牙区辨识系统的制作方法
1.本发明是关于一种辨识系统,特别是关于一种牙区辨识系统。
背景技术:
2.传统上,牙医需要将齿镜置入患者的口腔内,通过齿镜以观看患者部分口腔,然而,即使智能齿镜搭载镜头,由于镜头的视野线制,也只能拍摄到部分牙齿,且人类左右侧牙齿接近对称,因此一般人难以判断齿镜与实际牙齿位置的相应区域,需要牙医的经验去判断齿镜上的镜头目前放置在患者哪一颗牙齿。
3.因此,如何自动且精准的辨识出智能齿镜所拍摄到的实际牙齿位置,仍为本领域所需改进的问题之一。
技术实现要素:
4.为了解决上述的问题,本公开内容的一个态样提供了一种牙区辨识系统,其包含电子装置以及运算装置。电子装置包含第一摄影机。第一摄影机用以拍摄多个牙齿影像。运算装置包含第二摄影机以及处理器。第二摄影机用以拍摄用户影像。处理器用以接收这些牙齿影像,比对这些牙齿影像中每个像素点的对应位置,以产生深度图,将这些牙齿影像、深度图及多个第一牙齿区域标识输入牙齿深度学习模型,牙齿深度学习模型输出与这些第一牙齿区域标识数量相同的多个深度学习机率值,处理器将用户照片及多个第二牙齿区域标识输入用户影像深度学习模型,用户影像深度学习模型输出左区域机率值及右区域机率值,处理器将这些深度学习机率值、左区域机率值与右区域机率值视为多个特征值,将这些特征值及多个第三牙齿区域标识输入多层感知机(multi-layer perceptron classifier),多层感知机输出这些牙齿影像所对应的牙齿位置机率。
5.本公开内容的另一个态样提供了牙区辨识系统,其包含电子装置以及运算装置。电子装置包含第一摄影机以及惯性测量单元(inertial measurement unit,imu)。第一摄影机用以拍摄多个牙齿影像。惯性测量单元用以测量电子装置的姿态信息及运动轨迹。运算装置包含处理器。处理器用以接收这些牙齿影像,比对这些牙齿影像中每个像素点的对应位置,以产生深度图,将这些牙齿影像、深度图及多个第一牙齿区域标识输入牙齿深度学习模型,牙齿深度学习模型输出与这些第一牙齿区域标识数量相同的多个深度学习机率值,处理器将姿态信息、运动轨迹及多个第二牙齿区域标识输入imu动作深度学习模型,imu动作深度学习模型输出多个象限机率值,将这些深度学习机率值及这些象限机率值视为多个特征值,处理器将这些特征值及多个第三牙齿区域标识输入多层感知机,多层感知机输出这些牙齿影像所对应的牙齿位置机率。
6.本发明所示的牙区辨识系统,应用牙齿区域标识及牙齿深度学习模型,以达到自动并准确判断牙齿影像对应实际牙齿位置的效果。
附图说明
7.图1a是依照本发明的实施例描绘一种牙区辨识系统的示意图。
8.图1b是根据本发明的实施例描绘一种牙区辨识系统的方块图。
9.图2是根据本发明的实施例描绘一种牙区辨识方法的流程图。
10.图3a~3b是根据本发明的实施例描绘一种牙区表示位置的示意图。
11.图4是根据本发明的实施例描绘一种应用牙齿深度学习模型以取得深度学习机率值的方法的示意图。
12.图5是根据本发明的实施例描绘一种应用用户影像深度学习模型以取得左区域机率值及右区域机率值的方法的示意图。
13.图6是根据本发明的实施例描绘一种卷积神经网络模型的示意图。
14.图7是根据本发明的实施例描绘一种应用imu动作深度学习模型取得象限机率值的方法的示意图。
15.图8是根据本发明的实施例描绘一种递归神经网络模型的示意图。
16.图9是根据本发明的实施例描绘一种应用多层感知机mlp以推算出牙齿影像所对应的牙齿位置机率的示意图。
17.图10是根据本发明的实施例描绘一种牙区辨识方法的示意图。
18.图11a~11b是根据本发明的实施例描绘一种应用多层感知机mlp模型的示意图。
具体实施方式
19.以下说明是为完成发明的较佳实现方式,其目的在于描述本发明的基本精神,但并不用以限定本发明。实际的发明内容必须参考之后的权利要求范围。
20.必须了解的是,使用在本说明书中的”包含”、”包括”等词,是用以表示存在特定的技术特征、数值、方法步骤、作业处理、元件以及/或组件,但并不排除可加上更多的技术特征、数值、方法步骤、作业处理、元件、组件,或以上的任意组合。
21.在权利要求中使用如”第一”、"第二"、"第三"等词是用来修饰权利要求中的元件,并非用来表示之间具有优先权顺序,先行关系,或者是一个元件先于另一个元件,或者是执行方法步骤时的时间先后顺序,仅用来区别具有相同名字的元件。
22.请一并参照图1a~1b,图1a是依照本发明的实施例描绘一种牙区辨识系统的示意图。图1b是根据本发明的实施例描绘一种牙区辨识系统100的方块图。在实施例中,电子装置110(例如为数字齿镜或其它可用以拍摄口腔内部的装置,以下以数字齿镜作举例)中包含摄影机112及惯性测量单元(inertial measurement unit,imu)114。在实施例中,数字齿镜110还包含光源装置116及传输装置118。在实施例中,用户usr将数字齿镜110放入口腔时,光源装置116用以提供光源,摄影机112拍摄用以口腔中部分牙齿,以获取多张牙齿影像。
23.在实施例中,摄影机112是由至少一个电荷耦合元件(charge coupled device;ccd)或互补式金氧半导体(complementary metal-oxide semiconductor;cmos)感测器所组成。
24.在实施例中,惯性测量单元114是测量物体三轴姿态角(或角速率)以及加速度的装置。惯性测量单元114内可包含三轴的陀螺仪和三个方向的加速度计,来测量物体在三维
空间中的角速度和加速度,并依感测到的角速度和加速度算出物体的移动信息。例如,用户usr将数字齿镜110放入口腔时,惯性测量单元114用以测量数字齿镜110的姿态信息及运动轨迹。
25.在实施例中,光源装置116可以由包含发光二极体的半导体的装置实现。
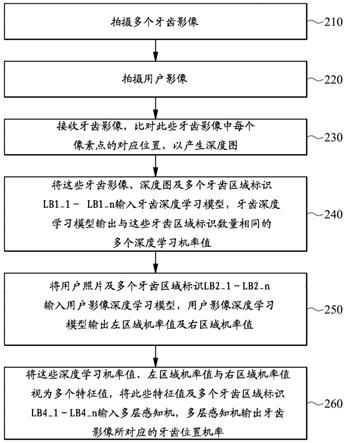
26.在实施例中,传输装置118、128之间可以由有线或无线的方式建立通信连结lk,传输装置118、128可以是蓝牙装置、无线网卡或其它具有通信功能的装置。
27.在实施例中,传输装置118将摄影机112拍摄到的多张牙齿影像通过通信连结lk传送到运算装置120。在实施例中,运算装置120包含处理器122。在实施例中,运算装置120还包含摄影机124。在实施例中,运算装置120还包含显示器126及传输装置128。
28.在实施例中,运算装置120可以是手机、平板、笔记本电脑、台式机或其它具运算功能的装置。
29.在实施例中,处理器122可由集成电路如微控制单元(micro controller)、微处理器(microprocessor)、数字信号处理器(digital signal processor)、专用集成电路(application specific integrated circuit,asic)或逻辑电路来实施。
30.在实施例中,显示器126用以显示运算装置120所接收到的来自摄影机112的牙齿影像。
31.图2是根据本发明的实施例描绘一种牙区辨识方法的流程图200。
32.在步骤210中,摄影机112用以拍摄多个牙齿影像。
33.请参阅图3a~3b,图3a~3b是根据本发明的实施例描绘一种牙区表示位置的示意图。图3a~3b是国际牙科联盟(f
éꢀ
d
éꢀ
ration dentaire internationale,fdi)提出的牙位表示法,为世界通用,也称iso-3950表示法,每颗牙用两位阿拉伯数字表示,第一位表示牙齿所在的象限,将图3a的牙齿位置的右上、左上、左下、右下在恒牙为1、2、3、4,在乳牙为5、6、7、8;第二位表示牙齿的位置:从中门齿到第三臼齿为1~8,其对应表亦可以由图3b所示。一般而言,成人的恒牙约为32颗,例如,摄影机112可能在成人口腔内针对特定的至少一颗牙齿(例如为1~2颗牙齿)进行多次拍摄,以取得多张牙齿影像,依后续步骤辨识这些牙齿影像所对应到图3a~3b中的位置。
34.在步骤220中,摄影机124拍摄用户影像。
35.在实施例中,摄影机124为运算装置120的前镜头(自拍镜头)。当数字齿镜110置入用户usr口腔内时,用户usr或其它手持运算装置120的人员,以摄影机124拍摄用户影像。在实施例中,用户usr可以用摄影机124自拍使用数字齿镜110的情境,以取得用户影像。
36.在步骤230中,处理器122接收牙齿影像,比对这些牙齿影像中每个像素点的对应位置,以产生深度图dp。举例而言,处理器122可通过接收到的多张牙齿影像,利用已知的演算法,如,单视角影像(monocular)、利用双视角影像(binocular)产生深度图。
37.请参阅图4,图4是根据本发明的实施例描绘一种应用牙齿深度学习模型tm以取得深度学习机率值的方法400的示意图。
38.在步骤240中,处理器122将这些牙齿影像、深度图及多个牙齿区域标识lb1_1~lb1_n输入牙齿深度学习模型tm,牙齿深度学习模型tm输出与这些牙齿区域标识数量相同的多个深度学习机率值a1~a16。
39.在实施例中,牙齿影像包含原始影像img_f、r通道阵列影像img_r、g通道阵列影像
img_g、b通道阵列影像img_b及/或深度图dp。在实施例中,牙齿影像可包含多种角度的各组原始影像img_f、r通道阵列影像img_r、g通道阵列影像img_g、b通道阵列影像img_b及/或深度图dp。
40.多个牙齿区域标识lb1_1~lb1_n例如包含所有牙齿的右半部(右上及右下),即16颗牙齿的细部区域的编号,例如将图3a~3b所示的牙位表示法中的牙齿位置21~28、31~38都标上编号,处理器122将牙齿位置21~28、31~38都各自定义一个牙齿区域标识lb1_1~lb1_n,例如牙齿位置21的位置定义为牙齿区域标识lb1_1、牙齿位置22的位置定义为牙齿区域标识lb1_2
…
牙齿位置38定义为牙齿区域标识lb1_16(在此例中,n为16)。此处仅为一例子,此处的对应方式可依据牙区辨识系统100实际实作而调整。
41.在一些实施例中,多个牙齿区域标识lb1_1~lb1_n亦可以是一颗或多颗牙齿的俯视区域、左右侧区域及/或前后侧区域。
42.处理器122将原始影像img_f、r通道阵列影像img_r、g通道阵列影像img_g、b通道阵列影像img_b及/或深度图dp及多个牙齿区域标识lb_1输入牙齿深度学习模型tm,牙齿深度学习模型tm输出与这些牙齿区域标识lb1_1~lb1_n数量相同(例如16个)的多个深度学习机率值a1~a16。换言之,深度学习机率值a1~a16的数量会与牙齿区域标识lb1_1~lb1_n对应,同为16个。
43.在实施例中,牙齿区域标识lb1_1~lb1_n中的每个编号各自对应到一个深度学习机率值a1~a16,例如牙齿编号21的位置对应到深度学习机率值a1、牙齿编号22的位置对应到深度学习机率值a2、牙齿编号23的位置对应到深度学习机率值a3。此处仅为一例子,此处的对应方式可依据牙区辨识系统100实际实作而调整。
44.在实施例中,牙齿深度学习模型tm输出的深度学习机率值a1例如为90%、深度学习机率值a2例如为30%、深度学习机率值a3例如为10%,若在所有深度学习机率值a1~a16中,深度学习机率值a1的值最高,代表这些牙齿影像是深度学习机率值a1所对应的牙齿区域标识lb1_1(例如牙齿编号21的位置)的机率最高。
45.请参阅图5,图5是根据本发明的实施例描绘一种应用用户影像深度学习模型um以取得左区域机率值rs及右区域机率值ls的方法500的示意图。
46.在步骤250中,处理器122将用户照片及多个牙齿区域标识lb2_1~lb2_n输入用户影像深度学习模型um,用户影像深度学习模型输出左区域机率值rs及右区域机率值ls。
47.在实施例中,牙齿区域标识lb2_1~lb2_n例如为2个区域(在此例中,n为2),例如所有牙齿的右半部(右上及右下)为牙齿区域标识lb2_1,所有牙齿的左半部(左上及左下)为牙齿区域标识lb2_n。此处仅为一例子,此处的对应方式可依据牙区辨识系统100实际实作而调整。
48.换言之,图5中用户影像深度学习模型um输出的机率值(左区域机率值rs及右区域机率值ls)的数量会与牙齿区域标识lb2_1~lb2_n对应,同为2个。
49.在实施例中,用户照片可以为多张,这些用户照片包含原始照片usr_f、r通道阵列影像usr_r、g通道阵列影像usr_g及/或b通道阵列影像usr_b。在实施例中,用户照片可包含多种角度的各组原始照片usr_f、r通道阵列影像usr_r、g通道阵列影像usr_g及/或b通道阵列影像usr_b。
50.处理器122将原始照片usr_f、r通道阵列影像usr_r、g通道阵列影像usr_g及/或b
通道阵列影像usr_b输入用户影像深度学习模型um,用户影像深度学习模型um输出左区域机率值rs及右区域机率值ls。
51.在实施例中,当左区域机率值rs大于右区域机率值ls时,代表用户usr使用数字齿镜110拍摄所有牙齿的左半区域较高。当左区域机率值rs小于右区域机率值ls时,代表用户usr使用数字齿镜110拍摄所有牙齿的右半区域较高。
52.在实施例中,牙齿深度学习模型tm及用户影像深度学习模型um各自以卷积神经网络(convolutional neural network,cnn)模型实现。
53.请参阅图6,图6是根据本发明的实施例描绘一种卷积神经网络模型的示意图。卷积神经网络是将至少一张原始影像img_i(例如原始影像img_f、r通道阵列影像img_r、g通道阵列影像img_g、b通道阵列影像img_b、深度图dp、原始照片usr_f、r通道阵列影像usr_r、g通道阵列影像usr_g及/或b通道阵列影像usr_b)进行卷积运算(convolution),使用relu函数去掉负值,更能淬炼出物体的形状,接着进行池化运算(pooling),此处的卷积运算、relu函数运算及池化运算可以是为一组运算,此组运算可以重复复数次,例如在图6中重复两次,以完成特征学习部分,换言之,原始影像img_i输入后,会经过两个卷积层(convolution layer)然后把它进行平坦运算(flatten)之后进入全连结层(fully connected layer)最后就是进入softmax函式转为机率,以分类出结果(例如,深度学习机率值a1~a16或左区域机率值rs及右区域机率值ls)。然而,本领域具通常知识者应能理解,本发明不限于采用cnn模型,只要是可以达到自动分类的其它神经网络模型亦可应用。其中,softmax函数是有限项离散概率分布的梯度对数归一化,为已知演算法,故此处不赘述。
54.请参阅图7,图7是根据本发明的实施例描绘一种应用imu动作深度学习模型im取得象限机率值ur、ul、ll及lr的方法700的示意图。
55.在实施例中,惯性测量单元114用以测量数字齿镜110的姿态信息p1及运动轨迹p2。其中,处理器122将姿态信息p1、运动轨迹p2及多个牙齿区域标识lb3_1~lb3_4输入imu动作深度学习模型im,imu动作深度学习模型im输出多个象限机率值ur、ul、ll及/或lr。多个牙齿区域标识lb3_1~lb3_4例如第3a所示,将所有牙齿位置画分成四个象限(右上为第一象限牙齿标示区域lb3_1、左上为第二象限牙齿标示区域lb3_2、左下为第三象限牙齿标示区域lb3_3、右下为第四象限为牙齿标示区域lb3_4),imu动作深度学习模型im输出第一象限的象限机率值ur、第二象限的象限机率值ul、第三象限的象限机率值ll、第四象限的象限机率值lr。
56.在实施例中,imu动作深度学习模型im输出的象限机率值ur例如为90%、象限机率值ur例如为30%、象限机率值ul例如为10%、象限机率值ll例如为20%,在此例中,在所有象限机率值ur、ul、ll及lr中,象限机率值ur的值最高,代表这些牙齿影像是象限机率值ur所对应的牙齿区域标识lb3_1(例如牙齿编号21~28的位置)的机率最高。
57.在实施例中,imu动作深度学习模型im以递归神经网络(recurrent neural network,rnn)模型实现。
58.请参阅图8,图8是根据本发明的实施例描绘一种递归神经网络模型的示意图。递归神经网络模型常用于与时间序列相关的分类(如imu动作分类),将imu的时间序列资料输入至递归神经网络模型,并将其分类。图8以简单循环神经网络(simple rnn)分类为例:符号f代表单一递归神经网络模型;输入的符号x0~xt为时间0~t的imu资料(如惯性测量单
元114测量到的资料),符号h0~ht为时间0~t的隐藏状态(hidden state),会成为下一个递归神经网络的输入。换句话说,递归神经网络旨在建立一种记忆,也就是为了不将先前输出的结果遗忘,将其累积成某种隐藏状态(hidden state),并与当前输入结合,一起产出结果,再进一步传递下去。也因此,递归神经网络适合接收序列(sequence)作为输入并输出序列,提供了序列生成一个简洁的模型。最后的隐藏状态ht进入softmax函式转为机率,以分类出结果(例如为象限机率值ur、ul、ll及lr)。在实施例中,递归神经网络在训练阶段输入多组已分类好的imu资料,以更新递归神经网络模型内的参数,并储存最佳参数当作最佳的递归神经网络模型。
59.递归神经网络模型相当多种,实际应用上可能使用简单循环神经网络、长短期记忆网络(long short term memory network,lstm)
…
等递归神经网络架构。
60.请参阅图9,图9是根据本发明的实施例描绘一种应用多层感知机mlp以推算出牙齿影像所对应的牙齿位置机率pos1~pos32的示意图。
61.在步骤260中,处理器122将这些深度学习机率值a1~a16、左区域机率值rs与右区域机率值ls视为多个特征值,将这些特征值及多个牙齿区域标识lb4_1~lb4_n输入多层感知机(multi-layer perceptron classifier)mlp,多层感知机mlp输出牙齿影像所对应的牙齿位置机率pos1~pos32。
62.在实施例中,多个牙齿区域标识lb4_1~lb4_n例如是依据32颗牙齿的位置分成32个区域(在此例中,n为32)。处理器122将这些深度学习机率值a1~a16(16个特征值)、左区域机率值rs与右区域机率值ls(2个特征值)视为多个特征值(共18个特征值),将这些特征值及牙齿区域标识lb4_1~lb4_n(在此例中,n为32)输入多层感知机mlp,多层感知机mlp输出32个牙齿位置机率pos1~pos32。需注意的是,在此例中,输入为18个特征值(前述象限机率值ur、ul、ll及lr尚未作为特征值输入,因此只输入18个特征值),特征值的数量可依牙区辨识系统100实作时调整。一般而言,输入特征值的数量越多,输入多层感知机mlp输出的牙齿位置机率pos1~pos32判断结果越准确。
63.在实施例中,如图9所示,处理器122将这些深度学习机率值a1~a16、左区域机率值rs、右区域机率值ls、象限机率值ur、ul、ll及lr视为这些特征值(共22个特征值),将这些特征值及这些牙齿区域标识lb4_1~lb4_n(在此例中,n为32)输入多层感知机,多层感知机输出这些牙齿影像所对应的此牙齿位置机率pos1~pos32。
64.请一并参阅图10、11a~11b,图10是根据本发明的实施例描绘一种牙区辨识方法的示意图。图11a~11b是根据本发明的实施例描绘一种应用多层感知机mlp模型的示意图。在图10中,符号f1~fm即为输入的特征值(input features),符号bias代表偏权值,符号r1~rm可视为一个神经元集合,代表进入多层感知机mlp后的输入特征,其构成输入层(input layer),在一些实施例中,隐藏层(hidden layer)可以有多层,每个神经元在隐藏层会根据前一层的输出的结果,作为当前此层的输入,最后输出结果ot1~otn,这些结果构成输出层(output layer),输出层即为所需分类的类别,例如,输出层输出结果ot1、ot3、otn分别为:拍摄到左下位置38的机率(例如左下位置38对应的牙齿位置机率pos10为90%)、拍摄到左下位置37的机率(例如左下位置37对应的牙齿位置机率pos11为90%)...及拍摄到右下位置46的机率(例如右下位置46对应的牙齿位置机率pos21为10%),若机率为90%为输出层中数值最高,则处理器122判断这些输入影像对应的牙齿位置为牙位表示法中的左下位置
38及左下位置37。然而,本领域具通常知识者应可理解,上述仅为一示例,输出层输出的方式不限于此,亦可通过其他输出参数的方式呈现运算结果。
65.在实施例中,训练阶段输入多组已分类好的特征资料,以更新多层感知机mlp内的参数,并储存最佳参数当作最佳的模型。
66.在实施例中,多层感知机mlp的实作可应用软件scikit-learn,软件scikit-learn是一个用于python编程语言的免费软件机器学习库。例如,多层感知机mlp在实作上可应用软件scikit-learn的sklearn.neural_network.mlpclassifier函式库。
67.在实施例中,数字齿镜110的摄影机112用以拍摄一个或多个牙齿影像,惯性测量单元114,用以测量数字齿镜110的姿态信息p1及运动轨迹p2。运算装置120的处理器122用以接收这些牙齿影像,比对这些牙齿影像中每个像素点的对应位置,以产生深度图dp,将这些牙齿影像、深度图dp及多个牙齿区域标识lb1_1~lb1_n输入牙齿深度学习模型tm,牙齿深度学习模型tm输出与这些牙齿区域标识lb1_1~lb1_n数量相同的多个深度学习机率值a1~a16,处理器122将姿态信息p1、运动轨迹p2及多个牙齿区域标识lb3_1~lb3_4输入imu动作深度学习模型im,imu动作深度学习模型im输出多个象限机率值ur、ul、ll及/或lr,将这些深度学习机率值a1~a16及这些象限机率值ur、ul、ll及/或lr视为多个特征值,处理器122将这些特征值及多个牙齿区域标识lb4_1~lb4_n输入多层感知机,多层感知机mlp输出这些牙齿影像所对应的牙齿位置机率。
68.在实施例中,在图11a~11b中,数字齿镜110的摄影机112依序拍摄到原始影像img_f、原始影像img_f’,数字齿镜110的惯性测量单元114在拍摄到原始影像img_f的当下取得移动信息imu_d,在拍摄到原始影像img_f’的当下取得移动信息imu_d’,处理器122接收这些信息并将原始影像img_f、原始影像img_f’、移动信息imu_d及移动信息imu_d’输入深度地图产生器dmg,以产生深度图dp。其中,深度地图产生器dmg可以由现有技术实现,例如应用单视角影像、双视角影像
…
等方式,以硬体电路或软件实作深度地图产生器dmg,故此处不赘述。
69.由图11a~11b可知,方法400可选择性地搭配方法700及/或方法500以产生多个特征值。
70.例如,处理器122执行方法400(图11a)会产生多个深度学习机率值(例如a1~a16),处理器122执行方法700(图11b)会产生象限机率值ur、ul、ll及lr,则处理器122执行方法400搭配方法700会产生20个特征值,处理器将此20个特征值代入多层感知机mlp以推算出牙齿影像所对应的牙齿位置机率,例如,输出层输出:拍摄到左下位置38的机率(例如左下位置38对应的牙齿位置机率pos10为80%)、拍摄到左下位置37的机率(例如左下位置37对应的牙齿位置机率pos11为80%)...及拍摄到右下位置46的机率(例如右下位置46对应的牙齿位置机率pos21为30%),若机率为80%为输出层中数值最高,则处理器122判断这些输入影像对应的牙齿位置为牙位表示法中的左下位置38及左下位置37。
71.例如,处理器122执行方法400(图11a)会产生多个深度学习机率值(例如a1~a16),处理器122执行方法500(图11b)会产生左区域机率值rs及右区域机率值ls,则处理器122执行方法400搭配方法500会产生18个特征值,处理器将此18个特征值代入多层感知机mlp以推算出牙齿影像所对应的牙齿位置机率,例如,输出层输出:拍摄到左下位置38的机率(例如左下位置38对应的牙齿位置机率pos10为70%)、拍摄到左下位置37的机率(例如左
下位置37对应的牙齿位置机率pos11为70%)...及拍摄到右下位置46的机率(例如右下位置46对应的牙齿位置机率pos21为40%),若机率为70%为输出层中数值最高,则处理器122判断这些输入影像对应的牙齿位置为牙位表示法中的左下位置38及左下位置37。
72.例如,处理器122执行方法400(图11a)会产生多个深度学习机率值(例如a1~a16),处理器122执行方法700(图11b)会产生象限机率值ur、ul、ll及lr,并且执行方法500(图11b)产生左区域机率值rs及右区域机率值ls,则处理器122执行方法400搭配方法500及方法700会产生22个特征值,处理器将此22个特征值代入多层感知机mlp以推算出牙齿影像所对应的牙齿位置机率,例如,输出层输出:拍摄到左下位置38的机率(例如左下位置38对应的牙齿位置机率pos10为95%)、拍摄到左下位置37的机率(例如左下位置37对应的牙齿位置机率pos11为95%)...及拍摄到右下位置46的机率(例如右下位置46对应的牙齿位置机率pos21为10%),若机率为95%为输出层中数值最高,则处理器122判断这些输入影像对应的牙齿位置为牙位表示法中的左下位置38及左下位置37。
73.本发明所示的牙区辨识系统,应用牙齿区域标识及牙齿深度学习模型,以达到自动并准确判断牙齿影像对应实际牙齿位置的效果。
74.[符号说明]
[0075]
100:牙区辨识系统
[0076]
110:电子装置
[0077]
lk:通信连结
[0078]
120:运算装置
[0079]
usr:用户
[0080]
112、124:摄影机
[0081]
114:惯性测量单元
[0082]
116:光源装置
[0083]
118、128:传输装置
[0084]
122:处理器
[0085]
126:显示器
[0086]
200:牙区辨识方法的流程图
[0087]
210~260:步骤
[0088]
11~18、21~28、31~38、42~48:牙齿位置
[0089]
400:应用牙齿深度学习模型以取得深度学习机率值的方法
[0090]
dp:深度图
[0091]
img_f、usr_f:原始影像
[0092]
img_r:r通道阵列影像
[0093]
img_g、usr_r:g通道阵列影像
[0094]
img_b、usr_b:b通道阵列影像
[0095]
lb1_1~lb1_n、lb2_1~lb2_n、lb3_1~lb3_4、lb4_1~lb4_n:牙齿区域标识
[0096]
tm:牙齿深度学习模型
[0097]
500:应用用户影像深度学习模型以取得左区域机率值及右区域机率值的方法
[0098]
um:用户影像深度学习模型
[0099]
ls:右区域机率值
[0100]
rs:左区域机率值
[0101]
700:应用imu动作深度学习模型取得象限机率值的方法
[0102]
p1:姿态信息
[0103]
p2:运动轨迹
[0104]
im:imu动作深度学习模型
[0105]
ur、ul、ll、lr:象限机率值
[0106]
x0~xt:时间0~t的imu资料
[0107]
h0~ht:时间0~t的隐藏状态
[0108]
f:单一递归神经网络模型
[0109]
a1~a16:深度学习机率值
[0110]
mlp:多层感知机
[0111]
pos1~pos32:牙齿位置机率
[0112]
f1~fm:输入的特征值
[0113]
r1~rm:神经元集合
[0114]
bias:偏权值
[0115]
ot1~otn:输出结果
[0116]
img_f、img_f’:原始影像
[0117]
imu_d、imu_d’:移动信息
[0118]
dmg:深度地图产生器
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1