基于异构并行存算一体架构的高速分子动力学计算方法
1.本发明属于分子动力学计算领域,特别是一种应用存算分离与存算一体芯片进行异构并行高效加速分子动力学计算的方法。
背景技术:
2.分子动力学(molecular dynamics,md)是使用仿真计算领域中针对原子尺度的体系,进行微观层面的仿真技术,在物理、化学、材料、生物、制药等领域中有不可代替的地位。然而,随着仿真体系以及时间尺度的增大,计算资源的消耗非常大。目前用来增加算力的方式仅仅是计算机器的叠加。传统的分子动力学方法,使用存算分离架构的机器进行计算,绝大部分时间和功耗消耗在了搬运数据的过程中,造成了计算效率大幅度降低,算力的严重浪费,使得分子动力学的高速计算需要花费高昂的计算费用,在实际研究以及生产过程中难以应用。在小型计算机上,需要花费的计算时间十分漫长,拖慢了研究和生产的效率,而使用超算集群等大型工作站,需要消耗的成本过于昂贵,难以在巨大的用户群体中普及。分子动力学计算过程中最耗时的步骤就是计算原子间的相互作用力。因此,亟需研究一种能够高速进行分子动力学的计算架构,以提高分子动力学计算的效率。
技术实现要素:
3.本发明的目的是使用基于异构并行存算一体架构的高速分子动力学计算方法,从而获得分子动力学计算的大幅加速。
4.实现本发明目的的技术解决方案为:
5.基于异构并行存算一体架构的高速分子动力学计算方法,步骤如下:
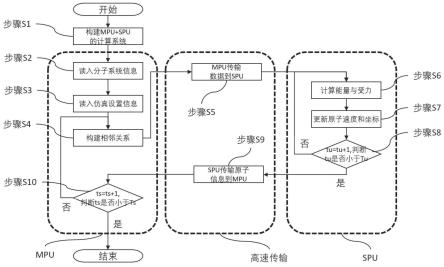
6.步骤s1,构建包含存算一体构架与流水线的计算机系统;
7.如图2所示,计算机系统主要由主处理器(master processing unit,mpu)和从处理器(slave processing unit,spu)以及两者之间的高速传输接口(high-speed transmission interface,hti)构成,mpu和spu之间使用hti进行通信。mpu具有存算分离的特点,具体地,包括但不限于中央处理器(central processing unit,cpu),图像处理器(graphics processing unit,gpu)等处理器。spu具有存算一体和流水线工作的特点,具体地,包括但不限于现场可编程逻辑门阵列(field programmable gate array,fpga),专用集成电路(application specific integrated circuit,asic)等处理器。高速传输接口具有数据传输高效迅速的特点,具体地,包括但不限于pcie(peripheral component interconnect express,pci-express),高清多媒体接口(high definition multimedia interface,hdmi)等高速接口。
8.如图1所示,步骤s2~步骤s10将在此步骤构建的计算机系统中完成,进一步地,步骤s2~步骤s4以及步骤s10单独在mpu中完成,而步骤s6~步骤s8单独在spu中完成,而步骤s5和步骤s9是高速传输的步骤,由mpu和spu一起,通过hti通信完成。优选地,在mpu中进行的步骤使用多核并行加速完成,进一步提高运行速度。
9.步骤s2,mpu从数据文件中读入仿真分子系统的信息;
10.具体地,系统中总共有na个原子,原子编号为i(i=0,1,2,...,na-1)。标记其对应原子种类si,原子质量mi,原子坐标ri,原子速度vi以及原子受力fi。
11.步骤s3,mpu从数据文件中读入仿真设置;
12.仿真设置包括但不限于:仿真的系综,温度,压强,时长,恒温器,恒压器。md的原子设置仿真单位步长为dt(单位fs),设仿真的总时间步数为ts
×
tu,当前步数为step,仿真时间为t(t=step
×
dt);ts为用户设置的构建相邻关系的次数;tu为需要重新构建相邻关系的最大步数,spu每运行tu步md,mpu才更新相邻关系1次。当前构建次数为ts,当前mpu运行步数为tu。可知step=ts
×
tu+tu。初始化ts=0。
13.步骤s4,mpu构建相邻关系;
14.将分子系统,使用截断半径rc划分为均等的盒子单元。每个盒子单元的一阶相邻及其本身共27个盒子单元为相邻盒子单元。以一盒子单元中的任一原子i为中心,筛选相邻盒子单元中的其他原子,与其原子间距小于rc的作为相邻原子,否则不为相邻原子。设定ni,使得相邻原子不超过ni个,构建一个大小为na
×
ni的矩阵v,v(i,k)表示第i个原子的第k(k=0,1,..,ni-1)个相邻原子的编号,相邻原子个数不满ni的行,不满的部分补为-1。若考虑周期性边界条件,构建一个大小为na
×
ni
×
3的矩阵p,p(i,k,d)表示第i个原子的第k个相邻原子的d(d=x,y,z)方向的平移关系,值1表示往d正方向平移,值-1表示往d负方向平移,值0表示不平移。
15.步骤s5,mpu传输原子信息到spu;
16.mpu将必要的计算信息通过hti传送给spu。传送的信息包括但不限于:原子信息(原子序号、原子种类、原子坐标、原子速度)、相邻关系矩阵v、矩阵p以及控温参数。
17.传输的数据需要mpu编码,spu使用相应方式解码。spu获取数据之后,初始化tu=0;
18.步骤s6,spu计算能量及原子受力;
19.spu中的计算流程为,取出原子数据,构建原子结构特征,计算原子能量,能量求导计算原子间相互作用力的分力,但不限于此,还可以计算直接导出,或者变形公式得出的物理量,如维里,压强等。
20.对于求取每个原子的能量,或者是原子总能,可以按照用户设定来实现不同函数形式,包括但不限于经典力场(如:lennard-jones,stillinger-weber等),神经网络势函数(如:deepmd,schnet等),机器学习势函数(如:gaussianapproximation potentials)等。
21.原子间作用力f
ij
定义如下:
[0022][0023]
维里定义如下:
[0024][0025]
步骤s7,spu更新原子的速度以及坐标;
[0026]
积分过程中,将分力f
ij
累加得到原子受力fi,使用恒温器进行控温,使用恒压器控
压,更新的原子速度和坐标重新存回spu的存储单元。
[0027]
仿真系综和积分公式根据用户设定来选择不同功能。系综包括正则系综(nvt),微正则系综(nve),巨正则系综(vtu)等温等压(npt),等压等焓(nph)。结合系综的积分公式包括但不限于如nose-hoover,langevin,andersen,berendsen等积分公式。
[0028]
步骤s8,判断spu传输数据到mpu;
[0029]
tu=tu+1;判定是否tu》=tu。若是进行步骤s9,否则进行步骤s6。
[0030]
步骤s9,将spu中计算更新的原子信息通过hti传输回mpu;
[0031]
spu传输数据给mpu,传输的信息包括但不限于:原子信息(原子序号,原子种类,原子坐标,原子速度),控温参数。传输的数据需要spu编码,mpu使用相应方式解码。然后mpu更新原子信息,并将轨迹记录到数据文件中。
[0032]
步骤s10,判断是否程序结束;
[0033]
ts=ts+1;若ts》=ts,则结束程序,否则进行步骤s4。
[0034]
本发明与现有技术相比,其显著优点在于,该发明中的高速分子动力学计算方法,通过异构并行架构的方法,利用mpu计算频率高,计算核心多,适合复杂逻辑计算的特点,和spu存算一体和流水线带来的高计算效率的特点,使用高速传输接口thi来结合两者优势,能够大大加速进行相同精度下的分子动力学计算过程。在确保高精度的前提下,极大的缩短了计算时间,适合于高速分子动力学计算。
附图说明
[0035]
图1是本发明的操作流程图;
[0036]
图2是本发明的计算机系统结构;
[0037]
图3(a)是将分子系统按截断半径划分成网格;
[0038]
图3(b)展示中心的盒子单元(深色)与其相邻盒子单元;
[0039]
图3(c)展示中心盒子中的原子如何筛选截断半径内的相邻原子;
[0040]
图4(a)展示实例gete的起始分子结构,处于不定性态的gete;
[0041]
图4(b)展示实例gete的末态分子结构,处于晶态的gete;
[0042]
图4(c)展示仿真温度随时间变化的曲线。
具体实施方式
[0043]
以下将结合说明书附图和优选实施例对本发明作进一步详细说明。
[0044]
本发明的目的是使用基于异构并行存算一体架构的高速分子动力学计算方法,从而获得分子动力学计算的大幅加速。需要注意的是,这里的优选实施例是为描述具体实施方式,而非意图限制根据本公开的实施方式。
[0045]
实现本发明目的的技术解决方案为:
[0046]
基于异构并行存算一体架构的高速分子动力学计算方法,步骤如下:
[0047]
步骤s1,构建包含存算一体构架与流水线的计算机系统;
[0048]
如图2所示,计算机系统主要由主处理器(master processing unit,mpu)和从处理器(slave processing unit,spu)以及两者之间的高速传输接口(high-speed transmission interface,hti)构成,mpu和spu之间使用hti进行通信。mpu具有存算分离的
特点,具体地,包括但不限于中央处理器(central processing unit,cpu),图像处理器(graphics processing unit,gpu)等处理器。spu具有存算一体和流水线工作的特点,具体地,包括但不限于现场可编程逻辑门阵列(field programmable gate array,fpga),专用集成电路(application specific integrated circuit,asic)等处理器。高速传输接口具有数据传输高效迅速的特点,具体地,包括但不限于pcie(peripheral component interconnect express,pci-express),高清多媒体接口(high definition multimedia interface,hdmi)等高速接口。
[0049]
如图1所示,步骤s2~步骤s10将在此步骤构建的计算机系统中完成,具体地,步骤s2~步骤s4以及步骤s10单独在mpu中完成,而步骤s6~步骤s8单独在spu中完成,而步骤s5和步骤s9是高速传输的步骤,由mpu和spu一起,通过hti通信完成。优选地,在mpu中进行的步骤使用多核并行加速完成,进一步提高运行速度。
[0050]
优选地,设置mpu为cpu,spu为fpga,hti为pcie 3.0
×
16。
[0051]
步骤s2,mpu从数据文件中读入仿真分子系统的信息;
[0052]
具体地,系统中总共有na个原子,原子编号为i(i=0,1,2,...,na-1)。标记其对应原子种类si,原子质量mi,原子坐标ri,原子速度vi以及原子受力fi。
[0053]
优选地,具体实施例选择碲化锗(gete)的不定性态系统来进行分子动力学,如图4(a)所示,是原子种类和坐标画出的系统三维图像。展示的实施例中gete不定性态的原子数为1728个,元素种类为ge和te。
[0054]
步骤s3,mpu从数据文件中读入仿真设置;
[0055]
仿真设置包括但不限于:仿真的系综,温度,压强,时长,恒温器,恒压器。md的原子运动的很慢,因此在一定时间步数内,不需更新原子的相邻关系,具体地,设置仿真单位步长为dt(单位fs),设仿真的总时间步数为ts
×
tu,当前步数为step,仿真时间为t(t=step
×
dt);ts为用户设置的构建相邻关系的次数;tu为需要重新构建相邻关系的最大步数,spu每运行tu步md,mpu才更新相邻关系1次。当前构建次数为ts,当前mpu运行步数为tu。可知step=ts
×
tu+tu。初始化ts=0。
[0056]
为了仿真gete的重结晶过程,验证本公开的精度和速度,优选地,设置dt为1fs,tu为50,ts为23200。设置系综为正则系综(nvt),恒温器为berendsen恒温器;仿真温度变化如图4(c)所示,为80ps恒定300k
→
80ps由300k升温到600k
→
1000ps恒定600k。
[0057]
步骤s4,mpu构建相邻关系;
[0058]
在本技术领域构建相邻关系的方法一般为分割网格的方法。传统的遍历所有原子的方法的计算复杂度是o(na2)增长的,而划分网格的方法的计算复杂度可以做到o(na)增长。在此简述此方法,但其他变化形式也同样适用。
[0059]
由于在一定体积内的原子不可能任意多,为此可以设置一个足够大的相邻原子数目,具体地,任一原子i在设定截断半径rc内的相邻原子不超过ni个,构建一个大小为na
×
ni的矩阵v,v(i,k)表示第i个原子的第k(k=0,1,..,ni-1)个相邻原子的编号,相邻原子个数不满ni的行,不满的部分补为-1。构建一个大小为na
×
ni
×
3的矩阵p,p(i,k,d)表示第i个原子的第k个相邻原子的d(d=x,y,z)方向的平移关系,值1表示往d正方向平移,值-1表示往d负方向平移,值0表示不平移。具体步骤如下:
[0060]
步骤s4.1,将v中数值初始化为-1,p中数值初始化为0。
[0061]
步骤s4.2,将盒子大小为lx
×
ly
×
lz的分子系统,按照截断半径rc划分为均等的l
×m×
n等分的盒子单元,标记为c
0,0,0
,c
1,0,0
,
……
,c
l-1,m-1,n-1
。c
l,m,n
表示x方向第l个,y方向上第m个,z方向上第n个盒子单元,这个单元包含的原子编号保存在向量lc
l,m,n
。如图3(a)所示,分子系统被均匀地分割为相同大小形状的盒子单元。
[0062]
如图3(b)所示,中心盒子单元其周围一阶相邻的26个盒子单元及其本身共27个盒子单元构成用于筛选相邻原子的相邻盒子单元,设此集合为nc
l,m,n
。这样就大大减小了筛选的目标相邻原子范围,提高计算效率。
[0063]
进一步地,相邻原子单元集合nc
l,m,n
定义为:
[0064]
nc
l,m,n
={c
l',m',n'
|l'=mod(l,l);m'=mod(m,m);n'=mod(n,n)}
ꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
[0065]
进一步地,函数mod(a,a)定义为:
[0066]
mod(a,a)={(a-1+a)%a,a,(a+1)%a}
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
[0067]
进一步地,相邻盒子单元平移关系p
l’,m’,n’的集合pbc
l,m,n
定义为:
[0068]
pbc
l,m,n
={(pl',pm',pn')|pl'=pbc(l,l);pm'=pbc(m,m);pn'=pbc(n,n)} (3)
[0069]
p
l',m',k'
=(pl',pm',pn')
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)
[0070]
进一步地,函数pbc(a,a)定义为:
[0071]
pbc(a,a)={(a==0)?-1:0,0,(a==a-1)?1:0}
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(5)
[0072]
步骤s4.3,从lc
l,m,n
中取出一个原子编号i,并索引得坐标ri,新建链表vi和pi。
[0073]
步骤s4.4,中心盒子单元中的中心原子i通过划定截断半径为rc的球体区域来从相邻盒子单元中筛选相邻原子。如图3(c)所示,中心盒子单元c
l,m,n
中的原子i,将原子间距在截断半径rc相邻盒子单元c
l+1,m,n
中的原子筛选出来,但图示不失一般性,可以用同样的方法将其他相邻盒子单元中的相邻原子筛选出来。
[0074]
具体地,取出相邻盒子单元c
l’,m’,n’对应的平移关系p
l’,m’,n’;编号向量lnc
l’,m’,n’中取出原子编号j,并索引得坐标rj,计算周期性平移之后的相对原子坐标r
ij
=r
j-ri+(lx,ly,lz)*p
l’,m’,n’。
[0075]
计算原子间距r
ji
=|r
ji
|,r
ji
小于截断半径rc则添加j到原子i对应的相邻关系向量vi中,并添加p
l’,m’,n’到pi。以此类推,逐一筛选整个相邻盒子单元中的原子,得到vi和pi。将vi赋值到v(i),将pi赋值给p(i)。
[0076]
步骤s4.5,以此类推,遍历全部盒子单元的原子重复步骤s4.3到步骤s4.4,得到v和p。
[0077]
优选地,在本实施例中,rc为l=m=n=6,ni为64。优选地,步骤s4使用的多核cpu可以使用mpi进行有效地并行,提高计算效率。
[0078]
步骤s5,mpu传输原子信息到spu;
[0079]
为了利用mpu与spu各自计算优势,mpu将必要的计算信息通过hti传送给spu。传送的信息包括但不限于:原子信息(原子序号、原子种类、原子坐标、原子速度)、相邻关系矩阵、控温参数。具体步骤如下:
[0080]
步骤s5.1,按一定格式编码原子信息,相邻关系矩阵,以及控温参数等数据。并将数据存在存储器内。
[0081]
步骤s5.2,mpu加载hti驱动,配置hti传输参数。
[0082]
步骤s5.3,mpu驱动hti驱动执行传输,将步骤s5.1所述中mpu编码缓存的数据传输
到spu的存储单元内。
[0083]
步骤s5.4,spu接收数据,将数据分发到相应的计算模块内部的存储单元。然后初始化tu=0;
[0084]
优选地,发送下去的原子信息如坐标,速度之类的变量,采用浮点数转定点数的方式。而其他整数或者布尔值,无需转换。这样就充分利用了cpu与fpga的计算优势。而原子信息按原子编号排序即可。
[0085]
步骤s6,spu计算能量及原子受力;
[0086]
spu能够使用存算一体架构和流水线计算模式的优势,对计算原子受力进行大幅加速。spu中的计算流程为,取出原子数据,构建原子结构特征,计算原子能量,能量求导计算原子间相互作用力的分力,但不限于此,还可以计算直接导出,或者变形公式得出的物理量,如维里,压强等。具体步骤如下:
[0087]
步骤s6.1,初始化编号i=0。
[0088]
步骤s6.2,取si,ri,v(i),p(i)。从v(i)中取得编号j=v(i,k)(k=0,1,...,ni-1),去索引相邻原子信息sj,rj,索引为-1的,sj和rj的数值与si,ri一致。
[0089]
步骤s6.3,使用si,ri,sj,rj,按公式计算系统总势能e。将系统总能按求导公式对r
ij
求负梯度,得到原子间作用力f
ij
,定义如下:
[0090][0091]
对于求取每个原子的能量,或者是原子总能,可以按照用户设定来实现不同函数形式,包括但不限于经典力场(如:lennard-jones,stillinger-weber等),神经网络势函数(如:deepmd,schnet等),机器学习势函数(如:gaussianapproximation potentials)等。不失一般性地,下面以deepmd形式的神经网络势函数为例说明,本领域技术人员明白,其他势函数的形式同样适用。
[0092]
deepmd的势函数包括特征网络和拟合网络两个网络。特征网络是1输入多输出的网络。拟合网络是多输入1输出的网络。具体步骤如下:
[0093]
步骤s6.3.1,对原子i,构建其保持平移不变性,旋转不变性以及置换不变性的网络输入特征di。优选地,可以将此过程中的特征网络构建成查找表的形式,节约资源消耗。
[0094]
步骤s6.3.2,将di输入到用户设定大小的拟合网络,预测得到原子能量ei。优选地,可以将此过程中拟合网络的权值进行量化,将乘法变成有限次的移位求和操作,进一步节省资源消耗。
[0095]
步骤s6.3.3,将ei求和得到e。
[0096]
步骤s6.3.4,按e对r
ij
的求导解析式的形式计算原子间作用力f
ij
。
[0097]
步骤s6.4,设置ni+1块存储单元,编号为bf0,bf1,
……
,bf
ni
。每个存储单元都相同大小,能够存储至少na的数据深度,其第j行位置设为bfk(j)。将bfk(j)中的数据取出,并在此数值上累加上求取得到的f
ij
,再存回bfk(j)。将ni个f
ij
累加将数值存到bf
ni
(i)。
[0098]
s6.5可选地,也可以添加计算其他物理量,如维里:
[0099][0100]
步骤s6.6,i=i+1,判断是否i》=na,是则进入步骤s7,否则进入步骤s6.2。
[0101]
步骤s7,spu更新原子的速度以及坐标;
[0102]
积分过程中,使用恒温器进行控温,更新的原子速度和坐标重新存回spu的存储单元。具体步骤如下:
[0103]
步骤s7.1,初始化i=0;
[0104]
步骤s7.2,取出bf0(i),bf1(i),bf2(i),
……
,bf
ni
(i)中的数据,共ni+1个分力计算得原子受力fi;
[0105]
步骤s7.3,取出原子i的原子种类si,原子质量mi,原子坐标ri和原子速度vi。使用这些原子信息,连同fi,带入积分公式来计算算下一仿真时间的ri和vi。仿真系综和积分公式根据用户设定来选择不同功能。系综包括正则系综(nvt),微正则系综(nve),巨正则系综(vtu)等温等压(npt),等压等焓(nph)。结合系综的积分公式包括但不限于如nose-hoover,langevin,andersen,berendsen等积分公式。具体地,以nvt系综下的berendsen为例:
[0106][0107][0108]
这里的α是用户设置的控温系数,t是仿真体系的当前温度,t
t
是仿真体系的目标温度。这里的当前温度可以使用如下公式求取:
[0109][0110][0111]
这里的ek是系统动能,kb是玻尔兹曼常数。
[0112]
步骤s7.4,将si,ri和vi存回存储单元。
[0113]
步骤s7.5,i=i+1。判断是否i》=na,是则进入步骤s8,否则进入步骤s7.2
[0114]
优选地,这里的积分公式选择berendsen公式,α为500fs。
[0115]
步骤s8,判断spu传输数据到mpu;
[0116]
tu=tu+1;判定是否tu》=tu。进行步骤s9,否则进行步骤s6。
[0117]
步骤s9,将spu中计算更新的原子信息通过hti传输回mpu;
[0118]
spu传输数据给mpu,同样需要按一定格式才能传输。mpu接收到数据之后需要解码。然后mpu更新原子信息,并将轨迹记录到数据文件中。具体步骤如下:
[0119]
步骤s9.1,spu将一定格式编码数据,包括但不限于,原子坐标,原子速度,仿真参数。并将数据存在专用于数据传输的存储器内;spu给mpu发送可读取数据的消息;
[0120]
步骤s9.2,mpu读取spu读数据消息,驱动hti驱动执行传输;
[0121]
步骤s9.3,mpu将读取得到的信息进行解码,并将数据存储在存储器中;
[0122]
步骤s10,判断是否程序结束;
[0123]
ts=ts+1;若ts》=ts,则结束程序,否则进行步骤s4。
[0124]
使用本发明的计算方法,与一般小型计算机运行台式计算机比,能够得到数量级上的加速。在本实施例中,使用传统的计算方法,仿真速度在10-5
s/step/atom的量级,而使
用本发明的方法,得到了10-8
s/step/atom的计算速度。
[0125]
本发明与现有技术相比,其显著优点在于,该发明中的高速分子动力学计算方法,通过异构并行架构的方法,利用mpu计算频率高,计算核心多,适合复杂逻辑计算的特点,和spu存算一体和流水线带来的高计算效率的特点,使用高速传输接口thi来结合两者优势,能够大大加速进行相同精度下的分子动力学计算过程。在确保高精度的前提下,极大的缩短了计算时间,适合于高速分子动力学计算。
[0126]
以上所述,仅为本发明优选的实施例,但本发明的保护范围并不局限于此,任何熟悉本领域的技术人员在本发明所公开的范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都属于本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1