基于深度学习的多频段光声无创血糖浓度预测系统的制作方法
本发明涉及血糖无创检测领域,具体是基于深度学习的多频段光声无创血糖浓度预测系统。
背景技术:
最新统计显示中国糖尿病患者约有1.144亿,人数占全球第一。而且随着人民生活水平的不断提高和老年化趋势,糖尿病的发病率呈上升趋势。糖尿病患者由于持续的高糖血症导致了大量的微血管并发症,给患者带来了严重的身心危害,同时给患者家庭和社会带来了沉重的经济负担。然而,由于医学水平发展的有限,目前尚无根治糖尿病的方法,但如果能对血糖进行自我检测,结合多种治疗手段便可以对糖尿病进行相应控制,减缓病情和减少相应并发症的发生。
传统血糖检测要求糖尿病患者定期使用电化学测试条提取血液样本,存在交叉感染、表皮损伤、取血疼痛等不足,限制了血糖检测的频率而直接影响患者的治疗。为了克服有创血糖检测的局限性,无创血糖检测技术得到了快速发展。传统的无创血糖主要集中于非光学检测和光学检测,非光学无创血糖检测主要是初步的可行性实验验证,存在检测的实时性、稳定性、准确性等问题,因此限制了其实际应用。而采用传统的光学方法进行无损血糖检测主要具有以下局限性:葡萄糖在血液中浓度很低,光学系数的微小变化难以检测;血糖与其他体内化合物化学结构类似,易受干扰,影响检测。
光声技术是血糖无创检测领域的新兴技术,相比传统的光学检测方法,该方法具有检测灵敏度高、适合活体组织等优势。但已有的光声光谱无创血糖检测主要集中于单频段的光声信号的研究,无法全面反映血糖水平,导致血糖浓度预测精度不高。因此探究新的测量系统克服单频段的光声信号不能全面反映血糖水平对光声光谱测量的影响来提高精度,实现无创血糖便携、高效的检测具有十分重要的现实意义。
技术实现要素:
本发明的目的是解决现有技术中存在的问题。
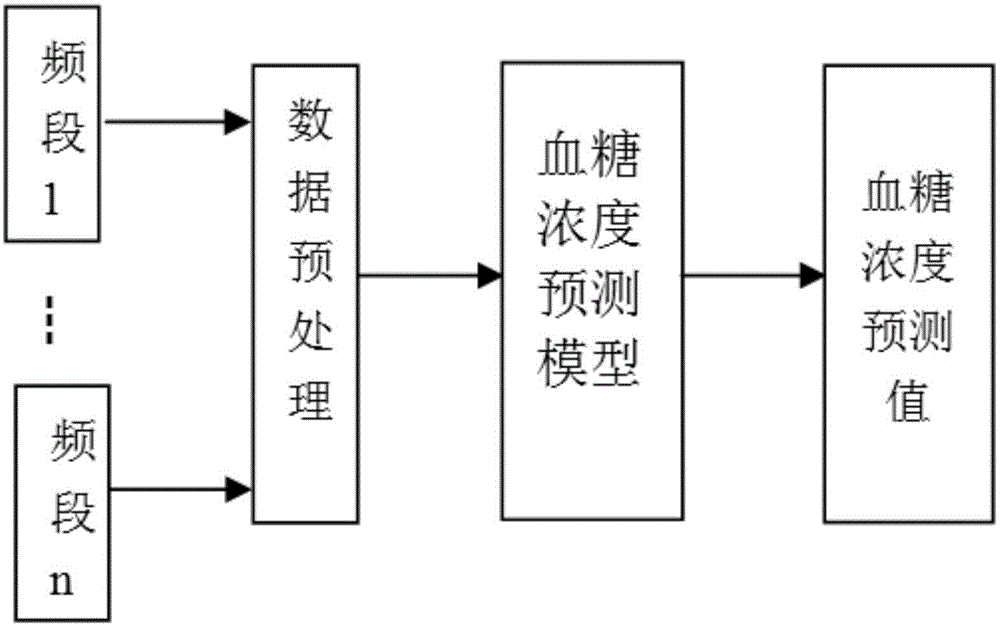
为实现本发明目的而采用的技术方案是这样的,基于深度学习的多频段光声无创血糖浓度预测系统,主要包括激光源、n个不同频段的超声换能器、放大器、数据采集卡和信号处理模块。
激光源向人体皮肤组织发射激光,人体血管内的血糖因吸收光能热膨胀激发产生不同频段的光声信号。
n个不同频段的超声换能器分别获取不同频段的光声信号。
所述超声换能器材料为压电陶瓷。
放大器包括低噪前置放大器和锁相放大器。
低噪前置放大器对超声换能器获取的光声信号进行放大,并将放大的光声信号发送给锁相放大器。
锁相放大器放大光声信号,从而将光声信号与噪声分离,并将光声信号发送给数据采集卡。
数据采集卡采集光声信号的时域信息,并将采集到的数据发送给信号处理模块。
信号处理模块具有基于深度学习的多频段光声无创血糖浓度预测模型。
在信号处理模块中写入基于深度学习的多频段光声无创血糖浓度预测模型的主要步骤如下:
1)利用静脉采血方式获取m个使用者的血糖浓度真实值,记为样本集s=(s1,s2,…,si,…,sm)。si为第i个使用者的血糖浓度真实值。
2)n个不同频段的超声换能器分别采集m个使用者不同频段的光声信号,记为样本集t=(t1,t2,…,ti,…,tm)。ti为第i个使用者在n个频段上的光声信号。ti=(t1i,t2i,…tni)t。tni为第i个测试者第n个超声换能器的光声信号的时域信息。
低噪前置放大器对超声换能器获取的光声信号进行放大,并将放大的光声信号发送给锁相放大器。
锁相放大器放大光声信号,从而将光声信号与噪声分离,并将光声信号发送给数据采集卡。
3)数据采集卡采集光声信号的时域信息。
4)信号处理模块根据时域信息得到样本集t的频域信息,记为样本集f=(f1,f2,…,fi,…,fm)。fi为第i个使用者在n个频段上的光声信号的频域信息。fi=(f1i,f2i,…fni)t。fni为第i个使用者在第n个频段上的光声信号频域信息。
5)根据样本集f和样本集s建立数据集
将数据集
其中fi为基于深度学习的多频段光声无创血糖浓度预测模型的输入。样本集fi中的数据为光声信号频域信息。si为基于深度学习的多频段光声无创血糖浓度预测模型监督训练的标签。样本集si中的数据为血糖浓度真实值。
6)对训练集train和测试集进行归一化处理。
7)利用训练集train对基于深度学习的多频段光声无创血糖浓度预测模型进行监督预训练,主要步骤为:
7.1)设置受限玻尔兹曼机rbm的输入层的节点个数为n,输出层节点个数为1,并建立l个受限玻尔兹曼机rbm。
总频谱维度如下所示:
式中,dim为频谱维数。
7.2)基于l个受限玻尔兹曼机rbm建立一个深信度神经网络dbn。
7.3)确定rbm模型隐藏层的节点个数和学习率,并且对rbm的网络参数集权值和偏置进行初始化。
输入层v0和第一个隐藏层h1构建模型rbm1。
将训练集train中的数据作为输入数据,使用cd算法对模型rbm1进行训练,将重构值和输入值之间的差值作为重建误差。重建误差沿着rbm的权重反向传播,以迭代学习的过程不断反向传播,直到达到设定的误差阈值。训练完成后,rbm1内的参数达到最优。依次对dbn中的l个受限玻尔兹曼机rbm进行无监督训练,使得每个受限玻尔兹曼机rbm的参数达到局部最优。
8)训练好的l个受限玻尔兹曼机rbm与顶层的bp网络构成一个多层bp网络。
利用bp算法对多层bp网络进行有监督训练,并将误差逐层反向传播,微调各层的参数,进一步优化多层bp网络的所有权值和偏置,直至收敛。根据训练获得的权值和偏置建立基于深度学习的多频段光声无创血糖浓度预测模型。
9)将测试集test输入到基于深度学习的多频段光声无创血糖浓度预测模型中,对基于深度学习的多频段光声无创血糖浓度预测模型进行测试。
信号处理模块将光声信号的时域信息转换为频域信息,并将频域信息输入到光声无创血糖浓度预测模型中,从而获取血糖浓度值。
本发明的技术效果是毋庸置疑的。本发明公开的基于深度学习的多频段光声无创血糖浓度预测系统具有以下优势:(1)考虑多个频段数据而非单一的数据源能够克服单频段信号无法全面反应血糖水平的局限性。(2)采用深度学习深度挖掘目标深层特征和精细信息使得血糖浓度预测结果更为精确。
附图说明
图1为基于深度学习的多频段光声无创血糖浓度预测系统理论框图;
图2为基于深度学习的多频段光声无创血糖浓度预测系统框图。
具体实施方式
下面结合实施例对本发明作进一步说明,但不应该理解为本发明上述主题范围仅限于下述实施例。在不脱离本发明上述技术思想的情况下,根据本领域普通技术知识和惯用手段,做出各种替换和变更,均应包括在本发明的保护范围内。
实施例1:
参见图1和图2,基于深度学习的多频段光声无创血糖浓度预测系统,主要包括激光源、n个不同频段的超声换能器、放大器、数据采集卡和信号处理模块。
激光源向人体皮肤组织发射激光,人体血管内的血糖因吸收光能热膨胀激发产生不同频段的光声信号。光声信号是物体吸光后受热膨胀产生的信号。
n个不同频段的超声换能器分别获取不同频段的光声信号。一个超声换能器接收一个频段的光声信息。
所述超声换能器材料为压电陶瓷。
放大器包括低噪前置放大器和锁相放大器。
低噪前置放大器对超声换能器获取的光声信号进行放大,并将放大的光声信号发送给锁相放大器。
锁相放大器放大光声信号,从而将光声信号与噪声分离,提高光声信号信噪比,并将光声信号发送给数据采集卡。
锁相放大器放大光声信号的方法为:设定位于超声换能器接收频段内的参考信号,在接收到带有噪声的光声信号后,放大与参考信号同频率的信号。
锁相放大器(也称为相位检测器)是一种可以从干扰极大的环境(信噪比可低至-60db,甚至更低)中分离出特定载波频率信号的放大器。
数据采集卡采集光声信号的时域信息,并将采集到的数据发送给信号处理模块。
信号处理模块具有基于深度学习的多频段光声无创血糖浓度预测模型。
在信号处理模块中写入基于深度学习的多频段光声无创血糖浓度预测模型的主要步骤如下:
1)利用静脉采血方式获取m个使用者的血糖浓度真实值,记为样本集s=(s1,s2,…,si,…,sm)。si为第i个使用者的血糖浓度真实值。
2)n个不同频段的超声换能器分别采集m个使用者不同频段的光声信号,记为样本集t=(t1,t2,…,ti,…,tm)。ti为第i个使用者在n个频段上的光声信号。ti=(t1i,t2i,…tni)t。tni为第i个测试者第n个超声换能器的光声信号的时域信息。
低噪前置放大器对超声换能器获取的光声信号进行放大,并将放大的光声信号发送给锁相放大器。
锁相放大器放大光声信号,从而将光声信号与噪声分离,提高光声信号信噪比,并将光声信号发送给数据采集卡。
3)数据采集卡采集光声信号的时域信息,,并通过pci接口总线连接到计算机上,计算机通过labview软件将实验中测量的数据导出,导出的数据发送给信号处理模块。
4)信号处理模块根据时域信息得到样本集t的频域信息,记为样本集f=(f1,f2,…,fi,…,fm)。fi为第i个使用者在n个频段上的光声信号的频域信息。fi=(f1i,f2i,…fni)t。fni为第i个使用者在第n个频段上的光声信号频域信息。
5)根据样本集f和样本集s建立数据集
将数据集
其中fi为基于深度学习的多频段光声无创血糖浓度预测模型的输入。数据集fi中的数据为光声信号频域信息。si为基于深度学习的多频段光声无创血糖浓度预测模型监督训练的标签。数据集si中的数据为血糖浓度真实值。
6)对训练集train和测试集进行归一化处理。
7)利用训练集train对基于深度学习的多频段光声无创血糖浓度预测模型进行监督预训练,主要步骤为:
7.1)由于超声换能器的数量为n,因此设置受限玻尔兹曼机rbm(restrictedboltzmannmachine)的输入层的节点个数为n,输出层节点个数为1,并建立l个受限玻尔兹曼机rbm。
总频谱维度如下所示:
式中,dim为频谱维数。j为任意输入层节点,也即对应第j个超声换能器接收的信息。
受限玻尔兹曼机是一个随机神经网络(即当网络的神经元节点被激活时会有随机行为,随机取值)。它包含一层可视层(visiblelayer)和一层隐含层(hiddenlayer)。在同一层的神经元之间不会相互连接,而不在同一层的神经元之间会相互连接。神经元之间的连接是双向的以及对称的。这意味着在网络进行训练以及使用时信息会在两个方向上流动,而且两个方向上的权值是相同的。受限玻尔兹曼机这一层的输出为下一层的输入。
受限玻尔兹曼机每次用无监督学习只训练一层,将其训练结果作为其高一层的输入,用自顶而下的监督算法去调整所有层。
受限玻尔兹曼机rbm共两层。
7.2)基于l个受限玻尔兹曼机rbm建立一个深信度神经网络dbn(deepbeliefnetworks)。深信度神经网络dbn由l个受限玻尔兹曼机rbm叠加而成。
7.3)确定rbm模型隐藏层的节点个数和学习率,并且对rbm的网络参数集权值和偏置进行初始化。
输入层v0和第一个隐藏层h1构建模型rbm1。
将训练集train中的数据作为输入数据,使用cd算法对模型rbm1进行训练,将重构值和输入值之间的差值作为重建误差。重建误差沿着rbm的权重反向传播,以迭代学习的过程不断反向传播,直到达到设定的误差阈值。训练完成后,rbm1内的参数达到最优。依次对dbn中的l个受限玻尔兹曼机rbm进行无监督训练,使得每个受限玻尔兹曼机rbm的参数达到局部最优。
8)训练好的l个受限玻尔兹曼机rbm与顶层的bp网络构成一个多层bp网络。
利用bp算法对多层bp网络进行有监督训练,并将误差逐层反向传播,微调各层的参数,进一步优化多层bp网络的所有权值和偏置,直至收敛。根据训练获得的权值和偏置建立基于深度学习的多频段光声无创血糖浓度预测模型。
9)将测试集test输入到基于深度学习的多频段光声无创血糖浓度预测模型中,对基于深度学习的多频段光声无创血糖浓度预测模型进行测试。
信号处理模块将光声信号输入到光声无创血糖浓度预测模型中,从而获取血糖浓度值。
实施例2:
使用基于深度学习的多频段光声无创血糖浓度预测系统的方法,主要包括以下步骤:
i)将n个不同频段的超声换能器贴置于食指。
ii)激光源产生脉冲激光,照射人体皮肤组织。本实施例设定激光的波长为1064nm,单脉冲能量为15μj。
iii)n个不同频段的超声换能器分别获取不同频段的光声信号后,将光声信号发送给低噪前置放大器和锁相放大器。
iv)低噪前置放大器对超声换能器获取的光声信号进行放大,并将放大的光声信号发送给锁相放大器。
锁相放大器放大光声信号,从而将光声信号与噪声分离,提高光声信号信噪比,并将光声信号发送给数据采集卡。
v)数据采集卡采集光声信号的时域信息,并通过pci接口总线连接到计算机上,计算机通过labview软件将实验中测量的数据导出,导出的数据发送给信号处理模块。
vi)信号处理模块将光声信号输入到光声无创血糖浓度预测模型中,从而获取血糖浓度值。信号处理模块将血糖浓度值发送给上位机,并通过显示屏显示出来。上位机具有显示屏。
所述上位机可以为pc机、智能手环等。
- 还没有人留言评论。精彩留言会获得点赞!