一种基于大数据的数据调用链路还原分析系统的制作方法
streaming中的数据结构dstream;spark streaming提交的job会将数据进行多维关联分析性。
15.作为可选的实施方式,分别以rds审计日志、sls审计日志、arms应用堆栈信息为分析入口,进行全链路追踪过程分析,具体包括:
16.spark streaming流式处理组件消费kafka消息队列,周期性的获取kafka中每个主题的每个partition中的最新offsets,之后根据设定的maxrateperpartition来处理每个batch;
17.spark streaming流式处理组件利用impala组件获取中间连接数据,借助spark streaming流式处理组件和imapala脚本进行关联和sql连接分析;
18.分析后的数据回存到kafka,生成两个消息主题,其中一个消息主题用于存储,另一个消息主题用于展示;
19.由spark streaming流式处理组件消费存储信息主题,对数据流转链路进行分析,将分析后的数据存到hdfs或kudu数据库;
20.由java微服务定时轮询消费展示信息主题,用于存储数据链路展示信息,通过websocket推给前端微应用实时展示。
21.作为可选的实施方式,所述分析包括以下三个场景:
22.借助应用监控获取到的堆栈sql信息分析数据调用的完整链路;
23.借助rds审计日志结合应该监控信息分析数据调用完整链路;
24.借助sls审计日志分析数据服务调用的完整链路。
25.作为可选的实施方式,所述借助应用监控获取到的堆栈sql信息分析数据调用的完整链路,具体包括:
26.以应用监控的堆栈信息获取sql信息及链路标识,然后通过解析sql分析调用数据库的表及字段信息,通过链路标书查询微服务ip及微服务唯一标识;
27.通过所述微服务唯一标识查询关联数据库ip及端口,并匹配云数据库实例信息,获取数据源所在项目空间;
28.通过对接数据集成信息、dataworks数据源信息,获取到整个访问链路的详细信息。
29.作为可选的实施方式,所述借助rds审计日志结合应该监控信息分析数据调用完整链路,具体包括:
30.通过rds审计日志分析访问数据的微服务ip、sql以及rds实例信息,通过解析sql分析调用数据库的表及字段信息,通过云数据库唯一标识获取实例ip,通过实例ip与数据源的ip比对,确定目标库及任务空间id;
31.微服务ip通过对接应用监控信息,获取到微服务名称,通过微服务ip对接云服务器实例信息,获取到微服务所属的业务系统及部门;
32.通过任务空间唯一标识以及目标库、目标表比对查询数据集成表,获取到数据中台项目空间、数据中台表,最终得到数据集成同步到云数据库并且服务通过jdbc方式直连云数据库的应用场景的全链路信息。
33.作为可选的实施方式,所述借助sls审计日志分析数据服务调用的完整链路,具体为:
34.通过sls审计日志得出访问数据服务的微服务ip、sql信息以及云数据库唯一标识,通过解析sql分析目标数据库的表及字段信息,通过云数据库唯一标识查询云数据库名称和域名,然后通过解析域名获取云数据库ip,对接外部数据源信息,获取到目标库及任务空间唯一标识;
35.通过外部数据库、外部表及任务空间唯一标识对比查询数据集成表,获取中台项目空间、中表;微服务ip通过比对应用监控信息和云服务器实例信息,获取微服务名称、微服务所在业务系统、所在业务部门信息;
36.最终分析出通过数据集成同步到云数据库并且发布成数据服务进行调用应用场景的全链路信息。
37.作为可选的实施方式,所述数据存储引擎分为贴源层、共享层和分析层三层,贴源层用于存储采集到的源数据,共享层用于定时清洗、转换贴源层的数据,将结果存储到共享层;分析层用于存储分析引擎处理后的数据。
38.作为可选的实施方式,所述定时清洗贴源层的数据具体为:
39.过滤不符合要求的数据,将过滤的结果交给业务主管部门,确认是否过滤掉还是由业务单位修正之后再进行抽取。
40.作为可选的实施方式,所述定时清洗贴源层的数据具体为:
41.将不同业务系统的相同类型的数据统一、将贴源层数据按照共享层的主题域粒度进行聚合、以及不同业务规则中不同数据指标的计算。
42.与现有技术相比,本发明的有益效果是:
43.(1)本发明能够解决当前链路追踪无法获取服务所属的应用、服务具体调用了数据库的什么数据、数据中台到数据库的数据流转链路等信息的问题。用户可以在自建的系统中通过调用本发明对外公开的接口,方便地实现数据调用过程中的全链路信息。
44.(2)本发明能够将数据在各个访问过程中的数据无缝衔接起来,形成完整的访问链路,实现真正的数据全链路追踪。定时采集引擎通过在前台页面配置执行方法、cron表达式,后台采用feign组件进行服务之间通信,可以实现多种形式的数据采集;实时采集引擎是先将数据落地成json文件,然后通过flume组件实时采集,支持海量日志采集、聚合和传输,并且支持任何流事件数据的采集;采用kafka实现数据拉取和消费,通过topic将数据进行分类,支持多个生产者和消费者,支持broker的横向拓展,解决了数据量大并且种类多且消费时间及机制不一致的问题;采用spark streaming流式处理组件进行分析,达到准实时的响应,并且容错代价低。
45.本发明的其他特征和附加方面的优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本方面的实践了解到。
附图说明
46.图1为本发明实施例中的基于大数据的数据调用链路还原分析系统结构示意图;
47.图2为本发明实施例中的借助应用监控信息追踪全链路场景过程示意图;
48.图3为本发明实施例中的借助rds审计日志追踪全链路场景过程示意图;
49.图4为本发明实施例中的借助sls审计日志追踪全链路场景过程示意图。
具体实施方式
50.应该指出,以下详细说明都是例示性的,旨在对本技术提供进一步的说明。除非另有指明,本发明使用的所有技术和科学术语具有与本技术所属技术领域的普通技术人员通常理解的相同含义。
51.需要注意的是,这里所使用的术语仅是为了描述具体实施方式,而非意图限制根据本技术的示例性实施方式。如在这里所使用的,除非上下文另外明确指出,否则单数形式也意图包括复数形式,此外,还应当理解的是,当在本说明书中使用术语“包含”和/或“包括”时,其指明存在特征、步骤、操作、器件、组件和/或它们的组合。
52.实施例一
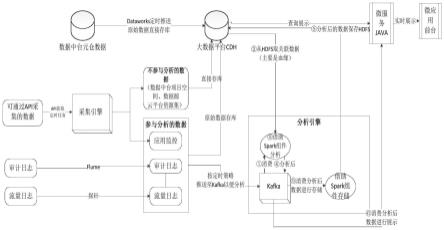
53.在一个或多个实施方式中,公开了一种基于大数据的数据调用链路还原分析系统,结合图1,具体包括:
54.(1)数据采集引擎,包括定时任务采集单元和flume实时采集单元;其中,定时任务采集单元通过java定时任务定时采集云平台资源集、数据源、应用监控等接口数据,采集到的数据直接存储到大数据平台,用于后续数据流转链路还原分析;flume实时采集单元先将rds数据库审计日志、cdh数据库审计日志、sls数据服务调用日志等日志数据落地成json文件然后通过flume组件实时采集,采集到的数据暂时存储到kafka,等待分析引擎进行消费。
55.本实施例中,数据访问过程包括终端、用户、业务系统、微服务、接口、数据库和表,要对整个访问过程进行链路分析,需要采集每个小过程的审计数据,包括流量日志、云上资源集信息、应用监控信息、数据源信息、数据库审计日志等。
56.非实时采集的数据由java实现一个定时任务,通过前台页面的配置任务名称、任务描述、调用方法、cron表达式的方式,将需要定时执行的方法、cron表达式、错误策略、任务名称传入后台,定时执行所需方法。
57.cron表达式是一个字符串,用于表达定时任务执行的频率和时间。任务执行时,本模块所在后台通过spring cloud feign声明式进行服务之间的通信,定义一个通过注解@feignclient()指定需要调用的服务的接口,启动类加上
58.@enablefeignclients开启feign功能即可,从而调用云平台数据获取模块的方法进行定时执行,实现云平台相关组件接口数据的定时采集。
59.需要实时采集的数据,先将cdh审计日志、rds数据库审计日志、sls数据服务审计日志等数据从接口获取以json文件形式暂存到服务器,然后通过大数据平台flume组件实时采集存储到数据缓冲区kafka和数据存储hdfs数据库。
60.(2)数据分析引擎,用于接收kafka中的数据,并转换为设定的数据结构,然后分别以云数据库审计日志、数据服务审计日志、应用监控堆栈信息为分析入口,进行全链路追踪过程分析;
61.本实施例中,数据分析引擎是由impala sql分析组件以及spark streaming流式处理组件两部分组成,spark streaming流式处理kafka中的数据,第一步是先把kafka数据接收过来,转换为spark streaming中的数据结构。接收数据的方式是利用接收器来接收kafka中的数据,使用kafka高阶用户api接口。对于所有的接收器,从kafka接收来的数据会存储在spark的执行器中,之后spark streaming提交的job会将数据进行多维关联分析性。任务处理过程中,结合impala sql组件进行sql分析,分别以云数据库审计日志、数据服务
审计日志、应用监控堆栈信息为分析入口,进行全链路追踪过程分析,分析后写入kafka,非实时展示的数据直接入库,实时展示的数据通过微服务微应用调用kafka接口获取数据来进行前台展示。
62.(3)数据存储引擎,用于对采集到的源数据、清洗、转换后的数据以及数据分析引擎处理后的数据进行分层存储;
63.本实施例中,数据存储引擎的作用是将采集的源数据进行大数据存储,并将存储分为贴源层、共享层、分析层三层,贴源层用于存储采集到的源数据,共享层存储清洗、转换后的数据,分析层主要存储分析引擎处理后的数据。
64.本实施例中,将采集引擎采集到的数据存储到贴源层,保留原始数据,以便于后续数据的溯源。
65.共享层的数据主要是通过在大数据平台kettle组件配置定时任务,定时清洗、转换贴源层数据,将结果存储到共享层;其中,数据清洗的任务是过滤那些不符合要求的数据,将过滤的结果交给业务主管部门,确认是否过滤掉还是由业务单位修正之后再进行抽取。不符合要求的数据主要是有不完整的数据、错误的数据和重复的数据三大类。数据转换的任务主要是进行不一致的数据转换、数据粒度的转换和商务规则的计算。不一致数据转换,将不同业务系统的相同类型的数据统一。数据粒度的转换,贴源层一般存储非常明细的数据,而共享层的数据是用来分析的,不需要非常明细的数据,将贴源层数据按照共享层的主题域粒度进行聚合。商务规则的计算,不同的部门有不同的业务规则,不同的数据指标,这些指标不是简单的加加减减就能完成,需要在数据传输工具中将这些数据指标计算好了之后存储在共享层中,供分析使用。
66.分析层数据主要存储的是经过分析引擎处理后的数据,分析引擎处理后的数据通过kafka对接hdfs存储到大数据平台的分析层,用于展示或对外数据共享。
67.(4)数据展示组件,用于获取数据分析引擎处理后的数据,分别从数据、微服务和应用系统三个维度展示全链路分析结果。
68.本实施例中,数据展示组件主要是采用vue、echarts、antv-g6等组件以图表、拓扑图等形式在微应用中展示,全链路分析后的结果过是通过微服务的借口获取kafka中分析引擎处理后的结果获取到的,并且展示组件分别以数据、微服务、应用系统三个维度展示全链路分析结果,实现数据中台数据流转的可视。
69.本实施例数据展示组件能够基于数据访问全链路分析结果,从不同维度,以不同形式展示数据访问过程。从数据的角度,以拓扑的形式展示数据从中台到业务系统经过的所有节点;从微服务的角度,以图表的形式展示服务访问接口、数据、数据来源等信息;从全局的角度,以表格和拓扑的形式,展示每一个访问事件的链路详情。
70.本发明主要以api的形式为用户提供接口,方便用户运用本发明的全链路追踪能力,并将结果集成到自己的业务系统中。一般实施方法是将本发明对应的sdk jar文件拷贝至用户业务系统的环境中,并在java构建路径中加入对jar文件的依赖。用户根据提供的api说明文档,调用需要的接口。
71.本实施例系统能够实现如下功能:查询数据流转链路、查询数据调用情况、查询应用拓扑、查询数据台账等。
72.本实施例中,借助大数据平台spark streaming流式处理组件、kafka、impala sql
分析组件等进行全链路追踪分析,主要过程如下:
73.s101:spark消费kafka消息队列,周期性的获取kafka中每个topic的每个partition中的最新offsets,之后根据设定的maxrateperpartition来处理每个batch。
74.s102:spark利用impala组件获取中间连接数据,借助spark streaming组件和imapala脚本进行关联和sql连接分析,主要分析三个场景:一是借助应用监控获取到的堆栈sql信息分析数据调用的完整链路,如图2所示;二是借助rds审计日志结合应该监控信息分析数据调用完整链路,如图3所示;三是借助sls审计日志分析数据服务的调用的完整链路,如图4所示。
75.具体地,结合图2,借助应用监控获取到的堆栈sql信息分析数据调用的完整链路的过程具体为:
76.以arms应用监控的堆栈信息获取sql信息及链路标识traceid,然后通过解析sql分析调用数据库的什么表及字段信息,通过traceid查询微服务ip及微服务唯一标识pid。然后通过pid查询关联数据库ip及端口,并匹配rds实例(即云数据库实例),获取数据源所在项目空间。最后通过对接数据集成信息、dataworks数据源信息,获取到整个访问链路的详细信息,包括原表名、原库名、目标表、目标库、执行时间、微服务名称、ip、业务系统、业务部门等信息。
77.结合图3,借助rds审计日志追踪全链路场景的过程具体为:通过rds审计日志分析访问数据的微服务ip、sql以及rds实例信息,通过解析sql分析调用数据库的表及字段信息,通过rds实例id获取实例的详细信息,包括实例名、实例ip,通过实例ip与数据源的ip比对,确定目标库及任务空间id。微服务ip通过对接arms应用监控信息,获取到微服务名称,通过微服务ip对接云服务器实例信息,获取到微服务所属的业务系统及部门。通过任务空间id以及目标库、目标表比对数据集成信息,获取到源库、源表,最终得到数据集成同步到rds并且服务通过jdbc方式直连rds数据库的应用场景的全链路信息。
78.包括原表名、原库名、目标表、目标库、执行时间、微服务名称、ip、业务系统、业务部门等信息。
79.结合图4,借助sls审计日志追踪全链路场景的过程具体为:通过sls审计日志得出访问数据服务的微服务ip、sql信息以及云数据库唯一标识,通过解析sql分析目标数据库的表及字段信息,通过云数据库唯一标识查询云数据库名称和域名,然后通过解析域名获取云数据库ip,对接外部数据源信息,获取到目标库及任务空间唯一标识。通过目标库、目标表及任务空间id对比数据集成信息,获取原库、源表。微服务ip通过比对arms应用监控信息和云服务器实例信息,获取微服务名称、微服务所在业务系统、所在业务部门等信息。最终分析出通过数据集成同步到rds并且发布成数据服务进行调用应用场景的全链路信息,包括业务系统数据,资源集id,资源集名称、微服务名称、原库名,原表名,目标表,目标库,是否敏感表,中台类型、api名称、api域名、api路径、请求发生时间、访问者ip等信息。
80.s103:分析后的数据回存到kafka,生成两个消息主题,分别为storeinfo和showinfo,一个用于存储,一个用于展示。
81.s104:由spark streaming流式处理组件消费存储信息主题,对数据流转链路进行分析,将分析后的数据存到hdfs或kudu数据库;
82.s105:由java微服务定时轮询消费展示信息主题,用于存储数据链路展示信息,通
过websocket推给前端微应用实时展示。
83.上述虽然结合附图对本发明的具体实施方式进行了描述,但并非对本发明保护范围的限制,所属领域技术人员应该明白,在本发明的技术方案的基础上,本领域技术人员不需要付出创造性劳动即可做出的各种修改或变形仍在本发明的保护范围以内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1