基于回归分析的压力性损伤风险预测模型校正方法与流程
1.本发明涉及医疗数据处理技术领域,具体涉及一种基于回归分析的压力性损伤风险预测模型校正方法。
背景技术:
2.压力性损伤(pressure injury,pi)是感觉及活动障碍、慢性病和老年患者的严重并发症之一。具体地,压力性损伤是指由压力或压力联合剪切力导致的皮肤和/或皮下组织的局部损伤,通常位于骨隆突处,但也可能与医疗器械或其他物体有关,多发生于长期卧床的患者。压力性损伤严重影响患者的生活质量,而且延长住院时间、加重病情、增加家庭和社会经济负担,消耗大量医疗资源,甚至导致患者死亡。目前,预防压力性损伤是最经济有效的手段已成为全球共识。
3.风险预测是压力性损伤预防的首要措施,风险预测结果的准确与否将直接影响预防措施的选择和预防效果。
4.例如,公开号为cn112185570a的中国专利文献公开一种压力性损伤动态预警系统,由中央处理器作为数据分析处理核心,由数据采集模块、数据分析模块、预警提示模块和数据库构成。数据采集模块采集患者的实时动态体征信息。数据分析模块对采集的患者动态体征信息数据进行分析。预警提示模块根据分析结果进行对应性的预警操作。数据库储存采集到的患者动态体征信息数据以及作为分析样本经过人工收集、调查、实践所获得的数据。该专利文献提供的压力性损伤动态预警系统以采集的患者动态体征信息作为变量,输入列线图模型中进行分析,采用cox回归模型与logistic回归模型。该专利文献提出通过实时动态变化的体征信息,比如温度、湿度、压力、血压、血氧、心率等,以最大化获得更全面更精确的患者体征信息,从而提高判断时对各种变量的综合判断能力,提升结果的精确性。但是该专利文献没有考虑到,当考虑的风险变量较多时,即温度、湿度、压力、血压、血氧、心率等,各个风险变量之间存在交互作用或者非交互作用。事实上,面对不同情况的患者,风险变量不同,而且大部分患者的情况存在复合的情况,例如,icu科室病人可能同时存在骨折的情况,而对于复合情况,当考虑的风险变量较多时,无法确定哪些风险变量起主要作用,哪些风险变量不起作用。而且,如果两个风险变量彼此互为因果关系的情况下,logistic回归模型由于是非线性回归模型,两个风险变量带来的影响会被重复计算,进而无法正确地评价风险变量对压力性损伤的“贡献程度”。更重要的是,利用cox回归模型与logistic回归模型进行计算时,没有考虑到最大化全面地获取风险变量,必然会包括针对不同类型病人所特定的压力性损伤变量,例如,针对骨折患者和普通非骨折患者,手术时长对于骨折患者是比较重要的风险变量,但对于普通非骨折患者,手术时长可能是无关联的风险变量,即该专利文献提供的压力性损伤风险预测的技术方案无法抵御其他无关风险变量的能力,存在稳定性较差的问题。
5.此外,一方面由于对本领域技术人员的理解存在差异;另一方面由于发明人做出本发明时研究了大量文献和专利,但篇幅所限并未详细罗列所有的细节与内容,然而这绝
非本发明不具备这些现有技术的特征,相反本发明已经具备现有技术的所有特征,而且申请人保留在背景技术中增加相关现有技术之权利。
技术实现要素:
6.针对现有技术之不足,本发明提供一种基于回归分析的压力性损伤风险预测模型校正方法,所述方法包括:
7.对病历数据进行筛选获取至少一个验证集和至少一个训练集;
8.基于验证集内病历数据的显著属性将验证集划分为多个分类验证集;
9.通过分类验证集验证由训练集建立的至少一个压力性损伤风险预测模型的方式获取针对该分类验证集的无关风险变量;
10.基于无关风险变量构建校正表,并将该校正表更新至压力性损伤风险预测模型中。现有技术可以根据预测性能和一致性更新压力性损伤风险预测模型。更新方式是改变训练集重新建立压力性损失风险预测模型。然而,在没有考虑到适用人群的情况下,使用混杂不同特征人群的验证集进行验证,可能使得更新后的压力性损伤风险预测模型偏离实际情况。例如,目标人群不同,对患者压力性损伤风险预测产生作用的风险变量不同,以及风险变量对压力性损伤风险预测产生作用的有效程度也不相同,因此需要压力性损伤风险预测模型能够针对不同的目标人群,抵御其他无关风险变量的能力。本发明通过同一分类验证集的正常压力性损伤风险预测模型与异常压力性损伤风险预测模型进行比较,能够获取压力性损伤风险预测模型中针对不同显著属性或特征的目标人群无关的风险变量,进而可以在利用压力性损伤风险预测模型进行风险预测时,通过校正表识别对应目标人群的无关风险变量,并进行校正或更新,提高压力性风险预测模型的稳定性。
11.根据一种优选实施方式,通过分类验证集获取针对该分类验证集的无关风险变量的步骤包括:
12.基于多个分类验证集验证由至少一个训练集建立的压力性损伤风险预测模型,并获取对应分类验证集的验证结果;
13.获取多个预测性能小于第一阈值或一致性小于第二阈值的异常压力性损伤风险预测模型以及预测性能大于第一阈值且一致性大于第二阈值的正常压力性损伤风险预测模型。优选地,验证结果至少包括预测性能和一致性。
14.根据一种优选实施方式,通过分类验证集获取针对该分类验证集的无关风险变量的步骤还包括:
15.基于同一分类验证集的正常压力性损伤风险预测模型与异常压力性损伤风险预测模型进行比较,获取针对该分类验证集的无关风险变量。
16.根据一种优选实施方式,所述方法还包括:
17.获取调谐风险变量;
18.跟踪调谐风险变量并进行修正,从而获取修正后的调谐回归系数;
19.将修正后的调谐回归系数纳入校正表中。
20.根据一种优选实施方式,获取调谐风险变量的步骤如下:
21.监测不同分类验证集的正常压力性损伤风险预测模型中回归系数波动或变化超过第三阈值的风险变量;
22.或者
23.通过两两比较不同分类验证集对应的正常压力性损伤风险预测模型中风险变量的回归系数曲线的方式筛选回归系数曲线的差异超过第四阈值的风险变量。
24.根据一种优选实施方式,获取修正后的调谐回归系数的步骤包括:
25.跟踪调谐风险变量在不同正常压力性损伤风险预测模型的回归系数以获取对应不同正常压力性损伤风险预测模型的回归系数曲线;
26.将多个回归系数曲线平均化处理得到修正后的调谐回归系数曲线,并将该调谐回归系数曲线对应的回归系数作为该调谐风险变量的回归系数。
27.根据一种优选实施方式,对病历数据进行筛选获取至少一个验证集和至少一个训练集的步骤包括:
28.对病历数据进行筛选获取可分析病历数据;
29.检索病历数据,排除入院时已发生皮肤类损伤的病历数据;
30.排除入院后第一时间阈值内发生压力性损伤的病历数据;
31.将可分析病历数据随机划分为用于建立压力性损伤风险预测模型的至少一个训练集和用于验证压力性损伤风险预测模型的至少一个验证集。
32.根据一种优选实施方式,基于验证集内病历数据的显著属性将验证集划分为多个分类验证集的步骤包括:
33.采用卡方检验对各风险变量进行分析,并找到对压力性损伤有显著影响的风险变量。显著属性指的是对压力性损伤有显著影响的风险变量。
34.本发明还提供一种基于回归分析的压力性损伤风险预测模型校正装置,包括处理单元。优选地,处理单元配置为执行如下步骤:
35.对病历数据进行筛选获取至少一个验证集和至少一个训练集;
36.基于验证集内病历数据的显著属性将验证集划分为多个分类验证集;
37.通过分类验证集验证由训练集建立的至少一个压力性损伤风险预测模型的方式获取针对该分类验证集的无关风险变量;
38.基于无关风险变量构建校正表,并将该校正表更新至压力性损伤风险预测模型中。
39.根据一种优选实施方式,处理单元配置为基于多个分类验证集验证由至少一个训练集建立的压力性损伤风险预测模型,并获取对应分类验证集的验证结果。验证结果至少包括预测性能和一致性。处理单元配置为获取多个预测性能小于第一阈值或一致性小于第二阈值的异常压力性损伤风险预测模型以及预测性能大于第一阈值且一致性大于第二阈值的正常压力性损伤风险预测模型。
附图说明
40.图1是本发明方法的一种优选实施方式的步骤流程示意图;
41.图2是本发明装置的一种优选实施方式的模块示意图。
42.附图标记列表
43.100:处理单元
ꢀꢀꢀꢀꢀꢀꢀꢀ
200:存储单元
ꢀꢀꢀꢀꢀꢀꢀꢀꢀ
300:通信单元
具体实施方式
44.下面结合附图进行详细说明。
45.优选地,风险预测模型是以多病因为基础,经过多因素分析,预测个体某种疾病发生或将要发生的绝对概率的一种工具。压力性损伤风险预测模型旨在准确预测压力性损伤发生的风险,便于医护人员及时采取针对性措施。
46.优选地,下面说明压力性损伤风险预测模型的建立步骤。压力性损伤风险预测模型的建立步骤如下。
47.s100:对病历数据进行筛选获取可分析病历数据。优选地,可以通过网络获取外部机构的病历数据。外部机构可以是医院、疾病中心或者存储病人病历的相关机构。网络可以是局域网、互联网、移动网络等。由于外部机构的数据库病历较多且具体情况不同,而需要对压力性损伤进行回归性分析的前置条件是患者还未发生压力性损伤,或者是患者短时间内未发生压力性损伤。因此有必要对外部接入的病历数据进行处理,筛除无法进行回归性分析的数据。对病历数据进行筛选的步骤如下。
48.s101:检索病历数据,排除入院时已发生皮肤类损伤的病历数据。
49.s102:排除入院后第一时间阈值内发生压力性损伤的病历数据。
50.优选地,对病历数据中入院时发生压力性损伤的病历数据进行排除,能够得到入院时未发生压力性损伤的数据。优选地,皮肤类损伤的病历包括烧伤类病历、银屑病、红斑狼疮等。
51.优选地,第一时间阈值可以根据需要设置,例如24小时、10天、20天等。为了确保用于学习训练的病历数据的有效性,需要考虑时间相关因素。例如,需要排除患者在入院后24小时内发生压力性损伤的病历。因为入院后短时间内产生的压力性损伤很有可能与未入院时的相关因素有关,导致压力性损伤风险预测模型不正确。
52.优选地,将可分析病历数据中的字符数值化。将数值化的可分析病历数据进行量纲归一化处理。优选地,由于病历数据中关于患者信息的表征可能不是数值,因此需要将此类信息转换为模型能够识别的数值。例如,可以采用2进制、8进制或者其他多进制表示。患者信息包括关于压力性损伤的风险变量。比如,进食情况可以采用0表示进食很差,1表示进食正常。失禁情况可以采用1表示完全控制,2表示偶尔失禁,3表示大/小便失禁,4表示大小便失禁。皮肤类型可以采用1表示正常,2表示薄,3表示干燥,4表示水肿,5表示潮湿,6表示颜色差,7表示开裂等。
53.优选地,可以采用国际单位制转换因子进行处理。例如,将肌酐转换为微摩尔每升需要乘以88.4。例如,将葡萄糖转换为毫摩尔每升需要乘以0.0555。优选地,量纲归一化处理包括将所有变量归一化至0~10范围内。归一化处理可以是当前值减去病历数据中变量的最小值然后除以变量最大值与最小值的差,然后将该值等比例放大10倍。通过该设置方式,达到的有益效果是:
54.现有采用随机森林模型、多元逻辑回归模型、支持向量机算法等多元分类算法通常将数据归一化至0~1内,但是这种设置方式,后续计算机计算时会产生较多的小数,进而计算机需要大量的浮点运算,将耗费大量的计算开销。而本发明将数据归一化至0~10范围内,减少产生的小数,进而降低浮点运算的计算量,从而节省计算开销。
55.s200:将可分析病历数据随机划分为用于建立压力性损伤风险预测模型的至少一
个训练集和用于验证压力性损伤风险预测模型的至少一个验证集。至少一个训练集可以是一份训练集、两份训练集、三份训练集或更多个。至少一个验证集可以是一份验证集、两份验证集、三份验证集或更多个。可分析病历数据随机划分的方式可以是随机将可分析病历数据均匀地划分为两个部分。优选地,可分析病历数据随机划分的方式还可以是非均匀地划分,例如将可分析病历数据随机划分为十份,其中九份用于建立压力性损伤风险预测模型,剩余的一份用于分别验证这九份训练集建立的压力性损伤风险预测模型。
56.优选地,基于训练集获取多个风险变量。
57.优选地,风险变量指的是影响压力性损伤发生的相关因素。风险变量至少包括年龄、性别、体重、住院时长、住院科室、手术类型、手术时长、生命体征指标、脉搏、血氧饱和度、血红蛋白、血清蛋白、血气分析相关指标、呼吸类型(是否机械通气)、有无相干合并症(比如糖尿病、感染)、吸烟情况、用药情况、进食情况、排泄情况等。
58.s201:对获取的多个风险变量进行筛选。
59.优选地,可以采用先单后多的方式对多个风险变量进行筛选,即先进行单因素分析,单因素有意义的风险变量再一起纳入多因素分析模型中。但在有些情况下,采用先单后多的风险变量筛选方式存在局限,比如风险变量的数量过多的情况下,又比如风险变量之间存在共线性的情况下,又比如缺失值较多且不舍弃含有缺失值样本的情况下。针对以上不同的情况,可以相应采取的方法进行筛选。例如,针对共线性问题可以采用正则化技术解决。正则化技术包括岭回归方法、lasso回归模型、弹性网络模型等。例如,针对缺失值较多的问题可以采用随机森林模型解决。此外,还可以采用聚类分析方法、主成分分析方法、逐步回归方法、梯度提升方法等进行多个风险变量的筛选。
60.s300:利用回归类算法建立压力性损伤风险预测模型,并将筛选后的风险变量纳入构建的压力性损伤风险预测模型中。
61.优选地,回归类算法模型可以采用参数化模型、半参数化模型或者非参数化模型。优选地,参数化模型可以是一般线性模型或者广义线性模型。一般线性模型可以是线性回归算法模型。广义线性模型可以是逻辑(logistic)回归模型或者泊松回归模型。半参数化模型可以是cox比例风险模型或者竞争风险模型。非参数化模型可以是机器学习类算法,比如knn最近邻算法、svm支持向量机、分类回归树、随机森林、神经网络或者深度学习。
62.优选地,风险变量为压力性损伤风险预测模型的自变量。压力性损伤风险预测模型的因变量为发生压力性损伤。以多元逻辑(logistic)回归模型举例说明。
63.优选地,因变量和自变量之间的关系可以表示为如下公式:
64.y=1/(1+e
‑
z
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
65.z=β0+β1x1+
…
+β
n
x
n
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
66.其中,y表示因变量。y的取值为0或1。o表示未发生压力性损伤,1表示发生压力性损伤。x
n
表示自变量,即风险变量。n表示自变量(风险变量)的数量。β
n
表示回归系数。回归系数表征自变量对因变量的影响程度,即回归系数用于表征相应的风险变量对发生压力性损伤的贡献程度。或者回归系数还可以是表征风险变量引起因变量变化程度的权重。
67.优选地,对公式(1)取对数后可以得到:
68.ln(y/1
‑
y)=β0+β1x1+
…
+β
n
x
n
ꢀꢀꢀꢀ
(3)
69.其中,ln(y/1
‑
y)为逻辑(logistic)变换。在公式(3)中y可以表示y取值为1的概
率。1
‑
y可以表示y取值为o的概率。
70.优选地,y取值为1的概率为p(y=1)=e
z
/(1+e
z
)。
71.优选地,y取值为o的概率为p(y=0)=1/(1+e
z
)。
72.优选地,可以根据最大似然法基于训练集内的病历数据估计回归系数的值。
73.s400:基于验证集验证建立的压力性损伤风险预测模型。优选地,根据预测性能和一致性更新压力性损伤风险预测模型。优选地,现阶段通常采用的更新方式可以是对训练集改变,例如重新划分训练集,并重新建立压力性损伤风险预测模型,进而使得压力性损伤风险预测模型更新。
74.优选地,预测性能和一致性是评价和验证压力性损伤风险预测模型优劣的主要指标。压力性损伤风险预测模型的预测性能可以用灵敏度、特异性、接受者操作特征曲线(roc)下的面积(auc)等指标表征。灵敏度用于表征风险预测模型筛选真正有病患者的能力。特异性表征风险预测模型排除真正没病患者的能力。接受者操作特征曲线(roc)下的面积(auc)一般为0.5~1,是评价风险预测模型区分能力的指标。auc值越大表明真实性越高。
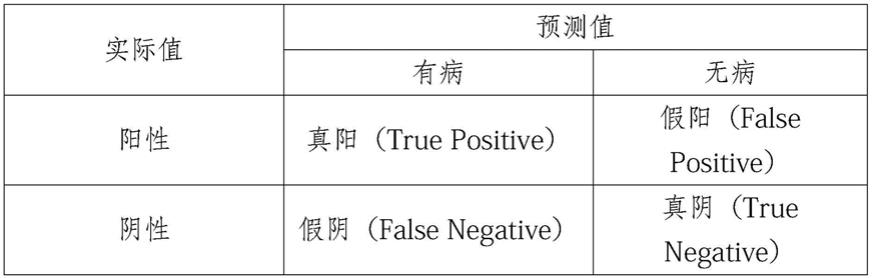
75.优选地,为进一步解释auc,通过混淆矩阵进行说明。混淆矩阵包括阳性(positive)和阴性(negative)。预测正确则为真(true)。预测错误则为假(false)。混淆矩阵包括真阳、假阳、真阴和假阴,如表1所示。
76.表1混淆矩阵
[0077][0078]
真阳可以用tp表示。真阳样本数量表示真正生病的患者被分类为有病的人数,即实际值为1,预测值也为1。
[0079]
假阳可以用fp表示。假阳样本数量表示健康的患者被分类为有病的人数,实际值为0,预测值为1。
[0080]
真阴可以用tn表示。真阴样本数量表示健康的患者被分类为无病的人数,实际值和预测值均为0。
[0081]
假阴可以用fn表示。假阴样本数量表示真正生病的患者被分类为无病的人数,实际值为1,预测值为0。
[0082]
灵敏度可以用真阳概率表示。真阳概率用于表示生病的患者被分类为有病的概率,可以用如下公式表征灵敏度。
[0083][0084]
特异性可以用真阴概率表示。真阴概率用于表示健康的患者被分类为无病的概率,可以用如下公式表征特异性。
[0085][0086]
auc表示接受者操作特征曲线(roc)下的面积。roc曲线的纵轴是灵敏度s
e
。roc曲线的横轴是1
‑
s
p
,即假阳的概率。roc曲线的函数表征为s
e
=f(1
‑
s
p
)。f(
·
)表示函数。auc为曲线s
e
=f(1
‑
s
p
)在由s
e
和1
‑
s
p
围成的矩形框内的面积。auc为1表示为最理想的情况,表示既没有把真正生病的患者错分为无病,也没有把健康的患者错分为有病,即auc可以用于表征压力性损伤风险预测模型的区分能力。
[0087]
优选地,一致性可以用拟合优度(goodness of fit,gof)评价。当风险预测模型的p值大于0.05时,表明风险预测模型已经充分提取数据中的信息,拟合优度较高。p值代表:在假设原假设正确时,出现现状或更差的情况的概率。优选地,风险预测模型的准确度一般为校准曲线。校准曲线是以预测发生概率为横坐标,以实际发生概率为纵坐标的散点图。在散点图进行直线拟合,如果直线为过原点的斜率45
°
直线,则模型准确性较好。如果离过原点的斜率45
°
直线越远,则模型的预测准确率越差。在逻辑(logistic)回归分析中,校准曲线实际上是拟合优度评价结果的可视化。
[0088]
实施例1
[0089]
本发明提供一种基于回归分析的压力性损伤风险预测模型校正方法。
[0090]
优选地,在步骤s201中需要对获取的多个风险变量进行筛选,从而避免变量之间的相互作用对压力性损伤风险预测结果带来的影响。但是,现阶段针对风险变量筛选的方式针对不同的特定情况而采取相应的解决方式,例如,针对风险变量之间的共线性问题,采用正则化技术解决;针对缺失值较多的问题采用随机森林模型解决。然而,实际的临床病历数据可能同时存在以上两种情况,并且正则化技术和随机森林分别单独使用,如果正则化技术和随机森林模型结合可能导致筛选的风险变量不够全面和准确。而且考虑到病历数据库中的病历没有经过分类,包括不同特征的目标人群,而相同的风险变量导致不同的目标人群发生压力性损伤的权重不同,因此利用验证集进行验证时,压力性损伤风险预测模型的预测性能(区分度)和一致性(准确性)差异过大。
[0091]
优选地,在步骤s400中,可以根据预测性能和一致性更新压力性损伤风险预测模型。更新方式是改变训练集重新建立压力性损失风险预测模型。然而,在没有考虑到适用人群的情况下,使用混杂不同特征人群的验证集进行验证,可能使得更新后的压力性损伤风险预测模型偏离实际情况。
[0092]
优选地,本发明针对目标人群不同、病历数据库提供资料不同、筛选的风险变量不同等原因,导致压力性损伤风险预测模型存在局限的问题,提供一种压力性损伤风险预测模型的校正方法,或者是一种压力性损伤风险预测模型的验证方法,或者还可以是一种压力性损伤风险预测模型的更新方法。本发明通过对压力性损伤风险预测模型建立过程中筛选的风险变量进行监测和调整,能够增加压力性损伤风险预测模型适应不同目标人群和病历数据库的能力。具体地,在应用压力性损伤风险预测模型的情况下,纳入全面的风险变量是实现压力性损伤风险准确预测的必要条件,但目标人群不同,对患者压力性损伤风险预测产生作用的风险变量不同,以及风险变量对压力性损伤风险预测产生作用的有效程度也不相同,因此需要压力性损伤风险预测模型能够针对不同的目标人群,抵御其他无关风险变量的能力。另一方面,当相关风险变量对压力性损伤风险预测产生作用的程度发生变化
的情况下,本发明的校正方法还能够减弱相关风险变量产生作用程度发生变化带来的影响。
[0093]
优选地,参见图1,校正压力性损伤风险预测模型的方法包括如下步骤。
[0094]
s10:基于验证集内病历数据的显著属性将验证集划分为多个分类验证集。优选地,病例数据的显著属性可以是根据患者入住医院的所在科室或者根据患者自身的患病类型进行划分。例如,可以将患者分为血管类疾病患者、心血管手术患者、骨科手术患者、icu患者等。优选地,可以采用卡方检验对各风险变量进行分析,并找到对压力性损伤有显著影响的风险变量。优选地,本实施例所涉及的显著属性指的是对压力性损伤有显著影响的风险变量,例如科室、bmi、皮肤类型、失禁、感知受限等。
[0095]
s20:基于多个分类验证集验证由至少一个训练集建立的压力性损伤风险预测模型,并获取对应分类验证集的验证结果。优选地,验证结果至少包括预测性能和一致性。
[0096]
s21:使用分类验证集验证基于训练集训练建立的压力性损伤风险预测模型。优选地,在步骤s200中,可以按照不同的比例随机划分可分析病历数据。例如,可以将可分析病历数据划分为10等份,其中5份数据集可以作为训练集,另外5份数据集作为验证集;还可以将其中9份数据集作为训练集,进而可以得到9个压力性损伤风险预测模型,剩余的1份数据集作为验证集,该1份验证集可以分别验证9个压力性损伤风向预测模型。
[0097]
优选地,根据验证结果调整筛选的风险变量以及回归系数。优选地,在本实施例中更新压力性损伤风险预测模型的方式可以是改变或调整筛选的风险变量,例如增加风险变量、减少风险变量或者替换风险变量。另一方面,更新压力性损伤风险预测模型的方式还可以是改变或调整筛选的风险变量的回归系数,即改变风险变量对应的权重。
[0098]
优选地,本实施例的验证指的是可以利用一个验证集分别验证不同训练集建立的压力性损伤风险预测模型。需要说明的是,一个压力性损伤风险预测模型可以被多次验证。
[0099]
s30:获取多个预测性能小于第一阈值或一致性小于第二阈值的异常压力性损伤风险预测模型以及预测性能大于第一阈值且一致性大于第二阈值的正常压力性损伤风险预测模型。优选地,预测性能可以用auc表征。第一阈值可以是指auc的值为0.75。优选地,一致性可以用拟合优度评价。第二阈值可以是指p值为0.05。
[0100]
s40:基于同一分类验证集的正常压力性损伤风险预测模型与异常压力性损伤风险预测模型进行比较,获取针对该分类验证集的无关风险变量。优选地,无关风险变量是不同目标特定人群所特有的且其主要作用的风险变量,无关风险变量能够对压力性损伤风险预测模型的风险预测结果产生影响。优选地,获取无关风险变量能够在利用压力性损伤风险预测模型进行风险预测时,屏蔽无关风险变量带来的影响。
[0101]
优选地,监测不同分类验证集的正常压力性损伤风险预测模型中回归系数波动或变化超过第三阈值的风险变量。优选地,第三阈值可以为0.1。
[0102]
优选地,或者还可以通过两两比较不同分类验证集对应的正常压力性损伤风险预测模型中风险变量的回归系数曲线的方式筛选回归系数曲线的差异超过第四阈值的风险变量。在本发明中,风险变量与因变量可能呈非线性关系,因此回归系数是关于风险变量的函数,因此回归系数曲线关于风险变量的动态变换的曲线。具体地,回归系数曲线的横坐标可以是风险变量的值,纵坐标为回归系数的值。优选地,回归系数曲线的差异超过第四阈值指的是在相同的风险变量的数值下回归系数之间的差值超过第四阈值。优选地,第四阈值
可以手动设置,在本实施例中第四阈值设置为0.1。
[0103]
优选地,为表述方便和区别于其他的风险变量,将回归系数波动或变化超过第三阈值的风险变量称为调谐风险变量。优选地,调谐风险变量用于表征因训练集大部分的病历数据普遍存在而导致对压力性损伤发生的影响被削弱或放大的风险变量。获取可调谐风险变量后,可以重新进行回归分析进而准确地获取该风险变量对压力性损伤带来的影响。具体地,在步骤s10中关于验证集的划分方式是根据临床经验进行划分而不是基于循证,因此对患者的人群分类刻画不够准确,导致存在偏离真实情况的问题。例如,可以划分为血管类疾病患者、心血管手术患者、骨科手术患者、icu患者等病历数据,以血管类疾病患者为例说明,如果血管类疾病患者的相关病历数据大部分存在体重偏高、肥胖或者高血脂的情况下,通过该验证集验证的压力性损伤风险预测模型可能预测性能和一致性较低,无法准确地验证压力性损伤风险预测模型的性能。另一方面,如果训练集存在前述情况,即训练集内大部分的患者存在体重偏高或者肥胖的情况,可能导致建立的压力性损伤预测风险模型偏离真实情况,进而无法适用体重正常或者偏瘦的人群。具体地,如果训练集内大部分的患者存在体重偏高或者肥胖的情况,体重偏高或者肥胖是该训练集较为常规的风险变量,体重这一风险变量变化引起的压力性损伤风险概率发生的变化较小,即基于该训练集建立的压力性损伤风险预测模型可能会忽视体重造成的影响,无法适用体重正常或者偏瘦的人群。如果假设训练集内的病历数据较为全面,能够全面地覆盖不同类别和特定的人群,那么纳入的风险变量不仅数量较多且较为全面。具体地,以血管类疾病患者和骨科手术患者举例说明,如果这两类患者全部纳入训练集,那么风险变量至少包括血管类疾病患者特有的风险变量和骨科手术患者特有的风险变量,比如血管类疾病患者的治疗血管类药物的摄入,骨科手术患者特有的手术器械造成的压力、手术时长、手术体位等,因此相对于单纯的血管类疾病患者,纳入的手术器械、手术时长、手术体位等风险变量为无关的风险变量,建立的压力性损伤风险预测模型需要能够针对特定的目标人群抵御无关的风险变量。此外,还需要说明的是部分风险变量,比如体重,其与压力性损伤发生之间呈非线性关系。根据现有医疗数据资料,体重的大小与压力性损伤发生的风险大致呈“u”型关系,即体重较大或者较小,发生压力性损伤的可能性较高,而体重正常的患者发生压力性损伤的可能性较低,因此部分风险变量的回归系数或者权重,应该随风险变量数值的变化而呈非线性变化。
[0104]
s50:获取对应分类验证集的无关风险变量后可以构建校正压力性损伤风险预测模型的校正表。优选地,可以基于无关风险变量构建校正表。校正表包括压力性损伤风险预测模型的所纳入的风险变量。每个风险变量至少对应两个值,一个值是该风险变量是否是无关风险变量,另一个值对应的是该风险变量被纳入无关风险变量所对应的显著属性。优选地,可以将校正表更新至压力性损伤风险预测模型中。
[0105]
通过该设置方式,达到的有益效果是:
[0106]
通过同一分类验证集的正常压力性损伤风险预测模型与异常压力性损伤风险预测模型进行比较,能够获取压力性损伤风险预测模型中针对不同显著属性或特征的目标人群无关的风险变量,进而可以在利用压力性损伤风险预测模型进行风险预测时,通过校正表识别对应目标人群的无关风险变量,并进行校正或更新,提高压力性风险预测模型的稳定性。
[0107]
优选地,由于校正表包括风险变量对应的显著属性,因此可以利用校正表和压力
性损伤风险预测模型进行风险预测。具体地,可以根据需要进行风险预测的病历数据进行识别,如果该病历数据包括与显著属性相关的参数,那么可以根据校正表搜索该显著属性对应的无关风险变量,然后将压力性损伤风险预测模型中的对应该无关风险变量的风险变量删除。
[0108]
s60:跟踪调谐风险变量在不同正常压力性损伤风险预测模型的回归系数以获取对应不同正常压力性损伤风险预测模型的回归系数曲线。将多个回归系数曲线平均化处理得到修正后的调谐回归系数曲线,并将该调谐回归系数曲线对应的回归系数作为该调谐风险变量的回归系数。
[0109]
通过该设置方式,达到的有益效果是:
[0110]
针对前述如果训练集内大部分的患者存在体重偏高或者肥胖的情况,体重偏高或者肥胖是该训练集较为常规的风险变量,体重这一风险变量变化引起的压力性损伤风险概率发生的变化较小,即基于该训练集建立的压力性损伤风险预测模型可能会忽视体重造成的影响,无法适用体重正常或者偏瘦的人群的问题,通过监测不同正常压力性损伤风险预测模型中回归系数波动较大或通过比较回归系数曲线发现相同的风险变量在不同的压力性损伤风险预测模型中波动较大的风险变量,识别或发现这种可能被忽视的风险变量,即调谐风险变量。而且,通过均值化的方式平滑处理这种波动,进而减少这种波动或者差异带来的影响,即减弱类似于训练集大量存在体重偏高导致压力性损伤风险预测模型无法适用体重正常或偏瘦人群的影响。
[0111]
s70:将修正后的调谐回归系数曲线对应的调谐回归系数纳入校正表中。例如,在校正表中的风险变量可以被分配第三个值。该第三个值对应的是修正后的调谐回归系数。通过该设置方式,在利用校正表和压力性损伤风险预测模型进行风险预测时,可以检索需要进行风险预测的病理数据是否包含该调谐风险变量,如果包含,则将修正后的回归系数纳入压力性损伤风险预测模型。
[0112]
优选地,参见图2,本实施例还提供一种用于校正压力性损伤风险预测模型的装置。该装置包括处理单元100、存储单元200和通信单元300。优选地,处理单元100可以执行上述步骤s100至s400以及步骤s10至s70。一方面,处理单元100可以配置为执行步骤s100至s400。另一方面,处理单元100可以配置为执行步骤s10至s70。优选地,存储单元200用于存储前述病历数据、可分析病历数据、训练集、验证集、压力性损伤风险预测模型、风险变量、回归系数等数据。优选地,通信单元300用于接入网络和连接设备,从而获取病历数据。例如,通信单元300可以通过有线和/或无线的方式接入互联网、物联网、移动网络、以太网等网络连接病历数据库。优选地,通信单元300还可以是以太网的rj
‑
45接口、细同轴电缆的bnc接口、粗同轴电缆aui接口、fddi接口、atm接口等。通信单元300还可以是wi
‑
fi模块、蓝牙模块、zigbee模块等。优选地,通信单元300还可以是rj
‑
45接口、bnc接口、粗同轴电缆aui接口、fddi接口、atm接口、wi
‑
fi模块、蓝牙模块、zigbee模块中的组合。
[0113]
优选地,处理单元100可以是中央处理器(central processing unit,cpu)、通用处理器、数字信号处理器(digital signal processor,dsp)、专用集成电路(application
‑
specific integrated circuit,asic)、现场可编程门阵列(field programmable gate array,fpga)、图形处理器(graphics processing unit,gpu)或者其他可编程逻辑器件、晶体管逻辑器件、硬件部件或者其任意组合。
[0114]
优选地,存储单元200可以是磁盘、硬盘、光盘、移动硬盘、固态硬盘、闪存等。
[0115]
本发明说明书包含多项发明构思,申请人保留根据每项发明构思提出分案申请的权利。本发明说明书包含多项发明构思,诸如“优选地”、“根据一个优选实施方式”或“可选地”均表示相应段落公开了一个独立的构思,申请人保留根据每项发明构思提出分案申请的权利。
[0116]
需要注意的是,上述具体实施例是示例性的,本领域技术人员可以在本发明公开内容的启发下想出各种解决方案,而这些解决方案也都属于本发明的公开范围并落入本发明的保护范围之内。本领域技术人员应该明白,本发明说明书及其附图均为说明性而并非构成对权利要求的限制。本发明的保护范围由权利要求及其等同物限定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1