一种基于代谢组学的中药四气判别方法与流程
本发明涉及中医药理论现代化研究领域,更具体的,涉及一种基于代谢组学的中药四气判别方法。
背景技术:
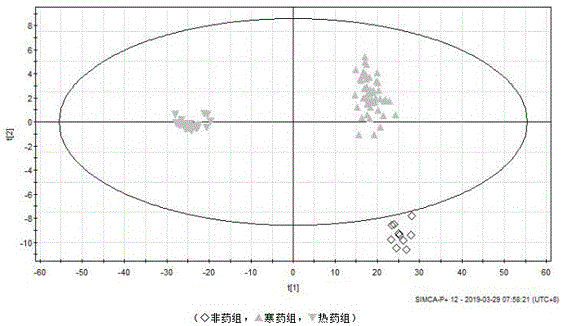
:中药“四气”即寒、热、温、凉,又称中药四性,是中药药性理论的重要组成部分,加强对中药四性的研究对于建立符合现代科学认知规律的中药药性表征体系及其规范标准具有重要意义。其研究成果不仅可为临床用药和实验研究提供理论指导,而且在促进中药新资源的开发利用、保持中医药特色与优势、提高中医药临床疗效以及中医药及其理论的现代化都有着极其重要的意义。中药药性是药物对机体影响的不同生物学效应。始于药物对正常人体的作用,“神农尝百草,一日遇七十毒”“尽知其平、毒、寒、温之性”。本质上来讲表现为寒、热两种属性。神农本草经记载:药有寒热温凉四气…,疗热以寒,疗寒以热。现代中医药理论研究认为凡是能减轻或消除热证的药物,一般属于寒性或凉性,凡是能减轻或消除寒证的药物一般属于热性或温性。可见对药物寒热属性从药物作用于人体所获得不同疗效的总结,即从药物的不同生物学效应来定义药物的寒热属性的。现有中药四气的判别方法是基于药物对人体的作用,结合医生掌握的医学知识,由医生主观判断。研究方法具有主观性的特点。随着现代中药的发展,中药四气的研究从两个方面阐述:一方面是中药的角度,通过对中药的物质构成解析,发现具有相同药性的药物在物质构成方面的同一性;另一方面应用现代药理学方法,依据能量代谢、中枢神经、植物神经、内分泌等相关指标,分析药物的属性,判断药物药性。从中药物质构成的方法研究中药的四气理论,不符合中药四气来源于生物效应的特点,后一种方法符合中药四气理论,但是研究基于还原论的研究思路,使四气研究走向片面化,碎片化,不符合中医整体观。两种方法判断中药四气都存在一定的不足。技术实现要素:为了克服现有技术的缺陷,本发明制备出了一种避免了传统方法以生物效应人工判别的主观判断错误,指标更全面,判断结果更准确,构建中药四气的判别模型的基于代谢组学的中药四气判别方法。为达此目的,本发明采用以下技术方案:本发明提供的基于代谢组学的中药四气判别方法,按照如下步骤进行:s1数据采集:以代谢组学方法采集寒药性中药样本、热药性中药样本及非药性中药样本,分别经预处理、使用高通量设备采集大鼠体液中代谢物后,获取各自代谢物与代谢物丰度值为一组的代谢物组数据;s2建立提取变量模板:对上述的代谢物组数据进行峰识别及峰对齐处理,获得提取变量模板;s3数据预处理:依次将上述的提取变量模板及数据匹配程序导入数据处理软件,运行并导出处理数据,得对应药性的导出数据;s4构建药性判别模型:以代谢物为变量,代谢物丰度为数据值,样品编号为观察变量,构建包括非药组、寒药组、热药组数据二维矩阵,该矩阵以代谢物名称或质荷比为变量,以上述二维矩阵数据为基础,基于pls-da(偏最小二乘法)原理,构建药性判别模型;s5药性判别模型有效性分析:使用cv-anova(交叉验证-方差分析)的方法,分析模型的有效性;s6待测样品药性检测并判别:以已知药性药品为待测样品,采集其代谢组数据,基于s4步骤建立模型,基于判断结果和药物已知药性,检验模型的预测能力。在本发明较佳的技术方案中,在所述步骤s1中,所述预处理包含以下步骤:a首次离心:将中药样本置于低温高速离心机中进行首次离心,静置后得离心后中药样本的上清液;b醇化:取步骤a中的上清液置于ep管中,向其中加入酸化剂,混匀,得混匀样本;c静置:将上述混匀样本置于4℃恒温冰箱中静置3~5h,得静置样本;d再离心:将上述静置样本置于低温高速离心机中进行再离心,取离心后的静置样本即完成所述预处理的样本。在本发明较佳的技术方案中,在所述步骤a和步骤d中,离心条件为:温度4℃,离心力12000xg~15000xg,时间5~10min。在本发明较佳的技术方案中,在所述步骤b中,所述酸化剂为甲醇或者乙腈,且所述甲醇或者所述乙腈的体积最多为取用所述上清液的体积3倍。在本发明较佳的技术方案中,其特征在于,在所述步骤b中,所述混匀所使用的仪器为旋涡混匀器。在本发明较佳的技术方案中,在步骤s1中,采用高通量快速检测技术,所述高通量快速检测技术中使用的检测仪器选自液质联用仪、气质联用仪、核磁共振仪之一。在本发明较佳的技术方案中,在所述步骤s3和步骤s4之间,还包括步骤s31归一化处理:将非药性中药样本数据、热药性中药样本数据与寒药性中药样本数据经归一化处理后,其数值范围是[0,1]。在本发明较佳的技术方案中,在步骤s3中,数据匹配程序的判断方法为:识别寒药性的中药样本数据和热药性的中药样本数据的质荷比,并分别与非药性的中药样本数据质荷比比较,当与非药性的中药样本数据的质荷比差不大于0.4时,将寒药性的中药样本数据与热药性的中药样本数据质荷比各自对应的相对丰度值改为非药性的中药样本数据质荷比所对应的相对丰度值。在本发明较佳的技术方案中,在步骤s5和步骤s6之间还包括,s51删除奇异样本,使用主成分分析法删除奇异样本;其中,奇异样本是指在主成分得分图中的hotellingt2(检验和多元方差分析)检验的置信度不超过95%的数据。在本发明较佳的技术方案中,在步骤s6中,已知药性样品的样本数不低于10个,若f检验标准f大于1,且p小于0.05,则判别模型有效。本发明的有益效果为:本发明提供的基于代谢组学的中药四气判别方法,代谢组学与其他组学技术(基因组、蛋白组等)比较,基因、蛋白反应环境影响下可能发生的生物效应,样品代谢组学反应环境影响下的已经发生的生物效应,基于已发生的生物效应,与中医传统的药性判别原则一致;现代药理学依据传统方法,从药物对中枢神经系统、自主神经系统、能量代谢等单或多指标的影响判断药性,不符合中医整体系统的研究思路,不能反映药性的科学内涵。本实验数据来源于代谢组学数据,结合模式识别技术,应用偏最小二乘法,创建中药四气判别模式。研究思路符合中医整体论要求,方法具有客观性。本方法减少了人为因素带来的误差,指标更全面,判断结果更准确。传统方法以生物效应人工判别,本方法以代谢组数据表征生物效应,基于偏最小二乘法判别分析,构建中药四气的判别模型,为中药、及其复方药性判别提供科学方法,创新中药药性的判别分析方法。附图说明图1示出的是药性判别模式得分散点图;图2示出的是寒药测试样本得分散点图;图3示出的是热药测试样本得分散点图。具体实施方式下面结合具体实施方式来进一步说明本发明的技术方案(以基于lc-ms-ms(气相-质谱-质谱联用)的尿液代谢组学为例)。代谢组学是一种系统生物学方法,通过对代谢产物的检测分析,反应生物体的生理病理变化,是生物效应的一种表现形式。1实验材料1.1药材:根据药材药性明确,具有代表性的原则选择附子,干姜,肉桂,花椒,高良姜,吴茱萸这6味典型热药,黄连、黄柏、栀子、龙胆草、苦参、黄芩这6味典型寒性中药,药材均由北京鹤元堂科技股份有限公司提供,产品批号:200610003,药材产地、性味、剂量信息如表1。依据中国药典(2015版)临床最大剂量按照人于大鼠体表面积比换算来制备水提液。表1药材信息及给药剂量序号热药剂量g/kg序号寒药剂量g/kg1附子1.351苦参0.812干姜0.92栀子0.93高良姜0.543龙胆0.544花椒0.544黄芩0.95肉桂0.455黄连0.456吴茱萸0.456黄柏1.081.2实验动物:sd雄性大鼠,体重(220±20)g,江西中医学院动物中心提供(许可证号:scxk(赣)2006-0001)。1.3实验仪器及试剂:sigma3-18k低温高速离心机(sartorius,germany),agilent12006410triplequadrupole质谱仪(agilenttechnologies,usa),代谢笼,电子分析天平(sartorius,germany),移液枪(finpeppte,france),水为去离子水,甲酸(fluka,usa),乙腈(td,usa),甲醇(色谱醇,山东禹王),其他试剂均为分析纯。1.4数据处理软件:simca-p12.0软件包(umetricsab,sweden),sqlserver(microsoft,usa)。2研究方法2.1药材水提液的制备药材水提液制备具体步骤:称取定量药材加入10倍水,浸泡1h,回流提取,保持微沸1.5h(附子2h),过滤收集滤液;药渣中加入8倍量水进行二次提取,保持微沸1h,过滤收集滤液,合并两次滤液,减压浓缩至所需浓度,-20℃放置备用。2.2动物分组与给药2.2.1分组130只sd大鼠购买至本实验室动物房后,自由饮水,适应实验室条件一周。随机分为13组,即非药组(对照)、附子组、干姜组、高良姜组、花椒组、肉桂组、吴茱萸组,黄连组、黄柏组、栀子组、龙胆草组、苦参组、黄芩组,每组10只。2.2.2给药具体如下:将适应实验条件一周后的大鼠,分别于第0,1,8,15,22,29天(以第1天开始给药计,给药的第1天向前推一天为第0天)早晨9:00将其放置代谢笼,14:00开始给药(第0天给蒸馏水),不同组别大鼠按表1剂量给予相应水提液,其余各非药组按10ml•kg-1给等量蒸馏水,连续给药30天,控制环境温度23±2℃,光照时间12h,给药期间大鼠自由进食,饮水。2.3样品采集所述样品是大鼠的代谢产物尿液样品,其采集并初步处理方法具体如下:收集每次给药后3小时内的尿样,低温高速离心机中进行首次离心,去除杂质,取上清液,-80℃保存,并根据样品所含的中药药性类别,将样品划分为寒药性、热药性以及非药性。2.4样品处理分别对寒药组、热药组、非药组大鼠尿液进行预处理,预处理目的是去除蛋白,得到各类别对应的中药样本的上清液。预处理按照如下步骤进行:低温解冻,置低温高速离心机离心。离心条件:温度4℃,离心力12000xg,离心时间10min。取上清液0.5ml置1.5mlep管中,加入甲醇0.5ml,漩涡混合器混匀1min。甲醇在此处的作用是酸化,利于后续步骤的进行。将混匀后样品置4℃恒温冰箱中静置3h沉淀蛋白,低温离心,离心条件:温度4℃,离心力15000xg,离心时间5min,取上清液,进样。需要进行说明的是,此处将离心力调整在12000xg~15000xg之间,离心时间5~10min之间,且两者在实验中的参数设置呈反比趋势,此时离心力和离心时间对实验结果的影响并不明显,故此处省略其他参数的实施例。2.5s1数据采集采用ls-ms-ms联用仪分别对寒药性的中药样本的上清液、热药性的中药样本的上清液、非药性的中药样本的上清液进行数据分析,并使用aglientmasshunter进行峰识别,得到各类别对应的中药样本的样本数据,各类别对应的中药样本的样本数据均为分子质荷比与分子质荷比的相对丰度。具体参数及操作步骤如下:色谱柱:agilentzorbaxeclipsesb-c18(4.6mm×150mm,5μm);流动相:乙腈(a)、0.1%甲酸(b);流速:0.4ml•min-1;进样量:3μl;柱温:35℃;运行20min;梯度洗脱条件如下:0~6min(b:100%),8min(b:30%),12~14min(b:10%),14.1~15min(b:10%),后运行5min。esi正离子模式;毛细管电压:4000v;雾化器压力:275.8kpa;干燥气流速:10l•min-1,干燥气温度:350℃,全扫描监测得尿液总离子流图(totalionchromatogram,tic),提取质谱信息,得到尿液样品所含物质的质荷比及其的相对丰度。2.6s2建立变量提取模板运行sqlserver软件,并导入基于步骤s1的样本数据,得提取变量模板,提取变量模板以.xls格式保存。2.7s3数据预处理运行基于步骤s2的sqlserver软件,并依次逐一导入基于步骤s2所得的提取变量模板以及数据匹配程序,再次运行,并导出数据,得各自药性对应的导出数据;该数据匹配程序的判断方法为:识别寒药性的中药样本数据和热药性的中药样本数据的质荷比,并分别与非药性的中药样本数据质荷比比较,当与非药性的中药样本数据的质荷比差不大于0.4时,将寒药性的中药样本数据与热药性的中药样本数据质荷比各自对应的相对丰度值改为非药性的中药样本数据质荷比所对应的相对丰度值。2.8s4构建药性判别模型:以代谢物为变量,代谢物丰度为数据值,样品编号为观察变量,构建包括非药组、寒药组、热药组数据二维矩阵,该矩阵以代谢物名称或质荷比为变量,以上述二维矩阵数据为基础,基于pls-da原理,构建药性判别模型。二维矩阵具体构建方法为:不同时间点数据表按药材类别放入12个文件夹,每个数据表均含有相应时间点的非药组数据和给药组数据,共20样本,831种物质,组成831个变量,20个观察值的二维矩阵。变量以m/z值命名,观察值以时间点和样品的组别命名。基于上述药性判别模型,得到所述pls-da模型中的参数为:r2x=0.799、r2y=0.973、q2=0.934,其中r2x反映模型对变量x解释能力,r2y反映模型对变量y解释能力,q2反映模型拟合程度,一般要求q2>0.5,r2x>70%,r2y>80%,说明建模过程中数据损失少,不存在严重失真现象。即拟合后的模型能解释79.9%的x变量,97.3%的y变量。2.9s5药性判别模型有效性分析:使用cv-anova(交叉验证-方差分析)的方法,分析模型的有效性;总共寒药数据6组,热药数据6组,分别随机抽寒药数据5组,热药数据5组,观察模型的预测能力,剩余各1组以作药性判别模型有效性分析用。向药性判别模型中导入已知药性测试样本,观察测试样本在模型中的位置,若位置与药性判别模型中的任一数据重合,则该数据所属药性与测试样本药性相同,且已知测试样本的样本数不低于10个,若f检验标准f大于1,且p小于0.05,则判别模型有效。cv-anova,即交叉有效性预测残差分析,是偏最小二乘法(pls)、正交偏最小二乘法(opls)、偏最小二乘法判别分析(pls-da)模型有效性的诊断方法。主要通过补充一个或多个应变量(y)方式,研究因变量(x)与应变量(y)之间的关系。这种方法是基于预测残差的方差分析,进而对模型有效性进行评价,并且只需要合理独立的数据和方差估计就可以对模型进行评价,从而避免了对模型有效性参数额外计算。计算方法较为简洁。方差分析用于比较模型的残差,对两种模型进行评价。这两种模型表达公式:然后根据平方和ss(d)和ss(e)进行方差分析(anova),但是平方和ss(d)和ss(e)不是独立的,他们有共同的应变量数据(y)。此时,我们就可以分析当前模型的预测残差是否显著的小于整体均数方差。图1示出的是药性判别模型,其中,横坐标t[1]方向表示组间差异,纵坐标t[2]方向反映组内个体差异(后同),寒药组样本相对分散,热药组样本点相对集中,说明选取寒药药性相差较大,热药组药材药性相近。寒药组、热药组、非药组样本点无交叉现象,说明三组药性存在明显差异,因此可以使用此模型预测其他药物药性。2.10s6待测样品药性检测并判别:以已知药性药品为待测样品,采集其代谢组数据,基于s4步骤建立模型,基于判断结果和药物已知药性,检验模型的预测能力。其中,已知药性测试样本是基于留一法原理,分别从不同药性药物的样本中随机留存一个样本,作为已知药性样本测试模型有效性。2.10.1寒药测试样本药性判别结果(以黄连为例)表2黄连药性测试结果表备注:1中性;2寒性;3热性黄连测试样本10个,图2可以看出黄连测试样本与寒性模式药物样本点重合,初步判断黄连药性数据寒性。具体测试结果见表2,表中可以看出黄连10个样品具被模型判断为寒性,药典记录黄连为寒性中药,研究结果与药典记录黄连药性一致。2.10.2热药测试样本判别分析结果(以附子为例)表3附子药性测试结果表备注:1中性;2寒性;3热性;附子测试样本10个,图3可以看出附子测试样本与热性模式药物样本点重合,初步判断附子药性数据热性。具体测试结果见表3,表中可以看出附子10个样品俱被模型判断为热性,药典记录附子为热性中药,研究结果与药典记录附子药性一致。结果表明模型对热药具有良好的预测能力。进一步的,在步骤s3和步骤s4之间,还有步骤s31归一化处理。样品中不同的代谢产物浓度差别较大,浓度高的物质在数据模型中的权重大,这样不利于低浓度物质的发现,因此在模型拟合前应对数据做归一化处理,以利于发现低浓度生物标记物,提高模拟拟合。非药性的样本数据、热药性的样本数据与寒药性的样本数据经归一化处理后,样本数据的数值范围是[0,1]。其归一化函数为:其中,p为需要进一步处理的数据,pn为归一化后的样本数据,minp为p中的最小值,maxp为p中的最大值。进一步的,在步骤s5和步骤s6之间还包括,s51删除奇异样本,使用主成分分析法删除奇异样本。主成份分析是最经典的基于线性分类的分类系统。这个分类系统的最大特点就是利用线性拟合的思路把分布在多个维度的高维数据投射到几个轴上。如果每个样本只有两个数据变量,这种拟合就是a1x1+a2x2=p,其中x1和x2分别是样本的两个变量,而a1和a2则被称为载荷量,计算出的p值就被称为主成份。实际上,当一个样本只有两个变量的时候,主成份分析本质上就是做一个线性回归。公式a1x1+a2x2=p本质上就是一条直线。主成分分析的函数为:a1x1+a2x2+…+anxn=pc1b1x1+b2x2+…+bnxn=pc2其中,n为样本个数,pc1称为第一主成份,pc2称为第二主成份。主成分分析是一种多变量数据分析方法,前两主成分得分散点图可以发现隐藏在数据中的样本变化趋势,聚类特征,差异样本点等信息。在主成分得分散点图中,椭圆表示hotellingt2检验的可信区间,在椭圆外的样本点表示经hotellingt2检验与其他样本点具有显著差异,可以将此样本点视为奇异值。进一步的,所述大鼠体液除了尿液还可以是血清或者血浆,其除采集样品方法及初处理与尿液处理方法不同外,其他实验方法均与尿液实验方法一致,血清与血浆采集与处理方法分别如下:连续给药30天后,动物麻醉处死,心脏或腹主动脉采血,静置或抗凝处理后,离心,收集血清或血浆,取0.5ml放置ep管。血清处理方法及初步处理:血液样本采集后,置4摄氏度冰箱静置12小时,3000转,4摄氏度离心,10分钟,取上清液,放-80℃冰箱冻存,并根据样品所含的中药药性类别,将样品划分为寒药性、热药性以及非药性。血浆处理方法及初步处理:血液样本采集后,放置含抗凝剂样品采集管,置4摄氏度冰箱静置2小时,3000转,4摄氏度离心,10分钟,取上清液,放-80℃冰箱冻存,并根据样品所含的中药药性类别,将样品划分为寒药性、热药性以及非药性。本发明是通过优选实施例进行描述的,本领域技术人员知悉,在不脱离本发明的精神和范围的情况下,可以对这些特征和实施例进行各种改变或等效替换。本发明不受此处所公开的具体实施例的限制,其他落入本申请的权利要求内的实施例都属于本发明保护的范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1