一种基于眼部运动的言语认知评估方法与流程
本发明属于认知和语言能力评估领域,具体涉及一种基于眼部运动的言语认知评估方法。
背景技术:
认知和语言能力评估是对个体认知水平、能力发展的一个重要评价标准,并在日常生活中受到广泛的应用。随着应用的不断拓展,语言认知评估方法也在不断的发展。教师或者评估人员,通过与被测试者的交谈,即可得到一个初步的评估结果,然而此结果易受主观因素的影响。目前,最常用的语言测试主要通过‘试题’的形式进行,即按照测试的内容设定对应的题目,由被测试者完成该题目,对被测试者的答案进行判别,统计出的答案得分决定了语言测试的成绩。传统的语言测试按照测试的不同方面将试题分为不同类别,通过对各类试题的分数统计,来得到测试者在语言不同方面的测试水平。然而这种方法只提供了一个模糊的分数,对于诸如学生的知识状态、认知结构等问题无法解答。为了在测试中获得更多的信息,语言测试工作者在传统语言测试的基础上结合了认知心理学、计量心理学、现代统计数学等理论,提出了许多语言认知诊断模型,如融合模型(hartz2002)、dina模型(junkerandsijtsma2001)等,以检测被测试者的认知结构等信息。例如,专利‘一种语言能力测试方法及系统’,申请号:201510096629.5,即提出了一种采用试题形式进行语言能力测试的方法。
主流的语言认知评估方法,随着不断的改进在测试语言功能方面取得了长足的进步,但其语言测试的形式依然是通过‘试题’的形式展开。该方法在测试过程中涉及了大脑不同脑区的协同工作,对注意力、工作记忆、视觉信息处理、运动控制等方面有较高的要求;同时在测试过程中涉及了很多交互的过程,包括对题意的理解、答案的输出等。任意环节的错误或缺失都将导致语言认知评估成绩的下降,语言认知评估受到诸多因素而非语言理解这单一因素的影响。对于检测分数偏低的被测试者,并不确定这个结果是由语言水平较差引起或者注意力缺陷等其他因素引起,从而降低了语言认知评估成绩的可信度。并且在测试中,需要被测试者主动的参与测试的全过程,测试耗时较长,十分消耗精力。
此外,主流的语言认知评估方法只适用于特征人群。对于有视觉缺陷或运动缺陷的患者,由于无法完成整个测试流程而不能用此类测试方法;对于有注意力缺陷、工作记忆缺陷等认知缺陷的患者,由于部分认知功能的不完善并不适用于此类测试方法。低龄儿童由于其感知、运动、认知的发育未完善,也不适用于此类测试方法。并且,主流的语言认知评估方法需从试题上获得信息输入,并将答案反馈到试题上。流程固定且形式不变,使用场景较为单一。
随着技术研究的发展,对于认知科学的研究,为语言认知评估提供了新的思路。人们受到认知科学的启发,提出了一些进行言语认知评估方法。专利‘语言理解的瞳孔度量评估’,申请号:201280049494.1提出了一种基于瞳孔测量的语言认知评估方法,播放听觉刺激的同时在屏幕上呈现图片,同时测量被测试者瞳孔随时间变化数据,通过将测得数据与标准数据进行比较判定其是否有语言理解缺陷。在认知研究中发现,瞳孔受到诸如光强、精神状态、认知负荷等多种因素的影响。该方法需要不断的转换图片,不可避免的带来光强的干扰,且评估选取的指标如最大瞳孔直径等也受到多种因素的干扰。hallowell(hallowell,wertzetal.2002)于2002年提出了一种使用眼动仪进行眼动检测的方法用于语言认知评估,播放听觉刺激的同时在屏幕上呈现图片,通过计算被测试者在图片不同位置的注视时间判定其是否理解该听觉刺激。此方法在使用前,需要指导被测试者注视屏幕的特定位置以校正眼动仪,部分发育缺陷个体无法完成这个任务。尽管假设被测试者对图片的注视是自发的,但其仍可能受到图片内容及外界因素的影响。
与此同时,认知科学领域的研究人员也在对人的语言处理机制进行研究。falkhuettig等人采用眼动与听觉视觉结合的方法,研究人的语言处理机制,并发掘了一系列重要发现。其主要研究方法为:在播放语音时刻前、播放语音时或播放语音时刻后,同时呈现多幅图片,不同的图片内容与语音内容有着不同程度的联系。在播放语音的同时,用眼动仪记录实验志愿者在不同图片上的注视时长,通过研究语音内容、图片内容、图片注视时长三者之间的关系,探究人的语言处理机制。ding等人采用meg(magnetoencephalography)、eeg(electroencephalograph)等脑信号测量方式与听觉结合的方法,研究人的语言处理机制,发现了大脑在语音加工时对字、词、句子等不同层级语言结构的跟踪。其主要研究方法为:在播放语音的同时,采用meg、eeg等方式测量记录人在进行语音处理时的大脑响应。通过研究语音内容和大脑响应之间的关系,探究人的语言处理机制。
技术实现要素:
现有技术中的主流的语言认知评估方法存在以下技术问题:1、主流的语言认知评估方法在测试过程中涉及了大脑不同脑区的协同工作,对注意力、工作记忆、视觉信息处理、运动控制等方面有较高的要求;同时在测试过程中涉及了很多交互的过程,包括对题意的理解、答案的输出等。任意环节的错误或缺失都将导致语言认知评估成绩的下降,语言认知评估受到诸多因素而非语言理解这单一因素的影响。对于检测分数偏低的被测试者,并不确定这个结果是由语言水平较差引起或者注意力缺陷等其他因素引起,从而降低了语言认知评估成绩的可信度。并且在测试中,需要被测试者主动的参与测试的全过程,测试耗时较长,十分消耗精力。2、主流的语言认知评估方法只适用于特征人群。对于有视觉缺陷或运动缺陷的患者,由于无法完成整个测试流程而不能用此类测试方法;对于有注意力缺陷、工作记忆缺陷等认知缺陷的患者,由于部分认知功能的不完善并不适用于此类测试方法。低龄儿童由于其感知、运动、认知的发育未完善,也不适用于此类测试方法。3、主流的语言认知评估方法需从试题上获得信息输入,并将答案反馈到试题上。流程固定且形式不变,使用场景较为单一。
本发明的目的在于解决上述技术问题,并提供一种基于眼部运动的言语认知评估方法。
首先,叙述本发明的理论基础:
在认知神经科学的研究中发现,当人在处理特定的语音时,可通过对其眼部运动的监测,分辨该人对这段语音内容的理解程度。在语言中,根据语法可划分出不同层级的语言结构,例如:字、词语、短语、句子等,短语由字组成,句子由字和短语组成;即短语是比字更高的语言结构,即句子是比短语更高的语言结构。对更低的语言结构内容的理解是对更高的语言结构内容理解的基础,如对一个句子,需要先理解句子中的每个词语才能理解整个句子。可将任意一个词语、一个短语、一个句子等含有多个语言结构的一个单元称谓一个语料。
在对被测试者的眼部运动进行监测时发现:当被测试者在处理某段语音时,被测试者的眼部运动模式可反映出其是否在加工语音中不同层级的语言结构内容。具体来讲,当被测试者理解某语言结构对应的内容时,其眼部运动可对该语言结构进行同步跟踪,可在被测试者眼部运动观测到与该语言结构同步的响应。若被测试者不理解该语言结构对应的内容,无法对其进行加工,则无法在眼部运动中监测到与该语言结构同步的运动。在实际的应用中,被测试者听某段内容时,也可通过检测被测试者眼部运动是否有对应于内容中最高语言结构的同步响应,以判断被测试者是否理解该段内容。特别的,眨眼与语言结构有较大的关联,具体表现为:当被测试者理解某语言结构对应的内容时,在听到该内容结尾处时有更大的几率发生眨眼。
基于以上的发现,可以设计出基于眼部运动的言语认知评估方案。其总体思路为:以特定材料组成的语音激发被测试者对语音中不同语言结构的同步运动,对采集的眼部运动数据进行分析从而判定被测试者对语音的理解程度。而通过改变材料的内容设置不同难度的语音,综合被测试者对于不同难度语音的理解程度得到被测试者的言语认知评估结果。
本发明所采用的具体技术方案如下:
一种基于眼部运动的言语认知评估方法,其步骤如下:
s1:将用于言语认知评估的每段语音通过测试者的听觉通道依次向被测试者呈现,且在呈现语音刺激的时间内,同步记录被测试者的眼部运动数据;所述的眼部运动数据为被测试者接受语音刺激时的眼球运动数据或眨眼数据;
s2:对所述的眼部运动数据和该数据同步对应的语音进行处理,识别眼部运动数据中是否存在与语音中的语言结构同步的指标特征;若存在则视为被测试者能够理解该段语音中的语言结构内容,若不存在则视为被测试者无法理解该段语音中的语言结构内容。
作为优选,所述的s1中,需向被测试者呈现若干组难度不同的刺激语音集合,每一组刺激语音集合中优选包含多段难度相同的语音;优选的,每一组刺激语音集合中的多段语音难度相同或相近;更优选的,每段语音均由多个拥有相同语言结构、相同难度且相同字数的语料组成。
作为优选,所述的s1中,将一个语料对应的语音向被测试者呈现多次,或者向被测试者呈现多段语料内容相同或相近的语音,以在信号处理时获得较高的信噪比。
作为优选,在向被测试者呈现语音刺激时,语音中每个字的呈现时长相同。
作为优选,在向被测试者呈现语言刺激前,使用听力计对被测试者进行听力检查,以排除其他因素的干扰。
作为优选,所述的眼部运动数据为眼动电图,采集所述眼动电图的电极布置方式为:在被测试者左眼和/或右眼的上方和下方各贴一个电极。
本发明的另一目的在于提供一种基于眼部运动的言语认知评估方法,其步骤如下:
s1:生成若干组不同难度的刺激语音集合,且每组刺激语音集合中包含n段(n取值可自定义)难度等级相同的语音;每段语音由多个具有相同语言结构、相同难度且相同字数的语料组成,且每段语音的总字数相同;
s2:将各刺激语音集合中的每段语音通过测试者的听觉通道依次向被测试者呈现,且每次仅呈现一段语音,相邻语音之间具有间隔,语音中每个字的呈现时长相同;
s3:在每段语音刺激的呈现时间内,同步记录被测试者的眼部运动数据,所述眼部运动数据采用被测试者在听语音过程中由眼动仪记录的眨眼数据;其中,被测试者在听第j段语音时的眨眼数据为xj,xj为与第j段语音等时长的时间序列,由数字0和1组成,序列值为1表示被测试者在该时刻处于眨眼状态,序列值为0表示被测试者在该时刻不处于眨眼状态;
s4:记录被测试者对所有语音刺激的眼部运动数据后,按照刺激语音集合的不同难度将眼部运动数据进行分类,对每一类难度的语音对应的眼部运动数据分别进行同步性分析,分析过程如下:
s401:对每一类难度的n条眨眼数据进行预处理:将n条眨眼数据平均,得到1条平均响应数据,以提高数据信噪比
s402:对每一类难度语音得到1条平均响应数据,对该数据做离散傅里叶变换,得到该类难度语音对应的频谱;
s403:针对每一类难度语音的频谱,对该类难度语音中含有的语言结构对应的频率点幅值进行显著性检验,若该类难度语音中含有的语言结构对应的频率点幅值都具有显著性,则认为被测试者能理解该难度的语音;否则认为被测试者不能理解该难度的语音。
本发明的另一目的在于提供另一种基于眼部运动的言语认知评估方法,其步骤如下:
s1:生成若干段语音,每段语音由多个具有任意语言结构、任意难度且任意字数的语料组成,且同一语料在所有的语音中重复若干次;
s2:将每段语音通过测试者的听觉通道依次向被测试者呈现,且每次仅呈现一段语音;同一语料在任意一段语音中每个字的呈现时长相同,语音波形也相同;
s3:利用布置于被测试者任意一只眼睛上方和下方的眼动电图采集电极,在每段语音刺激的呈现时间内,同步记录被测试者的眼部运动数据,所述眼部运动数据为在听第j段语音过程中电极记录的眼睛上方的电势a1j和眼睛下方的电势a2j;
s4:记录被测试者对所有语音刺激的眼部运动数据后,对语音对应的眼部运动数据进行同步性分析,分析过程如下:
s401:对于每一段语音,计算该段语音对应的眼部运动数据zj:
zj=a2j-a1j
对zj进行高通滤波,去除信号中由于仪器本身引起的无关响应;
s402:将每段语音逐段拼接,将每段语音对应的眼部运动数据zj也按照相同的顺序逐段进行拼接得到序列y=[y0y1…yn],序列y的长度为n+1;
s403:对拼接后的语音中第i个语料的出现时刻进行标记,第i个语料对应的出现时刻标记为
s404:设置hi为对应于第i个语料眼电响应的时间序列,hi的序列长度大于所有语料中播放时间最长的语料对应的播放时长,hi的序列长度为k+1;
s405:在每个xi序列前加k个0,更新
将y与x1,x2,…,xi,…,xm中的数值代入计算矩阵
根据下列公式计算得到
s406:将语料眼电响应的时间序列h1,h2,…,hi,…,hm进行归一化,使每个序列hi的均值为0,标准差为1;
s407:截取得到每一个语料对应的语音信号,将语音信号取绝对值,并做低通滤波,得到语音包络;
s408:对语音包络进行降采样,使得语音包络的采样率与眼部运动数据采样率相同,对降采样后的语音包络进行归一化,对序列长度小于语音响应hi长度的语音包络信号末尾补零,使得每个语料的语音包络信号与语音响应信号具有相同的长度;
s409:对于每一个语料,向预先经过训练的二分类器中,输入该语料的语音包络和语音响应的时间序列,输出被测试者是否理解该语料。
作为优选,s2中向被测试者呈现的每段语音之间具有间隔,以防止被测试者听觉疲劳,使获得的数据能够真实反映其理解能力。
作为优选,二分类器的训练方法为:选择能理解该语料的人,按步骤s1~s3以及s4中的s401~s408得到语音包络和语音响应,将其作为理解语料的标准响应样本;选择不能理解该语料的人,按步骤s1~s3以及s4中的s401~s408得到语音包络和语音响应,将其作为不能理解语料的标准响应样本;用这两类样本对分类器进行训练,得到一个用于区分被测试者是否理解该语料的二分类器。
本发明相对于现有技术而言,具有以下有益效果:
1、本发明基于眼部运动的言语认知评估方法只采用听觉作为知觉通道的输入;在信息处理过程中涉及较少的高级认知系统,可推广至低龄儿童、发育缺陷患者使用,有更广泛的使用人群。
2、本发明基于眼部运动的言语认知评估方法只涉及了信息的输入与语言的自动加工,涉及较少的认知环节,所得到的测试结果更为客观。同时,被测试者可较轻松的完成测试。
3、本发明基于眼动的言语认知评估方法有多种可供选择的方法进行数据采集,信息采用听觉输入可将声音外放或使用耳机播放,具有较多的使用场景。
附图说明
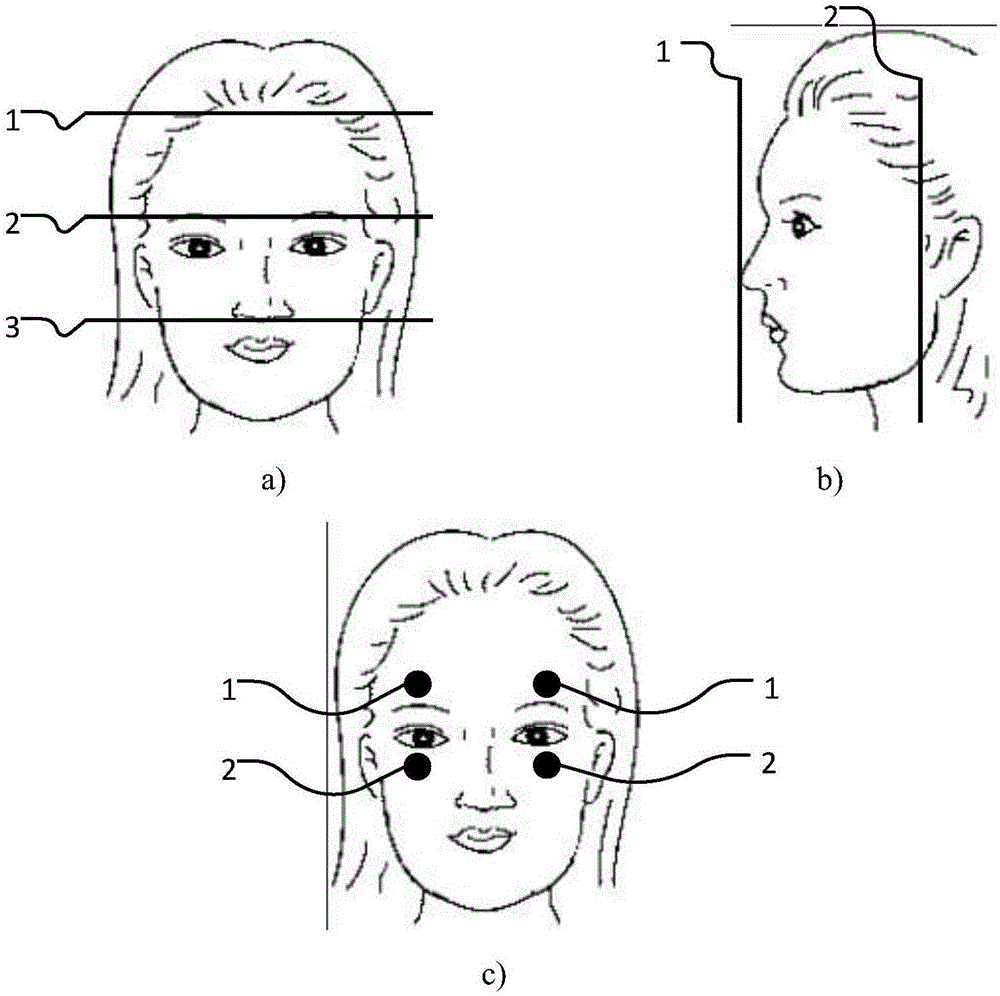
图1为电极贴放示意图;其中a)为电极贴放竖直范围示意图,b)为电极贴放水平范围示意图,c)为电极贴放位置示意图。
图2为实施例1中的实验语音材料;
图3为实施例1中的语音响应eog频谱图;
图4为实施例2中的眼动仪使用示意图;
图5为实施例2中的语音响应眼动频谱图;
图6为实施例2中的语音响应眨眼频谱图;
图7为语言评估流程图;
图8为实施例3中的语音示例;
图9为实施例3中的语音刺激示例;
图10为实施例3中的结果分析流程图;
图11为实施例4中的语音示例;
图12为实施例4中的语音刺激示例;
图13为实施例4中的结果分析流程图;
图14为实施例4中的输入输出图。
具体实施方式
下面结合附图和具体实施方式对本发明做进一步阐述和说明。本发明中各个实施方式的技术特征在没有相互冲突的前提下,均可进行相应组合。
本发明中提出的基于眼部运动的言语认知评估方法,其基本步骤如下:
s1:将用于言语认知评估的每段语音通过测试者的听觉通道依次向被测试者呈现,且在呈现语音刺激的时间内,同步记录被测试者的眼部运动数据;眼部运动数据为被测试者接受语音刺激时的眼球运动数据、眨眼数据,这些数据可以由眼动仪测定,也可以采用eog电极测量。
s2:对眼部运动数据和该数据同步对应的语音进行处理,识别眼部运动数据中是否存在与语音中的语言结构同步的指标特征;若存在则视为被测试者能够理解该段语音中的语言结构内容,若不存在则视为被测试者无法理解该段语音中的语言结构内容。
眼部运动数据是通过眼部运动监测来实现的,眼部运动监测是对眼球运动和眨眼进行监测,任何可进行眼部运动监测的仪器,例如摄像头、眼动仪、eog均适用于本系统,优选的选用eog方式进行数据记录。
采用eog方式的电极贴放范围如下图1.a、1.b所示:图1.a表示电极贴放的竖直范围,包含线段1和线段3之间的区域,以眉心即线段2为中点,包含鼻部底端到前额发际线附近的区域;图1.b表示电极贴放的水平范围,包含左右两侧线段2所示位置之间的区域,以鼻尖即线段1为中点,包含两侧耳屏之间的区域。在上述规定的eog电极贴放范围内,贴放的电极个数从1个到100个不等。优选的,只在被测试者左眼或右眼的上方和下放各贴放一个电极,即可记录数据,具有设备简单,数据处理方便的优点,电极推荐张贴位置示意图如图1.c所示。
与语音中的语言结构同步的指标特征可以采取多种方法来判断,例如求信号的互相关、时间响应函数(trf)方法、基于系统辨识的建模、傅里叶变换等。任何可用于判断同步性的方法均在本方案的考虑范围之内,
下面将通过两个实施例展示两个关于眼动与语言理解实验的实验结果,以证明当理解某语言结构对应的内容时眼部运动可对该语言结构进行同步跟踪,可在眼部运动观测到与该语言结构同步的响应。各实施例中,语音均通过声音外放或使用耳机播放,被测试者接收。在向被测试者呈现语言刺激前,进行相应的检查以排除其他因素的干扰,采用听觉通路播放刺激前,使用听力计对被测试者进行听力检查。
实施例1
本实施例在被测试者听语音时,采用eog电极对眼部运动产生的眼电数据进行捕捉。eog测量实验结果用以说明,采用eog测量的眼动数据,可以观测到对语言结构的同步跟踪。需要特别说明的是,现有研究已表明eog测量得到的眼电主要由眼球运动引起,即eog测量得到的电势变化反应了眼球的运动情况。
步骤s1:
实验使用3种语料,实验语料如下图2所示,每段语料由48个字组成。语料1含有双字词语,语料2含有双字词语和四字句子,语料3由随机字组成不含词语和句子。实验中使用上述3种语料各30段。
步骤s2:
采用听觉通道(语音通过耳机播放)向被测试者呈现刺激,所有语音均由软件合成。向能理解中文的正常被测试者(测试者能够理解所有的语料)分别播放由上述3类语料组成的语音各30段,每个字的时长固定为250ms,每段语音的播放时长为12s。每次向被测者呈现一段语音的语音刺激,相邻语音之间的间隔时长可由被测试者决定,以防止被测试者听觉疲劳,使获得的数据能够真实反映其理解能力。
步骤s3:
选用eog的方式记录眼部运动数据,电极的贴放示意图如图1.c所示,上下两个电极分别记为电极通道1、电极通道2。要求被测试者在听语音的过程中保持闭眼状态。在被测试者听语音的过程中保持同步的数据记录,只记录被测试者听语音时的眼部运动状态数据。
步骤s4:
对采集得到的眼部运动状态数据进行处理,数据处理过程如下:
流程①
对于每一类语料,每一段眼部运动可按如下公式计算γj作为该段语音对应的眼部运动数据:
γj=b2j-b1j
其中,b1j、b2j为图1.c)所示两个电极记录的该类语料中第j段语音的响应信号。
γj的数值大小表示电势差大小,正负表示电势差方向。求差时需要对相同时刻的b1j、b2j数值点求差,作为该时刻的γj数值。
然后采用fir高通滤波器,截止频率0.5hz,对γj进行高通滤波,去除信号中由于仪器本身引起的无关响应。
流程②
对于每一类语料,将该类语料对应的30段语音响应信号叠加平均,以提高信号的信噪比。
流程③
对于每一类语料,将平均后的信号
对图3的特别说明:由于实施例1、实施例2的眼电、眼动、眨眼的数据单位各不相同,眨眼数据表示发生概率没有具体单位,故对所有的图3、图5、图6数据做归一化处理,只比较数据间的相对大小。纵坐标单位为a.u.,即表示这是相对值没有具体单位。
流程④
对于每一类难度的语音集合,对该语音中语言结构对应的频率点幅值进行显著性检验。将该频率点幅值与周围频率点幅值的均值进行比较,检验该频率点幅值是否显著性大于周围频率点幅值的均值。
结果分析:
双字词语结构的呈现时长为500ms即每500ms出现一次,对应频率为2hz,四字句子结构的呈现时长为1000ms即每1000ms出现一次,对应频率为1hz。若eog测量的眼动数据中有显著的2hz幅值,则说明眼动有对双字词语这个层级结构进行同步跟踪,若eog测量的眼动数据中有显著的1hz幅值,则说明眼动有对四字句子这个层级结构进行同步跟踪。
数据处理结果如下图3所示。将语料一响应在1hz、2hz处做显著性t检验,语料一响应在1hz处幅值没有显著大于周围的值,语料一响应在2hz处幅值显著大于周围的值,即听语料一的语音时有对双字词语的同步跟踪但没有对四字句子的同步跟踪。将语料二响应在1hz、2hz处做显著性t检验,语料二响应在1hz处幅值显著大于周围的值,语料二响应在2hz处幅值显著大于周围的值,即听语料二的语音时有对双字词语和四字句子的同步跟踪。将语料三响应在1hz、2hz处做显著性t检验,语料三响应在1hz、2hz处的幅值没有显著大于周围的值,即听语料三的语音时没有对双字词语和四字句子的同步跟踪。
综上,在听语料一时有对双字词语这个层级结构进行同步跟踪,在听语料二时有对双字词语和四字句子这两个层级结构进行同步跟踪,在听预料三时没有对词语和句子这些层级结构的同步跟踪。实验结果与语料内容相吻合,当理解某语言结构对应的内容时眼部运动可对该语言结构进行同步跟踪。语料三由随机字组成不含词语和句子,因此不会产生对词语和句子这些层级结构的同步跟踪。进行语言认知评估时,若被测试者不理解语音中的词语或句子则无法识别出这是一个词语或句子,因此不会产生对词语和句子这些层级结构的同步跟踪,其对语音的响应与对语料三的响应相似。
实施例2
本实施例在被测试者听语音时,采用眼动仪对眼动数据进行捕捉。本实施例的眼动仪测量实验结果用以说明,采用眼动仪测量的眼动数据,可以观测到对语言结构的同步跟踪。
实验测量的思路和数据处理方法与实施例1类似,不同之处仅在于实施例1的eog测量实验中的使用的eog数据作为眼部运动数据,而本实施例中则使用眼动仪测量的眼动数据和眨眼数据替代作为眼部运动数据。具体实验过程如下:
步骤s1:
实验语料采用了图2中的语料2和语料3两种语料,实验语料如下图2所示,每段语料由48个字组成。语料2含有双字词语和四字句子,语料3由随机字组成不含词语和句子。实验中使用上述3种语料各30段。
步骤s2:
采用听觉通道(语音通过耳机播放)向被测试者呈现刺激,所有语音均由软件合成。向能理解中文的正常被测试者(测试者能够理解所有的语料)分别播放由上述3类语料组成的语音各30段,每个字的时长固定为250ms,每段语音的播放时长为12s。每次向被测者呈现一段语音的语音刺激,相邻语音之间的间隔时长可由被测试者决定,以防止被测试者听觉疲劳,使获得的数据能够真实反映其理解能力。
步骤s3:
采用眼动仪测量眼动数据,即眼球运动数据和眨眼数据,眼动仪使用示意图如下图4所示。被测试者正前方放置了一个显示屏,显示屏的前方放置了一个眼动仪。被测试者在测试时,为稳定头部可将头部倚靠在头托上。在正式测试之前需对眼动仪进行校准,在屏幕上依次呈现一定个数的点,每次呈现1个点,要求被测试者注视屏幕上出现的每一个点。在测试时,为使眼动仪数据更准确,要求被测试者将视线保持在屏幕范围内,同时屏幕显示为全黑色以减少对眼动的干扰。使用眼动仪在被测试者听语音的过程中保持同步的数据记录,记录被测试者听语音时的眼动数据,即眼球运动数据和眨眼数据。
步骤s4:
对采集得到的眼动数据进行处理,眨眼数据与眼球运动数据可分别单独作为检测语言认知的指标,在下述部分分别描述这两部分数据的处理过程。数据处理过程如下:
流程①
对于每一类语料,εj表示眼动仪记录的被测试者听第j段语音时的眼球水平方向运动数据。εj为与语音j等时长的时间序列,序列中任意时刻的点表示被测试者在该时刻的眼球注视点水平坐标。
对于每一类语料,δj表示眼动仪记录的被测试者听第j段语音时的眨眼数据。δj为与语音j等时长的时间序列,由数字0和1组成,对于任意时刻,1表示被测试者在该时刻处于眨眼状态,0表示被测试者在该时刻不处于眨眼状态。
流程②
对于每一类语料,将该类语料对应的30段语音响应的眼球运动数据叠加平均,以提高信号的信噪比。
对于每一类语料,将该类语料对应的30段语音响应的眨眼数据叠加平均,以提高信号的信噪比。
流程③
对于每一类语料,将平均后的眼球运动数据
对于每一类语料,将平均后的眨眼数据
对图5、图6的特别说明:由于实施例1、实施例2的眼电、眼动、眨眼的数据单位各不相同,眨眼数据表示发生概率没有具体单位,故对所有的图3、图5、图6数据做归一化处理,只比较数据间的相对大小。纵坐标单位为a.u.,即表示这是相对值没有具体单位。
流程④
对于每一类难度的语音集合,对于眼球运动数据和眨眼数据,对该语音中语言结构对应的频率点幅值进行显著性检验。将该频率点幅值与周围频率点幅值的均值进行比较,检验该频率点幅值是否显著性大于周围频率点幅值的均值。
结果分析:
双字词语结构的呈现时长为500ms即每500ms出现一次,对应频率为2hz,四字句子结构的呈现时长为1000ms即每1000ms出现一次,对应频率为1hz。若eog测量的眼动数据中有显著的2hz幅值,则说明眼动有对双字词语这个层级结构进行同步跟踪,若eog测量的眼动数据中有显著的1hz幅值,则说明眼动有对四字句子这个层级结构进行同步跟踪。
眼动数据的处理结果如图5所示。显著性检验过程同实施例1。由结果可得出,听语料三的语音时没有对双字词语和四字句子的同步跟踪,听语料二的语音时有对双字词语和四字句子的同步跟踪。
眨眼数据的处理结果如图6所示。显著性检验过程同实施例1。由结果可得出,听语料三的语音时没有对双字词语和四字句子的同步跟踪,听语料二的语音时有对双字词语和四字句子的同步跟踪。
综上,眼动仪测量的眼动数据和眨眼数据可得出相同结论,在听语料二时有对双字词语和四字句子这两个层级结构进行同步跟踪,在听预料三时没有对词语和句子这些层级结构的同步跟踪。实验结果与语料内容相吻合,也与eog实验的结果相吻合,当理解某语言结构对应的内容时眼部运动可对该语言结构进行同步跟踪。
由上述实施例1中的eog测量实验结果和实施例2中的眼动仪测量实验结果可得出相同结论,在听语音时眼动和眨眼会产生对理解的语音内容的语言结构进行同步跟踪。而进行语言认知评估时,若被测试者不理解语音中的层级结构对应的内容则无法识别出这个层级结构,因此不会产生对这些层级结构的同步跟踪,其对语音的响应与对语料三的响应相似。
上述两个实施例表明,通过对被测试者听语音过程中获得的眼部运动数据和该数据同步对应的语音进行同步性分析,可以判断该被测试者是否能够理解该语音中的语料。因此,该方法可以评估其言语认知水平。
而下面将结合上述方法,提供两个更为具体的言语认知水平评估方式,两个案例的主要步骤基本相同,如下图7所示,其中步骤s2、s3重复循环进行,直到呈现完所有的语音后进入s4进行数据分析。s1中的语音(即语串)具体数量可以根据需要进行选择,可以仅有一种难度、一段语音,也可以有多种难度、多段语音。
实施例3的每段语音由多个拥有相同语言结构,难度相近且字数相同的语料组成,语料的每个字的呈现时长为250ms,采用眼动仪的方法记录眼部运动,对眨眼的数据进行分析。实施例4的每段语音由多个拥有任意语言结构,难度不定且任意字数的语料组成,语料的每个字具有任意呈现时长,采用eog的方法记录眼部运动,对眼电数据进行分析。相对而言,实施例4的语音更偏向于实际生活中听到的语音。由于实施例3和实施例4组成每段语音的语料具有不同特点,在这两个案例中采用了不同的数据处理方法。
实施例3
本实施例中,利用傅里叶变换来判断眼部运动数据中是否存在与语音中的语言结构同步的指标特征。本实施例的具体做法如下:
步骤s1:
生成不同难度的刺激语音集合,语音难度可采用语料习得年龄、语料出现频率、语料熟悉度或抽象程度、结构复杂度等标准,也可采用其他定义的可客观区分的标准。对语料难度的评价可以使用一个标准或综合考虑多个标准。为获得更好的效果,对于每一难度的语音集合,每段语音由多个具有相同语言结构,难度相同或相近,且字数相同的语料组成,每段语音的总字数也相同。每段语音中的语料具有相同等级的难度。
如下图8所示为语音的三个示例,可根据抽象程度和结构复杂度将这三段语音划分为不同的难度,属于三个不同难度的语音集合,语音1~3的难度逐渐提升。语音1代表的语音集合均由双字的具体名词组成,包含单字的字、双字的词语两个语言结构。语音2代表的语音集合均由双字的抽象名词组成,包含单字的字、双字的词语两个语言结构。语音3代表的语音集合均由四字的主谓结构句子组成,包含单字的字、双字的词、四字的句子三个语言结构。对每一难度的语音集合,均生成20段语音,每段语音由多个具有相同语言结构,难度相近且字数相同的语料组成。每段语音由40个字组成。
步骤s2:
采用听觉通道(语音通过耳机播放或者外放)向被测试者呈现刺激,所有语音均按照语串由软件合成。合成的每个字呈现时长为250ms,由简单计算可知,单字结构的呈现时长为250ms,双字结构的呈现时长为500ms,四字结构的呈现时长为1000ms。语音刺激示例图如下图9所示,每段语音由40个字组成,一段语音的语音时长为10s,每次向被测者呈现一段语音的语音刺激,相邻语音之间的间隔时长可由被测试者决定,以防止被测试者听觉疲劳,使获得的数据能够真实反映其理解能力。
步骤s3:
在每段语音刺激的呈现时间内,选用眼动仪的方式记录眼部运动数据,眼动仪使用示意图如图4所示,被测试者正前方放置了一个显示屏,显示屏的前方放置了一个眼动仪。被测试者在测试时,为稳定头部可将头部倚靠在头托上。在正式测试之前需对眼动仪进行校准,在屏幕上依次呈现一定个数的点,每次呈现1个点,要求被测试者注视屏幕上出现的每一个点。在测试时,为使眼动仪数据更准确,要求被测试者将视线保持在屏幕范围内,同时屏幕显示为全黑色以减少对眼动的干扰。使用眼动仪在被测试者听语音的过程中保持同步的数据记录,只记录被测试者听语音时的眼部运动状态(眨眼数据)。
步骤s4:
记录被测试者对所有语音刺激的眼部运动响应后,按照刺激语音的不同难度将眼部运动数据分类,对每一类难度语音对应的眼部运动数据分别进行分析。每一类难度语音对应的眼部运动数据(下面简称为每一类眼部运动数据)的处理流程如下图10所示,下面描述具体处理流程。
流程①预处理:
对于每一类眼部运动数据,xj表示眼动仪记录的被测试者听第j段语音时眨眼数据。xj为与语音j等时长的时间序列,由数字0和1组成,对于任意时刻,1表示被测试者在该时刻处于眨眼状态,0表示被测试者在该时刻不处于眨眼状态。
对于每一类眼部运动数据,将该类语料对应的20段语音响应信号叠加平均,以提高信号的信噪比。得到1段平均语音响应信号
流程②离散傅里叶变换:
对于每一类眼部运动数据,得到1段平均语音响应信号
流程③显著性检验:
对于每一类难度的语音集合,对该语音中含有的语言结构对应的频率点幅值进行显著性检验。具体的:对语音1、2代表的语音集合中双字词语这个语言结构的同步响应进行显著性检验,双字结构的呈现时长为500ms对应频率为2hz,对该语音集合对应频谱的2hz处频率点幅值进行显著性检验。对语音3代表的语音集合中双字词语和四字句子两个语言结构的同步响应进行显著性检验,双字结构的呈现时长为500ms对应频率为2hz,四字结构的呈现时长为1000ms对应频率为1hz。对该语音集合对应频谱的1hz、2hz处频率点幅值进行显著性检验。
对每一类难度语音集合的每一个语言结构对应频率点幅值做显著性检验。对频率点幅值进行f检验,取p值0.05,检验该频率点幅值是否显著大于周围值。
对于每一类难度的语音集合,若该语音中含有的语言结构对应的频率点幅值都具有显著性,即显著性检验结果为显著大于周围值,则认为被测试者能理解该难度的语音集合;否则认为被测试者不能理解该难度的语音集合。具体的:对语音1、2代表的语音集合,在2hz处进行显著性检验,若均显著则认为被测试者能理解语音1、2代表的语音集合;对语音3代表的语音集合,在1hz、2hz处进行显著性检验,若均显著则认为被测试者能理解语音3代表的语音集合;否则认为被测试者不能理解该难度的语音集合。
流程④语言认知评估:
对于每一类难度的语音集合,已知被测试者能理解哪些难度的语音集合不能理解哪些难度的语音集合。综合不同难度语言的理解情况,即可评估被测试者的语言认知水平。
实施例4
本实施例中,利用时间响应以及二分类器来判断被测试者是否理解语音。本实施例的具体做法如下:
步骤s1:
生成不同难度的语料,可采用语料习得年龄、语料出现频率、语料熟悉度或抽象程度、结构复杂度等标准,也可采用其他定义的可客观区分的标准。对语料难度的评价可以使用一个标准或综合考虑多个标准。每段语音由多个拥有任意语言结构,难度不定且任意字数的语料组成,语料的每个字具有任意呈现时长。在所有语音中,为提高采集信号的信噪比,将每个语料重复播放20次,通过语料之间不同的组合方式形成每段内容都不完全相同的语音,本实施例中共m段语音。
如图11所示为语音的两个示例,可根据抽象程度和结构复杂度将语料分为不同的难度等级,每段语音由拥有任意语言结构,不同难度且任意字数的语料组成。此种语音相对于其他实施例中的语音,具有更为任意的语言结构,比较符合实际生活中所听到的语音,能够更为真实的测得被测试者是否理解语音中的不同语料。
步骤s2:
采用听觉通道(语音通过耳机播放或者外放)向被测试者呈现语音刺激,所有语音均按照语串由软件合成。不同语料每个字呈现时长不同,但同一语料在不同语音中每个字的呈现时长相同,且语音波形也相同。不同段语音之间的字数和总播放时长有微小差别。语音刺激示例图如图12所示,每次向被测者呈现一段语音的语音刺激,相邻语音之间的间隔时长可由被测试者决定,以避免听觉疲劳。
步骤s3:
选用eog的方式记录眼部运动数据,电极的贴放示意图如图1.c所示,上下两个电极分别记为电极通道1、电极通道2。为屏蔽视野中的其他因素对眼部运动的干扰,选用eog方式时可要求被测试者在听语音的过程中保持闭眼状态。在被测试者听语音的过程中保持同步的数据记录,只记录被测试者听语音时的眼部运动状态。
步骤s4:
对于每一段眼部运动数据,可将电极通道1、电极通道2采集到的对应第j段语音的响应信号用a1j、a2j表示,分别表示在听语音过程中电极记录的被测试者眼睛上方的电势和眼睛下方的电势。a1j、a2j均是序列数据,序列个数与电极的采样频率有关。记录被测试者对所有语音刺激的眼部运动响应后,处理流程如图13所示,下面描述具体处理流程。
流程①预处理:
对于每一段眼部运动,可按如下公式计算zj作为该段语音对应的眼部运动数据:
zj=a2j-a1j
其中zj的数值大小表示电势差大小,正负表示电势差方向。求差时需要对相同时刻的a1j、a2j数值点求差,作为该时刻的zj数值。
然后采用fir高通滤波器,截止频率0.5hz,对zj进行高通滤波,去除信号中由于仪器本身引起的无关响应。
流程②求语音响应和语音包络:
可将被测试者看成一个系统,将每段语音逐段拼接,将所有记录的并经过上述预处理的眼部运动数据zj也按照相同的顺序逐段进行拼接得到序列y,视为系统的输出,语音在序列中的顺序与眼部运动数据在序列中的数据必须完全对应。y为语音响应的时间序列与语音刺激等时长,即图14中①所示语音的响应。
y=[z1z2…zj…zm],zj为采集的第j段语音响应经过预处理后的信号,j∈[1,m]。
拼接后的y可表示为[y0y1…yn],y0y1…yn分别为序列y的第1、2、…、n+1个数,序列y的长度为n+1。
设时间序列x1,x2,…,xi,…,xm为系统的输入,共m个输入,表示所有的m个语料的出现时刻标记。时间序列xi为第i个语料对应的出现时刻标记,
在系统中,人对每一个词产生一个响应,设对语料集合里的第i个词产生响应记为hi,即为对应于第i个语料眼电响应的时间序列。hi为我们希望求取的目标,即通过已知的y和x1,x2,…,xi,…,xm求取h1,h2,…,hi,…,hm。可取h1,h2,…,hi,…,hm的序列长度为所有语料中播放时间最长的语料对应的播放时长加上100ms,设h的序列长度为k+1。
y与x1,x2,…,xi,…,xm以及h1,h2,…,hi,…,hm三者之间的关系可用如下关系表示:
y[n]=(x1*h1)[n]+(x2*h2)[n]+…(xi*hi)[n]+…+(xm*hm)[n]+e[n]
*符号代表卷积运算,(xi*hi)代表对xi和hi进行卷积运算
y[n]表示时间序列y第n个位置对应的值
(xi*hi)[n]表示xi和hi卷积后序列第n个位置对应的值
e为建模假设的误差序列,即语音响应y中无法建模的部分
e[n]为误差时间序列e第n个位置对应的值
为使建模更加完整,需要在x1,x2,…,xi,…,xm的每个时间序列前加k个0,更新
由此,可将上述公式表示成矩阵形式
上述矩阵中,
y=[y0y1…yn]
其中,y0、y1、yn分别为时间序列y中第1个数、第2个数和第n+1个数。
其中,
其中,
e=[e0e1…en]
其中,e0、e1、en分别为时间序列e中第1个数、第2个数和第n+1个数。
已知y与x1,x2,…,xi,…,xm,可将y与x1,x2,…,xi,…,xm代入公式,求出h1,h2,…,hi,…,hm,求解方法如下:
矩阵形式简化表示成如下公式。
其中,
即
可采用最小二乘法求解,计算公式如下所示
可求得
将语料对应的时间序列h1,h2,…,hi,…,hm进行归一化,使每个序列hi的均值为0,标准差为1。
对于每一个语料,可截取得到对应的语音信号,将语音信号取绝对值,并做低通滤波,得到语音包络。
对语音包络进行降采样使得语音包络的采样率与s3中eog信号采样率相同,降采样后对语音包络做归一化,对序列长度小于语音响应hi长度的语音包络信号末尾补零,使得每个语料的语音包络信号与语音响应信号hi具有相同的长度。
流程③响应分类:
对于每一个语料,向预先经过训练的二分类器中,输入该语料的语音包络和语音响应的时间序列,输出被测试者是否理解该语料。
上述二分类器需要在前期采集一定数量的样本进行二分类器训练。训练方法具体为:选择可以理解该语料的人,按上述步骤得到语音包络和语音响应,认为该响应为理解语料的标准响应样本;选择不能理解该语料的人,按上述步骤得到语音包络和语音响应,认为该响应为不理解语料的标准响应样本。将用两类样本对分类器进行训练,得到一个二分类器,训练样本应当足够大。
流程④语言认知评估:
对于每一个语料,已知被测试者能否理解该语料以及该语料的难度。综合不同难度语料的理解情况,即可评估被测试者的语言认知水平。
以上所述的实施例只是本发明的一种较佳的方案,然其并非用以限制本发明。有关技术领域的普通技术人员,在不脱离本发明的精神和范围的情况下,还可以做出各种变化和变型。因此凡采取等同替换或等效变换的方式所获得的技术方案,均落在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!