机器学习引导的多肽分析的制作方法
机器学习引导的多肽分析
1.相关申请
2.本技术要求于2019年2月11日提交的美国临时申请号62/804,034以及于2019年2月11日提交的美国临时申请号62/804,036的权益。将上述申请的全部传授内容通过援引并入本文。
背景技术:
3.蛋白质是生物体所必需的大分子,并在生物体内执行许多功能或与许多功能相关,这些功能包括例如催化代谢反应、促进dna复制、响应刺激、为细胞和组织提供结构、以及转运分子。蛋白质由一条或多条氨基酸链构成,并且典型地形成三维构象。
技术实现要素:
4.本文描述了用于评估蛋白质或多肽信息以及在一些实施例中产生性质或功能的预测的系统、装置、软件和方法。蛋白质性质和蛋白质功能是描述表型的可测量值。在实践中,蛋白质功能可以指主要治疗功能,并且蛋白质性质可以指其他所需的药物样性质。在本文描述的系统、装置、软件和方法的一些实施例中,鉴定了氨基酸序列和蛋白质功能之间的以前未知的关系。
5.传统上,基于氨基酸序列的蛋白质功能预测具有很高的挑战性,至少部分是由于由看似简单的一级氨基酸序列可能产生的结构复杂性。传统的方法是基于具有已知功能的蛋白质之间的同源性(或其他类似方法)应用统计比较,这未能提供基于氨基酸序列预测蛋白质功能的准确且可重复的方法。
6.事实上,关于基于一级序列(例如dna、rna或氨基酸序列)的蛋白质预测的传统思想是,一级蛋白质序列不能与已知功能直接关联,因为如此多的蛋白质功能是通过其最终的三级(或四级)结构驱动的。
7.与关于蛋白质分析的传统方法和传统思想相反,本文描述的创新系统、装置、软件和方法使用创新的机器学习技术和/或先进的分析来分析氨基酸序列,以准确和可重复地鉴定氨基酸序列和蛋白质功能之间的以前未知的关系。也就是说,鉴于关于蛋白质分析和蛋白质结构的传统思想,本文描述的创新是出乎意料的并且产生了出乎意料的结果。
8.本文描述了为所需蛋白质性质建模的方法,该方法包括:(a)提供包含神经网嵌入器和任选的神经网预测器的第一预训练系统,该预训练系统的神经网预测器不同于该所需蛋白质性质;(b)将预训练系统的神经网嵌入器的至少一部分迁移到包含神经网嵌入器和神经网预测器的第二系统,该第二系统的神经网预测器提供该所需蛋白质性质;以及(c)通过该第二系统分析蛋白质分析物的一级氨基酸序列,从而生成该蛋白质分析物的该所需蛋白质性质的预测。
9.本领域普通技术人员可以认识到,在一些实施例中,一级氨基酸序列可以是给定蛋白质分析物的完整或部分氨基酸序列。在实施例中,氨基酸序列可以是连续序列和不连续序列。在实施例中,氨基酸序列与蛋白质分析物的一级序列具有至少95%的同一性。
10.在一些实施例中,第一系统和第二系统的神经网嵌入器的架构是独立地选自vgg16、vgg19、deep resnet、inception/googlenet(v1
‑
v4)、inception/googlenet resnet、xception、alexnet、lenet、mobilenet、densenet、nasnet或mobilenet的卷积架构。在一些实施例中,第一系统包含生成式对抗网络(gan)、递归神经网络、或变分自编码器(vae)。在一些实施例中,第一系统包含选自条件式gan、dcgan、cgan、sgan或渐进式生成式对抗网络gan、sagan、lsgan、wgan、ebgan、began或infogan的(gan)。在一些实施例中,第一系统包含选自bi
‑
lstm/lstm、bi
‑
gru/gru或转换器网络的递归神经网络。在一些实施例中,第一系统包含变分自编码器(vae)。在一些实施例中,嵌入器用一组至少50、100、150、200、250、300、350、400、450、500、600、700、800、900或1000个或更多个氨基酸序列蛋白质氨基酸序列进行训练。在一些实施例中,氨基酸序列包括跨功能表示的注释,这些功能表示包括gp、pfam、关键字、kegg本体论、interpro、supfam或orthodb中的至少一种。在一些实施例中,蛋白质氨基酸序列具有至少约1万、2万、3万、4万、5万、7.5万、10万、12万、14万、15万、16万或17万个可能的注释。在一些实施例中,相对于未使用第一模型的迁移嵌入器而训练的模型,第二模型具有改进的性能指标。在一些实施例中,第一系统或第二系统由adam、rms prop、具有动量的随机梯度下降(sgd)、具有动量和nestrov加速梯度的sgd、不具有动量的sgd、adagrad、adadelta或nadam优化。可以使用以下激活函数中的中任一个来优化该第一模型和该第二模型:softmax、elu、selu、softplus、softsign、relu、tanh、sigmoid、hard_sigmoid、指数、prelu和leaskyrelu或线性。在一些实施例中,神经网嵌入器包含至少10、50、100、250、500、750或1000或更多个层,并且预测器包含至少1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19或20或更多个层。在一些实施例中,第一系统或第二系统中的至少一个利用选自以下的正则化:提前停止、l1
‑
l2正则化、残差连接或其组合,其中在1、2、3、4、5或更多个层上执行该正则化。在一些实施例中,使用批归一化执行该正则化。在一些实施例中,使用组归一化执行该正则化。在一些实施例中,第二系统的第二模型包含第一系统的第一模型,其中去除了最后一层。在一些实施例中,在迁移到该第二模型时,该第一模型的2、3、4、5或更多个层被去除。在一些实施例中,在该第二模型的训练期间,这些迁移层被冻结。在一些实施例中,在该第二模型的训练期间,这些迁移层被解冻。在一些实施例中,该第二模型具有1、2、3、4、5、6、7、8、9、10或更多个层添加到该第一模型的迁移层。在一些实施例中,该第二系统的神经网预测器预测蛋白质结合活性、核酸结合活性、蛋白质溶解度和蛋白质稳定性中的一种或多种。在一些实施例中,该第二系统的神经网预测器预测蛋白荧光。在一些实施例中,该第二系统的神经网预测器预测酶。
11.本文描述了一种用于鉴定氨基酸序列和蛋白质功能之间以前未知的关联的计算机实施的方法,该方法包括:(a)使用第一机器学习软件模块生成多个蛋白质性质和多个氨基酸序列之间的多个关联的第一模型;(b)将该第一模型或其部分迁移到第二机器学习软件模块;(c)由该第二机器学习软件模块生成包含该第一模型或其部分的第二模型;以及(d)基于该第二模型,鉴定该氨基酸序列和该蛋白质功能之间以前未知的关联。在一些实施例中,该氨基酸序列包含一级蛋白质结构。在一些实施例中,该氨基酸序列导致蛋白质构型,该蛋白质构型产生蛋白质功能。在一些实施例中,该蛋白质功能包含荧光。在一些实施例中,该蛋白质功能包含酶活性。在一些实施例中,该蛋白质功能包含核酸酶活性。示例核酸酶活性包括限制性、核酸内切酶活性和序列引导的核酸内切酶活性(例如cas9核酸内切
酶活性)。在一些实施例中,该蛋白质功能包含蛋白质稳定性程度。在一些实施例中,该多个蛋白质性质和该多个氨基酸序列来自uniprot。在一些实施例中,该多个蛋白质性质包含标签gp、pfam、关键字、kegg本体论、interpro、supfam和orthodb中的一种或多种。在一些实施例中,该多个氨基酸序列包括多个蛋白质的一级蛋白质结构、二级蛋白质结构和三级蛋白质结构。在一些实施例中,氨基酸序列包括可在折叠蛋白质中形成一级、二级和/或三级结构的序列。
12.在一些实施例中,该第一模型用输入数据进行训练,该输入数据包含多维张量、3维原子位置的表示、成对相互作用的邻接矩阵和字符嵌入中的一种或多种。在一些实施例中,该方法包括向第二机器学习模块输入与一级氨基酸序列的突变、氨基酸相互作用的接触图、三级蛋白质结构和来自可变剪接转录物的预测同种型相关的数据中的至少一种。在一些实施例中,该第一模型和该第二模型使用监督学习进行训练。在一些实施例中,该第一模型使用监督学习进行训练,并且该第二模型使用无监督学习进行训练。在一些实施例中,该第一模型和该第二模型包含含有卷积神经网络、生成式对抗网络、递归神经网络或变分自编码器的神经网络。在一些实施例中,该第一模型和该第二模型各自包含不同的神经网络架构。在一些实施例中,该卷积网络包含vgg16、vgg19、deep resnet、inception/googlenet(v1
‑
v4)、inception/googlenet resnet、xception、alexnet、lenet、mobilenet、densenet、nasnet或mobilenet中的一个。在一些实施例中,该第一模型包含嵌入器,并且该第二模型包含预测器。在一些实施例中,第一模型架构包含多个层,并且第二模型架构包含该多个层中的至少两个层。在一些实施例中,该第一机器学习软件模块用包含至少10,000个蛋白质性质的第一训练数据集训练该第一模型,并且该第二机器学习软件模块使用第二训练数据集训练该第二模型。
13.本文描述了一种用于鉴定氨基酸序列和蛋白质功能之间以前未知的关联的计算机系统,该系统包含:(a)处理器;(b)用软件编码的非暂态计算机可读介质,该软件被配置用于使该处理器:(i)使用第一机器学习软件模型生成多个蛋白质性质和多个氨基酸序列之间的多个关联的第一模型;(ii)将该第一模型或其部分迁移到第二机器学习软件模块;(iii)由该第二机器学习软件模块生成包含该第一模型或其部分的第二模型;(iv)基于该第二模型,鉴定该氨基酸序列和该蛋白质功能之间以前未知的关联。在一些实施例中,该氨基酸序列包含一级蛋白质结构。在一些实施例中,该氨基酸序列导致蛋白质构型,该蛋白质构型产生蛋白质功能。在一些实施例中,该蛋白质功能包含荧光。在一些实施例中,该蛋白质功能包含酶活性。在一些实施例中,该蛋白质功能包含核酸酶活性。在一些实施例中,该蛋白质功能包含蛋白质稳定性程度。在一些实施例中,该多个蛋白质性质和该多个蛋白质标记物来自uniprot。在一些实施例中,该多个蛋白质性质包含标签gp、pfam、关键字、kegg本体论、interpro、supfam和orthodb中的一种或多种。在一些实施例中,该多个氨基酸序列包括多个蛋白质的一级蛋白质结构、二级蛋白质结构和三级蛋白质结构。在一些实施例中,该第一模型用输入数据进行训练,该输入数据包含多维张量、3维原子位置的表示、成对相互作用的邻接矩阵和字符嵌入中的一种或多种。在一些实施例中,该软件被配置为使该处理器向该第二机器学习模块输入与一级氨基酸序列的突变、氨基酸相互作用的接触图、三级蛋白质结构和来自可变剪接转录物的预测同种型相关的数据中的至少一种。在一些实施例中,该第一模型和该第二模型使用监督学习进行训练。在一些实施例中,该第一模型使用
监督学习进行训练,并且该第二模型使用无监督学习进行训练。在一些实施例中,该第一模型和该第二模型包含含有卷积神经网络、生成式对抗网络、递归神经网络或变分自编码器的神经网络。在一些实施例中,该第一模型和该第二模型各自包含不同的神经网络架构。在一些实施例中,该卷积网络包含vgg16、vgg19、deep resnet、inception/googlenet(v1
‑
v4)、inception/googlenet resnet、xception、alexnet、lenet、mobilenet、densenet、nasnet或mobilenet中的一个。在一些实施例中,该第一模型包含嵌入器,并且该第二模型包含预测器。在一些实施例中,第一模型架构包含多个层,并且第二模型架构包含该多个层中的至少两个层。在一些实施例中,该第一机器学习软件模块用包含至少10,000个蛋白质性质的第一训练数据集训练该第一模型,并且该第二机器学习软件模块使用第二训练数据集训练该第二模型。
14.在一些实施例中,对所需蛋白质性质建模的方法包括用第一组数据训练第一系统。第一系统包括第一神经网转换器编码器和第一解码器。预训练系统的第一解码器被配置为生成与所需蛋白质性质不同的输出。该方法进一步包括将该预训练系统的第一转换器编码器的至少一部分迁移到第二系统,该第二系统包含第二转换器编码器和第二解码器。该方法进一步包括用第二组数据训练该第二系统。该第二组数据包括一组蛋白质,该组蛋白质表示比第一组数据数量更少的蛋白质类别,其中这些蛋白质类别包括以下中的一种或多种:(a)该第一组数据内的蛋白质类别,以及(b)从该第一组数据中排除的蛋白质类别。该方法进一步包括通过该第二系统分析蛋白质分析物的一级氨基酸序列,从而生成该蛋白质分析物的所需蛋白质性质的预测。在一些实施例中,第二组数据可以包括一些与第一组数据重叠的数据,或者完全与第一组数据重叠的数据。可替代地,在一些实施例中,第二组数据与第一组数据没有重叠数据。
15.在一些实施例中,蛋白质分析物的一级氨基酸序列可以是一个或多个天冬酰胺酶序列和相应的活性标签。在一些实施例中,第一组数据包含一组蛋白质,该组蛋白质包括多种蛋白质类别。示例蛋白质类别包括结构蛋白、收缩蛋白、贮藏蛋白、防御蛋白(例如抗体)、转运蛋白、信号蛋白和酶蛋白。通常,蛋白质类别包括具有共享一种或多种功能相似性和/或结构相似性的氨基酸序列的蛋白质,并且包括以下描述的蛋白质类别。本领域普通技术人员可以进一步理解,这些类别可以包括基于生物物理性质的分组,例如溶解度、结构特征、二级或三级基序、热稳定性和本领域已知的其他特征。第二组数据可以是一个蛋白质类别,例如酶。在一些实施例中,系统可被适配用于执行以上方法。
附图说明
16.本专利或申请文件包含至少一个彩色附图。应请求并且支付必要的费用后,具有一个或多个彩色附图的本专利或专利申请公开的副本将由专利局提供。
17.前述内容从接下来对示例性实施例进行的更具体的说明中将是明显的,如在附图中所示的,在附图中,相同的参考符号在不同图中代表相同部分。附图并非必定按比例,而是将重点放在说明实施例上。
18.本发明的新颖特征在所附权利要求书中详细阐述。通过参考下面的详细描述和附图,将获得对本发明特征和优点的更好理解,下面的详细描述阐述了说明性实施例,其中利用了本披露的原理,并且附图中:
19.图1示出了基础深度学习模型的输入块的综述;
20.图2示出了深度学习模型的恒等残差块(identity block)的实例;
21.图3示出了深度学习模型的卷积残差块(convolutional block)的实例;
22.图4示出了深度学习模型的输出层的实例;
23.图5示出了使用如实例1中描述的第一模型作为起点和如实例2中描述的第二模型,小蛋白的预期的稳定性相对于预测的稳定性;
24.图6示出了不同机器学习模型的预测的数据相对于测量的数据的皮尔逊(pearson)相关性随模型训练中使用的经标记的蛋白序列的数量的变化;预训练表示第一模型被用作第二模型的起点的方法,如在特定蛋白的荧光功能上进行训练;
25.图7示出了不同机器学习模型的肯定预测能力随模型训练中使用的经标记的蛋白序列的数量的变化。预训练(完整模型)表示第一模型被用作第二模型的起点的方法,如在特定蛋白的荧光功能上进行训练;
26.图8示出了被配置为执行本披露的方法或功能的系统的实施例;以及
27.图9示出了过程的实施例,通过该过程第一模型用带注释的uniprot序列进行训练并用于通过迁移学习生成第二模型。
28.图10a是说明本披露的示例性实施例的框图。
29.图10b是说明本披露的方法的示例性实施例的框图。
30.图11说明了按抗体位置拆分的示例性实施例。
31.图12说明了使用随机拆分和按位置拆分的线性转换器、朴素转换器和预训练转换器结果的示例性结果。
32.图13是说明天冬酰胺酶序列的重构误差的图。
具体实施方式
33.示例性实施例的描述如下。
34.本文描述了用于评估蛋白质或多肽信息以及在一些实施例中产生性质或功能的预测的系统、装置、软件和方法。机器学习方法允许生成接收输入数据(例如一级氨基酸序列)的模型,并预测至少部分由氨基酸序列定义的所得多肽或蛋白质的一种或多种功能或特征。输入数据可以包括另外的信息,例如氨基酸相互作用的接触图、三级蛋白质结构或与多肽结构有关的其他相关信息。在一些情况下,迁移学习用于在经标记的训练数据不足时提高模型的预测能力。
35.多肽性质或功能的预测
36.本文描述了设备、软件、系统和方法,所述设备、软件、系统和方法用于评估包含蛋白质或多肽信息(例如氨基酸序列(或编码氨基酸序列的核酸序列))的输入数据,以便基于输入数据预测一种或多种特定功能或性质。氨基酸序列(例如蛋白质)的一种或多种特定功能或性质的外推将对许多分子生物学应用是有益的。因此,本文所述的设备、软件、系统和方法利用人工智能或机器学习技术对多肽或蛋白质分析的能力来预测结构和/或功能。与标准的非机器学习方法相比,机器学习技术能够生成具有增加的预测能力的模型。在一些情况下,当没有足够的数据来训练模型以获得所需的输出时,可以利用迁移学习来提高预测准确性。替代性地,在一些情况下,当有足够的数据来训练模型以实现与并入迁移学习的
模型相当的统计参数时,不使用迁移学习。
37.在一些实施例中,输入数据包含蛋白质或多肽的一级氨基酸序列。在一些情况下,使用包含一级氨基酸序列的经标记的数据集训练模型。例如,数据集可以包括基于荧光强度的程度标记的荧光蛋白的氨基酸序列。因此,可以使用机器学习方法用该数据集训练模型以生成氨基酸序列输入的荧光强度的预测。在一些实施例中,输入数据还包含除一级氨基酸序列之外的信息,例如像表面电荷、疏水表面积、测量的或预测的溶解度或其他相关信息。在一些实施例中,输入数据包含多维输入数据,该多维输入数据包括多种类型或类别的数据。
38.在一些实施例中,本文描述的设备、软件、系统和方法利用数据增强来增强一种或多种预测模型的性能。数据增强需要使用相似但不同的训练数据集的实例或变体进行训练。例如,在图像分类中,可以通过稍微改变图像的方向(例如,轻微旋转)来增强图像数据。在一些实施例中,数据输入(例如一级氨基酸序列)通过对一级氨基酸序列的随机突变和/或生物学上获知的突变、多序列比对、氨基酸相互作用的接触图和/或三级蛋白质结构而增强。另外的增强策略包括使用来自可变剪接转录物的已知的同种型和预测的同种型。例如,输入数据可以通过包括对应于相同功能或性质的可变剪接转录物的同种型来增强。因此,关于同种型或突变的数据可以允许鉴定不显著影响预测的功能或性质的一级序列的那些部分或特征。这允许模型解释信息,例如像增强、降低或不影响预测的蛋白质性质(例如稳定性)的氨基酸突变。例如,数据输入可以包含在已知不影响功能的位置处具有随机取代的氨基酸的序列。这允许以下模型,该模型用该数据训练以了解预测的功能相对于那些特定突变是不变的。
39.在一些实施例中,数据增强涉及“混合(mixup)”学习原理,该原理需要用实例对和相应标签的凸组合训练网络,如zhang等人,mixup:beyond empirical risk minimization[mixup:超越经验风险最小化],arxiv 2018中所述。该方法将网络正则化,以支持训练样本之间的简单线性行为。混合提供了与数据无关的数据增强方法。在一些实施例中,混合数据增强包含根据以下公式生成虚拟训练实例或数据:
[0040][0041][0042]
参数χ
i
和χ
j
是原始输入向量,γ
i
和γ
j
是独热编码。(χ
i
,γ
i
)和(χ
j
,γ
j
)是随机选自训练数据集的两个实例或数据输入。
[0043]
本文描述的设备、软件、系统和方法可用于生成各种预测。预测可以涉及蛋白质功能和/或性质(例如,酶活性、稳定性等)。蛋白质稳定性可以根据各种指标进行预测,例如像热稳定性、氧化稳定性或血清稳定性。如由rocklin定义的蛋白质稳定性可以被认为是一个指标(例如,对蛋白酶切割的易感性),但另一个指标可以是折叠(三级)结构的自由能。在一些实施例中,预测包含一个或多个结构特征,例如像二级结构、三级蛋白质结构、四级结构或其任何组合。二级结构可包括指定多肽中的氨基酸或氨基酸序列是否被预测为具有α螺旋结构、β折叠结构或无序或环结构。三级结构可包括氨基酸或多肽部分在三维空间中的位置或定位。四级结构可包括形成单个蛋白质的多个多肽的位置或定位。在一些实施例中,预测包含一种或多种功能。多肽或蛋白质功能可以属于各种类别,包括代谢反应、dna复制、提
供结构、运输、抗原识别、细胞内或细胞外信号传导以及其他功能类别。在一些实施例中,预测包含酶促功能,例如像催化效率(例如,特异性常数k
cat
/k
m
)或催化特异性。
[0044]
在一些实施例中,预测包含蛋白质或多肽的酶功能。在一些实施例中,蛋白质功能是酶功能。酶可以进行各种酶促反应,并且可以归类为迁移酶(例如,将官能团从一个分子迁移到另一个分子)、氧化还原酶(例如,催化氧化还原反应)、水解酶(例如,经由水解切割化学键)、裂解酶(例如,产生双键)、连接酶(例如,经由共价键连接两个分子)和异构酶(例如,催化分子内从一种异构体到另一种异构体的结构变化)。在一些实施例中,水解酶包括蛋白酶,例如丝氨酸蛋白酶、苏氨酸蛋白酶、半胱氨酸蛋白酶、金属蛋白酶、天冬酰胺肽裂解酶、谷氨酸蛋白酶和天冬氨酸蛋白酶。丝氨酸蛋白酶在凝血、伤口愈合、消化、免疫反应和肿瘤侵袭和转移等方面具有多种生理作用。丝氨酸蛋白酶的实例包括胰凝乳蛋白酶、胰蛋白酶、弹性蛋白酶、因子10、因子11、凝血酶、纤溶酶、c1r、c1s和c3转化酶。苏氨酸蛋白酶包括在活性催化位点内具有苏氨酸的蛋白酶家族。苏氨酸蛋白酶的实例包括蛋白酶体的亚基。蛋白酶体是由α和β亚基组成的桶状蛋白质复合物。催化活性β亚基可在每个催化活性位点包括保守的n
‑
末端苏氨酸。半胱氨酸蛋白酶具有利用半胱氨酸巯基基团的催化机制。半胱氨酸蛋白酶的实例包括木瓜蛋白酶、组织蛋白酶、半胱天冬酶和钙蛋白酶。天冬氨酸蛋白酶具有两个在活性位点参与酸/碱催化的天冬氨酸残基。天冬氨酸蛋白酶的实例包括消化酶胃蛋白酶、一些溶酶体蛋白酶和肾素。金属蛋白酶包括消化酶羧肽酶、在细胞外基质重塑和细胞信号传导中发挥作用的基质金属蛋白酶(mmp)、adam(解聚素和金属蛋白酶结构域)和溶酶体蛋白酶。酶的其他非限制性实例包括蛋白酶、核酸酶、dna连接酶、聚合酶、纤维素酶、木质素酶、淀粉酶、脂肪酶、果胶酶、木聚糖酶、木质素过氧化物酶、脱羧酶、甘露聚糖酶、脱氢酶和其他基于多肽的酶。
[0045]
在一些实施例中,酶促反应包括靶分子的翻译后修饰。翻译后修饰的实例包括乙酰化、酰胺化、甲酰化、糖基化、羟基化、甲基化、肉豆蔻酰化、磷酸化、脱酰胺、异戊二烯化(例如,法呢基化、香叶基化等)、泛素化、核糖基化和硫酸化。磷酸化可发生在氨基酸(例如酪氨酸、丝氨酸、苏氨酸或组氨酸)上。
[0046]
在一些实施例中,蛋白质功能是发光,其是不需要应用加热的光发射。在一些实施例中,蛋白质功能是化学发光,例如生物发光。例如,化学发光酶(例如萤光素)可以作用于底物(萤光素),以催化底物氧化,从而释放光。在一些实施例中,蛋白质功能是荧光,其中荧光蛋白或肽吸收某些一种或多种波长的光并发射不同的一种或多种波长的光。荧光蛋白的实例包括绿色荧光蛋白(gfp)或gfp的衍生物,例如ebfp、ebfp2、石青蓝(azurite)、mkalama1、ecfp、蔚蓝(cerulean)、cypet、yfp、柠檬色(citrine)、venus或ypet。一些蛋白质如gfp是天然荧光的。荧光蛋白的实例包括egfp、蓝色荧光蛋白(ebfp、ebfp2、石青蓝、mkalamal)、青色荧光蛋白(ecfp、蔚蓝、cypet)、黄色荧光蛋白(yfp、柠檬色、venus、ypet)、氧化还原敏感gfp(rogfp)和单体gfp。
[0047]
在一些实施例中,蛋白质功能包含酶功能、结合(例如,dna/rna结合、蛋白质结合等)、免疫功能(例如,抗体)、收缩(例如,肌动蛋白、肌球蛋白)以及其他功能。在一些实施例中,输出包含与蛋白质功能相关的值,例如像酶功能或结合的动力学。此类输出可以包括亲和力、特异性和反应速率的指标。
[0048]
在一些实施例中,本文描述的一种或多种机器学习方法包含监督机器学习。监督
机器学习包括分类和回归。在一些实施例中,一种或多种机器学习方法包含无监督机器学习。无监督机器学习包括聚类、自编码、变分自编码、蛋白质语言模型(例如,其中,当可以访问前一个氨基酸时,模型预测序列中的下一个氨基酸)和关联规则挖掘。
[0049]
在一些实施例中,预测包含分类,例如二进制、多标签或多类别分类。在一些实施例中,预测可以是蛋白质性质。分类通常用于基于输入参数预测离散类别或标签。
[0050]
二进制分类基于输入预测多肽或蛋白质属于两组中的哪一组。在一些实施例中,二进制分类包括对蛋白质或多肽序列的性质或功能的肯定或否定预测。在一些实施例中,二进制分类包括受制于阈值的任何定量读数,例如像,高于某亲和力水平结合至dna序列、高于某动力学参数阈值催化反应或在高于某个解链温度时表现出热稳定性。二进制分类的实例包括以下的肯定/否定预测:多肽序列表现出自发荧光,是丝氨酸蛋白酶,或者是gpi锚定的跨膜蛋白。
[0051]
在一些实施例中,(预测的)分类是多类别分类或多标签分类。例如,多类别分类可将输入多肽分类为两个以上互斥组或类别之一,而多标签分类将输入分类为多个标签或组。例如,多标签分类可以将多肽标记为细胞内蛋白(相对于细胞外)和蛋白酶。相比之下,多类别分类可以包括将氨基酸分类为属于α螺旋、β折叠或无序/环肽序列之一。因此,蛋白质性质可包括表现出自发荧光、为丝氨酸蛋白酶、为gpi锚定的跨膜蛋白、为细胞内蛋白(相对于细胞外)和/或蛋白酶,以及属于α螺旋、β折叠或无序/环肽序列。
[0052]
在一些实施例中,预测包含提供连续变量或值(例如像蛋白质的自发荧光强度或稳定性)的回归。在一些实施例中,预测包含本文描述的任何性质或功能的连续变量或值。例如,连续变量或值可以指示基质金属蛋白酶对特定底物细胞外基质组分的靶向特异性。另外的实例包括各种定量读数,例如靶分子的结合亲和力(例如dna结合)、酶的反应速率或热稳定性。
[0053]
机器学习方法
[0054]
本文描述了应用一种或多种用于分析输入数据的方法以生成与一种或多种蛋白质或多肽性质或功能相关的预测的设备、软件、系统和方法。在一些实施例中,这些方法利用统计建模来生成关于一种或多种蛋白质或多肽功能或性质的预测或估计。在一些实施例中,机器学习方法用于训练预测模型和/或进行预测。在一些实施例中,该方法预测一种或多种性质或功能的可能性或概率。在一些实施例中,方法利用例如神经网络、决策树、支持向量机或其他适用模型的预测模型。使用训练数据,方法形成分类器,用于根据相关特征生成分类或预测。可以使用多种方法对选择用于分类的特征进行分类。在一些实施例中,训练方法包含机器学习方法。
[0055]
在一些实施例中,机器学习方法使用支持向量机(svm)、朴素贝叶斯分类、随机森林或人工神经网络。机器学习技术包括分装程序、升压程序、随机森林法及其组合。在一些实施例中,预测模型是深度神经网络。在一些实施例中,预测模型是深度卷积神经网络。
[0056]
在一些实施例中,机器学习方法使用监督学习方法。在监督学习中,该方法从经标记的训练数据中生成函数。每个训练实例都是一对,包括输入对象和所需的输出值。在一些实施例中,最佳方案允许该方法针对未见情况正确确定类标签。在一些实施例中,监督学习方法需要用户确定一个或多个控制参数。通过优化训练集的子集(称为验证集)的性能,任选地调整这些参数。在参数调整和学习之后,任选地用与训练集分开的测试集测量所得函
数的性能。回归方法常用于监督学习。因此,监督学习允许使用其中预期输出预先已知的训练数据生成或训练模型或分类器,例如在已知一级氨基酸序列时计算蛋白质功能中。
[0057]
在一些实施例中,机器学习方法使用无监督学习方法。在无监督学习中,该方法生成函数以描述来自未标记数据的隐藏结构(例如,分类或归类不包括在观察中)。由于提供给学习者的实例是未标记的,因此没有对相关方法输出的结构的准确性进行评估。无监督学习的方法包括:聚类、异常检测和基于神经网络的方法,包括自动编码器和变分自编码器。
[0058]
在一些实施例中,机器学习方法利用多类别学习。多任务学习(mtl)是机器学习的一个领域,在该领域中,以利用跨多项任务的共性和差异的方式同时解决一个以上学习任务。与单独训练那些模型相比,该方法的优点可以包括提高具体预测模型的学习效率和预测准确性。可以通过要求一种方法在相关任务上表现良好来提供正则化以防止过拟合。该方法可能比对所有复杂性应用相同罚分的正则化更好。当应用于具有显著共性和/或样本不足的任务或预测时,多类别学习可能尤其有用。在一些实施例中,多类别学习对于不具有显著共性的任务(例如,不相关的任务或分类)是有效的。在一些实施例中,多类别学习与迁移学习组合使用。
[0059]
在一些实施例中,机器学习方法基于训练数据集和该批次的其他输入分批学习。在其他实施例中,机器学习方法在更新权重和误差计算的情况下(例如使用新的或更新的训练数据)执行另外的学习。在一些实施例中,机器学习方法基于新的或更新的数据更新预测模型。例如,机器学习方法可以应用于待重新训练或优化的新的或更新的数据,以生成新的预测模型。在一些实施例中,随着另外的数据变得可用,机器学习方法或模型被定期重新训练。
[0060]
在一些实施例中,本披露的分类器或训练方法包含一个特征空间。在一些情况下,分类器包含两个或更多个特征空间。在一些实施例中,两个或更多个特征空间彼此不同。在一些实施例中,通过在分类器中组合两个或更多个特征空间而不是使用单个特征空间来提高分类或预测的准确性。属性通常构成特征空间的输入特征,并被标记以指示每个案例的针对对应于该案例的给定输入特征集的分类。
[0061]
通过在预测模型或分类器中组合两个或更多个特征空间而不是使用单个特征空间,可以提高分类的准确性。在一些实施例中,预测模型包含至少两个、三个、四个、五个、六个、七个、八个、九个、或十个或更多个特征空间。多肽序列信息和任选另外的数据通常构成特征空间的输入特征,并被标记以指示每个案例的针对对应于该案例的给定输入特征集的分类。在许多情况下,分类是案例的结果。训练数据被输入到机器学习方法中,该方法处理输入特征和相关的结果以生成训练模型或预测器。在一些情况下,机器学习方法提供有包括分类的训练数据,从而使该方法能够通过将其输出与实际输出进行比较来“学习”,以修改和改进模型。这经常被称为监督学习。替代性地,在一些情况下,机器学习方法提供有未标记或未分类的数据,这留下了鉴定案例中隐藏结构的方法(例如,聚类)。这被称为无监督学习。
[0062]
在一些实施例中,使用机器学习方法使用一组或多组训练数据来训练模型。在一些实施例中,本文所述的方法包括使用训练数据集训练模型。在一些实施例中,使用包含多个氨基酸序列的训练数据集训练模型。在一些实施例中,训练数据集包含至少1百万、2百
万、3百万、4百万、5百万、6百万、7百万、8百万、9百万、1千万、1500万、2千万、2500万、3千万、3500万、4千万、4500万、5千万、5500万、5600万、5700万、5800万个蛋白质氨基酸序列。在一些实施例中,训练数据集包含至少10、20、30、40、50、60、70、80、90、100、150、200、250、300、350、400、450、500、600、700、800、900或1000或更多个氨基酸序列。在一些实施例中,训练数据集包含至少50、100、200、300、400、500、600、700、800、900、1000、2000、3000、4000、5000、6000、7000、8000、9000或10000或更多个注释。尽管本披露的实例性实施例包括使用深度神经网络的机器学习方法,但是设想了各种类型的方法。在一些实施例中,该方法利用例如神经网络、决策树、支持向量机或其他适用模型的预测模型。在一些实施例中,机器学习方法选自下组,该组包括监督学习、半监督学习和无监督学习,例如像支持向量机(svm)、朴素贝叶斯分类、随机森林、人工神经网络、决策树、k均值、学习矢量量化(lvq)、自组织图(som)、图模型、回归方法(例如,线性、逻辑、多变量、关联规则学习、深度学习、维度减少和集合选择方法。在一些实施例中,机器学习方法选自下组,该组包括支持向量机(svm)、朴素贝叶斯分类、随机森林和人工神经网络。机器学习技术包括分装程序、升压程序、随机森林法及其组合。用于分析数据的说明性方法包括但不限于直接处理大量变量的方法,例如统计方法和基于机器学习技术的方法。统计方法包括惩罚逻辑回归、微阵列预测分析(pam)、基于缩小的质心的方法、支持向量机分析和正则化线性辨别分析。
[0063]
迁移学习
[0064]
本文描述了用于基于例如一级氨基酸序列的信息预测一种或多种蛋白质或多肽性质或功能的设备、软件、系统和方法。在一些实施例中,迁移学习用于提高预测准确性。迁移学习是一种机器学习技术,其中为一项任务开发的模型可以重复用作第二项任务的模型的起点。通过让模型在数据丰富的相关任务上学习,迁移学习可用于提高对数据有限的任务的预测准确性。因此,本文描述了用于从测序的蛋白质的大数据集中学习蛋白质的一般功能特征并将其用作模型的起点以预测任何特定蛋白质功能、性质或特征的方法。本披露认识到令人惊讶的发现,可以将在所有测序蛋白质中由第一预测模型编码的信息迁移以使用第二预测模型设计感兴趣的特定蛋白质功能。在一些实施例中,预测模型是神经网络,例如像深度卷积神经网络。
[0065]
本披露可以经由一个或多个实施例来实施,以实现以下优势中的一个或多个。在一些实施例中,使用迁移学习训练的预测模块或预测器从资源消耗的角度表现出改进,例如表现出小的内存占用、低延迟或低计算成本。在可能需要巨大计算能力的复杂分析中,不能低估这一优势。在一些情况下,需要使用迁移学习来在合理的时间段内(例如,几天而不是几周)训练足够准确的预测器。在一些实施例中,与未使用迁移学习训练的预测器相比,使用迁移学习训练的预测器提供高准确性。在一些实施例中,与未使用迁移学习的其他方法或模型相比,在用于预测多肽结构、性质和/或功能的系统中使用深度神经网络和/或迁移学习提高了计算效率。
[0066]
本文描述了对所需蛋白质功能或性质进行建模的方法。在一些实施例中,提供包含神经网嵌入器的第一系统。在一些实施例中,该神经网嵌入器包含一个或多个嵌入层。在一些实施例中,神经网络的输入包含表示为“独热”向量的蛋白质序列,该“独热”向量将氨基酸序列编码为矩阵。例如,在该矩阵内,每一行可以配置为恰好含有1个非零条目,该条目对应于存在于残基处的氨基酸。在一些实施例中,第一系统包含神经网预测器。在一些实施
例中,预测器包含用于基于输入生成预测或输出的一个或多个输出层。在一些实施例中,使用第一训练数据集对第一系统进行预训练以提供预训练神经网嵌入器。使用迁移学习,预训练的第一系统或其部分可以被迁移以形成第二系统的部分。当在第二系统中使用时,可以冻结神经网嵌入器的一个层或多个层。在一些实施例中,第二系统包含来自第一系统的神经网嵌入器或其部分。在一些实施例中,第二系统包含神经网嵌入器和神经网预测器。神经网预测器可以包括一个或多个用于生成最终输出或预测的输出层。可以使用根据感兴趣的蛋白质功能或性质标记的第二训练数据集训练第二系统。如本文所用,嵌入器和预测器可以指例如使用机器学习训练的神经网络的预测模型的组件。
[0067]
在一些实施例中,迁移学习用于训练第一模型,该第一模型至少一部分用于形成第二模型的一部分。第一模型的输入数据可以包含已知的天然和合成蛋白质的大型数据储存库,而不管功能或其他性质。输入数据可以包括以下任何组合:一级氨基酸序列、二级结构序列、氨基酸相互作用的接触图、作为氨基酸物理化学性质的函数的一级氨基酸序列、和/或三级蛋白质结构。尽管本文提供了这些具体实例,但考虑了与蛋白质或多肽有关的任何另外的信息。在一些实施例中,输入数据被嵌入。例如,输入数据可以表示为序列的二进制独热编码的多维张量、实值(例如,在物理化学性质或来自三级结构的3维原子位置的情况下)、成对相互作用的邻接矩阵、或使用数据的直接嵌入(例如,一级氨基酸序列的字符嵌入)。
[0068]
图9是说明应用于神经网络架构的迁移学习过程的实施例的框图。如图所示,第一系统(左)具有带有嵌入向量和线性模型的卷积神经网络架构,该模型使用uniprot氨基酸序列和约70,000个注释(例如序列标签)进行训练。在迁移学习过程中,第一系统或模型的嵌入向量和卷积神经网络部分被迁移以形成第二系统或模型的核心,该第二系统或模型还并入新的线性模型,该线性模型被配置为预测与第一模型或系统中配置的任何预测不同的蛋白质性质或功能。具有与第一系统分离的线性模型的第二系统使用基于对应于蛋白质性质或功能的所需序列标签的第二训练数据集进行训练。一旦训练完成,可以针对验证数据集和/或测试数据集(例如,未在训练中使用的数据)评估第二系统,并且一旦验证,第二系统就可以用于针对蛋白质性质或功能分析序列。蛋白质性质可用于例如治疗应用。治疗应用除蛋白质主要治疗功能(例如,对酶的催化、对抗体的结合亲和力、刺激激素的信号传导途径等)以外,有时可能需要蛋白质具有多种药物样性质,包括稳定性、溶解度和表达(例如,用于制造)。
[0069]
在一些实施例中,第一模型和/或第二模型的数据输入通过另外的数据(例如一级氨基酸序列的随机突变和/或生物学上获知的突变、氨基酸相互作用的接触图和/或三级蛋白质结构)增强。另外的增强策略包括使用来自可变剪接转录物的已知的同种型和预测的同种型。在一些实施例中,不同类型的输入(例如,氨基酸序列、接触图等)由一个或多个模型的不同部分处理。在初始处理步骤之后,来自多个数据源的信息可以在网络的层处进行组合。例如,网络可以包含序列编码器、接触图编码器和其他被配置为接收和/或处理各种类型的数据输入的编码器。在一些实施例中,数据被转为网络中一个或多个层内的嵌入。
[0070]
第一模型的数据输入的标签可以从一个或多个公共蛋白质序列注释资源中提取,例如:基因本体(go)、pfam结构域、supfam结构域、酶委员会(ec)编号、分类学、极端微生物名称、关键字、包括orthodb和kegg直系同源的直系同源组分配。此外,可以基于数据库(例
如scop、fssp或cath)指定的已知结构或折叠分类来分配标签,包括全α、全β、α+β、α/β、膜、固有无序、卷曲螺旋、小蛋白质或设计蛋白质。对于结构已知的蛋白质,定量全局特性(例如总表面电荷、疏水表面积、测量或预测的溶解度或其他数字量)可用作由预测模型(例如多任务模型)拟合的另外的标签。尽管这些输入是在迁移学习的上下文中描述的,但也考虑将这些输入应用于非迁移学习方法。在一些实施例中,第一模型包含被剥离以留下由编码器构成的核心网络的注释层。注释层可以包括多个独立的层,每个层对应于特定的注释,例如像一级氨基酸序列、go、pfam、interpro、supfam、ko、orthodb和关键字。在一些实施例中,注释层包含至少1、2、3、4、5、6、7、8、9、10、15、20、25、30、40、50、60、70、80、90、100、1000、5000、10000、50000、100000或150000或更多个独立的层。在一些实施例中,注释层包含180000个独立的层。在一些实施例中,使用至少1、2、3、4、5、6、7、8、9、10、15、20、25、30、40、50、60、70、80、90、100、1000、5000、10000、50000、100000、或150000个或更多个注释训练模型。在一些实施例中,使用大约180000个注释训练模型。在一些实施例中,使用跨多个功能表示(例如,go、pfam、关键字、kegg本体论、interpro、supfam和orthodb中的一个或多个)的多个注释训练模型。氨基酸序列和注释信息可以从各种数据库(例如uniprot)中获得。
[0071]
在一些实施例中,第一模型和第二模型包含神经网络架构。第一模型和第二模型可以是使用呈1d卷积(例如一级氨基酸序列)、2d卷积(例如氨基酸相互作用的接触图)或3d卷积(例如三级蛋白质结构)形式的卷积架构的监督模型。卷积架构可以是以下描述的架构之一:vgg16、vgg19、deep resnet、inception/googlenet(v1
‑
v4)、inception/googlenet resnet、xception、alexnet、lenet、mobilenet、densenet、nasnet或mobilenet。在一些实施例中,考虑了利用本文描述的任何架构的单一模型方法(例如,非迁移学习)。
[0072]
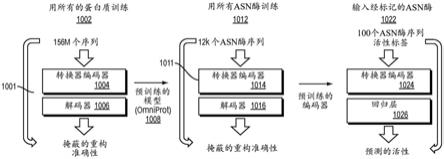
第一模型也可以是使用生成式对抗网络(gan)、递归神经网络或变分自编码器(vae)的无监督模型。如果是gan,第一模型可以是条件gan、深度卷积gan、stackgan、infogan、wasserstein gan、用生成式对抗网络发现跨结构域关系(disco gans)。在递归神经网络的情况下,第一模型可以是bi
‑
lstm/lstm、bi
‑
gru/gru或转换器网络。在一些实施例中,考虑了利用本文描述的任何架构的单一模型方法(例如,非迁移学习)。在一些实施例中,gan是dcgan、cgan、sgan/渐进式gan、sagan、lsgan、wgan、ebgan、began、或infogan。递归神经网络(rnn)是为循序数据构建的传统神经网络的变体。lstm是指长短期记忆(其是rnn中的一种神经元),其记忆允许它对数据中的顺序或时间依赖性进行建模。gru是指门控递归单元(其是lstm的变体),其试图解决lstm的一些缺点。bi
‑
lstm/bi
‑
gru是指lstm和gru的“双向”变体。典型地,lstm和gru在“正向”方向上顺序处理,但双向版本也在“反向”方向学习。lstm可以使用隐藏状态保存来自已经通过它的数据输入的信息。单向lstm只保留过去的信息,因为它只看到过去的输入。相比之下,双向lstm在从过去到未来的两个方向上运行数据输入,反之亦然。因此,正向和方向运行的双向lstm保留了来自未来和过去的信息。
[0073]
对于第一模型和第二模型以及监督模型和无监督模型,它们可以具有可替代的正则化方法,包括提前停止,包括在1、2、3、4个层直到所有层的退出,包括在1、2、3、4个层直到所有层的l1
‑
l2正则化,包括在1、2、3、4个层直到所有层残差连接。对于第一模型和第二模型,可以使用批归一化或组归一化进行正则化。l1正则化(也称为lasso)控制权重向量的l1范数(norm)允许的长度,而l2控制l2范数可能的大小。可以从resnet架构获得残差连接。
[0074]
可以使用以下优化程序的任一种来优化第一模型和第二模型:adam、rms prop、具
有动量的随机梯度下降(sgd)、具有动量和nestrov加速梯度的sgd、不具有动量的sgd、adagrad、adadelta或nadam。可以使用以下激活函数中的中任一个来优化该第一模型和该第二模型:softmax、elu、selu、softplus、softsign、relu、tanh、sigmoid、hard_sigmoid、指数、prelu和leaskyrelu或线性。在一些实施例中,本文描述的方法包括对上面列出的优化器试图最小化的损失函数进行“重赋权”,使得在肯定实例和否定实例两者上放置大约相等的权重。例如,180,000个输出中的一个预测给定蛋白质是膜蛋白的概率。由于蛋白质只能是膜蛋白或不是膜蛋白,所以这是二进制分类任务,并且二进制分类任务的传统损失函数是“二元交叉熵”:loss(p,y)=
‑
y*log(p)
‑
(1
‑
y)*log(1
‑
p),其中p是根据网络成为膜蛋白的概率,并且y是“标签”,如果蛋白质是膜蛋白,则为1,如果蛋白质不是膜蛋白,则为0。如果y=0的实例多得多,则可能会出现问题,因为网络可能会学习总是预测该注释的极低概率的病理规则,因为它很少因总是预测y=0而受到罚分。为了解决该问题,在一些实施例中,损失函数被修改为以下:损失(p,y)=
‑
w1*y*log(p)
‑
w0*(1
‑
y)*log(1
‑
p),其中w1是肯定类别权重,w0是否定类别权重。该方法假设w0=1并且w1=1/√((1
‑
f0)/f1),其中f0是否定实例的频率,f1是肯定实例的频率。该权重方案“增权重”罕见的肯定实例,并“减权重”了更常见的否定实例。
[0075]
第二模型可以使用第一模型作为训练的起点。起点可以是除输出层之外冻结的完整第一模型,该模型对靶蛋白功能或蛋白质性质进行训练。起点可以是第一模型,其中嵌入层、最后2层、最后3层或所有层被解冻,模型的其余部分在对靶蛋白功能或蛋白质性质训练期间被冻结。起点可以是第一模型,其中去除了嵌入层,并添加了1、2、3个或更多个层,并对靶蛋白功能或蛋白质性质进行了训练。在一些实施例中,冻结层的数量为1至10。在一些实施例中,冻结层的数量为1至2、1至3、1至4、1至5、1至6、1至7、1至8、1至9、1至10、2至3、2至4、2至5、2至6、2至7、2至8、2至9、2至10、3至4、3至5、3至6、3至7、3至8、3至9、3至10、4至5、4至6、4至7、4至8、4至9、4至10、5至6、5至7、5至8、5至9、5至10、6至7、6至8、6至9、6至10、7至8、7至9、7至10、8至9、8至10、或9至10。在一些实施例中,冻结层的数量为1、2、3、4、5、6、7、8、9或10。在一些实施例中,冻结层的数量为至少1、2、3、4、5、6、7、8或9。在一些实施例中、冻结层的数量为至多2、3、4、5、6、7、8、9或10。在一些实施例中,在迁移学习期间没有层被冻结。在一些实施例中,在第一模型中冻结的层数至少部分地基于可用于训练第二模型的样本数来确定。本披露认识到冻结一个层或多个层或增加冻结层的数量可以增强第二模型的预测性能。在用于训练第二模型的样本量小的情况下,该效果可能更加突出。在一些实施例中,当第二模型在训练集中具有不超过200、190、180、170、160、150、140、130、120、110、100、90、80、70、60、50、40或30个样本时,来自第一模型的所有层被冻结。在一些实施例中,当用于训练第二模型的样本数在训练集中不超过200、190、180、170、160、150、140、130、120、110、100、90、80、70、60、50、40或30个样本时,第一模型中的至少1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、25、30、35、40、45、50、55、60、65、70、75、80、85、90、95、或至少100个层被冻结以迁移至第二模型。
[0076]
第一模型和第二模型可以具有10
‑
100个层、100
‑
500个层、500
‑
1000个层、1000
‑
10000个层、或多达1000000个层。在一些实施例中,第一模型和/或第二模型包含10个层或1,000,000个层。在一些实施例中,第一模型和/或第二模型包含10个层至50个层、10个层至100个层、10个层至200个层、10个层至500个层、10个层至1,000个层、10个层至5,000个层、
10个层至10,000个层、10个层至50,000个层、10个层至100,000个层、10个层至500,000个层、10个层至1,000,000个层、50个层至100个层、50个层至200个层、50个层至500个层、50个层至1,000个层、50个层至5,000个层、50个层至10,000个层、50个层至50,000个层、50个层至100,000个层、50个层至500,000个层、50个层至1,000,000个层、100个层至200个层、100个层至500个层、100个层至1,000个层、100个层至5,000个层、100个层至10,000个层、100个层至50,000个层、100个层至100,000个层、100个层至500,000个层、100个层至1,000,000个层、200个层至500个层、200个层至1,000个层、200个层至5,000个层、200个层至10,000个层、200个层至50,000个层、200个层至100,000个层、200个层至500,000个层、200个层至1,000,000个层、500个层至1,000个层、500个层至5,000个层、500个层至10,000个层、500个层至50,000个层、500个层至100,000个层、500个层至500,000个层、500个层至1,000,000个层、1,000个层至5,000个层、1,000个层至10,000个层、1,000个层至50,000个层、1,000个层至100,000个层、1,000个层至500,000个层、1,000个层至1,000,000个层、5,000个层至10,000个层、5,000个层至50,000个层、5,000个层至100,000个层、5,000个层至500,000个层、5,000个层至1,000,000个层、10,000个层至50,000个层、10,000个层至100,000个层、10,000个层至500,000个层、10,000个层至1,000,000个层、50,000个层至100,000个层、50,000个层至500,000个层、50,000个层至1,000,000个层、100,000个层至500,000个层、100,000个层至1,000,000个层、或500,000个层至1,000,000个层。在一些实施例中,第一模型和/或第二模型包含10个层、50个层、100个层、200个层、500个层、1,000个层、5,000个层、10,000个层、50,000个层、100,000个层、500,000个层、或1,000,000个层。在一些实施例中,第一模型和/或第二模型包含至少10个层、50个层、100个层、200个层、500个层、1,000个层、5,000个层、10,000个层、50,000个层、100,000个层、或500,000个层。在一些实施例中,第一模型和/或第二模型包含至多50个层、100个层、200个层、500个层、1,000个层、5,000个层、10,000个层、50,000个层、100,000个层、500,000个层、或1,000,000个层。
[0077]
在一些实施例中,本文描述了第一系统,该第一系统包含神经网嵌入器和任选的神经网预测器。在一些实施例中,第二系统包含神经网嵌入器和神经网预测器。在一些实施例中,嵌入器包含10个层至200个层。在一些实施例中,嵌入器包含10个层至20个层、10个层至30个层、10个层至40个层、10个层至50个层、10个层至60个层、10个层至70个层、10个层至80个层、10个层至90个层、10个层至100个层、10个层至200个层、20个层至30个层、20个层至40个层、20个层至50个层、20个层至60个层、20个层至70个层、20个层至80个层、20个层至90个层、20个层至100个层、20个层至200个层、30个层至40个层、30个层至50个层、30个层至60个层、30个层至70个层、30个层至80个层、30个层至90个层、30个层至100个层、30个层至200个层、40个层至50个层、40个层至60个层、40个层至70个层、40个层至80个层、40个层至90个层、40个层至100个层、40个层至200个层、50个层至60个层、50个层至70个层、50个层至80个层、50个层至90个层、50个层至100个层、50个层至200个层、60个层至70个层、60个层至80个层、60个层至90个层、60个层至100个层、60个层至200个层、70个层至80个层、70个层至90个层、70个层至100个层、70个层至200个层、80个层至90个层、80个层至100个层、80个层至200个层、90个层至100个层、90个层至200个层、或100个层至200个层。在一些实施例中,嵌入器包含10个层、20个层、30个层、40个层、50个层、60个层、70个层、80个层、90个层、100个层、或200个层。在一些实施例中,嵌入器包含至少10个层、20个层、30个层、40个层、50个层、60个
层、70个层、80个层、90个层、或100个层。在一些实施例中,嵌入器包含至多20个层、30个层、40个层、50个层、60个层、70个层、80个层、90个层、100个层、或200个层。
[0078]
在一些实施例中,神经网预测器包含多个层。在一些实施例中,嵌入器包含1个层至20个层。在一些实施例中,嵌入器包含1个层至2个层、1个层至3个层、1个层至4个层、1个层至5个层、1个层至6个层、1个层至7个层、1个层至8个层、1个层至9个层、1个层至10个层、1个层至15个层、1个层至20个层、2个层至3个层、2个层至4个层、2个层至5个层、2个层至6个层、2个层至7个层、2个层至8个层、2个层至9个层、2个层至10个层、2个层至15个层、2个层至20个层、3个层至4个层、3个层至5个层、3个层至6个层、3个层至7个层、3个层至8个层、3个层至9个层、3个层至10个层、3个层至15个层、3个层至20个层、4个层至5个层、4个层至6个层、4个层至7个层、4个层至8个层、4个层至9个层、4个层至10个层、4个层至15个层、4个层至20个层、5个层至6个层、5个层至7个层、5个层至8个层、5个层至9个层、5个层至10个层、5个层至15个层、5个层至20个层、6个层至7个层、6个层至8个层、6个层至9个层、6个层至10个层、6个层至15个层、6个层至20个层、7个层至8个层、7个层至9个层、7个层至10个层、7个层至15个层、7个层至20个层、8个层至9个层、8个层至10个层、8个层至15个层、8个层至20个层、9个层至10个层、9个层至15个层、9个层至20个层、10个层至15个层、10个层至20个层、或15个层至20个层。在一些实施例中,嵌入器包含1个层、2个层、3个层、4个层、5个层、6个层、7个层、8个层、9个层、10个层、15个层、或20个层。在一些实施例中,嵌入器包含至少1个层、2个层、3个层、4个层、5个层、6个层、7个层、8个层、9个层、10个层、或15个层。在一些实施例中,嵌入器包含至多2个层、3个层、4个层、5个层、6个层、7个层、8个层、9个层、10个层、15个层、或20个层。
[0079]
在一些实施例中,不使用迁移学习来生成最终的训练模型。例如,在有足够数据可用的情况下,与不使用迁移学习的模型(例如,针对测试数据集进行测试时)相比,至少部分使用迁移学习生成的模型在预测方面没有提供显著改进。因此,在一些实施例中,利用非迁移学习方法来生成训练模型。
[0080]
在一些实施例中,训练模型包含10个层至1,000,000个层。在一些实施例中,模型包含10个层至50个层、10个层至100个层、10个层至200个层、10个层至500个层、10个层至1,000个层、10个层至5,000个层、10个层至10,000个层、10个层至50,000个层、10个层至100,000个层、10个层至500,000个层、10个层至1,000,000个层、50个层至100个层、50个层至200个层、50个层至500个层、50个层至1,000个层、50个层至5,000个层、50个层至10,000个层、50个层至50,000个层、50个层至100,000个层、50个层至500,000个层、50个层至1,000,000个层、100个层至200个层、100个层至500个层、100个层至1,000个层、100个层至5,000个层、100个层至10,000个层、100个层至50,000个层、100个层至100,000个层、100个层至500,000个层、100个层至1,000,000个层、200个层至500个层、200个层至1,000个层、200个层至5,000个层、200个层至10,000个层、200个层至50,000个层、200个层至100,000个层、200个层至500,000个层、200个层至1,000,000个层、500个层至1,000个层、500个层至5,000个层、500个层至10,000个层、500个层至50,000个层、500个层至100,000个层、500个层至500,000个层、500个层至1,000,000个层、1,000个层至5,000个层、1,000个层至10,000个层、1,000个层至50,000个层、1,000个层至100,000个层、1,000个层至500,000个层、1,000个层至1,000,000个层、5,000个层至10,000个层、5,000个层至50,000个层、5,000个层至100,000个
层、5,000个层至500,000个层、5,000个层至1,000,000个层、10,000个层至50,000个层、10,000个层至100,000个层、10,000个层至500,000个层、10,000个层至1,000,000个层、50,000个层至100,000个层、50,000个层至500,000个层、50,000个层至1,000,000个层、100,000个层至500,000个层、100,000个层至1,000,000个层、或500,000个层至1,000,000个层。在一些实施例中,模型包含10个层、50个层、100个层、200个层、500个层、1,000个层、5,000个层、10,000个层、50,000个层、100,000个层、500,000个层、或1,000,000个层。在一些实施例中,模型包含至少10个层、50个层、100个层、200个层、500个层、1,000个层、5,000个层、10,000个层、50,000个层、100,000个层、或500,000个层。在一些实施例中,模型包含至多50个层、100个层、200个层、500个层、1,000个层、5,000个层、10,000个层、50,000个层、100,000个层、500,000个层、或1,000,000个层。
[0081]
在一些实施例中,机器学习方法包括使用不用于训练的数据进行测试以评估其预测能力的训练模型或分类器。在一些实施例中,使用一种或多种性能指标来评估训练模型或分类器的预测能力。这些性能指标包括分类准确性、特异性、灵敏度、肯定预测值、否定预测值、受试者工作曲线下的测量面积(auroc)、均方误差、错误发现率以及预测值和实际值之间的皮尔逊相关性,这些性能指标通过针对一组独立案例对它进行测试来确定模型。如果值是连续的,则预测值与测量值之间的均方误差(mse)或皮尔逊相关系数是两个常见指标。对于离散分类任务,分类准确性、肯定预测值、精确率/召回率和roc曲线下面积(auc)是常见的性能指标。
[0082]
在一些情况下,针对至少约50、60、70、80、90、100、110、120、130、140、150、160、170、180、190或200个独立案例(包括其中的增量),方法具有至少约60%、65%、70%、75%、80%、85%、90%、95%或更多的auroc(包括其中的增量)。在一些情况下,针对至少约50、60、70、80、90、100、110、120、130、140、150、160、170、180、190或200个独立案例(包括其中的增量),方法具有至少约75%、80%、85%、90%、95%或更高的准确性(包括其中的增量)。在一些情况下,针对至少约50、60、70、80、90、100、110、120、130、140、150、160、170、180、190或200个独立案例(包括其中的增量),方法具有至少约75%、80%、85%、90%、95%或更高的特异性(包括其中的增量)。在一些情况下,针对至少约50、60、70、80、90、100、110、120、130、140、150、160、170、180、190或200个独立案例(包括其中的增量),方法具有至少约75%、80%、85%、90%、95%或更高的灵敏度(包括其中的增量)。在一些情况下,针对至少约50、60、70、80、90、100、110、120、130、140、150、160、170、180、190或200个独立案例(包括其中的增量),方法具有至少约75%、80%、85%、90%、95%或更高的肯定预测值(包括其中的增量)。在一些情况下,针对至少约50、60、70、80、90、100、110、120、130、140、150、160、170、180、190或200个独立案例(包括其中的增量),方法具有至少约75%、80%、85%、90%、95%或更高的否定预测值(包括其中的增量)。
[0083]
计算系统和软件
[0084]
在一些实施例中,如本文所述的系统被配置为提供软件应用,例如多肽预测引擎。在一些实施例中,多肽预测引擎包含用于基于输入数据例如一级氨基酸序列预测至少一种功能或性质的一个或多个模型。在一些实施例中,如本文所述的系统包含计算设备,例如数字处理设备。在一些实施例中,如本文所述的系统包含用于与服务器通信的网络元件。在一些实施例中,如本文所述的系统包含服务器。在一些实施例中,系统被配置为上载到服务器
和/或从服务器下载数据。在一些实施例中,服务器被配置为存储输入数据、输出和/或其他信息。在一些实施例中,服务器被配置为从系统或装置备份数据。
[0085]
在一些实施例中,系统包含一个或多个数字处理设备。在一些实施例中,系统包含被配置为生成一个或多个训练模型的多个处理单元。在一些实施例中,系统包含多个图形处理单元(gpu),这些图形处理单元适用于机器学习应用。例如,与中央处理单元(cpu)相比,gpu通常表征为由算术逻辑单元(alu)、控制单元和存储器缓存构成的较小逻辑核的数量增加。因此,gpu被配置为并行处理更多数量的简单且相同的计算,这些计算适用于机器学习方法中常见的数学矩阵计算。在一些实施例中,系统包含一个或多个张量处理单元(tpu),这些张量处理单元是由谷歌开发的用于神经网络机器学习的ai专用集成电路(asic)。在一些实施例中,本文描述的方法在包含多个gpu和/或tpu的系统上实施。在一些实施例中,系统包含至少2、3、4、5、6、7、8、9、10、15、20、30、40、50、60、70、80、90、或100个或更多个gpu或tpu。在一些实施例中,gpu或tpu被配置为提供并行处理。
[0086]
在一些实施例中,系统或装置被配置为加密数据。在一些实施例中,服务器上的数据被加密。在一些实施例中,系统或装置包含用于存储数据的数据存储单元或存储器。在一些实施例中,使用高级加密标准(aes)来进行数据加密。在一些实施例中,使用128位、192位或256位aes加密来进行数据加密。在一些实施例中,数据加密包含数据存储单元的全盘加密。在一些实施例中,数据加密包含虚拟磁盘加密。在一些实施例中,数据加密包含文件加密。在一些实施例中,在系统或装置与其他设备或服务器之间传输或以其他方式通信的数据在传输期间被加密。在一些实施例中,系统或装置与其他设备或服务器之间的无线通信被加密。在一些实施例中,传输中的数据使用安全套接层(ssl)加密。
[0087]
如本文所述的装置包含数字处理设备,该数字处理设备包括一个或多个执行设备功能的硬件中央处理单元(cpu)或通用图形处理单元(gpgpu)。数字处理设备进一步包含被配置为执行可执行指令的操作系统。数字处理设备任选地连接到计算机网络。数字处理设备任选地连接到互联网,以便它访问万维网。数字处理设备任选地连接到云计算基础设施。合适的数字处理设备包括,以非限制性实例的方式,服务器计算机、台式计算机、膝上型计算机、笔记本计算机、小型笔记本计算机、上网本计算机、netpad计算机、机顶计算机、流媒体设备、手持式计算机、因特网设备、移动智能手机、平板计算机、个人数字助理、视频游戏控制台和传播媒介。本领域技术人员将认识到,许多智能手机适用于在本文描述的系统中使用。
[0088]
典型地,数字处理设备包括被配置为执行可执行指令的操作系统。例如,操作系统是软件,包括程序和数据,该操作系统管理设备的硬件并为应用的执行提供服务。本领域技术人员将认识到,以非限制性实例的方式,合适的服务器操作系统包括freebsd、openbsd、linux、mac os x windows 和和本领域技术人员将认识到,以非限制性实例的方式,合适的个人计算机操作系统包括mac os 和类unix操作系统,例如在一些实施例中,操作系统由云计算提供。
[0089]
如本文所述的数字处理设备包括或可操作地耦合到存储和/或存储器设备。存储和/或存储器设备是一种或多种用于临时或永久存储数据或程序的物理装置。在一些实施
例中,设备是易失性存储器并且需要电源来维持存储的信息。在一些实施例中,设备是非易失性存储器并且在数字处理设备未通电时保留存储的信息。在另外的实施例中,非易失性存储器包含闪存。在一些实施例中,非易失性存储器包含动态随机存取存储器(dram)。在一些实施例中,非易失性存储器包括铁电随机存取存储器(fram)。在一些实施例中,非易失性存储器包含相变随机存取存储器(pram)。在其他实施例中,设备是存储设备,以非限制性实例的方式,包括cd
‑
rom、dvd、闪存设备、磁盘驱动器、磁带驱动器、光盘驱动器、和基于云计算的存储。在另外的实施例中,存储和/或存储器设备是如本文所披露的那些设备的组合。
[0090]
在一些实施例中,如本文所述的系统或方法生成含有或包含输入和/或输出数据的数据库。本文描述的系统的一些实施例是基于计算机的系统。这些实施例包括cpu(包括处理器和存储器),其可以呈非暂态计算机可读存储介质的形式。这些系统实施例进一步包括典型地存储在存储器(例如呈非暂态计算机可读存储介质的形式)中的软件,其中该软件被配置为使处理器执行功能。并入本文所述系统的软件实施例含有一个或多个模块。
[0091]
在各种实施例中,装置包含计算设备或组件,例如数字处理设备。在本文描述的一些实施例中,数字处理设备包括显示器以显示视觉信息。适用于与本文描述的系统和方法一起使用的显示器的非限制性实例包括液晶显示器(lcd)、薄膜晶体管液晶显示器(tft
‑
lcd)、有机发光二极管(oled)显示器、oled显示器、有源矩阵oled(amoled)显示器、或等离子显示器。
[0092]
在本文描述的一些实施例中,数字处理设备包括用于接收信息的输入设备。适用于与本文描述的系统和方法一起使用的输入设备的非限制性实例包括键盘、鼠标、轨迹球、轨迹板或手写笔。在一些实施例中,输入设备是触摸屏或多触摸屏。
[0093]
本文描述的系统和方法典型地包括一个或多个非暂态计算机可读存储介质,该存储介质用程序编码,该程序包括可由任选网络化的数字处理设备的操作系统执行的指令。在本文描述的系统和方法的一些实施例中,非暂态存储介质是数字处理设备的组件,该数字处理设备是系统的组件或在方法中使用。在仍另外的实施例中,计算机可读存储介质任选地可从数字处理设备去除。在一些实施例中,计算机可读存储介质,以非限制性实例的方式,包括cd
‑
rom、dvd、闪存设备、固态存储器、磁盘驱动器、磁带驱动器、光盘驱动器、云计算系统和服务器等。在一些情况下,程序和指令永久地、基本上永久地、半永久地或非暂态地编码在介质上。
[0094]
典型地,本文描述的系统和方法包括至少一个计算机程序或其使用。计算机程序包括一系列指令,其可在数字处理设备的cpu中执行,被编写以执行指定任务。计算机可读指令可以被实施为执行特定任务或实施特定抽象数据类型的程序模块,例如函数、对象、应用编程接口(api)、数据结构等。根据本文提供的披露内容,本领域技术人员将认识到可以以各种语言的各种版本来编写计算机程序。计算机可读指令的功能可以根据需要在各种环境中组合或分布。在一些实施例中,计算机程序包含一个指令序列。在一些实施例中,计算机程序包含多个指令序列。在一些实施例中,从一个位置提供计算机程序。在其他实施例中,从多个位置提供计算机程序。在各种实施例中,计算机程序包括一个或多个软件模块。在各种实施例中,计算机程序以部分地或全部地包括一个或多个网络应用、一个或多个移动应用、一个或多个独立应用、一个或多个网络浏览器插件、扩展、外接程序或附加组件、或其组合。在各种实施例中,软件模块包含文件、代码段、编程对象、编程结构或其组合。在另
外的各种实施例中,软件模块包含多个文件、多个代码段、多个编程对象、多个编程结构或其组合。在各种实施例中,以非限制性实例的方式,一个或多个软件模块包含网络应用、移动应用和独立应用。在一些实施例中,软件模块在一个计算机程序或应用中。在其他实施例中,软件模块在一个以上的计算机程序或应用中。在一些实施例中,软件模块驻留在一台机器上。在其他实施例中,软件模块驻留在一台以上机器上。在另外的实施例中,软件模块驻留在云计算平台上。在一些实施例中,软件模块驻留在一个位置的一台或多台机器上。在其他实施例中,软件模块驻留在多于一个位置的一台或多台机器上。
[0095]
典型地,本文描述的系统和方法包括和/或利用一个或多个数据库。鉴于本文提供的披露内容,本领域技术人员将认识到,许多数据库适用于基线数据集、文件、文件系统、对象、对象系统以及本文描述的数据结构和其他类型信息的存储和检索。在各种实施例中,以非限制性实例的方式,合适的数据库包括关系型数据库、非关系型数据库、面向对象的数据库、对象数据库、实体关系模型数据库、关联数据库和xml数据库。另外的非限制性实例包括sql、postgresql、mysql、oracle、db2和sybase。在一些实施例中,数据库是基于互联网的。在另外的实施例中,数据库是基于网络的。在仍另外的实施例中,数据库是基于云计算的。在其他实施例中,数据库基于一个或多个本地计算机存储设备。
[0096]
图8示出了如本文所述的系统的示例性实施例,该系统包含装置,例如数字处理设备801。数字处理设备801包括被配置为分析输入数据的软件应用。数字处理设备801可以包括中央处理单元(cpu,本文也称为“处理器”和“计算机处理器”)805,该中央处理单元可以是单核或多核处理器,或者是用于并行处理的多个处理器。数字处理设备801还包括存储器或存储器位置810(例如,随机存取存储器、只读存储器、闪存)、电子存储单元815(例如,硬盘)、通信接口820(例如,网络适配器、网络接口),用于与一个或多个其他系统和外围设备(例如缓存)进行通信。外围设备可以包括经由存储接口870与设备的其余部分通信的一个或多个存储设备或存储介质865。存储器810、存储单元815、接口820和外围设备被配置为通过通信总线825例如主板与cpu 805通信。数字处理设备801可以在通信接口820的帮助下可操作地耦合到计算机网络(“网络”)830。网络830可以包含因特网。网络830可以是电信和/或数据网络。
[0097]
数字处理设备801包括一个或多个输入设备845以接收信息,该一个或多个输入设备经由输入接口850与设备的其他元件通信。数字处理设备801可以包括经由输出接口860与设备的其他元件通信的一个或多个输出设备855。
[0098]
cpu 805被配置为执行体现在软件应用或模块中的机器可读指令。指令可以存储在存储器位置,例如存储器810。存储器810可以包括各种组件(例如,机器可读介质),包括但不限于随机存取存储器组件(例如,ram)(例如,静态ram“sram”、动态ram“dram”等),或只读组件(例如,rom)。存储器810还可以包括基本输入/输出系统(bios),其包括有助于在数字处理设备内的元件之间传输信息的基本例行程序,例如在设备启动期间,可以存储在存储器810中。
[0099]
存储单元815可被配置为存储文件,例如一级氨基酸序列。存储单元815还可用于存储操作系统、应用程序等。任选地,存储单元815可以可移除地与数字处理设备接口(例如,经由外部端口连接器(未示出)和/或经由存储单元接口)。软件可以完全地或部分地驻留在存储单元815内部或外部的计算机可读存储介质中。在另一个实例中,软件可以完全地
或部分地驻留在一个或多个处理器805内。
[0100]
信息和数据可以通过显示器835显示给用户。显示器经由接口840连接到总线825,并且设备801的显示器其他元件之间的数据传输可以经由接口840来控制。
[0101]
可以通过存储在数字处理设备801的电子存储位置(例如像存储器810或电子存储单元815)上的机器(例如,计算机处理器)可执行代码的方式来实施本文所述的方法。机器可执行或机器可读代码可以以软件应用或软件模块的形式提供。在使用期间,代码可由处理器805执行。在一些情况下,可以从存储单元815中检索代码并将其存储在存储器810上用于处理器805随时访问。在一些情况下,可以排除电子存储单元815,并且将机器可执行指令存储在存储器810上。
[0102]
在一些实施例中,远程设备802被配置为与数字处理设备801通信,并且可以包含任何移动计算设备,该移动计算设备的非限制性实例包括平板计算机、膝上型计算机、智能电话或智能手表。例如,在一些实施例中,远程设备802是用户的智能电话,其被配置为从本文所述的装置或系统的数字处理设备801接收信息,其中该信息可以包括汇总、输入、输出或其他数据。在一些实施例中,远程设备802是网络上的服务器,其被配置为向本文所述的装置或系统发送和/或从本文所述的装置或系统接收数据。
[0103]
本文所述的系统和方法的一些实施例被配置为生成含有或包括输入和/或输出数据的数据库。如本文所述,数据库被配置为用作例如用于输入和输出数据的数据储存库。在一些实施例中,数据库存储在网络上的服务器上。在一些实施例中,数据库本地地存储在装置(例如,装置的监视器组件)上。在一些实施例中,数据库与服务器提供的数据备份一起本地存储。
[0104]
某些定义
[0105]
如本文所有,单数形式“一个/一种(a/an)”以及“该(这些)”包括复数个指示物,除非上下文中另外明确指明。例如,术语“样本”包括多个样本,包括其混合物。除非另有说明,否则本文中对“或”的任何引用均旨在涵盖“和/或”。
[0106]
如本文所用,术语“核酸”通常是指一种或多种核碱基、核苷或核苷酸。例如,核酸可以包括一个或多个选自腺苷(a)、胞嘧啶(c)、鸟嘌呤(g)、胸腺嘧啶(t)和尿嘧啶(u)或其变体的核苷酸。核苷酸通常包括核苷和至少1、2、3、4、5、6、7、8、9、10个或更多个磷酸(po3)基团。核苷酸可以包括核碱基、五碳糖(核糖或脱氧核糖)以及一个或多个磷酸基团。核糖核苷酸包括其中糖为核糖的核苷酸。脱氧核糖核苷酸包括其中糖是脱氧核糖的核苷酸。核苷酸可以是核苷一磷酸、核苷二磷酸、核苷三磷酸或核苷多磷酸。
[0107]
如本文所用,术语“多肽”、“蛋白质”和“肽”可互换使用,并且是指经由肽键连接的氨基酸残基的聚合物,并且其可由两条或更多条多肽链构成。术语“多肽”、“蛋白质”和“肽”是指通过酰胺键连接在一起的至少两个氨基酸单体的聚合物。氨基酸可以是l光学异构体或d光学异构体。更具体地说,术语“多肽”、“蛋白质”和“肽”是指由两个或更多个氨基酸以特定顺序构成的分子;例如,由编码蛋白质的基因或rna中核苷酸的碱基序列决定的顺序。蛋白质对身体细胞、组织和器官的结构、功能和调节至关重要,并且每种蛋白质都具有独特的功能。实例是激素、酶、抗体及其任何片段。在一些情况下,蛋白质可以是蛋白质的部分,例如蛋白质的结构域、亚结构域或基序。在一些情况下,蛋白质可以是蛋白质的变体(或突变),其中一个或多个氨基酸残基被插入到天然存在的(或至少已知的)蛋白质氨基酸序列
中、从其中缺失和/或取代到其中。蛋白质或其变体可以是天然存在的或重组的。多肽可以是通过相邻氨基酸残基的羧基基团和氨基基团之间的肽键结合在一起的氨基酸的单一线性聚合物链。例如,可以通过添加碳水化合物、磷酸化等来修饰多肽。蛋白质可以包含一种或多种多肽。
[0108]
如本文所用,术语“神经网”是指人工神经网络。人工神经网络具有互连的节点组的一般结构。节点通常被组织成多个层,其中每个层包含一个或多个节点。信号可以通过神经网络从一层传播到下一层。在一些实施例中,神经网络包含嵌入器。嵌入器可以包括一个层或多个层,例如嵌入层。在一些实施例中,神经网络包含预测器。预测器可以包括一个或多个生成输出或结果(例如,基于一级氨基酸序列的预测功能或性质)的输出层。
[0109]
如本文所用,术语“预训练系统”是指用至少一个数据集训练的至少一个模型。模型的实例可以是线性模型、转换器或神经网络,例如卷积神经网络(cnn)。预训练系统可以包括用一个或多个数据集训练的一个或多个模型。该系统还可以包括权重,例如模型或神经网络的嵌入权重。
[0110]
如本文所用,术语“人工智能”通常是指能够以“智能”或非重复或死记硬背或预编程的方式执行任务的机器或计算机。
[0111]
如本文所用,术语“机器学习”是指机器(例如,计算机程序)可以在没有被编程的情况下自行学习的一种学习类型。
[0112]
如本文所用,术语“机器学习”是指机器(例如,计算机程序)可以在没有被编程的情况下自行学习的一种学习类型。
[0113]
如本文所用,术语“约”数字是指该数字加上或减去该数字的10%。术语“约”范围是指该范围减去其最低值的10%,以及加上其最大值的10%。
[0114]
如本文所用,短语“a、b、c和d中的至少一个”是指a、b、c或d,以及包含a、b、c和d中的两个或两个以上的任何和所有组合。
[0115]
实例
[0116]
实例1:构建所有蛋白质功能和特征的模型
[0117]
本实例描述了针对特定蛋白质功能或蛋白质性质的迁移学习中第一模型的构建。第一模型是用来自uniprot数据库(https://www.uniprot.org/)的5800万个蛋白质序列训练的,其中在跨7个不同的功能表示(go、pfam、关键字、kegg本体论、interpro、supfam和orthodb)具有172,401+个注释。该模型是基于遵循残差学习架构的深度神经网络。网络的输入是表示为“独热”向量的蛋白质序列,该向量将氨基酸序列编码为矩阵,其中每行恰好含有1个非零条目,该条目对应于该残基处存在的氨基酸。该矩阵允许25种可能的氨基酸来覆盖所有典型和非典型氨基酸的可能性,并且所有长度长于1000个氨基酸的蛋白质被截短为前1000个氨基酸。然后输入通过以下进行处理:具有64个过滤器的1维卷积层,然后是批归一化、修正线性(relu)激活函数,并且最后通过1维最大池化操作。这被称为“输入块”并且在图1中示出。
[0118]
在输入块之后,进行称为“恒等残差块”和“卷积残差块”的一系列重复的操作。恒等残差块进行一系列1维卷积、批归一化和relu激活,以将输入转换为块,同时保留输入的形状。然后将这些转换的结果添加回输入并使用relu激活转换,并且然后传递到后续层/块。图2中示出实例性恒等残差块。
[0119]
卷积残差块类似于恒等残差块,不同的是该卷积残差块不是鉴定分支,它含有具有调整输入大小的单个卷积操作的分支。这些卷积残差块用于改变(例如,经常增加)网络内部蛋白质序列表示的大小。卷积残差块的实例在图3中示出。
[0120]
在输入块之后,使用以卷积残差块形式的一系列操作(以调整表示的大小),然后使用2
‑
5个恒等残差块来构建网络的核心。该方案(卷积残差块+多个恒等残差块)总共重复了5次。最后,执行全局平均合并层,然后是具有512个隐藏单元的密集层,以创建序列嵌入。嵌入可以被视为存在于512维空间中的向量,该向量对序列中与功能相关的所有信息进行编码。使用嵌入,使用每个注释的线性模型预测172,401个注释中的每个注释的存在或不存在。显示该过程的输出层在图4中示出。
[0121]
在具有8个v100 gpu的计算节点上,使用称为adam的随机梯度下降的变体通过训练数据集中的57,587,648个蛋白质对模型进行6次完整训练。训练大约需要一周。使用由大约700万个蛋白质构成的验证数据集对训练的模型进行了验证。
[0122]
网络被训练以最小化每个注释的二元交叉熵总和,使用分类交叉熵损失的orthodb除外。由于一些注释非常罕见,因此损失再权重策略改进了性能。对于每个二进制分类任务,使用少数类别的逆频率的平方根,对少数类别(例如,肯定类别)的损失进行增权重。这鼓励网络大致相等地“关注”肯定实例和否定实例,即使大多数序列对于绝大多数注释都是否定实例。
[0123]
最终模型导致总体经权重f1准确性结果为0.84(表1),以跨7个不同任务仅从一级蛋白质序列预测任何标签。f1是精确率和召回率的调和平均值的准确性测量,并且在1时是完美的,在0时完全失败。宏观和微观平均准确性示于表1。对于宏观平均值,每个类别的准确性都是独立计算的,并且然后确定平均值。这种方法同样地处理所有类别。微观平均准确性汇总了所有类别的贡献以计算平均指标。
[0124]
表1:第一模型的预测准确性
[0125]
来源宏观微观go0.420.75interpro0.630.83关键字0.800.88ko0.230.25orthodb0.760.91pfam0.630.82supfam0.770.91
[0126]
实例2:蛋白质稳定性的深度神经网络分析技术
[0127]
该实例描述了第二模型的训练,以直接从一级氨基酸序列预测特定蛋白质性质,即蛋白质稳定性。实例1中描述的第一模型用作第二模型训练的起点。
[0128]
第二模型的数据输入获得自rocklin等人,science[科学],2017,并包括30,000种小蛋白,已在高通量酵母展示测定中评估了这些小蛋白的蛋白质稳定性。简而言之,为了生成该实例中第二模型的数据输入,通过使用酵母展示系统来测定蛋白质的稳定性,其中每个测定的蛋白质都遗传地融合至可以被荧光标记的表达标签。将细胞与不同浓度的蛋白酶一起温育。通过荧光激活的细胞分选(facs)分离那些展示稳定蛋白质的细胞,并通过深度
测序确定每种蛋白质的身份。确定了最终稳定性评分,该评分表明了未折叠状态下该序列的测量的ec50和预测的ec50之间的差异。
[0129]
该最终稳定性评分用作第二模型的数据输入。从rocklin等人发表的补充数据中提取56,126个氨基酸序列的实值稳定性评分,然后打乱并随机分配到40,000个序列的训练集或16,126个序列的独立测试集。
[0130]
通过去除注释预测的输出层并添加具有线性激活函数的密集连接的1维输出层来调整实例1的预训练模型的架构,以适应每个样本的蛋白质稳定性值。使用128个序列的批量大小和学习率为1x 10
‑4的adam优化,该模型拟合90%的训练数据并使用剩余的10%进行验证,最小化均方误差(mse),持续多达25轮(epoch)(如果连续两轮验证损失增加,则提前停止)。对预训练模型(其具有预训练权重的迁移学习模型)并且对具有随机初始化参数的相同模型架构(“朴素”模型)重复该过程。对于基线比较,具有l2正则化的线性回归模型(“岭”模型)拟合相同的数据。经由mse和皮尔逊相关性评估独立测试集中的预测值与实际值的性能。接下来,通过从训练集中抽取10个随机样本来创建“学习曲线”,样本大小为10、50、100、500、1000、5000和10000,并对每个模型重复上述训练/测试程序。
[0131]
在如实例1中所述训练第一模型并将其用作当前实例2中所述的第二模型训练的起点后,展示了预测稳定性和预期稳定性之间的皮尔逊相关系数为0.72,mse为0.15(图5),其中预测能力与标准线性回归模型相比提高了24%。图6的学习曲线展示了预训练模型在低样本量下的高相对准确性,其随着训练集的增长而持续。与朴素模型相比,预训练模型需要更少的样本来实现同等的性能水平,尽管这些模型似乎在高样本量时如预期的那样收敛。两种深度学习模型在一定样本量下都优于线性模型,因为线性模型的性能最终会饱和。
[0132]
实例3:蛋白荧光的深度神经网络分析技术
[0133]
该实例描述了第二模型的训练,以直接从一级序列预测特定蛋白质功能,即荧光。
[0134]
实例1中描述的第一模型用作第二模型训练的起点。在该实例中,第二模型的数据输入来自sarkisyan等人,nature[自然],2016中,并包括51,715个经标记的gfp变体。简而言之,使用荧光激活细胞分选测定gfp活性以将表达每个变体的细菌分选为具有510nm发射的不同亮度的八个群体。
[0135]
通过去除注释预测的输出层并添加具有sigmoid激活函数的密集连接的1维输出层来调整实例1的预训练模型的架构,以将每个序列分类为发荧光或不发荧光。使用128个序列的批量大小和adam优化(具有1x10
‑4的学习率)训练模型以最小化二元交叉熵,持续200轮。对于具有预训练权重的迁移学习模型(“预训练”模型)以及对于具有随机初始化参数的相同模型架构(“朴素”模型)重复该过程。对于基线比较,具有l2正则化的线性回归模型(“岭”模型)拟合相同的数据。
[0136]
完整数据拆分为训练集和验证集,其中验证数据是前20%最亮的蛋白质,训练集是后80%。为了估计迁移学习模型如何改进非迁移学习方法,对训练数据集进行二次采样,以创建40、50、100、500、1000、5000、10000、25000、40000和48000个序列的样本大小。对来自完整训练数据集的每个样本大小的10个实现进行随机抽样,以测量每种方法的性能和可变性。感兴趣的主要指标是肯定预测值,该预测值是来自模型的所有肯定预测中真肯定的百分比。
[0137]
迁移学习的添加既增加了总肯定预测值,但也允许使用比任何其他方法更少的数
据的预测能力(图7)。例如,用100个序列函数gfp对作为第二模型的输入数据,添加用于训练的第一模型导致错误预测减少了33%。此外,仅用40个序列函数gfp对作为第二模型的输入数据,添加用于训练的第一模型导致70%的肯定预测值,而单独的第二模型或标准逻辑回归模型未定义,具有0肯定预测值。
[0138]
实例4:蛋白质酶活性的深度神经网络分析技术
[0139]
该实例描述了第二模型的训练,以直接从一级氨基酸序列预测蛋白质酶活性。第二模型的数据输入来自halabi等人,cell[细胞],2009,并包括1,300个s1a丝氨酸蛋白酶。引自文章的数据说明如下:“包含s1a、pas、sh2和sh3家族的序列是通过迭代psi
‑
blast(altschul等人,1997),并用cn3d(wang等人,2000)和clustalx(thompson等人,1997)进行比对,然后是标准的手动调整方法(doolittle,1996)从ncbi非冗余数据库(版本2.2.14,2006年5月7日)中收集的。”使用该数据训练第二模型,其目标是针对以下类别从一级氨基酸序列预测一级催化特异性:胰蛋白酶、胰凝乳蛋白酶、颗粒酶和激肽释放酶。对这4个类别共有422个序列。重要的是,所有模型都没有使用多序列比对,这表明该任务在无需多序列比对的情况下是可能的。
[0140]
通过去除注释预测的输出层并添加具有softmax激活函数的密集连接的4维输出层来调整实例1的预训练模型的架构,以将每个序列分类为4个可能类别中的1个。使用128个序列的批量大小和学习率为1x10
‑4的adam优化,该模型拟合90%的训练数据并使用剩余的10%进行验证,最小化分类交叉熵,持续多达500轮(如果连续十轮验证损失增加,则提前停止)。整个过程重复10次(称为10倍交叉验证),以评估每个模型的准确性和可变性。对预训练模型(其具有预训练权重的迁移学习模型)并且对具有随机初始化参数的相同模型架构(“朴素”模型)重复该过程。对于基线比较,具有l2正则化的线性回归模型(“岭”模型)拟合相同的数据。性能是评估每个折叠中保留的数据的分类准确性。
[0141]
在如实例1中所述训练第一模型并将它用作当前实例2中描述的第二模型的训练起点后,结果表明与使用朴素模型为81%和使用线性回归为80%相比,使用预训练模型的中值分类准确性为93%。这示于表2中。
[0142]
表2:s1a丝氨酸蛋白酶数据的分类准确性
[0143][0144]
实例5:蛋白溶解度的深度神经网络分析技术
[0145]
许多氨基酸序列导致在溶液中聚集的结构。降低氨基酸序列聚集的趋势(例如,提高溶解度)是设计更好疗法的目标。因此,用于直接从序列预测聚集和溶解度的模型是实现这一目标的重要工具。该实例描述了转换器架构的自我监督预训练和随后的模型微调,以经由读取反向性质蛋白质聚集来预测淀粉样蛋白β(aβ)溶解度。在高通量深度突变扫描中,对所有可能的单点突变使用聚集测定来测量数据。gray等人,“elucidating the molecular determinants of aβaggregation with deep mutational scanning[用深度突变扫描阐明aβ聚集的分子决定因素]”于g3,2019中,包括在至少一个实例中用于训练本模型的数据。然而,在一些实施例中,其他数据可用于训练。在该实例中,使用与之前实例不
同的编码器架构展示了迁移学习的有效性,在此情况下使用的是转换器而不是卷积神经网络。迁移学习改善了模型对训练数据中看不到的蛋白质位置的泛化。
[0146]
在该实例中,数据被收集并格式化为一组791个序列标签对。标签是每个序列经多次重复的实值聚集测定测量值的平均值。数据通过两种方法以4:1的比率拆分为训练集/测试集:(1)随机化,其中每个经标记的序列分配给训练集、验证集或测试集,或(2)通过残基,其中将在给定位置具有突变的所有序列聚集在训练或测试集中,使得该模型在训练期间与来自某些随机选择的位置的数据隔离(例如,从不暴露于),但被强制对保留的测试数据预测这些不可见位置处的输出。图11说明了按蛋白质位置拆分的示例性实施例。
[0147]
该实例使用bert语言模型的转换器架构来预测蛋白质的性质。模型以“自我监督”的方式进行训练,使得输入序列的某些残基对于模型被掩蔽或隐藏,并且该模型的任务是在给定未掩蔽残基的情况下确定被掩蔽残基的身份。在该实例中,模型使用超过1.56亿个蛋白质氨基酸序列的全集进行训练,这些氨基酸序列可在模型开发时从uniprotkb数据库下载。对于每个序列,从模型中随机掩蔽15%的氨基酸位置,将掩蔽序列转换为实例1中描述的“独热”输入格式,并训练模型以最大化掩蔽预测的准确性。本领域普通技术人员可以理解rives等人,“biological structure and function emerge from scaling unsupervised learning to 250m protein sequences[生物结构和功能从无监督学习扩展到2.5亿蛋白质序列]”,http://dx.doi.org/10.1101/622803,2019(以下简称“rives”)描述了其他应用。
[0148]
图10a是说明本披露的示例性实施例的框图1050。图1050说明了训练omniprot(一种可以实施本披露中描述的方法的系统)。omniprot可以指预训练的转换器。可以理解,omniprot的训练在多个方面与rives等人相似,但也有变化。首先,序列和具有所述序列的性质(预测函数或其他性质)的相应注释预训练1052omniprot的神经网络/模型。这些序列是巨大的数据集,并且在该实例中是1.56亿个序列。然后,较小的数据,特定的库测量值,微调1054omniprot。在该特定的实例中,较小的数据集是791个淀粉样蛋白β序列聚集标签。然而,本领域普通技术人员可以认识到可以采用其他数量的序列和标签以及其他类型。一旦微调,omniprot数据库就可以输出序列的预测函数。
[0149]
在更详细的水平上,迁移学习方法微调了蛋白质聚集预测任务的预训练模型。转换器架构中的解码器被去除,它显示l x d维张量作为剩余编码器的输出,其中l是蛋白质的长度,并且嵌入维度d是超参数。通过计算长度维度l上的平均值,将该张量缩减为d维嵌入向量。然后,添加具有线性激活函数的新的密集连接的1维输出层,并拟合模型中所有层的权重到标量聚集测定值。对于基线比较,具有l2正则化的线性回归模型和朴素转换器(使用随机初始化而不是预训练权重)也拟合到训练数据。对于保留的测试数据,使用预测相对于真实标签的皮尔逊相关性来评估所有模型的性能。
[0150]
图12说明了使用随机拆分和按位置拆分的线性转换器、朴素转换器和预训练转换器结果的示例性结果。对于所有三种模型,按位置拆分数据是一项更困难的任务,其中使用所有类型的模型,性能均下降。由于数据的本质,线性模型无法从基于位置的拆分中的数据中学习。对于任何特定的氨基酸变体,独热输入向量在训练集和测试集之间没有重叠。然而,两种转换器模型(例如,朴素转换器和预训练转换器)都能够将蛋白质聚集规则从一组位置泛化到训练数据中看不到的另一组位置,其中与数据的随机拆分相比,准确性只有很
小的损失。朴素转换器的r=0.80,预训练转换器的r=0.87。此外,对于这两种类型的数据拆分,预训练转换器的准确性远高于朴素模型,证明了在具有与之前实例完全不同的深度学习架构情况下迁移学习对蛋白质的能力。
[0151]
实例6:对于酶活性预测而言的连续靶向预训练
[0152]
l
‑
天冬酰胺酶是一种代谢酶,其将氨基酸天冬酰胺转化为天冬氨酸和铵。虽然人类自然会产生这种酶,但高活性细菌变体(源自大肠杆菌或菊欧文氏菌)通过直接注射到体内用来治疗某些白血病。天冬酰胺酶通过从血液中去除l
‑
天冬酰胺发挥作用,杀死依赖该氨基酸的癌细胞。
[0153]
以开发酶活性预测模型为目标,对一组197个天然存在的ii型天冬酰胺酶序列变体进行了分析。所有序列都作为克隆质粒订购,在大肠杆菌中表达,分离,并测定酶的最大酶促速率,如下所示:96孔高结合板用抗6his标签抗体包被。然后使用bsa封闭缓冲液将孔清洗和封闭。封闭后,再次洗涤孔,并且然后与含有表达的his标签的asn酶的适当稀释的大肠杆菌裂解物一起孵育。1小时后,洗涤板并加入天冬酰胺酶活性测定混合物(来自biovision试剂盒k754)。酶活性通过分光光度法在540nm处测量,每分钟读取一次,持续25分钟。将4分钟窗口内的最高斜率作为每种酶的最大瞬时速率,以确定每个样本的速率。所述酶促速率是蛋白质功能的一个实例。这些活性经标记的序列被分成100个序列的训练集和97个序列的测试集。
[0154]
图10b是说明本披露的方法的示例性实施例的框图1000。从理论上讲,对来自实例5的预训练模型的随后一轮无监督微调(使用所有已知的天冬酰胺酶样蛋白质)提高了模型在迁移学习任务中对少量测量序列的预测性能。实例5的预训练转换器模型(其最初在来自uniprotkb的所有已知蛋白质序列的全域内进行了训练)在使用interpro家族ipr004550,“l
‑
天冬酰胺酶,ii型”注释的12,583个序列上进一步微调。这是一个两步预训练过程,其中两个步骤都应用与实例5相同的自监督方法。
[0155]
具有转换器编码器和解码器1006的第一系统1001使用具有所有蛋白质的组进行训练。在该实例中,使用了1.56亿个蛋白质序列,然而,本领域普通技术人员可以理解可以使用其他数量的序列。本领域普通技术人员可以进一步理解,用于训练模型1001的数据的大小大于用于训练第二系统1011的数据的大小。第一模型生成预训练模型1008,该模型被发送到第二系统1011。
[0156]
第二系统1011接受预训练模型1008,并用asn酶序列1012的较小数据集训练模型。然而,本领域普通技术人员可以认识到,可以使用其他数据集进行该微调训练。然后第二系统1011通过用线性回归层1026替换解码器层1016并进一步训练所得模型以预测标量酶促活性值1022(作为监督任务)来应用迁移学习方法以预测活性。经标记的序列被随机拆分成训练集和测试集。该模型用100个活性经标记的天冬酰胺酶序列1022的训练集进行训练,然后用保留的测试集评估性能。从理论上讲,具有第二预训练步骤的迁移学习(利用蛋白质家族中的所有可用序列)在低数据情景(即当第二训练的数据比初始训练少或少得多时)下显著提高了预测准确性。
[0157]
图13a是说明1000个未标记的天冬酰胺酶序列的掩蔽预测的重构误差的图。图13a说明,与使用天然天冬酰胺酶序列模型(右)微调的omniprot相比,天冬酰胺酶蛋白(左)的第二轮预训练后的重构误差降低了。图13b是说明仅用100个经标记的序列训练后,对97个
保留的活性经标记的序列的预测准确性的图。与单(omniprot)预训练步骤相比,两步预训练显著改善了测量的活性相对于模型预测的皮尔逊相关性。
[0158]
在以上描述和实例中,本领域普通技术人员可以认识到样本大小、迭代、轮、批次大小、学习率、准确性、数据输入大小、过滤器、氨基酸序列和其他数字的特定数量可以调整或优化。尽管在实例中描述了特定实施例,但实例中列出的数字是非限制性的。
[0159]
虽然本文已经显示和描述了本发明的优选实施例,但是本领域技术人员将理解的是,此类实施例仅以举例的方式提供。在不脱离本发明的情况下,现在本领域技术人员将想到许多改变、变化和取代。应该理解的是,本文所述的本发明的实施例的各种替代方案可用于实践本发明。其意图是以下权利要求限定本发明的范围,并且由此覆盖这些权利要求及其等同项范围内的方法和结构。虽然示例性实施例已进行了具体显示和描述,但本领域的技术人员应当理解,在不偏离由所附权利要求书涵盖的本实施例范围的情况下,可以在其中做出在形式和细节方面的各种改变。
[0160]
所有专利、公开的申请以及在此引用的参考文献的传授内容都通过引用将其全文进行结合。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1