数据分类的方法、装置、存储介质及电子设备与流程
本公开涉及数据分类领域,具体地,涉及一种数据分类的方法、装置、存储介质及电子设备。
背景技术:
目前医学上对于患者身体状况的判断多是基于对各种身体状况指标数据的分析,例如性别、年龄、血红蛋白、微量元素等指标数据,通常情况下,对于与患者相关的目标事件(例如,肾脏病患者在完成本次透析之后,对于该患者本次透析时机的评价事件)的评价多是基于对患者身体状况指标数据的临床观察性研究和医护人员的经验判断,但由于不同患者身体状况各不相同,对应的指标数据也较多,单纯仅通过临床观察和经验判断对目标事件进行评价不仅效率较低,而且准确度也有待提高。
技术实现要素:
本公开的目的是提供一种数据分类的方法、装置、存储介质及电子设备。
第一方面,提供一种数据分类的方法,所述方法包括:获取目标事件在多个数据标签下对应的样本数据;获取预设数据筛选模型,从所述数据标签中确定预先设置的关键数据标签和非关键数据标签,并从所述样本数据中确定所述关键数据标签对应的关键数据以及所述非关键数据标签对应的非关键数据;根据所述关键数据和所述非关键数据通过所述预设数据筛选模型从所述非关键数据标签中确定与所述关键数据标签相关的关联数据标签;获取预设数据分类训练模型,通过所述关键数据和所述关联数据标签对应的非关键数据对所述预设数据分类训练模型进行训练,得到目标数据分类模型;获取所述目标事件中待分类的目标数据,将所述目标数据作为所述目标数据分类模型的输入,得到分类结果。
可选地,所述根据所述关键数据和所述非关键数据通过所述预设数据筛选模型从所述非关键数据标签中确定与所述关键数据标签相关的关联数据标签包括:对所述非关键数据标签进行排列组合处理,得到多个非关键数据标签集,其中,不同的所述非关键数据标签集对应不同的排列组合结果;将所述关键数据标签分别与每个所述非关键数据标签集组合,得到多个数据标签集组;依次将每个数据标签集组中,关键数据标签对应的关键数据和非关健数据标签对应的非关健数据作为预设数据筛选模型的输入,得到输出结果;根据所述输出结果确定每个所述数据标签集组对应的分类正确率;从全部所述数据标签集组中,确定分类正确率最高的目标标签集组,并将所述目标标签集组中的非关键数据标签,确定为所述关联数据标签。
可选地,所述根据输出结果确定每个所述数据标签集组对应的分类正确率包括:获取每个所述数据标签集组对应期望输出结果;根据所述输出结果和所述期望输出结果得到所述分类正确率。
可选地,所述目标数据分类模型包括:
其中,x1,x2,...xn表示所述目标数据分类模型的输入变量,xi表示第i个数据,y表示所述目标分类模型的输出变量,bi、ci、pi、a0表示所述目标数据分类模型的参数,i包括从1到n中的任意一个。
第二方面,提供一种数据分类的装置,所述装置包括:获取模块,用于获取目标事件在多个数据标签下对应的样本数据;确定模块,用于获取预设数据筛选模型,从所述数据标签中确定预先设置的关键数据标签和非关键数据标签,并从所述样本数据中确定所述关键数据标签对应的关键数据以及所述非关键数据标签对应的非关键数据;数据筛选模块,用于根据所述关键数据和所述非关键数据通过所述预设数据筛选模型从所述非关键数据标签中确定与所述关键数据标签相关的关联数据标签;模型训练模块,用于获取预设数据分类训练模型,通过所述关键数据和所述关联数据标签对应的非关键数据对所述预设数据分类训练模型进行训练,得到目标数据分类模型;分类模块,用于获取所述目标事件中待分类的目标数据,将所述目标数据作为所述目标数据分类模型的输入,得到分类结果。
可选地,所述数据筛选模块包括:第一确定子模块,用于对所述非关键数据标签进行排列组合处理,得到多个非关键数据标签集,其中,不同的所述非关键数据标签集对应不同的排列组合结果;第二确定子模块,用于将所述关键数据标签分别与每个所述非关键数据标签集组合,得到多个数据标签集组;第三确定子模块,用于依次将每个数据标签集组中,关键数据标签对应的关键数据和非关健数据标签对应的非关健数据作为预设数据筛选模型的输入,得到输出结果;第四确定子模块,用于根据所述输出结果确定每个所述数据标签集组对应的分类正确率;第五确定子模块,用于从全部所述数据标签集组中,确定分类正确率最高的目标标签集组,并将所述目标标签集组中的非关键数据标签,确定为所述关联数据标签。
可选地,所述第四确定子模块,用于获取每个所述数据标签集组对应期望输出结果;根据所述输出结果和所述期望输出结果得到所述分类正确率。
可选地,所述目标数据分类模型包括:
其中,x1,x2,...xn表示所述目标数据分类模型的输入变量,xi表示第i个数据,y表示所述目标分类模型的输出变量,bi、ci、pi、a0表示所述目标数据分类模型的参数,i包括从1到n中的任意一个。
第三方面,提供一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现本公开第一方面所述方法的步骤。
第四方面,提供一种电子设备,包括:存储器,其上存储有计算机程序;处理器,用于执行所述存储器中的所述计算机程序,以实现本公开第一方面所述方法的步骤。
通过上述技术方案,获取目标事件在多个数据标签下对应的样本数据;获取预设数据筛选模型,从所述数据标签中确定预先设置的关键数据标签和非关键数据标签,并从所述样本数据中确定所述关键数据标签对应的关键数据以及所述非关键数据标签对应的非关键数据;根据所述关键数据和所述非关键数据通过所述预设数据筛选模型从所述非关键数据标签中确定与所述关键数据标签相关的关联数据标签;获取预设数据分类训练模型,通过所述关键数据和所述关联数据标签对应的非关键数据对所述预设数据分类训练模型进行训练,得到目标数据分类模型;获取所述目标事件中待分类的目标数据,将所述目标数据作为所述目标数据分类模型的输入,得到分类结果,这样,可以根据该目标数据通过该目标数据分类模型对目标事件进行评价,在提高数据分析效率的同时,也提高了对目标事件评价的准确率。
本公开的其他特征和优点将在随后的具体实施方式部分予以详细说明。
附图说明
附图是用来提供对本公开的进一步理解,并且构成说明书的一部分,与下面的具体实施方式一起用于解释本公开,但并不构成对本公开的限制。在附图中:
图1是根据一示例性实施例示出的第一种数据分类的方法的流程图;
图2是根据一示例性实施例示出的第二种数据分类的方法的流程图;
图3是根据一示例性实施例示出的第一种数据分类的装置的框图;
图4是根据一示例性实施例示出的第二种数据分类的装置的框图;
图5是根据一示例性实施例示出的一种电子设备的框图。
具体实施方式
以下结合附图对本公开的具体实施方式进行详细说明。应当理解的是,此处所描述的具体实施方式仅用于说明和解释本公开,并不用于限制本公开。
本公开提供一种数据分类的方法、装置、存储介质及电子设备,首先获取目标事件在多个数据标签下对应的样本数据以及预设数据筛选模型,然后通过预设数据筛选模型对目标事件在多个数据标签下对应的样本数据进行筛选,确定影响目标数据分类模型分类结果的目标数据标签,以此提高模型分类结果的准确度,并根据该目标数据标签对应的目标样本数据对预设数据分类训练模型进行训练,得到目标数据分类模型,这样,可以通过该目标数据分类模型对目标事件中待分类的目标数据进行分类,从而根据该目标数据对该目标事件进行评价,在提高数据分析效率的同时,也提高了对目标事件评价的准确率,进一步地,可以为对与患者相关的目标事件进行评价提供技术支撑,降低患者的致残率及死亡率。
下面结合附图对本公开的具体实施方式进行详细说明。
图1是根据一示例性实施例示出的一种数据分类方法的流程图,如图1所示,该方法包括以下步骤:
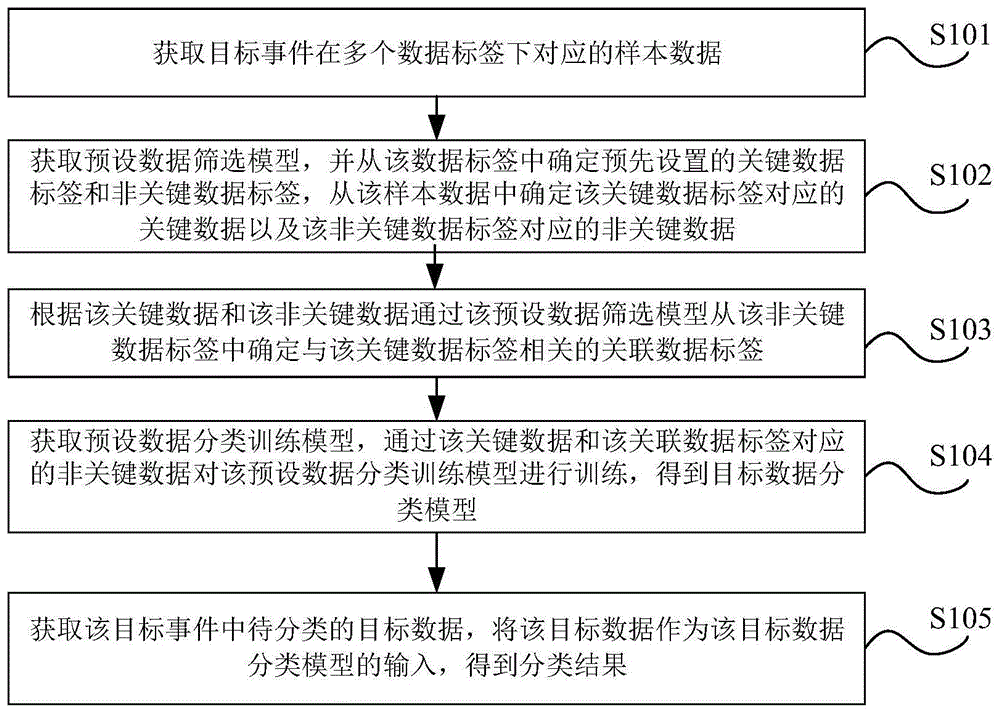
s101,获取目标事件在多个数据标签下对应的样本数据。
其中,该目标事件可以包括肾脏病患者在完成本次透析之后,对于该患者本次透析时机的评价事件、肿瘤患者在完成本次化疗之后,对于该患者本次化疗时机的评价事件等,该样本数据可以包括身体状况指标数据,该数据标签可以用于表示每个样本数据的属性,例如,该数据标签可以包括性别、透析时年龄、首次透析时间、血红蛋白、白蛋白、肌酐、尿素、钾、磷、是否心衰、是否恶心呕吐、是否水肿、是否有糖尿病肾病、是否有尿毒症脑病等标签。
在一种可能的实现方式中,可以在相关数据库中获取到该样本数据,例如,在对尿毒症患者的血液透析时机进行评价时,可以从中国研究数据服务平台(chineseresearchdataservicesplatform,cnrds)中的全国血液透析病例信息登记系统随机选取近三年内的1000例尿毒症患者的身体状况指标数据作为该样本数据。
通常情况下,在根据样本数据对预设模型(如后文提到的预设数据筛选模型,预设数据分类训练模型等)进行训练之前,为排除噪声数据、提高模型训练的效率,并能降低模型计算的复杂度,还需对样本数据进行数据预处理,例如,在该样本数据包括数据标签分别为性别、透析时年龄、首次透析时间、血红蛋白、白蛋白、肌酐、尿素、钾、磷、是否心衰、是否恶心呕吐、是否水肿、是否有糖尿病肾病、是否有尿毒症脑病的数据时,该样本数据中包括两类数据,一类是数值型数据,包括透析时年龄、首次透析时间、血红蛋白、白蛋白、肌酐、尿素、钾、磷,另一类为布尔型数据,包括性别、是否心衰、是否恶心呕吐、是否水肿、是否有糖尿病肾病、是否有尿毒症脑病,此时,可以对样本数据中的数值型数据进行归一化处理(例如,可以将数值型数据均取以e为底的自然对数),可以将布尔型数据赋值为0或1,从而完成样本数据的预处理操作。
s102,获取预设数据筛选模型,从该数据标签中确定预先设置的关键数据标签和非关键数据标签,从该样本数据中确定该关键数据标签对应的关键数据以及该非关键数据标签对应的非关键数据。
其中,该预设数据筛选模型可以包括bp神经网络。
考虑到实际的应用场景中,部分数据标签对应的样本数据是必选的样本数据,例如,在该目标事件为对尿毒症患者血液透析时机的评价事件时,样本数据中数据标签分别为性别、透析时年龄、首次透析时间、血红蛋白、白蛋白、肌酐、尿素对应的样本数据为必选的样本数据,此时,该关键数据标签即为性别、透析时年龄、首次透析时间、血红蛋白、白蛋白、肌酐、尿素,该非关键数据标签即为钾、磷、是否心衰、是否恶心呕吐、是否水肿、是否有糖尿病肾病、是否有尿毒症脑病,在此只是举例说明,本公开对此不作限定,该关键数据标签和该非关键数据标签可以根据不同的应用场景具体设置,本公开对此不作限定。
s103,根据该关键数据和该非关键数据通过该预设数据筛选模型从该非关键数据标签中确定与该关键数据标签相关的关联数据标签。
在本步骤中,可以对该非关键数据标签进行排列组合处理,得到多个非关键数据标签集,其中,不同的该非关键数据标签集对应不同的排列组合结果;将该关键数据标签分别与每个该非关键数据标签集组合,得到多个数据标签集组;依次将每个数据标签集组中,关键数据标签对应的关键数据和非关健数据标签对应的非关健数据作为预设数据筛选模型的输入,得到输出结果;根据该输出结果确定每个该数据标签集组对应的分类正确率;从全部该数据标签集组中,确定分类正确率最高的目标标签集组,并将该目标标签集组中的非关键数据标签,确定为该关联数据标签,另外,在根据该输出结果确定每个该数据标签集组对应的分类正确率时,可以获取每个该数据标签集组对应的期望输出结果,然后根据该输出结果和该期望输出结果得到该分类正确率。
其中,该输出结果可以包括患者的生存时间(例如,可以以月为单位),例如,该输出结果可以为“该患者的生存时间为30个月”,在一种可能的实现方式中,还可以对该患者的生存时间进行分类,此时,该输出结果可以包括该患者的生存时间所在的类别,例如,可以对该患者的生存时间进行二分类,以36个月为临界值,在该患者的生存时间小于36个月时,可以将该患者确定为生存劣质组,在该患者的生存时间大于或者等于36个月时,可以将该患者确定为生存优质组,当然,也可以将该生存时间进行多分类(大于两类),并且该临界值可以根据实际的应用场景具体设置,本公开对此不作限定;该期望输出结果可以包括每个患者的实际生存时间或者该实际生存时间所在的类别,由于样本数据中记录了每个患者的首次透析时间分别对应的实际生存时间,因此,每个患者的实际生存时间或者该实际生存时间所在的类别均是已知的,也就是说,该数据标签集组下每个患者分别对应的该期望输出结果是已知的。
另外,由于每个该数据标签集组中的数据标签可以对应多个患者的样本数据,因此,该输出结果可以包括每个该数据标签集组对应的多个患者中每个患者分别对应的该输出结果,也就是说,在将每个数据标签集组中的数据标签(即为每个该数据标签集组中的关键数据标签和非关健数据标签)对应的样本数据作为该预设数据筛选模型的输入,得到该输出结果时,可以将该数据标签集组对应的多个患者的该样本数据依次输入该预设数据筛选模型,这样,可以得到每个患者分别对应的该输出结果,相应的,每个该数据标签集组对应的该期望输出结果可以包括该数据标签集组下的多个患者中每个患者分别对应的该期望输出结果。
在根据输出结果确定每个该数据标签集组对应的分类正确率时,可以通过获取每个该数据标签集组下的每个患者分别对应的期望输出结果,然后根据每个患者分别对应的该输出结果和该期望输出结果得到该分类正确率,具体地,可以将每个患者的该输出结果与该患者的期望输出结果进行比较,并在根据该比较结果确定该输出结果与对应的期望输出结果相同时,可以确定该输出结果正确,这样,可以通过计算该数据标签集组对应的该输出结果正确的患者的数量与该数据标签集组对应的患者总数的比值,得到该数据标签集组对应的分类正确率。
s104,获取预设数据分类训练模型,通过该关键数据和该关联数据标签对应的非关键数据对该预设数据分类训练模型进行训练,得到目标数据分类模型。
其中,该预设数据分类训练模型可以包括模糊t-s神经网络,该目标数据分类模型可以包括:
其中,x1,x2,...xn表示该目标数据分类模型的输入变量(例如,该输入变量可以为身体状况指标数据),xi表示输入变量中第i个数据,y表示该目标分类模型的输出变量(例如,该输出变量可以为生存时间),bi(i=1,2,...,n)、ci(i=1,2,...,n)、pi(i=1,2,...,n)、a0表示该目标数据分类模型的参数。
在一种可能的实现方式中,可以通过粒子群算法将该关键数据和该关联数据一起作为该预设数据分类训练模型的输入,对该预设数据分类训练模型进行训练,确定分类模型的模型参数,例如,该模型参数可以包括模糊t-s神经网络中前件网络中隶属函数的参数(即为目标数据分类模型中的参数bi、ci)和模糊t-s神经网络中后件网络中线性结构的系数(即为目标数据分类模型中的pi)。
s105,获取该目标事件中待分类的目标数据,将该目标数据作为该目标数据分类模型的输入,得到分类结果。
在该目标事件为肾脏病患者在完成本次透析之后,对于该患者本次透析时机的评价事件时,该目标数据分类模型的输入可以包括某一肾脏病患者身体状况指标数据中的性别、透析时年龄、首次透析时间、血红蛋白、白蛋白、肌酐、尿素等关键标签对应的数据和通过预设数据筛选模型确定的该肾脏病患者身体状况指标数据中的钾、磷、是否水肿、是否有糖尿病肾病、是否有肾脏病脑病等关联数据标签对应的数据,该目标数据分类模型的输出可以包括该肾脏病患者的生存时间(例如可以以月为单位),更进一步地,可以对该肾脏病患者的生存时间进行分类,此时,该分类结果即为该肾脏病患者的生存时间所在的类别,例如,可以对该生存时间进行二分类,以36个月为临界值,在该肾脏病患者的生存时间小于36个月时,可以将该肾脏病患者确定为生存劣质组,在该肾脏病患者的生存时间大于或者等于36个月时,可以将该肾脏病患者确定为生存优质组,当然,也可以将该生存时间进行多分类(大于两类),并且该临界值可以根据实际的应用场景具体设置,本公开对此不作限定。
采用上述方法,可以通过该目标数据分类模型对目标事件中待分类的目标数据进行分类,从而根据该目标数据对该目标事件进行评价,在提高数据分析效率的同时,也提高了对目标事件评价的准确率。
图2是根据一示例性实施例示出的一种数据分类的方法的流程图,在本示例中,以该目标事件为尿毒症患者在完成本次透析之后,对于该患者本次透析时机的评价事件为例进行说明,如图2所示,该方法包括以下步骤:
s201,获取对尿毒症患者血液透析时机的评价事件在多个数据标签下对应的样本数据。
其中,该样本数据可以包括身体状况指标数据,该数据标签可以用于表示每个样本数据的属性,例如,该数据标签可以包括性别、透析时年龄、首次透析时间、血红蛋白、白蛋白、肌酐、尿素、钾、磷、是否心衰、是否恶心呕吐、是否水肿、是否有糖尿病肾病、是否有尿毒症脑病等标签。
在一种可能的实现方式中,可以在相关数据库中获取到该样本数据,例如,在对尿毒症患者的血液透析时机进行评价时,可以从中国研究数据服务平台(chineseresearchdataservicesplatform,cnrds)中的全国血液透析病例信息登记系统随机选取近三年内的1000例尿毒症患者的身体状况指标数据作为该样本数据。
通常情况下,在根据样本数据对预设模型(如后文提到的预设数据筛选模型,预设数据分类训练模型等)进行训练之前,为排除噪声数据、提高模型训练的效率,并能降低模型计算的复杂度,还需对样本数据进行数据预处理,例如,在该样本数据包括数据标签分别为性别、透析时年龄、首次透析时间、血红蛋白、白蛋白、肌酐、尿素、钾、磷、是否心衰、是否恶心呕吐、是否水肿、是否有糖尿病肾病、是否有尿毒症脑病的数据时,该样本数据中包括两类数据,一类是数值型数据,包括透析时年龄、首次透析时间、血红蛋白、白蛋白、肌酐、尿素、钾、磷,另一类为布尔型数据,包括性别、是否心衰、是否恶心呕吐、是否水肿、是否有糖尿病肾病、是否有尿毒症脑病,此时,可以对样本数据中的数值型数据进行归一化处理(例如,可以将数值型数据均取以e为底的自然对数),可以将布尔型数据赋值为0或1,从而完成样本数据的预处理操作。
s202,获取预设数据筛选模型,从该数据标签中确定预先设置的关键数据标签和非关键数据标签,并从该样本数据中确定该关键数据标签对应的关键数据以及该非关键数据标签对应的非关键数据。
其中,该预设数据筛选模型可以包括bp神经网络。
考虑到实际的应用场景中,部分数据标签对应的样本数据是必选的样本数据,例如,在对尿毒症患者血液透析时机的评价事件时,样本数据中数据标签分别为性别、透析时年龄、首次透析时间、血红蛋白、白蛋白、肌酐、尿素对应的样本数据为必选的样本数据,此时,该关键数据标签即为性别、透析时年龄、首次透析时间、血红蛋白、白蛋白、肌酐、尿素,该非关键数据标签即为钾、磷、是否心衰、是否恶心呕吐、是否水肿、是否有糖尿病肾病、是否有尿毒症脑病,在此只是举例说明,本公开对此不作限定,该关键数据标签和该非关键数据标签可以根据不同的应用场景具体设置,本公开对此不作限定。
s203,对该非关键数据标签进行排列组合处理,得到多个非关键数据标签集。
其中,不同的该非关键数据标签集对应不同的排列组合结果。
示例地,以该非关键数据标签包括钾、磷、是否心衰三种标签为例进行说明,对上述三种标签进行排列组合处理后,得到七个非关键数据标签集,分别为(钾)、(磷)、(是否心衰)、(钾,磷)、(钾,是否心衰)、(磷,是否心衰)、(钾,磷,是否心衰),上述示例只是举例说明,本公开对此不作限定。
s204,将该关键数据标签分别与每个该非关键数据标签集组合,得到多个数据标签集组。
其中,不同的数据标签集组包括不同的非关键数据标签集。
示例地,以该关键数据标签包括性别、透析时年龄、首次透析时间、血红蛋白、白蛋白、肌酐、尿素为例进行说明,假设在执行s203后,得到(钾)、(磷)、(是否心衰)、(钾,磷)、(钾,是否心衰)、(磷,是否心衰)、(钾,磷,是否心衰)七个非关键数据标签集,此时,将该关键数据标签与每个该非关键数据标签集组合,可以得到七个数据标签集组,分别为(性别,透析时年龄,首次透析时间,血红蛋白,白蛋白,肌酐,尿素,钾)、(性别,透析时年龄,首次透析时间,血红蛋白,白蛋白,肌酐,尿素,磷)、(性别,透析时年龄,首次透析时间,血红蛋白,白蛋白,肌酐,尿素,是否心衰)、(性别,透析时年龄,首次透析时间,血红蛋白,白蛋白,肌酐,尿素,钾,磷)、(性别,透析时年龄,首次透析时间,血红蛋白,白蛋白,肌酐,尿素,钾,是否心衰)、(性别,透析时年龄,首次透析时间,血红蛋白,白蛋白,肌酐,尿素,磷,是否心衰)以及(性别,透析时年龄,首次透析时间,血红蛋白,白蛋白,肌酐,尿素,钾,磷,是否心衰),上述示例只是举例说明,本公开对此不作限定。
需要说明的是,每个该数据标签集组中的数据标签可以对应多个患者的样本数据,例如,在该样本数据包括患者a、患者b、患者c三个患者的身体状况指标数据时,每个该数据标签集组中的数据标签可以对应a、b、c三个患者的身体状况指标数据。
s205,依次将每个数据标签集组中,关键数据标签对应的关键数据和非关健数据标签对应的非关健数据作为预设数据筛选模型的输入,得到输出结果。
其中,该输出结果可以包括患者的生存时间(例如,可以以月为单位),例如,该输出结果可以为“该患者的生存时间为30个月”,在一种可能的实现方式中,还可以对该患者的生存时间进行分类,此时,该输出结果可以包括该患者的生存时间所在的类别,例如,可以对该生存时间进行二分类,以36个月为临界值,在该患者的生存时间小于36个月时,可以将该患者确定为生存劣质组,在该患者的生存时间大于或者等于36个月时,可以将该患者确定为生存优质组,当然,也可以将该生存时间进行多分类(大于两类),并且该临界值可以根据实际的应用场景具体设置,本公开对此不作限定。
还需说明的是,由于每个该数据标签集组中的数据标签可以对应多个患者的样本数据,因此,该输出结果可以包括每个该数据标签集组对应的多个患者中每个患者分别对应的该输出结果,也就是说,在将每个数据标签集组中的数据标签(即为每个该数据标签集组中的关键数据标签和非关健数据标签)对应的样本数据作为该预设数据筛选模型的输入,得到该输出结果时,可以将该数据标签集组对应的多个患者的该样本数据依次输入该预设数据筛选模型,这样,可以得到每个患者分别对应的该输出结果,例如,在每个该数据标签集组中的数据标签均对应a、b、c三个患者的身体状况指标数据时,在执行本步骤时,可以首先将该数据标签集组中的数据标签对应的患者a的身体状况指标数据输入该预设数据筛选模型,得到患者a对应的输出结果;然后将该数据标签集组中的数据标签对应的患者b的身体状况指标数据输入该预设数据筛选模型,得到患者b对应的输出结果;最后将该数据标签集组中的数据标签对应的患者c的身体状况指标数据输入该预设数据筛选模型,得到患者c对应的输出结果,上述只是举例说明,本公开对此不作限定。
s206,根据该输出结果确定每个该数据标签集组对应的分类正确率。
在本步骤中,可以通过获取每个该数据标签集组下的每个患者分别对应的期望输出结果,然后根据每个患者分别对应的该输出结果和该期望输出结果得到该分类正确率,例如,该期望输出结果可以包括每个患者的实际生存时间或者该实际生存时间所在的类别,由于样本数据中记录了每个患者的首次透析时间分别对应的实际生存时间,因此,每个患者的实际生存时间或者该实际生存时间所在的类别均是已知的,也就是说,该数据标签集组下每个患者分别对应的该期望输出结果是已知的。
由于每个该数据标签集组中的数据标签可以对应多个患者的样本数据,而在执行s205后,可以得到每个患者分别对应的该输出结果,因此,在计算该分类正确率时,可以将每个患者的该输出结果与该患者的期望输出结果进行比较,并在根据比较结果确定该输出结果与对应的期望输出结果相同时,可以确定该输出结果正确,这样,可以通过计算该数据标签集组对应的该输出结果正确的患者的数量与该数据标签集组对应的患者总数的比值,得到该数据标签集组对应的分类正确率。
示例地,以该输出结果为患者生存时间所在的类别为例进行说明,在本示例中,该患者生存时间所在的类别包括生存优质组(生存时间大于或者等于36个月)和生存劣质组(生存时间小于36个月)两类,表1所示的数据标签集组对应a、b、c三个患者的身体状况指标数据,在计算表1所示的数据标签集组的分类正确率时,首先将患者a对应的身体状况指标数据输入该预设数据筛选模型得到患者a对应的输出结果为:患者a的生存时间属于生存优质组,又因为患者a实际生存时间所在的类别是已知的,例如,在患者a实际生存时间为40个月时,可以确定患者a对应的期望输出结果为生存优质组,此时可以确定患者a对应的模型的输出结果与期望输出结果相同,也就是说,该预设数据筛选模型对患者a的生存时间的分类结果正确,同理可以确定该预设数据筛选模型对患者b和患者c的生存时间的分类结果,假设对患者b的生存时间的分类结果错误(例如,患者b实际生存时间属于生存优质组,而将患者b的身体状况指标数据输入该预设数据筛选模型后,得到的输出结果为患者b的生存时间属于生存劣质组时,确定预设数据筛选模型对患者b的生存时间的分类结果错误),对患者c的生存时间的分类结果正确,也就是说,当将表1所示的数据标签集组对应的a、b、c三个患者的身体状况指标数据分别输入该预设数据筛选模型后,根据模型的输出结果可以确定有两个患者的生存时间的分类结果正确,有一个患者的生存时间的分类结果错误,因此,表1所示的数据标签集组对应的分类正确率为2/3,约为66.7%,上述示例只是举例说明,本公开对此不作限定。
s207,从全部该数据标签集组中,确定分类正确率最高的目标标签集组,并将该目标标签集组中的非关键数据标签,确定为关联数据标签。
其中,该关联数据标签可以包括与该关键数据标签相关的数据标签。示例地,以每个该数据标签集组中的数据标签均对应a、b、c三个患者的身体状况指标数据为例进行说明,假设在执行s204后,得到三个数据标签集组,分别为数据标签集组1:(性别,透析时年龄,首次透析时间,血红蛋白,白蛋白,肌酐,尿素,钾)(如表1所示)、数据标签集组2:(性别,透析时年龄,首次透析时间,血红蛋白,白蛋白,肌酐,尿素,磷)(如表2所示),以及数据标签集组3:(性别,透析时年龄,首次透析时间,血红蛋白,白蛋白,肌酐,尿素,钾,磷)(如表3所示),依次将表1所示的数据标签集组1中的数据标签对应的患者a、患者b以及患者c的身体状况指标数据输入该预设数据筛选模型后,得出的分类正确率为66.67%;依次将表2所示的数据标签集组2中的数据标签对应的患者a、患者b以及患者c的身体状况指标数据输入该预设数据筛选模型后,得出的分类正确率为33.33%;依次将表3所示的数据标签集组3中的数据标签对应的患者a、患者b以及患者c的身体状况指标数据输入该预设数据筛选模型后,得出的分类正确率为100%,此时,可以确定该目标标签集组为表3所示的数据标签集组3(性别,透析时年龄,首次透析时间,血红蛋白,白蛋白,肌酐,尿素,钾,磷),进一步地,可以确定该关联数据标签为该目标标签集组中的非关键数据标签钾和磷,上述示例只是举例说明,本公开对此不做限定。
表1
表2
表3s208,获取预设数据分类训练模型,通过该关键数据和该关联数据标签对应的非关键数据对该预设数据分类训练模型进行训练,得到目标数据分类模型。
其中,该目标数据分类模型可以包括:
其中,(x1,x2,...xn)表示该目标数据分类模型的输入变量(例如,该输入变量可以为身体状况指标数据),xi可以表示输入变量(x1,x2,...xn)中第i(i=1,2,...n)个数据,y表示该目标分类模型的输出变量(例如,该输出变量可以为生存时间),bi(i=1,2,...,n)、ci(i=1,2,...,n)、pi(i=1,2,...,n)、a0表示该目标数据分类模型的参数。
在一种可能的实现方式中,可以通过粒子群算法将该关键数据和该关联数据一起作为该预设数据分类训练模型的输入,对该预设数据分类训练模型进行训练,确定分类模型的模型参数,例如,该模型参数可以包括模糊t-s神经网络中前件网络中隶属函数的参数(即为目标数据分类模型中的参数bi、ci)和模糊t-s神经网络中后件网络中线性结构的系数(即为目标数据分类模型中的pi)。
s209,获取该目标事件中待分类的目标数据,将该目标数据作为该目标数据分类模型的输入,得到分类结果。
在该目标事件为尿毒症患者的血液透析时机的评价事件时,该目标数据分类模型的输入可以包括某一尿毒症患者身体状况指标数据中的性别、透析时年龄、首次透析时间、血红蛋白、白蛋白、肌酐、尿素等关键标签对应的数据和通过预设数据筛选模型确定的该尿毒症患者身体状况指标数据中的钾、磷、是否水肿、是否有糖尿病肾病、是否有尿毒症脑病等关联数据标签对应的数据,该目标数据分类模型的输出可以包括该尿毒症患者的生存时间(例如可以以月为单位),更进一步地,可以对该尿毒症患者的生存时间进行分类,此时,该分类结果即为该尿毒症患者的生存时间所在的类别,例如,可以对该生存时间进行二分类,以36个月为临界值,在该尿毒症患者的生存时间小于36个月时,可以将该尿毒症患者确定为生存劣质组,在该尿毒症患者的生存时间大于或者等于36个月时,可以将该尿毒症患者确定为生存优质组,当然,也可以将该生存时间进行多分类(大于两类),本公开对此不作限定。
另外,该临界值也可以根据实际的应用场景具体确定,例如,可以将该临界值设置为12个月或者24个月,也可以是其他临界值,本公开对此不作限定。
需要说明的是,在本示例中,基于机器学习算法(如模糊t-s神经网络)建立了评价透析时机的数学模型,从而为建立尿毒症患者的透析时机标准提供了技术支撑,并将数据挖掘方法与医学研究结合起来,建立了系统的血液透析评价体系,更进一步地,可以降低透析患者的致残率和死亡率,减轻血液透析时的医疗负担。
采用上述方法,可以通过该目标数据分类模型对目标事件中待分类的目标数据进行分类,从而根据该目标数据对该目标事件进行评价,在提高数据分析效率的同时,也提高了对目标事件评价的准确率。
图3是根据一示例性实施例示出的一种数据分类的装置的框图,如图3所示,该装置包括:
获取模块301,用于获取目标事件在多个数据标签下对应的样本数据;
确定模块302,用于获取预设数据筛选模型,从该数据标签中确定预先设置的关键数据标签和非关键数据标签,并从该样本数据中确定该关键数据标签对应的关键数据以及该非关键数据标签对应的非关键数据;
数据筛选模块303,用于根据该关键数据和该非关键数据通过该预设数据筛选模型从该非关键数据标签中确定与该关键数据标签相关的关联数据标签;
模型训练模块304,用于获取预设数据分类训练模型,通过该关键数据和该关联数据标签对应的非关键数据对该预设数据分类训练模型进行训练,得到目标数据分类模型;
分类模块305,用于获取该目标事件中待分类的目标数据,将该目标数据作为该目标数据分类模型的输入,得到分类结果。
可选地,图4是根据图3所示实施例示出的一种数据分类的装置的框图,如图4所示,该数据筛选模块303包括:第一确定子模块3031,用于对该非关键数据标签进行排列组合处理,得到多个非关键数据标签集,其中,不同的该非关键数据标签集对应不同的排列组合结果;第二确定子模块3032,用于将该关键数据标签分别与每个该非关键数据标签集组合,得到多个数据标签集组;第三确定子模块3033,用于依次将每个数据标签集组中,关键数据标签对应的关键数据和非关健数据标签对应的非关健数据作为预设数据筛选模型的输入,得到输出结果;第四确定子模块3034,用于根据该输出结果确定每个该数据标签集组对应的分类正确率;第五确定子模块3035,用于从全部该数据标签集组中,确定分类正确率最高的目标标签集组,并将该目标标签集组中的非关键数据标签,确定为该关联数据标签。
可选地,该第四确定子模块3034,用于获取每个该数据标签集组对应期望输出结果;根据该输出结果和该期望输出结果得到该分类正确率。
可选地,该目标数据分类模型包括:
其中,(x1,x2,...xn)表示该目标数据分类模型的输入变量,xi表示(x1,x2,...xn)中第i(i=1,2,...n)个数据,y表示该目标分类模型的输出变量,bi(i=1,2,...,n)、ci(i=1,2,...,n)、pi(i=1,2,...,n)、a0表示该目标数据分类模型的参数。
关于上述实施例中的装置,其中各个模块执行操作的具体方式已经在有关该方法的实施例中进行了详细描述,此处将不做详细阐述说明。
采用上述装置,可以通过该目标数据分类模型对目标事件中待分类的目标数据进行分类,从而根据该目标数据对该目标事件进行评价,在提高数据分析效率的同时,也提高了对目标事件评价的准确率。
图5是根据一示例性实施例示出的一种电子设备500的框图。如图5所示,该电子设备500可以包括:处理器501,存储器502。该电子设备500还可以包括多媒体组件503,输入/输出(i/o)接口504,以及通信组件505中的一者或多者。
其中,处理器501用于控制该电子设备500的整体操作,以完成上述的数据分类方法中的全部或部分步骤。存储器502用于存储各种类型的数据以支持在该电子设备500的操作,这些数据例如可以包括用于在该电子设备500上操作的任何应用程序或方法的指令,以及应用程序相关的数据,例如联系人数据、收发的消息、图片、音频、视频等等。该存储器502可以由任何类型的易失性或非易失性存储设备或者它们的组合实现,例如静态随机存取存储器(staticrandomaccessmemory,简称sram),电可擦除可编程只读存储器(electricallyerasableprogrammableread-onlymemory,简称eeprom),可擦除可编程只读存储器(erasableprogrammableread-onlymemory,简称eprom),可编程只读存储器(programmableread-onlymemory,简称prom),只读存储器(read-onlymemory,简称rom),磁存储器,快闪存储器,磁盘或光盘。多媒体组件503可以包括屏幕和音频组件。其中屏幕例如可以是触摸屏,音频组件用于输出和/或输入音频信号。例如,音频组件可以包括一个麦克风,麦克风用于接收外部音频信号。所接收的音频信号可以被进一步存储在存储器502或通过通信组件505发送。音频组件还包括至少一个扬声器,用于输出音频信号。i/o接口504为处理器501和其他接口模块之间提供接口,上述其他接口模块可以是键盘,鼠标,按钮等。这些按钮可以是虚拟按钮或者实体按钮。通信组件505用于该电子设备500与其他设备之间进行有线或无线通信。无线通信,例如wi-fi,蓝牙,近场通信(nearfieldcommunication,简称nfc),2g、3g或4g,或它们中的一种或几种的组合,因此相应的该通信组件505可以包括:wi-fi模块,蓝牙模块,nfc模块。
在一示例性实施例中,电子设备500可以被一个或多个应用专用集成电路(applicationspecificintegratedcircuit,简称asic)、数字信号处理器(digitalsignalprocessor,简称dsp)、数字信号处理设备(digitalsignalprocessingdevice,简称dspd)、可编程逻辑器件(programmablelogicdevice,简称pld)、现场可编程门阵列(fieldprogrammablegatearray,简称fpga)、控制器、微控制器、微处理器或其他电子元件实现,用于执行上述的数据分类方法。
在另一示例性实施例中,还提供了一种包括程序指令的计算机可读存储介质,该程序指令被处理器执行时实现上述的数据分类方法的步骤。例如,该计算机可读存储介质可以为上述包括程序指令的存储器502,上述程序指令可由电子设备500的处理器501执行以完成上述的数据分类方法。
以上结合附图详细描述了本公开的优选实施方式,但是,本公开并不限于上述实施方式中的具体细节,在本公开的技术构思范围内,可以对本公开的技术方案进行多种简单变型,这些简单变型均属于本公开的保护范围。
另外需要说明的是,在上述具体实施方式中所描述的各个具体技术特征,在不矛盾的情况下,可以通过任何合适的方式进行组合,为了避免不必要的重复,本公开对各种可能的组合方式不再另行说明。
此外,本公开的各种不同的实施方式之间也可以进行任意组合,只要其不违背本公开的思想,其同样应当视为本公开所公开的内容。
- 还没有人留言评论。精彩留言会获得点赞!