问卷生成方法、分类模型的训练方法、装置和计算机设备与流程
1.本申请涉及临床试验技术领域,特别是涉及一种问卷生成方法、分类模型的训练方法、装置、计算机设备和存储介质。
背景技术:
2.随着临床试验技术的发展,出现了越来越多的临床试验项目,针对临床试验项目所需的受试者,传统的方式中采用面对面沟通的方式获取受试者的特征信息,或者,针对每一临床试验项目根据其多条入排标准人工制定调查问卷收集受试者的特征信息。
3.然而,传统方式中受试者的特征信息收集方式均需要花费大量人力成本,且对应的招募临床试验受试者的效率低下。
技术实现要素:
4.基于此,有必要针对上述技术问题,提供一种问卷生成方法、分类模型的训练方法、装置、计算机设备和存储介质。
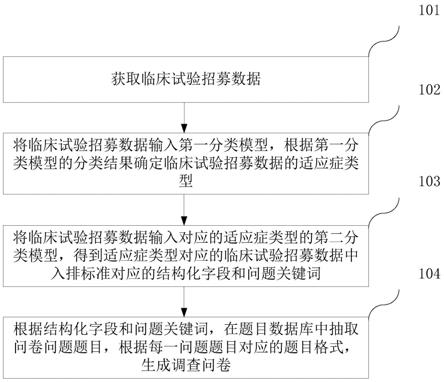
5.一种问卷生成方法,所述方法包括:
6.获取临床试验招募数据;
7.将所述临床试验招募数据输入第一分类模型,根据所述第一分类模型的分类结果确定所述临床试验招募数据的适应症类型;
8.将所述临床试验招募数据输入对应的适应症类型的第二分类模型,得到所述适应症类型对应的临床试验招募数据中入排标准对应的结构化字段和问题关键词;
9.根据所述结构化字段和所述问题关键词,在题目数据库中抽取问卷问题题目,根据每一所述问题题目对应的题目格式,生成调查问卷。
10.在其中一个实施例中,所述获取临床试验招募数据,包括:
11.获取待处理的临床试验招募文本数据;
12.将待处理的所述临床试验招募文本数据通过训练好的词向量化模型进行向量化处理,得到所述临床试验招募文本数据的向量化结果,将所述向量化结果作为所述临床试验招募数据。
13.一种分类模型的训练方法,其特征在于,所述方法包括:
14.获取第一临床试验招募训练样本,所述第一临床试验招募训练样本中包含每一临床试验招募训练数据的整句向量化值;
15.将所述第一临床试验招募训练样本中的整句向量化值输入至分类模型中,通过所述分类模型得到初始分类结果;
16.根据所述第一临床试验招募训练样本携带的适应症类别标签和适应症细分特征标签对应的基准分类结果对所述初始分类结果进行验证,若所述初始分类结果与所述基准分类结果不一致,则对所述分类模型进行模型参数调整。
17.在其中一个实施例中,所述获取第一临床试验招募训练样本,包括:
18.获取临床试验招募文本数据;
19.根据词向量化模型以及预设的加权平均算法,得到每一条所述临床试验招募文本数据的整句向量化值;
20.根据分类基准向量化值,对所述临床试验招募数据进行分类处理,得到所述临床试验招募文本数据的整句向量化值的分类结果;
21.针对每一所述分类结果进行适应症类别和适应症细分特征的标注,得到携带所述适应症类别标签和所述适应症细分特征标签的第一临床试验招募训练样本。
22.一种分类模型的训练方法,所述方法包括:
23.获取第二临床试验招募训练样本;所述第二临床试验招募训练样本中包含每一临床试验招募训练数据的入排标准向量化值;
24.将所述第二临床试验招募训练样本输入分类模型中,得到所述临床试验招募数据的分类结果;
25.根据所述第二临床试验招募训练样本携带的入排标准结构化字段标签和问题关键词标签对应的基准分类结果对所述分类模型得到的分类结果进行验证,若所述分类结果与所述基准分类结果不一致,则对所述分类模型进行模型参数调整。
26.在其中一个实施例中,所述获取第二临床试验招募训练样本,包括:
27.根据适应症类别获取对应的临床试验招募文本数据;
28.对每一适应症类别的所述临床试验招募文本数据进行向量化处理,得到所述临床试验招募文本数据对应的向量化结果;
29.根据基准向量化结果,对所述临床试验招募文本数据中的向量化结果进行分类处理,得到对应的分类结果;
30.针对每一分类结果进行入排标准的结构化字段和对应的问题关键词的标注,得到携带有入排标准结构化字段标签和问题关键词标签的第二临床试验招募数据样本。
31.一种问卷生成装置,所述装置包括:
32.获取模块,用于获取临床试验招募数据;
33.第一分类模块,用于将所述临床试验招募数据输入第一分类模型,根据所述第一分类模型的分类结果确定所述临床试验招募数据的适应症类型;
34.第二分类模块,用于将所述临床试验招募数据输入对应的适应症类型的第二分类模型,得到所述适应症类型对应的临床试验招募数据中入排标准对应的结构化字段和问题关键词;
35.生成模块,用于根据所述结构化字段和所述问题关键词,在题目数据库中抽取问卷问题题目,根据每一所述问题题目对应的题目格式,生成调查问卷。
36.在其中一个实施例中,所述获取模块还用于获取待处理的临床试验招募文本数据;
37.将待处理的所述临床试验招募文本数据通过训练好的词向量化模型进行向量化处理,得到所述临床试验招募文本数据的向量化结果,将所述向量化结果作为所述临床试验招募数据。
38.一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现以下步骤:
39.获取临床试验招募数据;
40.将所述临床试验招募数据输入第一分类模型,根据所述第一分类模型的分类结果确定所述临床试验招募数据的适应症类型;
41.将所述临床试验招募数据输入对应的适应症类型的第二分类模型,得到所述适应症类型对应的临床试验招募数据中入排标准对应的结构化字段和问题关键词;
42.根据所述结构化字段和所述问题关键词,在题目数据库中抽取问卷问题题目,根据每一所述问题题目对应的题目格式,生成调查问卷。
43.一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现以下步骤:
44.获取临床试验招募数据;
45.将所述临床试验招募数据输入第一分类模型,根据所述第一分类模型的分类结果确定所述临床试验招募数据的适应症类型;
46.将所述临床试验招募数据输入对应的适应症类型的第二分类模型,得到所述适应症类型对应的临床试验招募数据中入排标准对应的结构化字段和问题关键词;
47.根据所述结构化字段和所述问题关键词,在题目数据库中抽取问卷问题题目,根据每一所述问题题目对应的题目格式,生成调查问卷。
48.上述问卷生成方法、装置、计算机设备和存储介质,获取临床试验招募数据;将所述临床试验招募数据输入第一分类模型,根据所述第一分类模型的分类结果确定所述临床试验招募数据的适应症类型;将所述临床试验招募数据输入对应的适应症类型的第二分类模型,得到所述适应症类型对应的临床试验招募数据中入排标准对应的结构化字段和问题关键词;根据所述结构化字段和所述问题关键词,在题目数据库中抽取问卷问题题目,根据每一所述问题题目对应的题目格式,生成调查问卷。采用本方法,通过第一分类模型确定临床试验招募数据的适应症类别,通过第二分类模型确定临床试验招募数据入排标准的结构化字段及对应的问题关键词,进而根据结构化字段和问题关键词结合题目数据库,自动化生成调查问卷,提高调查问卷生成效率。
附图说明
49.图1为一个实施例中问卷生成方法的流程示意图;
50.图2为一个实施例中题目数据库的数据存储形式示意图;
51.图3为一个实施例中生成的不同适应症类型初始调查问卷的示意图;
52.图4为一个实施例中获取临床试验招募数据的步骤的流程示意图;
53.图5为一个实施例中第一分类模型的训练方法的流程示意图;
54.图6为一个实施例中构建第一临床试验招募训练样本的步骤的流程示意图;
55.图7为一个实施例中第二分类模型的训练方法的流程示意图;
56.图8为一个实施例中构建第二临床试验招募训练样本的步骤的流程示意图;
57.图9为一个实施例中问卷生成装置的结构框图;
58.图10为一个实施例中分类模型的训练装置的结构框图;
59.图11为一个实施例中分类模型的训练装置的结构框图;
60.图12为一个实施例中计算机设备的内部结构图。
具体实施方式
61.为了使本申请的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本申请进行进一步详细说明。应当理解,此处描述的具体实施例仅仅用以解释本申请,并不用于限定本申请。
62.在一个实施例中,如图1所示,提供了一种问卷生成方法,本实施例以该方法应用于终端进行举例说明,可以理解的是,该方法也可以应用于服务器,还可以应用于包括终端和服务器的系统,并通过终端和服务器的交互实现。本实施例中,该方法包括以下步骤:
63.步骤101,获取临床试验招募数据。
64.在实施中,计算机设备获取临床试验招募数据,该临床试验招募数据是基于发布的临床试验招募文本信息经过向量化处理得到的结构化数据。
65.步骤102,将临床试验招募数据输入第一分类模型,根据第一分类模型的分类结果确定临床试验招募数据的适应症类型。
66.其中,第一分类模型为临床试验项目的适应症(或疾病)分类模型,具体地,第一分类模型可以为逻辑回归分类模型、随机森林分类模型、决策树分类模型和gbdt(gradient boosting decision tree,梯度提升决策树)分类模型等,本实施例不做限定。
67.在实施中,计算机设备将临床试验招募数据输入第一分类模型,通过该第一分类模型的分类处理,确定临床试验招募数据对应的适应症类型。
68.具体地,针对全网公布的全部种类的适应症类型(或疾病类型),分别对应建立一个第一分类模型,若全网有100000种适应症类型(也包含具体的疾病细分特征),则对应有100000个第一分类模型,将待处理的临床试验招募数据输入至100000个第一分类模型中进行遍历,针对每个分类模型给出的分类结果,即判断出是或否该类适应症(也包括疾病细分特征),可以确定出该临床试验招募数据对应的适应症类型和疾病细分特征。
69.如下表1所示,针对输入的临床试验数据输出(output)的适应症类型分类和疾病细分特征:
[0070][0071]
步骤103,将临床试验招募数据输入对应的适应症类型的第二分类模型,得到适应症类型对应的临床试验招募数据中入排标准对应的结构化字段和问题关键词。
[0072]
其中,每一第二分类模型对应一种适应症类型,第二分类模型是针对该类适应症类型的临床试验的入排标准的分类模型,具体地,该第二分类模型可以为逻辑回归分类模型、随机森林分类模型、决策树分类模型和gbdt分类模型等,本实施例不做具体限定。
[0073]
在实施中,在确定临床试验的适应症类型之后,计算机设备将临床试验招募数据输入对应的适应症类型的第二分类模型,通过该第二分类模型的分类处理,将临床试验数据中全部的向量化结果进行分类,得到该适应症类型下临床试验招募数据中向量化结果的分类结果,而每一向量化结果对应的分类结果对应一种入排标准对应的结构化字段和问题关键词。
[0074]
例如,如下表2所示,针对输入的临床试验数据输出(output)的结构化字段和问题关键词:
[0075]
表2
[0076][0077]
步骤104,根据结构化字段和问题关键词,在题目数据库中抽取问卷问题题目,根据每一问题题目对应的题目格式,生成调查问卷。
[0078]
在实施中,计算机设备根据临床试验数据确定出的结构化字段和问题关键词(即question_key),在题目数据库(question_dict)中抽取对应的问卷问题题目,其中,每一问卷题目对应配置了题目形式(例如,选择题或填空题),根据每一问题题目对应的题目格式,生成调查问卷。
[0079]
具体地,题目数据库中的问题关键词与具体问卷问题的题目格式的存储形式,如图2所示,其中,针对“age”(年龄)这一问题关键词,对应的具体问卷题目格式为{“type”:“text”,“name”:“question1”,“title”:患者年龄,“isrequired
”……
}其中,类型为“text”文本形式,题目为:question1,第一题,问题题目为“患者年龄“,题目属性:isrequired必答题,
……
则每一适应症类型的临床试验招募数据确定出的所有结构化字段和问题关键词均对应确定出问题题目以及题目格式,进而生成初始调查问卷(也称为问卷草稿版question_draft版),如图3所示,进而得到针对每一适应症类型的调查问卷。
[0080]
可选地,针对所有生成的调查问卷草稿(question_draft),可以将其发送至计算机设备前端进行输出显示,并通过本领域技术人员对调查问卷进行进一步验证,确保调查问卷的准确性和专业性,若调查问卷草稿无误,则将该版调查问卷草稿作为最终版本发布至患者客户端进行调查问卷的填写,若调查问卷存在错误,则由本领域技术人员对齐进行修正,同时,再度输入计算机设备,通过修改正后的调查问卷与调查问卷草稿版进行对比,实现计算机设备内部各模型的模型训练。
[0081]
上述问卷生成方法中,获取临床试验招募数据;将临床试验招募数据输入第一分类模型,根据第一分类模型的分类结果确定临床试验招募数据的适应症类型;将临床试验招募数据输入对应的适应症类型的第二分类模型,得到适应症类型对应的临床试验招募数
据中入排标准对应的结构化字段和问题关键词;根据结构化字段和问题关键词,在题目数据库中抽取问卷问题题目,根据每一问题题目对应的题目格式,生成调查问卷。采用本方法,通过第一分类模型确定临床试验招募数据的适应症类别,通过第二分类模型确定临床试验招募数据入排标准的结构化字段及对应的问题关键词,进而根据结构化字段和问题关键词结合题目数据库,自动化生成调查问卷,提高调查问卷生成效率。
[0082]
在一个实施例中,如图4所示,步骤101的具体处理过程包括以下步骤:
[0083]
其中,各网络平台发布的临床试验招募信息为临床试验招募文本数据,因此,在对每一临床试验招募信息进行问卷生成之前,需要对临床试验招募文本数据进行预处理,得到计算机设备可以识别的数值数据。
[0084]
步骤401,获取待处理的临床试验招募文本数据。
[0085]
在实施中,计算机设备获取待处理的临床试验招募文本数据。待处理的临床试验招募文本数据包括适应症/疾病、试验目的和试验专业题目,例如,如下表3所示的多条临床试验招募文本数据:
[0086]
表3
[0087]
[0088][0089]
另外,该临床试验招募文本数据中还包括针对该临床试验招募数据的入排标准信息,例如,最小年龄、最大年龄、性别、是否用药、不良事件等,本实施例不在表格中进行展示。
[0090]
步骤402,将待处理的临床试验招募文本数据通过训练好的词向量化模型进行向量化处理,得到临床试验招募文本数据的向量化结果,将向量化结果作为临床试验招募数据。
[0091]
在实施中,计算机设备将待处理的临床试验招募文本数通过训练好的词向量化模型(word2vec)进行向量化处理,得到临床试验招募文本数据的向量化结果,然后,将该向量化结果作为后续可输入分类模型进行处理的临床试验招募数据。
[0092]
具体地,训练好的词向量化模型word2vec将临床试验招募文本数据三大指标(适应症、试验目的和试验专业题目)中的字段按照词语进行切分,针对每个词语进行词语向量化得到word2vec值,再由每个词语的词语向量化结果(word2vec值)的加权平均可以得到分句向量化结果,即得到每个分句的sentence2vec值,三个指标对应的sentence2vec值加权平均得到该条临床试验招募文本数据的整句向量化值(即row2vec)。另外,针对该临床试验招募数据中的入排标准信息,针对每条入排标准也通过词向量化模型进行向量化,得到每条入排标准中包含的词语向量值(word2vec值),进而对词语向量化值加权平均得到该条入排标准的分句向量化值sentence2vec值,对此一条临床试验招募文本数据中的关键指标均已向量化处理完成。
[0093]
可选地,对于词向量化模型,利用预先构建好的训练样本(包含训练集、验证集和测试集),在经过词向量化模型对训练样本中的训练集的初始向量化赋值,结果验证集中的验证结果对词向量化模型进行参数调整,并通过测试集对训练好的词向量化模型进行测试,得到模型最终测试结果,确定该训练好的模型参数下,新输入的临床试验数据会对应的转换为准确的向量化值。其中,为了提高词向量化模型对于临床试验专业化名词的辨识度的赋值准确度,训练样本可以采用临床试验领域的专业高频名词词典进行构建,本申请实施例不做限定。
[0094]
本实施例中,通过将临床试验的招募文本数据转换为对应的向量化结果,便于计算机设备进行识别处理,提高了临床试验数据的处理效率。
[0095]
在一个实施例中,如图5所示,提供了一种分类模型的训练方法,以该方法应用于终端为例进行说明,包括以下步骤:
[0096]
步骤501,获取第一临床试验招募训练样本,第一临床试验招募训练样本中包含每一临床试验招募训练数据的整句向量化值。
[0097]
其中,分类模型对应于上述步骤102中的用于临床试验招募数据适应症分类的第一分类模型。可选地,第一分类模型可以为逻辑回归分类模型、随机森林分类模型、决策树分类模型和gbdt分类模型,本实施例不做限定。
[0098]
在实施中,计算机设备获取第一临床试验招募训练样本,该第一临床试验招募训练样本中包含每一临床试验招募训练数据的整句向量化值(即训练数据的row2vec值),其中,该第一临床试验招募训练样本中的每一条临床试验招募训练数据具备适应症类别、疾病细分特征等数据标签特征,以用于训练第一分类模型。
[0099]
步骤502,将第一临床试验招募训练样本中的整句向量化值输入至分类模型中,通过分类模型得到初始分类结果。
[0100]
在实施中,计算机设备将第一临床试验招募训练样本中的整句向量化值输入至分类模型中,通过该分类模型(第一分类模型)最初的模型参数进行分类处理,得到初始分类结果。
[0101]
步骤503,根据第一临床试验招募训练样本携带的适应症类别标签和适应症细分特征标签对应的基准分类结果对初始分类结果进行验证,若初始分类结果与基准分类结果不一致,则对分类模型进行模型参数调整。
[0102]
其中,由于第一临床试验招募训练样本包含对应的训练集、验证集和测试集,因此,针对分类模型(第一分类模型)给出的初始分类结果需要进行验证。
[0103]
在实施中,计算机设备根据第一临床试验招募训练样本携带的适应症类别标签和适应症细分特征标签得到的基准分类结果对初始分类结果进行验证,若初始分类结果与基准分类结果不一致,则对该分类模型(第一分类模型)进行模型参数调整,已完成分类模型的训练。例如,仅有三种适应症类型,分别为肺癌、食管癌和胃癌,第一分类模型选用随机森林分类模型或者决策树分类模型,另外,第一临床试验招募训练样本中包含10条临床试验招募训练数据,这10条临床试验招募训练数据中分别有3条肺癌类型的临床试验招募训练数据,5条食管癌类型的临床试验招募训练数据和2条胃癌类型的临床试验招募训练数据。针对这10条临床试验招募训练数据分别数据对应的这三类第一分类模型中,对应的基准分类结果应为:肺癌类型分类模型的分类结果3:7(3条是肺癌,7条不是肺癌);食管癌类型分类模型的分类结果5:5(5条是食管癌,5条不是食管癌);胃癌类型分类模型的分类结果2:8(2条是胃癌,8条不是胃癌)。进而,针对每一适应症类型的分类模型的所得初始分类结果,若与基准分类结果不一致,则对应需要调整该适应症类型分类模型的模型参数,直至得到准确的分类结果。
[0104]
其中,基于上述适应症类型的分类,每一适应症类型的分类模型可以得到临床试验招募数据是否为该类适应症的判别结果,以0和1进行表示,0代表“否”,不是该类适应症,1代表“是”,是该类适应症,则对应于每一临床试验招募训练数据或者临床试验招募数据(即待处理数据)针对全部种类的适应症类型可以得到对应结果向量,例如,针对上述例子中3种适应症类型,则可以得到一个三维的结果向量,其中,该三维向量中每个元素代表一种适应症类型,第一元素代表肺癌类型,第二元素代表食管癌类型,第三元素代表胃癌类型。具体地,每一肺癌类型的临床试验招募训练数据可以得到[1,0,0]结果向量,每一食管
癌类型的临床试验招募训练数据可以得到[0,1,0]结果向量,每一胃癌类型的临床试验招募训练数据可以得到[0,0,1]结果向量。
[0105]
可选地,针对临床试验中全部的适应症类型的种类,可以有3种,也可以有10万种,本实施例不做限定,适应症类型的种类与第一分类模型的数据以及对应的结果向量的向量维度保持一致。
[0106]
可选地,针对结果向量中判别是否的结果,当选用的第一分类模型为逻辑回归模型、gbdt模型时,无法针对某一适应症类型得到准确的0或1的判别结果,但是根据该结果的预设阈值,例如大于0.8即表征“是”的情况,小于0.4即表征“否”的情况,因此,结果向量还可以对应的表示为[0.1,0,9,0.2]的情况,该结果向量依旧可以表征对应的适应症类型。因此,本实施例对于结果向量的表现形式也不做限定。
[0107]
可选地,该第一分类模型的模型训练准确度需要达到的如下表2的标准:
[0108]
表2
[0109]
accuracyprecisionrecallf199%98%96%97%
[0110]
其中,accuracy是准确率,达到99%,最直观的衡量利用结构化字段抓取结构化字段值这一逻辑模型好坏的指标。precision:精确率(又称查准率)。recall:召回率(又称查全率)。f1是查准率和查全率的一个加权平均。
[0111]
本实施例中,通过第一临床试验招募训练样本对分类模型进行训练,使得对于新增的待处理临床试验招募数据,分类模型可以准确判别其对应的适应症类型和疾病细分特征,自动化处理新增的待处理的临床试验招募数据,提高临床试验招募数据的处理效率。
[0112]
在一个实施例中,如图6所示,步骤501的具体处理过程如下所示:
[0113]
步骤601,获取临床试验招募文本数据。
[0114]
在实施中,计算机设备获取临床试验招募文本数据。其中,该临床试验招募文本数据可以是从网络平台获取的历史临床试验招募文本数据,具备适应症类型和疾病细分特征以用于构建训练样本。
[0115]
步骤602,根据词向量化模型以及预设的加权平均算法,得到每一条临床试验招募文本数据的整句向量化值。
[0116]
在实施中,计算机设备根据训练好的词向量化模型以及预设的加权平均算法,得到每一条临床试验招文本数据的整句向量化值(即row2vec),具体地,根据词向量化模型(word2vec模型)得到词语向量化结果(word2vec值)并根据词语向量化结果通过加权平均计算sentence值,进而计算row2vec值的处理过程,以及在应用词向量化模型之前所需的词向量化模型的训练过程与上述步骤202的处理过程相同,本实施例不再赘述。
[0117]
步骤603,根据分类基准向量化值,对临床试验招募数据进行分类处理,得到临床试验招募文本数据的整句向量化值的分类结果。
[0118]
在实施中,计算机设备根据分类基准向量化值,对临床试验招募数据进行分类处理,得到临床试验招募文本数据的整句向量化值的分类结果。
[0119]
具体地,计算所有临床试验招募数据的整句向量化值与每一基准向量化值的相似度值,若存在整句向量化值与某一基准向量化值(例如,第一基准向量化值)间的相似度值满足预设阈值(例如,大于或等于0.8),则将满足预设阈值的临床试验招募数据作为第一基
准向量化值对应的分类类别中的组内数据,得到所有临床试验招募文本数据的整句向量化值的分类结果。
[0120]
步骤604,针对每一分类结果进行适应症类别和适应症细分特征的标注,得到携带适应症类别标签和适应症细分特征标签的第一临床试验招募训练样本。
[0121]
在实施中,计算机设备针对每一分类结果进行适应症类别和适应症细分特征的标注,即例如,针对第一基准向量化值对应的分类组(也即分类结果),将组内的临床试验招募数据标注为肺癌类别的非小细胞肺癌;针对第二基准向量化对应的分类组,将组内的临床试验招募数据标注为食管癌,将分类结果数据按照分类组排列,得到携带对应适应症类别标签和适应症细分特征标签的第一临床试验招募训练样本。
[0122]
本实施例中,通过对临床试验招募文本数据进行向量化和分类标注处理,得到可以用于分类模型训练的第一临床试验招募数据样本,通过该训练样本中携带的标签作为验证数据,为模型训练提供分类标准。
[0123]
在一个实施例中,如图7所示,提供了一种分类模型的训练方法,以该方法应用于终端为例进行说明,具体包括以下步骤:
[0124]
步骤701,获取第二临床试验招募训练样本;第二临床试验招募训练样本中包含每一临床试验招募训练数据的入排标准向量化值;
[0125]
其中,分类模型对应于上述步骤103中的用于临床试验招募数据入排标准分类的第二分类模型。可选地,第二分类模型可以为逻辑回归分类模型、随机森林分类模型、决策树分类模型和gbdt分类模型,本实施例不做限定。
[0126]
在实施中,计算机设备获取第二临床试验招募训练样本,该第二临床试验招募训练样本中包含每一临床试验招募训练数据的多条入排标准向量化值(即每一入排标准的sentence值)。例如,针对其中的一条临床试验招募训练数据的多条入排标准的向量化值分别为[0.1,0.3,0.5,0.9],[0,0.6,0.4,0.7],[0.3,0.8,0.2,0.1]
……
(其中的向量化值仅作为举例说明,并不用于限定本申请)
[0127]
步骤702,将第二临床试验招募训练样本输入分类模型中,得到临床试验招募数据的分类结果。
[0128]
在实施中,计算机设备将第二临床试验训练样本输入分类模型(即第二分类模型)中,通过该分类模型(第二分类模型)初始的模型参数进行分类处理,得到临床试验招募数据的分类结果(即向量化数值对应的入排标准分类结果,该入排标准分类结果对应入排标准的结构化字段和问题关键词)。
[0129]
步骤703,根据第二临床试验招募训练样本携带的入排标准结构化字段标签和问题关键词标签对应的基准分类结果对分类模型得到的分类结果进行验证,若分类结果与基准分类结果不一致,则对分类模型进行模型参数调整。
[0130]
在实施中,计算机设备根据第二临床试验招募训练样本携带的入排标准结构化字段标签和问题关键词标签对应的基准分类结果对分类模型(第二分类模型)初始模型参数下得到的分类结果进行验证,若分类结果与基准分类结果不一致,则对分类模型(第二分类模型)进行模型参数调整,以完成分类模型的训练。
[0131]
具体地,若第二临床试验招募训练样本中的一条临床试验招募训练数据包括3条入排标准信息,则对应的具备3个入排标准的向量化数值,针对其中每一个入排标准的向量
化数值,将其分别输入临床试验领域全部入排标准类型对应的第二分类模型(一条入排标准对应一个第二分类模型)中进行分类判别,每一分类模型可以给出该向量化数值是否对应该条入排标准的结果,即最终给出该向量化数值的具体对应入排标准结构化字段和对应的问题关键词(另外2个入排标准的向量化数值的判别方法同理)。进而,若对应得到的该向量化数值对应的入排标准的结构化字段和问题关键词与训练样本中预先携带的入排标准结构化字段标签以及问题关键词不一致,则需要对应调整分类模型的模型参数。
[0132]
在一个实施例中,如图8所示,步骤701的具体处理过程如下所示:
[0133]
步骤801,根据适应症类别获取对应的临床试验招募文本数据。
[0134]
在实施中,计算机设备根据适应症类别获取对应的临床试验招募文本数据。例如,针对肺癌类型获取对应的临床试验招募文本数据;针对食道癌类型获取对应的临床试验招募文本数据
……
[0135]
步骤802,对每一适应症类别的临床试验招募文本数据进行向量化处理,得到临床试验招募文本数据对应的向量化结果。
[0136]
在实施中,计算机设备对每一适应症类别的临床试验招募文本数据进行向量化处理,得到临床试验招募文本数据对应的向量化结果。
[0137]
具体地,针对每一类型的临床试验招募文本数据,每一条临床试验招募文本数据中的多条入排标准信息进行向量化,通过训练好的词向量化模型(word2vec)得到每条入排标准中包含的词语向量值(word2vec值),进而对词语向量化值加权平均得到该条入排标准的分句向量化值sentence2vec值,
[0138]
步骤803,根据基准向量化结果,对临床试验招募文本数据中的向量化结果进行分类处理,得到对应的分类结果。
[0139]
在实施中,计算机设备根据基准向量化结果,对临床试验招募文本数据中的向量化结果进行分类处理,得到对应的分类结果。
[0140]
具体地,计算机设备根据每一类别入排标准的基准向量化值,计算所有临床试验招募文本数据中向量化得到的向量化结果与基准向量化值间的相似度,若存在临床试验招募文本数据的向量化结果与某一基准向量化值(例如,最小年龄,最大年龄的入排标准的基准向量化值【1111】)间的相似度满足预设相似度阈值(例如,大于或等于0.8),则将这些临床试验招募文本数据的向量化结果确定为基准向量【1111】对应的入排标准的分类,进而得到全部临床试验招募文本数据的分类结果。
[0141]
步骤804,针对每一分类结果进行入排标准的结构化字段和对应的问题关键词的标注,得到携带有入排标准结构化字段标签和问题关键词标签的第二临床试验招募数据样本。
[0142]
在实施中,计算机设备针对每一分类结果进行入排标准的结构化字段和对应的问题关键词的标准,例如,针对基准向量【1111】得到的分类结果,将该分类结果进行结构化字段“min_age,max_age”标签的标注和“患者年龄”问题关键词的标注。得到全部分类结果中临床试验招募数据均携带有入排标准结构化字段标签和问题关键词标签的第二临床试验招募数据样本。
[0143]
本实施例中,通过对临床试验招募文本数据进行向量化和分类标注处理,得到可以用于分类模型训练的第二临床试验招募数据样本,通过该训练样本中携带的标签作为验
证数据,为模型训练提供分类标准。
[0144]
应该理解的是,虽然图1,4
‑
8的流程图中的各个步骤按照箭头的指示依次显示,但是这些步骤并不是必然按照箭头指示的顺序依次执行。除非本文中有明确的说明,这些步骤的执行并没有严格的顺序限制,这些步骤可以以其它的顺序执行。而且,图1,4
‑
8中的至少一部分步骤可以包括多个步骤或者多个阶段,这些步骤或者阶段并不必然是在同一时刻执行完成,而是可以在不同的时刻执行,这些步骤或者阶段的执行顺序也不必然是依次进行,而是可以与其它步骤或者其它步骤中的步骤或者阶段的至少一部分轮流或者交替地执行。
[0145]
在一个实施例中,如图9所示,提供了一种问卷生成装置900,包括:获取模块910、第一分类模块920、第二分类模块930和生成模块940,其中:
[0146]
获取模块910,用于获取临床试验招募数据;
[0147]
第一分类模块920,用于将临床试验招募数据输入第一分类模型,根据第一分类模型的分类结果确定临床试验招募数据的适应症类型;
[0148]
第二分类模块930,用于将临床试验招募数据输入对应的适应症类型的第二分类模型,得到适应症类型对应的临床试验招募数据中入排标准对应的结构化字段和问题关键词;
[0149]
生成模块940,用于根据结构化字段和问题关键词,在题目数据库中抽取问卷问题题目,根据每一问题题目对应的题目格式,生成调查问卷。
[0150]
在一个实施例中,获取模块910具体用于将待处理的临床试验招募文本数据通过训练好的词向量化模型进行向量化处理,得到临床试验招募文本数据的向量化结果,将向量化结果作为临床试验招募数据。
[0151]
在一个实施例中,如图10所示,提供了一种分类模型的训练装置1000,包括:获取模块1010、分类模块1020和训练模块1030,其中:
[0152]
获取模块1010,用于获取第一临床试验招募训练样本,第一临床试验招募训练样本中包含每一临床试验招募训练数据的整句向量化值;
[0153]
分类模块1020,用于将第一临床试验招募训练样本中的整句向量化值输入至分类模型中,通过分类模型得到初始分类结果;
[0154]
训练模块1030,用于根据第一临床试验招募训练样本携带的适应症类别标签和适应症细分特征标签对应的基准分类结果对初始分类结果进行验证,若初始分类结果与基准分类结果不一致,则对分类模型进行模型参数调整。
[0155]
在一个实施例中,获取模块1010具体用于获取临床试验招募文本数据;
[0156]
根据词向量化模型以及预设的加权平均算法,得到每一条临床试验招募文本数据的整句向量化值;
[0157]
根据分类基准向量化值,对临床试验招募数据进行分类处理,得到临床试验招募文本数据的整句向量化值的分类结果;
[0158]
针对每一分类结果进行适应症类别和适应症细分特征的标注,得到携带适应症类别标签和适应症细分特征标签的第一临床试验招募训练样本。
[0159]
在一个实施例中,如图11所示,提供了一种分类模型的训练装置1100,该包括:获取模块1110、分类模块1120和训练模块1130,其中:
[0160]
获取模块1110,用于获取第二临床试验招募训练样本;第二临床试验招募训练样本中包含每一临床试验招募训练数据的入排标准向量化值;
[0161]
分类模块1120,用于将第二临床试验招募训练样本输入分类模型中,得到临床试验招募数据的分类结果;
[0162]
训练模块1130,用于根据第二临床试验招募训练样本携带的入排标准结构化字段标签和问题关键词标签对应的基准分类结果对分类模型得到的分类结果进行验证,若分类结果与基准分类结果不一致,则对分类模型进行模型参数调整。
[0163]
在其中一个实施例中,获取模块1110具体用于根据适应症类别获取对应的临床试验招募文本数据;
[0164]
对每一适应症类别的临床试验招募文本数据进行向量化处理,得到临床试验招募文本数据对应的向量化结果;
[0165]
根据基准向量化结果,对临床试验招募文本数据中的向量化结果进行分类处理,得到对应的分类结果;
[0166]
针对每一分类结果进行入排标准的结构化字段和对应的问题关键词的标注,得到携带有入排标准结构化字段标签和问题关键词标签的第二临床试验招募数据样本。
[0167]
关于问卷生成装置的具体限定可以参见上文中对于问卷生成方法的限定,在此不再赘述。上述问卷生成装置中的各个模块可全部或部分通过软件、硬件及其组合来实现。上述各模块可以硬件形式内嵌于或独立于计算机设备中的处理器中,也可以以软件形式存储于计算机设备中的存储器中,以便于处理器调用执行以上各个模块对应的操作。
[0168]
在一个实施例中,提供了一种计算机设备,该计算机设备可以是终端,其内部结构图可以如图12所示。该计算机设备包括通过系统总线连接的处理器、存储器、通信接口、显示屏和输入装置。其中,该计算机设备的处理器用于提供计算和控制能力。该计算机设备的存储器包括非易失性存储介质、内存储器。该非易失性存储介质存储有操作系统和计算机程序。该内存储器为非易失性存储介质中的操作系统和计算机程序的运行提供环境。该计算机设备的通信接口用于与外部的终端进行有线或无线方式的通信,无线方式可通过wifi、运营商网络、nfc(近场通信)或其他技术实现。该计算机程序被处理器执行时以实现一种问卷生成方法和/或一种分类模型训练方法。该计算机设备的显示屏可以是液晶显示屏或者电子墨水显示屏,该计算机设备的输入装置可以是显示屏上覆盖的触摸层,也可以是计算机设备外壳上设置的按键、轨迹球或触控板,还可以是外接的键盘、触控板或鼠标等。
[0169]
本领域技术人员可以理解,图12中示出的结构,仅仅是与本申请方案相关的部分结构的框图,并不构成对本申请方案所应用于其上的计算机设备的限定,具体的计算机设备可以包括比图中所示更多或更少的部件,或者组合某些部件,或者具有不同的部件布置。
[0170]
在一个实施例中,提供了一种计算机设备,包括存储器和处理器,存储器中存储有计算机程序,该处理器执行计算机程序时实现以下步骤:
[0171]
获取临床试验招募数据;
[0172]
将临床试验招募数据输入第一分类模型,根据第一分类模型的分类结果确定临床试验招募数据的适应症类型;
[0173]
将临床试验招募数据输入对应的适应症类型的第二分类模型,得到适应症类型对
应的临床试验招募数据中入排标准对应的结构化字段和问题关键词;根据结构化字段和问题关键词,在题目数据库中抽取问卷问题题目,根据每一问题题目对应的题目格式,生成调查问卷。
[0174]
在一个实施例中,处理器执行计算机程序时还实现以下步骤:
[0175]
获取待处理的临床试验招募文本数据;
[0176]
将待处理的临床试验招募文本数据通过训练好的词向量化模型进行向量化处理,得到临床试验招募文本数据的向量化结果,将向量化结果作为临床试验招募数据。
[0177]
在一个实施例中,提供了一种计算机设备,包括存储器和处理器,存储器中存储有计算机程序,该处理器执行计算机程序时实现以下步骤:
[0178]
获取第一临床试验招募训练样本,第一临床试验招募训练样本中包含每一临床试验招募训练数据的整句向量化值;
[0179]
将第一临床试验招募训练样本中的整句向量化值输入至分类模型中,通过分类模型得到初始分类结果;
[0180]
根据第一临床试验招募训练样本携带的适应症类别标签和适应症细分特征标签对应的基准分类结果对初始分类结果进行验证,若初始分类结果与基准分类结果不一致,则对分类模型进行模型参数调整。
[0181]
在一个实施例中,处理器执行计算机程序时还实现以下步骤:
[0182]
获取临床试验招募文本数据;
[0183]
根据词向量化模型以及预设的加权平均算法,得到每一条临床试验招募文本数据的整句向量化值;
[0184]
根据分类基准向量化值,对临床试验招募数据进行分类处理,得到临床试验招募文本数据的整句向量化值的分类结果;
[0185]
针对每一分类结果进行适应症类别和适应症细分特征的标注,得到携带适应症类别标签和适应症细分特征标签的第一临床试验招募训练样本。
[0186]
在一个实施例中,提供了一种计算机设备,包括存储器和处理器,存储器中存储有计算机程序,该处理器执行计算机程序时实现以下步骤:
[0187]
获取第二临床试验招募训练样本;第二临床试验招募训练样本中包含每一临床试验招募训练数据的入排标准向量化值;
[0188]
将第二临床试验招募训练样本输入分类模型中,得到临床试验招募数据的分类结果;
[0189]
根据第二临床试验招募训练样本携带的入排标准结构化字段标签和问题关键词标签对应的基准分类结果对分类模型得到的分类结果进行验证,若分类结果与基准分类结果不一致,则对分类模型进行模型参数调整。
[0190]
在一个实施例中,处理器执行计算机程序时还实现以下步骤:
[0191]
根据适应症类别获取对应的临床试验招募文本数据;
[0192]
对每一适应症类别的临床试验招募文本数据进行向量化处理,得到临床试验招募文本数据对应的向量化结果;
[0193]
根据基准向量化结果,对临床试验招募文本数据中的向量化结果进行分类处理,得到对应的分类结果;
[0194]
针对每一分类结果进行入排标准的结构化字段和对应的问题关键词的标注,得到携带有入排标准结构化字段标签和问题关键词标签的第二临床试验招募数据样本。
[0195]
在一个实施例中,提供了一种计算机可读存储介质,其上存储有计算机程序,计算机程序被处理器执行时实现以下步骤:
[0196]
获取临床试验招募数据;
[0197]
将临床试验招募数据输入第一分类模型,根据第一分类模型的分类结果确定临床试验招募数据的适应症类型;
[0198]
将临床试验招募数据输入对应的适应症类型的第二分类模型,得到适应症类型对应的临床试验招募数据中入排标准对应的结构化字段和问题关键词;
[0199]
根据结构化字段和问题关键词,在题目数据库中抽取问卷问题题目,根据每一问题题目对应的题目格式,生成调查问卷。
[0200]
在一个实施例中,计算机程序被处理器执行时还实现以下步骤:
[0201]
获取待处理的临床试验招募文本数据;
[0202]
将待处理的临床试验招募文本数据通过训练好的词向量化模型进行向量化处理,得到临床试验招募文本数据的向量化结果,将向量化结果作为临床试验招募数据。
[0203]
在一个实施例中,提供了一种计算机可读存储介质,其上存储有计算机程序,计算机程序被处理器执行时实现以下步骤:
[0204]
获取第一临床试验招募训练样本,第一临床试验招募训练样本中包含每一临床试验招募训练数据的整句向量化值;
[0205]
将第一临床试验招募训练样本中的整句向量化值输入至分类模型中,通过分类模型得到初始分类结果;
[0206]
根据第一临床试验招募训练样本携带的适应症类别标签和适应症细分特征标签对应的基准分类结果对初始分类结果进行验证,若初始分类结果与基准分类结果不一致,则对分类模型进行模型参数调整。
[0207]
在一个实施例中,计算机程序被处理器执行时还实现以下步骤:
[0208]
获取临床试验招募文本数据;
[0209]
根据词向量化模型以及预设的加权平均算法,得到每一条临床试验招募文本数据的整句向量化值;
[0210]
根据分类基准向量化值,对临床试验招募数据进行分类处理,得到临床试验招募文本数据的整句向量化值的分类结果;
[0211]
针对每一分类结果进行适应症类别和适应症细分特征的标注,得到携带适应症类别标签和适应症细分特征标签的第一临床试验招募训练样本。
[0212]
在一个实施例中,提供了一种计算机可读存储介质,其上存储有计算机程序,计算机程序被处理器执行时实现以下步骤:
[0213]
获取第二临床试验招募训练样本;第二临床试验招募训练样本中包含每一临床试验招募训练数据的入排标准向量化值;
[0214]
将第二临床试验招募训练样本输入分类模型中,得到临床试验招募数据的分类结果;
[0215]
根据第二临床试验招募训练样本携带的入排标准结构化字段标签和问题关键词
标签对应的基准分类结果对分类模型得到的分类结果进行验证,若分类结果与基准分类结果不一致,则对分类模型进行模型参数调整。
[0216]
在一个实施例中,计算机程序被处理器执行时还实现以下步骤:
[0217]
根据适应症类别获取对应的临床试验招募文本数据;
[0218]
对每一适应症类别的临床试验招募文本数据进行向量化处理,得到临床试验招募文本数据对应的向量化结果;
[0219]
根据基准向量化结果,对临床试验招募文本数据中的向量化结果进行分类处理,得到对应的分类结果;
[0220]
针对每一分类结果进行入排标准的结构化字段和对应的问题关键词的标注,得到携带有入排标准结构化字段标签和问题关键词标签的第二临床试验招募数据样本。
[0221]
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,所述的计算机程序可存储于一非易失性计算机可读取存储介质中,该计算机程序在执行时,可包括如上述各方法的实施例的流程。其中,本申请所提供的各实施例中所使用的对存储器、存储、数据库或其它介质的任何引用,均可包括非易失性和易失性存储器中的至少一种。非易失性存储器可包括只读存储器(read
‑
only memory,rom)、磁带、软盘、闪存或光存储器等。易失性存储器可包括随机存取存储器(random access memory,ram)或外部高速缓冲存储器。作为说明而非局限,ram可以是多种形式,比如静态随机存取存储器(static random access memory,sram)或动态随机存取存储器(dynamic random access memory,dram)等。
[0222]
以上实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
[0223]
以上所述实施例仅表达了本申请的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本申请构思的前提下,还可以做出若干变形和改进,这些都属于本申请的保护范围。因此,本申请专利的保护范围应以所附权利要求为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1