一种基于上下文感知残差网络的舌图像分割方法与流程
本发明涉及图像处理技术领域,特别是一种基于上下文感知残差网络的舌图像分割方法。
背景技术:
舌诊是传统中医“望诊”的主要内容之一,是具有中医特色的传统诊断方法之一。舌象是反映人体生理功能和病理变化最敏感的指标,在中医诊疗过程中具有重要的应用价值。应用图像处理技术,建立舌诊信息的客观量化、识别方法,实现中医舌诊的自动化,对中医现代化具有重要的现实意义。自动化舌诊系统中,病人的舌图像经过数字采集仪器(工业相机、摄像头等)获取后,必须首先对目标区域(舌体)进行自动的分割,然后才能提取舌体特征和进行诊断。因此,舌图像分割成了连接舌图像采集和舌体诊断的重要纽带,分割质量将直接影响到后续诊断的准确性。
舌图像分割的难点在于:(1)舌体的颜色与脸部的颜色特别是嘴唇的颜色很接近,容易混淆;(2)舌体作为一个软体,没有固定的形状,舌体形状的个体差异性大;(3)舌体不平滑,舌苔舌质因人而异,病理特征差异较大;(4)舌体的裂纹、舌苔色块可能影响舌体的准确分割。
鉴于舌图像分割的困难和挑战,单一传统的图像分割技术往往难以获得满意的分割效果。因此,人们开始研究多种传统分割技术的融合。在多种传统分割技术融合的框架下,主流的方法是基于主动轮廓模型(acm,activecontourmodel)的方法。acm又称为snake模型,是一种流行的可变形状模型,广泛应用于轮廓提取中。给定一个初始轮廓曲线,主动轮廓模型在内外力的共同作用下将初始轮廓曲线朝着真实目标轮廓处演化。基于acm的分割方法主要研究点在初始轮廓的获取和曲线演化上。但现有传统舌图像分割方法的分割效果仍然有待提高。
最近,基于深度卷积神经网络(convolutionalneuralnetwork,cnn)的方法在计算机视觉和图像处理领域取得了显著的成功。在医学图像分割领域,由于cnn强大的特征学习和表示能力,基于cnn的方法也得到了广泛的应用。在这些方法中,全卷积网络(fullyconvolutionalnetwork,fcn)展示了在生物细胞和器官分割上的良好表现。u型网络(u-net)从fcn发展而来,并考虑了编码器和解码器之间的跳转连接,通过扩展对称自编码器设计,将编码路径中的高分辨率特征与上采样输出相结合,更好地定位图像中的目标。u-net网络被用于识别和分割不同发育阶段的果蝇心脏区域。此外,卷积神经网络还被用来构建基于焦点堆叠的方法,用于从血涂片中自动检测恶性疟原虫疟疾。基于深度学习的舌图像分割近两年来刚起步。
技术实现要素:
有鉴于此,本发明的目的是提出一种基于上下文感知残差网络的舌图像分割方法,能够有效提高舌图像分割的精度。
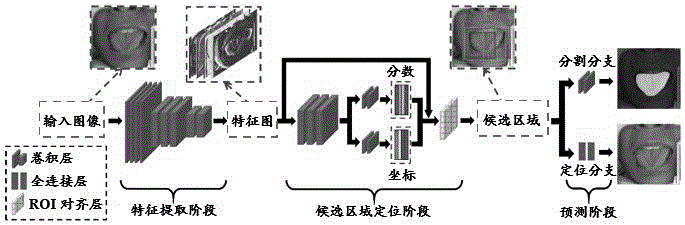
本发明采用以下方案实现:一种基于上下文感知残差网络的舌图像分割方法,具体包括以下步骤:
利用深度神经网络自动提取图像特征;
基于提取到的特征图,利用区域候选网络确定舌体所在的候选区域;
最后通过分割候选区域得到舌体分割结果。
进一步地,所述利用深度神经网络自动提取图像特征具体包括以下步骤:
步骤s11:建立空洞残差模块,其所对应的映射如下所示:
式中,xi和xi+1分别代表第i个残差块的输入和输出,d表示空洞卷积操作,gd(·)和fd(·)分别代表两个不同的非线性映射组,其中每一个映射组均由一个空洞卷积运算、一个批量归一化运算以及一个relu激活函数组成;
步骤s12:利用步骤s1建立的空洞残差模块建立特征金字塔网络,实现对舌图像的多尺度特征提取,得到多尺度的特征图;
该特征金字塔网络包括自底向上路径模块、横向连接模块以及自顶向下路径模块,其中,自底向上路径模块是由五个上下文感知的空洞残差模块串行构建而成的特征提取基础网络,横向连接模块用于将自底向上路径模块的特征图连接至自顶向下路径模块。
进一步地,所述利用区域候选网络确定舌体所在的候选区域具体为:区域候选网络利用一个滑动窗口在多尺度的特征图上进行候选目标提取,接着通过一个3×3卷积核大小的标准卷积层得到一个2048维的向量,其紧跟由1×1卷积核大小的标准卷积层构成的候选框分类和候选框回归两个分支,分别实现候选框的目标分类和位置定位,由此分别产生2k个类别概率和4k个候选框坐标位置;其中,类别概率包括舌体概率与非舌体概率,候选框坐标位置包括x坐标、y坐标、box宽、box高。
进一步地,所述通过分割候选区域得到舌体分割结果具体为:首先通过一个roi对齐模块,利用双线性插值技术,将每一个候选区域所对应的特征图转化成一个固定大小的候选特征图,将多个候选特征图进行对齐,然后分别通过定位分支网络和分割分支网络实现最终的舌体定位和分割。
进一步地,所述定位分支网络是由两个全连接层作为回归器进行位置回归操作,实现精确定位;所述分割分支网络由两层标准卷积层作为像素分类器进行像素级的分类,即舌体分割。
进一步地,定位分支网络和分割分支网络的训练过程所采用的损失函数为:
l=lloc+lmask;
其中,
式中,ti是手动标注的舌体位置,
其中,
lmask=∑c(1-tic)
式中,tic是tversky相似性度量,定义如下:
式中,pic是预测的像素i属于舌体类别的概率,
与现有技术相比,本发明有以下有益效果:本发明首先对舌体区域进行定位,然后在定位后的区域中进行像素级的分类,实现最终的精确分割,有效避免复杂背景的干扰。在特征学习的过程中,为了提取到更具表示性的特征,本发明提出了一种新的基于上下文感知的空洞残差模块,结合特征金字塔网络,能够实现多级尺度特征的有效提取。本发明能够有效提升舌图像分割的精度和鲁棒性。
附图说明
图1为本发明实施例的方法原理示意图。
图2为resnet中原始的残差模块结构。
图3为本发明实施例的上下文感知的空洞残差模块结构。
图4为本发明实施例的特征金字塔网络。
图5为本发明实施例的特征图样例:上下文感知的特征金字塔网络的输出。
图6为本发明实施例的区域候选网络。
图7为三个数据集上各种方法分割性能的箱线图。其中,(a)为precision,(b)为dice,(c)为mlou,(d)为fpr,(e)为fnr,(f)为me。
图8为三个数据集上各种算法分割性能的定量比较。
图9为三个数据集上随机选择的三幅舌图像的分割结果对比。其中(a)为数据集testset1,(b)为testset2,(c)为testset3。
具体实施方式
下面结合附图及实施例对本发明做进一步说明。
应该指出,以下详细说明都是示例性的,旨在对本申请提供进一步的说明。除非另有指明,本文使用的所有技术和科学术语具有与本申请所属技术领域的普通技术人员通常理解的相同含义。
需要注意的是,这里所使用的术语仅是为了描述具体实施方式,而非意图限制根据本申请的示例性实施方式。如在这里所使用的,除非上下文另外明确指出,否则单数形式也意图包括复数形式,此外,还应当理解的是,当在本说明书中使用术语“包含”和/或“包括”时,其指明存在特征、步骤、操作、器件、组件和/或它们的组合。
如图1所示,本实施例提供了一种基于上下文感知残差网络的舌图像分割方法,本实施例的整体网络框架为一种端到端的舌体定位与分割深度神经网络,简称为tonguenet,整个算法流程由三个阶段组成:特征提取阶段(featureextractionstage)、区域候选阶段(regionproposalstage)、预测阶段(predictionstage)。首先,在特征提取阶段,为了有效地提取图像空间信息和舌体的先验信息(比如:颜色、形状、舌苔纹理等),本实施例提出了金字塔网络模块,该模块基于空洞卷积dilatedconvolution)和残差学习(residuallearning),能够有效地实现舌图像的多尺度特征提取;接着,在区域候选阶段,基于特征提取阶段提取到的特征图,本实施例利用区域候选网络(regionproposalnetwork),实现舌体候选区域的有效粗定位;最终,在预测阶段,基于区域候选阶段定位到的舌体候选区域及其特征图,通过优化本发明所设计的多任务损失函数,实现对两个不同的学习任务(分割和定位)的联合学习。
具体包括以下步骤:
利用深度神经网络自动提取图像特征;
基于提取到的特征图,利用区域候选网络确定舌体所在的候选区域;
最后通过分割候选区域得到舌体分割结果。
实验表明,本实施例的方法显著提高了舌图像的分割精度。
较佳的,一个理想的特征提取网络应该是一个足够深的神经网络,用来实现多尺度特征的有效提取。受启发于resnet在特征提取和图像分类任务中的成功应用,本实施例基于resnet中的残差块(residualblocks),提出了一种新的上下文感知的空洞残差模块(context-awaredilatedresidualblock),实现更具有判别性的舌体特征的提取。原始的残差块由不同卷积核大小的卷积层构成,其所对应的映射如下式所示:
其中,xi和xi+1分别代表第i个残差块的输入和输出,g(·)和f(·)分别代表两个不同的非线性映射组,其中每一个映射组均由一个标准卷积运算(standardconvolution)、一个批量归一化运算(batchnormalization)以及一个relu激活函数组成;
在本实施例中,所述利用深度神经网络网络自动提取图像特征具体包括以下步骤:
步骤s11:不同于resnet中原始的残差块结构,本实施例提出了一种新的上下文感知的空洞残差模块,其所对应的映射如下所示:
式中,xi和xi+1分别代表第i个残差块的输入和输出,d表示空洞卷积操作,gd(·)和fd(·)分别代表两个不同的非线性映射组,其中每一个映射组均由一个空洞卷积运算、一个批量归一化运算以及一个relu激活函数组成;
步骤s12:利用步骤s1建立的空洞残差模块建立特征金字塔网络,实现对舌图像的多尺度特征提取,得到多尺度的特征图;
如图4所示,该特征金字塔网络包括自底向上路径模块(bottom-uppathway)、横向连接模块以及自顶向下路径模块,其中自底向上路径模块是由五个上下文感知的空洞残差模块(dconv1_x、dconv2_x、dconv3_x、dconv4_x和dconv5_x)串行构建而成的特征提取基础网络,横向连接模块用于将自底向上路径模块的特征图连接至自顶向下路径模块。最终构成一个多级尺度的特征金字塔,用于区域候选阶段舌体区域的粗定位和预测阶段舌体区域的精确定位与分割。图5所示是上下文感知的特征金字塔网络所输出的多级尺度的特征图。
较佳的,在区域候选阶段,基于特征提取阶段提取到的多级尺度特征图,本实施例利用区域候选网络,实现舌体候选区域的有效粗定位,而定位到的舌体候选区域所对应的特征图用于预测阶段舌体的精确定位和分割。
在本实施例中,如图6所示,所述利用区域候选网络确定舌体所在的候选区域具体为:区域候选网络利用一个滑动窗口(slidingwindow)在多尺度的特征图上进行候选目标提取,接着通过一个3×3卷积核大小的标准卷积层得到一个2048维的向量,其紧跟由1×1卷积核大小的标准卷积层构成的候选框分类(boxclassification)和候选框回归(boxregression)两个分支,分别实现候选框的目标分类和位置定位,由此分别产生2k个类别概率和4k个候选框坐标位置;其中,类别概率包括舌体概率与非舌体概率,候选框坐标位置包括x坐标、y坐标、box宽、box高。
在本实施例中,所述通过分割候选区域得到舌体分割结果具体为:首先通过一个roi对齐(align)模块,利用双线性插值技术,将每一个候选区域所对应的特征图转化成一个固定大小的候选特征图,将多个候选特征图进行对齐,然后分别通过定位分支网络(localizationbranch)和分割分支网络(maskbranch)实现最终的舌体定位和分割。
在本实施例中,所述定位分支网络是由两个全连接层作为回归器进行位置回归操作,实现精确定位;所述分割分支网络由两层标准卷积层作为像素分类器进行像素级的分类,即舌体分割。
在本实施例中,定位分支网络和分割分支网络的训练过程所采用的损失函数为:
l=lloc+lmask;
其中,
式中,ti是手动标注的舌体位置,
其中,
lmask=∑c(1-tic)
式中,tic是tversky相似性度量,定义如下:
式中,pic是预测的像素i属于舌体类别的概率,
其中,α=0.3,β=0.7。
本实施例通过所提出的一个新的端到端的多任务深度学习框架来提升舌图像分割的精度和鲁棒性。首先对舌体区域进行定位,然后在定位后的区域中进行像素级的分类,实现最终的精确分割,有效避免复杂背景的干扰。在特征学习的过程中,为了提取到更具表示性的特征,本实施例提出了一种新的上下文感知的空洞残差模块,结合特征金字塔网络,实现多级尺度特征的有效提取。
特别的,为了评价舌图像分割算法的性能,本实施例在testset1(300张分辨率为768×576的舌图像)、testset2(331张分辨率为550×650的舌图像)、testset3(290张分辨率为600×576的舌图像)三个数据集上进行了十折交叉验证实验,分割性能通过6个常见的分割测度进行度量。前3个测度即精度(precision)、dice系数(dicecoefficient)以及miou(meanintersectionoverunion)常用在基于深度学习的分割模型性能度量上,测度值越大表示分割性能越好;后3个测度即假正率/虚警率(falsepositiverate,fpr)、假负率(falsenegativerate,fnr)以及错分类误差(misclassificationerror,me)常用于传统的分割模型性能度量上,测度值越小表示分割性能越好。这些测度的定义为:
式中,bg和fg表示手动标准分割结果的背景和目标,bp和fp代表自动分割算法对应分割结果中的背景和目标,|·|代表集合中元素的个数。六个测度的取值范围均为0-1。越低的me、fpr和fnr值代表越好的分割效果;相反,越高的precision、dice和miou值代表越好的分割效果。
为验证本实施例方法在舌图像分割上的有效性,本实施例将其与新近提出的深度学习算法fcn、u-net、segnet、deeptongue、maskr-cnn进行了比较。如图7的箱线图和图8的表格所示,本发明算法(tonguenet)在三个数据集六种测度下的度量结果几乎都是最好的,其对应的precision、dice、miou测度值明显高于其他方法,其对应的fpr和me测度值明显低于其他方法。唯一例外的情况,在fnr测度上,deeptongue和u-net在部分数据集上优于本发明算法,但这是由于这两种算法分割结果存在更明显的过分割现象而导致的。图7的箱线图进一步证实了本发明算法比其他方法稳定性更好,因为其离群点通常更少或偏离程度更轻。
图9分别给出了三个数据集上随机选择的三幅舌图像的手动分割结果和算法的分割结果,其中,虚线代表手动的理想分割结果,实线代表算法的分割结果。从图9可以看出,本发明算法分割结果与手动理想分割结果通常最接近(虚线与实现重合度最高),分割效果最好;且在三个数据集三幅随机选择的舌图像上都基本取得了最佳的分割效果,说明其分割性能最稳定。
本领域内的技术人员应明白,本申请的实施例可提供为方法、系统、或计算机程序产品。因此,本申请可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本申请可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
以上所述,仅是本发明的较佳实施例而已,并非是对本发明作其它形式的限制,任何熟悉本专业的技术人员可能利用上述揭示的技术内容加以变更或改型为等同变化的等效实施例。但是凡是未脱离本发明技术方案内容,依据本发明的技术实质对以上实施例所作的任何简单修改、等同变化与改型,仍属于本发明技术方案的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!