病历检测方法及相关模型的训练方法和相关设备、装置与流程
本申请涉及自然语言理解技术领域,特别是涉及一种病历检测方法及相关模型的训练方法和相关设备、装置。
背景技术:
随着医疗行业的快速发展以及医疗技术的不断提高,病历质量越来越受到重要。作为病历质量中极其重要的一环,病情与诊断之间的语义一致性,而如何检测病情与诊断之间的语义一致性也是病历质检中突出问题。目前,主要通过人工抽查的方式对病历进行检测,需要耗费大量的人力物力,效率低且成本高,且由于抽查的滞后性和不完整性,抽查只能作为事后的评价指标而不能实时提醒医生。有鉴于此,如何提高病历检测的效率和即时性,并降低病历检测的成本成为极具研究价值的课题。
技术实现要素:
本申请主要解决的技术问题文本是提供一种病历检测方法及相关模型的训练方法和相关设备、装置,能够提高病历检测的效率和即时性,并降低病历检测的成本。
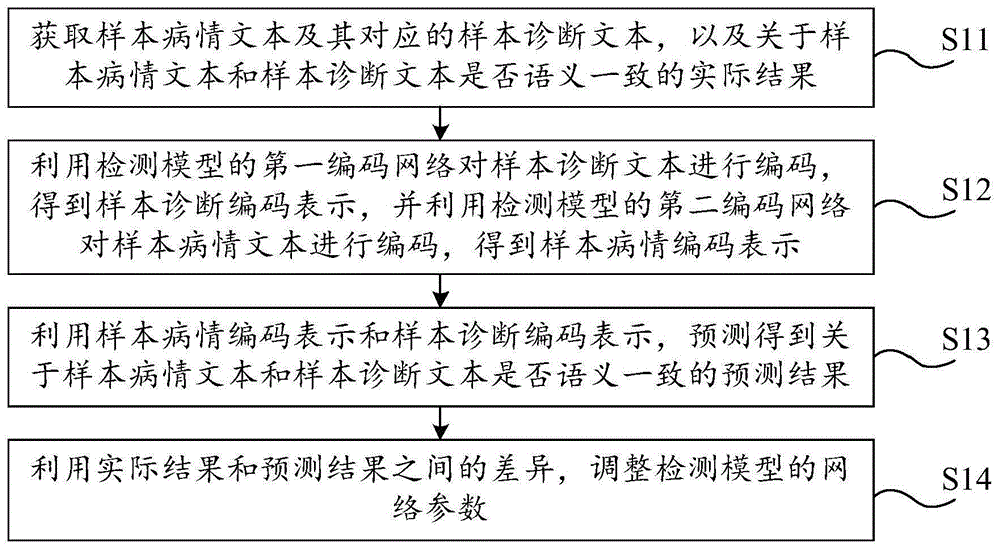
为了解决上述问题文本,本申请第一方面提供了一种检测模型的训练方法,包括:获取样本病情文本及其对应的样本诊断文本,以及关于样本病情文本和样本诊断文本是否语义一致的实际结果;利用检测模型的第一编码网络对样本诊断文本进行编码,得到样本诊断编码表示,并利用检测模型的第二编码网络对样本病情文本进行编码,得到样本病情编码表示;其中,样本诊断编码表示包含:样本诊断文本本身的语义信息、样本诊断文本中分词的语义信息和与样本诊断文本相关的参考词语的语义信息;利用样本病情编码表示和样本诊断编码表示,预测得到关于样本病情文本和样本诊断文本是否语义一致的预测结果;利用实际结果和预测结果之间的差异,调整检测模型的网络参数。
为了解决上述问题文本,本申请第二方面提供了一种病历检测方法,包括:在患者病历中获取病情文本及其对应的诊断文本;获取诊断文本的诊断编码表示,并获取病情文本的病情编码表示;其中,诊断编码表示包含:诊断文本本身的语义信息、诊断文本所含分词的语义信息和与诊断文本相关的参考词语的语义信息;利用病情编码表示和诊断编码表示进行一致性检测,得到关于病情文本和诊断文本是否语义一致的检测结果。
为了解决上述问题文本,本申请第三方面提供了一种电子设备,包括相互耦接的存储器和处理器,存储器中存储有程序指令,处理器用于执行程序指令以实现上述第一方面中的检测模型的训练方法,或实现上述第二方面中的病历检测方法。
为了解决上述问题文本,本申请第四方面提供了一种存储装置,存储有能够被处理器运行的程序指令,程序指令用于实现上述第一方面中的检测模型的训练方法,或实现上述第二方面中的病历检测方法。
上述方案,通过获取样本病情文本及其对应的样本诊断文本,以及关于样本病情文本和样本诊断文本是否语义一致的实际结果,从而利用检测模型的第一编码网络对样本诊断文本进行编码,得到样本诊断编码表示,并利用检测模型的第二编码网络对样本病情文本进行编码,得到样本病情编码表示,且样本诊断编码表示包含:样本诊断文本本身的语义信息、样本诊断文本中分词的语义信息和与样本诊断文本相关的参考词语的语义信息,进而利用样本病情编码表示和样本诊断编码表示,预测得到关于样本病情文本和样本诊断文本是否语义一致的预测结果,在此基础上,再利用实际结果和预测结果之间的差异,调整检测模型的网络参数,由于在样本诊断编码表示中融入了样本诊断文本本身的语义信息、样本诊断文本中分词的语义信息和与样本诊断文本相关的参考词语的语义信息等多种与样本诊断文本相关的语义信息,故能够有利于增强样本诊断编码表示,提升检测模型的泛化能力,且由于通过检测模型能够无需人工抽查即可即时检测病历,最终能够提高病历检测的效率和即时性,并降低病历检测的成本。
附图说明
图1是本申请检测模型的训练方法一实施例的流程示意图;
图2是本申请检测模型的训练方法另一实施例的流程示意图;
图3是知识图一实施例的框架示意图;
图4是获取分词之间相关度一实施例的流程示意图;
图5是获取样本病情编码表示一实施例的流程示意图;
图6是图1中步骤s13一实施例的流程示意图;
图7是本申请病历检测方法一实施例的流程示意图;
图8是本申请病历检测方法一实施例的状态示意图;
图9是本申请电子设备一实施例的框架示意图;
图10是本申请存储装置一实施例的框架示意图。
具体实施方式
下面结合说明书附图,对本申请实施例的方案进行详细说明。
以下描述中,为了说明而不是为了限定,提出了诸如特定系统结构、接口、技术之类的具体细节,以便透彻理解本申请。
本文中术语“系统”和“网络”在本文中常被可互换使用。本文中术语“和/或”,仅仅是一种描述关联对象的关联关系,表示可以存在三种关系,例如,a和/或b,可以表示:单独存在a,同时存在a和b,单独存在b这三种情况。另外,本文中字符“/”,一般表示前后关联对象是一种“或”的关系。此外,本文中的“多”表示两个或者多于两个。
请参阅图1,图1是本申请检测模型的训练方法一实施例的流程示意图。具体而言,可以包括如下步骤:
步骤s11:获取样本病情文本及其对应的样本诊断文本,以及关于样本病情文本和样本诊断文本是否语义一致的实际结果。
在一个实施场景中,样本病情文本可以包括但不限于:病人主诉、病人病史等等。例如,病人主诉“持续发烧4天、伴咳嗽、咳痰2天”,病人现病史“病人4天前起无明显诱因下出现发烧,为低热,无明显出汗、无皮疹,无全身酸痛……”,病人既往史“平素体健,前列腺炎病史数年;否认有肝炎、肺结核等传染病病史,否认有糖尿病、高血压病史,无手术、外伤史……”,在此基础上,可以将上述病人主诉、病人现病史、病人既往史等与病情相关的文本,作为样本病情文本。上述举例仅仅为实际应用中可能出现的一种样本病情文本,在此并不限定其他可能出现的情况,具体可以根据实际病历而提取样本病情文本,在此不做限定。
在一个实施场景中,样本诊断文本可以包括但不限于:第一诊断文本。医生在获取病人主诉、现病史、既往史的基础上,进行体格检查、实验室检查(如,血常规、尿常规等)及器械检查(如,胸部x线检查、核磁共振等)之后,通常会下第一诊断、第二诊断等,且第一诊断通常与病情吻合度较高,在此基础上,可以将第一诊断文本作为样本病情文本的样本诊断文本。仍以上述样本病情文本为例,第一诊断可以为“肺炎”、第二诊断可以为“高血压病”,则可以将第一诊断“肺炎”作为样本诊断文本。上述举例仅仅为实际应用中可能出现的一种样本诊断文本,在此并不限定其他可能出现的情况,具体可以根据实际病历而提取样本诊断文本,在此不做限定。
在一个实施场景中,可以获取医疗机构已有病历,并将已有病历中与病情相关的文本(如前述病人主诉、病人病史等),作为样本病情文本,将与诊断相关的文本(如前述第一诊断),作为样本诊断文本,在此基础上,通过人工标注等方式获取样本病情文本和样本诊断文本是否语义一致的实际结果。仍以上述样本病情文本和样本诊断文本为例,可以通过人工标注的方式,确定样本病情文本“持续发烧4天、伴咳嗽、咳痰2;病人4天前起无明显诱因下出现发烧,为低热,无明显出汗、无皮疹,无全身酸痛……;平素体健,前列腺炎病史数年;否认有肝炎、肺结核等传染病病史,否认有糖尿病、高血压病史,无手术、外伤史……”以及样本诊断文本“肺炎”之间是否语义一致的实际结果为:语义一致。其他情况可以以此类推,在此不再一一举例。
在另一个实施场景中,也可以从医疗机构的已有病历中满足质量要求条件的病历,作为目标病历。具体地,质量要求条件可以包括:主任医师等专家或高年资医师的病历,在此不做限定。在此基础上,可以提取目标病历中与病情相关的文本(如前述病人主诉、病人病史等),作为样本病情文本,将与诊断相关的文本(如前述第一诊断),作为样本诊断文本,从而可以直接标注样本病情文本和样本诊断文本之间是否语义一致的实际结果为:语义一致。仍以上述样本病情文本和样本诊断文本为例,上述样本病情文本和样本诊断文本是从目标病历中提取得到的,则可以直接标注样本病情文本“持续发烧4天、伴咳嗽、咳痰2;病人4天前起无明显诱因下出现发烧,为低热,无明显出汗、无皮疹,无全身酸痛……;平素体健,前列腺炎病史数年;否认有肝炎、肺结核等传染病病史,否认有糖尿病、高血压病史,无手术、外伤史……”以及样本诊断文本“肺炎”之间是否语义一致的实际结果为:语义一致。其他情况可以以此类推,在此不再一一举例。
步骤s12:利用检测模型的第一编码网络对样本诊断文本进行编码,得到样本诊断编码表示,并利用检测模型的第二编码网络对样本病情文本进行编码,得到样本病情编码表示。
本公开实施例中,样本诊断编码表示包含:样本诊断文本本身的语义信息、样本诊断文本中分词的语义信息和与样本诊断文本相关的参考词语的语义信息。
在一个实施场景中,样本诊断文本中分词具体可以是利用分词工具对样本诊断文本进行分词得到的。具体地,分词工具可以包括但不限于:结巴分词、ltp、hanlp等等,在此不做限定。以前述样本诊断文本“肺炎”为例,经分词工具分词之后,可以得到样本诊断文本中分词:“肺炎”;或者,以样本诊断文本“咽炎伴支气管炎”为例,经分词工具分词之后,可以得到样本诊断文本中分词:“咽炎”、“支气管炎”。其他情况可以以此类推,在此不再一一举例。
在另一个实施场景中,与样本诊断文本相关的参考词语可以包括但不限于:症状描述类参考词语、部位描述类参考词语、病因描述类参考词语等等,在此不做限定。需要说明的是,症状描述类参考词语表示与样本诊断文本所对应疾病的症状相关的参考词语,部位描述类参考词语表示与样本诊断文本对应疾病的部位相关的参考词语,而病因描述类参数词语表示与样本诊断文本对应疾病的病因相关的参考词语。仍以前述样本诊断文本“肺炎”为例,其症状描述类参考词语可以包括但不限于:“咳嗽”、“发烧”、“呼吸困难”等等,在此不做限定,其部位描述类参考词语可以包括但不限于:“肺部”、“支气管”等等,在此不做限定,其病因描述类参考词语可以包括但不限于:“细菌”、“病毒”、“真菌”等等,在此不做限定。上述症状描述类参考词语、部位描述类参考词语以及病因描述类参数词语仅仅是实际应用中可能存在的参考词语,并不因此而限定其他可能出现的参考词语,在此不再一一举例。
在一个实施场景中,第一编码网络和第二编码网络具体可以包括:bert(bidirectionalencoderrepresentationfromtransformers,即双向transformer的encoder)等等,在此不做限定。在此基础上,可以将样本诊断文本以及与样本诊断文本相关的参考词语送入第一编码网络,得到样本诊断编码表示,并将样本病情文本送入第二编码网络,得到样本病情编码表示。
在另一个实施场景中,为了适应诊断文本和与其相关的参考词语之间的非欧几里得结构关系,并进一步聚合语义信息,提高编码表示的准确性,第一编码网络还可以包括图神经网络(graphneuralnetwork,gnn),图神经网络具体可以为图卷积图像(graphconvolutionalnetworks,gcn)。在此基础上,可以预先构建知识图,且知识图包括多个词语和多个词语之间的相关度,多个词语包括:属于同一词语类别的参考词语、与至少一个参考词语相关的疾病名词,以及参考词语和/或疾病名词中各个分词,从而可以将知识图送入上述图神经网络,得到知识图中各个词语的词语编码表示,并利用与样本诊断文本相同的词语的词语编码表示,得到样本诊断文本的样本诊断编码表示。具体可以参阅下述相关公开实施例,在此暂不赘述。
在一个具体的实施场景中,需要说明的是,现实场景中诊断文本和参考词语之间的关系通常为多对多的关系,即多种诊断文本可能对应于同一参考词语,而多个参考词语也可能对应于同一诊断文本,故两者之间是典型的非欧几里得结构关系。例如,对于诊断文本“咽炎”和诊断文本“肺炎”均对应于同一个症状描述类参考词语“咳嗽”,而对于症状描述类参考词语“咳嗽”和“发烧”均对应于同一诊断文本“肺炎”,或者对于症状描述类参考词语“吞咽困难”和“咳嗽”均对应于同一诊断文本“咽炎”,其他情况可以以此类推,在此不再一一举例。
在另一个具体的实施场景中,若词语之间具有关联性,则可以直接将这两个词语之间的相关度设置为第一数值(如,1),反之,若词语之间不具有相关性,则可以直接将这两个词语之间的相关度设置为第二数值(如,0)。仍以前述样本诊断文本“肺炎”为例,多个词语中可以包含:样本诊断文本“肺炎”本身,以及与样本诊断文本“肺炎”相关的参考词语,如症状描述类参考词语“咳嗽”和“发烧”,或者部位描述类参考词语“肺部”和“支气管”,或者病因描述类参考词语“细菌”、“病毒”和“真菌”,在此基础上,可以将词语“肺炎”与词语“咳嗽”、“发烧”、“肺部”、“支气管”、“细菌”、“病毒”和“真菌”之间的相关度设置为第一数值(如,1)。此外,多个词语中还可以包括:与样本诊断文本“肺炎”无关的参考词语,如症状描述类参考词语“吞咽困难”,或者,如部位描述类参考词语“咽喉”,或者,如病因描述类参考词语“饮酒过度”,在此基础上,可以将词语“肺炎”与词语“吞咽困难”、“咽喉”、“饮酒过度”之间的相关度设置为第二数值(如,0)。其他情况可以以此类推,在此不再一一举例。
在又一个实施场景中,为了提高样本诊断编码表示和样本病情编码表示之间输出空间的一致性,第二编码网络还可以包括图神经网络(graphneuralnetwork,gnn),图神经网络具体可以为图卷积图像(graphconvolutionalnetworks,gcn),从而可以将样本病情文本送入图神经网络,得到样本病情文本的样本病情编码表示。具体可以参阅下述相关实施例,在此暂不赘述。
步骤s13:利用样本病情编码表示和样本诊断编码表示,预测得到关于样本病情文本和样本诊断文本是否语义一致的预测结果。
在一个实施场景中,可以通过获取样本病情编码表示和样本诊断编码表示之间的语义相似度,来预测得到样本病情文本和样本诊断文本是否语义一致的预测结果。例如,在语义相似度大于一预设阈值的情况下,可以认为预测结果为语义一致;或者,在语义相似度不大于上述预设阈值的情况下,可以认为预测结果为语义不一致。
在另一个实施场景中,为了提高预测效率,检测模型还可以包括结果预测网络,从而可以直接将样本病情编码表示和样本诊断编码表示送入结果预测网络,得到样本病情文本和样本诊断文本是否语义一致的预测结果。
步骤s14:利用实际结果和预测结果之间的差异,调整检测模型的网络参数。
在一个实施场景中,上述预测结果具体可以包括表示语义一致的预测概率值,从而可以利用二分类交叉熵损失值函数处理实际结果和上述预测概率值,得到检测模型的损失值,进而可以利用损失值,调整检测模型的网络参数。
在另一个实施场景中,考虑到现实场景中,同一病情文本可能对应有多个语义一致的诊断文本以及多个语义不一致的诊断文本,例如,对于病情文本“咳嗽,并伴有轻微发烧”,其可能对应有语义一致的诊断文本“感冒”、“支气管炎”、“上呼吸道感染”等等,以及对应有语义不一致的诊断文本“胃炎”、“内分泌失调”等等,为了使检测模型能够同时对比语义一致的诊断文本和语义不一致的诊断文本,从而提高检测模型的学习效率,样本诊断文本具体可以包括:与样本病情文本语义一致的第一样本诊断文本,与样本病情文本语义不一致的至少一个第二样本诊断文本,从而可以将样本病情文本、第一样本诊断文本作为一组训练样本,经上述步骤处理,可以得到样本病情文本和第一样本诊断文本语义一致的第一检测概率,类似地,可以将样本病情文本、第二样本诊断文本作为另一组训练样本,经上述步骤处理,可以得到样本病情文本和第二样本诊断文本语义一致的第二检测概率,进而可以利用交叉熵损失函数处理第一检测概率和第二检测概率,得到检测模型的第一损失值,并利用第一损失值,调整检测模型的网络参数。上述方式,通过将样本诊断文本设置为包括:样本诊断文本包括:与样本病情文本语义一致的第一样本诊断文本、与样本病情文本内涵不一致的至少一个第二样本诊断文本,从而对应地,预测结果包括:样本病情文本和第一样本诊断文本语义一致的第一检测概率、样本病情文本和第二样本诊断文本语义一致的第二检测概率,从而利用交叉熵损失函数处理第一检测概率和第二检测概率,得到检测模型的第一损失值,进而利用第一损失值,调整检测模型的网络参数,能够有利于使得检测模型同时学习到正例样本与负例样本之间的不同,提高检测模型的学习效率,并提升检测模型的性能。
在一个具体的实施场景中,如前所述,可以从医疗机构的已有病历中满足质量要求条件的病历,作为目标病历,并提取目标病历中与病情相关的文本(如前述病人主诉、病人病史等),作为样本病情文本,以及提取与诊断相关的文本(如前述第一诊断),作为第一样本诊断文本。在此基础上,可以从目标病历所属科室之外的其他科室的病历中,抽取与诊断相关的文本(如前述第一诊断),作为第二样本诊断文本。例如,目标病历属于呼吸内科,第一样本诊断文本为“感冒”,在此基础上,可以从诸如神经内科、内分泌科、免疫科等其他科室的病历中,抽取与诊断相关的文本(如,前述第一诊断),如抽取“内分泌失调”、“风湿性关节炎”、“癫痫”等作为第二样本诊断文本。其他情况可以以此类推,在此不再一一举例。
在另一个具体的实施场景中,为了便于描述,可以将第一检测概率记为
上述公式(1)中,losscompare表示第一损失值,ypos表示正例标签(如,可以设置为1),yi表示第i个第二样本诊断文本对应的负例标签(如,可以设置为0),neg表示第二样本诊断文本的总数量。
在又一个实施场景中,如前所述,病情文本通常为长文本序列,而诊断文本的编码表示又需要融合其本身(通常为短文本)的语义信息以及相关的参考词语的语义信息,即病情文本的编码表示和诊断文本的编码表示两者的输出空间往往存在一定的不同之处,故为了提高两者输出空间一致性,还可以利用样本病情编码表示进行预测,得到第一预测诊断文本,并利用样本诊断编码表示进行预测,得到第二预测诊断文本,从而可以利用预测诊断文本与第一样本诊断文本之间的差异,以及利用第二预测诊断文本与样本诊断文本之间的差异,得到检测模型的第二损失值,从而可以利用第一损失值和第二损失值,调整检测模型的网络参数。需要说明的是,上述“第二预测诊断文本与样本诊断文本之间的差异”所指的“样本诊断文本”为样本诊断编码表示所对应的样本诊断文本。具体地,在样本诊断编码表示是由前述第一样本诊断文本提取得到的,则上述“第二预测诊断文本与样本诊断文本之间的差异”所指的“样本诊断文本”为第一样本诊断文本,类似地,在在样本诊断编码表示是由前述第二样本诊断文本提取得到的,则上述“第二预测诊断文本与样本诊断文本之间的差异”所指的“样本诊断文本”为第二样本诊断文本。上述方式,利用样本病情编码表示进行预测,得到第一预测诊断文本,并利用样本诊断编码表示进行预测,得到第二预测诊断文本,从而利用第一预测诊断文本与第一样本诊断文本之间的差异,以及利用第二预测诊断文本与样本诊断文本之间的差异,得到检测模型的第二损失值,进而利用第一损失值和第二损失值,调整检测模型的网络参数,即期望样本病情文本的样本病情编码表示分类至与其语义一致的样本诊断文本,并期望样本诊断文本的样本诊断编码表示分类至其本身(即样本诊断文本本身),故能够在反向传播调整网络参数的过程中,尽量保持病情编码表示和诊断编码表示处于较一致的输出空间,有利于提升两者输出空间的一致性。
在一个具体的实施场景中,为了便于描述,可以将样本病情编码表示记为x2,并将样本诊断编码表示记为d,则可以利用全连接层对样本病情编码表示x2进行预测,得到第一预测诊断文本,并利用全连接层对样本诊断编码表示d进行预测,得到第二预测诊断文本。具体可以表示为:
上述公式(2)和公式(3)中,mlp表示全连接层,具体可以为两层全连接层、三层全连接层等等,在此不做限定。此外,rt表示实数矩阵,该实数矩阵共包含t种诊断文本对应的one-hot编码,
在另一个具体的实施场景中,为了便于描述,可以将第一样本诊断文本的one-hot编码记为
上述公式(4)中,i表示第i个样本,例如,
在又一个具体的实施场景中,可以利用第一权值、第二权值分别对第一损失值、第二损失值进行加权处理,得到检测模型的损失值,并利用加权得到的损失值,调整检测模型的网络参数。为了便于描述,可以将第一权值记为λ1,并将第二权值记为λ2,则检测模型的损失值可以表示为:
loss=λ2*lossclass+λ1*losscompare……(5)
上述公式(5)中,loss表示检测模型的损失值,losscompare表示第一损失值,lossclass表示第二损失值,λ1表示第一权值,λ2表示第二权值。具体地,λ1可以设置为1,λ2可以根据诊断分类任务在训练过程中所占权重来设置,例如,诊断分类任务在训练过程中所占权重较大的情况下,可以将第二权值λ2设置地稍大一些,如可以设置为:0.8、0.85、0.9等等,在此不做限定;或者,诊断分类任务在训练过程中所占权重较小的情况下,可以将第二权值λ2设置地稍小一些,如可以设置为:0.3、0.35、0.4等等,在此不做限定。特别地,可以将第二权值λ2设置为0,即在训练过程中,也可以不计算上述第二损失值。
需要说明的是,本公开实施例所调整的检测模型的网络参数至少包括前述第一编码网络的网络参数和前述第二编码网络的网络参数。此外,在检测模型还包括前述结果预测网络的情况下,所调整的网络参数还可以进一步包括结果预测网络的网络参数。
上述方案,通过获取样本病情文本及其对应的样本诊断文本,以及关于样本病情文本和样本诊断文本是否语义一致的实际结果,从而利用检测模型的第一编码网络对样本诊断文本进行编码,得到样本诊断编码表示,并利用检测模型的第二编码网络对样本病情文本进行编码,得到样本病情编码表示,且样本诊断编码表示包含:样本诊断文本本身的语义信息、样本诊断文本中分词的语义信息和与样本诊断文本相关的参考词语的语义信息,进而利用样本病情编码表示和样本诊断编码表示,预测得到关于样本病情文本和样本诊断文本是否语义一致的预测结果,在此基础上,再利用实际结果和预测结果之间的差异,调整检测模型的网络参数,由于在样本诊断编码表示中融入了样本诊断文本本身的语义信息、样本诊断文本中分词的语义信息和与样本诊断文本相关的参考词语的语义信息等多种与样本诊断文本相关的语义信息,故能够有利于增强样本诊断编码表示,提升检测模型的泛化能力,且由于通过检测模型能够无需人工抽查即可即时检测病历,最终能够提高病历检测的效率和即时性,并降低病历检测的成本。
请参阅图2,图2是本申请检测模型的训练方法另一实施例的流程示意图。本公开实施例中,第一编码网络具体可以包括第一图神经网络,第一图神经网络具体可以为图卷积网络,具体可以参阅前述公开实施例中相关描述,在此不再赘述。本公开实施例具体可以包括如下步骤:
步骤s21:获取样本病情文本及其对应的样本诊断文本,以及关于样本病情文本和样本诊断文本是否语义一致的实际结果。
具体可以参阅前述公开实施例中的步骤,在此不再赘述。
步骤s22:获取至少一个知识图。
本公开实施例中,每一知识图包括多个词语和多个词语之间的相关度,多个词语包括:属于同一词语类别的参考词语、与至少一个参考词语相关的疾病名词,以及参考词语和/或疾病名词中各个分词。也就是说,知识图中包含三种类型的词语:疾病名词本身、与疾病名词相关的参考词语,以及疾病名词和/或参考词语中各个分词。此外,同一知识图中参考词语所属的词语类别是相同的,且不同知识图中参考词语所属的词语类别是不同的。具体地,词语类别可以包括但不限于:症状描述类、部位描述类、病因描述类。以疾病名词“急性上呼吸道感染”为例,其相关的参考词语可以包括:症状描述类参考词语“咳嗽”、“流涕”、“发烧”等,以及部位描述类参考词语“鼻”、“咽”等,以及病因描述类参考词语“受凉”等,具体可以参阅前述公开实施例中相关描述,在此不再赘述。
在一个实施场景中,可以通过人工(如专家、医师等)对各个参考词语标注与其相关的疾病名词。例如,可以通过人工对症状描述类参考词语“咳嗽”标注与其相关的疾病名字“急性上呼吸道感染”、“肺炎”、“咽炎”等,或者,可以通过人工对部位描述类参考词语“鼻”标注与其相关的疾病名词“急性上呼吸道感染”、“鼻疖”﹑“鼻前庭炎”等,或者,可以对病因描述类参考词语“受凉”标注与其相关的疾病名词“关节炎”、“急性上呼吸道感染”等,其他情况可以以此类推,在此不再一一举例。
在另一个实施场景中,也可以通过机器自动对各个参考词语标注与其相关的疾病名词,为了提高准确性,在机器自动标注之后,还可以由人工(如专家、医师等)对自动标注的疾病名词进行校验。
在另一个实施场景中,可以通过分词工具对疾病名词和/或参考词语进行分词,得到疾病名词和/或参考词语中分词。分词工具具体可以参阅前述公开实施例中相关描述,在此不再赘述。
在又一个实施场景中,可以设置参考词语和参考词语中分词之间的相关度为预设数值(如,1)。例如,参考词语“吞咽困难”和“吞咽困难”中分词“吞咽”、“困难”之间的相关度可以设置预设数值(如,1)。为了便于后续第一图神经网络处理,可以将参考词语和参考词语中分词的相关度记为
在又一个实施场景中,可以设置疾病名词和疾病名词中分词之间的相关度为预设数值(如,1)。例如,疾病名词“肺炎”和“肺炎”中分词“肺炎”(疾病名词“肺炎”仅有一个分词,即“肺炎”)之间的相关度可以设置预设数值(如,1)。为了便于后续第一图神经网络处理,可以将疾病名词和疾病名词中分词之间的相关度记为
在又一个实施场景中,可以设置参考词语和与其相关的疾病名词之间的相关度为预设数值(如,1)。例如,疾病名词“肺炎”与症状描述类参考词语“咳嗽”之间的相关度可以设置为预设数值(如,1)。为了便于后续第一图神经网络处理,可以将参考词语和与其相关的疾病名词之间的相关度记为
请结合参阅图3,图3是知识图一实施例的框架示意图。具体地,图3所示的知识图是与症状类参考词语所对应的知识图,如图3所示,以斜线填充的圆形所表示的症状类参考词语,无填充圆形所表示的是与至少一个参考词语相关的疾病名词,而以网格填充的圆形所表示的是疾病名词和/或参考词语中分词。需要说明的是,在疾病名词与参考词语之间、疾病名词与分词之间,以及参考词语与分词之间,以实线相连表示两者之间的相关度为上述预设数值(如,1),未以实线相连表示两者之间的相关度为上述其他数值(如,0)。图3所示的知识图仅仅是实际应用过程中可能存在的一种知识图,并不因此而限定实际应用中可能存在其他知识图的情况,具体可以根据应用情况进行设置,在此不做限定。
请继续结合参阅图3,为了更加准确地描述知识图中各个词语之间的相关度,还需获取疾病名词和/或参考词语中分词之间的相关度,即图3中以网格填充的圆形之间的相关度。请结合参阅图4,图4是获取分词之间相关度一实施例的流程示意图,为了提高分词之间相关度的准确性,可以采取如下步骤:
步骤s41:将样本病历集合内各个样本文本中分词的组合,作为词表。
在一个实施场景中,各个样本文本可以包括但不限于:样本病情文本、样本诊断文本,例如,可以包括诸如“持续发烧、伴咳嗽、咳痰”等样本病情文本,也可以包括诸如“肺炎”等样本诊断文本,在此不做限定。
在一个实施场景中,具体可以采用分词工具对各个样本文本进行分词,并将所得分词的组合,作为词表。例如,在各个样本文本包括前述“持续发烧4天、伴咳嗽、咳痰2天”和“肺炎”的情况下,词表可以为:“持续”、“发烧”、“咳嗽”、“咳痰”、“肺炎”。其他情况可以以此类推,在此不再一一举例。
步骤s42:采用预设窗口在词表中滑动若干次直至滑动至词表末尾,并以任意两个分词为词语对。
在一个实施场景中,预设窗口的长度为预设长度值,预设长度值可以设置为:2、3、4、5等等,在此不做限定。
在一个实施场景中,预设窗口在滑动时的滑动步长可以设置为1个分词长度,即每次可以滑动一个分词。以上述词表为例,在某次滑动时,预设窗口的头部在分词“持续”处,则下次滑动后,预设窗口的头部在分词“发烧”处。其他情况可以以此类推,在此不再一一举例。此外,滑动步长也可以设置为2个分词长度、3个分词长度等等,在此不做限定。
在一个实施场景中,仍以前述词表为例,可以将词表中任意两个分词作为词语对,如可以将分词“持续”和“发烧”作为一个词语对,将分词“发烧”和“咳嗽”作为一个词语对,其他分词可以以此类推,在此不再一一举例。
步骤s43:统计词语对在预设窗口中同时出现的第一次数,并统计词语对中分词在预设窗口中单独出现的第二次数。
在一个实施场景中,仍以前述词表为例,在预设窗口的长度为6且滑动步长为1个分词长度的情况下,第一次滑动时,预设窗口内的分词包括:“持续”、“发烧”、“咳嗽”;第二次滑动时,预设窗口内的分词包括:“发烧”、“咳嗽”、“咳痰”,第三次滑动时,预设窗口内的分词包括:“咳嗽”、“咳痰”、“肺炎”,此时已滑动至词表末尾,可以停止滑动。在此基础上,可以统计词语对“持续”和“发烧”同时出现在预设窗口中的第一次数为1次,分词“持续”单独出现在预设窗口中的第二次数为1次,分词“发烧”单独出现在预设窗口中的第二次数为2次。其他词语对可以以此类推,在此不再一一举例。
步骤s44:基于第一次数和第二次数,获取词语对之间的相关度。
在一个实施场景中,可以进一步统计预设窗口滑动的总次数,仍以前述词表为例,在预设窗口的长度为6且滑动步长为1个分词长度的情况下,预设窗口滑动的总次数为3次。
在一个实施场景中,可以基于第一次数和总次数,可以得到词语对的共现频率,而基于第二词语和总次数,可以得到分词的出现频率,在此基础上,可以获取词语对的互信息,若互信息大于0,则可以将词语对之间的相关度设置为该互信息,反之可以将词语对之间的相关度设置为0。需要说明的是,在词语对中的两个分词相同的情况下,可以认为两者之间的相关度为1。
在另一个实施场景中,为了便于描述,可以将总次数记为#w,将由分词i和分词j组成的词语对在预设窗口中同时出现的第一次数记为#w(i,j),将分词i在预设窗口中单独出现的第二次数记为#w(i),将分词j在预设窗口中单独出现的第二次数记为#w(j),则由分词i和分词j组成的词语对的共现频率p(i,j)可以表示为:
类似地,分词i的出现频率p(i)可以表示为:
类似地,分词j的出现频率p(j)可以表示为:
在此基础上,由分词i和分词j组成的词语对的互信息pmi(i,j)可以表示为:
从而对于分词i和分词j之间的相关度
如上述公式(10)所示,在互信息pmi(i,j)大于0的情况下,可以将分词i和分词j之间的相关度设置为两者之间的互信息,而在分词i和分词j相同的情况下,可以将分词i和分词j之间的相关度设置为1,其他情况(即公式(10)中的otherwise)下,可以将分词i和分词j之间的相关度设置为0。
上述方式,通过将样本病历集合内各个样本文本中分词的组合,作为词表,从而采用预设窗口在词表中滑动若干次直至滑动至词表末尾,并以任意两个分词为词语对,在此基础上,统计词语对在预设窗口中同时出现的第一次数,并统计词语对中分词在预设窗口中单独出现的第二次数,最终基于第一次数和第二次数,获取词语对之间的相关度,能够基于样本病历集合的大量数据来统计分词之间的相关度,进而能够有利于提高分词之间相关度的准确性。
在此基础上,请继续结合参阅图3,知识图中分词之间的相关度可以直接由上述统计得到的相关度提取得到,即可以直接设置
步骤s23:分别将至少一个知识图输入第一图神经网络,得到知识图中各个词语的词语编码表示。
本公开实施例中,样本诊断编码表示包含:样本诊断文本本身的语义信息、样本诊断文本中分词的语义信息和与样本诊断文本相关的参考词语的语义信息。具体可以参阅前述公开实施例中的步骤,在此不再赘述。
在一个实施场景中,可以对多个词语中分词进行向量映射,得到分词的第一向量表示,即可以对疾病名词和/或参考词语中分词进行向量映射,得到第一向量表示,并获取疾病名词和参考词语的第二向量表示,且第二向量表示是在训练过程中与网络参数一起调整的,在此基础上,可以将第一向量表示、第二向量表示和多个词语之间的相关度输入第一图神经网络,得到词语编码表示。具体地,在首次训练时,可以将疾病名词和参考词语的第二向量表示初始化为随机向量,并在之后的训练过程中,随网络参数一起调整其第二向量表示。上述方式,通过对多个词语中分词进行向量映射,得到分词的第一向量表示,并获取疾病名词和参考词语的第二向量表示,且第二向量表示是在训练过程中与网络参数一起调整的,从而将第一向量表示、第二向量表示和多个词语之间的相关度输入第一图神经网络,得到词语编码表示,进而能够使第二向量表示在训练过程中学习到疾病相关知识,故能够有利于提高词语编码表示的准确性,提高检测模型的泛化能力。
在一个具体的实施场景中,以第一图神经网络为gcn为例,在第一图神经网络为两层gcn的情况下,词语编码表示可以表示为:
上述公式(11)中,
在另一个具体的实施场景中,仍以第一图神经网络gcn为例,首先可以利用知识图中词语之间的相关度ai,j处理得到度矩阵di,j,具体可以表示为:
在此基础上,可以利用度矩阵di,j对上述相关度ai,j的相关度矩阵a进行归一化处理,得到矩阵
进一步地,可以利用第l层gcn的网络参数wl对上述矩阵
上述公式(14)中,relu(rectifiedlinearunit,线性整流函数)表示激活函数。对于知识图中各个词语,通过第一图神经网络可以聚合其本身的语义信息,以及与其相关的分词、参考词语、疾病名词的语义信息。而对于疾病名词,不仅能够聚合其本身的语义信息,还能够通过知识图中相关度聚合相关疾病名词、参考词语的语义信息。例如,在采用两层gcn的情况下,疾病名词可以聚合2阶邻居信息。故此,能够有利于进一步提高词语编码表示的准确性,并提升检测模型的泛化能力。
步骤s24:搜索至少一个知识图中与样本诊断文本相同的词语,作为目标词语,并利用目标词语的词语编码表示,得到样本诊断编码表示。
以第k个知识图为例,可以在上述词语编码表示
在提取得到每一知识图中目标词语的词语编码表示之后,可以将各个目标词语的词语编码表示的组合,作为样本诊断文本的样本诊断编码表示。为了便于描述,如前所述,第k个知识图中词语编码表示可以记为
步骤s25:利用检测模型的第二编码网络对样本病情文本进行编码,得到样本病情编码表示。
具体可以参阅前述公开实施例中相关步骤,在此不再赘述。
步骤s26:利用样本病情编码表示和样本诊断编码表示,预测得到关于样本病情文本和样本诊断文本是否语义一致的预测结果。
具体可以参阅前述公开实施例中的步骤,在此不再赘述。
步骤s27:利用实际结果和预测结果之间的差异,调整检测模型的网络参数。
具体可以参阅前述公开实施例中的步骤,在此不再赘述。
需要说明的是,在一次训练之后,可以重新执行上述步骤s23以及后续步骤,以进行后续第j次训练,其中,j为大于1的整数。
区别于前述实施例,通过获取至少一个知识图,且每一知识图包括多个词语和多个词语之间的相关度,多个词语包括:属于同一词语类别的参考词语、与至少一个参考词语相关的疾病名词,以及参考词语和/或疾病名词中各个分词,从而分别将至少一个知识图输入第一图神经网络,得到知识图中各个词语的词语编码表示,进而搜索至少一个知识图中与样本诊断文本相同的词语,作为目标词语,并利用目标词语的词语编码表示,得到样本诊断编码表示,能够有利于通过第一图神经网络和知识图中各个词语之间的相关度,来聚合词语各个本身的语义信息,以及与其相关的分词、参考词语、疾病名词的语义信息,从而能够有利于提高检测模型的泛化能力,并提高词语编码表示的准确性,进而能够提高样本诊断编码表示的准确性。
请参阅5,图5是获取样本病情编码表示一实施例的流程示意图。本公开实施例中,第二编码网络可以包括第二图神经网络,第二图神经网络具体可以为gcn。本公开实施例具体可以包括如下步骤:
步骤s51:获取样本病情文本中若干分词的第三向量表示,并获取若干分词之间的相关度。
在一个实施场景中,可以对样本病情文本中若干分词分别进行向量映射,得到若干分词的第四向量表示,并将若干分词的第四向量表示输入长短期记忆网络,得到若干分词的第三向量表示。故此,通过长短期记忆网络来编码得到第三向量表示,能够有利于从序列角度建模样本病情编码表示,从而能够提高对样本病情文本的建模能力,进而能够有利于提高后续样本病情编码表示的准确性。
为了便于描述,可以将若干词语经向量映射之后,所得到的第四向量表示的组合记为x0,其中,x0∈rh×e,即x0是一个h*e大小的实数矩阵,h为样本病情文本中若干词语的个数,e为第四向量表示的词向量维度。此外,长短期记忆网络具体可以为双向长短期记忆网络(bi-directionallong-shorttermmemory,bilstm)。在此基础上,第三向量表示x1可以表示为:
x1=bilstm(x0),x1∈rh×e……(15)
在一个实施场景中,若干分词之间的相关度,以及至少一个知识图中对应分词之间的相关度相同。请结合参阅图3,以样本病情文本“持续发烧4天、伴咳嗽、咳痰2天”为例,该样本病情文本中分词“咳嗽”和分词“发烧”之间的相关度,以及图3所示的知识图中词语“咳嗽”和词语“发烧”之间的相关度相同,其他情况可以以此类推,在此不再一一举例。具体地,样本病情文本中若干分词之间的相关度具体是从前述公开实施例中词语对之间的相关度
步骤s52:将第三向量表示和若干分词之间的相关度输入第二图神经网络,得到样本病情编码表示。
在一个实施场景中,在第一图神经网络为l层gcn的情况下,第二图神经网络可以为l层gcn,从而能够有利于进一步提高样本病情编码表示和样本诊断编码表示两者输出空间的一致性。
在一个实施场景中,为了便于描述,样本病情编码表示可以记为x2,以第二图神经网络为2层gcn为例,样本病情编码表示x2具体可以表示为:
x2=gcn(gcn(x1,asub),asub),x2∈rh×e……(16)
在另一个实施场景中,gcn的具体处理过程可以参阅前述公开实施例中相关描述,在此不再赘述。
区别于前述实施例,通过获取样本病情文本中若干分词的第三向量表示,并获取若干分词之间的相关度,从而将第三向量表示和若干分词之间的相关度输入第二图神经网络,得到样本病情编码表示,故能够有利于提高样本病情编码表示和样本诊断编码表示两者输出空间的一致性。
请参阅图6,图6是图1中步骤s13一实施例的流程示意图。具体可以包括如下步骤:
步骤s61:基于双线性注意力机制,获取样本病情编码表示和样本诊断编码表示之间的注意力分值。
在一个实施场景中,为了便于描述,双线性注意力机制的网络参数可以记为w,则样本病情编码表示x2和样本诊断编码表示d之间的注意力分值m可以表示为:
m=x2wdt,m∈rh×k,w∈re×e……(17)
如上述公式(17)所示,双线性注意力机制的网络参数w是一个e*e大小的实数矩阵,e的具体含义可以参阅前述公开实施例中相关描述,在此不再赘述。此外,注意力分值m是一个h*k大小的实数矩阵,h和k的具体含义可以参阅前述公开实施例中相关描述,在此不再赘述。
步骤s62:利用注意力分值对样本诊断编码表示进行加权,得到第一加权编码表示,并利用注意力分值对样本病情编码表示进行加权,得到第二加权编码表示。
为了便于描述,可以将第一加权编码表示记为
如上述公式(18)所示,第一加权编码表示
为了便于描述,可以将第二加权编码表示记为
如上述公式(19)所示,第二加权编码表示
步骤s63:利用第一加权编码表示和第二加权编码表示,预测得到预测结果。
如前述公开实施例所述,检测网络还可以包括结果预测网络,该结果预测网络具体可以包括全连接层,在此基础上,可以将第一加权编码表示和第二加权编码表示送入结果预测网络,得到预测结果。为了便于描述,可以将结果预测网络记为mlp,预测结果可以记为ypre,具体可以表示为:
如上述公式(20)所示,预测结果ypre为一实数,该实数具体可以表示样本病情文本和样本诊断文本语义一致的可能性。
区别于前述实施例,基于双线性注意力机制,获取样本病情编码表示和样本诊断编码表示之间的注意力分值,从而利用注意力分值对样本诊断编码表示进行加权,得到第一加权编码表示,并利用注意力分值对样本病情编码表示进行加权,得到第二加权编码表示,进而利用第一加权编码表示和第二加权编码表示,预测得到预测结果,能够有利于在结果预测过程中,通过双线性注意力机制弥合样本诊断编码表示和样本病情编码表示两者输出空间的不同,从而能够有利于提高结果预测的准确性。
请参阅图7,图7是本申请病历检测方法一实施例的流程示意图。具体而言,可以包括如下步骤:
步骤s71:在患者病历中获取病情文本及其对应的诊断文本。
在一个实施场景中,病情文本可以包括但不限于:病人主诉、病人病史等等。具体可以参阅前述公开实施例中关于样本病情文本相关描述,在此不再赘述。
在另一个实施场景中,诊断文本具体可以包括但不限于:第一诊断文本。具体可以参阅前述公开实施例中关于样本病情文本相关描述,在此不再赘述。
步骤s72:获取诊断文本的诊断编码表示,并获取病情文本的病情编码表示。
本公开实施例中,诊断编码表示包含:诊断文本本身的语义信息、诊断文本所含分词的语义信息和与诊断文本相关的参考词语的语义信息。具体可以参阅前述公开实施例中相关描述,在此不再赘述。
在一个实施场景中,如前述公开实施例所述,可以将诊断文本送入诸如bert等编码网络,得到诊断编码表示,并将病情文本送入诸如bert等编码网络,得到病情编码表示,具体可以参阅前述公开实施例中相关描述,在此不再赘述。
在一个实施场景中,下述步骤中检测结果是由检测模型检测得到的,且检测模型是利用上述任一检测模型的训练方法训练得到的。
在一个具体的实施场景中,在此基础上,如前述公开实施例所述,检测模型包括第一编码网络和第二编码网络,且第一编码网络包括第一图神经网络,则可以获取至少一个知识图,并将至少一个知识图输入第一图神经网络,得到知识图中各个词语的词语编码表示,从而搜索至少一个知识图中与诊断文本相同的词语,作为目标词语,并利用目标词语的词语编码表示,得到诊断编码表示。具体可以参阅前述公开实施例中相关描述,在此不再赘述。
在另一个具体的实施场景中,在此基础上,还可以直接收集检测模型最后一次训练过程中,各个样本诊断文本的样本诊断编码表示,从而可以搜索与诊断文本相同的样本诊断文本的样本诊断编码表示,作为诊断文本的诊断编码表示。例如,检测模型最后一次训练之后,可以得到各个样本诊断文本的样本诊断编码表示,如“咽炎”的样本诊断编码表示、“肺炎”的样本诊断编码表示等等,在此不再一一举例。在此基础上,在诊断文本为“咽炎”的情况下,可以直接将“咽炎”的样本诊断编码表示,作为诊断文本“咽炎”的诊断编码表示。上述方式,由于最后一次训练过程中各个样本诊断文本的样本诊断编码表示可以视为样本诊断文本最佳的编码表示,故通过收集检测模型最后一次训练过程中,各个样本诊断文本的样本诊断编码表示,并搜索与诊断文本相同的样本诊断文本的样本诊断编码表示,作为诊断文本的诊断编码表示,能够有利于在降低病历检测的计算负荷,提高病历检测的准确性。
在又一个具体的实施场景中,在此基础上,如前述公开实施例所述,第二编码网络具体可以包含第二图神经网络,则可以获取病情文本中若干分词的向量表示,并获取若干分词之间的相关度,从而可以将若干分词的向量表示和若干分词之间的相关度输入第二图神经网络,得到病情编码表示。具体可以参阅前述公开实施例中的相关描述,在此不再赘述。
步骤s73:利用病情编码表示和诊断编码表示进行一致性检测,得到关于病情文本和诊断文本是否语义一致的检测结果。
在一个实施场景中,如前所述,检测结果是由检测模型检测得到的,且检测模型是利用上述任一检测模型的训练方法训练得到的。此外,如前述公开实施例所述,检测模型还可以包括结果预测网络,从而可以将病情编码表示和诊断编码表示送入结果预测网络,得到检测结果。
在一个实施场景中,具体可以基于双线性注意力机制,获取病情编码表示和诊断编码表示之间的注意力分值,从而利用注意力分值对诊断编码表示进行加权,得到第一加权编码表示,并利用注意力分值对病情编码表示进行加权,得到第二加权编码表示,最终利用第一加权编码表示和第二加权编码表示,预测得到检测结果。
如前述公开实施例所述,为了便于描述,可以将检测结果记为ypre,在得到检测结果ypre之后,可以通过比较检测结果ypre与预设阈值θ之间的大小关系,来确定病情文本和诊断文本是否语义一致。具体地,在检测结果ypre大于预设阈值θ的情况下,可以认为病情文本和诊断文本语义一致,反之可以认为病情文本和诊断文本语义不一致。
请结合参阅图8,图8是本申请病历检测方法一实施例的状态示意图。如图8所示,病情文本中各个分词可以先经过词向量转换,再通过编码得到病情编码表示,而诊断文本可以利用前述任一种方式,得到其诊断编码表示,最终可以根据病情编码表示和诊断编码表示,预测病情文本和诊断文本是否语义一致。
区别于前述实施例,通过在患者病历中获取病情文本及其对应的诊断文本,从而获取诊断文本的诊断编码表示,并获取病情文本的病情编码表示,且诊断编码表示包含:诊断文本本身的语义信息、诊断文本所含分词的语义信息和与诊断文本相关的参考词语的语义信息,进而利用病情编码表示和诊断编码表示进行一致性检测,得到关于病情文本和诊断文本是否语义一致的检测结果,由于在诊断编码表示中融合了诊断文本本身的语义信息、诊断文本中分词的语义信息和与诊断文本相关的参考词语的语义信息等多种与诊断文本相关的语义信息,故能够有利于增强诊断编码表示,有利于提高病历检测的准确性,且由于无需人工抽查即可即时检测病历,最终能够提高病历检测的效率和即时性,并降低病历检测的成本。
请参阅图9,图9是本申请电子设备90一实施例的框架示意图。电子设备90包括相互耦接的存储器91和处理器92,存储器91中存储有程序指令,处理器92用于执行程序指令以实现上述任一检测模型的训练方法实施例中的步骤,或实现上述任一病历检测方法实施例中的步骤。
具体而言,处理器92用于控制其自身以及存储器91以实现上述任一检测模型的训练方法实施例中的步骤,或实现上述任一病历检测方法实施例中的步骤。处理器92还可以称为cpu(centralprocessingunit,中央处理单元)。处理器92可能是一种集成电路芯片,具有信号的处理能力。处理器92还可以是通用处理器、数字信号处理器(digitalsignalprocessor,dsp)、专用集成电路(applicationspecificintegratedcircuit,asic)、现场可编程门阵列(field-programmablegatearray,fpga)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件。通用处理器可以是微处理器或者该处理器也可以是任何常规的处理器等。另外,处理器92可以由集成电路芯片共同实现。
在一些公开实施例中,处理器92用于获取样本病情文本及其对应的样本诊断文本,以及关于样本病情文本和样本诊断文本是否语义一致的实际结果;处理器92用于利用检测模型的第一编码网络对样本诊断文本进行编码,得到样本诊断编码表示,并利用检测模型的第二编码网络对样本病情文本进行编码,得到样本病情编码表示;其中,样本诊断编码表示包含:样本诊断文本本身的语义信息、样本诊断文本中分词的语义信息和与样本诊断文本相关的参考词语的语义信息;处理器92用于利用样本病情编码表示和样本诊断编码表示,预测得到关于样本病情文本和样本诊断文本是否语义一致的预测结果;处理器92用于利用实际结果和预测结果之间的差异,调整检测模型的网络参数。
上述方案,通过获取样本病情文本及其对应的样本诊断文本,以及关于样本病情文本和样本诊断文本是否语义一致的实际结果,从而利用检测模型的第一编码网络对样本诊断文本进行编码,得到样本诊断编码表示,并利用检测模型的第二编码网络对样本病情文本进行编码,得到样本病情编码表示,且样本诊断编码表示包含:样本诊断文本本身的语义信息、样本诊断文本中分词的语义信息和与样本诊断文本相关的参考词语的语义信息,进而利用样本病情编码表示和样本诊断编码表示,预测得到关于样本病情文本和样本诊断文本是否语义一致的预测结果,在此基础上,再利用实际结果和预测结果之间的差异,调整检测模型的网络参数,由于在样本诊断编码表示中融入了样本诊断文本本身的语义信息、样本诊断文本中分词的语义信息和与样本诊断文本相关的参考词语的语义信息等多种与样本诊断文本相关的语义信息,故能够有利于增强样本诊断编码表示,提升检测模型的泛化能力,且由于通过检测模型能够无需人工抽查即可即时检测病历,最终能够提高病历检测的效率和即时性,并降低病历检测的成本。
在一些公开实施例中,第一编码网络包括第一图神经网络,处理器92用于获取至少一个知识图;其中,每一知识图包括多个词语和多个词语之间的相关度,多个词语包括:属于同一词语类别的参考词语、与至少一个参考词语相关的疾病名词,以及参考词语和/或疾病名词中各个分词,处理器92用于分别将至少一个知识图输入第一图神经网络,得到知识图中各个词语的词语编码表示;处理器92用于搜索至少一个知识图中与样本诊断文本相同的词语,作为目标词语,并利用目标词语的词语编码表示,得到样本诊断编码表示。
区别于前述实施例,通过获取至少一个知识图,且每一知识图包括多个词语和多个词语之间的相关度,多个词语包括:属于同一词语类别的参考词语、与至少一个参考词语相关的疾病名词,以及参考词语和/或疾病名词中各个分词,从而分别将至少一个知识图输入第一图神经网络,得到知识图中各个词语的词语编码表示,进而搜索至少一个知识图中与样本诊断文本相同的词语,作为目标词语,并利用目标词语的词语编码表示,得到样本诊断编码表示,能够有利于通过第一图神经网络和知识图中各个词语之间的相关度,来聚合词语各个本身的语义信息,以及与其相关的分词、参考词语、疾病名词的语义信息,从而能够有利于提高检测模型的泛化能力,并提高词语编码表示的准确性,进而能够提高样本诊断编码表示的准确性。
在一些公开实施例中,词语类别包括以下至少一种:症状描述类、部位描述类、病因描述类;和/或,参考词语和参考词语中分词之间的相关度为预设数值;和/或,疾病名词和疾病名词中分词之间的相关度为预设数值;和/或,参考词语和与其相关的疾病名词之间的相关度为预设数值。
区别于前述实施例,将词语类别设置为包括以下至少一种:症状描述类、部位描述类、病因描述类,能够有利于在检测过程中,融入尽可能多的与诊断文本相关的知识,从而能够有利于提高语义一致性检测的准确性;而将参考词语和参考词语中分词之间的相关度设置为预设数值,将疾病名词和疾病名词中分词之间的相关度设置为预设数值,将参考词语和与其相关的疾病名词之间的相关度设置为预设数值,能够有利于降低设置相关度的复杂度。
在一些公开实施例中,处理器92用于将样本病历集合内各个样本文本中分词的组合,作为词表;处理器92用于采用预设窗口在词表中滑动若干次直至滑动至词表末尾,并以任意两个分词为词语对;处理器92用于统计词语对在预设窗口中同时出现的第一次数,并统计词语对中分词在预设窗口中单独出现的第二次数;处理器92用于基于第一次数和第二次数,获取词语对之间的相关度。
区别于前述实施例,通过将样本病历集合内各个样本文本中分词的组合,作为词表,从而采用预设窗口在词表中滑动若干次直至滑动至词表末尾,并以任意两个分词为词语对,在此基础上,统计词语对在预设窗口中同时出现的第一次数,并统计词语对中分词在预设窗口中单独出现的第二次数,最终基于第一次数和第二次数,获取词语对之间的相关度,能够基于样本病历集合的大量数据来统计分词之间的相关度,进而能够有利于提高分词之间相关度的准确性。
在一些公开实施例中,处理器92用于对多个词语中分词进行向量映射,得到分词的第一向量表示,并获取疾病名词和参考词语的第二向量表示;其中,第二向量表示是在训练过程中与网络参数一起调整的;处理器92用于将第一向量表示、第二向量表示和多个词语之间的相关度输入第一图神经网络,得到词语编码表示。
区别于前述实施例,通过对多个词语中分词进行向量映射,得到分词的第一向量表示,并获取疾病名词和参考词语的第二向量表示,且第二向量表示是在训练过程中与网络参数一起调整的,从而将第一向量表示、第二向量表示和多个词语之间的相关度输入第一图神经网络,得到词语编码表示,进而能够使第二向量表示在训练过程中学习到疾病相关知识,故能够有利于提高词语编码表示的准确性,提高检测模型的泛化能力。
在一些公开实施例中,第二编码网络包括第二图神经网络,处理器92用于获取样本病情文本中若干分词的第三向量表示,并获取若干分词之间的相关度;处理器92用于将第三向量表示和若干分词之间的相关度输入第二图神经网络,得到样本病情编码表示。
区别于前述实施例,通过获取样本病情文本中若干分词的第三向量表示,并获取若干分词之间的相关度,从而将第三向量表示和若干分词之间的相关度输入第二图神经网络,得到样本病情编码表示,故能够有利于提高样本病情编码表示和样本诊断编码表示两者输出空间的一致性。
在一些公开实施例中,若干分词之间的相关度,以及至少一个知识图中对应分词之间的相关度相同。
区别于前述实施例,能够在获取样本病情编码表示过程中,使用全局的共现信息对词语进行编码,从而能够在样本病情编码表示中建模全局的词语间相关度,进而能够有利于提高样本病情编码表示的准确性。
在一些公开实施例中,处理器92用于对若干分词进行向量映射,得到若干分词的第四向量表示;处理器92用于将若干分词的第四向量表示输入长短期记忆网络,得到若干分词的第三向量表示。
区别于前述实施例,通过长短期记忆网络来编码得到第三向量表示,能够有利于从序列角度建模样本病情编码表示,从而能够提高对样本病情文本的建模能力,进而能够有利于提高后续样本病情编码表示的准确性。
在一些公开实施例中,处理器92用于基于双线性注意力机制,获取样本病情编码表示和样本诊断编码表示之间的注意力分值;处理器92用于利用注意力分值对样本诊断编码表示进行加权,得到第一加权编码表示,并利用注意力分值对样本病情编码表示进行加权,得到第二加权编码表示;处理器92用于利用第一加权编码表示和第二加权编码表示,预测得到预测结果。
区别于前述实施例,基于双线性注意力机制,获取样本病情编码表示和样本诊断编码表示之间的注意力分值,从而利用注意力分值对样本诊断编码表示进行加权,得到第一加权编码表示,并利用注意力分值对样本病情编码表示进行加权,得到第二加权编码表示,进而利用第一加权编码表示和第二加权编码表示,预测得到预测结果,能够有利于在结果预测过程中,通过双线性注意力机制弥合样本诊断编码表示和样本病情编码表示两者输出空间的不同,从而能够有利于提高结果预测的准确性。
在一些公开实施例中,样本诊断文本包括:与样本病情文本语义一致的第一样本诊断文本、与样本病情文本内涵不一致的至少一个第二样本诊断文本,预测结果包括:样本病情文本和第一样本诊断文本语义一致的第一检测概率、样本病情文本和第二样本诊断文本语义一致的第二检测概率,处理器92用于利用交叉熵损失函数处理第一检测概率和第二检测概率,得到检测模型的第一损失值;处理器92用于利用第一损失值,调整检测模型的网络参数。
区别于前述实施例,通过将样本诊断文本设置为包括:样本诊断文本包括:与样本病情文本语义一致的第一样本诊断文本、与样本病情文本内涵不一致的至少一个第二样本诊断文本,从而对应地,预测结果包括:样本病情文本和第一样本诊断文本语义一致的第一检测概率、样本病情文本和第二样本诊断文本语义一致的第二检测概率,从而利用交叉熵损失函数处理第一检测概率和第二检测概率,得到检测模型的第一损失值,进而利用第一损失值,调整检测模型的网络参数,能够有利于使得检测模型同时学习到正例样本与负例样本之间的不同,提高检测模型的学习效率,并提升检测模型的性能。
在一些公开实施例中,处理器92用于利用样本病情编码表示进行预测,得到第一预测诊断文本,并利用样本诊断编码表示进行预测,得到第二预测诊断文本;处理器92用于利用第一预测诊断文本与第一样本诊断文本之间的差异,以及利用第二预测诊断文本与样本诊断文本之间的差异,得到检测模型的第二损失值;处理器92用于利用第一损失值和第二损失值,调整检测模型的网络参数。
区别于前述实施例,利用样本病情编码表示进行预测,得到第一预测诊断文本,并利用样本诊断编码表示进行预测,得到第二预测诊断文本,从而利用第一预测诊断文本与第一样本诊断文本之间的差异,以及利用第二预测诊断文本与样本诊断文本之间的差异,得到检测模型的第二损失值,进而利用第一损失值和第二损失值,调整检测模型的网络参数,即期望样本病情文本的样本病情编码表示分类至与其语义一致的样本诊断文本,并期望样本诊断文本的样本诊断编码表示分类至其本身(即样本诊断文本本身),故能够在反向传播调整网络参数的过程中,尽量保持病情编码表示和诊断编码表示处于较一致的输出空间,有利于提升两者输出空间的一致性。
在一些公开实施例中,处理器92用于在患者病历中获取病情文本及其对应的诊断文本;处理器92用于获取诊断文本的诊断编码表示,并获取病情文本的病情编码表示;其中,诊断编码表示包含:诊断文本本身的语义信息、诊断文本所含分词的语义信息和与诊断文本相关的参考词语的语义信息;处理器92用于利用病情编码表示和诊断编码表示进行一致性检测,得到关于病情文本和诊断文本是否语义一致的检测结果。
区别于前述实施例,通过在患者病历中获取病情文本及其对应的诊断文本,从而获取诊断文本的诊断编码表示,并获取病情文本的病情编码表示,且诊断编码表示包含:诊断文本本身的语义信息、诊断文本所含分词的语义信息和与诊断文本相关的参考词语的语义信息,进而利用病情编码表示和诊断编码表示进行一致性检测,得到关于病情文本和诊断文本是否语义一致的检测结果,由于在诊断编码表示中融合了诊断文本本身的语义信息、诊断文本中分词的语义信息和与诊断文本相关的参考词语的语义信息等多种与诊断文本相关的语义信息,故能够有利于增强诊断编码表示,有利于提高病历检测的准确性,且由于无需人工抽查即可即时检测病历,最终能够提高病历检测的效率和即时性,并降低病历检测的成本。
在一些公开实施例中,检测结果是由检测模型检测得到的,检测模型是利用上述任一检测模型的训练方法实施例中的步骤训练得到的。
区别于前述实施例,通过检测模型检测得到检测模型检测得到,且检测模型是利用上述任一检测模型的训练方法实施例中的步骤训练得到的,能够有利于进一步增强诊断编码表示,有利于提高病历检测的准确性,且由于无需人工抽查即可即时检测病历,最终能够提高病历检测的效率和即时性,并降低病历检测的成本。
在一些公开实施例中,处理器92用于收集检测模型最后一次训练过程中,各个样本诊断文本的样本诊断编码表示;处理器92用于搜索与诊断文本相同的样本诊断文本的样本诊断编码表示,作为诊断文本的诊断编码表示。
区别于前述实施例,由于最后一次训练过程中各个样本诊断文本的样本诊断编码表示可以视为样本诊断文本最佳的编码表示,故通过收集检测模型最后一次训练过程中,各个样本诊断文本的样本诊断编码表示,并搜索与诊断文本相同的样本诊断文本的样本诊断编码表示,作为诊断文本的诊断编码表示,能够有利于在降低病历检测的计算负荷,提高病历检测的准确性。
请参阅图10,图10是本申请存储装置100一实施例的框架示意图。存储装置100存储有能够被处理器运行的程序指令101,程序指令101用于实现上述任一检测模型的训练方法实施例中的步骤,或实现上述任一病历检测方法实施例中的步骤。
上述方案,能够有利于增强样本诊断编码表示,提升检测模型的泛化能力,且由于通过检测模型能够无需人工抽查即可即时检测病历,最终能够提高病历检测的效率和即时性,并降低病历检测的成本。
在一些实施例中,本公开实施例提供的装置具有的功能或包含的模块可以用于执行上文方法实施例描述的方法,其具体实现可以参照上文方法实施例的描述,为了简洁,这里不再赘述。
上文对各个实施例的描述倾向于强调各个实施例之间的不同之处,其相同或相似之处可以互相参考,为了简洁,本文不再赘述。
在本申请所提供的几个实施例中,应该理解到,所揭露的方法和装置,可以通过其它的方式实现。例如,以上所描述的装置实施方式仅仅是示意性的,例如,模块或单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。另一点,所显示或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些接口,装置或单元的间接耦合或通信连接,可以是电性、机械或其它的形式。
作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部单元来实现本实施方式方案的目的。
另外,在本申请各个实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。上述集成的单元既可以采用硬件的形式实现,也可以采用软件功能单元的形式实现。
集成的单元如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本申请的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的全部或部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)或处理器(processor)执行本申请各个实施方式方法的全部或部分步骤。而前述的存储介质包括:u盘、移动硬盘、只读存储器(rom,read-onlymemory)、随机存取存储器(ram,randomaccessmemory)、磁碟或者光盘等各种可以存储程序代码的介质。
- 还没有人留言评论。精彩留言会获得点赞!