种可能架构设计;
48.图11示出了图5a所示的后期融合的一种可能架构设计;
49.图12示出了创建数据集以训练机器学习算法直接从原始数据产生视差图和深度图的流程;
50.图13示出了所提出方法与典型方法相比的一些定性结果,两种方法都使用了stereoraw数据集;
51.图14示出了一种用于对由摄像机中的图像传感器拍摄到的原始图像实现深度处理的设备的示例。
具体实施方式
52.当前提出的方法使用原始图像数据而不是rgb图像执行视差估算,或相应地执行深度估算(当摄像机标定和基线已知时)。这种方法具有以下几个优点。isp中的操作是复杂、非线性的操作,通过裁剪和动态范围压缩可能会导致信息丢失。通常情况下,原始图像包括更多的可能值,例如,每种颜色有10到16位,但是,rgb图像通常会经过动态范围压缩,每种颜色降低到8位。另外,如上所述,isp中的去马赛克步骤和其它模块可能会导致错误和内插伪影。在isp中,上游模块中的任何错误都会向下游传播到最终产生的rgb图像中。因此,简化isp管道还可以将这些错误减到最少。直接对原始图像执行立体估算可以避免由于isp而可能产生的复杂情况。也就是说,从物理上获取的数据开始解决了去马赛克过程中图像内插带来的质量下降问题。另外,当图像形成的目的是为了估算深度时,由于可以完全跳过isp,因此有可能节省大量计算。相反,视差估算可以立即直接从原始数据计算得到。因此,提出直接从在不同机位捕获到的两个以上原始图像来估算深度。也就是说,创建深度图的数据是图像传感器通过色彩滤波阵列检测到的原始数据,而且不执行isp中的操作链。
53.具体地,提出了一种用于深度估算的深度学习管道,其输入为来自图4所示的两个不同摄像机的原始立体图像。所提出的视差和深度估算方法包括端到端可训练的人工神经网络,该神经网络用于直接确定立体图像匹配任务的代价并且用于估算解码深度的视差图。本文所指的匹配代价体积(cost volume)是记录深度的概率方式。由于这种提出的方法中的处理是直接对色彩滤波阵列(colour filter array,cfa)数据(即原始数据)执行的,因此不需要图像信号处理器(image signal processor,isp)。图4示出了提出的stereoraw方法400,其中,将两个尚未经过isp处理的原始图像402和404作为输入,使这两个图像通过专门为原始数据设计的神经网络架构406,从而产生视差图408。
54.所提出的方法可以实现为一种设备的一部分,所述设备用于对使用一个或多个摄像机捕获到的第一和第二图像执行深度估算。所述一个或多个摄像机具有色彩滤波阵列,每个捕获到的图像包括多个颜色通道,每个颜色通道对应于所述色彩滤波阵列的相应颜色通道。因此,所述设备可以用于通过从所述第一和第二图像的颜色通道估算视差,执行深度估算。也就是说,不需要前面的isp处理步骤。因此,即使每个像素位置由于滤波阵列模式的原因只具有色彩滤波阵列的其中一个颜色通道的信息(即,每个不同的颜色通道覆盖不同的传感器坐标且没有一个坐标被多个颜色通道覆盖),视差估算也可以直接根据在每个像素位置上进行采样的数据进行。也就是说,每个颜色通道中的坐标(x,y)表示不同的图像坐标,而且颜色通道之间没有重叠,例如,图像坐标(0,0)可以与绿色坐标(0,0)或蓝色坐标(0,0)不同,但可以与红色坐标(0,0)相同。所使用的颜色通道之间存在像素位移。
55.为所提出的stereoraw管道而设计的网络架构如下所述。图5a和图5b示出了所提出的两种不同网络架构,其中一种网络架构产生在分离原始数据之后获得的单独匹配代价体积,另一种网络架构产生在分离原始数据并且后续对单独通道进行特征融合之后获得的单个融合匹配代价体积。深度估算可以通过以下步骤执行:对于图像的每个颜色通道,估算这些颜色通道之间的差异的匹配代价体积;根据所述匹配代价体积估算视差。可选地,深度估算可以通过以下步骤执行:估算图像的所有颜色通道之间的差异的公共匹配代价体积;根据所述公共匹配代价体积估算视差。
56.为执行深度估算的stereoraw方法所提出的两种神经网络都能够删除典型的图像
信号处理(image signal processing,isp)管道。所提出方法中的深度估算不需要isp管道,而且删除isp管道还避免引入复杂的噪声模式。
57.图5a示出了第一个提出的架构选项,产生在分离原始数据之后获得的单独匹配代价体积。这一架构包括对分离的颜色通道504a、504b、504c和504d计算单独匹配代价体积502。每个通道分支504独立工作,这些通道只在末尾506融合在一起,以提供组合的视差估算508,这种视差估算考虑为所有通道504a至504d估算的视差。
58.具体地,第一种提出的方法首先提供使用具有拜耳阵列模式的cfa获得的原始图像数据。然后,通过分离模块510将原始数据提取到不同的颜色通道(例如r、g、g和b)中。这些颜色通道包括对应于不同颜色的至少两个颜色通道。在一些情况下,这些颜色通道可以包括对应于相同颜色(例如绿色或黄色)的至少两个颜色通道。具体的颜色通道取决于所使用的cfa,例如可以是红色、黄色、黄色、蓝色(ryyb)或红色、绿色、绿色、蓝色(rggb)。
59.反卷积层用于恢复输入图像的全分辨率,而像素偏移则通过确保在上采样前后对齐对应顶点来解决。其次,残差块用于细化恢复后的全分辨率输入。再次,不同的颜色通道504a至504d由相应的编码器512分别处理,并与特征图的另一个视图匹配,以通过匹配代价体积生成器过程514构建匹配代价体积502。接着,根据匹配代价体积生成粗视差图,指导下的上采样模块516逐步细化粗视差图,以产生细化后的视差图518。最后,融合模块506用于与另一个残差模块一起处理来自不同颜色通道的不同视差,以进一步细化完整视差并产生最终的视差图508。
60.一种实现所提出方法的设备可以用于通过从图像的两个颜色通道估算视差,执行深度估算。从颜色通道估算视差可以在没有对颜色通道执行非线性操作的情况下确定。一种实现所提出方法的设备可以包括图像信号处理器。在这种情况下,所述设备可以用于在没有通过所述图像信号处理器处理所述颜色通道的情况下,从所述颜色通道估算视差。视差可以在没有将颜色通道转换到rgb颜色空间的情况下,从所述颜色通道估算。
61.使用图5b所示架构的所提出的可选方法包括上述和图5a所示的架构中的许多相同组件和过程。然而,可选方法包括融合匹配代价体积估算520,可以避免在上述所提出的单独stereoraw方法开始时进行不必要的内插。也就是说,图5b的架构在所提出的一般方法的前期阶段融合单独颜色通道。这种融合匹配代价体积架构的优点在于,可以避免可能带来不正确信息的初始内插步骤。图5b所示的包括融合匹配代价体积估算520的第二架构通过将cfa输入图像分成或分解为每个立体图像对的4个通道来实现这一点。其次,通过将像素位置映射到特征图522中,形成每个视图522a和522b的一个全分辨率特征图。接着,来自左侧和右侧视图的融合特征522可以用于产生一个匹配代价体积520。与单独的匹配代价体积方法类似,粗视差根据匹配代价体积获得,并借助于原始图像或原始图像经过处理的某一版本进一步细化。
62.所提出的一般方法使用立体原始图像,而不是isp管道中通常使用的立体rgb图像。所提出的方法中的神经网络直接编码原始信息,并在左侧和右侧视图之间进行比较,从而考虑cfa拜耳阵列模式。原始输入图像是从两个连接的左侧和右侧摄像机获取的。因此,图像是从空间偏移位置上捕获到的。所述实现所提出方法的设备用于识别图像的重叠部分并根据上述识别执行深度估算。所提出的深度网络能够使用cfa拜耳阵列模式编码原始图像,并利用极面几何来学习最终的视差。因此,模态是形成输入的stereoraw图像和形成输
出的视差图。
63.下面详细描述了用于所提出方法的架构。为简单起见,只针对一个机位(即左侧摄像机的机位)给出网络的详细信息。在另一个机位(例如右侧摄像机的机位)上拍摄到的图像进行相同的操作。每条处理路线,例如,图5a的左侧和右侧摄像机处理分支,可以使用相同权重。一个或每个估算出的视差可以通过空间变化的加权函数进行加权。空间变化的加权函数或机制用于使用与一个通道相关的多个权重,其中,所述多个权重是通过机器学习算法根据另一个通道中的视差而学习到的。因此,深度估算可以通过训练过的机器学习算法来执行,所以,这些权重是神经网络的参数,这些参数在训练过程中学习到,可以相互依赖,也可以不相互依赖。
64.在所提出方法的一种示例性实现方式中,左侧和右侧摄像机可以是间隔开的摄像机,包括在相同设备中并用于捕获有重叠视场角的图像。
65.下面结合上述所提出方法的总体架构来描述不同模块的详细架构。具体地,所提出方法中的单独匹配代价体积估算架构的详细架构如图5a所示。应当理解,图5a和图5b所示的两种不同架构中存在的模块可以按照如下所述的相同详细架构进行设置。
66.图6示出了图5a和图5b的左侧和右侧机位分支中存在的分离模块510的一种可能架构设计。首先,将原始输入图像602分成不同的颜色通道数据604,同时保持单色通道原始数据的空间分布。其次,对数据进行内插,以将缺失的对应颜色通道数据提供给图像中cfa不包括对应滤镜颜色的区域。也就是说,颜色通道数据中的不同颜色的滤镜遮挡该颜色的入射光的空隙通过双线性内插过程606填充。接着,分别获取每个颜色通道的全分辨率图像,并在其各自的颜色通道分支中进行操作。这些操作模块608可以包括一个或多个卷积模块,在初始全分辨率单色通道数据提供的指导下。最后,输入原始图像数据的每个颜色通道可以按与原始原始输入相同的分辨率进行操作。
67.图7示出了编码器模块512的一种可能架构设计。对于每个单颜色通道输入,编码器模块512分别在左侧和右侧分支上操作。也就是说,左侧530原始图像和右侧540原始图像分别可以由不同的编码器来操作,也可以由相同的编码器来操作,但是分别针对每个机位和每个颜色通道的图像来操作。图7的示例性编码器设置有输入图像702,输入图像702包括单色通道和单个机位的原始数据。然后,这些图像702经过卷积层704、三个残差块706和另一个卷积层708进行操作。在经过另外两个卷积层710和712之后,提供一系列输出图像或特征图714。
68.图8示出了匹配代价体积生成器模块514的一种可能架构设计。匹配代价体积生成器对左侧和右侧机位数据进行操作,以确定粗匹配代价体积802,并且将这种匹配代价体积细化为更细化的匹配代价体积。匹配代价体积生成器可以如图5a所示在某个时间对单、色通道的左侧和右侧机位数据进行操作,或者如图5b所示对已经融合的包括特定机位的所有不同颜色通道的左侧和右侧机位数据进行操作。在生成粗匹配代价体积802之后,经过5个卷积层804,然后输出细化后的匹配代价体积806。
69.图9示出了解码器/引导下的上采样器模块的一种可能架构设计。在这个特定的示例中,在输入图像902提供的引导下对匹配代价体积进行上采样。匹配代价体积是通过soft argmin计算904逐步进行上采样的,soft argmin计算904提供具有1/8比例视差906的图像。其次,在输入图像902的引导下,通过深度细化模块908对图像进行分层放大,以提供具有1/
4比例视差910的第一图像。在输入图像902的引导下,又一深度细化过程912进行另一轮放大,以提供具有1/2比例视差914的图像。最终的深度细化过程916进行最后一轮放大,以提供具有全比例视差918的图像。
70.图10示出了深度细化模块的一种可能架构设计。深度细化模块通过将上采样的全比例视差图像1002与处理图像1004级联,细化上采样后的全比例视差图像1002的视差。两个输入在级联1010之前经过相应的卷积层1006和两个残差块1008。之后,经过另外4个残差块1012和最终的卷积层1014,产生细化后的视差输出1016。
71.图11示出了图5a中的后期融合的一种可能架构设计。后期融合506包括融合1104每个颜色通道1102a至1102d的细化后视差以及处理1106,以产生最终视差1108。
72.为了以监督学习的方式训练所提出方法中的神经网络,在不同比例和不同通道上,使预测视差和地面真值视差之间的像素级差异最小化。例如,以下能量项方程(1)说明了如何组合每个部分的单独像素级损失。
73.l
total
=l
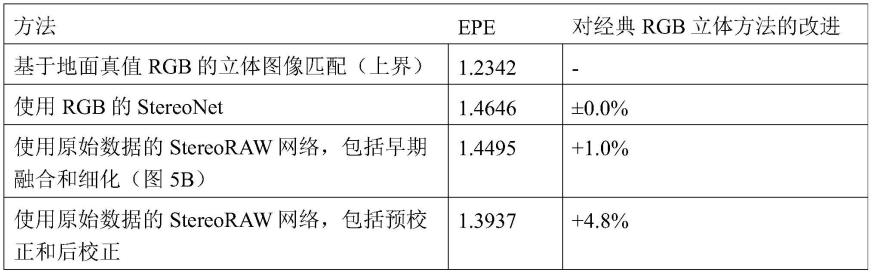
raw
+l
red
+l
green1
+l
green2
+l
blue
ꢀꢀꢀꢀ
(1)
74.对于每个颜色通道,采用了像素级重建损失函数。更具体地,根据以下方程(2)执行原始图像的预测视差和地面真值视差的l1损失函数。
[0075][0076]
类似地,方程(2)还提供了不同颜色通道和不同尺度的重建损失函数:l
red
、l
green1
、l
green2
和l
blue
。
[0077]
为了训练用于原始数据方法的神经网络,并使用完美像素地面真值量化管道的性能,还需要专门为任务创建一个新的模拟数据集。
[0078]
由于视觉社区中没有满足必要需求的原始立体数据集,因此可以基于弗莱堡大学提供的sceneflow数据集(通过lmb.informatik.uni-freiburg.de/resources/datasets/sceneflowdatasets.en.html获取)等创建新的数据集。
[0079]
图12示出了创建数据集以训练网络直接从原始数据产生视差图和深度图的流程。该过程开始于一组立体图像对或彩色图像训练数据及其地面真值视差。其次,所有图像都进行中心裁剪,得到固定大小为640
×
480像素的图像。接着,采用逆isp管道,从干净的rgb数据中生成原始图像。由于现有技术中的方法在isp过程后对rgb图像操作,所以将isp管道应用于原始图像,以获得用于比较的rgb图像。也就是说,现有数据集包括数据rbg(1)图像及其视差,但所需的数据是原始图像及其视差。因此,可以通过执行逆isp过程获取rgb(1)图像并从中计算原始数据集。为了公平地比较本文中提出的原始数据方法与“现有技术”中的rgb方法,将原始数据通过isp以获得第二组rgb(2)图像。因此,地面真值视差仍然保持不变,但随后可以训练神经网络以从原始数据产生估算的视差,并将其与从rgb(2)图像数据中产生估算的视差进行比较。这样做是有必要的,因为当应用逆isp管道来创建原始数据时会导致质量下降,如果简单地将rgb(1)图像数据作为比较输入,则不会出现质量下降。也就是说,rgb(1)会提供在进行比较中使用的不公平输入,以反映首先采集原始数据的真实情况。图12中的地面真值视差示为通过光线跟踪来创建。然而,也可以使用从rgb图像数据产生地面真值视差的其它方法。
[0080]
所提出的训练机器学习算法以对使用具有色彩滤波阵列的一个或多个摄像机捕获到的第一和第二图像执行深度估算的方法包括以下步骤。配置所述算法的第一实例,以接收多个颜色通道并通过从所述第一和第二图像的颜色通道估算视差,执行深度估算,其中,每个颜色通道对应于所述色彩滤波阵列的相应颜色通道。其次,将所述算法的所述第一个实例的输出与来自上述创建的数据集等的预期输出进行比较。接着,根据所述比较的结果,形成所述算法的第二实例。
[0081]
在一种示例性实现方式中,所述算法可以是一种端到端可训练算法。训练所述算法可以包括:接收彩色图像训练数据;根据所述训练数据,通过程序控制计算机估算多个颜色通道。再次,可以将所述估算出的多个颜色通道作为输入提供给所述算法的所述第一实例。然后,训练可以包括迭代深度估算任务,因为可以根据推理执行,以迭代地改进和训练所述算法。这个阶段可以涉及训练所述算法以在两个可选匹配代价体积过程中的任何一个中进行操作。也就是说,所述算法的所述第一实例可以用于通过以下步骤执行深度估算:对于所述第一和第二图像的每个颜色通道,估算这两个图像的颜色通道之间的差异的匹配代价体积,然后,根据所述匹配代价体积估算视差。可选地,所述算法的第一实例可以用于通过以下步骤执行深度估算:估算所述第一和第二图像的所有颜色通道之间的差异的公共匹配代价体积,然后,根据所述公共匹配代价体积估算视差。
[0082]
上述方法相比于在rbg域中操作的现有方法,深度精度更高。这是因为噪声在原始域(即在isp管道中进行复杂的非线性操作(例如去马赛克)之前)中表现得更加可预测。所提出的深度估算方法还使深度信息可用于其它任务,例如在获取传感器读数之后的图像对位。
[0083]
上述方法的一些潜在优点包括:
[0084]
通过使用两个以上摄像机及其本机色彩滤波阵列(colour filter array,cfa)数据执行立体深度估算,可以在传感器网格的几何正确位置上利用光子测量。
[0085]
通过使用原始数据处理执行视差估算,并且不实施典型的图像信号处理器(image signal processor,isp),可以使用更准确的测量,而不会由于典型的isp预处理步骤而产生任何错误。由于操作较少,没有isp的操作提供了更高效的数据使用,因此可能会更好地去除噪声。能够跳过isp中的非线性运算符。
[0086]
通过实现具有原始输入和视差和/或深度输出的端到端可训练神经网络,可以提供学习的公共潜在空间,其允许在单个匹配代价体积中进行数据聚合。还可能存在一种可选实现方式,其在单独视差估算之后融合波长相关信息。
[0087]
由于使用与方法论无关的训练阶段,可以使用包括完全监督训练和自监督损失的训练方法。还可以利用反向isp以在没有原始数据的地面真值注释的情况下提供训练。
[0088]
表1示出了所提出方法的一些测试结果。所提出的方法优于使用rgb图像的传统方法,表明从原始图像开始会有利于深度估算。
[0089]
表1:基于创建的stereoraw数据集的各种方法的深度估算性能(其中,epe代表“终点误差”,表示平均绝对误差。)
[0090][0091]
图13示出了所提出方法与典型方法相比的一些定性结果,两种方法都使用了stereoraw数据集。顶行1302图像示出了获取深度图的典型rgb isp方法的输入和输出。底行1304图像示出了所提出的从原始数据获取深度图的stereoraw方法(包括神经网络或机器学习算法)的输入和输出。顶行1302显示了左侧摄像机的输入rgb图像1306和右侧摄像机的rgb图像1308,都是从创建的stereoraw数据集中获取。通过典型的基于rgb isp的视差和深度估算产生的深度图1310显示在右侧,针对不同的视差进行灰度编码。底行1304显示了左侧摄像机的输入原始图像1312和右侧摄像机的原始图像1314,都是从创建的stereoraw数据集中获取。通过本文中提出的根据直接用于生成视差和深度估算的原始数据的方法产生的深度图1316显示在底行的右侧,进行相同的灰度图像编码。可以看出,根据rgb生成的深度图1310中的一些细节不存在于根据原始数据生成的深度图1316中,反之亦然。然而,在rgb深度图1310中存在其它细节的情况下,可以从rgb图像中看到,这些细节可能源自基于颜色变化的细节,而颜色变化被错误地归因于深度变化。
[0092]
图14示出了一种用于对由摄像机1401中的图像传感器1402拍摄到的图像实现深度处理的设备的示例。摄像机1401通常包括一定机载处理能力。这种能力可以由处理器1404提供。处理器1404还可以用于执行摄像机的基本操作功能。摄像机通常还包括存储器1403。
[0093]
收发器1405能够连接到网络并通过该网络与其它实体1410、1411通信。如上所述,这些实体可以物理上远离摄像机1401。该网络可以是公共可访问网络,如互联网。实体1410、1411可以位于云网络1406中。在一个示例中,实体1410是计算实体,实体1411是命令和控制实体。在这个示例中,这些实体是逻辑实体,并且可以能够执行本文中提出的全部或部分深度处理。在实践中,这些实体可以分别由一个或多个物理设备(例如服务器和数据存储器)提供,并且两个以上实体的功能可以由单个物理设备提供。实现一个实体的每个物理设备可以包括处理器和存储器。这些设备还可以包括收发器,用于在摄像机1401的收发器1405之间发送和接收数据。存储器以非瞬时方式存储代码,所述代码可由处理器执行,以使用本文中描述的方式实现相应实体。
[0094]
命令和控制实体1411可以训练系统的每个模块中使用的人工智能模型。这种训练通常是一项计算密集型任务,即使所得到的模型可以被高效描述,因此开发在云中待执行的算法可能是高效的,在云端可以预期有大量的能量和计算资源可用。可以预期的是,这比在典型的摄像机中形成这种模型更高效。
[0095]
在一种实现方式中,一旦在云中开发了深度学习算法,命令和控制实体就可以自动形成对应的模型,并使该模型传输到相关的摄像机设备。在这个示例中,该系统由处理器
1404在摄像机1401处实现。
[0096]
在另一种可能的实现方式中,图像可以由摄像机传感器1402捕获到,图像数据可以由收发器1405发送到云端以在系统进行处理。然后,可以将所得到的深度图或深度图像发送回摄像机1401,如图14中的1412所示。可选地,可以将所得到的深度图或深度图像发送到系统的另一个设备,用于显示或用于另一个过程中。
[0097]
因此,上述方法可以通过多种方式部署,例如在云端、在摄像机设备上,或者在专用硬件中部署。如上所述,云设施可以执行训练,以开发新的算法或细化现有算法。根据接近于数据语料库的计算能力,训练可以使用推理引擎等在源数据附近进行或在云端进行。该系统也可以在摄像机处、一个专用硬件中或在云端实现。
[0098]
申请人在此单独公开本文所述的每个单独的特征以及两个以上此类特征的任意组合。在这个意义上,鉴于本领域技术人员的常识,此类特征或组合能够根据本说明书作为整体实现,而不考虑此类特征或特征的组合是否能解决本文中公开的任何问题,且不对权利要求书的范围造成限制。申请人表明本发明的各方面可以由任何这类单独特征或特征的组合构成。鉴于上文描述,可以在本发明的范围内进行各种修改对本领域技术人员来说是显而易见的。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1