一种蛋白质谱图数据库快速增量构建方法与流程
本发明涉及蛋白质组学中的机器学习技术领域,具体涉及一种蛋白质谱图数据库快速增量构建方法。
背景技术:
蛋白质是人类生命的物质基础,是组成人体一切细胞、组织的重要成分,是生命活动的主要承担者。蛋白质组学是一门大规模、高通量、系统化的研究某一类型细胞、组织或体液中的所有蛋白质组成及其功能的新兴学科,1994年由marcwikins提出。蛋白质组学以蛋白质组为研究对象,旨在大规模水平上研究蛋白质的特征,包括蛋白质种类、表达水平、翻译修饰、相互作用等,由此获得蛋白质水平上关于疾病发生、细胞代谢等过程的整体而全面的认识。蛋白质组是蛋白质和基因组两词的组合,代表着“一种基因组所表达的全部蛋白质”。通过对蛋白质组的研究,不仅能为生命活动规律提供物质基础,也为众多疾病机理的阐明及攻克提供了理论依据和解决途径。
随着人类基因组计划的完成,蛋白质组学的重要性也在不断地提高。目前,以鸟枪法蛋白质组学为核心的自下而上的策略被广泛的使用。随着技术的进步,液相色谱-串联质谱(lc-ms/ms)在蛋白质组学中也有了长足的发展。在鸟枪蛋白组学实验中,通过酶切及lc来分离蛋白混合物,之后使用ms/ms处理生成相应的谱图数据,通过谱图搜库的方法完成肽和蛋白质的定性分析,最后,通过生物信息学分析,得出对生物学有价值的结论或信息。
蛋白质谱图数据库是专门用来存储蛋白质实验数据的谱图库,便于研究者使用,同时在鸟枪法蛋白组学实验中,通常使用搜库方法完成蛋白质的定性操作。但鸟枪法实验通常会产生大量包含相同肽段的高度冗余谱图数据,在搜库时会重复比对,浪费了大量的搜库时间且占用了较多的存储空间,影响肽鉴定的效率。
目前,已出现多种蛋白质谱图聚类工具或方法,如pep-miner、ms-cluster、pride-cluster、maracluster、mscrush、gleams等,通过对同一肽段产生的谱图进行聚类,从聚类簇中选取一致性谱图取代聚类簇,完成谱图的搜库鉴定。算法在一定程度上减少了谱图数据的冗余,提高了肽鉴定的效率。
随着蛋白质组学实验数据的增加,现有的聚类算法弊端也逐渐显露了出来,现有的聚类算法大多采用静态聚类方法进行设计,当新的一批数据需要聚类时,不能利用现有数据库的聚类结果进行聚类,使算法的时效性受到限制;随着新增数据的逐渐增多,算法每次聚类所需开销也在递进增长,增加了数据库存储聚类的成本。
技术实现要素:
为了解决上述问题,本发明提供一种蛋白质谱图数据库快速增量构建方法。
一种蛋白质谱图数据库快速增量构建方法,包括以下步骤:
s1、采用gleams深度嵌入模型中的embedder嵌入器对增量谱图数据进行降维处理,得到降维后的增量数据;通过faiss框架中的indexivfflat索引方法对降维后的增量数据进行索引创建,得到增量数据的索引id文件ic.index;
s2、将蛋白质谱图库的索引id文件db.index与增量数据的索引id文件ic.index索引进行合并,得到合并索引;
s3、采用knn算法,通过增量数据对合并索引进行局部搜索,采用增量聚类方法对新增数据进行初步聚类,得到初步聚类后的增量数据,将初步聚类的数据和聚类库中的数据进行合并:通过单点和批量插入数据的方式实现聚类后的增量数据到蛋白质谱图库的插入操作;
s4、对数据库中的数据进行去除重复操作,同时合并满足阈值的簇中的数据,完成谱图数据库的增量聚类;
s5、存储谱图库的索引,为下次新数据添加时合并使用。
进一步的,gleams深度嵌入模型包括:embedder嵌入器、索引模块、增量聚类模块;所述embedder嵌入器用于降维;所述索引模块用于索引合并,所述索引模块选取indexivfflat作为gleams深度嵌入模型索引,实现了索引合并和便利了索引的自定义;所述增量聚类模块用于聚类。
进一步的,embedder嵌入器中包括共享权重的两个相同的基于深度学习的谱图嵌入模型,两个谱图嵌入模型使用孪生神经网络连接。
进一步的,所述索引模块选用indexivfflat索引。
进一步的,步骤s1在索引创建完成的基础上还包括进行数据搜索,具体包括:
s11、获取高质量的实验谱图数据作为增量数据,将增量数据输入gleams深度嵌入模型,在gleams深度嵌入模型中通过embedder嵌入器对成对输入的增量数据进行降维处理,得到降维后的增量数据;
s12、通过faiss框架中的indexivfflat索引方法对降维后的增量数据进行索引创建,得到增量数据的索引id文件ic.index;
索引创建完成的基础上进行数据搜索,通过knn算法对每条索引索索其最近的1000个邻居,得到knn搜索的索引结果;
s13、对knn搜索的索引结果进行筛选:根据knn搜索的每条索引的value值,对索引key进行降序排列,根据筛选条件对降序排列的索引进行筛选,进而实现对增量谱图的过滤,从增量数据中自动选取簇心进行聚类;
s14、计算邻居索引与簇心索引的距离,合并簇心距离在阈值范围内的簇集合,输出聚类结果,完成增量数据的聚类。
进一步的,在gleams深度嵌入模型中通过embedder嵌入器对成对输入的增量数据进行降维处理,得到降维后的增量数据,具体包括:
s01、将谱图数据中的前体特征、特征强度和参考光谱分别输入两个嵌入模型,在嵌入模型中进行一系列卷积、池化操作,将谱图数据嵌入到新的n维空间中,得到两个嵌入模型分别嵌入到n维空间中的嵌入谱图对;
s02、计算嵌入谱图对之间的欧式距离,根据欧氏距离及label值计算损失函数;
s03、根据损失函数,对谱图对进行惩罚,更新embedder嵌入器的权值,具体操作是:将输入的由相同肽段产生的相似谱图对拉到一起,将由不同肽段产生的负谱图对推开,最终将谱图对映射到新的低维空间中,形成降维后的增量数据。
进一步的,损失函数的计算公式如下:
其中,l表示损失函数,w表示embedder嵌入器中的权重;label表示惩罚项,取值为0或1,label=1表示两个谱图由相同肽段产生,label=0表示两个谱图由不同肽段产生;ea和eb分别表示increment.mzml(增量原始谱图)、database.mzml(数据库原始谱图)通过embedder嵌入器转换之后的特征向量。
进一步的,合并索引前已获得蛋白质谱图库的索引id文件db.index,合并索引时,通过调用faiss库中index函数实现索引数据的添加,之后使用merge_from函数实现索引文件的合并,索引在合并的过程中,根据上层索引的长度,自动递增的添加索引,使得索引连续,便于局部数据搜索;在数据进行搜索时,将增量数据通过合并的索引值进行局部搜索,加快knn搜索速度,提升模型性能。
相对于现有技术,本发明的有益效果如下:
本发明使用动态增量聚类算法,在gleams深度嵌入模型的基础上,使用faiss库高效相似度搜索和聚类框架,利用索引合并的设计方式实现了一种新型的基于gleams的动态增量聚类算法,通过索引合并和单点插入的增量聚类方法,有效的提升了算法的时效性,缩短了数据库聚类插入的时间,有效的解决了数据增量插入和算法的时效性问题。
附图说明
下面结合附图和具体实施方式对本发明做进一步详细的说明。
图1为embedder嵌入器架构图。
图2为基于gleams的增量模型设计图;
图3为gleams模型聚类算法;
图4为基于gleams增量模型算法执行流程图;
图5为模型时间对比图;
图6为增量模型架构图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明的总体思想包括:在gleams深度嵌入模型的基础上加入动态增量聚类算法,使用faiss库高效相似度搜索和聚类框架,利用indexivfflat索引合并的方式实现了一种基于gleams的新型动态增量聚类算法,通过索引合并和单点插入的增量聚类方法,有效的提升了算法的时效性,缩短了数据库聚类插入的时间,有效的解决了数据增量插入和算法的时效性问题。
下述实施例中所使用的gleams深度嵌入模型是基于gleams模型的改进模型,主要改进之处包括:
1.索引的改进:gleams的索引使用的是indexflat2,索引模块选用的索引是indexivfflat。
2.增量聚类算法的加入。
3.采用knn算法进行局部索引搜索和数据合并的方法来减少增量插入的谱图数据,提高单点插入的时间效率。
gleams深度嵌入模型包括:embedder嵌入器、索引模块、增量聚类模块。所述embedder嵌入器用于降维。所述索引模块用于索引合并,所述索引模块选取indexivfflat作为gleams深度嵌入模型索引,实现了索引合并和便利了索引的自定义。所述增量聚类模块用于聚类。
gleams深度嵌入模型是基于孪生神经网络设计的深度嵌入模型,其利用网络间权重相同的特点,通过embedder嵌入器对输入数据进行降维;利用损失函数进行模型的权重更新;通过y惩罚项对标记值进行惩罚;最终通过增量聚类模块中的聚类算法实现对谱图数据的聚类。
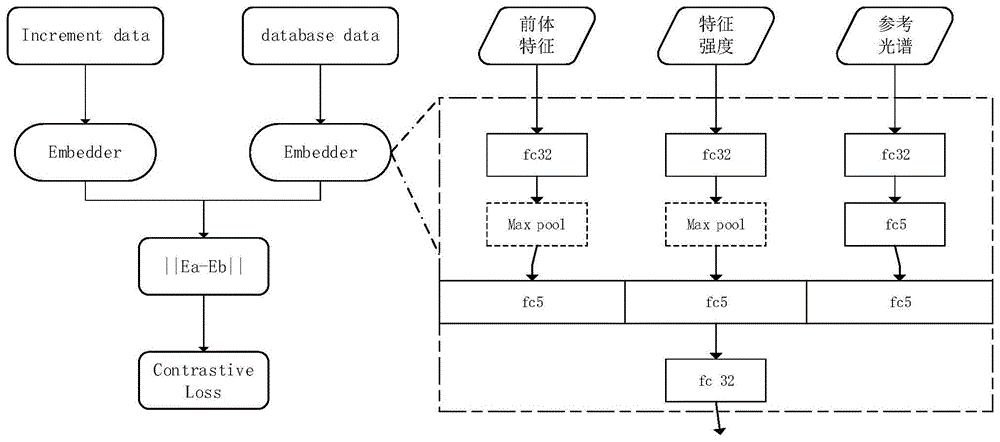
embedder嵌入器架构图如图1所示,嵌入器中包括共享权重的两个相同的基于深度学习的谱图嵌入模型,两个谱图嵌入模型使用孪生神经网络连接。谱图嵌入模型的内部结构包括卷积层(对应附图1中的“fc32”)、最大池化层(对应附图1中的“maxpooling”),对于特征值较少的参考光谱数据使用简单的全连接网络进行特征提取,对于特征值较多的碎片离子数据,将前体特征和特征强度使用卷积池化等操作来提取特征。将上述参考光谱、前提特征和特征强度这三种特征进行整合连接,作为全连接层网络的输入进行处理,输出n(32)维度谱图数据,最终经过embedder模型处理转换,将其映射到新的低维空间中,形成降维后的增量数据特征向量。
embedder嵌入器执行流程如下:
s01、将谱图数据中的前体特征、特征强度和参考光谱分别输入两个谱图嵌入模型,在谱图嵌入模型中进行一系列卷积、池化操作,将谱图数据嵌入到新的n维空间中(n优选为32维度),得到两个谱图嵌入模型分别嵌入到n维空间中的嵌入谱图对。
s02、计算嵌入谱图对之间的欧式距离,根据欧氏距离及lable值计算损失函数l。
损失函数l的计算公式如下:
其中,w表示embedder嵌入器中的权重;label表示惩罚项,取值为0或1,ea和eb分别表示increment.mzml(增量原始谱图)、database.mzml(数据库原始谱图)通过embedder嵌入器转换之后的特征向量。
谱图对附带1或0的label标签来代表相似、不相似的谱图对,如果两个谱图由相同肽段产生,则为相似谱图对,lable=1,如果两个谱图由不同肽段产生,则为负谱图对,label=0。
s03、在进行惩罚时,根据损失函数来更新embedder嵌入器的权值,通过将相同标记对(label=1)上的网络输入拉到一起,将不同标记对(label=0)推开,对谱图对进行惩罚,完成权值的更新,最终将谱图对映射到新的低维空间中,形成降维后的增量数据特征向量。
索引模块的选择
现有的gleams模型选择indexflat2索引方法来对索引进行创建,indexflat2索引方法是一种暴力的精确搜索方式,主要通过计算l2距离来实现knn搜索,当数据集较大时,这种暴力搜索方式的时间复杂度高,效率低。其次,现有的使用indexflat2索引方法的gleams模型在自定义索引列表时,必须通过indexidmap进行封装才可进行索引的自定义,不利于数据的恢复,不易于对原始数据的查找;最为重要的是该索引方法创建的索引无法进行索引合并,每次聚类都无法使用上一次处理好的聚类信息,增长了谱图数据聚类的时间。为解决上述问题,本发明通过对faiss的indexflat2、indexivfflat、indexlsh、indexflatip四种索引方法进行比较验证,如下表:
由表可知,四种索引方法中只有indexivfflat索引方法支持索引合并,虽然indexivfflat索引方法不是精度最高的搜索方法,但其内部通过cell_probe方法能加快数据的搜索,当对整体搜索时,其结果和indexflat2相同;此外,indexivfflat在进行索引自定义时,可直接调用add_with_ids方法完成索引自定义,而indexflat2和indexflatip索引方法需要通过封装来完成,不易于数据恢复。因此,本实施例中,gleams深度嵌入模型选取indexivfflat作为gleams深度嵌入模型的索引,以实现索引合并和便利了索引的自定义。
indexivfflat索引方法通过merge_from来实现索引的合并。索引在合并的过程中,根据上层索引的长度,自动递增的添加索引,使得索引连续,便于局部数据搜索。在数据进行搜索时,将增量数据通过合并的索引值进行局部搜索,加快knn搜索速度,提升模型性能。
增量聚类模型采用增量聚类算法实现聚类。
传统的聚类算法是一种无监督学习的方法,无需提供标号信息,自动对数据进行分类。现有的聚类算法可分为层次聚类、划分聚类、密度聚类、网格聚类、模型聚类以及谱聚类等。增量聚类算法是维持或改变k个簇的结构问题,通过对新增数据的划分来改变原有簇的结构。增量聚类算法通过计算每条新增的数据到现有聚类簇中心距离是否满足阈值范围来进行判断,实现对聚类库中数据的更新。增量聚类算法使用单点数据进行聚类。
增量聚类算法的处理过程包括聚类初始化点的选择、聚类过程中对簇的调整以及对聚类簇的有效评估。初始化点的选取会影响聚类的准确度,常使用随机抽样法、距离优化法和密度评估法来进行初始化选择;增量在聚类过程中,由于新的数据的添加,可能会对现有簇进行合并、分解或产生新的簇,通过对内置簇结构进行合理的调整,来提高聚类簇的了精度和效率;因选择合适的算法和参数来评估算法的有效性。增量聚类算法与传统聚类算法相比,有效的减少了内外部存储器时间和内存的开销,通过单点或批量聚类,有效的解决了传统聚类不能利用已有聚类信息聚类的弊端,提高了聚类的时间。
在一些可选的实施例中,增量聚类算法可以选择基于层次聚类的增量算法、划分聚类的增量算法或者基于密度聚类的增量算法中的任意一种或多种的组合。
gleams深度嵌入模型中增量聚类方法的选择如图2所示:为解决数据库增量聚类问题,需要在gleams模型中加入增量聚类方法来实现数据库基于增量数据进行添加。在三种增量聚类方法中,通过聚类结果和所处理的数据类型进行划分,选择出合适的增量聚类算法与gleams模型结合。比较结果如下表:
上表中,前两组算法是基于层次的聚类算法,3、4是基于划分的聚类算法,后两组是基于密度的聚类算法。由于蛋白质谱图数据是高维数据,经过gleams模型降维后依然有32维度,为使得聚类数据拥有较好的可解释性,需对聚类算法进行选取。通过上表可知,三类聚类算法在scalability(可扩展性)上由于基于密度聚类的扩展性低,故不作为选择的标准。对于剩余两种算法的选择,在dimension(高维)和disturbing(抗干扰性)相似的情况下,通过(effectiveness)算法效率和单点插入性能比较,k-means算法在数据进行单点插入时性能较高,因此选取基于划分聚类的k-means算法作为聚类算法,在此基础上使用增量算法与gleams模型结合,完成数据的增量操作。
在gleams深度嵌入模型的基础上使用增量聚类算法,能够在很好的运用在大数据背景下进行聚类,实现数据库的动态增量聚类。
本实施例提供一种蛋白质谱图数据库快速增量构建方法,其特征在于,包括但不限于以下步骤:
s1、获得增量数据的索引。采用gleams深度嵌入模型中的embedder嵌入器对增量谱图数据进行降维处理,得到降维后的增量数据;通过faiss框架中的indexivfflat索引方法对降维后的增量数据进行索引创建,得到增量数据的索引id文件ic.index。
具体的,gleams深度嵌入模型流程图如图3所示,包括如下步骤:
s11、获取高质量的实验谱图数据作为增量数据,将增量数据输入gleams深度嵌入模型,在gleams深度嵌入模型中通过embedder嵌入器对成对输入的增量谱图数据进行降维处理,得到降维后的增量数据;
s12、通过faiss框架中的indexivfflat索引方法对降维后的增量数据进行索引创建,得到增量数据的索引id文件ic.index。
索引创建完成的基础上实现数据的搜索,包括:向蛋白质谱图数据库中加入降维后的增量数据,通过knn算法对每条索引索其最近的1000个邻居,得到knn搜索的索引结果;
s13、对knn搜索的索引结果进行筛选:根据knn搜索的每条索引的value值,对索引key进行降序排列,根据筛选条件对降序排列的索引进行筛选,进而实现对增量谱图的过滤,从增量数据中自动选取簇心进行聚类。
筛选条件:当一个索引key被选为簇心时,在之后的选取中,该索引key不再以邻居的身份出现。
具体地,根据knn搜索的每条索引的value值的个数对索引key进行降序排列,在进行簇心的自动选取时,当一个索引key被选为簇心时,在之后的选取中,该索引key不能再以邻居的身份出现,目的是为了尽可能保证每个簇的唯一性,不相交。
s14、计算邻居索引与簇心索引的距离,合并所有簇心距离在阈值范围内的簇集合,输出聚类结果,完成增量数据的聚类。
在faiss框架进行索引创建时,通过faiss.indexivfflat()创建索引index,在此基础上利用index.add()方法加入降维后的增量数据,最后基于gpu完成索引的创建,并将索引文件存储为ic.index。
步骤s1中进行聚类的目的是获得降维后的增量数据文件和增量数据的索引文件,增量数据的索引用于在后续步骤中和蛋白质谱图库的索引进行合并,避免gleams对新加入的数据从头建立索引,节省索引建立的时间。此外,需要说明的是,步骤s1只是对增量数据进行处理,不涉及谱图数据和谱图库数据的动态插入。
s2、索引合并:将蛋白质谱图库的索引id文件db.index与聚类索引簇的索引id文件ic.index索引进行合并,得到合并索引。
合并索引前已获得蛋白质谱图库的索引id文件db.index,合并索引时,通过调用faiss库中index.add()函数实现索引数据的添加,之后使用merge_from函数实现索引文件的合并,索引在合并的过程中,根据上层索引的长度,自动递增的添加索引,使得索引连续,便于局部数据搜索;在数据进行搜索时,将增量数据通过合并的索引值进行局部搜索,加快knn搜索速度,提升模型性能。
s3、数据合并,即数据的增量插入。将初步聚类的数据和蛋白质谱图库中的数据进行合并,具体实施过程是:首先进行局部搜索:采用knn算法,通过增量数据对合并索引进行局部搜索,采用增量聚类方法对新增数据进行初步聚类,得到初步聚类后的增量数据。对合并索引进行局部搜索可以加快knn搜索的时间。通过单点和批量插入数据的方式将初步聚类后的增量数据插入到蛋白质谱图库中。
s4、去重。增量数据插入蛋白质谱图数据库后,对蛋白质谱图数据库中的数据进行去除重复操作,同时合并满足阈值的簇中的数据,完成蛋白质谱图数据库的增量聚类。
增量数据插入蛋白质谱图数据库后,由于局部索引数据搜索,可能存在重复的数据插入到数据库中,因此需要对增量过后的数据库进行清理。使用倒排索引的方法,删除重复数据;增量数据插入后,会产生大量新的谱图簇,为使得每个簇所表示属性的唯一性,对簇的质心之间的距离进行计算,判断是否满足设定阈值范围之内,若在设定阈值范围之内,则对两簇进行合并,往数据量多的属性簇合并。
s5、存储索引,为下次新数据添加时合并使用。需要说明的是,该步骤存储的索引是谱图库和增量数据合并的索引。谱图库在最初创建时会有一个蛋白质谱图库数据的索引,在此索引的基础上,对新增数据的索引进行合并,这样的做法是为了保证更多的谱图被识别出来,从而有助于更准确的聚类。
为了使本发明的蛋白质谱图数据库快速增量构建方法更加清楚完整,通过一个具体实施例进行进一步的说明。
首先,获取质谱数据,将数据分为两部分,增量数据ic{x1,x2,...,xi,...,xm}和数据库数据db{y1,y2,...,yi,...,yn}。构造对比实验,分别将db数据和ic数据以及db+ic数据通过改进的gleams算法进行聚类,生成对应的数据文件分别将其存储为.index索引文件,.h5谱图数据文件,_e.h5降维谱图数据文件以及_con.txt聚类簇索引文件。
其次,对索引进行合并搜索。将数据处理阶段的ic数据文件和db的数据文件.index通过faiss的merge_from方法进行索引,在索引合并的过程中,通过提供ic和db的索引数据文件.h5来创建索引;索引创建后,将.h5数据文件的数据添加到索引merge_from方法中,实现索引数据的合并。索引合并时,根据ic和db数据的行数自动有序的进行索引的构建,当ic的数据添加完成后,自动添加db的数据。索引构建完毕后,对ic的数据通过index.search搜索方法并利用knn进行局部索引搜索,快速实现指定邻居个数的查找。通过gleams算法对ic数据的邻居进行去重、阈值筛选、簇质心限制策略以及簇合并操作构建出基于ic的聚类簇,最终生成合并索引merge_index文件和ic_con.txt文件。
第三,增量聚类的设计。获取前两步骤中db_con.txt文件和ic_con.txt文件进行数据读取,将其分别存储在集合db.map和ic.map中,通过set方法找出ic.map中的value值和db.map的key值之间的关系集合:t=set(ic:value).intersection(db.keys())。通过集合t之间的关系,对相关的两个或多个集合进行排序和阈值筛选,选取value值多的key作为主要合并簇,将其余的簇的value值在阈值的筛选下进行合并,保留不满足条件的value值,将其存取在列表list中;对集合ic.map和db.map通过update进行合并为s.map,按value值对集合进行倒序排列,进行去重操作,根据key必定不能是value的筛选条件进行再次筛选,利用key值保证簇的唯一性;之后,对list列表中的数据进行基于单点的插入操作,减少谱图的丢失;将处理好的数据文件进行存储,数据存储为increment.txt。
最后,将gleams增量聚类簇文件gleams_con.txt和增量聚类簇文件increment.txt进行数据比对,通过时间、聚类簇、谱图差异个数来判定模型优劣。算法执行流程图如图4所示。
验证基于gleams模型增量聚类算法的聚类时间性能,本实施例通过两组对比实验进行验证。实验数据集分别来自param-medicsoftware和pridecluster,从中选取编号为pxd0097的数据作为第一组实验数据;选取编号为pxd0561的数组作为第二组实验数据。
实验分为三个阶段,第一阶段是验证不同的faiss索引来对gleams模型聚类效率的影响,选取合适的索引类型对gleams进行优化。实验中选取一组质谱文件pxd和pxd15作为实验数据,设置6个对照实验来择优选取合适的索引类型和搜索方法。实验设计表如下:
通过表中的6个对照实验可知,最优的索引选择方案是编号为1的indexflat2索引且搜索方法为knn。但该索引不具有索引合并的功能。随着数据集的逐渐增大,该方法每次聚类都要重新构建索引,对新的数据集进行降维处理,会带来很大的时间消耗;使用该索引进行计算时,由于gleams算法是按照knn搜索的元素的个数按从大到小排列的方式进行簇质心的筛选,导致每次产生的簇不同,不易于进行对比试验。实验2和3选取了可合并的索引方法indexivfflat,通过控制indexreconstruct变量进行实验对比,由结果可知,通过索引合并的方法所得结果和直接聚类结果相同,验证了merge_from的可用性。实验4验证搜索方法对聚类效率的影响。4.1和4.2验证在不同索引下,range_search对结果的影响。4.2和4.3验证索引合并前后range_search对结果的影响。通过结果和需求,最终将实验3作为索引聚类的最优选择方案。
第二阶段通过不同量级的数据集验证增量数据谱图聚类的精确度。通过两组实验进行验证。第一组实验数据来自pxd0097,大小为11.4g,由6个后缀名为.mzml的质谱数据文件构成。实验先分别对一批数据进行处理,生成增量数据和谱图库数据,之后增量数据采用逐一增加的方法向谱图库中进行增量聚类。实验结果如表:
第二组实验数据来自pxd0561,大小为60g。为验证增量模型在大数据上的泛化能力和性能,构造大数据集的谱图库,增量数据使用小样本进行添加。实验结果如图表:
通过表两表中的数据,我们可以得出结论,增量算法随着数据集的增加,差异谱图的比值控制在1%以内,且随着数据的增加,增量算法所聚类的簇的个数有所增加。增量模型在大数据下的增量泛化能力强,性能高。相比原模型可知,增量模型通过牺牲少量的谱图数来提高聚类的性能,增加谱图簇聚类的个数。
第三阶段是在第二阶段的基础上验证增量模型的时间效率。实验数据集来自pxd0561和pxd0097。实验中,通过对数据降维、faiss搜索和簇文件处理输出三部分时间的记录来表示原模型gleams的聚类时间;通过对单谱图文件聚类、索引合并搜索和增量聚类、簇处理输出三部分时间的记录表示增量模型的聚类时间。实验结果如图5所示。
图5(a)是pxd0097数据的时间性能对比图。在小数据集上进行增量聚类。由图可知,在首次聚类时,增量模型会消耗一定的时间来对增量数据进行处理,所消耗的时间相对原模型要高。之后的聚类过程中,因增量模型可利用前一次处理好的增量数据,所以时间性能大大提升。在小数据集下,增量模型时间效率能提高30%左右。
图5(b)是pxd0561数据的时间性能对比图。在大数据集上进行增量聚类。由图可知,在大数据集下,增量模型的性能更好,除首次聚类消耗大量时间外,时间性能大幅提高98%左右,模型泛化能力强。
本发明利用增量聚类的思想对gleams模型进行改进。设计出一种基于faiss的全新的增量聚类模型。模型架构图如图6所示。该模型使用indexivfflat索引对索引进行合并,极大的缩短了数据索引创建的时间,并设计增量算法,使用单点插入的方式对数据进行增量插入,将数据差异限制在0.01以内,保证了算法的可靠性;算法在一定程度上提高了聚类簇的个数,大大减少了聚类的时间,使得数据能更好、更快的通过增量聚类的方法插入到数据库中。
当介绍本申请的各种实施例的元件时,冠词“一”、“一个”、“这个”和“所述”都意图表示有一个或多个元件。词语“包括”、“包含”和“具有”都是包括性的并意味着除了列出的元件之外,还可以有其它元件。
需要说明的是,本领域普通技术人员可以理解实现上述方法实施例中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,所述的程序可存储于一计算机可读取存储介质中,该程序在执行时,可包括如上述各方法实施例的流程。其中,所述存储介质可为磁碟、光盘、只读存储记忆体(read-0nlymemory,rom)或随机存储记忆体(randomaccessmemory,ram)等。
以上所述仅是本申请的具体实施方式,应当指出,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
- 还没有人留言评论。精彩留言会获得点赞!