基于大数据的上颈椎手术早期并发症信息采集系统及方法与流程
本发明属于大数据分析领域,尤其涉及一种基于大数据的上颈椎手术早期并发症信息采集系统及方法。
背景技术:
颈椎手术的早期并发症包括,感染:颈椎前路手术有时需要取髂骨进行植骨融合,有时可能会出现取骨区和植骨区的感染。喉上神经或喉返神经损伤:上颈椎前路手术有时会发生喉上神经损伤,表现为术后在饮水及吃流质时,发生以呛咳为主要的症状。血肿与咽下困难:多由于骨刀开骨槽时,推体骨松质区渗血所致,若血肿吸收不良,食道与报体前方可发生粘连,引起吞咽困难。胸膜损伤,颈椎过伸性瘫痪与震动性瘫痪等,手术后的病发症可能会产生生命威胁,所以需要进行提前进行风险预估。目前只能通过经验进行对术后的并发症进行大体的估计和防范,没有精确的数据,统计时可能会片面统计,造成信息统计不完整。
综上所述,现有技术存在的问题是:目前只能通过经验进行对术后的并发症进行大体的估计和防范,没有精确的数据,统计时可能会片面统计,造成信息统计不完整。
现有技术中不能将上颈椎手术病人的检测信息、诊断信息和治疗信息的误差信息进行剔除,不利于采集准确的病人信息,无法保证后续工作的准确进行;现有技术中不能有效的对各种并发症的病人信息进行准确快速的分类,工作效率较差;现有技术中不能对信息进行校正后储存,对信息的增益和偏移不能反馈修正,不利于信息被准确、无误的存储,无法保证调用时的信息质量。
技术实现要素:
针对现有技术存在的问题,本发明提供了一种基于大数据的上颈椎手术早期并发症信息采集系统及方法。
本发明是这样实现的,一种基于大数据的上颈椎手术早期并发症信息采集方法,所述基于大数据的上颈椎手术早期并发症信息采集方法包括:
步骤一,采用肖维涅算法对上颈椎手术病人的检测信息、诊断信息和治疗信息进行剔除误差数的信息收集;
步骤二,采用朴素贝叶斯分类算法对各种并发症的病人信息进行分类,统计,将信息进行保存;
步骤三,对病人的其他信息进行补充修改,采用神经网络方法对信息进行暂时的校正储存;
步骤四,将颈椎手术的早期并发症信息上传到大数据平台。
进一步,所述步骤一中采用肖维涅算法将上颈椎手术病人的检测信息、诊断信息和治疗信息的误差信息进行剔除,具体算法为:
利用数据样本集合s0={x0,x1,…,xn},n个样本数据中含有m个误差数据样本点,f0(x)是反映这组数据样本基本特征的函数:
式中:n是一组数据的个体数;
di=|xi-f(xi)|;
用来衡量样本点数据xi偏离函数关系的程度,di越大,样本点成为误差数据的可能性越大;对n个数据求di最大值;
肖维涅算法剔除di值最大的样本点j,建立新的样本集合s1={s0–xj},对剩余的数据进行重复运算,数据满足运算终止条件时,剔除的m个样本点就是误差数据。
进一步,所述步骤二中采用朴素贝叶斯分类算法,具体算法为:
d是训练对象与其相关联的类标号的集合;每个对象用一个n维属性向量x={x1,x2…xn}表示,描述n个属性a1,a2…an的值;原始集合基于n维属性共划分为m个类c1,c2…cm,计算每个类对x的后验概率,并将对象x归属于具有最高后验概率的类;后验概率p(ci|x)的计算公式为:
由于p(ci|x)的计算开销较大,进行类条件独立的假定,给定向量的类标号,并假定属性值有条件的相互独立;p(xi|c)的计算公式为:
其中,p(x1|ci)p(x2|ci)…p(xn|cn)由训练对象求算,xk表示x在属性ak上的值;对每个类别ci计算p(x|ci)p(ci);当p(x|ci)p(ci)>p(x|cj)p(cj),1≤j≤m,j≠i成立时,x属于类ci。
本发明的另一目的在于提供一种实现所述基于大数据的上颈椎手术早期并发症信息采集方法的基于大数据的上颈椎手术早期并发症信息采集系统,所述基于大数据的上颈椎手术早期并发症信息采集系统包括:
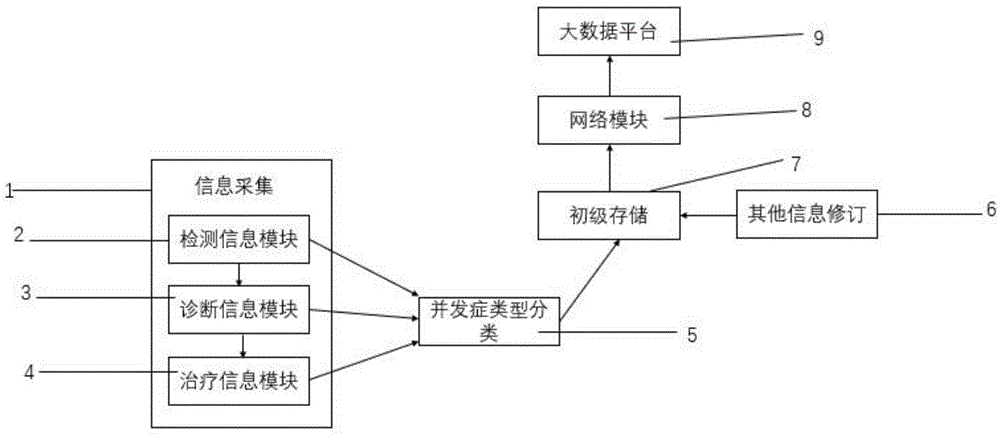
信息采集系统,包括检测信息模块、诊断信息模块、治疗信息模块,信息采集系统后进行并发症类型分类模块,并将其保存到初级储存;
检测信息模块后继续诊断信息模块,诊断信息模块后统计治疗信息模块;
初级储存后,通过其他信息修订模块进行修订;初级储存后通过网络模块将信息传输到大数据平台。
本发明的另一目的在于提供一种应用所述基于大数据的上颈椎手术早期并发症信息采集方法的信息数据处理终端。
本发明的优点及积极效果为:本发明设置有其他信息修订模块,可以通过对病人以往病史的了解对颈椎术后患者进行修订,来避免因为具有其他的病史对术后并发症造成的影响;该发明设置有大数据平台,可以对颈椎病人术后的并发症信息进行统计,进而可以得出术后各种并发症的出现概率,并可以对原因进行统计,进而可以方便医学上的研究,以及对病人的治疗与有着很大的帮助。该发明可以对颈椎术后的并发症进行统计,并提供大量数据信息,可以对病因进行统计,进而可以方便医学上的研究,以及对病人的治疗与有着很大的帮助。
本发明采用肖维涅算法将上颈椎手术病人的检测信息、诊断信息和治疗信息的误差信息进行剔除,有利于采集准确的病人信息,保证后续工作的准确进行;本发明采用朴素贝叶斯分类算法,提高分类速度及提升分类效果,对各种并发症的病人信息进行准确快速的分类,提高工作效率;本发明采用神经网络方法对信息进行暂时的校正储存,根据像元校正后的期望输出,对信息的增益和偏移进行反馈修正,有利于信息被准确、无误的存储,保证调用时的信息质量。
附图说明
图1是本发明实施例提供的基于大数据的上颈椎手术早期并发症信息采集系统结构示意图;
图2是本发明实施例提供的基于大数据的上颈椎手术早期并发症信息采集系统原理示意图;
图3是本发明实施例提供的基于大数据分析的上颈椎手术的早期并发症信息采集方法流程图;
图中:1、信息采集系统;2、检测信息模块;3、诊断信息模块;4、治疗信息模块;5、并发症类型分类模块;6、其他信息修订模块;7、初级存储;8、网络模块;9、大数据平台。
具体实施方式
为能进一步了解本发明的发明内容、特点及功效,兹例举以下实施例,并配合附图详细说明如下。
下面结合附图对本发明的结构作详细的描述。
如图1-图2所示,本发明实施例提供的基于大数据的上颈椎手术早期并发症信息采集系统包括:
检测信息模块2、诊断信息模块3、治疗信息模块4、并发症类型分类模块5、其他信息修订模块6、初级存储7、网络模块8、大数据平台9。
本发明实施例提供的信息采集系统1包括检测信息模块2、诊断信息模块3、治疗信息模块4,信息采集系统1后进行并发症类型分类模块5,并将其保存到初级储存7。
本发明实施例提供的检测信息模块2后继续诊断信息模块3,诊断信息模块3后统计治疗信息模块4。
本发明实施例提供的初级储存7后可以通过其他信息修订模块6进行修订。
本发明实施例提供的初级储存7后通过网络模块8将信息传输到大数据平台9。
如图3所示,本发明实施例提供的基于大数据的上颈椎手术早期并发症信息采集方法,具备包括以下步骤:
s101:采用肖维涅算法对上颈椎手术病人的检测信息、诊断信息和治疗信息进行剔除误差数的信息收集;
s102:采用朴素贝叶斯分类算法对各种并发症的病人信息进行分类,统计,将信息进行保存;
s103:对病人的其他信息进行补充修改,采用神经网络方法对信息进行暂时的校正储存;
s104:将颈椎手术的早期并发症信息上传到大数据平台。
步骤s101中,本发明实施例提供的采用肖维涅算法将上颈椎手术病人的检测信息、诊断信息和治疗信息的误差信息进行剔除,有利于采集准确的病人信息,保证后续工作的准确进行;具体算法为:
利用数据样本集合s0={x0,x1,…,xn},n个样本数据中含有m个误差数据样本
点,f0(x)是反映这组数据样本基本特征的函数,如下:
式中:n是一组数据的个体数;
di=|xi-f(xi)|
用来衡量样本点数据xi偏离函数关系的程度,di越大,样本点成为误差数据的可能性越大;对n个数据求di最大值;
肖维涅算法剔除di值最大的样本点j,建立新的样本集合s1={s0–xj},对剩余的数据进行重复运算,数据满足运算终止条件时,剔除的m个样本点就是误差数据。
步骤s102中,本发明实施例提供的采用朴素贝叶斯分类算法,提高分类速度及提升分类效果,对各种并发症的病人信息进行准确快速的分类,提高工作效率;具体算法为:
设d是训练对象与其相关联的类标号的集合;每个对象用一个n维属性向量x={x1,x2…xn}表示,描述n个属性a1,a2…an的值;假定原始集合基于n维属性共划分为m个类c1,c2…cm,计算每个类对x的后验概率,并将对象x归属于具有最高后验概率的类;后验概率p(ci|x)的计算公式为:
由于p(ci|x)的计算开销较大,进行类条件独立的假定,给定向量的类标号,并假定属性值有条件的相互独立;p(xi|c)的计算公式为:
其中,p(x1|ci)p(x2|ci)…p(xn|cn)可以容易地由训练对象求算,xk表示x在属性ak上的值;对每个类别ci计算p(x|ci)p(ci);当p(x|ci)p(ci)>p(x|cj)p(cj),1≤j≤m,j≠i成立时,x属于类ci。
步骤s103中,本发明实施例提供的采用神经网络方法对信息进行暂时的校正储存,根据像元校正后的期望输出,对信息的增益和偏移进行反馈修正,有利于信息被准确、无误的存储,保证调用时的信息质量,神经网络算法的具体过程如下:
(1)输入第k帧信息,对第k帧信息进行修正并输出:
yij=gijxij+oij
式中:xij为探测器单元(i,j)的实际输出值;gij为该单元的增益系数;oij为该单元的偏置系数;yij为该单元校正后的输出;
(2)计算邻域平均值作为(i,j)点的真值:
式中:
(3)计算误差函数:
式中:fij是输出值与期望输出之间的误差,它是增益系数和偏置系数的函数;
(4)采用最速下降法,对每个对象的校正系数进行迭代更新:
式中:α、β为神经网络的学习率;
(5)回到第1步,对第k+1帧进行操作。
本发明的工作原理:
该发明通过信息采集模块1中的检测信息模块2、诊断信息模块3、治疗信息模块4收集病人的信息,通过并发症类型分类模块5,对各种并发症的病人信息进行分类保存,并进行统计,将信息保存到初级储存7,对信息进行暂时的储存,通过其他信息修订模块6进行对病人信息进行补充修改,通过网络模块8将信息上传到大数据平台9。
以上所述仅是对本发明的较佳实施例而已,并非对本发明作任何形式上的限制,凡是依据本发明的技术实质对以上实施例所做的任何简单修改,等同变化与修饰,均属于本发明技术方案的范围内。
- 还没有人留言评论。精彩留言会获得点赞!