一种基于高斯混合分布的群体体质评估方法与流程
本发明属于体质评估领域,涉及一种体质健康评估方法,具体涉及一种基于高斯混合分布的群体体质评估方法。
背景技术:
体质是指人体的质量,是在遗传性和获得性的基础上表现出来的人体形态结构、生理功能、心理因素的综合及相对稳定的特征。体质健康评估一直以来都是健康研究领域的热点话题。体质评估能用科学的指标和方法评价国民体质与健康状况,进而不断改善和增强国民体质。截至目前,关于体质监测、评估系统的研究,有很多国内的学者做了大量积极有益的探索与实践.也取得了不错的效果。这些已有研究成果大多是通过前期调研来获得专家知识从而得出各种评价指标及其权重系数,然后利用现成的统计公式或曲线拟合技术对个体体质进行评估。而在最近二十年的公开文献中,评估群体体质健康情况则是对个体评估结果的简单统计。
机器学习是人工智能的一个分支,在很多情况下几乎成为人工智能的代名词。机器学习系统用于识别图像中的对象,将语音转录成文本,将新闻条目、帖子或产品与用户的兴趣进行匹配,并选择搜索的相关结果。它也是一种重要的医疗辅助手段,在医疗保健领域具有重要的应用价值。虽然评估模型在其他领域得到了广泛的应用,但复杂数据环境下的群体体质健康评估问题仍然是一个值得而未被深入研究的问题。
技术实现要素:
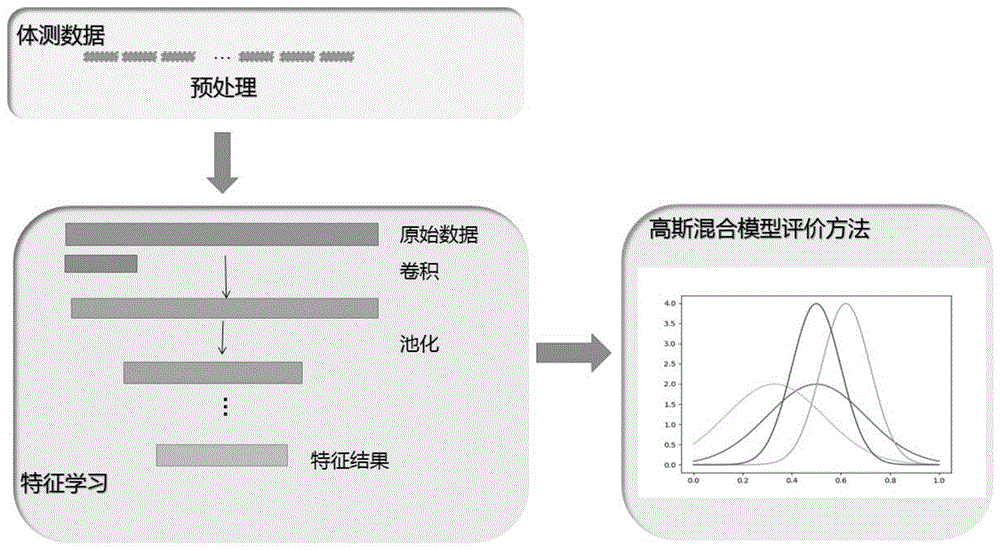
为了解决现群体体质评估问题,本发明提供了一种基于高斯混合分布的群体体质评估方法。该方法的核心思想是应用卷积神经网络无监督地从原始体育测试数据中自动学习特征,并基于高斯混合分布提出群体体质三级评估模型,将学到的特征送入评估模型得出群体体质评估结果。
本发明的目的是通过以下技术方案实现的:
一种基于高斯混合分布的群体体质评估方法,包括如下步骤:
步骤1:将未标记的体育测试数据随机分成若干段作为测试数据与训练数据;
步骤2:对步骤1中的各段测试数据与训练数据进行预处理操作;
步骤3:将步骤2预处理后的训练数据作为卷积神经网络模型的每次输入,使用非监督学习算法提取各组特征数据;
步骤4:拟合步骤3得到的各组特征数据,判断混合分布的个数;
步骤5:根据步骤3得到的各组特征数据,利用em算法计算各混合分布的权重、均值;
步骤6:建立三级评价模型,将步骤4与步骤5的观察和计算结果代入三级评价模型和群体体质评估量化公式中,得出等级和评分结果。
相比于现有技术,本发明具有如下优点:
1、本发明完全独立于个体体质评价结果,不需要依靠个体评价的结果,即得出群体体质评估结果。
2、本发明充分考虑了群体体质分布特征,可用于至各地区、各类别人群体质评估,具有全局性、广泛性的特点。
附图说明
图1是本发明基于高斯混合分布的群体体质评估方法的训练流程图;
图2是本发明中特征提取卷积神经网络图;
图3是本发明基于高斯混合分布的群体体质评估方法的测试数据特征分布图;
图4是本发明中测试数据下的两组高斯混合分布拆分图。
具体实施方式
下面结合附图对本发明的技术方案作进一步的说明,但并不局限于此,凡是对本发明技术方案进行修改或者等同替换,而不脱离本发明技术方案的精神和范围,均应涵盖在本发明的保护范围中。
本发明考虑到群体体质特征分布情况对群体体质评价有着重要的影响,提出了一种基于高斯混合分布的群体体质评估方法。该方法利用机器学习的方法提出主要由特征的学习和特征的评估两部分组成的体质健康的评估模型,旨在独立于个体评估结果,通过分析群体体质测试数据,建立群体体质健康状态评估模型,从而掌握群体健康状态。如图1所示,所述体质评价方法具体包括以下步骤:
步骤1:将未标记的体育测试数据分成若干段作为训练数据。
将未标记的体育测试数据分成若干段作为训练数据,训练数据将作为卷积神经网络的输入,输入至模型中。依据不同的测试项目,将数据分为7个维度,每个维度上随机抽出1800个数据项作为测试数据,剩下的数据作为训练数据。在这些训练数据中,每次随机抽取1800个数据项作为一个训练输入。
步骤2:为各段数据进行预处理操作。
在特征提取之前,我们需要对数据进行规范化处理。在特征提取中,规范化非常重要。这是因为不同样本可能有多个特征,而不同特征的取值尺度不同。如果不经过规范处理,量纲巨大的差异可能会导致整个模型失效。
在本步骤中,我们采用了7个维度的数据,为维持原始数据的分布特征,我们采用0-1规范化方法:
其中,x是输入数据项包括训练数据和测试数据,xmax为这组数据的最大项,xmin为这组数据的最小项。本发明中,max取1,min取0。数据规范化公式即可写为:
最终将所有数据规范至0-1之间。
步骤3:使用非监督学习算法提取特征信息。
本步骤中,使用了一个由两层卷积神经网络组成的模型,将大量的原始信号转化为约简集特征。如图2所示,卷积神经网络包括两个卷积层、两个激活层、两个池化层。卷积层中,卷积核大小设置为3×1,步长设计为1;激活层采用relu激活函数;池化层过滤器设置为2×1,使用最大池化函数。将步骤2的数据作为模型的每次输入,经过卷积层、激活层、池化层后,得到体质数据的特征映射。再结合自编码的思想,通过分析输入数据与重构输入之间的重构误差,反馈调节网络参数,最终可以得到较好的学习特征。步骤3需要进行5000次迭代,当误差趋于零时,即可取出对应的特征列。
步骤4:拟合特征数据,判断高斯混合分布的个数。
本步骤中,需要观察特征数据的混合分布情况。利用python语言中拟合函数拟合出步骤3得到的特征数据,观察数据分布情况,记录此混合分布的分布个数。
步骤5:利用em算法计算各混合分布的权重、均值。
本步骤中,利用步骤3得出的各组特征数据计算出对应组中各混合分布的权重、均值。em算法过程如表1所示:
表1
步骤6:建立三级评价模型,将步骤5的计算结果代入群体体质评估量化公式,得出等级和评分结果。
步骤6.1:
本步骤建立的三级评价模型如表2所示:
表2
其中,k为分模型的个数,αmax为k个分模型中最大的权重,μn与μm分别为最大的两个权重分模型所对应的均值。a(0<a<1)是用来描述权重差的阈值,b(0<b<1)是用来描述权重最大的两个分布的距离阈值。本步骤中设置权重差阈值a=0.3,距离阈值b=0.3。将步骤4与步骤5中观察和计算出来的分布个数、权重、均值代入表2,可得出体质评价等级。
当特征表现为一个单高斯模型或多高斯模型且满足不等式αmax-(1-αmax)>α时,评定为a等级;
当特征表现为多高斯模型且满足不等式组
当特征表现为多高斯模型且满足不等式组
步骤6.2:计算评估结果。
依据分布个数、权重、均值,结合本发明中设计的群体体质评估量化公式可计算出所属群体的体质评价结果。群体体质评估量化公式如下:
公式中,h=max(0,x),其余各项参数与步骤6.1相同。
在实验中,我们利用某高校网站公开的全校(女生)体育测试成绩测试了本方法。并依据中国教育部最新修订的《国家学生体质健康标准》,我们选取bim、肺活量、立定跳远、坐位体前屈、50米跑、800米跑、一分钟仰卧起坐作为七项测试项目,得出各项特征概率分布图,如图3所示。
从此概率分布图可知,特征基本服从高斯分布。但是一些特征的概率分布不是服从单高斯分布,而是服从混合高斯分布,依据步骤6.1中建立的三级评价模型,利用群体体质评估量化公式得出结果,如表3所示。
表3
最后可将bim与肺活量的高斯混合分布图拆分为单高斯分布图,如图4所示。
- 还没有人留言评论。精彩留言会获得点赞!