使用基因表达和染色质可接近性表征细胞的方法与流程
使用基因表达和染色质可接近性表征细胞的方法
1.相关申请的交叉引用
2.本技术要求2020年2月13日提交的美国临时专利申请第62/976,270号、2020年2月21日提交的美国临时专利申请第62/979,986号、2020年11月16日提交的美国临时专利申请第63/114,378号和2020年12月14日提交的美国临时专利申请第63/125,331号的权益,所述申请各自出于所有目的以引用的方式整体并入本文。
背景技术:
3.虽然用于在单细胞分辨率下测定转录或染色质可接近性(例如,使用atac-seq)的稳健高通量系统现在很普遍,但研究人员和临床医生通常必须拆分细胞样品并单独分析每种模态,并通过计算推断基因表达和染色质可接近性数据之间的关联。
技术实现要素:
4.在一些实施方案中,本文公开了用于表征细胞或细胞核的方法。在一个方面,本公开提供了一种用于表征细胞或细胞核的方法,所述方法包括:提供包含多个细胞或细胞核和多个颗粒的多个分区,其中所述多个分区中的分区包含所述多个细胞或细胞核中的细胞或细胞核和所述多个颗粒中的颗粒,其中(i)所述多个细胞或细胞核包含多个核酸分子,其中所述多个核酸分子包含多个核糖核酸(rna)分子和多个脱氧核糖核酸(dna)分子;并且(ii)所述多个颗粒包含偶联至所述多个颗粒的多个核酸条形码分子,其中所述多个核酸条形码分子中的核酸条形码分子包含多个核酸条形码序列中的核酸条形码序列,并且其中所述颗粒包含所述多个核酸条形码序列中的独特核酸条形码序列;在所述多个分区内,使用所述多个核酸条形码分子中的核酸条形码分子和所述多个核酸分子中的核酸分子产生多个条形码化核酸分子,其中所述多个条形码化核酸分子包含(i)包含对应于所述多个rna分子中的rna分子的序列的第一子集和(ii)包含对应于所述多个dna分子中的dna分子的序列的第二子集,其中所述多个条形码化核酸分子中的条形码化核酸分子包含对应于所述多个核酸条形码序列中的核酸条形码序列的序列;处理所述多个条形码化核酸分子或其衍生物以产生对应于所述rna分子和所述dna分子的序列信息;以及使用所述序列信息来鉴定所述多个细胞或细胞核的特征。在一些实施方案中,所述多个细胞或细胞核包括细胞类型。在一些实施方案中,所述细胞类型选自由单核细胞、自然杀伤细胞、b细胞、t细胞、粒细胞、树突细胞和基质细胞组成的组。在一些实施方案中,所述b细胞选自由复制b细胞、正常b细胞和肿瘤b细胞组成的组。在一些实施方案中,所述b细胞选自由幼稚b细胞、记忆b细胞、浆母细胞b细胞、淋巴浆细胞样细胞、b-1细胞、调节性b细胞和浆b细胞组成的组。在一些实施方案中,所述t细胞选自由复制t细胞和正常t细胞组成的组。在一些实施方案中,所述t细胞选自由辅助t细胞、细胞毒性t细胞、记忆t细胞、调节性t细胞、自然杀伤t细胞、粘膜相关不变型t(mait)细胞、γδt细胞、效应t细胞和幼稚t细胞组成的组。在一些实施方案中,所述单核细胞选自由以cd14细胞表面受体的高水平表达为特征的单核细胞和以cd16细胞表面受体的高水平表达为特征的单核细胞组成的组。在一些实施方案中,所述树突细胞选自由常规树
突细胞和浆细胞样树突细胞组成的组。
5.在一些实施方案中,对应于所述多个dna分子中的所述dna分子的所述序列对应于可接近染色质区域。在一些实施方案中,所述多个rna分子中的所述rna分子包括信使rna(mrna)分子。在一些实施方案中,所述序列信息包含对应于所述dna分子的第一多个测序读段和对应于所述rna分子的第二多个测序读段。在一些实施方案中,所述序列信息包含与所述多个细胞或细胞核中的个别细胞或细胞核相关的多个测序读段。在一些实施方案中,(d)包括使用所述序列信息确定所述多个细胞或细胞核中的所述细胞或细胞核的关联特征,所述细胞或细胞核的所述关联特征将包含对应于所述细胞或细胞核的dna分子的序列信息的第一数据集和包含对应于所述细胞或细胞核的rna分子的序列信息的第二数据集关联起来。在一些实施方案中,(d)包括使用所述序列信息依据基因表达特征和/或依据可接近染色质区域特征对所述多个细胞或细胞核中的细胞或细胞核进行聚类。在一些实施方案中,(d)包括(i)使用所述序列信息依据可接近染色质区域特征对所述多个细胞或细胞核中的细胞或细胞核进行聚类,(ii)使用所述序列信息依据基因表达特征对所述多个细胞或细胞核中的细胞或细胞核进行聚类,以及(iii)使用所述序列信息和依据所述基因表达特征聚类的所述细胞或细胞核进一步表征依据所述可接近染色质区域聚类的所述细胞或细胞核。在一些实施方案中,(d)包括(i)使用所述序列信息依据可接近染色质区域特征对所述多个细胞或细胞核中的细胞或细胞核进行聚类,(ii)使用所述序列信息依据基因表达特征对所述多个细胞或细胞核中的细胞或细胞核进行聚类,以及(iii)使用所述序列信息和依据所述可接近染色质区域特征聚类的所述细胞或细胞核进一步表征依据所述基因表达特征聚类的所述细胞或细胞核。
6.在一些实施方案中,所述多个细胞或细胞核源自包含肿瘤或疑似包含肿瘤的样品。在一些实施方案中,所述方法还包括将对应于所述rna分子和所述dna分子的所述序列信息与从对照样品产生的序列信息进行处理。在一些实施方案中,所述样品源自体液。在一些实施方案中,所述样品源自活检物。在一些实施方案中,所述肿瘤是b细胞淋巴瘤肿瘤。在一些实施方案中,所述方法还包括使用所述序列信息来鉴定所述样品中肿瘤细胞或细胞核的存在。在一些实施方案中,所述方法还包括(e)使用所述序列信息来鉴定所述样品中的细胞类型、细胞状态、肿瘤特异性基因表达模式或肿瘤特异性差异性可接近染色质区域。在一些实施方案中,所述方法还包括至少部分地基于(e)确定用于治疗所述样品所源自的受试者的治疗方案。在一些实施方案中,所述治疗方案包括施用治疗有效量的靶向以所述肿瘤特异性基因表达模式或所述肿瘤特异性差异性可接近染色质区域鉴定的一个或多个靶标的剂。
7.在一些实施方案中,所述多个分区包括多个液滴。在一些实施方案中,所述多个细胞或细胞核包括多个转座核。在一些实施方案中,所述多个颗粒包括多个凝胶珠粒。在一些实施方案中,所述多个核酸条形码分子可释放地偶联至所述多个颗粒。在一些实施方案中,所述多个核酸条形码分子中的核酸条形码分子在施加刺激时能够从所述多个颗粒中的所述颗粒释放。
8.在一些实施方案中,所述刺激是化学刺激。在一些实施方案中,所述刺激包括还原剂。在一些实施方案中,所述多个核酸条形码分子通过多个不稳定部分偶联至所述多个颗粒。在一些实施方案中,所述方法还包括使用微流体装置产生所述多个分区。在一些实施方
案中,所述方法还包括从所述多个分区的所述至少所述子集回收所述多个条形码化核酸分子。在一些实施方案中,所述方法还包括在(b)之前溶解或透化所述多个细胞或细胞核以接近其中的所述多个核酸分子。在一些实施方案中,所述方法还包括在(a)之前用转座酶处理所述多个细胞或细胞核的开放染色质结构以提供所述多个dna分子。在一些实施方案中,在所述多个分区的所述至少所述子集内逆转录所述多个rna分子以提供多个互补dna(cdna)分子。
9.在一些实施方案中,本文公开了用于鉴定遗传特征的方法。在一个方面,本公开提供了一种用于鉴定遗传特征的方法,所述方法包括:
10.一种用于鉴定遗传特征的系统,所述系统包括:(a)提供对应于多个细胞或细胞核的多个脱氧核糖核酸(dna)分子的可接近染色质区域的第一数据集和对应于所述多个细胞或细胞核的多个核糖核酸(rna)分子的第二数据集,其中所述第一数据集包含对应于所述可接近染色质区域的序列和多个核酸条形码序列的第一多个测序读段,并且其中所述第二数据集包含对应于所述多个rna分子的序列和所述多个核酸条形码序列的第二多个测序读段,其中所述多个细胞或细胞核中的细胞或细胞核对应于所述多个核酸条形码序列中的核酸条形码序列;(b)使用所述第一数据集和所述第二数据集的所述多个核酸条形码序列将所述第一多个测序读段中的第一测序读段和所述第二多个测序读段中的第二测序读段鉴定为对应于所述多个细胞或细胞核中的细胞或细胞核,由此产生包含对应于与所述多个细胞或细胞核中的细胞或细胞核相关的可接近染色质区域和rna分子的序列信息的第三数据集;(c)使用所述序列信息来鉴定所述细胞或细胞核的细胞类型;(d)使用对应于所述rna分子的所述序列信息来鉴定所述细胞类型中的细胞类型的表达蛋白;以及(e)使用对应于所述可接近染色质区域的所述序列信息来鉴定对应于所述表达蛋白的遗传特征。
11.在一些实施方案中,所述细胞类型选自由单核细胞、自然杀伤细胞、b细胞、t细胞、粒细胞、树突细胞和基质细胞组成的组。在一些实施方案中,所述b细胞选自由复制b细胞、正常b细胞和肿瘤b细胞组成的组。在一些实施方案中,所述b细胞选自由幼稚b细胞、记忆b细胞、浆母细胞b细胞、淋巴浆细胞样细胞、b-1细胞、调节性b细胞和浆b细胞组成的组。在一些实施方案中,所述t细胞选自由复制t细胞和正常t细胞组成的组。在一些实施方案中,所述t细胞选自由辅助t细胞、细胞毒性t细胞、记忆t细胞、调节性t细胞、自然杀伤t细胞、粘膜相关不变型t(mait)细胞、γδt细胞、效应t细胞和幼稚t细胞组成的组。在一些实施方案中,所述单核细胞选自由以cd14细胞表面受体的高水平表达为特征的单核细胞和以cd16细胞表面受体的高水平表达为特征的单核细胞组成的组。在一些实施方案中,所述树突细胞选自由常规树突细胞和浆细胞样树突细胞组成的组。在一些实施方案中,所述多个细胞或细胞核包含至少500个细胞或细胞核。在一些实施方案中,所述多个细胞或细胞核包含至少1,000个细胞或细胞核。在一些实施方案中,所述多个细胞或细胞核包含至少10,000个细胞或细胞核。
12.在一些实施方案中,所述遗传特征是顺式调控元件。在一些实施方案中,所述顺式调控元件是启动子。在一些实施方案中,所述顺式调控元件是增强子。在一些实施方案中,所述表达蛋白是细胞因子。在一些实施方案中,所述多个rna分子包括多个信使rna(mrna)分子。在一些实施方案中,所述方法还包括使用所述第一数据集和所述第二数据集确定所述多个细胞或细胞核中的所述细胞或细胞核的关联特征,所述细胞或细胞核的所述关联特
征将包含对应于所述细胞或细胞核的dna分子的序列信息的第四数据集和包含对应于所述细胞或细胞核的rna分子的序列信息的第五数据集关联起来。在一些实施方案中,(c)包括使用所述序列信息依据可接近染色质区域特征对所述多个细胞或细胞核中的细胞或细胞核进行聚类。在一些实施方案中,(c)包括使用所述序列信息依据基因表达特征对所述多个细胞或细胞核中的细胞或细胞核进行聚类。在一些实施方案中,(c)包括(i)使用所述序列信息依据可接近染色质区域特征对所述多个细胞或细胞核中的细胞或细胞核进行聚类,(ii)使用所述序列信息依据基因表达特征对所述多个细胞或细胞核中的细胞或细胞核进行聚类,以及(iii)使用所述序列信息和依据所述基因表达特征聚类的所述细胞或细胞核进一步表征依据所述可接近染色质区域聚类的所述细胞或细胞核。在一些实施方案中,(c)包括(i)使用所述序列信息依据可接近染色质区域特征对所述多个细胞或细胞核中的细胞或细胞核进行聚类,(ii)使用所述序列信息依据基因表达特征对所述多个细胞或细胞核中的细胞或细胞核进行聚类,以及(iii)使用所述序列信息和依据所述可接近染色质区域特征聚类的所述细胞或细胞核进一步表征依据所述基因表达特征聚类的所述细胞或细胞核。
13.在一些实施方案中,所述多个细胞或细胞核源自包含肿瘤或疑似包含肿瘤的样品。在一些实施方案中,所述样品源自体液。在一些实施方案中,所述样品源自活检物。在一些实施方案中,所述肿瘤是b细胞淋巴瘤肿瘤。在一些实施方案中,所述方法还包括使用所述序列信息来鉴定所述样品中肿瘤细胞或细胞核的存在。在一些实施方案中,所述方法还包括(f)使用所述序列信息来鉴定所述样品中的细胞类型、细胞状态、肿瘤特异性基因表达模式或肿瘤特异性差异性可接近染色质区域。在一些实施方案中,所述方法还包括至少部分地基于(f)确定用于治疗所述样品所源自的受试者的治疗方案。在一些实施方案中,所述治疗方案包括施用治疗有效量的靶向以所述肿瘤特异性基因表达模式或所述肿瘤特异性差异性可接近染色质区域鉴定的一个或多个靶标的剂。
14.在一些实施方案中,本文公开了用于鉴定遗传特征的系统。在一个方面,本公开提供了一种用于鉴定遗传特征的系统,所述系统包括:一个或多个数据库,所述一个或多个数据库包含对应于多个细胞或细胞核的多个脱氧核糖核酸(dna)分子的可接近染色质区域的第一数据集和对应于所述多个细胞或细胞核的多个核糖核酸(rna)分子的第二数据集,其中所述第一数据集包含对应于所述可接近染色质区域的序列和多个核酸条形码序列的第一多个测序读段,并且其中所述第二数据集包含对应于所述多个rna分子的序列和所述多个核酸条形码序列的第二多个测序读段,其中所述多个细胞或细胞核中的细胞或细胞核对应于所述多个核酸条形码序列中的核酸条形码序列;和一个或多个计算机处理器,所述一个或多个计算机处理器可操作地耦合至所述一个或多个数据库,其中所述一个或多个计算机处理器单独地或共同地被编程为:(i)使用所述第一数据集和所述第二数据集的所述多个核酸条形码序列将所述第一多个测序读段中的第一测序读段和所述第二多个测序读段中的第二测序读段鉴定为对应于所述多个细胞或细胞核中的细胞或细胞核,由此产生包含对应于与所述多个细胞或细胞核中的细胞或细胞核相关的可接近染色质区域和rna分子的序列信息的第三数据集;(ii)使用所述序列信息来鉴定所述细胞或细胞核的细胞类型;(iii)使用对应于所述rna分子的所述序列信息来鉴定所述细胞类型中的细胞类型的表达蛋白;并且(iv)使用对应于所述可接近染色质区域的所述序列信息来鉴定对应于所述表达蛋白的遗传特征。
15.在一些实施方案中,所述细胞类型选自由单核细胞、自然杀伤细胞、b细胞、t细胞、粒细胞、树突细胞和基质细胞组成的组。在一些实施方案中,所述b细胞选自由复制b细胞、正常b细胞和肿瘤b细胞组成的组。在一些实施方案中,所述b细胞选自由幼稚b细胞、记忆b细胞、浆母细胞b细胞、淋巴浆细胞样细胞、b-1细胞、调节性b细胞和浆b细胞组成的组。在一些实施方案中,所述t细胞选自由复制t细胞和正常t细胞组成的组。在一些实施方案中,所述t细胞选自由辅助t细胞、细胞毒性t细胞、记忆t细胞、调节性t细胞、自然杀伤t细胞、粘膜相关不变型t(mait)细胞、γδt细胞、效应t细胞和幼稚t细胞组成的组。在一些实施方案中,所述单核细胞选自由以cd14细胞表面受体的高水平表达为特征的单核细胞和以cd16细胞表面受体的高水平表达为特征的单核细胞组成的组。在一些实施方案中,所述树突细胞选自由常规树突细胞和浆细胞样树突细胞组成的组。在一些实施方案中,所述多个细胞或细胞核包含至少500个细胞或细胞核。在一些实施方案中,所述多个细胞或细胞核包含至少1,000个细胞或细胞核。在一些实施方案中,所述多个细胞或细胞核包含至少10,000个细胞或细胞核。
16.在一些实施方案中,所述遗传特征是顺式调控元件。在一些实施方案中,所述顺式调控元件是启动子。在一些实施方案中,所述顺式调控元件是增强子。在一些实施方案中,所述表达蛋白是细胞因子。在一些实施方案中,所述多个rna分子包括多个信使rna(mrna)分子。在一些实施方案中,所述一个或多个计算机处理器单独地或共同地被编程为使用所述第一数据集和所述第二数据集确定所述多个细胞或细胞核中的所述细胞或细胞核的关联特征,所述细胞或细胞核的所述关联特征将包含对应于所述细胞或细胞核的dna分子的序列信息的第四数据集和包含对应于所述细胞或细胞核的rna分子的序列信息的第五数据集关联起来。
17.在一些实施方案中,所述一个或多个计算机处理器单独地或共同地被编程为在(ii)中使用所述序列信息依据可接近染色质区域特征对所述多个细胞或细胞核中的细胞或细胞核进行聚类。在一些实施方案中,所述一个或多个计算机处理器单独地或共同地被编程为在(ii)中使用所述序列信息依据基因表达特征对所述多个细胞或细胞核中的细胞或细胞核进行聚类。在一些实施方案中,在(ii)中所述一个或多个计算机处理器单独地或共同地被编程为使用所述序列信息(1)依据可接近染色质区域特征对所述多个细胞或细胞核中的细胞或细胞核进行聚类,(2)依据基因表达特征对所述多个细胞或细胞核中的细胞或细胞核进行聚类,并且(3)用依据所述基因表达特征聚类的所述细胞或细胞核进一步表征依据所述可接近染色质区域聚类的所述细胞或细胞核。在一些实施方案中,在(ii)中所述一个或多个计算机处理器单独地或共同地被编程为使用所述序列信息(1)依据可接近染色质区域特征对所述多个细胞或细胞核中的细胞或细胞核进行聚类,(2)依据基因表达特征对所述多个细胞或细胞核中的细胞或细胞核进行聚类,并且(3)用依据所述可接近染色质区域特征聚类的所述细胞或细胞核进一步表征依据所述基因表达特征聚类的所述细胞或细胞核。在一些实施方案中,所述一个或多个计算机处理器单独地或共同地被进一步编程为产生与检测所述样品中的疾病或疾患有关的输出,所述输出包含所述可接近染色质区域特征和基因表达特征,所述疾病或疾患的存在或不存在;或所述疾病或疾患的进展水平。
18.在一些实施方案中,所述多个细胞或细胞核源自包含肿瘤或疑似包含肿瘤的样品。在一些实施方案中,所述样品源自体液。在一些实施方案中,所述样品源自活检物。在一
些实施方案中,所述肿瘤是b细胞淋巴瘤肿瘤。在一些实施方案中,所述一个或多个计算机处理器单独地或共同地被进一步编程为使用所述序列信息来鉴定所述样品中肿瘤细胞或细胞核的存在。在一些实施方案中,所述一个或多个计算机处理器单独地或共同地被进一步编程为将所述序列信息与来自对照样品的序列信息进行比较。
19.在一些实施方案中,所述一个或多个计算机处理器单独地或共同地被进一步编程为使用所述序列信息来鉴定所述样品中的细胞类型、细胞状态、肿瘤特异性基因表达模式或肿瘤特异性差异性可接近染色质区域。在一些实施方案中,所述一个或多个计算机处理器单独地或共同地被进一步编程为至少部分地基于所述使用所述序列信息来鉴定所述样品中的所述细胞类型、所述细胞状态、所述肿瘤特异性基因表达模式或所述肿瘤特异性差异性可接近染色质区域,确定用于治疗所述样品所源自的受试者的治疗方案。在一些实施方案中,所述治疗方案包括施用治疗有效量的靶向以所述肿瘤特异性基因表达模式或所述肿瘤特异性差异性可接近染色质区域鉴定的一个或多个靶标的剂。在一些实施方案中,所述系统用于监测所述治疗方案的治疗功效。
20.在一些实施方案中,本文公开了用于确定样品的疾患的方法。在一个方面,本公开提供了一种用于确定样品的疾患的方法,所述方法包括:产生(i)包含对应于所述样品的细胞或细胞核的多个脱氧核糖核酸(dna)分子的可接近染色质区域的测序信息的第一数据集,(ii)包含对应于所述细胞或细胞核的多个核糖核酸(rna)分子的测序信息的第二数据集,和(iii)使用所述第一数据集和所述第二数据集产生的所述细胞或细胞核的关联特征;使用所述细胞或细胞核的所述关联特征和对照样品的对照细胞或细胞核的对照关联特征来确定指示所述疾患的所述多个dna分子的一个或多个可接近染色质区域或从所述多个rna分子表达的一个或多个基因。
21.在一些实施方案中,所述方法还包括c)确定疑似患有所述疾患的个体的一个或多个样品中的在b)中确定的指示所述疾患的所述一个或多个可接近染色质区域和/或所表达的所述一个或多个基因的水平。在一些实施方案中,所述方法还包括提供对所述疾患的诊断评估、对所述疾患的预后评估、对所述疾患的监测和/或对所述疾患的管理。在一些实施方案中,与在b)中确定的所述一个或多个可接近染色质区域和/或所表达的一个或多个基因相关的基因被鉴定为用于治疗所述疾患的治疗方案的靶标。在一些实施方案中,所述方法还包括将治疗有效量的靶向所述靶标的剂施用于受试者,其中所述样品源自所述受试者。在一些实施方案中,所述方法还包括确定所述剂在所述受试者中的功效。在一些实施方案中,确定所述功效包括检测所述受试者对所述剂的反应的存在或不存在,其中所述反应包括在施用所述剂的第一剂量或后续剂量后反应的数量、程度或范围。在一些实施方案中,所述反应包括在施用所述剂前后之间所述靶标的基因表达和/或染色质可接近性的差异。
22.在一些实施方案中,所述样品来自患有肿瘤或疑似患有肿瘤的受试者。在一些实施方案中,所述疾患是肿瘤、癌症、恶性肿瘤、赘生物或其他增生性疾病或病症。在一些实施方案中,所述疾患是b细胞恶性肿瘤。在一些实施方案中,所述b细胞恶性肿瘤是b细胞淋巴瘤。在一些实施方案中,所述样品源自体液。在一些实施方案中,所述样品源自活检物。在一些实施方案中,在用于确定样品的疾患的方法中,a)包括提供对应于所述多个dna分子和所述多个rna分子的序列的多个测序读段,其中所述测序读段各自通过核酸条形码序列对应于所述细胞或细胞核。在一些实施方案中,所述方法还包括在b)之前依据所述样品的多个
细胞或细胞核的各自的可接近染色质区域特征,依据各自的所表达基因,和/或依据各自的关联特征对所述多个细胞或细胞核进行聚类。
23.在一些实施方案中,依据选自由单核细胞、自然杀伤细胞、b细胞、t细胞、粒细胞、树突细胞和基质细胞组成的组的细胞类型对所述多个细胞或细胞核进行聚类。在一些实施方案中,所述b细胞选自由复制b细胞、正常b细胞和肿瘤b细胞组成的组。在一些实施方案中,所述b细胞选自由幼稚b细胞、记忆b细胞、浆母细胞b细胞、淋巴浆细胞样细胞、b-1细胞、调节性b细胞和浆b细胞组成的组。在一些实施方案中,所述t细胞选自由复制t细胞和正常t细胞组成的组。在一些实施方案中,所述t细胞选自由辅助t细胞、细胞毒性t细胞、记忆t细胞、调节性t细胞、自然杀伤t细胞、粘膜相关不变型t(mait)细胞、γδt细胞、效应t细胞和幼稚t细胞组成的组。
24.在一些实施方案中,所述方法还包括c)监测所述个体中的在b)中确定的指示所述疾患的所述一个或多个可接近染色质区域和/或所表达的所述一个或多个基因的水平。在一些实施方案中,所述方法还包括在步骤a)之前产生多个标签化dna片段。在一些实施方案中,所述方法还包括在a)之前产生多个条形码化核酸分子,其中所述多个条形码化核酸分子包含(i)包含对应于所述样品的所述细胞或细胞核的所述多个脱氧核糖核酸(dna)分子的可接近染色质区域的序列的第一子集和(ii)包含对应于所述细胞或细胞核的所述核糖核酸(rna)分子的序列的第二子集。
25.在一些实施方案中,所述产生是在多个分区内执行的。在一些实施方案中,所述方法还包括对所述多个条形码化核酸分子进行测序。在一些实施方案中,所述第一数据集是通过对包含对应于所述样品的所述细胞或细胞核的所述多个脱氧核糖核酸(dna)分子的可接近染色质区域的序列的第一多个条形码化核酸分子进行测序而产生的;并且所述第二数据集是通过对包含所述细胞或细胞核的所述核糖核酸(rna)分子的序列的第二多个条形码化核酸分子进行测序而产生的。
26.在一些实施方案中,本文公开了制备生物样品的体外方法。在一个方面,本公开提供了一种制备生物样品的体外方法,所述体外方法包括:(a)用转座酶处理来自所述生物样品的t细胞和/或b细胞的开放染色质结构以提供多个dna分子;(b)产生包含在(a)中处理的所述多个dna分子的第一多个条形码化核酸分子;(c)产生包含含有来自所述生物样品的所述t细胞和/或b细胞的mrna序列或其衍生物的多个核酸的第二多个条形码化核酸分子;以及(d)分别从所述第一多个条形码化核酸分子和所述第二多个条形码化核酸分子产生第一测序文库和第二测序文库,以确定所述t细胞和/或b细胞的细胞的关联特征。
27.在一些实施方案中,其中步骤(b)和/或步骤(c)是在多个分区内执行的。在一些实施方案中,所述方法还包括确定在步骤(d)中确定的所述关联特征的显著性水平。在一些实施方案中,其中步骤(c)包括逆转录来自所述生物样品的所述t细胞和/或b细胞的所述多个mrna序列以提供多个互补dna(cdna)分子,并且所述第二多个条形码化核酸分子包含所述cdna分子。在一些实施方案中,其中步骤(c)包括对所述mrna的3’末端进行条形码化。在一些实施方案中,所述方法还包括在步骤(b)之前将所述t细胞和/或b细胞的单个细胞核包封在液滴中。在一些实施方案中,所述方法还包括(e)由所述第一测序文库和所述第二测序文库确定与疾患有关的所述一个或多个关联特征的存在、不存在和/或水平。在一些实施方案中,所述疾患是肿瘤、癌症、恶性肿瘤、赘生物或其他增生性疾病或病症。在一些实施方案
中,所述疾患是b细胞恶性肿瘤。在一些实施方案中,所述b细胞恶性肿瘤是b细胞淋巴瘤。在一些实施方案中,将所述t细胞和/或b细胞的细胞或细胞核的所述关联特征与对照样品的对照细胞或细胞核的对照关联特征进行比较。在一些实施方案中,所述方法包括提供从个体分离和获得的生物样品。在一些方面,所述方法还包括从所述个体获得所述生物样品。在一些方面,所述方法可以但不必须包括从所述个体获得所述生物样品的另外步骤。在一些实施方案中,所述方法是离体执行的。在一些实施方案中,所述方法还包括在步骤(a)之前提供从个体分离和获得的所述生物样品。
28.在一些实施方案中,本文公开了用于表征细胞的系统。在一个方面,本公开提供了一种用于表征细胞的系统,所述系统包括:多个分区,所述多个分区包含多个细胞或细胞核和多个颗粒,其中所述多个分区中的分区包含所述多个细胞或细胞核中的细胞或细胞核和所述多个颗粒中的颗粒,其中(i)所述多个细胞或细胞核包含多个核酸分子,其中所述多个核酸分子包含多个rna分子和多个dna分子;并且(ii)所述多个颗粒包含偶联至所述多个颗粒的多个核酸条形码分子,其中所述多个核酸条形码分子中的核酸条形码分子包含多个核酸条形码序列中的核酸条形码序列,并且其中所述颗粒包含所述多个核酸条形码序列中的独特核酸条形码序列;和一个或多个计算机处理器,所述一个或多个计算机处理器单独地或共同地被编程为:(a)处理使用所述多个核酸条形码分子和所述多个核酸分子或其衍生物在所述多个分区中产生的多个条形码化核酸分子,以产生对应于所述rna分子和所述dna分子的序列信息;并且(b)使用所述序列信息来鉴定所述多个细胞或细胞核的特征。
29.在一些实施方案中,所述多个细胞或细胞核的特征包括细胞类型。在一些实施方案中,所述细胞类型选自由单核细胞、自然杀伤细胞、b细胞、t细胞、粒细胞、树突细胞和基质细胞组成的组。在一些实施方案中,所述b细胞选自由复制b细胞、正常b细胞和肿瘤b细胞组成的组。在一些实施方案中,所述b细胞选自由幼稚b细胞、记忆b细胞、浆母细胞b细胞、淋巴浆细胞样细胞、b-1细胞、调节性b细胞和浆b细胞组成的组。在一些实施方案中,所述t细胞选自由复制t细胞和正常t细胞组成的组。在一些实施方案中,所述t细胞选自由辅助t细胞、细胞毒性t细胞、记忆t细胞、调节性t细胞、自然杀伤t细胞、粘膜相关不变型t(mait)细胞、γδt细胞、效应t细胞和幼稚t细胞组成的组。在一些实施方案中,所述单核细胞选自由以cd14细胞表面受体的高水平表达为特征的单核细胞和以cd16细胞表面受体的高水平表达为特征的单核细胞组成的组。在一些实施方案中,所述树突细胞选自由常规树突细胞和浆细胞样树突细胞组成的组。在一些实施方案中,对应于所述多个dna分子中的所述dna分子的所述序列对应于可接近染色质区域。在一些实施方案中,所述多个rna分子中的所述rna分子包括信使rna(mrna)分子。在一些实施方案中,所述序列信息包含对应于所述dna分子的第一多个测序读段和对应于所述rna分子的第二多个测序读段。在一些实施方案中,所述序列信息包含与所述多个细胞或细胞核中的个别细胞或细胞核相关的多个测序读段。
30.在一些实施方案中,其中在(b)中所述一个或多个计算机处理器单独地或共同地被编程为使用所述序列信息确定所述多个细胞或细胞核中的所述细胞或细胞核的关联特征,所述细胞或细胞核的所述关联特征将包含对应于所述细胞或细胞核的dna分子的序列信息的第一数据集和包含对应于所述细胞或细胞核的rna分子的序列信息的第二数据集关联起来。在一些实施方案中,其中在(b)中所述一个或多个计算机处理器单独地或共同地被编程为使用所述序列信息依据基因表达特征和/或依据可接近染色质区域特征对所述多个
细胞或细胞核中的细胞或细胞核进行聚类。在一些实施方案中,其中在(b)中所述一个或多个计算机处理器单独地或共同地被编程为(i)使用所述序列信息依据可接近染色质区域特征对所述多个细胞或细胞核中的细胞或细胞核进行聚类,(ii)使用所述序列信息依据基因表达特征对所述多个细胞或细胞核中的细胞或细胞核进行聚类,并且(iii)使用所述序列信息和依据所述基因表达特征聚类的所述细胞或细胞核进一步表征依据所述可接近染色质区域聚类的所述细胞或细胞核。在一些实施方案中,其中在(b)中所述一个或多个计算机处理器单独地或共同地被编程为(i)使用所述序列信息依据可接近染色质区域特征对所述多个细胞或细胞核中的细胞或细胞核进行聚类,(ii)使用所述序列信息依据基因表达特征对所述多个细胞或细胞核中的细胞或细胞核进行聚类,并且(iii)使用所述序列信息和依据所述可接近染色质区域特征聚类的所述细胞或细胞核进一步表征依据所述基因表达特征聚类的所述细胞或细胞核。
31.在一些实施方案中,所述多个细胞或细胞核源自包含肿瘤或疑似包含肿瘤的样品。在一些实施方案中,所述一个或多个计算机处理器单独地或共同地被进一步编程为将对应于所述rna分子和所述dna分子的所述序列信息与从对照样品产生的序列信息进行处理。在一些实施方案中,所述样品源自体液。在一些实施方案中,所述样品源自活检物。在一些实施方案中,所述肿瘤是b细胞淋巴瘤肿瘤。在一些实施方案中,所述一个或多个计算机处理器单独地或共同地被进一步编程为使用所述序列信息来鉴定所述样品中肿瘤细胞或细胞核的存在。在一些实施方案中,所述一个或多个计算机处理器单独地或共同地被进一步编程为(c)使用所述序列信息来鉴定所述样品中的细胞类型、细胞状态、肿瘤特异性基因表达模式或肿瘤特异性差异性可接近染色质区域。在一些实施方案中,所述一个或多个计算机处理器单独地或共同地被进一步编程为至少部分地基于(c)确定用于治疗所述样品所源自的受试者的治疗方案。在一些实施方案中,所述治疗方案包括施用治疗有效量的靶向以所述肿瘤特异性基因表达模式或所述肿瘤特异性差异性可接近染色质区域鉴定的一个或多个靶标的剂。
32.在一些实施方案中,所述多个分区包括多个液滴。在一些实施方案中,所述多个细胞或细胞核包括多个转座核。在一些实施方案中,所述多个颗粒包括多个凝胶珠粒。在一些实施方案中,所述多个核酸条形码分子可释放地偶联至所述多个颗粒。在一些实施方案中,所述多个核酸条形码分子中的核酸条形码分子在施加刺激时能够从所述多个颗粒中的所述颗粒释放。在一些实施方案中,所述刺激是化学刺激。在一些实施方案中,所述刺激包括还原剂。在一些实施方案中,所述多个核酸条形码分子通过多个不稳定部分偶联至所述多个颗粒。在一些实施方案中,所述系统还包括产生所述多个分区的微流体装置。
33.在一些实施方案中,本文公开了用于确定样品的疾患的系统。在一个方面,一种用于确定样品的疾患的系统,所述系统包括:一个或多个数据库,所述一个或多个数据库包含(i)包含对应于所述样品的细胞或细胞核的多个脱氧核糖核酸(dna)分子的可接近染色质区域的测序信息的第一数据集,(ii)包含对应于所述细胞或细胞核的多个核糖核酸(rna)分子的测序信息的第二数据集,和(iii)使用所述第一数据集和所述第二数据集产生的所述细胞或细胞核的关联特征;一个或多个计算机处理器,所述一个或多个计算机处理器可操作地耦合至所述一个或多个数据库,其中所述一个或多个计算机处理器单独地或共同地被编程为使用所述细胞或细胞核的所述关联特征和对照样品的对照细胞或细胞核的对照
关联特征来确定指示所述疾患的所述多个dna分子的一个或多个可接近染色质区域或从所述多个rna分子表达的一个或多个基因。
34.在一些实施方案中,所述一个或多个计算机处理器单独地或共同地被编程为确定疑似患有所述疾患的个体的一个或多个样品中的指示所述疾患的所述一个或多个可接近染色质区域和/或所表达的所述一个或多个基因的水平。在一些实施方案中,所述一个或多个计算机处理器单独地或共同地被编程为产生与提供对所述疾患的诊断评估、对所述疾患的预后评估、对所述疾患的监测和/或对所述疾患的管理有关的输出。在一些实施方案中,所述一个或多个计算机处理器单独地或共同地被配置为将与所述一个或多个可接近染色质区域和/或所表达的一个或多个基因相关的基因鉴定为用于治疗所述疾患的治疗方案的靶标。
35.在一些实施方案中,所述一个或多个计算机处理器单独地或共同地被编程为产生与确定将治疗有效量的靶向所述靶标的剂施用于受试者的方案有关的输出,其中所述样品源自所述受试者。在一些实施方案中,所述一个或多个计算机处理器单独地或共同地被编程为产生与确定靶向所述靶标的剂在施用于受试者时的功效有关的输出,其中所述样品源自所述受试者。在一些实施方案中,所述一个或多个计算机处理器单独地或共同地被编程为产生与检测所述受试者对所述剂的反应的存在或不存在有关的输出,其中所述反应包括在施用所述剂的第一剂量或后续剂量后反应的数量、程度或范围。
36.在一些实施方案中,所述反应包括在施用所述剂前后之间所述靶标的基因表达和/或染色质可接近性的差异。在一些实施方案中,所述样品来自患有肿瘤或疑似患有肿瘤的受试者。在一些实施方案中,所述疾患是肿瘤、癌症、恶性肿瘤、赘生物或其他增生性疾病或病症。在一些实施方案中,所述疾患是b细胞恶性肿瘤。在一些实施方案中,所述b细胞恶性肿瘤是b细胞淋巴瘤。在一些实施方案中,所述样品源自体液。在一些实施方案中,所述样品源自活检物。
37.在一些实施方案中,所述第一数据集和所述第二数据集包含对应于所述多个dna分子和所述多个rna分子的序列的多个测序读段,其中所述测序读段各自通过核酸条形码序列对应于所述细胞或细胞核。在一些实施方案中,所述一个或多个计算机处理器单独地或共同地被编程为依据所述样品的多个细胞或细胞核的各自的可接近染色质区域特征,依据各自的所表达基因,和/或依据各自的关联特征对所述多个细胞或细胞核进行聚类。在一些实施方案中,依据选自由单核细胞、自然杀伤细胞、b细胞、t细胞、粒细胞、树突细胞和基质细胞组成的组的细胞类型对所述多个细胞或细胞核进行聚类。在一些实施方案中,所述b细胞选自由复制b细胞、正常b细胞和肿瘤b细胞组成的组。在一些实施方案中,所述b细胞选自由幼稚b细胞、记忆b细胞、浆母细胞b细胞、淋巴浆细胞样细胞、b-1细胞、调节性b细胞和浆b细胞组成的组。在一些实施方案中,所述t细胞选自由复制t细胞和正常t细胞组成的组。在一些实施方案中,所述t细胞选自由辅助t细胞、细胞毒性t细胞、记忆t细胞、调节性t细胞、自然杀伤t细胞、粘膜相关不变型t(mait)细胞、γδt细胞、效应t细胞和幼稚t细胞组成的组。
38.在一些实施方案中,所述一个或多个计算机处理器单独地或共同地被编程为监测所述个体的指示所述疾患的所述一个或多个可接近染色质区域和/或所表达的所述一个或多个基因的水平。
39.在一些实施方案中,所述多个dna片段是标签化的。在一些实施方案中,用条形码化核酸序列对包含对应于所述样品的细胞或细胞核的多个dna分子的可接近染色质区域的测序信息的第一数据集和包含对应于所述细胞或细胞核的多个rna分子的测序信息的第二数据集进行条形码化。在一些实施方案中,在多个分区内用条形码化核酸序列对包含对应于所述样品的细胞或细胞核的多个dna分子的可接近染色质区域的测序信息的第一数据集和包含对应于所述细胞或细胞核的多个rna分子的测序信息的第二数据集进行条形码化。
40.在一些实施方案中,所述系统还包括被配置为对多个条形码化核酸序列进行测序的装置或测序仪。在一些实施方案中,所述第一数据集是通过对包含对应于所述样品的所述细胞或细胞核的所述多个脱氧核糖核酸(dna)分子的可接近染色质区域的序列的第一多个条形码化核酸序列进行测序而产生的;并且所述第二数据集是通过对包含所述细胞或细胞核的所述核糖核酸(rna)分子的序列的第二多个条形码化核酸序列进行测序而产生的。
41.在一些实施方案中,所述一个或多个计算机处理器单独地或共同地被编程为处理所述第一数据集和/或所述第二数据集以产生经过滤的第一数据集和/或经过滤的第二数据集。在一些实施方案中,所述经过滤的第一数据集是使用基序富集过滤的。在一些实施方案中,所述经过滤的第二数据集是使用差异表达分析过滤的。在一些实施方案中,所述一个或多个计算机处理器单独地或共同地被编程为处理所述第一数据集和/或所述第二数据集以产生关联显著性。在一些实施方案中,所述一个或多个计算机处理器单独地或共同地被编程为处理所述经过滤的第一数据集和/或所述经过滤的第二数据集以产生富集评分。在一些实施方案中,所述经过滤的第一数据集和所述经过滤的第二数据集用于产生转录因子-靶基因网络。在一些实施方案中,其中来自所述转录因子-靶基因网络的基因被鉴定为用于治疗所述疾患的治疗方案的靶标。在一些实施方案中,所述靶标是转录因子。
42.本公开的另一方面提供了一种包括机器可执行代码的非暂时性计算机可读介质,所述机器可执行代码在由一个或多个计算机处理器执行时实现上文或本文别处的任何方法。
43.本公开的另一方面提供了一种系统,所述系统包括一个或多个计算机处理器和与其耦合的计算机存储器。所述计算机存储器包括机器可执行代码,所述机器可执行代码在由所述一个或多个计算机处理器执行时实现上文或本文别处的任何方法。
44.本领域的技术人员从以下具体实施方式将显而易见本公开的另外方面和优点,具体实施方式中仅仅展示和描述本公开的例示性实施方案。正如将认识到的那样,本公开能够具有其他不同的实施方案,并且其若干细节能够在各种明显的方面进行修改,都不脱离本公开。因此,附图和描述本质上应视为说明性而非限制性的。
45.可以出于各种目的处理样品,例如以鉴定样品内部分的类型。样品可以是生物样品。可以处理生物样品,例如以检测疾病(例如癌症)或鉴定特定物质。存在各种用于处理样品的方法,例如聚合酶链式反应(pcr)和测序。
46.可以在各种反应环境内,例如分区内,对生物样品进行处理。分区可以是孔或液滴。液滴或孔可用于以使得能够分配生物样品并单独处理的方式来处理生物样品。例如,此类液滴可以与其他液滴流体分离,从而使得能够精确控制液滴中的相应环境。
47.分区中的生物样品可以经受各种过程,例如化学过程或物理过程。分区中的样品可以经受加热或冷却,或化学反应,例如以获得可定性或定量处理的物质。
48.以引用的方式并入
49.本说明书中所提及的所有公布、专利和专利申请都以引用的方式并入本文中,其引用程度如同特别且个别地指示每篇个别公布、专利或专利申请以引用的方式并入一般。在以引用的方式并入的公布和专利或专利申请与本说明书中所含的公开内容矛盾的程度上,本说明书意图取代和/或优先于任何此类矛盾材料。
附图说明
50.本发明的新颖特征在所附权利要求书中详细地阐述。通过参考阐述利用本发明的原理的例示性实施方案的以下详细描述和附图(本文中又称为“图”),将更好地了解本发明的特征和优点,在附图中:
51.图1示出了用于分配单独的分析物载体的微流体通道结构的一个实例。
52.图2示出了用于将珠粒在控制下分配至离散液滴中的微流体通道结构的一个实例。
53.图3说明了携带条形码的珠粒的一个实例。
54.图4说明了携带条形码的珠粒的另一实例。
55.图5示意性地说明了示例性微孔阵列。
56.图6示意性地说明了用于处理核酸分子的示例性工作流程。
57.图7示出了经编程或以其他方式配置为实施本文公开的方法的计算机系统。
58.图8a和图8b示出了根据本公开的方法使用的珠粒。
59.图9说明了转座酶-核酸复合物,其包含转座酶、包含转座子末端序列和第一引物序列的第一双链寡核苷酸,和包含转座子末端序列和第二引物序列的第二双链寡核苷酸。
60.图10说明了转座酶-核酸复合物,其包含转座酶、包含转座子末端序列和第一与第二引物序列的第一双链寡核苷酸,和包含转座子末端序列和第三与第四引物序列的第二双链寡核苷酸。
61.图11说明了包含转座酶、第一发夹分子和第二发夹分子的转座酶-核酸复合物。
62.图12说明了用于串联atac连接和rna模板转换的一个方案。
63.图13说明了用于串联atac连接和rna模板转换的另一方案。
64.图14说明了用于串联atac连接和rna模板转换的示例性方案。
65.图15说明了用于串联atac连接和rna模板转换的另一方案。
66.图16说明了用于串联atac连接和rna模板转换的另一方案。
67.图17说明了用于串联atac连接和rna模板转换的另一方案。
68.图18说明了用于串联atac连接和rna模板转换的另一方案。
69.图19说明了用于串联atac连接和rna模板转换的另一方案。
70.图20说明了t7介导的线性扩增的方案。
71.图21示出了t7介导的线性扩增的修改的工作流程。
72.图22说明了用于串联atac和rna处理的一个方案。
73.图23说明了用于串联atac和rna处理的一个方案。
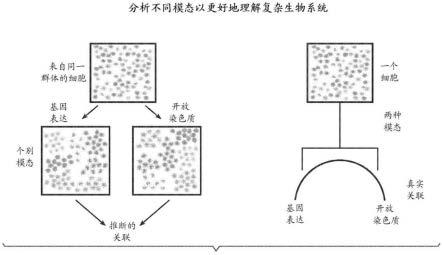
74.图24说明了以计算方式推断的关联与基因表达和开放染色质分析的真实单细胞关联之间的差异。
75.图25说明了产生单细胞可接近染色质(atac)和基因表达文库的方法的一个实例。
76.图26说明了使用表达标志物的细胞聚类和细胞注释。
77.图27说明了使用染色质可接近性(开放染色质)的细胞聚类和细胞注释。
78.图28说明了图26和图27的两个读出之间的一致性。
79.图29a至图29b说明了图26和图27的两个读出之间的另外代表性一致性。
80.图30说明了将基因表达标志物源性注释转移至可接近染色质聚类的群体。仅使用转录因子可接近性(即开放染色质)通过atac数据对细胞进行聚类提供了注释的细胞集群(左图),这些细胞集群可能缺乏区分基因表达标志物聚类可提供的某些细胞类型的特异性。因此,通过使用基因表达标志物来注释开放染色质(atac)集群中的细胞,可以提供关于特定细胞类型的另外背景。
81.图31说明了对新颖细胞群体的鉴定,这些新颖细胞群体在单独分析基因表达或开放染色质区域时将无法鉴定和/或未注释。此处,细胞群体的单独开放染色质分析将显示大细胞集群(例如,b细胞(蓝色),左上图)可以使用基因表达标志物(右上图)进行注释,以进一步层化依据开放染色质聚类的细胞(例如,幼稚/记忆b细胞,底部图)。
82.图32说明了图31中注释细胞中的差异基因表达,以及预期幼稚b细胞与记忆b细胞的鉴定和分化。此处,通过基因表达分析鉴定为单个集群的细胞群体(幼稚/记忆b细胞,右上图)在基因表达注释的开放染色质中被鉴定为两个不同的集群(幼稚/记忆b细胞,左上图)。在基因表达注释的开放染色质中查看差异基因表达,揭示了两个不同的细胞群体(子集群1和子集群2,左下图),当单独观察基因表达(右下图)时,它们被掩盖。对子集群1和子集群2的基因表达分析将子集群1鉴定为预期记忆b细胞(相对较高的ig,相对较低的幼稚b细胞相关转录物),并将子集群2鉴定为预期幼稚b细胞(相对较低的ig,相对较高的幼稚b细胞相关转录物)。
83.图33说明了通过单细胞开放染色质(atac-seq)和基因表达分析所分析的肿瘤样品的病理描述。
84.图34说明了使用基因表达(“gex”,左图)标志物和转录因子(“atac”,右图)可接近性对肿瘤样品的细胞类型注释。
85.图35说明了使用突变负荷(snv)和bank1途径(b细胞超活化的标志物)从正常b细胞中鉴定出肿瘤b细胞。
86.图36说明了对肿瘤细胞的基因表达注释以注释和鉴定开放染色质细胞群体。
87.图37说明了正常b细胞和肿瘤b细胞之间的差异基因表达。fcrl5/fcrl3编码免疫球蛋白受体超家族和fc受体样家族的成员。这些基因与b细胞发育和淋巴瘤发生有关。mir155hg代表一个微小rna宿主基因。从该基因转录的长rna在淋巴瘤中高水平表达,并可能作为一种致癌基因发挥作用。rasgrf1是一种鸟嘌呤核苷酸交换因子(gef),参与map-erk途径。il4r是关键炎症信号传导因子的受体,促生长和促转移。xaf1编码一种与iap(凋亡抑制因子)蛋白家族成员结合并抵消其抑制作用的蛋白质。bank1是b细胞淋巴瘤中的肿瘤阻抑因子。
88.图38a至图38c说明,基于开放染色质和基因表达的协方差,鉴定在肿瘤b细胞中特异性调节il4r表达的候选增强子区域。信号转导和转录活化因子(stat)蛋白是细胞因子信号传导的关键介质。在七种stat蛋白中,stat6被il-4和il-13活化,并在免疫系统中起主要
作用。此处,stat3和stat6的基因表达和可接近染色质表征指示il4r介导的stat6信号传导途径在该肿瘤中被活化。
89.图39示意性地说明了使用本文提供的方法获得的dna测序信息和rna测序信息之间的对应关系。
90.图40说明了用于鉴定与表达蛋白相关的顺式调控元件的示例性工作流程。
91.图41说明了使用正交证据线从正常b细胞中鉴定出肿瘤b细胞。
92.图42说明了应用基因表达和染色质数据来鉴定肿瘤系统中的信号传导途径。
93.图43说明了示出根据各个实施方案的特征关联分析的处理流程的一个示例性流程图。
94.图44说明了示出根据各个实施方案的特征关联分析的处理流程的另一示例性流程图。
95.图45a至图45b说明了对il4r基因的开放染色质和基因表达的分析以及在肿瘤b细胞中观察到的特征关联。
96.图46a说明了在正常b细胞、肿瘤b细胞和循环肿瘤b细胞中选定最高程度差异表达的免疫基因、转录因子和细胞周期基因的基因平均表达。图46b说明了肿瘤b细胞中上调基因的富集功能基因集。
97.图47说明了转录因子-基因网络构建的一个示例性工作流程。
98.图48a说明了肿瘤富集的特征关联的关联显著性分布,由cll注释的超级增强子的重叠分隔开。图48b说明了在pax5基因座处的atac切割位点覆盖和推断的特征关联(左)和pax5的每细胞类型表达和关联峰(右)。
99.图49a说明了基序富集的示例性分析工作流程,而图49b说明了所有基序(左)和最高富集命中(右)的基序富集评分。
100.图50说明了肿瘤b细胞中的转录因子调控网络。
101.图51说明了细胞中对于atac文库中鉴定的峰和基因表达文库中鉴定的转录物水平可以是正或负相关信号的特征关联。
102.本技术可以包含至少一幅彩色附图。在提出请求并支付必要费用后,本事务所将提供具有彩色附图的本专利申请公布的副本。
具体实施方式
103.虽然本文已经展示和描述了本发明的各个实施方案,但是本领域的技术人员显而易见此类实施方案仅仅是为了举例而提供。在不偏离本发明的情况下本领域技术人员现将进行各种改变、变化和取代。应了解,可以采用本文所述的本发明的实施方案的各个替换方案。
104.在值被称作范围的情况下,应了解,此类公开内容包括此类范围内的所有可能的子范围的公开,以及在此类范围内的具体数值,不管是否明确说明具体数值或具体子范围。
105.除非上下文另外明指示,否则如本文所用,术语“一个/种”和“所述”通常指单个和复数个指示物。
106.当术语“至少”、“大于”或“大于或等于”在一系列两个或更多个数值中的第一个数值之前时,术语“至少”、“大于”或“大于或等于”适用于该系列数值中的每个数值。例如,大
于或等于1、2或3等效于大于或等于1、大于或等于2或大于或等于3。
107.当术语“不大于”、“小于”或“小于或等于”在一系列两个或更多个数值中的第一个数值之前时,术语“不大于”、“小于”或“小于或等于”适用于该系列数值中的每个数值。例如,小于或等于3、2或1等效于小于或等于3、小于或等于2或小于或等于1。
108.如本文所用,术语“条形码”通常是指传达或能够传达关于分析物的信息的标记或标识符。条形码可以是分析物的一部分。条形码可以与分析物无关。条形码可以是除分析物的内源特征(例如分析物的尺寸或末端序列)外附接至分析物(例如核酸分子)的标签或标签的组合。条形码可以是独特的。条形码可以具有多种不同的格式。例如,条形码可以包括:多核苷酸条形码;随机的核酸和/或氨基酸序列;和合成的核酸和/或氨基酸序列。条形码可以用可逆的或不可逆的方式附接至分析物。条形码可以例如在样品测序之前、期间和/或之后加入至脱氧核糖核酸(dna)或核糖核酸(rna)样品的片段。条形码可以允许鉴定和/或量化单独测序读段。
109.如本文所用,术语“实时”可以指小于约1秒、十分之一秒、百分之一秒、毫秒或更少的响应时间。响应时间可以大于1秒。在一些情况下,实时可以指同时或基本上同时处理、检测或鉴定。
110.如本文所用,术语“受试者”通常是指动物,例如哺乳动物(例如人)或鸟禽(例如鸟),或其他生物体,例如植物。例如,受试者可以是脊椎动物、哺乳动物、啮齿动物(例如小鼠)、灵长类动物、猿或人。动物可以包括(但不限于)农畜、运动动物和宠物。受试者可以是健康或无症状的个体、患病或疑似患病(例如癌症)或易患病的个体、和/或需要治疗或疑似需要治疗的个体。受试者可以是患者。受试者可以是微生物(microorganism或microbe)(例如细菌、真菌、古菌、病毒)。
111.如本文所用,术语“基因组”通常是指来自受试者的基因组信息,其可以是例如受试者遗传信息的至少一部分或全部。基因组可以呈dna或rna编码。基因组可以包含编码区(例如编码蛋白质的区域)以及非编码区。基基因组可以包括生物体中在一起的所有染色体的序列。例如,人类基因组通常具有总共46条染色体。这些在一起的所有染色体的序列可以组成人类基因组。
112.术语“衔接子(adaptor)”、“衔接子(adapter)”和“标签”可以同义使用。衔接子或标签可通过任何方法偶联至待“标记”的多核苷酸序列,所述方法包括连接、杂交或其他方法。
113.如本文所用,术语“测序”通常是指用于确定一种或多种多核苷酸中的核苷酸碱基的序列的方法和技术。多核苷酸可以是例如核酸分子,例如脱氧核糖核酸(dna)或核糖核酸(rna),包括它们的变体或衍生物(例如单链dna)。测序可以通过现用多种系统进行,例如不限于pacific biosciencesoxford或life technologies(ion)的测序系统。可替代地或此外,可以使用核酸扩增、聚合酶链式反应(pcr)(例如数字pcr、定量pcr或实时pcr)或等温扩增。此类系统可以提供与受试者(例如人类)的遗传信息相对应的多个原始遗传数据,如通过系统从受试者提供的样品产生。在一些实例中,此类系统提供测序读段(本文中也称为“读段”)。读段可以包括与已经进行测序的核酸分子序列相对应的一串核酸碱基。在一些情形下,本文提供的系统和方法可以与蛋白质组学信息一起使用。
114.如本文所用,术语“珠粒”通常是指颗粒。珠粒可以是固体或半固体颗粒。珠粒可以是凝胶珠粒。凝胶珠粒可以包括聚合物基质(例如由聚合或交联形成的基质)。聚合物基质可以包括一种或多种聚合物(例如具有不同官能团或重复单元的聚合物)。聚合物基质中的聚合物可以随机排列,例如在无规共聚物中,和/或具有有序结构,例如在嵌段共聚物中。交联可以经由共价、离子或感应相互作用或物理缠结。珠粒可以是大分子。珠粒可以由结合在一起的核酸分子形成。珠粒可以经由分子(例如大分子)、例如单体或聚合物的共价或非共价装配形成。此类聚合物或单体可以是天然的或合成的。此类聚合物或单体可以是或包括例如核酸分子(例如dna或rna)。珠粒可以由聚合物材料形成。珠粒可以是磁性的或非磁性的。珠粒可以是刚性的。珠粒可以是柔性和/或可压缩的。珠粒可以是可破裂或可溶解的。珠粒可以是用包含一种或多种聚合物的涂层覆盖的固体颗粒(例如基于金属的颗粒,包括但不限于氧化铁、金或银)。此类涂层可以是可破裂或可溶解的。
115.如本文所用,术语“条形码化核酸分子”通常是指由例如处理核酸条形码分子与核酸序列(例如,与核酸条形码分子涵盖的核酸引物序列互补的核酸序列)而产生的核酸分子。核酸序列可以是靶向序列或非靶向序列。例如,在本文所述的方法和系统中,细胞的核酸分子(例如信使rna(mrna)分子)与核酸条形码分子(例如,含有条形码序列和与mrna分子的核酸序列互补的核酸引物序列的条形码核酸分子)的杂交和逆转录产生了具有与mrna的核酸序列和条形码序列(或其反向互补序列)相对应的序列的条形码化核酸分子。条形码化核酸分子可以用作模板,例如模板多核苷酸,其可以被进一步处理(例如扩增)和测序以获得靶核酸序列。例如,在本文所述的方法和系统中,条形码化核酸分子可以被进一步处理(例如扩增)和测序以获得mrna的核酸序列。
116.如本文所用,术语“样品”通常是指受试者的生物样品。生物样品可以包含许多大分子,例如细胞大分子。样品可以是细胞样品。样品可以是细胞系或细胞培养物样品。样品可以包括一种或多种细胞。样品可以包括一种或多种微生物。生物样品可以是核酸样品或蛋白质样品。生物样品也可以是碳水化合物样品或脂质样品。生物样品可以源自另一样品。样品可以是组织样品,例如活检物、芯活检物、针抽吸物或细针抽吸物。样品可以是流体样品,例如血液样品、尿液样品或唾液样品。样品可以是皮肤样品。样品可以是颊拭子。样品可以是血浆或血清样品。样品可以是无细胞的或无细胞样品。无细胞的样品可以包括胞外多核苷酸。胞外多核苷酸可以从可选自由以下组成的组的身体样品分离:血液、血浆、血清、尿液、唾液、黏膜排泄物、痰液、粪便和眼泪。
117.如本文所用,术语“生物颗粒”通常是指源自生物样品的离散生物系统。生物颗粒可以是大分子。生物颗粒可以是小分子。生物颗粒可以是病毒。生物颗粒可以是细胞或细胞的衍生物。生物颗粒可以是细胞器。生物颗粒可以是来自细胞群体的稀少细胞。生物颗粒可以任何类型的细胞,包括不限于原核细胞、真核细胞、细菌、真菌、植物、哺乳动物或其他动物细胞类型、支原体、正常组织细胞、肿瘤细胞或任何其他细胞类型,无论源自单细胞还是多细胞生物体。生物颗粒可以是细胞的成分。生物颗粒可以是或可以包括dna、rna、细胞器、蛋白质或它们的任何组合。生物颗粒可以是或可以包括包含细胞或来自细胞(例如细胞珠粒)的一种或多种成分,例如来自细胞的dna、rna、细胞器、蛋白质或它们的任何组合的基质(例如凝胶或聚合物基质)。生物颗粒可以从受试者的组织获得。生物颗粒可以是硬化细胞。此类硬化细胞可以包括或可以不包括细胞壁或细胞膜。生物颗粒可以包括细胞的一种或多
种成分,但可以不包括细胞的其他成分。此类成分的一个实例是细胞核或细胞器。细胞可以是活细胞。活细胞可能够被培养,例如当装入凝胶或聚合物基质中时培养,或当包含凝胶或聚合物基质时培养。
118.如本文所用,术语“大分子成分”通常是指生物颗粒内所含或来自生物颗粒的大分子。大分子成分可以包含核酸。在一些情况下,生物颗粒可以是大分子。大分子成分可以包含dna。大分子成分可以包含rna。rna可以是编码或非编码的。rna可以是例如信使rna(mrna)、核糖体rna(rrna)或转运rna。rna可以是转录物。rna可以是长度小于200个核酸碱基的小rna,或长度大于200个核酸碱基的大rna。小rna可以包括5.8s核糖体rna(rrna)、5s rrna、转运rna(trna)、微型rna(mirna)、小干扰rna(sirna)、小核仁rna(snorna)、piwi相互作用rna(pirna)、源自trna的小rna(tsrna)和源自小rdna的rna(srrna)。rna可以是双链rna或单链rna。rna可以是环形rna。大分子成分可以包含蛋白质。大分子成分可以包含肽。大分子成分可以包含多肽。
119.如本文所用,术语“分子标签”通常是指能够结合于大分子成分的分子。分子标签可以在高亲和力下结合于大分子成分。分子标签可以在高特异性下结合于大分子成分。分子标签可以包含核苷酸序列。分子标签可以包含核酸序列。核酸序列可以是分子标签的至少一部分或全部。分子标签可以是核酸分子或可以是核酸分子的一部分。分子标签可以是寡核苷酸或多肽。分子标签可以包含dna适体。分子标签可以是或包含引物。分子标签可以是或包含蛋白质。分子标签可以包含多肽。分子标签可以是条形码。
120.如本文所用,术语“分区”通常是指可适于容纳一种或多种物质或进行一种或多种反应的空间或体积。分区可以是物理隔室,例如液滴或孔。分区可将一个空间或体积与另一个空间或体积分隔开。液滴可以是在与第一相不可混合的第二相(例如油)中的第一相(例如水相)。液滴可以是在不与第一相分开的第二相中的第一相,例如在水相中的胶囊或脂质体。分区可以包含一个或多个其他(内部)分区。在一些情况下,分区可以是虚拟隔室,它可以通过标志(例如标志文库)跨越多个和/或偏远的物理隔室界定和鉴定。例如,物理隔室可以包含多个虚拟隔室。
121.本公开提供了用于处理多种类型的核酸分子的方法、系统和试剂盒。本文提供的方法、系统和试剂盒可促进用于对目标细胞、细胞珠粒或细胞核中所含的核酸分子进行测序的样品制备。例如,本公开提供了用于处理细胞、细胞珠粒或细胞核内所含的脱氧核糖核酸(dna)和核糖核酸(rna)分子的方法。所述方法可以包括以串联的高通量测序(atac-seq)和rna测序(rna-seq)测定进行转座酶可接近染色质的测定。分配和条形码化方案可用于促进所得测序读段与它们所源自的细胞、细胞珠粒或细胞核的鉴定。
122.本公开还提供了用于处理包含核酸分子的生物样品的方法、系统和试剂盒。所述方法可以包括从多个分区(例如多个液滴或孔)的一个分区中的核酸样品(例如包含细胞、细胞珠粒或细胞核的样品)提供一种或多种核酸分子(例如脱氧核糖核酸(dna)分子和/或核糖核酸(rna)分子)。所述一种或多种核酸分子可以是一种或多种dna分子。可转录所述一种或多种dna分子以产生一种或多种rna分子,其中可逆转录所述一种或多种rna分子以产生一种或多种互补dna(cdna)分子。然后可从所述多个分区的所述分区中回收所述一种或多种cdna分子或其衍生物(例如,通过汇集所述多个分区的内容物)。所述一种或多种cdna分子或其衍生物可以包含一个或多个核酸条形码序列或其互补序列,其中所述一个或多个
核酸条形码序列或其互补序列可在任何处理步骤期间(例如,在dna分子的转录、rna分子的逆转录期间等)并入核酸分子中。所述一个或多个核酸条形码序列或其互补序列可用于鉴定对应于来自核酸样品的所述一种或多种核酸分子的核酸分子的一种或多种cdna分子的测序读段(例如,使用核酸测序测定获得的测序读段)。
123.串联dna和rna条形码化
124.在一个方面,本公开提供了一种用于处理来自细胞、细胞珠粒或细胞核的核酸分子的方法。所述方法可以包括使细胞、细胞珠粒或细胞核与包含转座酶分子和一种或多种转座子末端寡核苷酸分子的转座酶-核酸复合物接触。细胞、细胞珠粒或细胞核可以与本体溶液中的转座酶-核酸复合物接触,使得细胞、细胞珠粒或细胞核通过标签化反应进行“标签化”。使细胞、细胞珠粒或细胞核与转座酶-核酸复合物接触可产生一个或多个模板核酸片段(例如“标签化片段(tagmented fragments或tagged fragments)”)。所述一个或多个模板核酸片段可对应于细胞、细胞珠粒或细胞核内的一种或多种靶核酸分子(例如脱氧核糖核酸(dna)分子)。并行地,细胞、细胞珠粒或细胞核可以与被配置为与一种或多种另外靶核酸分子(例如核糖核酸(rna)分子,例如信使rna(mrna)分子)相互作用的引物分子(例如,包含多聚t序列的引物分子)接触。细胞、细胞珠粒或细胞核可以与本体溶液中的引物分子接触。可替代地或此外,细胞、细胞珠粒或细胞核可以与分区内的引物分子接触。这些部分之间的相互作用可以产生一个或多个另外模板核酸片段(例如rna片段)。例如,引物分子可以与一种或多种另外靶核酸分子(例如mrna分子)具有至少部分序列互补性。引物分子可以与所述一种或多种另外靶核酸分子的另外靶核酸分子的序列杂交。细胞、细胞珠粒或细胞核可被分配(例如,与一种或多种试剂共同分配)到(例如多个分区的)一个分区中。分区可以是例如液滴或孔。分区可以包含一种或多种试剂,包括例如一种或多种包含一种或多种核酸条形码分子的颗粒(例如珠粒)。细胞、细胞珠粒或细胞核可进行溶解、透化、固定、交联或以其他方式操作以接近其中的一个或多个模板核酸片段和一个或多个另外模板核酸片段。其中的一个或多个模板核酸片段和一个或多个另外模板核酸片段可以在分区内进行一个或多个处理步骤。例如,一个或多个模板核酸片段和/或一个或多个另外模板核酸片段可进行条形码化过程、连接过程、逆转录过程、模板转换过程、线性扩增过程和/或缺口填充过程。所得的一个或多个经处理的模板核酸片段(例如标签化片段)和/或一个或多个经处理的另外模板核酸片段(例如rna片段)可各自包含条形码序列(例如核酸条形码序列,如本文描述)。一个或多个经处理的模板核酸片段和/或一个或多个经处理的另外模板核酸片段可以从分区释放(例如,与多个分区中的其他分区的内容物汇集)并且可进行一个或多个另外批量处理步骤。例如,一个或多个经处理的模板核酸片段和/或一个或多个经处理的另外模板核酸片段可以进行缺口填充过程、da加尾过程、末端转移酶过程、磷酸化过程、连接过程、核酸扩增过程或它们的组合。例如,一个或多个经处理的模板核酸片段和/或一个或多个经处理的另外模板核酸片段可以经受足以进行一种或多种聚合酶链反应(pcr,例如序列独立pcr)的条件以产生对应于所述一个或多个经处理的模板核酸片段(例如标签化片段)和/或所述一个或多个经处理的另外模板核酸片段(例如rna片段)的扩增产物。此类扩增产物的序列可以使用例如核酸测序测定来检测并且用于鉴定它们所源自的细胞、细胞珠粒或细胞核的一种或多种靶核酸分子(例如dna分子)和一种或多种另外靶核酸分子(例如rna分子)的序列。
125.生物样品(例如核酸样品)可以包含一种或多种细胞、细胞珠粒和/或细胞核。生物样品还可以包括组织,所述组织可以包含一种或多种细胞、细胞珠粒和/或细胞核。在一些情况下,生物样品可以包含含有多个细胞核的多个细胞。在一些情况下,生物样品可以包含多个细胞核,所述多个细胞核不包含在细胞内(例如,细胞的其他组分已降解、解离、溶解或以其他方式除去)。生物样品可以包含多个无细胞核酸分子(例如不包含在细胞内的核酸分子)。例如,生物样品可以包含多个无细胞胎儿dna(cffdna)或循环肿瘤dna(ctdna)或其他无细胞核酸分子(例如,源自降解细胞)。可处理这种生物样品以使此类无细胞核酸分子与细胞、细胞珠粒和/或细胞核分离,所述细胞、细胞珠粒和/或细胞核可经受进一步处理(例如,如本文所述)。
126.生物样品内包含的核酸分子可以包括,例如,dna分子和rna分子。例如,生物样品可以包含含有染色质的基因组dna(例如,在细胞、细胞珠粒或细胞核内)。生物样品可以包含多个rna分子,例如多个前体mrna或mrna分子(例如,在细胞、细胞珠粒或细胞核内)。mrna分子和其他rna分子可以包含多聚a序列。细胞或细胞珠粒内包含的多个rna分子的至少一个子集可以存在于细胞核中。
127.核酸分子可以在细胞、细胞珠粒或细胞核内进行一个或多个处理步骤。例如,细胞、细胞珠粒或细胞核内的染色质可以与转座酶接触。转座酶可以包含在转座酶-核酸复合物中,所述转座酶-核酸复合物可以包含转座酶分子和一个或多个转座子末端寡核苷酸分子。转座酶可以是tn转座酶,例如tn3、tn5、tn7、tn10、tn552、tn903转座酶。或者,转座酶可以是mua转座酶、vibhar转座酶(例如,来自哈维氏弧菌(vibrio harveyi))、ac-ds、ascot-1、bs1、cin4、copia、en/spm、f元件、hobo、hsmar1、hsmar2、in(hiv)、is1、is2、is3、is4、is5、is6、is10、is21、is30、is50、is51、is150、is256、is407、is427、is630、is903、is911、is982、is1031、isl2、l1、mariner、p元件、tam3、tc1、tc3、te1、the-1、tn/o、tna、tn3、tn5、tn7、tn10、tn552、tn903、tol1、tol2、tnlo、tyl、任何原核转座酶,或与以上所列的那些相关的和/或源自以上所列的那些的任何转座酶。例如,转座酶可以是tn5转座酶或突变的超活性tn5转座酶。与亲本转座酶相关和/或源自亲本转座酶的转座酶可以包含与亲本转座酶的对应肽片段具有至少约50%、约55%、约60%、约65%、约70%、约75%、约80%、约85%、约90%、约91%、约92%、约93%、约94%、约95%、约96%、约97%、约98%或约99%氨基酸序列同源性的肽片段。肽片段可以为至少约10个、约15个、约20个、约25个、约30个、约35个、约40个、约45个、约50个、约60个、约70个、约80个、约90个、约100个、约150个、约200个、约250个、约300个、约400个或约500个氨基酸长。例如,源自tn5的转座酶可以包含50个氨基酸长和与亲本tn5转座酶中的对应片段约80%同源的肽片段。转座酶的行为(例如插入)可以通过加入一种或多种阳离子,例如一种或多种二价阳离子(例如ca
2+
、mg
2+
或mn
2+
)来促进和/或引发。
128.转座酶-核酸复合物可以包含一个或多个核酸分子。例如,转座酶-核酸复合物可以包含一个或多个转座子末端寡核苷酸分子。转座子末端寡核苷酸分子可以包含一个或多个衔接子序列(例如,包含一个或多个引物序列)和/或一个或多个转座子末端序列。转座子末端序列可以是例如tn5或经修饰的tn5转座子末端序列或mu转座子末端序列。转座子末端序列可以具有例如agatgtgtataagagaca(seq id no:1)的序列。转座子末端寡核苷酸分子的引物序列可以是测序引物,例如r1或r2测序引物,或其一部分。测序引物可以是例如
trueseq或nextera测序引物。r1测序引物区可以具有tctacactctttccctacacgacgctcttccgatct(seq id no:2)的序列,或其一些部分。r1测序引物区可以具有tcgtcggcagcgtcagatgtgtataagagacag(seq id no:3)的序列,或其一些部分。转座子末端寡核苷酸分子可以包含部分r1序列。部分r1序列可以是actacacgacgctcttccgatct(seq id no:4)。转座子末端寡核苷酸分子可以包含r2测序引发区。r2测序引物区可以具有gtgactggagttcagacgtgtgctcttccgatct(seq id no:5)的序列,或其一些部分。r2测序引物区可以具有gtctcgtgggctcggagatgtgtataagagacag(seq id no:6)的序列,或其一些部分。转座子末端寡核苷酸分子可以包含t7启动子序列。t7启动子序列可以是taatacgactcactatag(seq id no:7)。转座子末端寡核苷酸分子可以包含与seq id no:1-7中的任一者至少70%、71%、72%、73%、74%、75%、76%、77%、78%、79%、80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或100%同一的区域。转座子末端寡核苷酸分子可以包含p5序列和/或p7序列。转座子末端寡核苷酸分子可以包含样品标志序列,例如条形码序列或独特分子标识符序列。转座酶-核酸复合物的一个或多个转座子末端寡核苷酸分子可附接至固体支持物(例如固体或半固体颗粒,例如珠粒(例如凝胶珠粒))。转座子末端寡核苷酸分子可以可释放地偶联至固体支持物(例如珠粒)。转座子末端寡核苷酸分子的实例可以在例如pct专利公布第wo2018/218226号、第wo2014/189957号、美国专利公布20180340171和美国专利10,059,989中找到;所述专利各自以引用的方式整体并入本文。
129.图9包括用于本文提供的方法中的转座酶-核酸复合物的一个实例。转座酶-核酸复合物900(例如,包含转座二聚体)包含部分双链寡核苷酸901和部分双链寡核苷酸905。部分双链寡核苷酸901包含转座子末端序列903、第一引物序列902和与转座子末端序列903互补的序列904。部分双链寡核苷酸905包含转座子末端序列906、第一引物序列907和与转座子末端序列906互补的序列908。引物序列902和907可以相同或不同。在一些情况下,引物序列902可以被指定为“r1”,并且引物序列907可以被指定为“r2”。转座子末端序列903和906可以相同或不同。转座子末端序列903和906可以可替代地称为“嵌合末端”或“me”序列,而它们的互补序列904和908可称为“镶嵌末端反向互补序列”或“merc”序列。
130.图10包括用于本文提供的方法中的转座酶-核酸复合物的另一实例。转座酶-核酸复合物1000(例如,包含转座二聚体)包含分叉衔接子1001和1006,所述分叉衔接子是部分双链寡核苷酸。部分双链寡核苷酸1001包含转座子末端序列1003、第一引物序列1002、第二引物序列1005和与转座子末端序列1003互补的序列1004。部分双链寡核苷酸1006包含转座子末端序列1007、第一引物序列1008、第二引物序列1010和与转座子末端序列1007互补的序列1009。引物序列1002、1005、1008和1010可以相同或不同。在一些情况下,引物序列1002和1008可以被指定为“r1”,并且引物序列1005和1010可以被指定为“r2”。或者,引物序列1002和1010可以被指定为“r1”,并且引物序列1005和1008可以被指定为“r2”。或者,引物序列1002和1008可以被指定为“r2”,并且引物序列1005和1010可以被指定为“r1”。或者,引物序列1002和1010可以被指定为“r2”,并且引物序列1005和1008可以被指定为“r1”。转座子末端序列1003和1007可以相同或不同。这些序列可以可替代地称为“嵌合末端”或“me”序列,而它们的互补序列1004和1009可称为“镶嵌末端反向互补序列”或“merc”序列。
131.图11示出了包含发夹分子1101和1106的转座酶-核酸复合物1100(例如,包含转座
二聚体)。发夹分子1101包含转座子末端序列1103、第一发夹序列1102、第二发夹序列1105和与转座子末端序列1103互补的序列1104。发夹分子1106包含转座子末端序列1107、第三发夹序列1108、第四发夹序列1110和与转座子末端序列1107互补的序列1109。发夹序列1102、1105、1108和1110可以相同或不同。例如,发夹序列1105可以与发夹序列1110相同或不同,并且/或者发夹序列1102可以与发夹序列1108相同或不同。发夹序列1102和1108可以是间隔区序列或衔接子序列。发夹序列1105和1110可以是启动子序列,例如t7识别或启动子序列和/或umi序列。转座子末端序列1103和1107可以相同或不同。转座子末端序列1103和1107可以可替代地称为“嵌合末端”或“me”序列,而它们的互补序列1104和1109在一些情况下,序列1104是转座子末端序列,并且1103是与序列1104互补的序列。在一些情况下,序列1109是转座子末端序列,并且1107是与序列1109互补的序列。
132.使包含一种或多种靶核酸分子(例如dna分子)的细胞、细胞珠粒或细胞核与转座酶-核酸复合物接触可以产生一个或多个模板核酸片段(例如“标签化片段”)。所述一个或多个模板核酸片段可以各自包含一种或多种靶核酸分子的序列(例如靶序列)。转座酶-核酸复合物可以被配置为靶向一种或多种靶核酸分子的特定区域以提供一个或多个包含特定靶序列的模板核酸片段。所述一个或多个模板核酸片段可以包含对应于可接近染色质的靶序列。标签化片段的产生可以发生在本体溶液中。在其他情况下,标签化片段的产生可以发生在分区(例如液滴或孔)内。模板核酸片段(例如标签化片段)可以包含一个或多个缺口(例如,在转座子末端序列或其互补序列与双链片段的一条或两条链上的靶序列之间)。可以通过使用例如聚合酶(例如dna聚合酶)、连接酶或逆转录酶的缺口填充过程来填充缺口。在一些情况下,酶混合物可用于修复部分双链核酸分子并填充一个或多个缺口。缺口填充可不包括链置换。可以在分区内部或外部填充缺口。
133.可替代地或此外,可以使一种或多种另外核酸分子与细胞、细胞珠粒或细胞核内的一种或多种捕获核酸分子接触以提供一个或多个另外模板核酸片段。例如,可使rna分子(例如mrna)分子与细胞、细胞珠粒或细胞核内的引物分子接触。引物分子可以包含引物序列,所述引物序列可以是靶向引物序列或非特异性引物序列(例如随机n-聚体)。靶向引物序列可以包含例如多聚t序列,所述多聚t序列可以与rna分子的多聚a序列相互作用。引物核酸分子还可以包含一个或多个另外序列,例如一个或多个样品标志序列、间隔区或接头序列,或一个或多个另外引物序列。另外模板核酸片段(例如rna片段)的产生可以在本体溶液中发生。在其他情况下,另外模板核酸片段的产生可以在分区(例如液滴或孔)内发生。
134.细胞、细胞珠粒或细胞核内核酸分子的处理(例如,使用转座酶-核酸复合物产生模板核酸片段和/或使用捕获核酸分子产生另外模板核酸片段)可以在包含多个细胞、细胞珠粒和/或细胞核的本体溶液中发生。在一些情况下,模板核酸片段(例如标签化片段)可以在本体溶液中产生,并且另外模板核酸片段(例如rna片段)可以在分区中产生。
135.多个细胞、细胞珠粒和/或细胞核(例如,已经进行了处理例如标签化过程的多个细胞、细胞珠粒和/或细胞核)可以被分配在多个分区之间。分区可以是例如液滴或孔。可以根据本文提供的方法来产生液滴(例如水性液滴)。可以根据本文提供的方法进行分配。例如,分配生物颗粒(例如细胞、细胞珠粒或细胞核)和一种或多种试剂可以包括使包含水性流体、生物颗粒和一种或多种试剂的第一相和包含与水性流体不混溶的第二相流向接点。在第一相和第二相相互作用时,可以形成包含生物颗粒和一种或多种试剂的第一相的离散
液滴。多个细胞、细胞珠粒和/或细胞核可以在多个分区之间分配,使得多个分区的至少一个子集可以包含至多一个细胞、细胞珠粒或细胞核。细胞、细胞珠粒和/或细胞核可以与一种或多种试剂共同分配,使得多个分区的至少一个子集的分区包含单个细胞、细胞珠粒或细胞核和一种或多种试剂。所述一种或多种试剂可以包括例如酶(例如聚合酶、逆转录酶、连接酶等)、核酸条形码分子(例如包含一个或多个条形码序列的核酸条形码分子,例如偶联至一个或多个珠粒的核酸条形码分子)、模板转换寡核苷酸、三磷酸脱氧核苷酸、缓冲剂、溶解剂、引物、条形码、洗涤剂、还原剂、螯合剂、氧化剂、纳米颗粒、珠粒、抗体或任何其他有用的试剂。酶可以包括例如温度敏感酶、ph敏感酶、光敏酶、逆转录酶、蛋白酶、连接酶、聚合酶、激酶、限制酶、核酸酶、蛋白酶抑制剂、核酸外切酶和核酸酶抑制剂。
136.一种或多种试剂中的一种试剂可用于溶解或透化细胞、细胞珠粒或细胞核,或以其他方式接近其中的核酸分子和/或模板核酸片段。细胞可以使用溶解剂,例如生物活性剂来溶解。可用于溶解细胞的生物活性剂可以是例如酶(例如,如本文所述)。用于溶解细胞的酶可能能够或可能不能够进行另外行为,例如降解一个或多个rna分子。可替代地,可以使用离子、两性离子或非离子表面活性剂来溶解细胞。表面活性剂的实例包括但不限于tritonx-100、tween 20、肌氨酰或十二烷基硫酸钠。细胞溶解还可以使用细胞破碎方法,例如电穿孔或热、声或机械破碎方法来实现。可替代地,细胞可以透化以接近其中所包括的多个核酸分子。透化可以涉及部分或完全溶解或破碎细胞膜或其一部分。透化可以通过例如使细胞膜与有机溶剂或例如triton x-100或np-40的洗涤剂接触来实现。通过溶解或透化分区(例如液滴)内的细胞、细胞珠粒或细胞核以接近其中的多个核酸分子和/或模板核酸片段,源自于同一细胞、细胞珠粒或细胞核的分子可以在同一分区内分离。
137.多个分区中的分区(例如包含细胞、细胞珠粒和/或细胞核的分区)可以包含一个或多个珠粒(例如凝胶珠粒)。珠粒可以是凝胶珠粒。珠粒可以包含多个核酸条形码分子(例如各自包含一个或多个条形码序列的核酸分子,如本文所述)。珠粒可以包含至少10,000个附接至珠粒的核酸条形码分子。例如,珠粒可以包含至少100,000个、1,000,000个或10,000,000个附接至珠粒的核酸条形码分子。多个核酸条形码分子可以可释放地附接至珠粒。在施加刺激后多个核酸条形码分子可以从珠粒释放。这种刺激可以选自由以下组成的组:热刺激、光刺激和化学刺激。例如,刺激可以是还原剂,例如二硫苏糖醇。刺激的施加可以引起以下中的一者或多者:(i)多个核酸条形码分子中的核酸条形码分子与珠粒之间的连接的裂解,以及(ii)珠粒的降解或溶解,从而从珠粒释放多个核酸条形码分子中的核酸条形码分子。
138.附接(例如,可释放地附接)至珠粒(例如凝胶珠粒)的多个核酸条形码分子可适合对源自多个细胞、细胞珠粒和/或细胞核的dna和/或rna分子的模板核酸片段或另外模板核酸片段进行条形码化。例如,多个核酸条形码分子中的核酸条形码分子可以包含条形码序列、独特分子标识符(umi)序列、引物序列、通用引物序列、测序衔接子或引物、流动池衔接子序列或任何其他有用的功能。在一个实例中,附接至珠粒的多个核酸条形码分子中的核酸条形码分子可以包含流动池衔接子序列(例如p5或p7序列)、条形码序列、捕获序列和测序引物序列或其部分(例如r1或r2序列或其部分),或这些序列中的任一者的互补序列。这些序列可以任何有用的顺序排列并且可以连接或可以包括一个或多个位于它们之间的间隔区序列。例如,流动池衔接子序列(如果存在)可以安置在核酸条形码分子的最接近珠粒
的末端附近(例如接近),而测序引物或其部分可以安置在核酸条形码分子的离珠粒最远(例如远离)的末端(例如,最可用于模板核酸片段进行相互作用)。在另一个实例中,附接至珠粒的多个核酸条形码分子中的核酸条形码分子可以包含流动池衔接子序列(例如p5或p7序列)、条形码序列、测序引物序列或其部分(例如r1或r2序列或其部分)和umi序列,或这些序列中的任一者的互补序列。核酸条形码分子还可以包含捕获序列,所述捕获序列可以是靶向捕获序列或包含模板转换序列(例如,包含多聚c或多聚g序列)。这些序列可以任何有用的顺序排列并且可以连接或可以包括一个或多个位于它们之间的间隔区序列。例如,流动池衔接子序列可以安置在核酸条形码分子的最接近珠粒的末端附近(例如接近),而捕获序列或模板转换序列可以安置在核酸条形码分子的离珠粒最远的末端(例如,最可用于模板核酸片段进行相互作用)。
139.附接(例如,可释放地附接)至多个珠粒中的一个珠粒(例如凝胶珠粒)的所有核酸条形码分子可以是相同的。例如,附接至珠粒的所有核酸条形码分子可以具有相同的核酸序列。在这种情况下,附接至珠粒的所有核酸条形码分子可以包含相同的流动池衔接子序列、测序引物或其部分,以及条形码序列。附接至多个珠粒中的一个珠粒的多个核酸条形码分子的条形码序列可以不同于附接至多个珠粒中的其他珠粒的其他核酸条形码分子的其他条形码序列。例如,多个珠粒可以包含多个条形码序列,使得对于多个珠粒的至少一个子集,每个珠粒包含多个条形码序列中的不同条形码序列。这种区分可以允许在多个分区之间与多个珠粒共同分配的模板核酸片段(例如,包含在细胞、细胞珠粒和/或细胞核内)在它们各自的分区内差异地条形码化,使得模板核酸片段或源自其的分子可以用它们所对应的分区(以及因此细胞、细胞珠粒和/或细胞核)来鉴定(例如,使用核酸测序测定,如本文所述)。条形码序列可以包含4-20个核苷酸。条形码序列可以包含一个或多个区段,所述区段的大小可以在2-20个核苷酸,例如4-20个核苷酸的范围内。可以使用组合组装方法,例如分裂池方法来组合此类片段以形成条形码序列。此类方法的细节可以例如在2018年11月15日提交的pct/us2018/061391和us 20190249226中找到,其各自以引用的方式整体并入本文。
140.在一些情况下,附接至珠粒的核酸条形码分子可能不同。例如,附接至珠粒的多个核酸条形码分子可以各自包含umi序列,所述umi序列在多个核酸条形码分子之间变化。附接至珠粒的多个核酸条形码分子的所有其他序列可以是相同的。
141.在一些情况下,珠粒可以包含附接至其的多个不同的核酸条形码分子。例如,珠粒可以包含第一多个核酸条形码分子和第二多个核酸条形码分子,所述第一多个核酸条形码分子不同于所述第二多个核酸条形码分子。偶联至珠粒的第一多个核酸条形码分子和第二多个核酸条形码分子可以包含一个或多个共享序列。例如,第一多个核酸条形码分子中的每个核酸条形码分子和第二多个核酸条形码分子中的每个核酸条形码分子可以包含相同的条形码序列(例如,如本文所述)。这种条形码序列可以使用组合组装过程(例如,如本文所述)来制备。例如,条形码序列可以包含相同的条形码序列区段。类似地,偶联至珠粒的第一多个核酸条形码分子中的每个核酸条形码分子可以包含与偶联至所述珠粒的第二多个核酸条形码中的每个核酸条形码分子相同的流动池衔接子序列和/或测序引物或其部分。在一个实例中,偶联至珠粒的第一多个核酸条形码分子中的每个核酸条形码分子包含测序引物,并且偶联至所述珠粒的第二多个核酸条形码分子中的每个核酸条形码分子包含同一测序引物的一部分。在一些情况下,偶联至珠粒的第一多个核酸条形码分子中的每个核酸
条形码分子可以包含第一测序引物(例如truseq r1序列)、条形码序列和第一功能序列,并且偶联至所述珠粒的第二多个核酸条形码分子中的每个核酸条形码分子可以包含第二测序引物(例如nextera r1序列或其一部分)、条形码序列和第二功能序列。偶联至同一珠粒的不同组核酸条形码分子之间共享的序列可以相同或不同的顺序包括并且可由相同或不同的序列隔开。可替代地或此外,偶联至珠粒的第一多个核酸条形码分子和第二多个核酸条形码分子可以包含一个或多个不同的序列。例如,偶联至多个珠粒中的一个珠粒的第一多个核酸条形码分子中的每个核酸条形码分子可以包含流动池衔接子序列、条形码序列、umi序列、捕获序列和测序引物或其部分中的一者或多者,而偶联至所述珠粒的第二多个核酸条形码分子中的每个核酸条形码分子可以包含流动池衔接子序列(例如同一流动池衔接子序列)、条形码序列(例如同一条形码序列)、umi序列、捕获序列和测序引物或其部分(例如同一测序引物或其部分)中的一者或多者。第一多个核酸条形码分子中的核酸条形码分子可以不包含umi序列或捕获序列。包含多个不同核酸条形码分子群体例如第一多个核酸分子和第二多个核酸分子(例如,如上所述)的珠粒可被称为“多功能珠粒”。
142.包含模板核酸片段(例如源自细胞、细胞珠粒或细胞核内所包含的dna或rna分子的模板核酸片段和另外模板核酸片段)的细胞、细胞珠粒或细胞核可以与一个或多个珠粒共同分配(例如,如本文所述)。例如,细胞、细胞珠粒或细胞核可以与第一珠粒(例如第一凝胶珠粒)和第二珠粒(例如第二凝胶珠粒)共同分配,所述第一珠粒被配置为与第一组模板核酸片段(例如源自dna分子的模板核酸片段,例如标签化片段)相互作用,所述第二珠粒被配置为与第二组模板核酸片段(例如源自rna分子的另外模板核酸片段)相互作用。第一珠粒可以包含第一核酸分子,所述第一核酸分子包含流动池衔接子序列、条形码序列和测序引物或其部分,所述测序引物或其部分可以被配置为与源自细胞、细胞珠粒或细胞核的dna分子的模板核酸片段或其衍生物中所包含的互补序列相互作用(例如,退火或杂交)。第二珠粒可以包含第二核酸分子,所述第二核酸分子包含流动池衔接子序列、条形码序列、测序引物或其一部分、umi序列和捕获序列,所述捕获序列可以被配置为与源自细胞、细胞珠粒或细胞核的rna分子的模板核酸片段或其衍生物的序列相互作用(例如,退火或杂交)。在一些情况下,捕获序列可以被配置为与在逆转录rna片段时产生的cdna分子的序列相互作用。第一珠粒和第二珠粒可以连接在一起(例如,共价或非共价地)。第一珠粒和第二珠粒可以各自包含多个核酸分子。例如,第一珠粒可以包含多个第一核酸分子,并且第二珠粒可以包含多个第二核酸分子,其中所述多个第一核酸分子中的每个第一核酸分子包含第一共享序列,并且所述多个第二核酸分子中的每个第二核酸分子包含第二共享序列。第一共享序列和第二共享序列可以相同或不同。第一共享序列和第二共享序列可以包含一种或多种共享组分,例如共享条形码序列或测序引物或其部分。
143.或者,包含模板核酸片段(例如源自细胞、细胞珠粒或细胞核内所包含的dna或rna分子的模板核酸片段或另外模板核酸片段)的细胞、细胞珠粒或细胞核可以与单个珠粒(例如凝胶珠粒)共同分配。例如,细胞、细胞珠粒或细胞核可以与珠粒共同分配,所述珠粒包含(i)被配置为与第一组模板核酸片段(例如源自dna分子的模板核酸片段,例如标签化片段)或其衍生物相互作用的第一多个核酸条形码分子,和(ii)被配置为与第二组模板核酸片段(例如源自rna分子的另外模板核酸片段)或其衍生物(例如从rna片段产生的cdna)相互作用的第二多个核酸条形码分子。第一多个核酸条形码分子中的核酸条形码分子可以包含流
动池衔接子序列、条形码序列和测序引物或其部分,所述测序引物或其部分可以被配置为与源自细胞、细胞珠粒或细胞核的dna分子的模板核酸片段或其衍生物中所包含的互补序列相互作用(例如,退火或杂交)。第二多个核酸条形码分子中的核酸条形码分子可以包含流动池衔接子序列、条形码序列、测序引物或其部分、umi序列和捕获序列,所述捕获序列可以被配置为与源自细胞、细胞珠粒或细胞核的rna分子的模板核酸片段或其衍生物(例如从rna片段产生的cdna)的序列相互作用(例如,退火或杂交)。第一多个核酸条形码分子可以包含与第二多个核酸条形码分子大致相同数量的核酸条形码分子。可替代地,第一多个核酸条形码分子可以包含比第二多个核酸条形码分子更多数量的核酸条形码分子,反之亦然。珠粒上核酸条形码分子的分布可以通过例如珠粒上的核酸条形码分子组装期间的序列控制、浓度控制和或封闭方法来控制。此类过程的细节提供于例如2018年11月15日提交的pct/us2018/061391和us 20190249226中,其各自以引用的方式整体并入。
144.图8a和图8b示出了根据本文提供的方法使用的珠粒的实例。图8a示出了第一珠粒801和第二珠粒811,它们可以与细胞、细胞珠粒或细胞核共同分配到多个分区(例如液滴或孔)中的一个分区中。第一珠粒801可以包含核酸分子802。核酸分子802可以包含序列803、804和805。序列803可以是例如流动池衔接子序列(例如p5或p7序列)。序列804可以是例如条形码序列。序列805可以是例如测序引物序列或其部分(例如r1或r2引物序列或其部分)。核酸分子802还可以包括另外序列,例如umi序列。第一珠粒801可以包含多个核酸分子802。第二珠粒811可以包含核酸分子812。核酸分子812可以包含序列813、814和815。序列813可以是例如流动池衔接子序列(例如p5或p7序列)。序列814可以是例如条形码序列。序列815可以是例如测序引物序列或其部分(例如r1或r2引物序列或其部分)。核酸分子812还可以包括另外序列,例如umi序列和捕获序列。第二珠粒801可以包含多个核酸分子812。
145.图8b示出了珠粒821(例如具有附接或偶联至其上的两种或更多种种类的核酸条形码分子的多功能珠粒),所述珠粒可以与细胞、细胞珠粒或细胞核共同分配到多个分区(例如液滴或孔)中的一个分区中。珠粒821可以包含核酸分子822和核酸分子826。核酸分子822可以包含序列823、824和825。序列823可以是例如流动池衔接子序列(例如p5或p7序列)。序列824可以是例如条形码序列。序列825可以是例如测序引物或其部分(例如r1或r2引物序列或其部分,例如nextera r1序列或其部分)。在一些情况下,序列825也可以是例如被配置为与如本文别处所述的夹板寡核苷酸杂交的序列。核酸分子826可以包含序列827、828和829。序列827可以是例如流动池衔接子序列(例如p5或p7序列)。序列828可以是例如条形码序列(例如与序列824相同的条形码序列)。序列829可以是例如测序引物或其部分(例如r1或r2引物序列或其部分)。序列827可以是例如测序引物或其部分(例如r1或r2引物序列或其部分,例如truseq r1序列或其部分)。序列828可以是例如条形码序列(例如与824相同的条形码序列)。序列829可以是例如捕获序列(例如多聚t序列),例如被配置为与靶核酸分子(例如mrna分子)杂交的捕获序列。序列829可以是例如模板转换寡核苷酸(tso)序列,其被配置为促进与靶核酸分子(例如mrna分子)的模板转换反应。序列823和序列827可以是相同的。可替代地,序列823和序列827可以是不同的。序列824和序列828可以是相同的。可替代地,序列824和序列828可以是不同的。序列825和序列829可以是相同的。可替代地,序列825和序列829可以是不同的。核酸分子822和826还可以包括另外序列,例如umi序列和捕获序列。珠粒821可以包含多个核酸分子822和多个核酸分子826。
146.在分区(例如,如本文所述)内,可以处理rna片段(例如,包含与引物分子杂交的细胞、细胞珠粒或细胞核的rna分子的序列的分子)以提供条形码化分子。rna片段可被逆转录以产生互补cdna链,所述cdna链可以被条形码化。在一些情况下,模板转换可用于增加cdna的长度(例如,通过并入一个或多个序列,例如一个或多个条形码或独特分子标识符序列)。在模板转换的一个实例中,可以由模板(例如mrna分子)的逆转录产生cdna,其中具有末端转移酶活性的逆转录酶可以例如在cdna的末端处向所述cdna添加另外核苷酸,例如多聚c,所述核苷酸不由所述模板编码。模板转换寡核苷酸(例如转换寡核苷酸)可以包含与另外核苷酸,例如多聚g(例如多聚ribog)互补的序列。cdna上的另外核苷酸(例如多聚c)可以杂交至与模板转换寡核苷酸上的另外核苷酸(例如多聚g)互补的序列,由此所述模板转换寡核苷酸可以被逆转录酶用作模板以进一步延伸cdna。模板转换寡核苷酸可以包含脱氧核糖核酸、核糖核酸、经修饰的核酸,包括锁核酸(lna),或它们的任何组合。模板转换寡核苷酸可以包含一个或多个序列,包括例如一个或多个选自由以下组成的组的序列:测序引物、条形码序列、独特分子标识符序列和均聚物序列(例如多聚g序列),或任何前述序列的互补序列。
147.在一些情况下,模板转换寡核苷酸的长度可为2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、31、32、33、34、35、36、37、38、39、40、41、42、43、44、45、46、47、48、49、50、51、52、53、54、55、56、57、58、59、60、61、62、63、64、65、66、67、68、69、70、71、72、73、74、75、76、77、78、79、80、81、82、83、84、85、86、87、88、89、90、91、92、93、94、95、96、97、98、99、100、101、102、103、104、105、106、107、108、109、110、111、112、113、114、115、116、117、118、119、120、121、122、123、124、125、126、127、128、129、130、131、132、133、134、135、136、137、138、139、140、141、142、143、144、145、146、147、148、149、150、151、152、153、154、155、156、157、158、159、160、161、162、163、164、165、166、167、168、169、170、171、172、173、174、175、176、177、178、179、180、181、182、183、184、185、186、187、188、189、190、191、192、193、194、195、196、197、198、199、200、201、202、203、204、205、206、207、208、209、210、211、212、213、214、215、216、217、218、219、220、221、222、223、224、225、226、227、228、229、230、231、232、233、234、235、236、237、238、239、240、241、242、243、244、245、246、247、248、249、250个核苷酸或更长。
148.在一些情况下,衔接子和/或条形码序列可以通过模板转换以外的方法添加至rna分子中。例如,可以将一个或多个序列连接至rna分子的末端。类似地,可以将一个或多个序列连接至通过rna分子的逆转录产生的cdna分子的末端。
149.在一个实例中,提供了包含染色质和一种或多种rna分子的细胞、细胞珠粒或细胞核。可以处理细胞、细胞珠粒或细胞核中的染色质以提供源自所述染色质的第一模板核酸片段(例如,如本文所述的标签化片段)。染色质可以在本体溶液中进行处理。可以处理rna分子以提供源自rna分子的第二模板核酸片段(例如,如本文所述)。rna分子可以在分区内进行处理。第一模板核酸片段的构型可以至少部分地取决于用于产生第一模板核酸片段的转座酶-核酸复合物的结构。例如,转座酶-核酸复合物,例如图9所示的转座酶-核酸复合物可用于制备第一模板核酸片段。第一模板核酸片段可以是至少部分双链的。第一模板核酸片段可以包含双链区,所述双链区包含细胞、细胞珠粒或细胞核的染色质的序列。双链区的第一链的第一末端可以连接至第一转座子末端序列(例如嵌合末端序列),所述第一转座子
末端序列可以连接至第一测序引物或其部分。双链区的第二链的第一末端(所述末端与第一链的第一末端相对)可以连接至第二转座子末端序列(例如嵌合末端序列),所述第二转座子末端序列可以连接至第二测序引物或其部分。第二转座子末端序列可以与第一转座子末端序列相同或不同。第一测序引物或其部分可以与第二测序引物或其部分相同或不同。在一些情况下,所述第一测序引物或其部分可以是r1序列或其部分,并且第二测序引物或其部分可以是r2序列或其部分。第一转座子末端序列可以与第一互补序列(例如嵌合末端反向互补序列)杂交,所述第一互补序列可以不连接至第一模板核酸片段的双链区的第二链的第二末端。类似地,第二转座子末端序列可以与第二互补序列(例如嵌合末端反向互补序列)杂交,所述第二互补序列可以不连接至第一模板核酸片段的双链区的第一链的第二末端。换言之,第一模板核酸片段可以包含一个或多个缺口。在一些情况下,一个或多个缺口的长度可以各自为大约9bp。第二模板核酸片段(例如另外模板核酸片段)可以包含细胞、细胞珠粒或细胞核的rna分子的序列和与引物分子(例如捕获核酸分子)杂交的序列。例如,第二模板核酸片段可以包含细胞、细胞珠粒或细胞核的rna分子的序列和与引物分子的多聚t序列杂交的多聚a序列。引物分子还可以包含另外引物序列。
150.包含第一模板核酸片段(例如标签化片段)的细胞、细胞珠粒或细胞核可以与一种或多种试剂共同分配到多个分区中的分区中(例如,如本文所述)。分区可以是例如液滴或孔。分区可以包含一个或多个珠粒(例如,如本文所述)。一个或多个珠粒中的一个珠粒可以包含第一多个核酸条形码分子。第一多个核酸条形码分子中的核酸条形码分子可以包含流动池衔接子序列(例如p5序列)、条形码序列、测序引物或其部分(例如r1序列或其部分,或其互补序列)以及被配置为与夹板寡核苷酸杂交的序列中的一者或多者。测序引物或其部分可以与第一模板核酸片段的序列互补。在一些情况下,第一多个核酸条形码分子中的核酸条形码分子可以包含流动池衔接子序列(例如p5序列)、条形码序列和被配置为与如本文别处所述的夹板寡核苷酸杂交的序列。一个或多个珠粒中的一个珠粒还可以包含第二多个核酸条形码分子。第二多个核酸条形码分子中的核酸条形码分子可以包含流动池衔接子序列(例如p5序列)、条形码序列、测序引物或其部分(例如r1序列或其部分,或其互补序列)以及被配置为与如本文别处所述的夹板寡核苷酸杂交的序列中的一者或多者。在一些情况下,第二多个核酸条形码分子中的核酸条形码分子可以包含测序引物或其部分(例如r1序列或其部分,或其互补序列)、条形码序列和被配置为与核酸分子(例如rna分子)杂交的捕获序列(例如多聚t序列)。在一些情况下,第一多个核酸条形码分子和第二多个核酸条形码分子可以是相同的。
151.在分区内,可以处理rna分子以提供第二模板核酸片段(例如,如本文所述)。
152.在分区内,细胞、细胞珠粒或细胞核可以被溶解或透化以接近其中的第一模板核酸片段和/或第二模板核酸片段(例如,如本文所述)。第二模板核酸片段可以在细胞、细胞珠粒或细胞核被溶解或透化之后产生。
153.第一模板核酸片段和第二模板核酸片段可以在分区内进行处理。在分区内,第一模板核酸分子中的缺口可以通过缺口填充延伸过程(例如,使用dna聚合酶或逆转录酶)填充。可以使所得双链核酸分子变性以提供包含染色质序列的单链,所述染色质序列侧接转座子末端序列和/或与转座子末端序列互补的序列。每个转座子末端序列和/或与转座子末端序列互补的序列可以连接至测序引物或其部分,或其互补序列(例如r1或r2序列或其部
分,或其互补序列)。第一多个核酸条形码分子中的核酸条形码分子可以与单链的测序引物或其部分或其互补序列杂交。然后可以使用引物延伸反应来产生单链的互补序列(例如,使用dna聚合酶或逆转录酶)。这种过程可以相当于线性扩增过程。此过程并入第一多个核酸条形码分子中的核酸条形码分子的条形码序列或其互补序列。可以使所得双链分子变性以提供单链,所述单链包含第一多个核酸条形码分子中的核酸条形码分子的流动池衔接子序列或其互补序列;第一多个核酸条形码分子中的核酸条形码分子的条形码序列或其互补序列;第一多个核酸条形码分子中的核酸条形码分子的测序引物或其部分,或其互补序列;转座子末端序列和/或其互补序列;第二测序引物或其部分,或其互补序列。另外扩增过程可以在或可以不在分区内进行。例如,指数扩增可以在或可以不在分区内进行。
154.在分区内,源自细胞、细胞珠粒或细胞核的rna分子的第二模板核酸片段可以被逆转录(例如,使用逆转录酶)以提供cdna链。逆转录过程可以将序列附加到包含rna链和cdna链的所得双链核酸分子的链的末端,例如多聚c序列。模板转换寡核苷酸可以包含可与双链核酸分子的至少一部分(例如,与附加的多聚c序列)杂交并用于进一步延伸所述双链核酸分子的链的序列(例如多聚g序列)以提供延伸的双链核酸分子。这样的序列可以包含核糖碱基。模板转换寡核苷酸可以包含umi序列或其互补序列,以及测序引物或其部分或其互补序列。可以使包含模板转换寡核苷酸及其互补序列的延伸的双链核酸分子和先前的双链核酸分子变性以提供单链,所述单链包含第二多个核酸条形码分子中的核酸条形码分子的测序引物或其部分或其互补序列;umi序列或其互补序列;多聚(c)或多聚(g)序列;对应于细胞、细胞珠粒或细胞核的rna分子的序列或其互补序列;以及捕获核酸分子的序列或其互补序列。第二多个核酸条形码分子中的核酸条形码分子可以与单链的测序引物或其部分或其互补序列杂交。然后可以使用引物延伸反应来产生单链的互补序列(例如,使用dna聚合酶)。这种过程可以相当于线性扩增过程。此过程并入第二多个核酸条形码分子中的核酸条形码分子的条形码序列或其互补序列。可以使所得双链分子变性以提供单链,所述单链包含第二多个核酸条形码分子中的核酸条形码分子的流动池衔接子序列或其互补序列;第二多个核酸条形码分子中的核酸条形码分子的条形码序列或其互补序列;第二多个核酸条形码分子中的核酸条形码分子的测序引物或其部分或其互补序列;umi序列或其互补序列;多聚(c)或多聚(g)序列;对应于细胞、细胞珠粒或细胞核的rna分子的序列或其互补序列;以及捕获核酸分子的序列或其互补序列。另外扩增过程可以在或可以不在分区内进行。例如,指数扩增可以在或可以不在分区内进行。
155.对应于在多个分区中的所述分区内包含的细胞、细胞珠粒或细胞核的染色质和rna分子的线性扩增产物可以从所述分区中回收。例如,可以汇集多个分区的内容物以在本体溶液中提供线性扩增产物。然后可以使对应于染色质的线性扩增产物经受足以进行一种或多种核酸扩增反应(例如pcr)的条件以产生对应于染色质的一种或多种扩增产物。核酸扩增过程可以并入一个或多个另外序列,例如一个或多个另外流动池衔接子序列。对应于rna分子的线性扩增产物可以经受片段化、末端修复和da加尾过程。然后可以将另外引物序列(例如测序引物或其部分,例如r2序列)连接至所得分子。然后可以进行核酸扩增反应(例如pcr)以产生一种或多种对应于rna分子的扩增产物。核酸扩增过程可以并入一个或多个另外序列,例如一个或多个另外流动池衔接子序列(参见,例如,图12)。
156.在rna工作流程中,分区内模板转换可以将测序引物(例如truseq r1或r2序列)附
接至rna转录物的3’或5’端。携带测序引物或其部分(例如部分truseq r1或r2序列)的珠粒(例如凝胶珠粒)也可用于dna(例如染色质)工作流程中的引发。这可以允许在从分区除去材料(例如破乳剂)和样品分裂后对dna(例如atac)和rna文库进行差异扩增。这种方法的另一个优点是可以使用相同的酶(例如dna聚合酶或逆转录酶)对源自dna(例如染色质)和rna的核酸片段进行条形码化。
157.图12示出了对应于前一实例的示例性示意图。图1200示出了对应于处理来自细胞、细胞珠粒或细胞核的染色质的工作流程,并且图1250示出了对应于处理来自细胞、细胞珠粒或细胞核的mrna分子的工作流程。在图中,示出了两个不同的珠粒(例如凝胶珠粒)。然而,在每个工作流程中可以使用同一珠粒(例如,可以是多功能珠粒的珠粒)。
158.如图1200所示,在本体溶液中,对细胞、细胞珠粒或细胞核内所包含的染色质进行处理(例如,如本文所述)以提供模板核酸片段(例如标签化片段)1204,所述模板核酸片段包含插入序列1208(例如开放染色质的区域)及其互补序列、转座子末端序列1206及其互补序列、测序引物或其部分1202(例如r1序列)、测序引物或其部分1210(例如r2序列)和缺口1207。模板核酸片段1204然后可以分配在分区内(例如,如本文所述的液滴或孔)。在分区内,包含模板核酸片段1204的细胞、细胞珠粒或细胞核可以被溶解、透化或以其他方式进行处理以接近其中的模板核酸片段1204(和一种或多种rna分子)。缺口1207可以通过缺口填充延伸过程(例如,使用dna聚合酶)来填充1212。分区可以包括与核酸条形码分子1218a偶联的珠粒(例如凝胶珠粒)1216a。核酸条形码分子1218a可以包含流动池衔接子序列1220a(例如p5序列)、条形码序列1222a和测序引物或其部分或其互补序列1202'。序列1202'可以与模板核酸片段1204的序列1202或其互补序列杂交,并且进行引物延伸1214以产生包含序列1220a、1222a、1202'、1210和插入序列1208或其互补序列的链。然后可以在本体溶液中回收分区的内容物(例如,可以使液滴破坏)以在本体溶液中提供链。此链可以进行扩增(例如pcr)1224以提供双链扩增产物1226,所述双链扩增产物包含核酸条形码分子1218a、原始染色质分子的序列和任选的可以是流动池衔接子序列(例如p7序列)的另外序列1228。
159.与图1200的染色质工作流程并行,可以处理源自同一细胞、细胞珠粒或细胞核的rna分子。如图1250所示,包含rna序列1260和多聚a序列1262的rna分子1258可以与包含多聚t序列1254和另外引物序列1256的引物分子1252接触1264。然后可以使用具有末端转移酶活性的逆转录酶将rna分子1258从多聚t序列1254逆转录1266出来,所述逆转录酶可以将序列1268附加到包含cdna序列1270的所得cdna分子上。序列1268可以是多聚c序列。包含测序引物或其部分或其互补序列1274、独特分子标识符序列或其互补序列1276和捕获序列(例如多聚g序列)1278的模板转换寡核苷酸1272然后可以与cdna分子杂交1280,并且模板转换可以发生。分区可以包括与核酸条形码分子1218b偶联的珠粒(例如凝胶珠粒)1216b。核酸条形码分子1218b可以包含流动池衔接子序列1220b(例如p5序列)、条形码序列1222b和测序引物或其部分或其互补序列1274'。珠粒(例如凝胶珠粒)1216b可以与珠粒1216a相同,使得分区包含单个珠粒(例如,1218a和1218b附接至单个珠粒)。在这种情况下,核酸条形码分子1218b和核酸条形码分子1218a可以具有相同的序列。序列1274'可以与cdna分子的序列1274或其互补序列杂交,并且进行引物延伸1282以产生包含序列1220b、1222b、1274'、1276或其互补序列1268或其互补序列和插入序列1270或其互补序列的链。然后可以在本体溶液中回收分区的内容物(例如,可以使液滴破坏)以在本体溶液中提供链。此链可
以进行扩增(例如pcr)1284以提供双链扩增产物1286,所述双链扩增产物包含核酸条形码分子的序列1218b、原始rna分子或与其对应的cdna,以及任选的另外序列1288,所述另外序列可以包含测序引物或其部分(例如r2序列)1290、样品标志序列1292和流动池衔接子序列(例如p7序列)1294。
160.图13示出了对应于前一实例的另一示例性示意图。图1300示出了对应于处理来自细胞、细胞珠粒或细胞核的染色质的工作流程,并且图1350示出了对应于处理来自细胞、细胞珠粒或细胞核的mrna分子的工作流程。在图中,示出了两个不同的珠粒(例如凝胶珠粒)。然而,在每个工作流程中可以使用同一珠粒(例如凝胶珠粒)。
161.如图1300所示,在本体溶液中,对细胞、细胞珠粒或细胞核内所包含的染色质进行处理(例如,如本文所述)以提供模板核酸片段(例如标签化片段)1304,所述模板核酸片段包含插入序列1308(例如开放染色质的区域)及其互补序列、转座子末端序列1306及其互补序列、测序引物或其部分1302(例如r1序列)、测序引物或其部分1310(例如r2序列)和缺口1307。模板核酸片段1304然后可以分配在分区内(例如,如本文所述的液滴或孔)。在分区内,包含模板核酸片段1304的细胞、细胞珠粒或细胞核可以被溶解、透化或以其他方式进行处理以接近其中的模板核酸片段1304(和一种或多种rna分子)。缺口1307可以通过缺口填充延伸过程(例如,使用dna聚合酶)来填充1312。分区可以包括与核酸条形码分子1318a偶联的珠粒(例如凝胶珠粒)1316a。核酸条形码分子1318a可以包含流动池衔接子序列1320a(例如p5序列)、条形码序列1322a和测序引物或其部分或其互补序列1302’。序列1302'可以与模板核酸片段1304的序列1302或其互补序列杂交,并且进行引物延伸1314以产生包含序列1320a、1322a、1302’、1310和插入序列1308或其互补序列的链。然后可以在本体溶液中回收分区的内容物(例如,可以使液滴破坏)以在本体溶液中提供链。此链可以进行扩增(例如pcr)1324以提供双链扩增产物1326,所述双链扩增产物包含核酸条形码分子1318a、原始染色质分子的序列和任选的可以是流动池衔接子序列(例如p7序列)的另外序列1328。
162.与图1300的染色质工作流程并行,可以处理源自同一细胞、细胞珠粒或细胞核的rna分子。如图1350所示,包含rna序列1360和多聚a序列1362的rna分子1358可以与包含多聚t序列1354、umi序列1355和测序引物或其部分(例如r1序列)1356的引物分子1352接触。可以使用具有末端转移酶活性的逆转录酶将rna分子1358从多聚t序列1354逆转录1364出来,所述逆转录酶可以将序列1366(例如多聚c序列)附加到包含cdna序列1368的所得cdna分子上。包含另外引物序列1372和与序列1366互补的均聚物序列1374(例如多聚g)序列的模板转换寡核苷酸1370然后可以与cdna分子杂交1376并且可以发生模板转换。分区可以包括与核酸条形码分子1318b偶联的珠粒(例如凝胶珠粒)1316b。核酸条形码分子1318b可以包含流动池衔接子序列1320b(例如p5序列)、条形码序列1322b和测序引物或其部分或其互补序列1356'。珠粒(例如凝胶珠粒)1316b可以与珠粒(例如凝胶珠粒)1316a相同,使得分区包含单个珠粒(即,1318a和1318b附接至单个珠粒)。在这种情况下,核酸条形码分子1318b和核酸条形码分子1318a可以具有相同的序列。序列1356'可以与cdna分子的序列1356或其互补序列杂交,并且进行引物延伸1378以产生包含序列1320b、1322b、1356’、1355或其互补序列1366或其互补序列和插入序列1368或其互补序列的链。然后可以在本体溶液中回收分区的内容物(例如,可以使液滴破坏)以在本体溶液中提供链。此链可以进行扩增(例如pcr)1380以提供双链扩增产物1382,所述双链扩增产物包含核酸条形码分子的序列1318b、原始
rna分子或与其对应的cdna,以及任选的另外序列1384,所述另外序列可以包含测序引物或其部分(例如r2序列)1390、样品标志序列1388和流动池衔接子序列(例如p7序列)1386。
163.在另一个实例中,提供了包含染色质和一种或多种rna分子的细胞、细胞珠粒或细胞核。可以处理细胞、细胞珠粒或细胞核中的染色质以提供源自所述染色质的第一模板核酸片段(例如,如本文所述的标签化片段)。染色质可以在本体溶液中进行处理。可以处理rna分子以提供源自rna分子的第二模板核酸片段(例如,如本文所述)。rna分子可以在分区内进行处理。第一模板核酸片段的构型可以至少部分地取决于用于产生第一模板核酸片段的转座酶-核酸复合物的结构。例如,转座酶-核酸复合物,例如图9所示的转座酶-核酸复合物可用于制备第一模板核酸片段。第一模板核酸片段可以是至少部分双链的。第一模板核酸片段可以包含双链区,所述双链区包含细胞、细胞珠粒或细胞核的染色质的序列。双链区的第一链的第一末端可以连接至第一转座子末端序列(例如嵌合末端序列),所述第一转座子末端序列可以连接至第一测序引物或其部分。双链区的第二链的第一末端(所述末端与第一链的第一末端相对)可以连接至第二转座子末端序列(例如嵌合末端序列),所述第二转座子末端序列可以连接至第二测序引物或其部分。第二转座子末端序列可以与第一转座子末端序列相同或不同。第一测序引物或其部分可以与第二测序引物或其部分相同或不同。在一些情况下,所述第一测序引物或其部分可以是r1序列或其部分,并且第二测序引物或其部分可以是r2序列或其部分。第一转座子末端序列可以与第一互补序列(例如嵌合末端反向互补序列)杂交,所述第一互补序列可以不连接至第一模板核酸片段的双链区的第二链的第二末端。类似地,第二转座子末端序列可以与第二互补序列(例如嵌合末端反向互补序列)杂交,所述第二互补序列可以不连接至第一模板核酸片段的双链区的第一链的第二末端。换言之,第一模板核酸片段可以包含一个或多个缺口。在一些情况下,一个或多个缺口的长度可以各自为大约9bp。例如,一个或多个缺口的长度可以是至少约1、2、3、4、5、6、7、8、9、10或更多bp。例如,一个或多个缺口的长度可以是至多约10、9、8、7、6、5、4、3、2或1bp。第二模板核酸片段(例如另外模板核酸片段)可以包含细胞、细胞珠粒或细胞核的rna分子的序列和与引物分子(例如捕获核酸分子)杂交的序列。例如,第二模板核酸片段可以包含细胞、细胞珠粒或细胞核的rna分子的序列和与引物分子的多聚t序列杂交的多聚a序列。引物分子还可以包含另外引物序列。
164.包含第一模板核酸片段(例如标签化片段)的细胞、细胞珠粒或细胞核可以与一种或多种试剂共同分配到多个分区中的分区中(例如,所述分区可以是例如液滴或孔)。分区可以包含一个或多个珠粒(例如,如本文所述)。一个或多个珠粒中的一个珠粒(例如凝胶珠粒)可以包含第一多个核酸条形码分子。第一多个核酸条形码分子中的核酸条形码分子可以包含流动池衔接子序列(例如p5序列)、条形码序列,以及测序引物或其部分(例如r1序列或其部分,或其互补序列)。测序引物或其部分可以与第一模板核酸片段的序列互补。流动池衔接子序列和/或条形码序列可以与它们的互补序列杂交。一个或多个珠粒中的一个珠粒(例如凝胶珠粒)还可以包含第二多个核酸条形码分子。第二多个核酸条形码分子中的核酸条形码分子可以包含流动池衔接子序列(例如p5序列)、条形码序列、测序引物或其部分(例如r1序列或其部分,或互补序列)、umi序列和捕获序列(例如多聚g序列、多聚dt序列或靶特异性序列)。在一些情况下,第一多个核酸条形码分子和第二多个核酸条形码分子可以偶联至同一珠粒,并且分区可以包含单个珠粒。
165.在分区内,可以处理rna分子以提供第二模板核酸片段(例如,如本文所述)。
166.在分区内,细胞、细胞珠粒或细胞核可以被溶解或透化以接近其中的第一模板核酸片段和/或第二模板核酸片段。第二模板核酸片段可以在细胞、细胞珠粒或细胞核被溶解或透化之后产生。
167.第一模板核酸片段和第二模板核酸片段可以在分区内进行处理。在分区内,对应于细胞、细胞珠粒或细胞核的染色质的第一模板核酸片段的测序引物或其部分可以与第一多个核酸条形码分子中的核酸条形码分子的测序引物或其部分杂交。然后可以将核酸条形码分子的测序引物或其部分连接(例如,使用连接酶)至第一模板核酸片段的转座子末端序列或其互补序列,以提供对应于细胞、细胞珠粒或细胞核的染色质的部分双链核酸分子。
168.在分区内,源自细胞、细胞珠粒或细胞核的rna分子的第二模板核酸片段可以被逆转录(例如,使用逆转录酶)以提供cdna链。逆转录过程可以将序列附加到包含rna链和cdna链的所得双链核酸分子的链的末端,例如多聚c序列。第二多个核酸条形码分子中的核酸条形码分子的捕获序列可以与双链核酸分子的附加序列(例如多聚c序列)杂交,并且可以发生模板转换过程以提供延伸的双链核酸分子。这样的序列可以包含核糖碱基。第二多个核酸条形码分子中的核酸条形码分子的序列可以被认为是模板转换寡核苷酸。因此,条形码化和模板转换可以同时发生以提供条形码化cdna分子。条形码化cdna分子(例如包含cdna链和rna链的分子)的cdna链可以包含多聚c序列、与模板转换寡核苷酸的序列或其部分互补的序列(例如与模板转换寡核苷酸的测序引物、条形码序列和umi序列互补的序列)、cdna序列、多聚t序列以及引物分子的另外引物序列。条形码化cdna分子的rna链可以包含模板转换寡核苷酸的序列、mrna序列以及与引物分子的另外引物序列互补的序列。
169.对应于细胞、细胞珠粒或细胞核的染色质的部分双链分子和对应于多个分区中的分区(例如液滴或孔)内所包含的细胞、细胞珠粒或细胞核的rna分子的条形码化cdna分子可以从所述分区中回收。例如,可以汇集多个分区的内容物以在本体溶液中提供这些产物。
170.在分区之外,对应于染色质的部分双链核酸分子中的缺口可以通过缺口填充延伸过程(例如,使用dna聚合酶或逆转录酶)来填充。缺口填充延伸过程可能不包括链置换。可以使所得的缺口填充双链核酸分子变性以提供单链,所述单链可以经受足以进行一种或多种核酸扩增反应(例如pcr)的条件以产生对应于细胞、细胞珠粒或细胞核的染色质的扩增产物。核酸扩增过程可以并入一个或多个另外序列,例如一个或多个另外流动池衔接子序列。
171.在分区之外,对应于rna分子的条形码化cdna分子可以经受片段化、末端修复、da加尾过程、标签化或它们的组合。可以将另外引物序列(例如测序引物或其部分,例如r2序列)连接至所得分子。可替代地或此外,可以进行核酸扩增反应(例如pcr)以产生一种或多种对应于rna分子或由其产生的cdna分子的扩增产物。核酸扩增过程可以并入一个或多个另外序列,例如一个或多个另外流动池衔接子序列。
172.图14示出了对应于前一实例的示例性示意图。图1400示出了对应于处理来自细胞、细胞珠粒或细胞核的染色质的工作流程,并且图1450示出了对应于处理来自细胞、细胞珠粒或细胞核的mrna分子的工作流程。
173.如图1400所示,在本体溶液中,对细胞、细胞珠粒或细胞核内所包含的染色质进行处理(例如,如本文所述)以提供模板核酸片段(例如标签化片段)1404,所述模板核酸片段
包含插入序列1408(例如开放染色质的区域)及其互补序列、转座子末端序列1406及其互补序列、测序引物或其部分1402(例如r1序列)、测序引物或其部分1410(例如r2序列)和缺口1407。模板核酸片段1404然后可以分配在分区内(例如,如本文所述的液滴或孔)。在分区内,包含模板核酸片段1404的细胞、细胞珠粒或细胞核可以被溶解、透化或以其他方式进行处理以接近其中的模板核酸片段1404(和一种或多种rna分子)。分区可以包括与核酸条形码分子1418a和1418b偶联的珠粒(例如凝胶珠粒)1416。核酸条形码分子1418a可以包含流动池衔接子序列1420a(例如p5序列)、条形码序列1422a和测序引物或其部分或其互补序列1402’。序列1420a和1422a可以分别与互补序列1420’和1422’杂交。序列1402’可以与模板核酸片段1404的序列1402或其互补序列杂交,并且序列1422’可以连接1412至模板核酸片段1404的序列1402。在一些情况下,模板核酸片段1404可以使用合适的激酶(例如多核苷酸激酶(pnk),例如t4 pnk)磷酸化。在一些情况下,pnk和atp可以在标签化(例如atac)反应中和/或在分配细胞、细胞珠粒或细胞核或它们中的多者之前大量添加。可以将15u的pnk和1mm的atp掺杂至标签化反应中。例如,可以将少于95u的pnk掺杂至标签化反应中。然后可以在本体溶液中回收分区的内容物(例如,可以使液滴破坏)以在本体溶液中提供部分双链核酸分子,所述部分双链核酸分子包含附接至模板核酸片段1404的核酸条形码分子1418a。在本体溶液中,缺口1407可以通过缺口填充延伸过程(例如,使用dna聚合酶)来填充1424以提供双链核酸分子。此分子可以进行扩增(例如pcr)1426以提供双链扩增产物1428,所述双链扩增产物包含核酸条形码分子1418a、原始染色质分子的序列和任选的可以是流动池衔接子序列(例如p7序列)的另外序列1430。可以在批量处理之前填充分区中的缺口。
174.与图1400的染色质工作流程并行,可以处理源自同一细胞、细胞珠粒或细胞核的rna分子。如图1450所示,包含rna序列1460和多聚a序列1462的rna分子1458可以与包含多聚t序列1454和另外引物序列1456的引物分子1452接触1464。然后可以使用具有末端转移酶活性的逆转录酶将rna分子1458从多聚t序列1454逆转录1476出来,所述逆转录酶可以将序列1470附加到包含cdna序列1468的所得cdna分子上。序列1470可以是多聚c序列。珠粒(例如凝胶珠粒)1416(例如,在图1400中描述的相同珠粒)可以包括在分区内并且可以与核酸条形码分子1418b偶联。核酸条形码分子1418b可以包含流动池衔接子序列1420b(例如p5序列)、条形码序列1422b、umi序列1472和与序列1470互补的序列1474(例如多聚g序列)。在一些情况下,核酸条形码分子1418b可以包含测序引物序列1420b(例如r1序列或部分r1序列)、条形码序列1422b、umi序列1472和与序列1470互补的模板转换序列1474(例如多聚g序列)。核酸条形码分子1418b可用于执行模板转换1478,所述过程也可以导致条形码化cdna分子的产生。然后可以在本体溶液中回收分区的内容物(例如,可以使液滴破坏)以在本体溶液中提供条形码化cdna分子。条形码化cdna分子可以进行扩增(例如pcr)1480以提供双链扩增产物1484,所述双链扩增产物包含核酸条形码分子的序列1418b、原始rna分子或与其对应的cdna、流动池衔接子序列1486,以及任选的另外序列1488,所述另外序列可以包含测序引物或其部分(例如r2序列)1490、样品标志序列1492和流动池衔接子序列(例如p7序列)1494。条形码化cdna分子还可以或可替代地进行片段化、末端修复、da加尾、一个或多个衔接子序列的连接和/或核酸扩增。
175.图15示出了对应于前一实例的另一示例性示意图。图1500示出了对应于处理来自细胞、细胞珠粒或细胞核的染色质的工作流程,并且图1550示出了对应于处理来自细胞、细
胞珠粒或细胞核的mrna分子的工作流程。
176.如图1500所示,在本体溶液中,对细胞、细胞珠粒或细胞核内所包含的染色质进行处理(例如,如本文所述)以提供模板核酸片段(例如标签化片段)1504,所述模板核酸片段包含插入序列1508(例如开放染色质的区域)及其互补序列、转座子末端序列1506及其互补序列、测序引物或其部分1502(例如r1序列)、测序引物或其部分1510(例如r2序列)和缺口1507。模板核酸片段1504然后可以分配在分区内(例如,如本文所述的液滴或孔)。在分区内,包含模板核酸片段1504的细胞、细胞珠粒或细胞核可以被溶解、透化或以其他方式进行处理以接近其中的模板核酸片段1504(和一种或多种rna分子)。分区可以包括与核酸条形码分子1518a和1518b偶联的珠粒(例如凝胶珠粒)1516。核酸条形码分子1518a可以包含流动池衔接子序列1520a(例如p5序列)、条形码序列1522a和测序引物或其部分或其互补序列1502’。序列1520a和1522a可以分别与互补序列1520’和1522’杂交。序列1502’可以与模板核酸片段1504的序列1502或其互补序列杂交,并且序列1522’可以连接1512至模板核酸片段1504的序列1502。在一些情况下,模板核酸片段1504可以使用合适的激酶(例如多核苷酸激酶(pnk),例如t4 pnk)磷酸化。在一些情况下,pnk和atp可以在标签化(例如atac)反应中和/或在分配细胞、细胞珠粒或细胞核或它们中的多者之前大量添加。可以将15u的pnk和1mm的atp掺杂至标签化反应中。例如,可以将少于95u的pnk掺杂至标签化反应中。然后可以在本体溶液中回收分区的内容物(例如,可以使液滴破坏)以在本体溶液中提供部分双链核酸分子,所述部分双链核酸分子包含附接至模板核酸片段1504的核酸条形码分子1518a。在本体溶液中,缺口1507可以通过缺口填充延伸过程(例如,使用dna聚合酶)来填充1524以提供双链核酸分子。此分子可以进行扩增(例如pcr)1526以提供双链扩增产物1528,所述双链扩增产物包含核酸条形码分子1518a、原始染色质分子的序列和任选的可以是流动池衔接子序列(例如p7序列)的另外序列1530。可以在批量处理之前填充分区中的缺口。
177.与图1500的染色质工作流程并行,可以处理源自同一细胞、细胞珠粒或细胞核的rna分子。如图1550所示,包含rna序列1560和多聚a序列1562的rna分子1558和珠粒(例如凝胶珠粒)1516可以提供在分区内。珠粒(例如凝胶珠粒)1516(例如,在图1500中描述的相同珠粒)可以包括在分区内并且可以与核酸条形码分子1518b偶联。核酸条形码分子1518b可以包含流动池衔接子序列1568(例如p5序列)、条形码序列1522b(例如与条形码序列1522a相同的条形码序列)、umi序列1566和与多聚a序列1562互补的多聚t序列1564。在一些情况下,核酸条形码分子1518b可以包含测序引物序列1568(例如r1序列或部分r1序列)、条形码序列1522b(例如与条形码序列1522a相同的条形码序列)、umi序列1566和与多聚a序列1562互补的多聚t序列1564。多聚t序列1564可以与rna分子1558的多聚a序列1562杂交。rna分子1558可以从多聚t序列1564逆转录1570出来以提供包含cdna序列1572的cdna分子。逆转录过程可以使用具有末端转移酶活性的逆转录酶,所述逆转录酶可以将序列1574附加到包含cdna序列1572的所得cdna分子上。序列1574可以是多聚c序列。包含引物序列1580和与序列1574互补的序列(例如多聚g序列)的模板转换寡核苷酸1578可以与cdna分子杂交并促进模板转换寡核苷酸1578上的模板转换反应。然后可以在本体溶液中回收分区的内容物(例如,可以使液滴破坏)以在本体溶液中提供cdna分子。cdna分子可以进行扩增(例如pcr)1584。可以进行另外扩增(例如pcr)1586以提供双链扩增产物1588,所述双链扩增产物包含核酸条形码分子1518b、原始rna分子的序列或与其对应的cdna、流动池衔接子序列1598(例如p7
序列)和另外序列1590,所述另外序列可以包含测序引物或其部分(例如r2序列)1596、样品标志序列1594和流动池衔接子序列(例如p5序列)1592。条形码化cdna分子还可以或可替代地进行片段化、末端修复、da加尾、一个或多个衔接子序列的连接和/或核酸扩增。
178.在另一个实例中,提供了包含染色质和一种或多种rna分子的细胞、细胞珠粒或细胞核。可以处理细胞、细胞珠粒或细胞核中的染色质以提供源自所述染色质的第一模板核酸片段(例如,如本文所述的标签化片段)。染色质可以在本体溶液中进行处理。可以处理rna分子以提供源自rna分子的第二模板核酸片段(例如,如本文所述的另外核酸片段)。rna分子可以在分区内进行处理。源自rna分子的第二模板核酸片段可以根据前述实例进行处理。第一模板核酸片段的构型可以至少部分地取决于用于产生第一模板核酸片段的转座酶-核酸复合物的结构。例如,转座酶-核酸复合物,例如图9所示的转座酶-核酸复合物可用于制备第一模板核酸片段。相对于前述实例,转座酶-核酸的极性可以逆转,使得测序引物(例如r1和r2测序引物)不直接连接至染色质(参见,例如,图17)。第一模板核酸片段可以是至少部分双链的。第一模板核酸片段可以包含双链区,所述双链区包含细胞、细胞珠粒或细胞核的染色质的序列。双链区的第一链的第一末端可以连接至第一转座子末端序列(例如嵌合末端序列)。双链区的第二链的第一末端(所述末端与第一链的第一末端相对)可以连接至第二转座子末端序列(例如嵌合末端序列)。第二转座子末端序列可以与第一转座子末端序列相同或不同。第一转座子末端序列可以与第一互补序列(例如嵌合末端反向互补序列)杂交,所述第一互补序列可以不连接至第一模板核酸片段的双链区的第二链的第二末端。第一互补序列可以连接至第一测序引物或其部分。类似地,第二转座子末端序列可以与第二互补序列(例如嵌合末端反向互补序列)杂交,所述第二互补序列可以不连接至第一模板核酸片段的双链区的第一链的第二末端。第二互补序列可以连接至第二测序引物或其部分。换言之,第一模板核酸片段可以包含一个或多个缺口。在一些情况下,一个或多个缺口的长度可以各自为大约9bp。例如,一个或多个缺口的长度可以是至少约1、2、3、4、5、6、7、8、9、10或更多bp。例如,一个或多个缺口的长度可以是至多约10、9、8、7、6、5、4、3、2或1bp。第一测序引物或其部分可以与第二测序引物或其部分相同或不同。在一些情况下,所述第一测序引物或其部分可以是r1序列或其部分,并且第二测序引物或其部分可以是r2序列或其部分。
179.包含第一模板核酸片段(例如标签化片段)的细胞、细胞珠粒或细胞核可以与一种或多种试剂共同分配到多个分区中的分区中(例如,如本文所述)。分区可以是例如液滴或孔。分区可以包含一个或多个珠粒(例如,如本文所述)。一个或多个珠粒中的一个珠粒(例如凝胶珠粒)可以包含第一多个核酸条形码分子。第一多个核酸条形码分子中的核酸条形码分子可以包含流动池衔接子序列(例如p5序列)、条形码序列,以及测序引物或其部分(例如r1序列或其部分,或其互补序列)。测序引物或其部分可以与第一模板核酸片段的序列互补。流动池衔接子序列和/或条形码序列可以与它们的互补序列杂交。同一珠粒或另一个珠粒可以包含第二多个核酸条形码分子。第二多个核酸条形码分子中的核酸条形码分子可以包含测序引物或其部分(例如r1序列或其部分,或其互补序列)、条形码序列、独特分子标识符序列和捕获顺序。
180.在分区内,可以处理rna分子以提供第二模板核酸片段(例如,如本文所述)。例如,rna分子(例如mrna分子)可以与包含第一引物序列(例如多聚t序列)和另外引物序列的引
物分子接触。
181.在分区内,细胞、细胞珠粒或细胞核可以被溶解或透化以接近其中的第一模板核酸片段和/或第二模板核酸片段(例如,如本文所述)。第二模板核酸片段可以在细胞、细胞珠粒或细胞核被溶解或透化之后产生。
182.第一模板核酸片段和第二模板核酸片段可以在分区内进行处理。在分区内,对应于细胞、细胞珠粒或细胞核的染色质的第一模板核酸片段的测序引物或其部分可以与第一多个核酸条形码分子中的核酸条形码分子的测序引物或其部分杂交。然后可以将核酸条形码分子的测序引物或其部分连接(例如,使用连接酶)至第一模板核酸片段的转座子末端序列或其互补序列,以提供对应于细胞、细胞珠粒或细胞核的染色质的部分双链核酸分子。对应于rna分子的第二模板核酸片段可以使用具有末端转移酶活性的逆转录酶进行逆转录,所述逆转录酶可以将序列(例如多聚c序列)附加到所得cdna分子的cdna链上。然后可以使cdna分子与可以是模板转换寡核苷酸的第二多个核酸条形码分子中的核酸条形码分子接触。核酸条形码分子可以包含测序引物或其部分(例如r1序列或其部分,或其互补序列)、条形码序列、独特分子标识符序列和捕获顺序。捕获序列可以是与附加到cdna链上的序列(例如多聚g序列)互补的序列。然后可以进行模板转换和条形码化以提供条形码化cdna分子。
183.对应于细胞、细胞珠粒或细胞核的染色质的部分双链分子和对应于多个分区中的分区内所包含的细胞、细胞珠粒或细胞核的rna分子(例如,如上文所述制备)的条形码化cdna分子可以从所述分区中回收。例如,可以汇集多个分区的内容物以在本体溶液中提供线性扩增产物。
184.在分区之外,对应于染色质的部分双链核酸分子中的缺口可以通过缺口填充延伸过程(例如,使用dna聚合酶)来填充。可以在批量处理之前填充分区中的缺口。可以使所得的缺口填充双链核酸分子变性以提供单链,所述单链可以经受足以进行一种或多种核酸扩增反应(例如pcr)的条件以产生对应于细胞、细胞珠粒或细胞核的染色质的扩增产物。核酸扩增过程可以并入一个或多个另外序列,例如一个或多个另外流动池衔接子序列。对应于rna分子的条形码化cdna分子也可以根据前述实例进行处理和扩增。
185.图16示出了对应于前一实例的示例性示意图。图1600示出了对应于处理来自细胞、细胞珠粒或细胞核的染色质的工作流程,并且图1650示出了对应于处理来自细胞、细胞珠粒或细胞核的mrna分子的工作流程。
186.如图1600所示,在本体溶液中,对细胞、细胞珠粒或细胞核内所包含的染色质进行处理(例如,如本文所述)以提供模板核酸片段(例如标签化片段)1604,所述模板核酸片段包含插入序列1608(例如开放染色质的区域)及其互补序列、转座子末端序列1606及其互补序列、测序引物或其部分1602(例如r1序列)、测序引物或其部分1610(例如r2序列)和缺口1607。模板核酸片段1604然后可以分配在分区内(例如,如本文所述的液滴或孔)。在分区内,包含模板核酸片段1604的细胞、细胞珠粒或细胞核可以被溶解、透化或以其他方式进行处理以接近其中的模板核酸片段1604(和一种或多种rna分子)。分区可以包括与核酸条形码分子1618a和1618b偶联的珠粒(例如凝胶珠粒)1616。核酸条形码分子1618a可以包含流动池衔接子序列1620a(例如p5序列)、条形码序列1622a和测序引物或其部分或其互补序列1602’。序列1602’可以与模板核酸片段1604的序列1602或其互补序列杂交。然后可以将序列1602’连接1612至模板核酸片段1604的转座子末端序列1606。在一些情况下,1604可以使
用合适的激酶(例如多核苷酸激酶(pnk),例如t4 pnk)磷酸化。在一些情况下,pnk和atp可以在标签化(例如atac)反应中和/或在分配细胞、细胞珠粒或细胞核或它们中的多者之前大量添加。可以将15u的pnk和1mm的atp掺杂至标签化反应中。例如,可以将少于95u的pnk掺杂至标签化反应中。然后可以在本体溶液中回收分区的内容物(例如,可以使液滴破坏)以在本体溶液中提供部分双链核酸分子,所述部分双链核酸分子包含附接至模板核酸片段1604的核酸条形码分子1618a。在本体溶液中,缺口1607可以通过缺口填充延伸过程(例如,使用dna聚合酶)和从序列1602延伸的分子来填充1614以提供双链核酸分子。此分子可以进行扩增(例如pcr)1624以提供双链扩增产物1626,所述双链扩增产物包含核酸条形码分子1618a、原始染色质分子的序列和任选的可以是流动池衔接子序列(例如p7序列)的另外序列1628。可以在批量处理之前填充分区中的缺口。
187.与图1600的染色质工作流程并行,可以处理源自同一细胞、细胞珠粒或细胞核的rna分子。如图1650所示,包含rna序列1660和多聚a序列1662的rna分子1658可以与包含多聚t序列1654和另外引物序列1656的引物分子1652接触1664。然后可以使用具有末端转移酶活性的逆转录酶将rna分子1658从多聚t序列1654逆转录1676出来,所述逆转录酶可以将序列1670附加到包含cdna序列1668的所得cdna分子上。序列1670可以是多聚c序列。珠粒(例如凝胶珠粒)1616(例如,在图1600中描述的相同珠粒)可以包括在分区内并且可以与核酸条形码分子1618b偶联。核酸条形码分子1618b可以包含流动池衔接子序列1620b(例如p5序列)、条形码序列1622b、umi序列1672和与序列1670互补的序列1674(例如多聚g序列)。在一些情况下,核酸条形码分子1618b可以包含测序引物序列1620b(例如r1序列或部分r1序列)、条形码序列1622b、umi序列1672和与序列1670互补的模板转换序列1674(例如多聚g序列)。核酸条形码分子1618b可用于执行模板转换1678,所述过程也可以导致条形码化cdna分子的产生。然后可以在本体溶液中回收分区的内容物(例如,可以使液滴破坏)以在本体溶液中提供条形码化cdna分子。条形码化cdna分子可以进行扩增(例如pcr)1680以提供双链扩增产物1684,所述双链扩增产物包含核酸条形码分子的序列1618b、原始rna分子或与其对应的cdna、流动池衔接子序列1686,以及任选的另外序列1688,所述另外序列可以包含测序引物或其部分(例如r2序列)1690、样品标志序列1692和流动池衔接子序列(例如p7序列)1694。条形码化cdna分子还可以或可替代地进行片段化、末端修复、da加尾、一个或多个衔接子序列的连接和/或核酸扩增。
188.图17示出了对应于前一实例的另一示例性示意图。图1700示出了对应于处理来自细胞、细胞珠粒或细胞核的染色质的工作流程,并且图1750示出了对应于处理来自细胞、细胞珠粒或细胞核的mrna分子的工作流程。
189.如图1700所示,在本体溶液中,对细胞、细胞珠粒或细胞核内所包含的染色质进行处理(例如,如本文所述)以提供模板核酸片段(例如标签化片段)1704,所述模板核酸片段包含插入序列1708(例如开放染色质的区域)及其互补序列、转座子末端序列1706及其互补序列、测序引物或其部分1702(例如r1序列)、测序引物或其部分1710(例如r2序列)和缺口1707。模板核酸片段1704然后可以分配在分区内(例如,如本文所述的液滴或孔)。在分区内,包含模板核酸片段1704的细胞、细胞珠粒或细胞核可以被溶解、透化或以其他方式进行处理以接近其中的模板核酸片段1704(和一种或多种rna分子)。分区可以包括与核酸条形码分子1718a和1718b偶联的珠粒(例如凝胶珠粒)1716。核酸条形码分子1718a可以包含流
动池衔接子序列1720a(例如p5序列)、条形码序列1722a和测序引物或其部分或其互补序列1702’。序列1702’可以与模板核酸片段1704的序列1702或其互补序列杂交。然后可以将序列1702’连接1712至模板核酸片段1704的转座子末端序列1706。在一些情况下,1704可以使用合适的激酶(例如多核苷酸激酶(pnk),例如t4 pnk)磷酸化。在一些情况下,pnk和atp可以在标签化反应(例如atac)中和/或在分配细胞、细胞珠粒或细胞核或它们中的多者之前大量添加。可以将15u的pnk和1mm的atp掺杂至标签化反应中。例如,可以将少于95u的pnk掺杂至标签化反应中。然后可以在本体溶液中回收分区的内容物(例如,可以使液滴破坏)以在本体溶液中提供部分双链核酸分子,所述部分双链核酸分子包含附接至模板核酸片段1704的核酸条形码分子1718a。在本体溶液中,缺口1707可以通过缺口填充延伸过程(例如,使用dna聚合酶)和从序列1702延伸的分子来填充1714以提供双链核酸分子。此分子可以进行扩增(例如pcr)1724以提供双链扩增产物1726,所述双链扩增产物包含核酸条形码分子1718a、原始染色质分子的序列和任选的可以是流动池衔接子序列(例如p7序列)的另外序列1728。可以在批量处理之前填充分区中的缺口。
190.与图1700的染色质工作流程并行,可以处理源自同一细胞、细胞珠粒或细胞核的rna分子。如图1750所示,包含rna序列1760和多聚a序列1762的rna分子1758和珠粒(例如凝胶珠粒)1716可以提供在分区内。珠粒(例如凝胶珠粒)1716(例如,在图1700中描述的相同珠粒)可以包括在分区内并且可以与核酸条形码分子1718b偶联。核酸条形码分子1718b可以包含流动池衔接子序列1768(例如p5序列)、条形码序列1722b(例如与条形码序列1722a相同的条形码序列)、umi序列1766和与多聚a序列1762互补的多聚t序列1764。在一些情况下,核酸条形码分子1718b可以包含测序引物序列1768(例如r1序列或部分r1序列)、条形码序列1722b(例如与条形码序列1722a相同的条形码序列)、umi序列1766和与多聚a序列1762互补的多聚t序列1764。多聚t序列1764可以与rna分子1758的多聚a序列1762杂交。rna分子1758可以从多聚t序列1764逆转录1770出来以提供包含cdna序列1772的cdna分子。逆转录过程可以使用具有末端转移酶活性的逆转录酶,所述逆转录酶可以将序列1774附加到包含cdna序列1772的所得cdna分子上。序列1774可以是多聚c序列。包含引物序列1780和与序列1774互补的序列(例如多聚g序列)的模板转换寡核苷酸1778可以与cdna分子杂交。然后可以在本体溶液中回收分区的内容物(例如,可以使液滴破坏)以在本体溶液中提供cdna分子。cdna分子可以进行扩增(例如pcr)1784。可以进行另外扩增(例如pcr)1786以提供双链扩增产物1788,所述双链扩增产物包含核酸条形码分子1718b、原始rna分子的序列或与其对应的cdna、流动池衔接子序列1798(例如p7序列)和另外序列1790,所述另外序列可以包含测序引物或其部分(例如r2序列)1796、样品标志序列1794和流动池衔接子序列(例如p5序列)1792。条形码化cdna分子还可以或可替代地进行片段化、末端修复、da加尾、一个或多个衔接子序列的连接和/或核酸扩增。
191.在另一个实例中,提供了包含染色质和一种或多种rna分子的细胞、细胞珠粒或细胞核。可以处理细胞、细胞珠粒或细胞核中的染色质以提供源自所述染色质的第一模板核酸片段(例如,如本文所述的标签化片段)。染色质可以在本体溶液中进行处理。可以处理rna分子以提供源自rna分子的第二模板核酸片段(例如,如本文所述)。rna分子可以在分区内进行处理。第一模板核酸片段的构型可以至少部分地取决于用于产生第一模板核酸片段的转座酶-核酸复合物的结构。例如,转座酶-核酸复合物,例如图9所示的转座酶-核酸复合
物可用于制备第一模板核酸片段。第一模板核酸片段可以是至少部分双链的。第一模板核酸片段可以包含双链区,所述双链区包含细胞、细胞珠粒或细胞核的染色质的序列。双链区的第一链的第一末端可以连接至第一转座子末端序列(例如嵌合末端序列),所述第一转座子末端序列可以连接至第一测序引物或其部分。双链区的第二链的第一末端(所述末端与第一链的第一末端相对)可以连接至第二转座子末端序列(例如嵌合末端序列),所述第二转座子末端序列可以连接至第二测序引物或其部分。第二转座子末端序列可以与第一转座子末端序列相同或不同。第一测序引物或其部分可以与第二测序引物或其部分相同或不同。在一些情况下,所述第一测序引物或其部分可以是r1序列或其部分,并且第二测序引物或其部分可以是r2序列或其部分。第一转座子末端序列可以与第一互补序列(例如嵌合末端反向互补序列)杂交,所述第一互补序列可以不连接至第一模板核酸片段的双链区的第二链的第二末端。类似地,第二转座子末端序列可以与第二互补序列(例如嵌合末端反向互补序列)杂交,所述第二互补序列可以不连接至第一模板核酸片段的双链区的第一链的第二末端。换言之,第一模板核酸片段可以包含一个或多个缺口。在一些情况下,一个或多个缺口的长度可以各自为大约9bp。例如,一个或多个缺口的长度可以是至少约1、2、3、4、5、6、7、8、9、10或更多bp。例如,一个或多个缺口的长度可以是至多约10、9、8、7、6、5、4、3、2或1bp。第二模板核酸片段(例如另外模板核酸片段)可以包含细胞、细胞珠粒或细胞核的rna分子的序列和与引物分子(例如捕获核酸分子)杂交的序列。例如,第二模板核酸片段可以包含细胞、细胞珠粒或细胞核的rna分子的序列和与引物分子的多聚t序列杂交的多聚a序列。引物分子还可以包含另外引物序列。
192.包含第一模板核酸片段(例如标签化片段)的细胞、细胞珠粒或细胞核可以与一种或多种试剂共同分配到多个分区中的分区中(例如,如本文所述)。分区可以是例如液滴或孔。分区可以包含一个或多个珠粒(例如,如本文所述)。一个或多个珠粒中的一个珠粒(例如凝胶珠粒)可以包含第一多个核酸条形码分子。第一多个核酸条形码分子中的核酸条形码分子可以包含流动池衔接子序列(例如p5序列)、条形码序列和悬突序列。分区还可以包含夹板序列,所述夹板序列包含与悬突序列互补的序列和可以与第一模板核酸片段的序列互补的测序引物或其部分。一个或多个珠粒中的一个珠粒还可以包含第二多个核酸条形码分子。第二多个核酸条形码分子中的核酸条形码分子可以包含流动池衔接子序列(例如p5序列)、条形码序列、测序引物或其部分(例如r1序列或其部分,或互补序列)、umi序列和捕获序列(例如多聚g序列或多聚dt序列)。在一些情况下,第一多个核酸条形码分子和第二多个核酸条形码分子可以偶联至同一珠粒,并且分区可以包含单个珠粒。
193.在分区内,可以处理rna分子以提供第二模板核酸片段(例如,如本文所述)。
194.在分区内,细胞、细胞珠粒或细胞核可以被溶解或透化以接近其中的第一模板核酸片段和/或第二模板核酸片段(例如,如本文所述)。第二模板核酸片段可以在细胞、细胞珠粒或细胞核被溶解或透化之后产生。
195.第一模板核酸片段和第二模板核酸片段可以在分区内进行处理。在分区内,对应于细胞、细胞珠粒或细胞核的染色质的第一模板核酸片段的测序引物或其部分可以与夹板序列中的测序引物或其部分的互补序列杂交。夹板序列还可以与第一多个核酸条形码分子中的核酸条形码分子的悬突序列杂交。然后可以将核酸条形码分子的悬突序列连接(例如,使用连接酶)至第一模板核酸片段的测序引物或其部分。所得部分双链核酸分子可以包含
条形码序列以及一个或多个缺口。
196.在分区内,源自细胞、细胞珠粒或细胞核的rna分子的第二模板核酸片段可以被逆转录(例如,使用逆转录酶)以提供cdna链。逆转录过程可以将序列附加到包含rna链和cdna链的所得双链核酸分子的链的末端,例如多聚c序列。第二多个核酸条形码分子中的核酸条形码分子的捕获序列可以与双链核酸分子的附加序列(例如多聚c序列)杂交,并且可以发生模板转换过程以提供第二双链核酸分子。第二多个核酸条形码分子中的核酸条形码分子的序列可以被认为是模板转换寡核苷酸。模板转换过程可以产生条形码化cdna分子。条形码化cdna分子可以包含第二多个核酸条形码分子中的核酸条形码分子的测序引物或其部分或其互补序列;第二多个核酸条形码分子中的核酸条形码分子的条形码序列或其互补序列;第二多个核酸条形码分子中的核酸条形码分子的umi序列或其互补序列;第二多个核酸条形码分子中的核酸条形码分子的捕获序列或其互补序列;多聚(c)或多聚(g)序列;对应于细胞、细胞珠粒或细胞核的rna分子的序列或其互补序列;以及捕获核酸分子的序列或其互补序列。
197.对应于细胞、细胞珠粒或细胞核的染色质的部分双链核酸分子和对应于多个分区中的分区内所包含的细胞、细胞珠粒或细胞核的rna分子的条形码化cdna分子可以从所述分区中回收。例如,可以汇集多个分区的内容物以在本体溶液中提供部分双链核酸分子和条形码化cdna分子。
198.在分区之外,对应于染色质的部分双链核酸分子中的缺口可以通过缺口填充延伸过程(例如,使用dna聚合酶或逆转录酶)来填充。dna聚合酶可能缺乏链置换活性。可以使所得的缺口填充双链核酸分子变性以提供单链,所述单链可以经受足以进行一种或多种核酸扩增反应(例如pcr)的条件以产生对应于细胞、细胞珠粒或细胞核的染色质的扩增产物。核酸扩增过程可以并入一个或多个另外序列,例如一个或多个另外流动池衔接子序列。
199.在分区之外,对应于rna分子的条形码化cdna分子可以经受片段化、末端修复、da加尾过程、标签化或它们的组合。然后可以将另外引物序列(例如测序引物或其部分,例如r2序列)连接至所得分子。然后可以进行核酸扩增反应(例如pcr)以产生一种或多种对应于rna分子的扩增产物。核酸扩增过程可以并入一个或多个另外序列,例如一个或多个另外流动池衔接子序列。
200.图18示出了对应于前一实例的示例性示意图。图1800示出了对应于处理来自细胞、细胞珠粒或细胞核的染色质的工作流程,并且图1850示出了对应于处理来自细胞、细胞珠粒或细胞核的mrna分子的工作流程。
201.如图1800所示,在本体溶液中,对细胞、细胞珠粒或细胞核内所包含的染色质进行处理(例如,如本文所述)以提供模板核酸片段(例如标签化片段)1804,所述模板核酸片段包含插入序列1808(例如开放染色质的区域)及其互补序列、转座子末端序列1806及其互补序列、测序引物或其部分1802(例如r1序列)、测序引物或其部分1810(例如r2序列)和缺口1807。模板核酸片段1804然后可以分配在分区内(例如,如本文所述的液滴或孔)。在分区内,包含模板核酸片段1804的细胞、细胞珠粒或细胞核可以被溶解、透化或以其他方式进行处理以接近其中的模板核酸片段1804(和一种或多种rna分子)。分区可以包含夹板序列1812,所述夹板序列可以包含与测序引物或其部分1802互补的第一序列1802’和第二序列1824。序列1824可以包含封闭基团(例如3’封闭基团),所述封闭基团可以防止通过逆转录
而延伸。分区可以包括与核酸条形码分子1818a和1812b偶联的珠粒(例如凝胶珠粒)1816。核酸条形码分子1818a可以包含流动池衔接子序列1820a(例如p5序列)、条形码序列1822a和与夹板序列的序列1824互补的悬突序列1824’。序列1824可以与序列1824’杂交以提供包含核酸条形码分子1818a和模板核酸片段1804的序列的部分双链核酸分子。核酸条形码分子1818a的序列1824’可以连接(例如,使用连接酶)1826至模板核酸片段1804的序列1802。在一些情况下,1804可以使用合适的激酶(例如多核苷酸激酶(pnk),例如t4 pnk)磷酸化。在一些情况下,pnk和atp可以在标签化反应(例如atac)中和/或在分配细胞、细胞珠粒或细胞核或它们中的多者之前大量添加。可以将15u的pnk和1mm的atp掺杂至标签化反应中。例如,可以将少于95u的pnk掺杂至标签化反应中。然后可以在本体溶液中回收分区的内容物(例如,可以使液滴破坏)以在本体溶液中提供部分双链核酸分子,所述部分双链核酸分子包含附接至模板核酸片段1804的核酸条形码分子1818a。在本体溶液中,缺口1807可以通过缺口填充延伸过程(例如,使用dna聚合酶)来填充1828以提供双链核酸分子。此分子可以进行扩增(例如pcr)1830以提供双链扩增产物1832,所述双链扩增产物包含核酸条形码分子1818a、原始染色质分子的序列和任选的可以是流动池衔接子序列(例如p7序列)的另外序列1834。可以在批量处理之前填充分区中的缺口。
202.与图1800的染色质工作流程并行,可以处理源自同一细胞、细胞珠粒或细胞核的rna分子。如图1850所示,包含rna序列1860和多聚a序列1862的rna分子1858可以与包含多聚t序列1854和另外引物序列1856的引物分子1852接触1864。然后可以使用具有末端转移酶活性的逆转录酶将rna分子1858从多聚t序列1854逆转录1876出来,所述逆转录酶可以将序列1870附加到包含cdna序列1868的所得cdna分子上。序列1870可以是多聚c序列。珠粒(例如凝胶珠粒)1816(例如,在图1800中描述的相同珠粒)可以包括在分区内并且可以与核酸条形码分子1818b偶联。核酸条形码分子1818b可以包含流动池衔接子序列1820b(例如p5序列)、条形码序列1822b、umi序列1872和与序列1870互补的序列1874(例如多聚g序列)。在一些情况下,核酸条形码分子1818b可以包含测序引物序列1820b(例如r1序列或部分r1序列)、条形码序列1822b、umi序列1872和与序列1870互补的序列1874(例如多聚g序列)。核酸条形码分子1818b可用于执行模板转换1878,所述过程也可以导致条形码化cdna分子的产生。然后可以在本体溶液中回收分区的内容物(例如,可以使液滴破坏)以在本体溶液中提供条形码化cdna分子。条形码化cdna分子可以进行扩增(例如pcr)1880以提供双链扩增产物1884,所述双链扩增产物包含核酸条形码分子的序列1818b、原始rna分子或与其对应的cdna、流动池衔接子序列1886,以及任选的另外序列1888,所述另外序列可以包含测序引物或其部分(例如r2序列)1890、样品标志序列1892和流动池衔接子序列(例如p7序列)1894。条形码化cdna分子还可以或可替代地进行片段化、末端修复、da加尾、一个或多个衔接子序列的连接和/或核酸扩增。
203.图19示出了对应于前一实例的示例性示意图。图1900示出了对应于处理来自细胞、细胞珠粒或细胞核的染色质的工作流程,并且图1950示出了对应于处理来自细胞、细胞珠粒或细胞核的mrna分子的工作流程。
204.如图1900所示,在本体溶液中,对细胞、细胞珠粒或细胞核内所包含的染色质进行处理(例如,如本文所述)以提供模板核酸片段(例如标签化片段)1904,所述模板核酸片段包含插入序列1908(例如开放染色质的区域)及其互补序列、转座子末端序列1906及其互补
序列、测序引物或其部分1902(例如r1序列)、测序引物或其部分1910(例如r2序列)和缺口1907。模板核酸片段1904然后可以分配在分区内(例如,如本文所述的液滴或孔)。在分区内,包含模板核酸片段1904的细胞、细胞珠粒或细胞核可以被溶解、透化或以其他方式进行处理以接近其中的模板核酸片段1904(和一种或多种rna分子)。分区可以包含夹板序列1912,所述夹板序列可以包含与测序引物或其部分1902互补的第一序列1902’和第二序列1924。序列1924可以包含封闭基团(例如3’封闭基团),所述封闭基团可以防止通过逆转录而延伸。分区可以包括与核酸条形码分子1918a和1918b偶联的珠粒(例如凝胶珠粒)1916。核酸条形码分子1918a可以包含流动池衔接子序列1920a(例如p5序列)、条形码序列1922a和与夹板序列的序列1924互补的悬突序列1924’。序列1924可以与序列1924’杂交以提供包含核酸条形码分子1918a和模板核酸片段1904的序列的部分双链核酸分子。核酸条形码分子1918a的序列1924’可以连接(例如,使用连接酶)1926至模板核酸片段1904的序列1902。在一些情况下,1904可以使用合适的激酶(例如多核苷酸激酶(pnk),例如t4 pnk)磷酸化。在一些情况下,pnk和atp可以在标签化反应(例如atac)中和/或在分配细胞、细胞珠粒或细胞核或它们中的多者之前大量添加。可以将15u的pnk和1mm的atp掺杂至标签化反应中。例如,可以将少于95u的pnk掺杂至标签化反应中。然后可以在本体溶液中回收分区的内容物(例如,可以使液滴破坏)以在本体溶液中提供部分双链核酸分子,所述部分双链核酸分子包含附接至模板核酸片段1904的核酸条形码分子1918a。在本体溶液中,缺口1907可以通过缺口填充延伸过程(例如,使用dna聚合酶)来填充1928以提供双链核酸分子。此分子可以进行扩增(例如pcr)1930以提供双链扩增产物1932,所述双链扩增产物包含核酸条形码分子1918a、原始染色质分子的序列和任选的可以是流动池衔接子序列(例如p7序列)的另外序列1934。可以在批量处理之前填充分区中的缺口。
205.与图1900的染色质工作流程并行,可以处理源自同一细胞、细胞珠粒或细胞核的rna分子。如图1950所示,包含rna序列1960和多聚a序列1962的rna分子1958和珠粒(例如凝胶珠粒)1916可以提供在分区内。珠粒(例如凝胶珠粒)1916(例如,在图1900中描述的相同珠粒)可以包括在分区内并且可以与核酸条形码分子1918b偶联。核酸条形码分子1918b可以包含流动池衔接子序列1968(例如p5序列)、条形码序列1922b(例如与条形码序列1922a相同的条形码序列)、umi序列1966和与多聚a序列1962互补的多聚t序列1964。在一些情况下,核酸条形码分子1918b可以包含测序引物序列1968(例如r1序列或部分r1序列)、条形码序列1922b(例如与条形码序列1922a相同的条形码序列)、umi序列1966和与多聚a序列1962互补的多聚t序列1964。多聚t序列1964可以与rna分子1958的多聚a序列1962杂交。rna分子1958可以从多聚t序列1964逆转录1970出来以提供包含cdna序列1972的cdna分子。逆转录过程可以使用具有末端转移酶活性的逆转录酶,所述逆转录酶可以将序列1974附加到包含cdna序列1972的所得cdna分子上。序列1974可以是多聚c序列。包含引物序列1980和与序列1974互补的序列(例如多聚g序列)的模板转换寡核苷酸1978可以与cdna分子杂交。然后可以在本体溶液中回收分区的内容物(例如,可以使液滴破坏)以在本体溶液中提供cdna分子。cdna分子可以进行扩增(例如pcr)1984。可以进行另外扩增(例如pcr)1986以提供双链扩增产物1988,所述双链扩增产物包含核酸条形码分子1918b、原始rna分子的序列或与其对应的cdna、流动池衔接子序列1998(例如p7序列)和另外序列1990,所述另外序列可以包含测序引物或其部分(例如r2序列)1996、样品标志序列1994和流动池衔接子序列(例如p5
序列)1992。条形码化cdna分子还可以或可替代地进行片段化、末端修复、da加尾、一个或多个衔接子序列的连接和/或核酸扩增。
206.在另一个方面,本公开提供了一种用于处理生物样品(例如核酸样品)的方法,所述方法可以包括在分区内进行顺序转录和逆转录过程。所述方法可以包括提供包含源自核酸样品的核酸分子(例如dna分子)的多个分区中的分区(例如液滴或孔)。核酸分子可以进行转录(例如,使用转录酶)以提供rna分子。rna分子然后可以在分区内进行逆转录(例如,使用逆转录酶)以产生互补dna(cdna)分子。cdna分子可以在分区内进行进一步处理以提供cdna分子的衍生物。可以从分区中回收cdna分子或其衍生物(例如,通过汇集多个分区的内容物)。分区可以是多个孔中的一个孔。可替代地,分区可以是多个液滴中的一个液滴。
207.根据本文提供的方法处理的核酸分子(例如dna分子)可以源自细胞、细胞珠粒或细胞核。在一些情况下,核酸分子可以包含在细胞、细胞珠粒或细胞核内。核酸分子可以是染色质。包含核酸分子的细胞、细胞珠粒或细胞核可以包括在分区内。例如,细胞、细胞珠粒或细胞核可以与一种或多种试剂(例如,如本文所述)共同分配到分区(例如液滴或孔)中。细胞、细胞珠粒或细胞核可以被溶解或透化(例如,在分区内)以接近其中的核酸分子(例如,如本文所述)。
208.根据本文提供的方法处理的核酸分子可以是dna分子,例如染色质。在一些情况下,所述方法还可以包括用转座酶(例如,包括在转座酶-核酸复合物中)处理核酸样品的开放染色质结构以提供核酸分子。例如,可以使核酸分子(例如,在细胞、细胞珠粒或细胞核内)与转座酶-核酸复合物(例如,如本文所述)接触。在这样的过程中使用的转座酶可以是例如tn5转座酶。转座酶-核酸复合物可以具有例如图9或图10的结构的结构。可替代地,转座酶-核酸复合物可以包含一个或多个转座子末端寡核苷酸分子,所述转座子末端寡核苷酸分子包含发夹分子。这种转座酶-核酸复合物的一个实例示于图11中。
209.使用包含一个或多个发夹分子的转座酶-核酸复合物处理的核酸分子可以是包含双链区的标签化片段,所述双链区包含对应于它所起源或来源的细胞、细胞珠粒或细胞核的核酸分子(例如染色质)的序列,以及附加到双链区的任一端上的一个或多个发夹分子。例如,双链区可以在一端包含第一发夹分子并且在第二端包含第二发夹分子。通常,发夹分子的仅一端可以附接至双链区,使得标签化片段在任一端包含缺口。例如,发夹分子可以附接至双链区的3’端。发夹分子可以包含启动子序列(例如t7启动子序列)和/或umi序列。
210.在分区内,核酸分子(例如标签化片段)可以用逆转录酶进行缺口填充过程。逆转录酶可以是突变型逆转录酶,例如但不限于莫洛尼鼠白血病病毒(mmlv)逆转录酶。在一个方面,逆转录酶是突变型mmlv逆转录酶,例如但不限于酶“42b”(参见美国专利公布第20180312822号)。当以例如小于1纳升(nl)的反应体积制备时,由于单细胞的细胞溶解物中存在的一种或多种未知组分,酶42b可以展现出降低对来自单细胞的mrna的逆转录的抑制。与可商购获得的突变型mmlv rt酶(ca-mmlv)相比,酶42b可以显示出改进的逆转录酶活性。这种过程可以产生双链核酸分子,所述双链核酸分子包含对应于其所源自的细胞、细胞珠粒或细胞核的核酸分子(例如染色质)的双链区、在所述双链区的任一端的发夹分子的序列以及与所述发夹分子的序列互补的序列。双链核酸分子然后可以用t7聚合酶进行转录,所述过程开始于发夹分子的t7启动子序列的末端。两条链都可以这种方式转录以提供两条核酸链,每条核酸链均包含t7启动子序列及其互补序列;一个或多个转座子末端序列,及其一
个或多个互补序列;以及细胞、细胞珠粒或细胞核的原始核酸分子的序列。所述链还可以包含一个或多个间隔区、umi或其他序列(例如,来自发夹分子)。链然后可以进行自引发过程,其中发夹分子的转座子末端序列及其互补序列彼此杂交以在所述链的末端再生发夹分子。所述发夹分子可以充当逆转录的引发位点。然后可以进行逆转录酶过程(例如,使用逆转录酶)。在此过程之前、期间或之后,可以将序列附加到分子的末端,所述序列可以是多聚c序列。包含与附加序列(例如多聚g序列)互补的序列的模板转换寡核苷酸可以与所述附加序列杂交。模板转换寡核苷酸可以包含umi序列(例如,可以标志进行模板转换的转录物的第二umi序列)、条形码序列和/或引发序列例如测序引物序列或其部分(例如r1或r2序列,或其部分)。模板转换寡核苷酸可以附接至包含在分区内的珠粒(例如凝胶珠粒)。例如,模板转换寡核苷酸可以是附接至珠粒的多个核酸条形码分子中的核酸条形码分子(例如,如本文所述)。所得部分双链核酸分子可以包含发夹部分;对应于细胞、细胞珠粒或细胞核的原始核酸分子的序列;和模板转换寡核苷酸的序列,包括条形码序列(参见,例如,图20)。
211.部分双链核酸分子可以从分区(例如液滴或孔)中释放。从分区中释放材料可以包括使液滴破坏或破碎。可以将多个分区中的多个分区的内容汇集在一起以提供用于进一步处理的本体溶液。多个分区中的分区的核酸分子(例如部分双链核酸分子)可以各自差异地条形码化,使得每个这样的分区的核酸分子包含不同的条形码序列。
212.在分区之外,可以使部分双链核酸分子部分变性以提供单链分子(例如单链cdna分子)。rna酶处理可用于除去发夹分子以及部分双链核酸分子的较短链(例如rna序列)。剩余的单链分子可以包括包含条形码序列和任选的umi序列的模板转换寡核苷酸。可以提供包含与模板转换寡核苷酸的引发序列互补的引发序列的引物分子并且可以与模板转换寡核苷酸的引发序列杂交。引物分子的引发序列可以是5’封闭的引发序列。具有da加尾活性的聚合酶(例如,具有5
’→3’
聚合酶活性的klenow片段,例如缺乏核酸外切酶活性的外切klenow片段)可用于产生第二核酸链。所得的第二链可以是da加尾的。第一链也可以是da加尾的。然而,如果在前面的过程中使用了5’封闭引发序列,则附加到第一链上的da尾可能不能用作另一个部分的杂交位点。相反,包含测序引物(例如r1序列或其互补序列)和流动池衔接子序列(例如p5序列或其互补序列)的引发序列可以与双链核酸分子的互补序列杂交。在双链核酸分子的另一端,附加到第二链末端的da部分可以充当在末端包含dt部分的引发序列、测序引物(例如r2序列或其互补序列)和流动池衔接子序列(例如p7序列或其互补序列)的杂交位点。然后可以使双链核酸分子经受足以进行一种或多种核酸扩增反应(例如pcr)的条件,以提供对应于细胞、细胞珠粒或细胞核的原始核酸分子的扩增产物。扩增产物可以在任一端包含流动池衔接子序列(例如p5和p7序列)以促进测序(例如,如本文所述)。
213.本文提供的方法可以克服在分区内进行逆转录的某些挑战。例如,逆转录酶可以具有依赖于dna的dna聚合酶活性和/或末端转移酶活性。后者可以导致在某些反应条件下产生可变的悬突。在本文提供的方法中,可以为每个插入位点提供t7启动子,从而避免可能通过r1-r1和r2-r2相互作用遇到的损失。此外,mrna和染色质来源的片段都可以使用相同的生物化学(例如rt模板转换)进行条形码化。对核酸分子的这两条链进行线性扩增可以提供链意识并且为例如atac-seq过程引入新的维度。此外,这种方法可以实现分区内转座酶来源的核酸片段的等温线性扩增。值得注意的是,这种方法可以与本文别处所述的任何rna工作流程相结合。
214.图20示出了对应于前一实例的工作流程2000。工作流程2000可以与rna工作流程并行执行,例如图12至图19中任一者的rna工作流程。多个珠粒可以包括在分区内,每个珠粒包含被配置用于分析dna或rna分子的核酸条形码分子。可替代地,包含被配置用于分析dna和rna分子的核酸条形码分子(例如,如本文所述)的单个珠粒(例如凝胶珠粒)可以包括在分区内。在一些实施方案中,单个珠粒(例如,在单个分区中)可以包含用于rna和dna分析的多个相同的核酸条形码分子。单个珠粒(例如,在单个分区内)可以包含用于dna分析的第一多个核酸条形码分子和用于rna分子的第二多个核酸条形码分子,其中所述第一多个核酸条形码分子和第二多个核酸条形码分子包含共有条形码序列。
215.可以制备模板核酸片段(例如标签化片段)2002(例如,使用转座酶-核酸复合物,例如图11所示的转座酶-核酸复合物)并提供在分区中(如本文所述)。模板核酸片段2002可以包含发夹部分2003和2004以及靶序列2005和2006。模板核酸片段2002还包含缺口2007。可以使用逆转录酶(例如42b酶)填充缺口2007,所述过程可能导致产生双链核酸分子,所述双链核酸分子包含对应于细胞、细胞珠粒或细胞核的原始核酸分子(例如染色质)的双链区,所述双链区包含序列2005和2006以及发夹分子2003和2004的序列。双链核酸分子可以包含转座子末端序列2008、启动子(例如t7启动子)序列2010和umi序列2012。双链核酸分子然后可以用t7聚合酶进行转录,所述过程开始于发夹分子的t7启动子序列的末端。两条链都可以这种方式转录以提供两条核酸链。图20示出了一条这样的链,其包含t7启动子序列2010及其互补序列;一个或多个转座子末端序列2008及其一个或多个互补序列;umi序列2012和umi序列的互补序列;以及对应于细胞、细胞珠粒或细胞核的原始核酸分子的序列2006的rna序列2006’。所述链然后可以进行自引发过程,其中发夹分子2004的转座子末端序列及其互补序列彼此杂交以在所述链的末端再生发夹分子。再生的发夹分子2004可以充当逆转录的引发位点。然后可以进行逆转录和模板转换(例如,使用逆转录酶)。逆转录过程可以将序列2014(例如多聚c序列)附加到包含cdna序列2026以及分别与序列2012和2008互补的序列2012’和2008’的所得cdna分子。模板转换过程可以包括使用与包括在分区内的珠粒(例如凝胶珠粒)2016偶联的模板转换寡核苷酸。珠粒(例如凝胶珠粒)2016可以与核酸条形码分子2018偶联,所述核酸条形码分子是包含测序引物或其部分2020、条形码序列2022、umi序列2024和与序列2014(例如多聚g序列)互补的序列2014’的模板转换寡核苷酸。所得cdna分子可以包含含有核酸条形码分子2018和rna序列2006’的第一链和含有cdna序列2026、附加序列2014以及分别与序列2020、2022和2024互补的序列2020’、2022’和2024’的第二链。
216.cdna分子可以从分区(例如液滴或孔)中释放。从分区中释放材料可以包括使液滴破坏或破碎。可以将多个分区中的多个分区的内容汇集在一起以提供用于进一步处理的本体溶液。在分区之外,可以用rna酶处理cdna分子以除去发夹分子以及部分双链核酸分子的较短链(例如rna序列)。剩余的单链分子可以包括序列2020’、2022’、2024’、2014、2012’、2008’和2026。引物分子2028然后可以与序列2020’杂交。引物分子2028可以是5’封闭的引发序列。具有da加尾活性的聚合酶(例如,具有5
’→3’
聚合酶活性的klenow片段,例如缺乏外切核酸酶活性的外切klenow片段)可用于产生包含与cdna序列2026互补的序列2026’的第二核酸链。所得的第二链可以是da加尾的。第一链也可以在序列2020'的末端进行da加尾。然而,如果在前面的过程中使用了5’封闭引发序列,则附加到第一链上的da尾可能不能
用作另一个部分的杂交位点。包含dt部分、测序引物(例如r2序列或其互补序列)2032和流动池衔接子序列(例如p7序列或其互补序列)2034的引发序列2030可以与双链核酸分子的da部分杂交。包含测序引物(例如r1序列或其互补序列)2038和流动池衔接子序列(例如p5序列或其互补序列)2040的引发序列2036可以与双链核酸分子的序列2028杂交。然后可以扩增双链核酸分子以提供经扩增的产物2042,所述扩增产物可以经受进一步处理,例如核酸测序。
217.图21提供了用于处理核酸分子(例如,在细胞、细胞珠粒或细胞核内包含的核酸分子)的工作流程2100的概览。将核酸分子(例如dna分子,例如染色质)标签化(例如,如本文所述)以产生标签化片段。标签化片段然后在分区内进行转录、逆转录和条形码化(例如,如本文所述)。所得产物从分区中释放出来并经受两个过程中的一个,第一个过程提供atac文库,并且第二个过程提供基因表达文库。第一个过程可能涉及rna酶处理以除去rna,并提供cdna,测序引物的da加尾和连接,以及pcr。第二个过程可能涉及cdna扩增;测序引物的片段化、da加尾和连接;以及pcr。
218.本公开还提供了一种使用逆转录酶填充过程与条形码化过程结合来处理细胞、细胞珠粒或细胞核的核酸分子的方法。核酸分子(例如dna分子)可以源自细胞、细胞珠粒或细胞核。在一些情况下,核酸分子可以包含在细胞、细胞珠粒或细胞核内。核酸分子可以是染色质。包含核酸分子的细胞、细胞珠粒或细胞核可以包括在分区内。例如,细胞、细胞珠粒或细胞核可以与一种或多种试剂(例如,如本文所述)共同分配到分区(例如液滴或孔)中。细胞、细胞珠粒或细胞核可以被溶解或透化(例如,在分区内)以接近其中的核酸分子(例如,如本文所述)。
219.根据本文提供的方法处理的核酸分子可以是dna分子,例如染色质。在一些情况下,所述方法还可以包括用转座酶(例如,包括在转座酶-核酸复合物中)处理核酸样品的开放染色质结构以提供核酸分子。例如,可以使核酸分子(例如,在细胞、细胞珠粒或细胞核内)与转座酶-核酸复合物(例如,如本文所述)接触。在这样的过程中使用的转座酶可以是例如tn5转座酶。转座酶-核酸复合物可以具有例如图9、图10或图11的结构的结构。在产生标签化片段(例如,如本文所述)之后,转座酶-核酸复合物的转座酶可以留下或被除去(例如被置换,例如,通过酶置换)。可替代地,转座酶可以保留在适当位置。标签化片段可以包含对应于细胞、细胞珠粒或细胞核的原始核酸分子的序列;转座子末端序列和与其互补的序列;以及一个或多个测序引物或其部分。包含与标签化片段的测序引物或其部分互补的序列的夹板序列可以与测序引物或其部分杂交。夹板序列可以连接至标签化片段的转座子末端序列或其互补序列(例如,使用连接酶)。在夹板序列杂交和/或连接之前或之后,可以将标签化片段分配到多个分区中的分区(例如孔的液滴)中。标签化片段可以与一种或多种试剂共同分配。标签化片段可以包含在细胞、细胞珠粒或细胞核内,所述细胞、细胞珠粒或细胞核可以被溶解或透化以接近其中的标签化片段(例如,如本文所述)。夹板序列的序列然后可以与核酸条形码分子(例如,如本文所述的偶联至珠粒的核酸条形码分子)杂交。珠粒(例如凝胶珠粒)可以包含多个核酸条形码分子,其中所述多个核酸条形码分子中的核酸条形码分子可以包含例如流动池衔接子序列、条形码序列和umi序列。核酸条形码分子还可以包含与夹板序列的序列具有序列互补性的悬突序列。悬突序列可以与夹板序列的序列杂交。标签化片段中保留的转座酶可以在这些过程中阻止缺口填充。夹板序列然后可以在分
区内扩增(例如,使用逆转录酶)。
220.在条形码/模板转换和延伸(例如逆转录)过程之后,多个分区中的所述分区的内容物可以从所述分区中释放(例如,如本文所述)。在释放分区的内容物之前或之后,可以将核酸条形码分子连接至经处理的标签化片段的测序引物。在分区之外,核酸条形码分子可以与模板核酸片段的测序引物或其部分杂交。如果转座酶保留在标签化片段中,则转座酶可以留下经处理的标签化片段(例如,通过链置换聚合酶)并且可以填充剩余的缺口以提供双链核酸分子。可替代地,可以如本文别处所述填充缺口。然后可以使双链核酸分子经受核酸扩增过程(例如,如本文所述的pcr)。扩增可以包括并入一个或多个另外序列,例如一个或多个流动池衔接子序列(例如p7序列)。
221.图22示出了对应于前一实例的示例性示意图。图2200示出了对应于处理来自细胞、细胞珠粒或细胞核的染色质的工作流程,并且图2250示出了对应于处理来自细胞、细胞珠粒或细胞核的mrna分子的工作流程。多个珠粒(例如凝胶珠粒)可以包括在分区内,每个珠粒包含被配置用于分析dna或rna分子的核酸条形码分子。可替代地,包含被配置用于分析dna和rna分子的核酸条形码分子(例如,如本文所述)的单个珠粒(例如凝胶珠粒)可以包括在给定分区内。
222.如图2200所示,在本体溶液中,对细胞、细胞珠粒或细胞核内所包含的染色质进行处理(例如,如本文所述)以提供模板核酸片段(例如标签化片段)2204,所述模板核酸片段包含插入序列2208(例如开放染色质的区域)及其互补序列、转座子末端序列2206及其互补序列、测序引物或其部分2202(例如r2序列)、测序引物或其部分2210(例如r1序列)和缺口2207。包含模板核酸片段2204的细胞、细胞珠粒或细胞核可以被溶解、透化或以其他方式进行处理以接近其中的模板核酸片段2204(和一种或多种rna分子)。模板核酸片段2204可以与夹板序列2212接触,所述夹板序列可以包含与测序引物或其部分2202互补的第一序列2202’,和第二序列2224。序列2224可以包含封闭基团(例如3’封闭基团),所述封闭基团可以防止通过逆转录而延伸。序列2202’可以与模板核酸片段2204的序列2202杂交2214以提供包含夹板序列2212和模板核酸片段2204的部分双链核酸分子。序列2202’可以连接2226至模板核酸片段2204的转座子末端序列2206的互补序列(例如,使用连接酶)。附接至夹板序列2212的模板核酸片段2204然后可以分配在多个分区内的一个分区(例如液滴或孔)内(例如,如本文所述)。分区可以包括与核酸条形码分子2218a和2218b偶联的珠粒(例如凝胶珠粒)2216。核酸条形码分子2218a可以包含流动池衔接子序列2220a(例如p5序列)、条形码序列2222a和与夹板序列2212的序列2224互补的悬突序列2224’。序列2224可以与序列2224’杂交2228。夹板序列2212然后可以延伸2230(例如,使用逆转录酶或dna聚合酶)以提供与核酸条形码分子2218a的序列2220a和2222a互补的序列2220a’和2222a’。可替代地,序列2224可以与序列2224’杂交以提供部分双链核酸分子,并且核酸条形码分子2218a可以连接(例如,使用连接酶)至模板核酸片段2204的序列2202。然后可以在本体溶液中回收分区的内容物(例如,可以使液滴破坏)以在本体溶液中提供部分双链核酸分子,所述部分双链核酸分子包含附接至夹板序列2212和模板核酸片段2204的核酸条形码分子2218a。核酸条形码分子2218a的序列2224’可以连接(例如,使用连接酶)2232至模板核酸片段2204的序列2202。在本体溶液中,缺口2207可以通过缺口填充延伸过程(例如,使用dna聚合酶)来填充2234以提供双链核酸分子。此分子还可以进行扩增(例如pcr)以提供双链扩增产物2236,所
述双链扩增产物包含核酸条形码分子2218a、原始染色质分子的序列和任选的可以是流动池衔接子序列(例如p7序列)的另外序列2238。可以在批量处理之前填充分区中的缺口。
223.与图2200的染色质工作流程并行,可以处理源自同一细胞、细胞珠粒或细胞核的rna分子。如图2250所示,包含rna序列2260和多聚a序列2262的rna分子2258可以与包含多聚t序列2254和另外引物序列2256的引物分子2252接触2264。然后可以使用具有末端转移酶活性的逆转录酶将rna分子2258从多聚t序列2254逆转录2276出来,所述逆转录酶可以将序列2270附加到包含cdna序列2268的所得cdna分子上。序列2270可以是多聚c序列。珠粒(例如凝胶珠粒)2216(例如,在图2200中描述的相同珠粒)可以包括在分区内并且可以与核酸条形码分子2218b偶联。核酸条形码分子2218b可以包含流动池衔接子序列2220b(例如p5序列)、条形码序列2222b、umi序列2272和与序列2270互补的序列2274(例如多聚g序列)。在一些情况下,核酸条形码分子2218b可以包含测序引物序列2220b(例如r1序列或部分r1序列)、条形码序列2222b、umi序列2272和与序列2270互补的序列2274(例如多聚g序列)。核酸条形码分子2218b可用于执行模板转换2278,所述过程也可以导致条形码化cdna分子的产生。然后可以在本体溶液中回收分区的内容物(例如,可以使液滴破坏)以在本体溶液中提供条形码化cdna分子。条形码化cdna分子可以进行扩增(例如pcr)2280以提供双链扩增产物2284,所述双链扩增产物包含核酸条形码分子的序列2218b、原始rna分子或与其对应的cdna、流动池衔接子序列2286,以及任选的另外序列2288,所述另外序列可以包含测序引物或其部分(例如r2序列)2290、样品标志序列2292和流动池衔接子序列(例如p7序列)2294。条形码化cdna分子还可以或可替代地进行片段化、末端修复、da加尾、一个或多个衔接子序列的连接和/或核酸扩增。
224.图23示出了对应于前一实例的另一示例性示意图。图2300示出了对应于处理来自细胞、细胞珠粒或细胞核的染色质的工作流程,并且图2350示出了对应于处理来自细胞、细胞珠粒或细胞核的mrna分子的工作流程。多个珠粒(例如凝胶珠粒)可以包括在分区内,每个珠粒包含被配置用于分析dna或rna分子的核酸条形码分子。可替代地,包含被配置用于分析dna和rna分子的核酸条形码分子(例如,如本文所述)的单个珠粒(例如凝胶珠粒)可以包括在给定分区内。
225.如图2300所示,在本体溶液中,对细胞、细胞珠粒或细胞核内所包含的染色质进行处理(例如,如本文所述)以提供模板核酸片段(例如标签化片段)2304,所述模板核酸片段包含插入序列2308(例如开放染色质的区域)及其互补序列、转座子末端序列2306及其互补序列、测序引物或其部分2302(例如r2序列)、测序引物或其部分2310(例如r1序列)和缺口2307。包含模板核酸片段2304的细胞、细胞珠粒或细胞核可以被溶解、透化或以其他方式进行处理以接近其中的模板核酸片段2304(和一种或多种rna分子)。模板核酸片段2304可以与夹板序列2312接触,所述夹板序列可以包含与测序引物或其部分2302互补的第一序列2302’,和第二序列2324。序列2324可以包含封闭基团(例如3’封闭基团),所述封闭基团可以防止通过逆转录而延伸。序列2302’可以与模板核酸片段2304的序列2302杂交2314以提供包含夹板序列2312和模板核酸片段2304的部分双链核酸分子。序列2302’可以连接2326至模板核酸片段2304的转座子末端序列2306的互补序列(例如,使用连接酶)。附接至夹板序列2312的模板核酸片段2304然后可以分配在多个分区内的一个分区(例如液滴或孔)内(例如,如本文所述)。分区可以包括与核酸条形码分子2318a和2318b偶联的珠粒(例如凝胶
珠粒)2316。核酸条形码分子2318a可以包含流动池衔接子序列2320a(例如p5序列)、条形码序列2322a和与夹板序列2312的序列2324互补的悬突序列2324’。序列2324可以与序列2324’杂交2328。夹板序列2312然后可以延伸2330(例如,使用逆转录酶或dna聚合酶)以提供与核酸条形码分子2318a的序列2320a和2322a互补的序列2320a’和2322a’。可替代地,序列2324可以与序列2324’杂交以提供部分双链核酸分子,并且核酸条形码分子2318a可以连接(例如,使用连接酶)至模板核酸片段2304的序列2302。然后可以在本体溶液中回收分区的内容物(例如,可以使液滴破坏)以在本体溶液中提供部分双链核酸分子,所述部分双链核酸分子包含附接至夹板序列2312和模板核酸片段2304的核酸条形码分子2318a。核酸条形码分子2318a的序列2324’可以连接(例如,使用连接酶)2332至模板核酸片段2304的序列2302。在本体溶液中,缺口2307可以通过缺口填充延伸过程(例如,使用dna聚合酶)来填充2334以提供双链核酸分子。此分子还可以进行扩增(例如pcr)以提供双链扩增产物2336,所述双链扩增产物包含核酸条形码分子2318a、原始染色质分子的序列和任选的可以是流动池衔接子序列(例如p7序列)的另外序列2338。可以在批量处理之前填充分区中的缺口。
226.与图2300的染色质工作流程并行,可以处理源自同一细胞、细胞珠粒或细胞核的rna分子。如图2350所示,包含rna序列2360和多聚a序列2362的rna分子2358和珠粒2316可以提供在分区内。珠粒(例如凝胶珠粒)2316(例如,在图2300中描述的相同珠粒)可以包括在分区内并且可以与核酸条形码分子2318b偶联。核酸条形码分子2318b可以包含流动池衔接子序列2368(例如p5序列)、条形码序列2322b(例如与条形码序列2322a相同的条形码序列)、umi序列2366和与多聚a序列2362互补的多聚t序列2364。在一些情况下,核酸条形码分子2318b可以包含测序引物序列2368(例如r1序列或部分r1序列)、条形码序列2322b(例如与条形码序列2322a相同的条形码序列)、umi序列2366和与多聚a序列2362互补的多聚t序列2364。多聚t序列2364可以与rna分子2358的多聚a序列2362杂交。rna分子2358可以从多聚t序列2364逆转录2370出来以提供包含cdna序列2372的cdna分子。逆转录过程可以使用具有末端转移酶活性的逆转录酶,所述逆转录酶可以将序列2374附加到包含cdna序列2372的所得cdna分子上。序列2374可以是多聚c序列。包含引物序列2380和与序列2374互补的序列(例如多聚g序列)的模板转换寡核苷酸2378可以与cdna分子杂交。然后可以在本体溶液中回收分区的内容物(例如,可以使液滴破坏)以在本体溶液中提供cdna分子。cdna分子可以进行扩增(例如pcr)2384。可以进行另外扩增(例如pcr)2386以提供双链扩增产物2388,所述双链扩增产物包含核酸条形码分子2318b、原始rna分子的序列或与其对应的cdna、流动池衔接子序列2398(例如p7序列)和另外序列2390,所述另外序列可以包含测序引物或其部分(例如r2序列)2396、样品标志序列2394和流动池衔接子序列(例如p5序列)2392。条形码化cdna分子还可以或可替代地进行片段化、末端修复、da加尾、一个或多个衔接子序列的连接和/或核酸扩增。
227.细胞表征
228.在一个方面,本公开提供了一种用于表征细胞和/或细胞核的方法。例如,本公开提供了一种用于将多个细胞和/或细胞核表征为属于不同细胞类别(例如细胞类型)和/或源自于不同来源(例如来自不同组织或器官)的方法。例如,本公开提供了一种用于在多个细胞和/或细胞核中鉴定肿瘤相关细胞和/或细胞核的方法。
229.用于表征细胞或细胞核的方法可以包括提供包含细胞或细胞核和颗粒(例如凝胶
珠粒)的分区(例如液滴)。细胞或细胞核可以包含多个核酸分子,所述多个核酸分子可以包含多个核糖核酸(rna)分子和多个脱氧核糖核酸(dna)分子。多个dna分子可以包含染色质(例如,如本文所述)。颗粒可以包含偶联至其的多个核酸条形码分子(例如,如本文所述)。所述多个核酸条形码分子可以可释放地偶联至颗粒并且可以在施加刺激例如化学刺激(例如还原剂例如dtt)时从颗粒释放。所述多个核酸条形码分子可以通过不稳定部分(例如,如本文所述)偶联至颗粒。偶联至颗粒的所述多个核酸条形码分子可以全部相同。可替代地,所述多个核酸条形码分子可以包含一个或多个不同的核酸序列。例如,多个核酸条形码分子中的每个核酸条形码分子可以包含独特分子标识符序列。多个核酸条形码分子的一个或多个其他序列可以是相同的。例如,多个核酸条形码分子中的每个核酸条形码分子可以包含相同的核酸条形码序列。偶联至颗粒的多个核酸条形码分子中的核酸条形码分子和细胞或细胞核的多个核酸分子中的核酸分子可用于产生多个条形码化核酸分子(例如,如本文所述)。用于产生条形码化核酸分子的工作流程的实例在本文别处进行了描述,并显示在例如图12至图23中。多个条形码化核酸分子可以包含(i)包含对应于多个rna分子中的rna分子的序列的第一子集和(ii)包含对应于多个dna分子中的dna分子的序列的第二子集。多个条形码化核酸分子中的每个条形码化核酸分子可以包含共同的合适条形码序列。可以处理多个条形码化核酸条形码分子或其衍生物以产生对应于dna分子和rna分子的测序信息。测序信息可用于表征细胞或细胞核。例如,测序信息可用于鉴定细胞或细胞核的类型。细胞或细胞核可被鉴定为具有选自由例如单核细胞、自然杀伤细胞、b细胞、t细胞、粒细胞、浆细胞样树突细胞、树突细胞和基质细胞组成的组的类型。也可以鉴定此类细胞类型的特定亚类。例如,细胞或细胞核可以被鉴定为cd14单核细胞、cd16单核细胞、髓样树突细胞、浆细胞样树突细胞、复制b细胞、正常b细胞、肿瘤b细胞、幼稚b细胞、记忆b细胞、浆母细胞b细胞、淋巴浆细胞样细胞、b-1细胞、调节性b细胞、浆b细胞、igm+记忆b细胞、igd+记忆b细胞、调节性b细胞、浆b细胞、复制t细胞、正常t细胞、辅助t细胞、细胞毒性t细胞、记忆t细胞、调节性t细胞、自然杀伤t细胞、粘膜相关不变型t(mait)细胞、cd8+mait细胞、cd8γδt细胞、效应t细胞、cd4记忆t细胞、幼稚t细胞或另一种细胞类型。
230.用于表征细胞和/或细胞核的方法可以涉及产生对应于核糖核酸(rna)分子(例如,如本文所述)的测序信息和对应于脱氧核糖核酸(dna)分子(例如,如本文所述)的测序信息。rna测序信息可以包括与基因表达有关的信息,因此在本文中也称为“基因表达数据”。例如,rna测序信息可以包括源自信使rna(mrna)的信息,这些信息可以提供对可能从mrna翻译的蛋白质的见解。dna测序信息可以包括与可接近染色质区域(例如标签化片段)有关的信息,因此在本文中交替地称为“染色质数据”或“atac数据”。例如,dna测序信息可以包括源自可接近或开放染色质区域(例如核小体之间的染色质区域)的信息。产生rna和dna测序信息可以包括制备包含对应于特定细胞和/或细胞核的核酸条形码序列的条形码化核酸分子。例如,可以在分区中提供细胞或细胞核并使其经受并行工作流程以处理其中包括的dna分子(例如染色质)和rna分子。此类工作流程的实例显示在例如图12至图23中。所得的条形码化核酸分子可以包括对应于细胞或细胞核的dna分子的第一组条形码化核酸分子和对应于细胞或细胞核的rna分子的第二组条形码化核酸分子。每个条形码化核酸分子可以包括核酸条形码序列,例如作为偶联至颗粒(例如凝胶珠粒)的核酸条形码分子的组分提供至分区的核酸条形码序列。针对与给定分区(例如液滴或孔)相关的给定细胞或细胞
核产生的条形码化核酸分子的核酸条形码序列在针对给定细胞或细胞核产生的条形码化核酸分子中可能是相同的。因此,对应于给定细胞或细胞核的dna和rna分子的条形码化核酸分子可以包含相同的核酸条形码序列。
231.在处理多个细胞或细胞核的情况下(例如,在多个分区内,如本文别处所述),与每个细胞或细胞核相关的条形码化核酸分子可以包含不同的核酸条形码序列(例如,如本文所述)。以这种方式处理多个细胞和/或细胞核可以产生包含对应于源自多个细胞和细胞核的dna分子(例如染色质或标签化片段)的第一多个条形码化核酸分子的测序信息的第一数据集和包含对应于源自多个细胞和细胞核的rna分子的第二多个条形码化核酸分子的测序信息的第二数据集。所述多个细胞或细胞核可以源自包含肿瘤或疑似包含肿瘤的样品。所述多个细胞或细胞核可以源自从受试者例如人类受试者获得的样品。可能已知受试者患有或曾经患有肿瘤和/或增生性疾病(例如癌症)。可替代地,受试者可能疑似患有肿瘤和/或增生性疾病(例如癌症)。样品可以源自体液,例如血液和/或血浆。样品可以源自活检物,例如肿瘤活检物。肿瘤可以是b细胞淋巴瘤肿瘤。
232.图24示意性地说明了如何使用并行dna(例如染色质)和rna处理(例如,如本文所述)将多个细胞中的细胞分组成细胞类型(例如模态)。如本文所述,通过核酸测序方法(例如,如本文所述)分析的条形码化核酸分子的核酸条形码序列可用于关联多个细胞中的特定细胞的dna(例如开放染色质)和rna(例如基因表达)信息。
233.图25示意性地说明了用于产生对应于多个细胞或细胞核的dna(例如染色质)和rna(例如基因表达)信息的示例性工作流程。如最左图所示,可以提供多个转座的细胞核和偶联至多个核酸条形码分子的多个颗粒(例如凝胶珠粒)。多个颗粒中的每个颗粒可以偶联至包含共同核酸条形码序列(例如,如本文所述)的多个核酸条形码分子中的核酸条形码分子。可以使用微流体装置处理多个转座细胞核和多个颗粒以产生多个液滴(例如,油中的水性液滴)。多个液滴的至少一个子集可以包含多个颗粒中的颗粒和多个转座细胞核中的转座细胞核。多个液滴还可包含一种或多种试剂,用于分析多个转座细胞核的dna和/或rna分子(例如,如本文所述)。可以使多个液滴经受足以处理多个转座细胞核中的转座细胞核的dna和/或rna分子以产生多个条形码化核酸分子的条件(例如,使用连接、逆转录等,如本文别处所述),其中多个条形码化核酸分子中的每个条形码化核酸分子包括偶联至多个颗粒的多个核酸条形码分子中的核酸条形码分子的核酸条形码序列。多个条形码化核酸分子可以从多个颗粒中回收并且可以进行另外处理(包括核酸扩增)以便产生多个条形码化核酸分子的拷贝,和/或将另外序列(例如测序引物和流动池序列)附加到所述多个条形码化核酸分子。然后可以处理所述多个条形码化核酸分子以产生对应于多个转座细胞核中的转座细胞核的可接近染色质和基因表达的测序文库。注意,该工作流程也可以用尚未进行转座的细胞或细胞核来执行(例如,可以在分区内执行转座过程,如本文别处所述)。
234.图39示意性地说明了通过并行dna(例如染色质)和rna处理(例如,如本文所述)产生的数据。第一数据集3900对应于多个细胞(此处为四个细胞)的dna分子并且包括测序读段3901、3902、3903、3904、3905、3906、3907和3908。每个测序读段包括条形码序列3911、3912、3913或3914。条形码序列3911与第一个细胞(“细胞1”)相关。条形码序列3912与第二个细胞(“细胞2”)相关。条形码序列3913与第三个细胞(“细胞3”)相关。条形码序列3914与第四个细胞(“细胞4”)相关。每个测序读段还包括对应于多个细胞中的细胞的dna分子(例
如染色质)的序列的序列。例如,测序读段3901包括序列3915。测序读段3902、3903、3904、3905、3906、3907和3908分别包括序列3916、3917、3918、3919、3920、3921和3922。第二数据集3930对应于多个细胞的rna分子并且包括测序读段3931、3932、3933、3934、3935、3936、3937和3938。每个测序读段包括条形码序列3911、3912、3913或3914,表明测序读段与多个细胞(例如,细胞1、细胞2、细胞3或细胞4)中的特定细胞相关。每个测序读段还包括对应于多个细胞中的细胞的rna分子的序列的序列。例如,测序读段3931包括序列3945。测序读段3932、3933、3934、3935、3936、3937和3938分别包括序列3946、3947、3948、3949、3950、3951和3952。可以处理第一数据集3900和第二数据集3930(例如,使用算法来鉴定测序读段内的核酸条形码序列并将包含共同核酸条形码序列的测序读段彼此关联)以产生第三数据集3960。第三数据集3960包括对应于多个细胞中的细胞的rna和dna测序信息。如图所示,条形码序列可用于将rna和dna测序读段鉴定为对应于多个细胞中的特定细胞。例如,测序读段3901、3902、3931和3932可以根据它们共享的核酸条形码序列3911被鉴定为源自细胞1。类似地,测序读段3903、3904、3933和3934可以根据条形码序列3912被鉴定为源自细胞2;测序读段3905、3906、3935和3936可以根据条形码序列3913被鉴定为源自细胞3;测序读段3907、3908、3937和3938可以根据条形码序列3914被鉴定为源自细胞4。如本文所述,与多个细胞中的细胞相关的互补rna(例如基因表达)和dna(例如可接近染色质)信息可用于表征细胞。例如,细胞1的基因表达和/或可接近染色质数据可用于将细胞1鉴定为肿瘤b细胞,而细胞2的基因表达和/或可接近染色质数据可用于将细胞2鉴定为正常b细胞。
235.针对dna分子(例如染色质)和rna分子(例如,如本文所述)获得的测序信息可用于表征其所源自的多个细胞的细胞和/或细胞核。在一些情况下,单独的基因表达信息可能足以鉴定多个细胞和/或细胞核中的给定细胞或细胞核或其集合的细胞类型。在其他情况下,单独的可接近染色质信息可能足以鉴定多个细胞和/或细胞核中的给定细胞或细胞核或其集合的细胞类型。在一些情况下,基因表达和可接近染色质信息可用于鉴定多个细胞和/或细胞核中的给定细胞或细胞核或其集合的细胞类型。基因表达和可接近染色质信息的组合对于鉴定多个细胞中的细胞类型可能特别有用,例如用于包含至少约100、200、300、400、500、600、700、800、900、1,000、2,000、3,000、4,000、5,000、6,000、7,000、8,000、9,000、10,000、15,000、20,000、25,000、30,000、40,000、50,000、60,000、70,000、80,000、90,000、100,000或更多个细胞的多个细胞。
236.图26示出了24,000个外周血单核细胞(pbmc)的基因表达分析,而图27示出了对相同细胞的atac分析。细胞可以依据细胞类型聚类,如图的左图和右图所示。如图所示,可以在粗略或精细级别表征细胞,并且可以在多个细胞中鉴定多种不同的细胞类型。在该实例中,可以使用基因表达而不是使用atac信息在更精细的分析中鉴定细胞。然而,反之亦然(例如,对于不同的细胞样品)。如图26和图27所示,细胞可以被鉴定为具有选自例如单核细胞、自然杀伤细胞、b细胞、t细胞、粒细胞、树突细胞和基质细胞的类型。b细胞可以被鉴定为例如正常b细胞、复制b细胞、肿瘤b细胞、幼稚b细胞、记忆b细胞、igm+记忆b细胞、igd+记忆b细胞、igm+igd+记忆b细胞和浆b细胞。t细胞可以被鉴定为例如复制t细胞、正常t细胞、粘膜相关不变型t(mait)细胞、cd8+mait细胞、cd8效应t细胞、cd4记忆t细胞和幼稚t细胞。单核细胞可以被鉴定为例如cd14单核细胞和cd16单核细胞。树突细胞可以被鉴定为例如髓样树突细胞和浆细胞样树突细胞。图28和图29a至图29b示出了分别在图26和图27中显示的基于
基因表达的细胞表征和基于染色质的细胞表征之间的一致性。图28的中央图中显示的叠加图是方向不同的基因表达和染色质细胞类型表示中的群集的结果。如图29a至图29b所示,使用染色质数据进行的细胞类型表征可以在与基因表达数据关联时被细分为更窄的细胞类别。例如,单核细胞可以被细分为cd14单核细胞和cd16单核细胞类别。类似地,b细胞可以被细分为幼稚/记忆b细胞、igm+igd+记忆b细胞等。使用基因表达标志物对染色质数据的重新注释在图30中示出。图31比较了基于开放染色质分析(左上图)、基因表达分析(右上图)和使用基因表达标志物注释的开放染色质分析(下图)的细胞聚类的不同表示。
237.对应于dna分子的测序信息(例如染色质信息)和对应于rna分子的测序信息(例如基因表达信息)可以被串联使用以细化细胞类型分类。例如,如上文所述,基因表达信息可用于对使用染色质信息鉴定的细胞类型进行细分(例如,注释)。类似地,染色质信息可用于对使用基因表达信息鉴定的细胞类型进行细分或拆解。这种过程的一个实例示于图32中。图32的上图显示基于用基因表达标志物注释的染色质信息的细胞分类(左上图)和仅基于基因表达信息的细胞分类(右上图)。如仅基于基因表达信息的分类(右上图)所示,幼稚/记忆b细胞可被鉴定为单个群集。然而,在基于用基因表达标志物注释的染色质信息的分类(左上图)中,幼稚b细胞和记忆b细胞被鉴定为两个不同的群集(例如,它们具有不同的染色质特征)。这些子集群在左下图中突出显示为子集群1和2。右下图说明当仅使用基因表达对细胞类型进行分类时,这些子集群可能会被掩盖。子集群1和2的基因表达分析基于相对较高的ig和相对较低的幼稚b细胞相关的转录物将子集群1鉴定为预期的记忆b细胞,而子集群2可能被鉴定为幼稚b细胞。因此,互补的基因表达和染色质分析可能有助于区分细胞或细胞核群体中的多种细胞类型,而这可能是仅使用单一分析无法区分的。
238.本文所述的方法可用于分析细胞群体,包括病变细胞例如肿瘤细胞。本文提供的方法可以包括使用测序信息来鉴定样品中肿瘤细胞或细胞核的存在。因此,本文提供的方法可用于诊断评估。本文提供的方法还可以或可替代地包括使用测序信息来鉴定样品中的细胞类型、细胞状态、肿瘤特异性基因表达模式或肿瘤特异性差异性可接近染色质区域。至少部分地基于这样的分析,可以确定例如用于样品所源自的受试者的治疗方案。治疗方案可以包括施用治疗有效量的靶向以肿瘤特异性基因表达模式或肿瘤特异性差异性可接近染色质区域鉴定的一个或多个靶标的剂。
239.本文提供的方法还可用于在单细胞水平上关联基因型和表型。此类分析可以提供对各种疾病和生物过程的独特见解。例如,这种分析可以提供对其中体细胞突变可能是关键特征的各种癌症和其他病症的发展、诊断和治疗的见解。基因表达分析与染色质分析相结合还可用于鉴定肿瘤特异性信号传导途径:基因表达分析可鉴定特定细胞类型(例如肿瘤细胞)的活性受体,而染色质分析可提供对转录因子活性的见解。
240.表征多个细胞或细胞核的方法可以包括提供对应于多个细胞或细胞核的多个dna分子(例如染色质)的可接近染色质区域的第一数据集和对应于所述多个细胞或细胞核的多个rna分子的第二数据集。第一数据集可以包含对应于可接近染色质区域的序列和多个核酸条形码序列的测序信息(例如第一多个测序读段)。第二数据集可以包含对应于多个rna分子的序列和多个核酸条形码序列的测序信息(例如第二多个测序读段)。多个细胞或细胞核中的细胞或细胞核可以对应于所述多个核酸条形码序列中的核酸条形码序列。例如,包含含有所述多个核酸条形码序列的共同核酸条形码序列的多个核酸条形码分子的颗
粒可用于处理所述多个细胞或细胞核中的细胞或细胞核的多个dna分子和rna分子(例如,在分区内)(如本文所述)。第一数据集和第二数据集的多个核酸条形码序列可用于将所述第一多个测序读段中的第一测序读段和所述第二多个测序读段中的第二测序读段鉴定为对应于所述多个细胞或细胞核中的细胞或细胞核,由此产生包含对应于与所述多个细胞或细胞核中的细胞或细胞核相关的可接近染色质区域和rna分子的序列信息的第三数据集。可以使用所述第三数据集的序列信息来鉴定细胞或细胞核的细胞类型。
241.在各个实施方案中,示例性数据分析工作流程可以包括以下分析操作中的一者或多者:基因表达数据处理操作、atac数据处理操作、联合细胞调用操作、基因表达分析操作、atac分析操作,和atac和rna分析操作,或它们的任何组合。应当理解,本公开内的某些操作可以单独使用,也可以与本公开内的其他操作结合使用,而本公开内的某些其他操作只能与本公开内的某些其他操作结合使用。此外,下文描述的一个或多个操作或过滤器(假定默认用作计算流程的一部分用于分析基因表达测序数据和单细胞atac测序数据)也不能根据用户输入来使用。应当理解,也设想相反的情况。还应当理解,用于分析由单细胞测序工作流程产生的测序数据的另外操作也被设想为本公开内的计算流程的一部分。
242.基因表达数据处理
243.基因表达数据处理操作可以包括对单细胞测序数据集中的条形码进行处理,以修复条形码中偶尔出现的测序错误,使得测序片段与原始条形码相关联,从而提高数据质量。
244.条形码处理操作可以包括对照正确条形码序列的“白名单”检查每个条形码序列。条形码处理操作还可以包括对每个白名单条形码的频率进行计数。条形码处理操作还可以包括各种条形码校正操作,作为本文公开的各个实施方案的一部分。例如,可以尝试通过查找白名单内与观察到的序列的差异在2(汉明距离《=2)内的所有条形码,然后根据该序列在读取数据中的丰度和不正确碱基的质量值对条形码进行评分,从而校正未包含在白名单中的条形码。作为另一实例,如果观察到的不存在于白名单中的条形码有》90%的概率是基于真实条形码的,则可以将其校正为白名单条形码。
245.基因表达数据处理还可以包括将读取序列(也称为“读段”)与参考序列进行比对。在本文各个实施方案的比对操作中,通过将读取序列(也称为“读段”)与参考序列进行比对来执行基于参考的分析。本文各个实施方案的参考序列可以包括参考转录组序列(包括基因和内含子)及其相关的基因组注释,其包括基因和转录物坐标。本文各个实施方案的参考转录组序列和注释可以获自信誉良好的确立已久的联盟,包括但不限于ncbi、gencode、ensembl和encode。在各个实施方案中,参考序列可以包括单物种和/或多物种参考序列。在各个实施方案中,本公开内的系统和方法还可以提供预先构建的单物种和多物种参考序列。在各个实施方案中,预先构建的参考序列可以包括与调控区有关的信息和文件,包括但不限于对启动子、增强子、ctcf结合位点和dna酶超敏性位点的注释。在各个实施方案中,本公开内的系统和方法还可以提供构建非预先构建的自定义参考序列。
246.本文的各个实施方案可以被配置为在umi计数之前校正umi序列中的测序错误。可以将确定映射到转录组的读段放入共享相同条形码、umi和基因注释的组中。如果两组读段具有相同的条形码和基因,但它们的umi仅相差单个碱基(即,相距汉明距离1),则其中一个umi可能是由测序中的取代错误引入的。在这种情况下,支持度较低的读段组的umi被校正为支持度较高的umi。
247.依据条形码、umi(可能已修正)和基因注释对读段进行分组后,如果两组或更多组读段具有相同的条形码和umi,但基因注释不同,则保留支持度最高的读段的基因注释进行umi计数,并且可以丢弃其他读段组。在获得最大读段支持度的情况下,可以丢弃所有读段组,因为无法确定地分配基因。
248.在这两个过滤操作之后,每个观察到的条形码、umi、基因组合被记录为未经过滤的特征-条形码矩阵中的umi计数,所述矩阵包含来自已知良好条形码序列的固定列表中的每个条形码。这包括背景和细胞相关的条形码。支持每个已计数umi的读段的数量也记录在分子信息文件中。
249.基因表达数据处理还可以包括将个别cdna片段读段注释为外显子的、内含子的、基因间的,以及它们是否与参考基因组以高置信度对齐。在各个实施方案中,如果片段的至少一部分与外显子相交,则片段读段被注释为外显子的。在各个实施方案中,如果片段读段是非外显子的并且与内含子相交,则片段读段被注释为内含子的。注释过程可以通过比对方法及其参数/设置来确定,如例如使用star比对器所执行的。
250.基因表达数据处理还可以包括独特的分子处理以更好地鉴定某些亚群,例如低rna含量的细胞,可以在细胞调用之前执行独特的分子处理操作。对于低rna含量的细胞,这样的操作很重要,特别是当低rna含量的细胞混合到高rna含量的细胞群中时。独特的分子处理可以包括高含量(例如rna含量)捕获操作和低含量捕获操作。
251.atac数据处理
252.atac数据处理操作可以包括对单细胞测序数据中的条形码进行处理,以修复条形码中偶尔出现的测序错误,使得测序片段与原始条形码相关联,从而提高数据质量。
253.条形码处理操作可以包括对照正确条形码序列的“白名单”检查每个条形码序列。条形码处理操作还可以包括对每个白名单条形码的频率进行计数。条形码处理操作还可以包括各种条形码校正操作,作为本文公开的各个实施方案的一部分。例如,可以尝试通过查找白名单内与观察到的序列的差异在2(汉明距离《=2)内的所有条形码,然后根据该序列在读取数据中的丰度和不正确碱基的质量值对条形码进行评分,从而校正未包含在白名单中的条形码。作为另一实例,如果观察到的不存在于白名单中的条形码有》90%的概率是基于真实条形码的,则可以将其校正为白名单条形码。
254.atac数据处理操作还可以包括将读取序列(也称为“读段”)与参考序列进行比对。在读取序列与参考基因组比对之前,可以利用多个子操作之一来修剪掉读取序列中的衔接子序列、引物寡核苷酸序列或两者。
255.atac数据处理操作还可以包括标记测序和pcr重复以及输出高质量的去重复片段。可以采用一个或多个子操作来鉴定重复读段,例如按5'位置对比对的读段进行排序以解决转座事件,以及鉴定读段对和原始读段对组。该过程还可以包括过滤器,所述过滤器当在本文的各个实施方案中激活时,可以确定片段是否在两个读段上被映射为mapq》30(即,包括映射质量低于30的读段的条形码重叠),而不是线粒体,且不是嵌合映射的。
256.atac数据处理操作可以包括峰调用分析,所述分析包括计算基因组每个碱基对周围窗口中的切割位点,并对其进行阈值化以找到富含开放染色质的区域。峰是基因组中以转座酶接近性富集的区域。只有不被核小体和调节性dna结合蛋白(例如转录因子)结合的开放染色质区域才能被转座酶接近用于atac测序。因此,本文各个实施方案的每个测序片
段的末端可以被认为指示开放染色质区域。因此,可以根据本文各个实施方案对来自这些片段的组合信号进行分析以确定富含开放染色质的基因组区域,从而了解这些区域的调控和功能意义。因此,使用由上述按位置排序的片段文件(例如,fragments.tsv.gz文件)中的片段末端确定的位点,可以计算沿基因组的每个碱基对的转座事件的数量。在本公开内的一个实施方案中,对基因组的每个碱基对周围的窗口中的切割位点进行计数。
257.联合细胞调用分析
258.联合细胞调用分析操作可以包括细胞调用分析,其包括将在单细胞基因表达文库和单细胞atac文库两者中观察到的条形码子集与从样品加载的细胞相关联。鉴定这些细胞条形码可以让人们以单细胞分辨率分析数据的变化和量化。
259.该过程还可以包括校正凝胶珠粒伪影,例如凝胶珠粒多重(其中细胞共享多于一个条形码化凝胶珠粒)和条形码多重(当细胞相关的凝胶珠粒具有多于一个条形码时发生)。在一些实施方案中,与细胞调用和凝胶珠粒伪影校正相关的操作一起用于执行必要的分析,作为本文各个实施方案的一部分。
260.根据各个实施方案,记录通过上述操作中公开的各个实施方案的所有过滤器并且在片段文件(例如fragments.tsv文件)中被指示为片段的映射的高质量片段的记录。利用在本文公开的峰调用操作中确定的峰,对于每个条形码,与任何峰区域重叠的片段的数量可用于将信号与噪声分开,即,将与细胞相关的条形码与非细胞条形码分开。应当理解,与单纯地使用每个条形码的片段数相比,这种从噪声中分离信号的方法在实践中效果更好。
261.根据本文的各个实施方案,各种方法可以用于联合细胞调用。在各个实施方案中,可以在至少两个操作中执行联合细胞调用。在本文的各个实施方案的细胞调用的第一操作中,鉴定具有低于基因组中峰分数的与所调用峰重叠的片段分数的条形码。当在本文的各个实施方案的细胞调用过程中采用该第一操作时,在峰两侧填充2000bp,以便解释片段长度用于此计算。
262.基因表达分析
263.基因表达分析操作可以包括产生特征-条形码矩阵,所述矩阵总结每个细胞的基因表达计数。特征-条码矩阵可以只包括检测到的细胞条形码。特征-条形码矩阵的产生可以涉及将来自每个细胞相关条形码(例如,来自上文讨论的
‘
细胞调用’操作的输出)的有效非过滤umi计数/基因(例如,来自上文讨论的
‘
独特分子处理’操作的输出)一起编译到最终输出计数矩阵中,然后可以将该矩阵用于下游分析操作。
264.基因表达分析操作可以包括各种降维、聚类、t-sne和umap投影工具。本文各个实施方案的降维工具用于通过获得一组主变量来减少考虑中的随机变量的数量。根据本文的各个实施方案,可以使用聚类工具来将本文各个实施方案的对象分配给同质组(称为集群),同时确保不同组中的对象不相似。本文各个实施方案的t-sne和umap投影工具可以包括用于对本文各个实施方案的数据进行可视化的算法。根据各个实施方案,本公开内的系统和方法还可以包括降维、聚类以及t-sne和umap投影工具。在一些实施方案中,与降维、聚类和用于可视化的t-sne和umap投影相关的分析被一起用于执行必要的分析,作为本文各个实施方案的一部分。用于降维的各种分析工具包括主成分分析(pca)、潜在语义分析(lsa)和概率潜在语义分析(plsa)、聚类以及用于可视化的t-sne和umap投影,允许对细胞群体进行分组并将细胞群体与另一细胞群体进行比较。
265.在一些实施方案中,本公开内的系统和方法涉及鉴定差异基因表达。由于数据在单细胞分辨率下是稀疏的,因此可以执行根据本文各个实施方案的降维以将数据投射到较低维空间中。
266.根据各个实施方案,基因表达分析操作可以包括差异表达分析,所述差异表达分析执行差异分析以鉴定其表达对每个集群特异的基因,针对每个基因和每个集群进行cell ranger测试以确定集群内均值是否不同于集群外均值。
267.atac分析
268.atac分析可以包括确定峰-条形码矩阵。根据各个实施方案,在atac分析操作中,可以首先产生原始峰-条形码矩阵,该矩阵是由每个条形码的每个峰区域内的片段末端(或切割位点)的计数组成的计数矩阵。这个原始峰-条形码矩阵捕获每个条形码的开放染色质的富集。然后可以通过从原始峰-条形码矩阵中过滤掉非细胞条形码来过滤原始矩阵以使其仅由细胞条形码组成,然后可以将其用于本文各个实施方案的各种降维、聚类和可视化操作中。
269.atac分析操作可以包括各种降维、聚类和t-sne投影工具,类似于上面在基因表达分析操作中描述的。
270.atac分析操作可以包括通过执行基因注释以及发现每个峰上的转录因子-基序匹配来注释峰。预期峰注释可以与本公开各个实施方案内的后续差异分析操作一起使用。设想各种峰注释程序和参数并在下面详细讨论。
271.峰是富含开放染色质的区域,因此具有调控功能的潜力。因此可以理解,观察与基因相关的峰的位置可能是有深刻见解的。本文的各个实施方案,例如,最接近-d=b的床具,可用于基于包装在参考中的最接近转录起始位点(tss)将每个峰与基因相关联。根据本公开内的一些实施方案,如果峰在tss上游600个碱基或下游100个碱基内,则峰与基因相关联。此外,根据本公开内的一些实施方案,基因可以与距tss远得多并且距转录物末端上游或下游小于100kb的推定远端峰相关联。这种关联可以被本文各个实施方案的配套可视化软件例如loupe cell browser采用。在另一个实施方案中,这种关联可以用于构建和可视化衍生特征,例如启动子总和,其可以将来自与基因相关的峰的计数汇集在一起。
272.atac分析操作还可以包括转录因子(tf)基序富集分析。tf基序富集分析包括针对每个基序和每个条形码产生tf-条形码矩阵,所述矩阵由具有tf基序匹配的峰-条形码矩阵(即峰的汇集切割位点计数)组成。在本公开的各个实施方案内,预期tf基序富集然后可用于后续分析操作,例如差异可接近性分析。下面提供了与tf基序富集分析相有关的细节。
273.atac分析操作还可以包括差异可接近性分析,其对tf结合基序和峰进行差异分析,以鉴定不同细胞或细胞组之间的差异基因表达。本公开中的各种算法和统计模型,例如负二项式(nb2)广义线性模型(glm),可以用于差异可接近性分析。
274.atac和rna特征关联分析
275.atac和rna分析操作可以包括特征关联分析,用于检测在多个细胞中的每一细胞中检测到的基因组特征对之间的相关性,例如,来自单细胞数据集的开放染色质区域和基因之间的相关性。这种相关性可以表示为特征关联或关联相关性,并可用于推断增强子-基因靶向关系和构建转录网络。特征关联分析的更多细节在图43中提供。
276.在各个实施方案中,来自联合细胞调用操作的联合数据可以由atac和rna分析操
作进一步处理,以鉴定单细胞基因表达文库和单细胞atac文库之间的相关性和相关性显著性。具有强关联相关性的特征可以被认为是“共同表达”的,并富集了共享的调控机制。例如,增强子的可接近性及其靶基因的表达可以在异质细胞群体中展示出非常同步的差异模式。高度可接近的增强子导致转录因子(tf)结合水平升高,进而导致基因表达升高(或受抑)。另一方面,当增强子不可接近时,没有tf可以与增强子结合,因此转录活化程度最小,这导致靶基因表达减少。
277.在一些实施方案中,与基因表达或染色质可接近性相关的分析还可以包括随机森林树、随机树、朴素贝叶斯分类器(bayes classifier)、k均值聚类、层次聚类、预测树、分类树、c4.5分类器、回归树、神经网络、仿射传播、凝聚聚类、birch dbscan聚类、小批量k均值、均值漂移、谱聚类、高斯混合或xgboost。
278.在一个方面,本公开提供了一种用于鉴定对应于表达蛋白的遗传特征例如顺式调控元件的方法。所述方法可以包括提供dna(例如染色质)测序信息和rna(例如基因表达)测序信息(例如,如本文所述)并将这些信息与它们所源自的细胞和/或细胞核相关联(例如,如本文所述)。细胞和/或细胞核可以被表征为对应于特定细胞类型(例如,如本文所述)。染色质数据和基因表达数据可用于鉴定细胞和/或细胞核的细胞类型。可替代地,仅一个数据集可用于鉴定细胞和/或细胞核的细胞类型。基因表达测序信息可用于鉴定目标表达蛋白,例如在不同细胞类型之间差异表达的蛋白。例如,基因表达数据可用于鉴定相对于第二细胞类型在第一细胞类型中过度表达的蛋白例如受体,其中第一细胞类型可能与疾病状态(例如肿瘤细胞)相关并且第二细胞类型可能与健康状态(例如正常细胞)相关。可替代地,基因表达数据可用于鉴定相对于第二细胞类型在第一细胞类型中低表达的蛋白例如受体,其中第一细胞类型可能与疾病状态(例如肿瘤细胞)相关并且第二细胞类型可能与健康状态(例如正常细胞)相关。差异表达的蛋白可以是例如细胞因子,例如白细胞介素(例如il-2、il-4、il-10、il-13等)受体。染色质信息可用于鉴定可能与差异表达的蛋白有关的遗传特征。遗传特征可以是例如顺式调控元件或反式调控元件。
279.鉴定对应于表达蛋白的遗传特征(例如调控区)的方法可以包括提供对应于多个细胞或细胞核的多个dna分子(例如染色质)的可接近染色质区域的第一数据集和对应于所述多个细胞或细胞核的多个rna分子的第二数据集。第一数据集可以包含对应于可接近染色质区域的序列和多个核酸条形码序列的测序信息(例如第一多个测序读段)。第二数据集可以包含对应于多个rna分子的序列和多个核酸条形码序列的测序信息(例如第二多个测序读段)。多个细胞或细胞核中的细胞或细胞核可以对应于所述多个核酸条形码序列中的核酸条形码序列。例如,包含含有所述多个核酸条形码序列的共同核酸条形码序列的多个核酸条形码分子的颗粒可用于处理所述多个细胞或细胞核中的细胞或细胞核的多个dna分子和rna分子(例如,在分区内)(如本文所述)。第一数据集和第二数据集的多个核酸条形码序列可用于将所述第一多个测序读段中的第一测序读段和所述第二多个测序读段中的第二测序读段鉴定为对应于所述多个细胞或细胞核中的细胞或细胞核,由此产生包含对应于与所述多个细胞或细胞核中的个别细胞或细胞核相关的可接近染色质区域和rna分子的序列信息的第三数据集。可以使用所述第三数据集的序列信息来鉴定细胞或细胞核的细胞类型。对应于rna分子的序列信息可用于鉴定所鉴定的细胞类型中的细胞类型的表达蛋白。对应于可接近染色质区域的序列信息可用于鉴定对应于所述表达蛋白的遗传特征例如顺式
调控元件。
280.在一些实施方案中,第一数据集所包含的序列信息是从如本文所述产生和处理的多个标签化dna片段产生的。在一些实例中,产生多个条形码化核酸分子,所述多个条形码化核酸分子包括包含对应于所述样品的细胞或细胞核的所述多个脱氧核糖核酸(dna)分子的可接近染色质区域的序列的第一子集和包含对应于相同细胞或细胞核的所述核糖核酸(rna)分子的序列的第二子集。在一些情况下,来自相同细胞或细胞核的多个条形码化核酸分子在同一分区内产生。在同一分区中产生的条形码化核酸分子可以共享相同的条形码序列。在一些实施方案中,所述方法包括对条形码化核酸分子进行测序。
281.特征关联和关联特征
282.在一些实施方案中,所提供的方法包括:产生包含对应于细胞或细胞核的多个脱氧核糖核酸(dna)分子的可接近染色质区域的测序信息的第一数据集(例如,包括atac数据处理和/或分析),产生包含对应于所述细胞或细胞核的多个核糖核酸(rna)分子的测序信息的第二数据集(例如,包括基因表达数据处理和/或分析),以及使用所述第一数据集和所述第二数据集产生所述细胞或细胞核的关联特征(例如,包括atac和rna特征关联分析)。在一些实施方案中,使用特征关联分析过程和工作流程或来自其中的信息来产生关联特征。在一些实施方案中,产生关联特征包括关联至少一个基因组特征对。在其他情况下,关联特征包括关联十个基因组特征中的至少两个、三个、四个、五个、六个、七个、八个、九个。在一些实施方案中,基因组特征可以包括可接近染色质区域或基因表达水平。在其他实施方案中,基因组特征可以包括转录因子可接近性、核小体占位、序列同一性、区域的二级结构、区域的三级结构、基因组中的位置或细胞核中的物理位置(例如核周dna定位或核孔复合体相关定位)。基因组中的位置可以基于两个基因座之间的物理距离或重组频率来计算。在一些实施方案中,至少两个基因组特征可以通过基因座关联起来。基因座可以包含基因的功能单元。基因的功能单元可以包含至少表达或合成核酸或多肽产物所需的序列。在一些情况下,启动子序列的染色质可接近性和由启动子序列驱动或调控的表达rna的水平可以关联起来。核酸产物可以是rna。rna可以包含编码或非编码rna。rna可以包括mrna、trna、rrna、snrna、snorna、长链非编码rna、mirna、源自小rdna的rna(srrna)、源自trna的小rna(tsrna)、反义rna、sirna或erna。rna还可以包含本文中的rna及其任何前体。
283.细胞或细胞核的关联特征可以将对应于关于细胞或细胞核的基因组特征或其他信息的两个或更多个不同数据集关联起来。关联特征可以包括基因组特征或其他信息的组合或有关数据集。例如,细胞或细胞核的关联特征可以关联包含对应于细胞或细胞核的多个dna分子的可接近染色质区域的测序信息的第一数据集和包含对应于多个rna分子的测序信息或其基因表达数据的第二数据集关联起来。关联特征可以包括对应于关于细胞或细胞核的基因组特征或其他信息的多个不同数据集的手动分类。关联特征还可以包括对应于基因组特征或关于细胞或细胞核的其他信息的多个不同数据集的计算分类。关联特征可以包括对应于关于细胞或细胞核的基因组特征或其他信息的多个不同数据集的加法、减法、乘法、除法或求幂。
284.在一些实施方案中,特征关联包括跨细胞或细胞核的在atac文库中鉴定的峰和在基因表达文库中鉴定的转录物水平的相关信号。在一些实施方案中,特征关联可以是正相关或负相关的(图51)。例如,开放增强子区域可能与其相关转录物的基因表达呈正相关,而
阻遏物的结合将导致负相关的特征关联。在一些实施方案中,可以确定特征关联的显著性。在一些情况下,开放染色质信号与基因表达之间的相关性越大,特征关联的显著性就越高。在一些实施方案中,可以比较测试样品与对照样品之间(或测试细胞或细胞核与其对照细胞或细胞核之间)在atac文库中鉴定的峰、在基因表达文库中鉴定的转录物水平和/或两者的相关特征关联(例如关联特征)的细胞核信号。
285.细胞或细胞核的关联特征可以将关于细胞或细胞核的不同信息片段关联起来以确定描述细胞或细胞核的样品或受试者的特征或疾患。细胞或细胞核的关联特征可以是所述细胞或细胞核独有的。细胞或细胞核的关联特征可以是共享相似特征的一组细胞或细胞核独有的。在一些情况下,可以将两个或更多个细胞各自的关联特征相互比较或以其他方式进行处理以确定所述两个或更多个细胞之间的相似性或差异。例如,可以将已知具有疾患的参考或对照细胞的关联特征与分析物细胞的关联特征进行比较或处理,并且如果所述两个关联特征的一个或多个方面是相似的,且所述一个或多个方面指示所述已知疾患,则可以确定所述分析物细胞或所述分析物细胞所源自的样品或受试者患有或罹患相同的已知疾患。类似地,如果所述两个关联特征的一个或多个方面相异,且所述一个或多个方面指示所述已知疾患,则可以确定所述分析物细胞或所述分析物细胞所源自的样品或受试者未患有或未罹患与参考或对照细胞相同的已知疾患。在一些实施方案中,多个关联特征的相似性或差异性可以通过所述多个关联特征的手动分类或计算分类来确定。多个关联特征的相似性或差异性也可以通过所述多个关联特征的定性或定量分类来确定。定性分类可以基于基因组特征或多个基因组特征的存在或不存在。多个关联特征的定量分类可以包括关联至少两个关联特征或计算多个关联特征的相似性。关联可以包括在多个关联特征之间执行相关性检验。相关性检验可以包括例如皮尔森(pearson)、斯皮尔曼秩(spearman’s rank)、肯德尔秩(kendall’s rank)、双权中相关、距离相关性、折弯百分比、shepherd's pi、blomqvist、hoeffding's d、伽马、高斯秩(gaussian rank)、点双列和双列、多分格、四分格、部分或多级相关性检验,或其他类型的相关性检验。在一些情况下,可以使用一种或多种机器学习算法来分析关联特征或多个关联特征。例如,机器学习算法可以包括统计分类模型或聚类模型。分类模型可以包括k最近邻分类器、朴素贝叶斯分类器、支持向量机或神经网络。聚类模型可以包括层次聚类、分类聚类或k均值聚类。可以基于相似性评分来计算多个关联特征的相似性。相似性评分可以包括距离度量。距离度量可以包括欧几里得距离或曼哈坦距离。
286.在一些实施方案中,本文提供的用于产生和处理细胞或细胞核的关联特征的方法可以确定疾患。在一些实施方案中,如果关联特征与患有疾患的对照关联特征相似,则所述特征可以指示所述疾患。在其他情况下,如果关联特征与未患有疾患的对照关联特征相异,则所述特征可以指示所述疾患。在一些实施方案中,如果关联特征被分类为与患有疾患的对照关联特征类别相同,则所述特征可以指示所述疾患。在一些实施方案中,如果关联特征未被分类为与未患有疾患的对照关联特征类别相同,则所述特征可以指示所述疾患。在一些实施方案中,如果关联特征被鉴定为与患有疾患的对照关联特征聚类相同,则所述特征可以指示所述疾患。在一些实施方案中,如果关联特征未被鉴定为与未患有疾患的对照关联特征聚类相同,则所述特征可以指示所述疾患。
287.对照关联特征可以包括来自对照细胞样品的对照细胞或细胞核的关联特征。在一
些实施方案中,对照关联特征谱可以从样品或受试者群体获得。对照细胞样品的对照细胞或细胞核可以包括具有至少一种已知改变、疾患、变异、特征或特性的细胞或细胞核。
288.在一些实施方案中,细胞或细胞核可以源自体液。在一些情况下,体液可以包括血液、唾液、排泄物、身体组织、粘液、精液、尿液、羊水、房水、胆汁、母乳、脑脊液、耵聍、乳糜、渗出液、胃液、淋巴液、心包液、腹膜液、胸膜液、脓液、皮脂、浆液、痰液、滑液、泪液、呕吐物或组织液。在其他情况下,细胞或细胞核可以源自活检物。活检物可以包括用于确定疾患的存在或程度的组织或细胞样品。活检物可以包括来自淋巴结的细胞或组织。淋巴结可以包括来自头部、颈部、胸部、腹部、手臂或下肢的淋巴结集群。
289.疾患可以包括疾病状态或疾病状态风险。疾病状态可以指罹患疾病或症状的受试者。在一些实施方案中,受试者可能被诊断出或可能未被诊断出患有疾病状态。在一些实施方案中,受试者可能未罹患疾病,但可能处于发展疾病状态的风险中。在一些实施方案中,疾病状态或疾病状态风险可以包括与细胞生长、分裂、分化、迁移、复制或增殖有关的疾病。在一些实施方案中,疾患可以是肿瘤、癌症、恶性肿瘤、赘生物或其他增生性疾病或病症。在一些实施方案中,疾病状态可以包括非霍奇金淋巴瘤。在其他情况下,疾病状态可以包括b细胞恶性肿瘤或t细胞恶性肿瘤。在一些实施方案中,疾病状态可以包括b细胞淋巴瘤。b细胞淋巴瘤可以包括弥漫性大b细胞淋巴瘤(dlbcl)、滤泡性淋巴瘤、慢性淋巴细胞白血病(cll)、小淋巴细胞淋巴瘤(sll)、套细胞淋巴瘤(mcl)、边缘区淋巴瘤、伯基特淋巴瘤、淋巴浆细胞淋巴瘤(华氏巨球蛋白血症)、毛细胞白血病、节边缘区b细胞淋巴瘤、脾边缘区淋巴瘤、原发性渗出性淋巴瘤、淋巴瘤样肉芽肿病、原发性中枢神经系统淋巴瘤、alk+大b细胞淋巴瘤、浆母细胞淋巴瘤或原发性眼内淋巴瘤。
290.本文提供的用于确定疾患的方法可以包括对疾患的诊断评估、预后评估、监测和/或管理。所述方法可以包括测量基因表达和/或染色质可接近性,例如以确定受试者在治疗之前、期间或之后的状态。在一些实施方案中,可以在从疑似患有病症的个体获得的样品中分析由指示所述疾患的关联特征确定的一个或多个可接近染色质区域或所表达的所述一个和/或多个基因的水平。在一些情况下,为了分析从疑似患有疾患的个体获得的样品,针对个别细胞分析由指示疾患的关联特征确定的一个或多个可接近染色质区域和所表达的所述一个和/或多个基因。在一些情况下,为了分析从疑似患有疾患的个体获得的样品,所述分析包括检测表现出指示所述疾患的关联特征的细胞。在一些实施方案中,基因表达数据可用于鉴定与疾患和/或特定细胞类型相关的上调基因的功能基因集,例如,使用chen等人,“enrichr:interactive and collaborative html5 gene list enrichment analysis tool”bmc bioinformatics.2013;128(14);kuleshov等人,“enrichr:a comprehensive gene set enrichment analysis web server 2016update”nucleic acids research.2016;gkw377所描述的工具。
291.在一些实施方案中,可以进行对疾患的诊断评估、预后评估、监测或管理的受试者是b细胞淋巴瘤肿瘤或转移的生长或转移增加的受试者,或疑似患有b细胞淋巴瘤的受试者。在任何此类实施方案中的一些实施方案中,对体外生物样品进行对疾患的诊断评估、预后评估、监测或管理。在一些实施方案中,通过手术切除的组织活检物确定受试者患有b细胞淋巴瘤。根据b细胞淋巴瘤的类型,可以通过免疫细胞化学、流式细胞术、荧光原位杂交或dna/rna(包括但不限于qpcr、数字pcr、dna测序或rna测序)测试淋巴结或其他组织的切除
活检物。例如,dlbcl细胞是cd45阳性的并表达cd19、cd20、cd22、cd79a,并且仅表达κ或λ免疫球蛋白轻链之一。正在进行b细胞淋巴瘤评估、监测或管理的受试者还可以包括接受ct扫描。ct扫描可用于测量肿瘤块和疾病相关症状的频率。b细胞淋巴瘤相关症状可以包括盗汗、发热、体重减轻、疲劳、食欲减退、呼吸急促、腹痛、腹部肿胀、胸痛、咳嗽、淋巴结肿大、严重瘙痒或它们的任何组合。在其他实施方案中,b细胞淋巴瘤的诊断评估、预后评估、监测或管理可以基于b细胞淋巴瘤肿瘤生长、b细胞淋巴瘤病变数目、b细胞淋巴瘤细胞数目或它们的任何组合。受试者可能罹患任何疾患或有风险患上任何疾患。
292.本文提供了用于分析生物样品的方法,所述方法包括确定所述生物样品中细胞或细胞核的一个或多个关联特征(例如特征关联),其中所述关联特征包括以下项的相关性:(i)对应于细胞或细胞核的多个脱氧核糖核酸(dna)分子的可接近染色质区域的测序信息和(ii)对应于细胞或细胞核的多个核糖核酸(rna)分子(或其衍生物)的测序信息,其中生物样品内至少一个可接近染色质区域和至少一个rna表达在显著水平上的关联特征指示细胞或细胞核的疾患。
293.本文提供了用于制备生物样品的体外方法,所述体外方法包括:用转座酶处理来自所述生物样品的t细胞和/或b细胞的开放染色质结构以提供多个dna分子;产生包含所述多个dna分子的第一多个条形码化核酸分子;产生包含含有来自所述生物样品的所述t细胞和/或b细胞的mrna序列或其衍生物的多个核酸的第二多个条形码化核酸分子;以及分别从所述第一多个条形码化核酸分子和所述第二多个条形码化核酸分子产生第一测序文库和第二测序文库,以确定所述t细胞和/或b细胞的细胞的关联特征。在一些实施方案中,特征关联(例如关联特征)可用于确定跨基因组的相关基因表达和开放染色质区域。在一些情况下,特征关联(例如关联特征)可用于确定基因调控网络。在一些情况下,可以确定关联特征的显著性水平。在一些实施方案中,提供和离体处理从个体分离和获得的生物样品。在一些方面,所述方法还包括从个体获得生物样品。在一些方面,所述方法可以包括但不要求从个体获得生物样品的另外步骤。在一些实施方案中,生物样品的制备和处理是离体执行的。
294.在任何此类实施方案中的一些实施方案中,第一多个条形码化核酸分子和/或第二多个条形码化核酸分子的产生可以在多个分区内执行。在一些方面,所述方法包括逆转录来自所述生物样品的所述t细胞和/或b细胞的所述多个mrna序列以提供多个互补dna(cdna)分子,并且所述第二多个条形码化核酸分子包含所述cdna分子。在一些方面,所述方法包括对mrna的3’末端进行条形码化。在一些实施方案中,所述方法包括将t细胞和/或b细胞的单个细胞核包封在液滴中。在一些情况下,可以在产生第一多个条形码化核酸分子和/或第二多个条形码化核酸分子之前形成液滴。在一些实施方案中,第一多个条形码化核酸分子和第二多个条形码化核酸分子的产生是同时执行的。
295.在一些实施方案中,所述方法还包括由所述第一测序文库和所述第二测序文库确定与疾患有关的所述一个或多个关联特征的存在、不存在和/或水平。在一些情况下,所述疾患是肿瘤、癌症、恶性肿瘤、赘生物或其他增生性疾病或病症。在一些情况下,所述疾患是b细胞恶性肿瘤(例如b细胞淋巴瘤)。在一些实施方案中,一种或多种生物标志物(例如,基因、转录因子)可以使用特征关联(例如关联特征)来鉴定或选择。在一些实施方案中,用于诊断评估、预后评估、监测或管理受试者的疾患(例如b细胞淋巴瘤)的一种或多种生物标志物可以选自图50。例如,所鉴定的一种或多种生物标志物(例如基因)可以在b细胞和肿瘤b
细胞之间差异表达。在任何处理实施方案中的一些实施方案中,将来自受试者(例如t细胞和/或b细胞)的细胞或细胞核的关联特征与对照样品的对照细胞或细胞核的对照关联特征进行比较。
296.可以将给定剂量的剂施用于罹患疾患或处于疾患风险中的受试者。在受试者的状态确实改善的情况下,根据对受试者状态的监测确定,根据施用者(例如医生)的判断,可以连续进行剂的施用。可替代地,可以暂时减少或暂时暂停剂的剂量某一段时间(例如,“药物假期”)。药物假期的长度可以是数小时、数天、数月和数年。这种药物假期期间的剂量减少可以是任意量。一旦受试者的疾患出现改善或维持,例如可以在施用者的判断下向受试者施用维持剂量。随后,可以减少施用的剂量或频率,或两者。受试者可以在疾患复发时接受间歇性治疗。
297.可以向进行疾病诊断评估、预后评估、监测或管理的受试者施用治疗有效量的剂。
298.施用于受试者的给定剂的量可以与例如特定剂、疾病严重程度、需要治疗的受试者或宿主的特性(例如体重)等因素相对应并且根据这些因素而变化,但仍可以根据关于病例的特定情况(包括例如所施用的特定剂、施用途径和所治疗的受试者或宿主)以本领域已知的方式常规确定。化合物的术语“治疗有效量”和“有效量”通常是指足以在疾病的治疗、预防和/或管理中提供治疗益处从而延迟或最小化与待治疗的疾病或病症相关的一种或多种症状的量。术语“治疗有效量”和“有效量”可涵盖改善整体治疗、减少或避免疾病或病症的症状或原因、或增强另一治疗剂的治疗功效的量。所需剂量可宜以单次剂量形式提供或以同时(或在较短时间段内)或在适当间隔下施用的分次剂量形式,例如以每天两次、三次、四次或四次以上亚剂量形式提供。
299.在一些情况下,剂的治疗有效量可以被确定为当施用于受试者施用可以将如从受试者的样品确定的疾患或风险的关联特征改变为例如从对照样品确定的未患有疾病或没有疾病风险的关联特征的剂的量或剂量。在一些实施方案中,剂的治疗有效量可以包括使受试者的关联特征与参考关联特征(例如,已知患有疾患或已知不患有疾患)的相似性改变至少约5%、10%、15%、20%、25%、30%、40%、50%、60%、70%、80%、90%、99%或更多的剂的量。在一些情况下,剂的治疗有效量可以在施用该剂的该剂量后使肿瘤大小或疾病相关症状的频率降低至少5%、10%、15%、20%、25%、30%、40%、50%、60%、70%、80%、90%、99%或更多。的在一些实施方案中,治疗有效量可以在施用该剂的该剂量后使b细胞淋巴瘤肿瘤生长、b细胞淋巴瘤病变数目、b细胞淋巴瘤细胞数目或它们的任何组合降低至少5%、10%、15%、20%、25%、30%、40%、50%、60%、70%、80%、90%、99%或更多。
300.本文提供的方法及其方法可用于将一个或多个可接近染色质区域和/或一个或多个表达基因鉴定为治疗有效剂的一个或多个靶标。
301.在一些实施方案中,所述方法可以鉴定在具有相同疾患的细胞中具有相同可及性的一个或多个靶可接近染色质区域。在一些实施方案中,所述方法可以鉴定由具有相同疾患的细胞表达的一个或多个靶基因。在一些实施方案中,所述方法可以鉴定不由具有相同疾患的细胞表达的一个或多个靶基因。在一些情况下,所述方法可以鉴定由具有相同疾患的细胞以大致相同程度表达的一个或多个靶基因。治疗有效剂可以包括小分子、核酸、多肽、辐射或益生菌。在一些实施方案中,治疗有效的剂可以改变靶区域的染色质可接近性。在其他情况下,治疗有效的剂可以使靶区域的染色质可接近性改变而不同于患有已知疾患
的细胞的染色质可接近性。在其他实施方案中,治疗有效的剂可以使靶区域的染色质可接近性改变而与未患有疾患的细胞的染色质可接近性相似。在一些实施方案中,治疗有效的剂可以改变靶基因的表达。在其他情况下,治疗有效的剂可以使靶基因的表达改变而不同于患有疾患的细胞的基因表达。在其他实施方案中,治疗有效的剂可以使靶基因的表达改变而与未患有疾患的细胞的基因表达相似。
302.可以将治疗有效的剂配制成与其预期施用途径相容。用于肠胃外、皮内或皮下应用的溶液或悬浮液可包括以下组分:无菌稀释剂,例如注射用水、盐水溶液、不挥发油、聚乙二醇、甘油、丙二醇或其他合成溶剂;抗菌剂,例如苯甲醇或对羟基苯甲酸甲酯;抗氧化剂,例如抗坏血酸或亚硫酸氢钠;螯合剂,例如乙二胺四乙酸;缓冲剂,例如乙酸盐、柠檬酸盐或磷酸盐;以及用于调节张力的剂,例如氯化钠或右旋糖。ph可以用酸或碱(例如盐酸或氢氧化钠)调节。肠胃外制剂可以封装在由玻璃或塑料制成的安瓿、一次性注射器或多剂量小瓶中。
303.本公开的治疗有效剂的施用或应用可以进行至少约至少约1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、31、32、33、34、35、36、37、38、39、40、41、42、43、44、45、46、47、48、49、50、51、52、53、54、55、56、57、58、59、60、61、62、63、64、65、66、67、68、69、70、71、72、73、74、75、76、77、78、79、80、81、82、83、84、85、86、87、88、89、90、91、92、93、94、95、96、97、98、99或100天连续或不连续天的治疗持续时间。在一些情况下,治疗持续时间可为约1至约30天、约2至约30天、约3至约30天、约4至约30天、约5至约30天、约6至约30天、约7至约30天、约8至约30天、约9至约30天、约10至约30天、约11至约30天、约12至约30天、约13至约30天、约14至约30天、约15至约30天、约16至约30天、约17至约30天、约18至约30天、约19至约30天、约20至约30天、约21至约30天、约22至约30天、约23至约30天、约24至约30天、约25至约30天、约26至约30天、约27至约30天、约28至约30天或约29至约30天。本文公开的组合物的施用或应用可以进行至少约1周、至少约1个月、至少约1年、至少约2年、至少约3年、至少约4年、至少约5年、至少约6年、至少约7年、至少约8年、至少约9年、至少约10年、至少约15年、至少约20年或更长的治疗持续时间。施用可以在受试者的一生中重复进行,例如在受试者的一生中每月一次或每年一次。施用可以在受试者一生大部分时间重复进行,例如每月一次或每年一次,持续至少约1年、5年、10年、15年、20年、25年、30年或更长时间。
304.本文公开的治疗有效剂的施用或应用可以进行至少1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23或24次。在一些情况下,本文公开的组合物的施用或应用可以每周进行至少1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20或21次。在一些情况下,本文公开的组合物的施用或应用可以每月进行至少1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、31、32、33、34、35、36、37、38、39、40、41、42、43、44、45、46、47、48、49、50、51、52、53、54、55、56、57、58、59、60、61、62、63、64、65、66、67、68、69、70、71、72、73、74、75、76、77、78、79、80、81、82、83、84、85、86、87、88、89或90次。在一些情况下,治疗有效剂可以作为单剂量或分次剂量施用/应用。在一些情况下,本文所述的剂可以在第一时间点和第二时间点施用。在一些情况下,可以施用剂,使得第一次施用在另一次施用之前施用,施用时间差异为1小时、2小时、4小时、8小时、12小时、16小时、20小时、1天、2天、4天、7天、2周、4周、2个月、3个月、4个月、5个月、6个
月、7个月、8个月、9个月、10个月、11个月、1年或更长时间。
305.在一些实施方案中,本文公开的剂可以是单剂量形式或多剂量形式。例如,本文所述的治疗有效剂可以是单位剂量形式。如本文所用,单位剂量形式是指适合施用于人类或非人类受试者(例如,宠物、家畜、非人类灵长类动物等)并单独包装的物理离散单位。每个单位剂量可以含有预定量的一种或多种活性成分,这些活性成分与药物载体、稀释剂、赋形剂或它们的任何组合相结合足以产生所需的治疗效果。单位剂量形式的实例可以包括安瓿、注射器和单独包装的片剂和胶囊。在一些情况下,单位剂量形式可以包含在食物中。在一些情况下,单位剂量形式可以分次或多次施用。多剂量形式可以是包装在单个容器中的多个相同的单位剂量形式,它们可以以分离的单位剂量形式施用。多剂量形式的例子可以包括小瓶、药片瓶或胶囊瓶、软糖瓶或品脱或加仑瓶。在一些情况下,多剂量形式可以包含不同的药物活性剂。在一些实施方案中,单位剂量形式可以是一份。在一些情况下,多剂量形式可具有多于约:1、2、3、4、5、6、7、8、9、10、15、20、30、40、50、60、70、80、90、100或200份。在一些实施方案中,多剂量形式可具有少于约:1、2、3、4、5、6、7、8、9、10、15、20、30、40、50、60、70、80、90、100或200份。在一些情况下,多剂量形式可具有约:1份至约200份、1份至约20份、5份至约50份、10份至约100份或约30份至约150份。
306.本文提供的确定疾患的方法及其方法可用于在施用治疗有效剂之前、期间或之后监测疾患。在一些实施方案中,剂的治疗有效剂量、给药方案、施用途径可以基于对疾患的监测进行修改。这种修改可以减少或增加剂的治疗有效剂量、给药方案、施用途径。在其他情况下,对疾患的监测可以包括转换、添加或去除治疗有效的剂。
307.根据各个实施方案,图43中提供了一般示意性工作流程4300,示出了用于特征关联分析的特征关联分析工作流程的非限制性示例性过程。工作流程4300可以包括特征的各种组合,无论是比图43中所示的特征更多还是更少的特征。因此,图43简单地说明了用于执行特征关联分析的可能工作流程的一个实例。
308.图43提供了用于执行特征关联分析的示意性工作流程4300。应认识到,图43的工作流程4300和随附描述中描述的方法可以独立于一般描述的用于产生单细胞基因表达测序数据或单细胞atac测序数据的方法来实施。因此,图43只要能够充分分析单细胞测序数据集以进行特征关联分析,就可以独立于测序数据产生工作流程来实施。
309.此外,数据分析工作流程可以包括图43所示的一个或多个分析操作。本公开内图43的所有操作并不都需要作为一个组使用。因此,图43内的一些操作能够作为本文公开的各个实施方案的一部分独立地执行必要的数据分析。因此,本公开内的某些操作可以单独使用,也可以与本公开内的其他操作结合使用,而本公开内的某些其他操作只能与本公开内的某些其他操作结合使用。此外,下文描述的一个或多个操作(假定默认用作计算流程的一部分)也不能根据用户输入来使用。应当理解,也设想相反的情况。还应当理解,用于分析所产生的测序数据的另外操作也被设想为本公开内的计算流程的一部分。
310.联合特征-条形码矩阵
311.在操作4310中,可以产生和接收联合特征-条形码矩阵。联合特征-条形码矩阵可以通过基因表达数据处理和atac数据处理产生。例如,联合细胞条形码矩阵可以包括每个条形码的每个峰区域内的片段末端(切割位点)的计数和每个条形码的umi计数。
312.矩阵归一化
313.在操作4320中,可以对联合特征-条形码矩阵进行归一化以产生归一化矩阵。归一化可以减少由每个单细胞的总信号的方差引入的偏差。每个细胞的总信号,可替代地称为深度,可以是基因表达的独特分子标识符(umi)的总和,或者是atac中总切割位点的总和。
314.以前的归一化方法将为特征关联分析产生很强的伪影,因此可以使用深度自适应负二项分布模型来克服这个缺陷。归一化可以包括选择在预设大小的基因组窗口(例如,100kb、200kb、300kb、400kb、500kb、600kb、700kb、800kb、900kb、1mb、1.5mb、2mb或任何中间范围或从中的值)内的多个细胞中的每一细胞中检测到的基因组特征。
315.归一化还可以包括使用深度自适应负二项分布模型来模拟联合特征-条形码矩阵的分子计数,其中假设每个基因组特征的分布均值随着每个细胞的文库大小线性变化。负二项分布是与离散随机变量一起使用的概率分布。这种类型的分布涉及为了获得预定数量的成功而必须进行的试验次数。在各个实施方案中,深度自适应负二项分布模型可以应用于至少两种数据类型,包括但不限于基因表达数据和atac数据两者。例如,归一化矩阵计数是原始计数x
ij
基于如下所示非限制示例性公式的归一化值:
[0316][0317][0318][0319][0320][0321][0322]
其中x
ij
是特征i和细胞j的特征-条形码矩阵的条目,并且是特征i和细胞j的归一化值。“μ帽”和“r帽”代表负二项式均值和离散度。
[0323]
矩阵平滑
[0324]
在操作4330中,联合特征-条形码矩阵可以通过k最近邻(knn)距离和高斯核来平滑以产生细胞-细胞相似性矩阵。
[0325]
由于单细胞数据(特别是峰中的切割位点计数)的稀疏性,当预期峰和基因都具有高表达水平时,很可能无法在一个细胞中同时检测到峰和基因的信号。因此,直接计算在多个细胞中的每一细胞中检测到的两个基因组特征之间的原始计数的相关性或其他依赖性量度可能无法产生任何有意义的值能将高度共同表达的特征与其余特征区分开来。
[0326]
为了克服这个障碍,可以执行平滑,以便通过从“相邻”细胞“借用”相同特征的值来增强给定细胞中的特征值。在此,相邻细胞描述了其基因表达谱或atac谱共享高相似性即低距离的细胞群体。例如,该距离是欧几里得距离。欧几里得距离或欧几里得度量是欧几里得空间中两点之间的“普通”直线距离。
[0327]
可以通过在主成分分析(pca)降维上应用称为“球树(ball-tree)”的k最近邻算法来确定高相似性。例如,球树最近邻算法以深度优先顺序检查节点,从根开始。在搜索过程
中,算法维护目前遇到的k最近点的最大优先级群组(通常用堆实现),此处用q表示。主成分分析(pca)是一种主要的线性降维技术,它将数据线性映射到低维空间,使数据在低维表示中的方差最大化。
[0328]
平滑包括从相邻细胞“借用”信息。在各个实施方案中,信息“借用”可以通过使用k最近邻距离(例如,k=30)的所有预定数量的相邻细胞的信号的加权求和来实现。k可以选择为10、20、30、40、50、60、70、80、90、100或任何中间范围或值,这取决于给定数据集中有多少细胞。例如,如果可用的细胞超过10,000个,则可能会选择更大的k值(k=50)。
[0329]
在各个实施方案中,细胞间相似性矩阵可以确定平滑权重。平滑权值可以基于基因表达主成分确定为欧几里得距离,使得只有当细胞i和j相邻且没有自边时,权重wij才为正。
[0330]
此外,为了避免过度平滑,可以使用高斯核对原始距离进行归一化:
[0331][0332]
在某些实施方案中,基于高斯核的使用,仅当两个细胞具有高度相似的基因表达谱时平滑权重较高,当细胞之间的相似性降低时平滑权重迅速衰减至零。用于平滑的“核”限定了用于取相邻点平均值的函数的形状。高斯核是具有高斯(正态分布)曲线形状的核。
[0333]
平滑后,与随机选择的特征对相比,假定的共表达特征显示出非常强的相关模式。
[0334]
平滑后的矩阵
[0335]
在操作4340中,可以通过来自操作4320的归一化矩阵和来自操作4330的细胞-细胞相似性矩阵来产生平滑后的矩阵。例如,可以通过将归一化矩阵与细胞-细胞相似性矩阵相乘来产生平滑后的矩阵。
[0336]
特征关联相关性
[0337]
在操作4350中,可以产生特征关联相关性。关联相关性是关联强度的直接量度,其取值范围为[-1,1]。相关性的符号表示正相联或负相联。它提供了一个非常可解释的关联强度量度。
[0338]
例如,可以通过计算在多个细胞中的每一细胞中检测到的两个基因组特征之间的皮尔森相关系数作为平滑之后的关联相关性来产生特征关联相关性。
[0339]
相同长度的向量x和y的皮尔森相关系数r
xy
称为皮尔森相关性,可以如下计算:
[0340][0341]
其中{(x1,y1)、(x2,y2)、...、(xn,yn)}是x和y的配对数据,i是细胞编号(1、2、3、...、n),并且n是样本大小。
[0342]
工作流程4300可以包括在操作4370中产生特征关联显著性。在各个实施方案中,特征关联显著性可以作为概率评分生成。
[0343]
特征关联显著提供了特征关联推断的统计不确定性的量度,并提供了强关联相对于弱关联的更多对比。可以通过确定在多个细胞中的每一细胞中检测到的至少两个基因组
特征之间的关联的局部相关值并将该值转换为高斯随机变量来产生显著性。该方法允许进行假设检验。
[0344]
例如,关联显著性是使用基于hotspot(detomaso等人,detomaso,d.,&yosef,n.(2020).identifying informative gene modules across modalities of single cell genomics.biorxiv,2020.02.06.937805)的局部相关性改进和扩展的改良算法计算的。
[0345]hxy
=w
ij
(xiyj+yixj)
[0346]
e(h
xy
)=0
[0347][0348][0349]
具体来说,通过将detomaso等人的基于循环的程序转换为基于矩阵乘法运算的程序,hxy和e(hxy2)的计算显著加快。在此矩阵乘法运算中,表示为z评分“zxy帽”的n个特征对(例如10,000个特征对)的局部相关性可以在一次运算操作中生成,而不是在n次运算(例如10,000次运算)循环中生成。
[0350]
另外和替代地,局部相关z评分可以扩展到假设检验框架以生成概率评分。由于z评分在上述归一化操作的基础上遵循均值0和方差1的高斯分布,因此可以将其转换为概率评分并进行多次测试校正。
[0351]
结果值是给定特征对x和y是否显著相关的错误发现率。
[0352]
稀疏性生成
[0353]
在操作4370中,工作流程4300可以包括稀疏性生成。稀疏统计模型是指只有相对较少数量的参数(或预测因子)发挥重要作用的模型。由于可计算关联的数量是特征数量的二次元,并且预计大多数可计算关联在生物学上都不显著,因此在特征关联的推断中自然会出现稀疏性。
[0354]
由于大多数特征关联都不显著,因此可以将显著性低于预设阈值的关联子集过滤掉,并使用稀疏关联矩阵进行更好的解释。可以基于特征显著性来选择阈值。对于特定实例,可以使用阈值化方法,将显著性《5的关联从关联矩阵中除去。阈值可以通过对连续下采样读段的分析以及对关联显著性和相关性衰减的比较来确定。例如,显著性=5可能对下采样的关联强度和稳定性有最好的平衡。在各个实施方案中,阈值化可以使用特征显著性阈值,例如大于或等于4、4.5、5、5.5、6或从中派生的任何中间范围或值的显著性,用于选择特征关联。在另外和替代实施方案中,阈值化可以使用相关值来设置,例如,相关值大于0.2、0.25、0.3、0.35、0.4、0.45、0.5或任何中间值或范围的特征关联可以被选择并设置为用于选择特征关联的阈值。
[0355]
可以使用几种稀疏性生成策略。例如,稀疏性生成可以使用阈值化,即排除具有预设相关性或显著性阈值的关联。基于其简单性、可解释性和对差异表达的良好一致性,阈值化可能是稀疏性生成策略的一个特定实例。
[0356]
在另外和替代实施方案中,稀疏性生成可以使用高斯图形模型(ggm)。ggm是一种无向图,其中每条边表示两个变量之间的两两相关,条件是与所有其他变量的相关(也称为偏相关系数)。ggm在线性回归技术方面有一个简单的解释。当对数据集中其余变量的两个随机变量x和y进行回归时,x和y之间的偏相关系数可以通过两次回归的残差的皮尔森相关性来确定。直观地说,我们除去所有其他变量对x和y的(线性)影响,并比较剩余的信号。如果变量仍然相关,则相关性直接由x和y的关联决定,而不由其他变量介导。
[0357]
几种基于ggm的方法已经过测试并且可以使用,包括但不限于图形套索、松弛图形套索、协方差的稀疏估计和稀疏steinian协方差估计。ggm的好处是它具有强大的统计框架并允许特定于关联的正则化。然而,基于精度矩阵优化的ggm算法会产生假阴性,从而错误地将强关联机构确定为零。可能需要使用优化协方差矩阵的ggm来改进基于ggm的稀疏性生成。
[0358]
特征关联矩阵
[0359]
工作流程4300可以包括在操作4380下在稀疏性生成之后生成特征关联矩阵以用于下游分析。
[0360]
特征关联分析方法
[0361]
在各个实施方案中,提供了用于特征关联分析的方法。所述方法可以通过计算机软件或硬件来实现。所述方法还可以在可包括用于特征关联分析的引擎组合的计算装置/系统上实现。在各个实施方案中,计算装置/系统可以通过直接连接或通过互联网连接以通信方式连接至数据源、样品分析仪(例如基因组序列分析仪)和显示装置中的一者或多者。
[0362]
现在参考图44,根据各个实施方案,公开了示出用于特征关联分析的非限制性示例性方法4400的流程图。所述方法可以包括在操作4402下接收包含针对多个细胞中的每一细胞检测的至少两个基因组特征的数据矩阵。例如,至少两个基因组特征可以是基因表达特征(例如基因和mrna)和转座酶可接近染色质(atac)特征(例如开放染色质区域或可接近染色质区域)的测定。例如,数据矩阵可以是联合特征-条形码矩阵,其包含每个条形码的切割位点和umi的数据。在另外和替代实施方案中,数据矩阵可以从如上文所讨论的单细胞测序、sci-car或snare-seq或它们的组合产生。
[0363]
所述方法可以包括在操作4404下使数据矩阵平滑以生成平滑后的矩阵,其中使数据矩阵平滑包括将数据矩阵中针对每一细胞鉴定的第一基因组特征和第二基因组特征以及来自相邻细胞的子集的第一基因组特征和第二基因组特征归一化。将数据矩阵归一化可以包括使用深度自适应负二项分布模型来对数据矩阵(例如联合特征-条形码矩阵)的分子计数进行建模。
[0364]
所述方法可以包括在操作4406下生成数据矩阵中针对多个细胞中的每一细胞鉴定的第一基因组特征和第二基因组特征之间的关联相关性。例如,可以通过计算两个基因组特征之间的皮尔森相关系数作为平滑之后的关联相关性来生成特征关联相关性。
[0365]
所述方法可以包括在操作4408下生成数据矩阵中针对多个细胞中的每一细胞鉴定的第一基因组特征和第二基因组特征的对的关联相关性的关联显著性。在各个实施方案中,特征关联显著性可以作为概率评分生成。例如,可以通过使用多个关联矩阵的乘法运算来生成特征关联显著性。每个关联矩阵可以包含数据矩阵中针对多个细胞中的每一细胞鉴定的第一基因组特征和第二基因组特征的对的关联相关性。
[0366]
在另外和替代实施方案中,可以使用矩阵乘法运算来生成特征关联显著性。在此矩阵乘法运算中,表示为z评分“zxy帽”的n个特征对(例如10,000个特征对)的局部相关性可以在一次运算操作中生成,而不是在n次运算(例如10,000次运算)循环中生成。
[0367]
所述方法可以包括在操作4410下输出关联相关性和关联显著性。
[0368]
在一些方面,特征关联、相关性和/或显著性可以用作生物颗粒(例如细胞和/或细胞核)的关联特征。在一些情况下,特征关联、相关性和/或显著性可用于生成多个生物颗粒(例如细胞和/或细胞核)中的每一者的多个关联特征。
[0369]
图40说明了用于鉴定对应于表达蛋白的遗传特征的方法的示例性工作流程。在过程4010中,将染色质测序信息和基因表达测序信息与细胞和/或细胞核相关联。在过程4020中,将细胞和/或细胞核表征为对应于特定细胞类型。在过程4030中,将基因表达测序信息用于鉴定表达蛋白。在过程4040中,将染色质测序信息用于鉴定对应于表达蛋白的遗传特征,例如顺式调控元件(例如启动子或增强子)。
[0370]
进行本文提供的分析的多个细胞或细胞核可以包含至少500个细胞。例如,多个细胞或细胞核可以包含至少500、1,000、2,000、5,000、7,500、10,000或更多个细胞或细胞核。
[0371]
可能与差异表达的蛋白有关的遗传特征可能位于附近基因的上游。可替代地,遗传特征可能位于附近基因的下游。在一些情况下,遗传特征可远离它可能影响的基因布置。
[0372]
顺式调控元件(cre)可能是调控附近基因转录的非编码dna区域。顺式调控元件可以位于转录位点的上游。可替代地,例如增强子之类的顺式调控元件可以位于其调控的基因的下游。顺式调控元件可以是例如启动子、增强子、操纵子或沉默子。启动子可能出现在转录起始的位点。启动子可以包括tata盒、转录因子ii b(tfiib)鉴定位点、启动子和核心启动子元件中的一者或多者。增强子可以影响(例如,增强)基因的转录。调节基因的顺式调控元件可以是影响基因转录的多个顺式调控元件(例如启动子和增强子)之一。顺式调控元件可替代地可以是抑制基因转录的沉默子或操纵子。
[0373]
例如顺式调控元件的遗传特征可以与表观遗传标志物有关,所述表观遗传标志物例如有包括在数据库例如策划的genehancer数据库中的表观遗传标志物。表观遗传标志物可以包含差异甲基化区域。表观遗传修饰的一个实例是h3k4me1,它包括组蛋白h3蛋白的第4个赖氨酸残基处的单甲基化。h3k4me1是各种基因的增强子特征。
[0374]
本文提供的方法可以促进跨各种细胞类型的相对蛋白表达的预测。在一些情况下,在对应于给定蛋白的一组细胞类型的可接近染色质数据中可测量的启动子峰可能无法预测蛋白表达。然而,启动子峰与另外遗传特征(例如,如上文所述的顺式调控元件)的相关性使得可以预测跨该组细胞类型的相对蛋白表达。该信息可能有助于开发包括各种癌症在内的疾病类型的诊断方法和疗法。
[0375]
除了鉴定遗传特征外,染色质信息还可用于分析其他蛋白质的活化和/或失活,包括信号转导子(例如,信号转导子与转录活化子(stat))蛋白。例如,可以分析潜伏蛋白例如stat蛋白的活化。此类蛋白是潜伏的胞质蛋白,使得表达不能很好地代表功能。染色质信息可用于鉴定给定结合基序对这种蛋白质的可接近性,并由此鉴定对给定细胞类型(例如,对肿瘤细胞类型)蛋白的活化。
[0376]
本文所述的方法可用于分析细胞群体,包括病变细胞例如肿瘤细胞。本文提供的方法可以包括使用测序信息来鉴定样品中肿瘤细胞或细胞核的存在。因此,本文提供的方
法可用于诊断评估。本文提供的方法还可以或可替代地包括使用测序信息来鉴定样品中的细胞类型、细胞状态、肿瘤特异性基因表达模式或肿瘤特异性差异性可接近染色质区域。至少部分地基于这样的分析,可以确定例如用于样品所源自的受试者的治疗方案。治疗方案可以包括施用治疗有效量的靶向以肿瘤特异性基因表达模式或肿瘤特异性差异性可接近染色质区域鉴定的一个或多个靶标的剂。
[0377]
本文提供的方法还可用于鉴定与各种疾病相关的单核苷酸多态性(snp)。将snp与特定疾病相关联的其他方法可能依赖于对染色质区域的分析,这些区域很容易与表达蛋白相关联。本公开通过提供一种用于鉴定可能与特定细胞类型(包括病变细胞)的基因表达相关的遗传特征(例如调控区)的机制改进了此类方法。因此,在另一方面,本公开提供了一种用于鉴定与疾病相关的单核苷酸多态性或其他遗传特征的方法。所述方法可以包括提供对应于多个细胞或细胞核的多个dna分子(例如染色质)的可接近染色质区域的第一数据集和对应于所述多个细胞或细胞核的多个rna分子的第二数据集。第一数据集可以包含对应于可接近染色质区域的序列和多个核酸条形码序列的测序信息(例如第一多个测序读段)。第二数据集可以包含对应于多个rna分子的序列和多个核酸条形码序列的测序信息(例如第二多个测序读段)。多个细胞或细胞核中的细胞或细胞核可以对应于所述多个核酸条形码序列中的核酸条形码序列。例如,包含含有所述多个核酸条形码序列的共同核酸条形码序列的多个核酸条形码分子的颗粒可用于处理所述多个细胞或细胞核中的细胞或细胞核的多个dna分子和rna分子(例如,在分区内)(如本文所述)。第一数据集和第二数据集的多个核酸条形码序列可用于将所述第一多个测序读段中的第一测序读段和所述第二多个测序读段中的第二测序读段鉴定为对应于所述多个细胞或细胞核中的细胞或细胞核,由此产生包含对应于与所述多个细胞或细胞核中的细胞或细胞核相关的可接近染色质区域和rna分子的序列信息的第三数据集。可以使用所述第三数据集的序列信息来鉴定细胞或细胞核的细胞类型。对应于rna分子的序列信息可用于鉴定所鉴定的细胞类型中的细胞类型的表达蛋白,例如针对病变细胞状态差异表达的蛋白质。对应于可接近染色质区域的序列信息可用于鉴定对应于所述表达蛋白的snp或其他遗传特征例如顺式调控元件,由此鉴定与病变细胞状态相关的snp或其他遗传特征。
[0378]
转录网络构建与分析
[0379]
在一些实施方案中,从工作流程4300的操作4380产生的特征关联矩阵可以用于进一步的下游分析,例如,以构建转录网络或转录因子(tf)网络。例如,用于构建tf网络的示例性工作流程在图47中描述。在一些方面,从峰-基因特征关联开始,峰和基因可以分别使用基序富集和差异表达分析进行过滤。其余的峰可以进一步映射到基序。在一些实施方案中,可以使用构建转录网络的三步法。首先,通过设置p值的阈值(例如,《10^-20),使用肿瘤细胞中差异表达的基因来产生在特定疾患中(例如,在肿瘤细胞中)上调的基因的列表。接下来,可以将基因列表与推断的特征关联相交以鉴定与疾患(例如肿瘤特异性基因)有关的峰。最后,基序富集分析可用于鉴定肿瘤细胞中具有富集基序的转录因子。在一些实施方案中,具有关联靶基因的富集转录因子可用于限定tf调控网络的边缘。
[0380]
在一些实施方案中,所述方法包括进行基序富集分析。在一些实例中,可以鉴定在疾患中(例如,相对于正常b细胞在肿瘤b细胞中)具有增加的可接近性的转录因子基序。在一些情况下,执行全局富集,包括使用两个群体(例如,两个细胞或细胞核群体)之间的所有
峰来估计富集。在一些方面,可以使用chromvar和双样本t检验评估两个群体之间(例如,肿瘤细胞和正常b细胞之间)每个基序的tf偏差z评分。在一些实施方案中,将两个群体之间的推断平均差进一步z评分为富集评分。在一些实施方案中,所述方法包括仅在与最高肿瘤上调基因关联的峰中鉴定基序富集。在一些情况下,执行背景依赖性富集,包括通过将潜在的肿瘤特异性增强子与一组共享肿瘤细胞中的gc和可接近性谱的背景峰进行比较,在肿瘤背景下估计的富集。例如,可以使用与chromvar类似的策略计算一组背景峰,改动是匹配每个细胞的gc含量和峰大小,而不是gc含量和切割位点。在一些实施方案中,通过增强子峰和背景峰中基序出现的超几何检验来确定基序富集。在一些实施方案中,鉴定了一个或多个富集基序(例如,全局分析中排名最高的基序和背景特定分析中排名最高的基序)。在一些情况下,可以去除冗余tf基序序列并例如通过基于基序聚类将已鉴定的基序分组到家族中进行进一步处理(fornes等人,(2020)nucleic acids research,48(d1):d87
–
d92)。
[0381]
用于样品划分的系统和方法
[0382]
在一个方面,本文所述的系统和方法提供一个或多个颗粒(例如生物颗粒、生物颗粒的大分子成分、珠粒、试剂等)划分、沉积或分配至离散隔室或分区(本文中可交换地称为分区),其中每个分区维持其自身的内容物与其他分区的内容物分开。分区可以是乳液中的液滴或孔。分区可以包括一个或多个其他分区。
[0383]
分区可以包括一个或多个颗粒。分区可以包括一种或多种类型的颗粒。例如,本公开的分区可以包含一个或多个生物颗粒和/或其大分子成分。分区可以包含一个或多个珠粒。分区可以包含一个或多个凝胶珠粒。分区可以包含一个或多个细胞珠粒。分区可以包括单个凝胶珠粒、单个细胞珠粒,或单个细胞珠粒和单个凝胶珠粒两者。分区可以包括一种或多种试剂。可替代地,分区可以是未被占用的。例如,分区可以不包含珠粒。细胞珠粒是例如经由含有生物颗粒的液滴与能够聚合或胶凝的前体的聚合而包裹在凝胶或聚合物基质内的生物颗粒和/或其大分子成分中的一种或多种。可以在液滴产生之前、之后或同时如通过微胶囊(例如珠粒)将独特标识符(例如条形码)注射到液滴中,如本文别处所述。
[0384]
本公开的方法和系统可以包括用于生成一个或多个分区例如液滴的方法和系统。液滴可以包括乳液中的多个液滴。在一些实例中,液滴可以包括在胶体中的液滴。在一些情况下,乳液可以包含微乳液或纳米乳液。在一些实例中,液滴可以借助微流体装置和/或通过使不混溶相的混合物经受搅拌(例如,在容器中)来产生。在一些情况下,上述方法的组合可用于液滴和/或乳液形成。
[0385]
液滴可以通过混合和/或搅拌不混溶相产生乳液来形成。混合或搅动可以包括各种搅动技术,例如涡旋、移液、管弹或其他搅拌技术。在一些情况下,可以在不使用微流体装置的情况下进行混合或搅拌。在一些实例中,液滴可以通过将混合物暴露于超声波或声处理来形成。在国际申请第pct/us20/17785号中描述了用于通过搅拌产生液滴和/或乳液的系统和方法,所述申请出于所有目的以引用的方式整体并入本文。
[0386]
包括微流体通道网络(例如,在芯片上)的微流体装置或平台可用于产生如本文所述的分区,例如液滴和/或乳液。在美国专利公布第2019/0367997号和第2019/0064173号描述了以下各项:用于产生分区(例如液滴)的方法和系统,包封生物颗粒的方法,增加液滴产生的吞吐量的方法,以及微流体装置和通道的各种几何形状、架构和配置,这些文献中的每一者出于所有目的以引用的方式整体并入本文。
[0387]
在一些实例中,可以通过将水性流体中的流动颗粒流引入到非水性流体的流动流或储器中来将单独颗粒分配到离散分区中,使得可以在两个流/储槽的交汇点处(例如,在本文别处提供的微流体装置的接点处)产生液滴。
[0388]
本公开的方法可以包括产生分区和/或包封颗粒,例如分析物载体或分析物载体,在一些情况下,单独的分析物载体,例如单个细胞。在一些实例中,试剂可以被包封和/或分配(例如,与分析物载体共同分配)在分区中。可以采用各种机制分配单独颗粒。一个实例可以包括多孔膜,细胞的水性混合物可以通过多孔膜被挤出到流体(例如,非水性流体)中。
[0389]
分区可在流体流内流动。分区可以包含例如微泡,所述微泡具有环绕内部流体中心或核心的外部屏障。在一些情况下,分区可以包括能够将材料夹带和/或保留在其基质内的多孔基质。分区可以是第一相在第二相内的液滴,其中第一相和第二相不可混溶。例如,分区可以是水性流体在非水性连续相(例如油相)内的液滴。在另一实例中,分区可以是非水性流体在水相内的液滴。在一些实例中,分区可以以油包水乳液或水包油乳液的形式提供。在例如美国专利申请公布第2014/0155295号中描述了多种不同的容器,所述申请出于所有目的以引用的方式整体并入本文。在例如美国专利申请公布第2010/0105112中描述了用于在非水或油连续相中产生稳定液滴的乳液体系,所述申请出于所有目的以引用方式以引用的方式整体并入本文。
[0390]
可以调节流体特性(例如流体流速、流体粘度等)、颗粒特性(例如体积分数、粒度、颗粒浓度等)、微流体架构(例如通道几何形状等)以及其他参数以控制所得分区的占用率(例如,每个分区的生物颗粒数量、每个分区的珠粒数量等)。例如,可以通过提供一定颗粒浓度和/或流速的水流来控制分区占用率。为了产生单个生物颗粒分区,可以选择不混溶流体的相对流速,使得所述分区可以每个分区含少于一个生物颗粒,以便确保被占用的那些分区主要被单个地占用。在一些情况下,多个分区中的分区至多可以含有一个生物颗粒(例如,珠粒、dna、细胞或细胞物质)。在一些实施方案中,可以选择或调节各种参数(例如流体特性、颗粒特性、微流体结构等),使得大部分分区被占用,例如,仅允许一小部分分区未被占用。可以控制流量和通道架构以确保给定量的单个已占用分区,低于某一水平的未占用分区和/或低于某一水平的多个已占用分区。
[0391]
图1示出了用于分配单独的生物颗粒的微流体通道结构100的一个实例。通道结构100可以包括在通道接点110处连通的通道区段102、104、106和108。在操作中,包括悬浮生物颗粒(或细胞)114的第一水性流体112可以沿通道区段102转运到接点110处,而与水性流体112不可混溶的第二流体116从通道区段104和106中的每一个递送至接点110处以产生第一水性流体112的离散液滴118、120,第一水性流体流入通道区段108中,并且从接点110处流走。通道区段108可以与出口储槽流体联接,可以将离散液滴储存和/或收获在出口储槽中。生成的离散液滴可以包括单独的生物颗粒114(例如液滴118)。生成的离散液滴可以包括多于一个的单独生物颗粒114(在图1中未示出)。离散液滴可以不含生物颗粒114(例如液滴120)。每个离散分区可以保持其自身内容物(例如,单独的生物颗粒114)与其他分区的内容物分离。
[0392]
第二流体116可以包含油,例如含氟油,所述油包括用于稳定所得液滴,例如抑制所得液滴118、120的后续聚结的含氟表面活化剂。特别有用的分配流体和含氟表面活性剂的实例描述于例如美国专利申请公布第2010/0105112号中,所述申请出于所有目的以引用
的方式整体并入本文。
[0393]
正如将认识到的,本文所述的通道区段可联接至多种不同流体源或接收部件(包括储槽、管道、歧管或其他系统的流体部件)中的任一者。正如将认识到的,微流体通道结构100可以具有其他几何形状。例如,微流体通道结构可以具有多于一个通道接点。例如,微流体通道结构可以具有2、3、4或5个通道区段,每个通道区段都携带有颗粒(例如,生物颗粒、细胞珠粒和/或凝胶珠粒),这些通道区段在通道接点处会合。可以引导流体经由一个或多个流体流动单元沿一个或多个通道或储槽流动。流体流动单元可以包括压缩机(例如,提供正压)、泵(例如,提供负压)、致动器等,以控制流体的流量。流体还可以或以其他方式通过施加的压力差、离心力、电动泵送、真空、毛细管流或重力流等来控制。
[0394]
产生的液滴可包括两个液滴子集:(1)已占用液滴118,其包含一个或多个生物颗粒114,和(2)已占用液滴120,其不包含任何生物颗粒114。已占用液滴118可以包括单个地占用的液滴(具有一个生物颗粒)和多个地占用的液滴(具有多于一个生物颗粒)。如本文别处所述,在一些情况下,大多数已占用分区中每个已占用分区可以包括不超过一个生物颗粒,并且生成的一些分区可未被占用(未被任何生物颗粒占用)。然而,在一些情况下,一些已占用分区可以包括多于一个生物颗粒。在一些情况下,可以控制分配过程,使得少于约25%的已占用分区含有多于一个生物颗粒,并且在许多情况下,少于约20%的已占用分区具有多于一个生物颗粒,而在一些情况下,少于约10%或甚至少于约5%的已占用分区的每个分区包括多于一个生物颗粒。
[0395]
在一些情况下,可能希望最小化过多数量的空分区的产生,例如以降低成本和/或提高效率。虽然这种最小化可以通过在分配接点110处提供足够数量的生物颗粒(例如,生物颗粒114)来实现,以便确保至少一个生物颗粒包封在分区中,但是泊松分布(poissonian distribution)可以预期地增加包括多个生物颗粒的分区的数量。因此,在要获得单个地占用的分区的情况下,所生成的分区中至多约95%、90%、85%、80%、75%、70%、65%、60%、55%、50%、45%、40%、35%、30%、25%、20%、15%、10%、5%或更少可未被占用。
[0396]
在一些情况下,可以控制一个或多个生物颗粒(例如,在通道区段102中)的流动,或者引导到分配接点中的其他流体(例如,在通道区段104、106中)的流动,使得在许多情况下,不多于约50%产生的分区、不多于约25%产生的分区或不多于约10%产生的分区未被占用。可以控制这些流量,以呈现单个占用分区的非泊松分布,同时提供较低水平的未占用分区。可以实现上述未占用分区的范围,同时仍提供上述任何单个占用率。例如,在许多情况下,本文所述的系统和方法的使用可以产生所得分区,所得分区具有小于约25%、小于约20%、小于约15%、小于约10%的多个占用率,并且在许多情况下,小于约5%,而未占用分区小于约50%、小于约40%、小于约30%、小于约20%、小于约10%、小于约5%或更少。
[0397]
正如将认识到的,上述占用率也适用于包括生物颗粒和附加试剂两者的分区,包括但不限于携带有条形码化核酸分子(例如,寡核苷酸)的微囊或珠粒(例如,凝胶珠粒)(相对于图2描述)。已占用分区(例如,至少约10%、20%、30%、40%、50%、60%、70%、80%、90%、95%或99%的已占用分区)可以包括包含条形码化核酸分子的微囊(例如,珠粒)和生物颗粒两者。
[0398]
在另一个方面,除了基于液滴的分配或作为其替代方案,生物颗粒可以包封在微胶囊内,所述微胶囊包括外壳、层或多孔基质,其中夹带一个或多个单独的生物颗粒或小组
生物颗粒。微囊可以包括其他试剂。生物颗粒的包封可以通过多种方法进行。此类方法可以将含有生物颗粒的含水流体与聚合物前体材料组合,所述聚合物前体材料在将特定刺激施加到聚合物前体时能够形成凝胶或其他固体或半固体基质。此类刺激可以包括例如热刺激(例如,加热或冷却)、光刺激(例如,通过光固化)、化学刺激(例如,通过交联、前体的聚合引发(例如,通过添加的引发剂))、机械刺激或它们的组合。
[0399]
包含生物颗粒的微胶囊的制备可以通过多种方法执行。例如,可以使用气刀液滴或气溶胶发生器将前体流体的液滴分配到胶凝溶液中,以便形成包括单独的生物颗粒或小群生物颗粒的微囊。同样,可以使用基于膜的包封系统来生成包含如本文所述的包封生物颗粒的微囊。如本文所述,本公开的微流体系统,例如图1中所示的微流体系统,可以容易地用于包封细胞。具体来说,并且参考图1,包含(i)生物颗粒114和(ii)聚合物前体材料(未示出)的水性流体112流入通道接点110中,在那里水性流体通过非水流体流116而分配成液滴118、120。在包封方法的情况下,非水性流体116还可以包括引发剂(未示出)以引起聚合物前体的聚合和/或交联以形成包括所夹带的生物颗粒的微囊。聚合物前体/引发剂对的实例包括美国专利申请公布第2014/0378345号中描述的那些,所述申请出于所有目的以引用的方式整体并入本文。
[0400]
例如,在聚合物前体材料包括线性聚合物材料(例如线性聚丙烯酰胺、peg或其他线性聚合物材料)的情况下,活化剂可包括交联剂或活化所形成的液滴内的交联剂的化学物质。同样,对于包含可聚合单体的聚合物前体,活化剂可以包含聚合引发剂。例如,在某些情况下,在聚合物前体包含丙烯酰胺单体与n,n
’‑
双-(丙烯酰基)胱胺(bac)共聚单体的混合物的情况下,可以在通道区段104和106中的第二流体流116内提供例如四乙基亚甲基二胺(temed)之类的试剂,该试剂可以引发丙烯酰胺和bac共聚成交联的聚合物网络或水凝胶。
[0401]
在第二流体流116与第一流体流112在接点110处接触后,在液滴形成期间,temed可以从第二流体116扩散到包含线性聚丙烯酰胺的水性流体112中,这样将活化液滴118、120内的聚丙烯酰胺的交联,从而导致形成凝胶(例如水凝胶)微囊,作为夹带有细胞114的固体或半固体珠粒或颗粒。尽管在聚丙烯酰胺包封方面进行了描述,但是在本文所述的方法和组合物的背景下也可以采用其他"可活化"包封组合物。例如,藻酸盐液滴的形成,随后暴露于二价金属离子(例如ca
2+
离子),可用作使用所述方法的包封方法。同样,琼脂糖液滴也可以通过基于温度的胶凝作用(例如,在冷却时,等等)转化成胶囊。
[0402]
在一些情况下,包封的生物颗粒可以选择性地从微囊中释放出来,例如随着时间的推移或在施加特定刺激时,充分降解微囊,以允许生物颗粒(例如,细胞)或它的其他内容物降从微囊中释放出来,例如释放到分区(例如,液滴)中。例如,在上述聚丙烯酰胺聚合物的情况下,微囊的降解可通过引入适当的还原剂例如dtt等来裂解使聚合物基质交联的二硫键而实现。参见,例如,美国专利申请公布第2014/0378345号,所述申请出于所有目的以引用的方式整体并入本文。
[0403]
可以使生物颗粒经受足以使前体聚合或胶凝的其他条件。足以使前体聚合或胶凝的条件可以包括暴露于加热、冷却、电磁辐射和/或光。足以使前体聚合或胶凝的条件可以包括足以使前体聚合或胶凝的任何条件。聚合或胶凝之后,可在生物颗粒周围形成聚合物或凝胶。聚合物或凝胶可以是化学或生化试剂可扩散性渗透的。聚合物或凝胶可以是生物
颗粒的大分子成分不可扩散性渗透的。以这种方式,聚合物或凝胶可以起到允许生物颗粒经受化学或生化操作的作用,同时将大分子成分在空间上限制到由聚合物或凝胶限定的液滴区域中。聚合物或凝胶可以包括以下的一种或多种:二硫化物交联的聚丙烯酰胺、琼脂糖、藻酸盐、聚乙烯醇、聚乙二醇(peg)-二丙烯酸酯、peg-丙烯酸酯、peg-硫醇、peg-叠氮化物、peg-炔、其他丙烯酸酯、壳聚糖、透明质酸、胶原、纤维蛋白、明胶或弹性蛋白。聚合物或凝胶可以包含任何其他聚合物或凝胶。
[0404]
可以将聚合物或凝胶官能化为与目标分析物,例如核酸、蛋白质、碳水化合物、脂质或其他分析物结合。聚合物或凝胶可以通过被动机制聚合或胶凝。聚合物或凝胶在碱性条件或高温下可以稳定。聚合物或凝胶可具有与珠粒的机械特性相似的机械特性。例如,聚合物或凝胶可以具有与珠粒相似的大小。聚合物或凝胶可具有与珠粒相似的机械强度(例如,拉伸强度)。聚合物或凝胶的密度可低于油。聚合物或凝胶的密度可以大致类似于缓冲剂的密度。聚合物或凝胶可具有可调的孔径。可以选择孔径以例如保留变性的核酸。可以选择孔径以保持对外源化学物质(例如氢氧化钠(naoh))和/或内源化学物质(例如抑制剂)的扩散渗透性。聚合物或凝胶可以是生物相容的。聚合物或凝胶可以维持或增强细胞活力。聚合物或凝胶可以是生物化学相容的。聚合物或凝胶可以通过热、化学、酶和/或光学方式聚合和/或解聚。
[0405]
聚合物可包含与二硫连键交联的聚(丙烯酰胺-共-丙烯酸)。聚合物的制备可以包括两步反应。在第一活化步骤中,可将聚(丙烯酰胺-共-丙烯酸)暴露于酰化剂,以将羧酸转化为酯。例如,可将聚(丙烯酰胺-共-丙烯酸)暴露于4-(4,6-二甲氧基-1,3,5-三嗪-2-基)-4-甲基吗啉盐酸盐(dmtmm)。可将聚丙烯酰胺-共-丙烯酸暴露于4-(4,6-二甲氧基-1,3,5-三嗪-2-基)-4-甲基吗啉的其他盐。在第二交联步骤中,可将第一步中形成的酯暴露于二硫化物交联剂。例如,可以将酯暴露于胱胺(2,2'-二硫代双(乙胺))。在这两个步骤之后,生物颗粒可被通过二硫桥连接在一起的聚丙烯酰胺链包围。以这种方式,可以将生物颗粒封闭在凝胶或基质(例如,聚合物基质)内部或包含该凝胶或基质,以形成“细胞珠粒”。
[0406]
细胞珠粒可以含有生物颗粒(例如,细胞)或生物颗粒的大分子成分(例如rna、dna、蛋白质等)。细胞珠可包括单个细胞或多个细胞,或单个细胞或多个细胞的衍生物。例如在溶解和洗涤细胞后,可以将来自细胞裂解物的抑制组分洗掉,并且大分子成分可以结合为细胞珠粒。本文公开的系统和方法可适用于含有生物颗粒的细胞珠粒(和/或液滴或其他分区)和含有生物颗粒的大分子成分的细胞珠粒(和/或液滴或其他分区)两者。细胞珠粒可以是或包括细胞、细胞衍生物、细胞物质和/或源自细胞的物质,所述细胞在基质(例如聚合物基质)中、在基质(例如聚合物基质)内或装入基质(例如聚合物基质)中。在一些情况下,细胞珠粒可以包含活细胞。在一些情况下,活细胞能够在装入凝胶或聚合物基质中时被培养,或在包含凝胶或聚合物基质时被培养。在一些情况下,聚合物或凝胶可以对某些组分扩散渗透而对其他组分(例如大分子成分)扩散不渗透。
[0407]
与基于液滴分配的生物颗粒相比,包封的生物颗粒可以提供更易储存和更便携的某些潜在优点。此外,在一些情况下,可能希望在分析之前允许生物颗粒孵育一段选定的时间,例如,以便表征在存在或不存在不同刺激(或试剂)的情况下此类生物颗粒随时间的变化。在此类情况下,包封可允许比在乳液液滴中分配更长的孵育,但是在一些情况下,液滴分区的生物颗粒也可以孵育不同的时间段,例如至少10秒、至少30秒、至少1分钟、至少5分
钟、至少10分钟、至少30分钟、至少1小时、至少2小时、至少5小时或至少10小时或更多时间。生物颗粒的包封可以构成生物颗粒的分区,其他试剂被共同分配到生物颗粒中。可替代地或此外,包封的生物颗粒可以容易地沉积到如上所述的其他分区(例如液滴)中。
[0408]
孔
[0409]
如本文所述,可以在分区中执行一个或多个过程,所述分区可以是孔。孔可以是基板的多个孔中的孔,例如微孔阵列或板的微孔,或者孔可以是包括基板的装置(例如微流体装置)的微孔或微室。孔可以是孔阵列或板的孔,或者孔可以是装置(例如流体装置)的孔或室。因此,孔或微孔可以呈现“开放”配置,其中孔或微孔暴露于环境(例如,包含开放表面)并且在基板的一个平面上是可接近的,或者孔或微孔可以呈现“封闭”或“密封”配置,其中微孔在基板的平面上是不可接近的。在一些情况下,孔或微孔可以被配置为在“开放”和“封闭”配置之间切换。例如,一个“开放”微孔或一组微孔可以使用膜(例如半透膜)、油(例如,氟化油以覆盖水溶液)或盖子来“封闭”或“密封”,如本文别处所述。
[0410]
孔的体积可以小于1毫升(ml)。例如,孔可以被配置为容纳至多1000微升(μl)、至多100μl、至多10μl、至多1μl、至多100纳升(nl)、至多10nl、至多1nl、至多100皮升(pl)、至多10(pl)或更少的体积。孔可以被配置为容纳约1000μl、约100μl、约10μl、约1μl、约100nl、约10nl、约1nl、约100pl、约10pl等的体积。孔可以被配置为容纳至少10pl、至少100pl、至少1nl、至少10nl、至少100nl、至少1μl、至少10μl、至少100μl、至少1000μl或更多的体积。孔可以被配置为容纳本文中列出的体积范围内的体积,例如约5nl至约20nl、约1nl至约100nl、约500pl至约100μl等。孔可以是具有不同体积的多个孔,并且可以被配置为保持适合容纳本文所述的任何分区体积的体积。
[0411]
在一些情况下,微孔阵列或板包括单一种类的微孔。在一些情况下,微孔阵列或板包括多种微孔。例如,微孔阵列或板可以在单个微孔阵列或板内包括一种或多种类型的微孔。微孔的类型可以具有不同的尺寸(例如,长度、宽度、直径、深度、截面积等)、形状(例如,圆形、三角形、正方形、矩形、五边形、六边形、七边形、八边形、九边形、十边形等)、纵横比或其他物理特征。微孔阵列或板可以包括任何数量的不同类型的微孔。例如,微孔阵列或板可以包括1种、2种、3种、4种、5种、6种、7种、8种、9种、10种、20种、30种、40种、50种、60种、70种、80种、90种、100种、200种、300种、400种、500种、600种、700种、800种、900种、1000种或更多种不同类型的微孔。孔可以具有任何尺寸(例如,长度、宽度、直径、深度、横截面积、体积等)、形状(例如,圆形、三角形、正方形、矩形、五边形、六边形、七边形、八边形、九边形、十边形、其他多边形等)、纵横比或本文所述的关于任何孔的其他物理特征。
[0412]
在某些情况下,微孔阵列或板包括在阵列或板内彼此相邻定位的不同类型的微孔。例如,具有一组尺寸的微孔可以与具有另一组不同尺寸的另一个微孔相邻并接触。类似地,不同几何形状的微孔可以彼此相邻或接触放置。相邻的微孔可以被配置为容纳不同物品;例如,一个微孔可用于容纳细胞、细胞珠粒或其他样品(例如,细胞组分、核酸分子等),而相邻的微孔可用于容纳微囊、液滴、珠粒或其他试剂。在一些情况下,相邻的微孔可以被配置为例如在施加刺激时或自发地在每个微孔中的物品接触时合并容纳在其中的内容物。
[0413]
如本文别处所述,多个分区可用于本文所述的系统、组合物和方法中。例如,可以产生或以其他方式提供任何合适数量的分区(例如孔或液滴)。例如,在使用孔的情况下,可以产生或以其他方式提供至少约1,000个孔、至少约5,000个孔、至少约10,000个孔、至少约
50,000个孔、至少约100,000个孔、至少约500,000个孔、至少约1,000,000个孔、至少约5,000,000个孔、至少约10,000,000个孔、至少约50,000,000个孔、至少约100,000,000个孔、至少约500,000,000个孔、至少约1,000,000,000个孔或更多个孔。此外,多个孔可以包括未占用孔(例如空孔)和已占用孔。
[0414]
孔可以包含本文所述的任何试剂或其组合。这些试剂可以包括例如条形码分子、酶、衔接子以及它们的组合。试剂可以与放置在孔中的样品(例如,细胞、细胞珠粒或细胞组分,例如蛋白质、核酸分子等)物理分离。这种物理分离可以通过将试剂包含在放置在孔内的微囊或珠粒内或使试剂偶联至微囊或珠粒来实现。物理分离还可以通过在孔中分配试剂并在将多核苷酸样品引入孔中之前用例如可溶解、可溶化的或可渗透的层覆盖试剂来实现。该层可以是例如油、蜡、膜(例如半透膜)等。孔可以在任何点密封,例如,在添加微囊或珠粒之后,在添加试剂之后,或在添加这些组分中的任一者之后。孔的密封可用于多种目的,包括防止珠粒或装载的试剂从孔中逸出,允许选择性地递送某些试剂(例如,通过使用半透膜),用于在进一步处理之前或之后储存等。
[0415]
孔可以包括游离试剂和/或封装在微囊、珠粒或液滴中或以其他方式与微囊、珠粒或液滴偶联或缔合的试剂。本公开中描述的任何试剂可以与适合涉及生物分子(例如但不限于核酸分子和蛋白质)的样品处理反应的任何化学品、颗粒和元件一起封装在微囊、液滴或珠粒中或以其他方式偶联至微囊、液滴或珠粒。例如,用于dna测序的样品制备反应中使用的珠粒或液滴可以包含以下试剂中的一者或多者:酶、限制性内切酶(例如,多个切割子)、连接酶、聚合酶、荧光团、寡核苷酸条形码、衔接子、缓冲液、核苷酸(例如,dntp、ddntp)等。
[0416]
试剂的其他实例包括但不限于:缓冲液、酸性溶液、碱性溶液、温度敏感酶、ph敏感酶、光敏酶、金属、金属离子、氯化镁、氯化钠、锰、水性缓冲液、温和缓冲液、离子缓冲液、抑制剂、酶、蛋白质、多核苷酸、抗体、糖类、脂质、油、盐、离子、去污剂、离子去污剂、非离子去污剂、寡核苷酸、核苷酸、脱氧核糖核苷酸三磷酸(dntp)、双脱氧核糖核苷酸三磷酸(ddntp)、dna、rna、肽多核苷酸、互补dna(cdna)、双链dna(dsdna)、单链dna(ssdna)、质粒dna、粘粒dna、染色体dna、基因组dna、病毒dna、细菌dna、mtdna(线粒体dna)、mrna、rrna、trna、nrna、sirna、snrna、snorna、scarna、微小rna、dsrna、核酶、核糖开关和病毒rna、聚合酶、连接酶、限制酶、蛋白酶、核酸酶、蛋白酶抑制剂、核酸酶抑制剂、螯合剂、还原剂、氧化剂、荧光团、探针、发色团、染料、有机物、乳化剂、表面活性剂、稳定剂、聚合物、水、小分子、药物、放射性分子、防腐剂、抗生素、适体和药物化合物。如本文所述,孔中的一种或多种试剂可用于进行一种或多种反应,包括但不限于:细胞溶解、细胞固定、透化、核酸反应,例如核酸延伸反应、扩增、逆转录、转座酶反应(例如,标记)等。
[0417]
孔可以作为试剂盒的一部分提供。例如,试剂盒可以包括使用说明、微孔阵列或装置以及试剂(例如珠粒)。试剂盒可以包括用于进行本文所述过程(例如,核酸反应、核酸分子的条形码化、样品处理(例如,用于细胞溶解、固定和/或透化))的任何有用试剂。
[0418]
在一些情况下,孔包括微囊、珠粒或液滴,其包含一组具有相似属性的试剂(例如,一组酶、一组矿物质、一组寡核苷酸、不同条形码分子的混合物、相同条形码分子的混合物)。在其他情况下,微囊、珠粒或液滴包含试剂的异质混合物。在一些情况下,试剂的异质混合物可以包含进行反应所需的所有组分。在一些情况下,此类混合物可以包含进行反应
所必需的所有组分,除了进行反应所必需的1、2、3、4、5种或更多种组分。在一些情况下,此类另外组分包含在不同的微囊、液滴或珠粒内,或以其他方与不同的微囊、液滴或珠粒偶联,或在系统的分区(例如微孔)内的溶液内。
[0419]
图5示意性地说明了微孔阵列的一个实例。阵列可以包含在基板500内。基板500包括多个孔502。孔502可以是任何尺寸或形状,并且根据具体应用,可以修改孔之间的间距、每个基板的孔数量以及基板500上的孔的密度。在一个这样的示例应用中,可以包含细胞或细胞组分(例如核酸分子)的样品分子506与可以包含与其偶联的核酸条形码分子的珠粒504共同分配。可以使用重力或其他装载技术(例如,离心、液体处理器、声学装载、光电等)来装载孔502。在一些情况下,孔502中的至少一个包含单个样品分子506(例如细胞)和单个珠子504。
[0420]
试剂可以顺序或同时装载至孔中。在一些情况下,在特定操作之前或之后将试剂引入装置。在一些情况下,顺序引入试剂(在某些情况下,可以在微囊、液滴或珠粒中提供),使得不同的反应或操作发生在不同的步骤。试剂(或微囊、液滴或珠粒)还可以在穿插反应或操作步骤的操作中装载。例如,可以将包含用于片段化多核苷酸(例如限制酶)和/或其他酶(例如,转座酶、连接酶、聚合酶等)的试剂的微囊(或液滴或珠粒)装载至孔或多个孔中,然后装载包含用于将核酸条形码分子附接至样品核酸分子的试剂的微囊、液滴或珠粒。试剂可以与样品(例如细胞或细胞组分(例如,细胞器、蛋白质、核酸分子、碳水化合物、脂质等))同时或顺序提供。因此,孔的使用在进行多步操作或反应中可能是有用的。
[0421]
如本文别处所述,核酸条形码分子和其他试剂可以包含在微囊、珠粒或液滴内。这些微囊、珠粒或液滴可以在装载细胞之前、之后或同时装载至分区(例如微孔)中,使得每个细胞与不同的微囊、珠粒或液滴接触。该技术可用于将独特的核酸条形码分子附接至从每个细胞获得的核酸分子。可替代地或此外,可以将样品核酸分子附接至支持物。例如,分区(例如微孔)可以包含与多个核酸条形码分子偶联的珠粒。样品核酸分子或其衍生物可以偶联或附接至支持物上的核酸条形码分子。所得的条形码化核酸分子然后可以从分区中除去,并且在一些情况下进行汇集和测序。在这种情况下,核酸条形码序列可用于追踪样品核酸分子的来源。例如,可以确定具有相同条形码的多核苷酸源自于相同的细胞或分区,同时可以确定具有不同条形码的多核苷酸源自于不同的细胞或分区。
[0422]
可以使用多种方法将样品或试剂装载至孔或微孔中。可以使用外力(例如,重力、电力、磁力)将样品(例如,细胞、细胞珠粒或细胞组分)或试剂(如本文所述)装载至孔或微孔中,或使用机械将样品或试剂驱动到孔中,例如,通过压力驱动流、离心、光电子、声学装载、电动泵送、真空、毛细管流等。在某些情况下,可以使用流体处理系统将样品或试剂装载至孔中。样品或试剂的装载可以遵循泊松分布或非泊松分布,例如超泊松或亚泊松。可以修改微孔的几何形状、孔间距、密度和尺寸以适应可用的样品或试剂分布;例如,可以调整微孔的尺寸和间距,使得样品或试剂可以超泊松方式分布。
[0423]
在一个具体的非限制性实例中,微孔阵列或板包括成对的微孔,其中每对微孔被配置为容纳液滴(例如,包括单个细胞)和单个珠粒(例如本文所述的那些,在一些情况下,其还可以封装在液滴中)。液滴和珠粒(或包含珠粒的液滴)可以同时或顺序装载,并且液滴和珠粒可以合并,例如,在液滴和珠粒接触时,或在施加刺激(例如,外力、搅拌、热、光、磁力或电力等)时。在一些情况下,液滴和珠粒的装载是超泊松的。在成对的微孔的其他实例中,
孔被配置为容纳包含不同试剂和/或样品的两个液滴,它们在接触或施加刺激时合并。在这种情况下,该对中的一个微孔的液滴可以包含可以与该对中的另一个微孔的液滴中的试剂反应的试剂。例如,一个液滴可以包含被配置为释放位于相邻微孔中的另一个液滴中的珠粒的核酸条形码分子的试剂。在液滴合并时,核酸条形码分子可以从珠粒释放至分区(例如,接触的微孔或微孔对)中,并且可以进行进一步处理(例如,条形码化、核酸反应等)。在完整或活细胞装载在微孔中的情况下,液滴中的一个可以包含用于在液滴合并时溶解细胞的溶解试剂。
[0424]
液滴或微囊可以分配至孔中。在装载至孔中之前,可以选择液滴或对其进行预处理。例如,液滴可以包含细胞,并且仅某些液滴,例如那些包含单个细胞(或至少一个细胞)的液滴,可以被选择用于孔的装载。这种预选过程可用于有效装载单个细胞,例如获得非泊松分布,或在孔中进一步分配之前针对所选特征对细胞进行预过滤。此外,该技术可用于在装载微孔之前或期间获得或防止细胞双峰或多峰形成。
[0425]
在一些情况下,孔可以包含与其附接的核酸条形码分子。核酸条形码分子可以附接至孔的表面(例如孔的壁)。一个孔的核酸条形码分子(例如分区条形码序列)可以不同于另一个孔的核酸条形码分子,这可以允许识别单个分区或孔中包含的内容物。在一些情况下,核酸条形码分子可以包含可以识别孔的空间坐标的空间条形码序列,例如在孔阵列或孔板内。在一些情况下,核酸条形码分子可以包含用于个体分子识别的独特分子标识符。在一些情况下,核酸条形码分子可以被配置为附接或捕获分布在孔中的样品或细胞内的核酸分子。例如,核酸条形码分子可以包含捕获序列,所述捕获序列可用于捕获样品内的核酸分子(例如,rna、dna)或与其杂交。在一些情况下,核酸条形码分子可以从微孔中释放。例如,核酸条形码分子可以包含化学交联剂,其可以在施加刺激(例如,光、磁、化学、生物刺激)时被裂解。释放的核酸条形码分子可以与样品核酸分子杂交或被配置为与样品核酸分子杂交,可以将释放的核酸条形码分子收集并汇集用于进一步处理,处理可以包括核酸处理(例如,扩增、延伸、逆转录等)和/或表征(例如,测序)。在这种情况下,独特的分区条形码序列可用于识别核酸分子起源的细胞或分区。
[0426]
可以对孔内的样品进行表征。在非限制性实例中,此类表征可以包括样品(例如,细胞、细胞珠粒或细胞组分)或其衍生物的成像。表征技术(例如显微镜检查或成像)可用于测量固定空间位置的样品谱。例如,当细胞被分配时,任选地具有珠粒,每个微孔和其中包含的内容物的成像可以提供关于以下的有用信息:细胞双峰形成(例如频率、空间位置等)、细胞-珠粒对效率、细胞活力、细胞大小、细胞形态、生物标志物(例如,表面标志物、其中的荧光标记分子等)的表达水平、细胞或珠粒装载率、细胞-珠粒对的数量等。在一些情况下,成像可用于表征孔中的活细胞,包括但不限于:动态活细胞跟踪、细胞-细胞相互作用(当两个或多个细胞共同分配时)、细胞增殖等。可替代地或此外,成像可用于表征孔中扩增产物的数量。
[0427]
在操作中,可以同时或顺序向孔装载样品和试剂。当装载细胞或细胞珠粒时,可以对孔进行洗涤,例如以从孔、微孔阵列或板中除去多余的细胞。类似地,可以进行洗涤以从孔、微孔阵列或板中除去多余的珠粒或其他试剂。在使用活细胞的情况下,可以在单独的分区中裂解细胞以释放细胞内组分或细胞分析物。可替代地,细胞可以在单独的分区中固定或透化。细胞内组分或细胞分析物可以与支持物偶联,例如,在微孔的表面上、在固体支持
物(例如珠粒)上,或者它们可以被收集用于进一步的下游处理。例如,在细胞溶解后,可以将细胞内组分或细胞分析物转移至单独的液滴或其他分区中进行条形码化。可替代地或此外,细胞内组分或细胞分析物(例如核酸分子)可以与包含核酸条形码分子的珠粒偶联;随后,可以收集珠粒并进一步处理,例如,进行核酸反应,例如逆转录、扩增或延伸,并且其上的核酸分子可以被进一步表征,例如,通过测序表征。可替代地或此外,细胞内组分或细胞分析物可以在孔中进行条形码化(例如,使用包含可释放的核酸条形码分子的珠粒或在包含核酸条形码分子的微孔的表面上)。条形码化核酸分子或分析物可以在孔中进一步处理,或者条形码化核酸分子或分析物可以从单独的分区收集并在分区的外部进行进一步处理。进一步处理可以包括核酸处理(例如,进行扩增、延伸)或表征(例如,扩增分子的荧光监测、测序)。在任何方便或有用的步骤中,孔(或微孔阵列或板)可以被密封(例如,使用油、膜、蜡等),这使得能够储存测定或选择性地引入另外试剂。
[0428]
图6示意性地示出了用于处理样品内的核酸分子的示例性工作流程。可以提供包括多个微孔602的基板600。可以包含细胞、细胞珠粒、细胞组分或分析物(例如蛋白质和/或核酸分子)的样品606可以在多个微孔602中与包含核酸条形码分子的多个珠粒604共同分配。在处理610期间,可以在分区内处理样品606。举例来说,在活细胞的情况下,可以使细胞经受足以溶解细胞并释放其中所含分析物的条件。在过程620中,可以进一步处理珠粒604。举例而言,过程620a和620b示意性地示出了不同的工作流程,这取决于珠粒604的特性。
[0429]
在620a中,珠粒包含与其附接的核酸条形码分子,并且样品核酸分子(例如,rna、dna)可以例如通过连接的杂交附接至核酸条形码分子。这种附接可能发生在珠粒上。在过程630中,来自多个孔602的珠粒604可以被收集和汇集。可以在过程640中进行进一步的处理。例如,可以进行一种或多种核酸反应,例如逆转录、核酸延伸、扩增、连接、转座等。在一些情况下,衔接子序列连接至核酸分子或其衍生物,如本文别处所述。例如,测序引物序列可以附加到核酸分子的每一端。在过程650中,可以进行进一步的表征例如测序以产生测序读段。测序读段可以产生关于个别细胞或细胞群体的信息,这些信息可以在视觉上或图形上表示,例如在图655中表示。
[0430]
在620b中,珠粒包含可释放地附接至其的核酸条形码分子,如下文所述。珠粒可以降解或以其他方式将核酸条形码分子释放到孔602中;然后可以使用核酸条形码分子对孔602内的核酸分子进行条形码化。可以在分区内部或分区外部进行进一步处理。例如,可以进行一种或多种核酸反应,例如逆转录、核酸延伸、扩增、连接、转座等。在一些情况下,衔接子序列连接至核酸分子或其衍生物,如本文别处所述。例如,测序引物序列可以附加到核酸分子的每一端。在过程650中,可以进行进一步的表征例如测序以产生测序读段。测序读段可以产生关于个别细胞或细胞群体的信息,这些信息可以在视觉上或图形上表示,例如在图655中表示。
[0431]
珠粒
[0432]
核酸条形码分子可以通过固体支持物或载体(例如珠粒)递送至分区(例如液滴或孔)。在一些情况下,核酸条形码分子最初与固体支持物缔合,然后在施加使核酸条形码分子解离或从固体支持物释放的刺激时从固体支持物释放。在具体实例中,核酸条形码分子最初与固体支持物(例如珠粒)缔合,然后在施加生物刺激、化学刺激、热刺激、电刺激、磁刺激和/或照片刺激时从固体支持物释放。
[0433]
核酸条形码分子可以含有条形码序列和功能序列,例如核酸引物序列或模板转换寡核苷酸(tso)序列。
[0434]
固体支持物可以是珠粒。固体支持物,例如珠粒,可以是多孔的、无孔的、中空的(例如微胶囊)、固体的、半固体的和/或它们的组合。珠粒可以是固体的、半固体的、半流体的、流体的和/或它们的组合。在一些情况下,固体支持物例如珠粒可以是至少部分地可溶解的、可破裂的和/或可降解的。在一些情况下,固体支持物例如珠粒可以不是可降解的。在一些情况下,固体支持物例如珠粒可以是凝胶珠粒。凝胶珠粒可以是水凝胶珠粒。凝胶珠粒可由分子前体例如聚合物或单体物质形成。半固体支持物例如珠粒可以是脂质体珠粒。固体支持物例如珠粒可以包含金属,包括氧化铁、金和银。在一些情况下,固体支持物例如珠粒可以是二氧化硅珠粒。在一些情况下,固体支持物例如珠粒可以是刚性的。在其他情况下,固体支持物例如珠粒可以是柔性的和/或可压缩性的。
[0435]
分区可以包含一个或多个独特标识符,例如条形码。条形码可以预先、随后或同时递送到容纳划分或分配的生物颗粒的分区中。例如,条形码可以在分别产生液滴或在微孔中提供试剂之前、之后或与之同时注入到液滴中。将条形码递送至特定分区允许随后将单独生物颗粒的特征归属于特定分区。条形码可以例如在核酸分子(例如寡核苷酸)上,通过任何适合机制递送至分区。条形码化核酸分子可通过微囊递送至分区。在一些情况下,微囊可以包含珠粒。下面更详细地描述珠粒。
[0436]
在一些情况下,条形码化核酸分子可以最初与微囊缔合,然后从微囊中释放出来。条形码化核酸分子的释放可以是被动的(例如,通过扩散出微囊)。此外或可替代地,从微囊中释放可以是在施加允许条形码化核酸分子从微胶囊中解离或释放的刺激时。此类刺激可以破坏微囊,这是一种使条形码化核酸分子偶联至微囊或处于微胶囊内或两者的相互作用。此类刺激可以包括,例如热刺激、光刺激、化学刺激(例如,ph的变化或还原剂的使用)、机械刺激、辐射刺激、生物刺激(例如酶)或它们的任何组合。用于将携带条形码的珠粒分配成液滴的方法和系统提供于美国专利公布第2019/0367997号和第2019/0064173号以及国际申请第pct/us20/17785号中,所述文献各自出于所有目的以引用的方式整体并入本文。
[0437]
在一些实例中,珠粒、分析物载体和液滴可以沿通道(例如,微流体装置的通道)流动,在一些情况下以基本上规则的流动曲线(例如,以规则的流速)流动。此类规则的流动曲线可以容许液滴包括单个珠粒和单个生物颗粒。此类规则的流动曲线可以容许液滴具有大于5%、10%、20%、30%、40%、50%、60%、70%、80%、90%或95%的占用率(例如,具有珠粒和生物颗粒的液滴)。在例如美国专利公布第2015/0292988号中提供了此类规则的流动曲线和可用于提供此类规则的流动曲线的装置,所述专利以引用的方式整体并入本文。
[0438]
珠粒可以是多孔的、无孔的、固体、半固体、半流体、流体和/或它们的组合。在一些情况下,珠粒可以是可溶解的、可破裂的和/或可降解的。在一些情况下,珠粒可以不是可降解的。在一些情况下,珠粒可以是凝胶珠粒。凝胶珠粒可以是水凝胶珠粒。凝胶珠粒可由分子前体例如聚合物或单体物质形成。半固体珠粒可以是脂质体珠粒。固体珠粒可以包含金属,包括氧化铁、金和银。在一些情况下,珠粒可以是二氧化硅珠粒。在一些情况下,珠粒可以是刚性的。在其他情况下,珠粒可以是柔性的和/或可压缩性的。
[0439]
珠粒可以具有任何适合形状。珠粒形状的实例包括但不限于球形、非球形、椭圆形、长方形、无定形、圆形、圆柱形及其变型。
[0440]
珠粒可以具有均一的大小或非均一的大小。在一些情况下,珠粒的直径可以为至少约10纳米(nm)、100nm、500nm、1微米(μm)、5μm、10μm、20μm、30μm、40μm、50μm、60μm、70μm、80μm、90μm、100μm、250μm、500μm、1mm或更大。在一些情况下,珠粒的直径可以小于约10nm、100nm、500nm、1μm、5μm、10μm、20μm、30μm、40μm、50μm、60μm、70μm、80μm、90μm、100μm、250μm、500μm、1mm或更小。在一些情况下,珠粒的直径可以在约40-75μm、30-75μm、20-75μm、40-85μm、40-95μm、20-100μm、10-100μm、1-100μm、20-250μm或20-500μm的范围内。
[0441]
在某些方面,珠粒可以作为具有相对单分散的粒度分布的珠粒群体或多个珠粒提供。在可能希望在分区内提供相对一致量的试剂的情况下,保持相对一致的珠粒特征(例如大小)可以有助于总体一致性。具体来说,本文所述的珠粒可具有这样的粒度分布,所述粒度分布在其横截面尺寸上的变异系数小于50%、小于40%、小于30%、小于20%,并且在一些情况下小于15%、小于10%、小于5%或更小。
[0442]
珠粒可以包含天然材料和/或合成材料。例如,珠粒可以包含天然聚合物、合成聚合物或天然聚合物和合成聚合物两者。天然聚合物的实例包括蛋白质和糖,例如脱氧核糖核酸、橡胶、纤维素、淀粉(例如直链淀粉、支链淀粉)、蛋白质、酶、多糖、丝、聚羟基烷基酸酯、壳聚糖、葡聚糖、胶原蛋白、卡拉胶、卵叶车前子、阿拉伯胶、琼脂、明胶、虫胶、梧桐胶、黄原胶、玉米糖胶、瓜尔胶、刺梧桐胶、琼脂糖、海藻酸、海藻酸盐或它们的天然聚合物。合成聚合物的实例包括丙烯酸类、尼龙、硅酮、氨纶、粘胶人造丝、聚羧酸、聚乙酸乙烯酯、聚丙烯酰胺、聚丙烯酸酯、聚乙二醇、聚氨酯、聚乳酸、二氧化硅、聚苯乙烯、聚丙烯腈、聚丁二烯、聚碳酸酯、聚乙烯、聚对苯二甲酸乙二醇酯、聚(氯三氟乙烯)、聚(环氧乙烷)、聚(对苯二甲酸乙二醇酯)、聚乙烯、聚异丁烯、聚(甲基丙烯酸甲酯)、聚(氧化亚甲基)、聚甲醛、聚丙烯、聚苯乙烯、聚(四氟乙烯)、聚(乙酸乙烯酯)、聚(乙烯醇)、聚(氯乙烯)、聚(偏二氯乙烯)、聚(偏二氟乙烯)、聚(氟乙烯)和/或它们的组合(例如,共聚物)。珠粒也可由除聚合物之外的材料(包括脂质、胶束、陶瓷、玻璃-陶瓷、复合材料、金属、其他无机材料等)形成。
[0443]
在一些情况下,珠粒可以含有分子前体(例如,单体或聚合物),其可以通过分子前体的聚合而形成聚合物网络。在一些情况下,前体可以是已经聚合的物质,其能够经由例如化学交联进行进一步聚合。在一些情况下,前体可以包含丙烯酰胺或甲基丙烯酰胺单体、低聚物或聚合物中的一种或多种。在一些情况下,珠粒可以包含预聚物,其是能够进一步聚合的低聚物。例如,可以使用预聚物制备的聚氨酯珠粒。在一些情况下,珠粒可以含有可进一步聚合在一起的单独聚合物。在一些情况下,可通过不同前体的聚合而产生珠粒,使得它们包含混合的聚合物、共聚物和/或嵌段共聚物。在一些情况下,珠粒可以包含在聚合物前体(例如,单体、低聚物、线性聚合物)、核酸分子(例如,寡核苷酸)、引物和其他实体之间的共价键或离子键。在一些情况下,共价键可以是碳-碳键、硫醚键或碳-杂原子键。
[0444]
交联可以是永久的或可逆的,这取决于所用的特定交联剂。可逆性交联可以允许聚合物在适当的条件下线性化或解离。在一些情况下,可逆性交联也可以允许与珠粒表面结合的材料的可逆性附接。在一些情况下,交联剂可以形成二硫连键。在一些情况下,形成二硫连键的化学交联剂可以是胱胺或修饰的胱胺。
[0445]
在一些情况下,二硫连键可以在掺入珠粒的分子前体单元(例如,单体、低聚物或线性聚合物)或前体与核酸分子(例如,寡核苷酸)之间形成。胱胺(包括修饰的胱胺)例如是一种包含二硫键的有机试剂,可以用作珠粒的单独的单体或聚合物前体之间的交联剂。聚
丙烯酰胺可以在胱胺或包含胱胺的物质(例如,修饰的胱胺)的存在下聚合,以产生包含二硫连键的聚丙烯酰胺凝胶珠粒(例如,包含可化学还原的交联剂的可化学降解的珠粒)。当珠粒暴露于还原剂时,二硫连键可容许珠粒降解(或溶解)。
[0446]
在一些情况下,壳聚糖(线性多糖聚合物)可以通过亲水链与戊二醛交联以形成珠粒。壳聚糖聚合物的交联可通过受热、压力、ph值变化和/或辐射引发的化学反应来实现。
[0447]
在一些情况下,珠粒可包含丙烯酰胺基(acrydite)部分,其在某些方面可用于将一个或多个核酸分子(例如,条形码序列、条形码化核酸分子、带条形码的寡核苷酸、引物或其他寡核苷酸)附接至珠粒。在一些情况下,丙烯酰胺基部分可以指由丙烯酰胺基与一种或多种物质的反应,例如聚合反应期间丙烯酰胺基与其他单体和交联剂的反应而产生的丙烯酰胺基类似物。可以对丙烯酰胺基部分进行修饰以与待附接的物质形成化学键,所述物质例如核酸分子(例如,条形码序列、条形码化核酸分子、带条形码的寡核苷酸、引物或其他寡核苷酸)。丙烯酰胺基部分可以用能够形成二硫键的硫醇基团修饰或者可以用已经包含二硫键的基团修饰。硫醇或二硫化物(通过二硫化物交换)可以用作要附接的物质的锚定点,或者可以将丙烯酰胺基部分的另一部分用于附接。在一些情况下,附接可以是可逆性的,使得当二硫键被破坏时(例如,在还原剂的存在下),所附接的物质从珠粒释放。在其他情况下,丙烯酰胺基部分可包含可用于附接的反应性羟基。
[0448]
用于附接核酸分子(例如,寡核苷酸)的珠粒的官能化可以通过多种不同方法实现,包括活化聚合物内的化学基团、将活性或可活化的官能团掺入聚合物结构中或者在珠粒生产中的预聚物或单体阶段进行附接。
[0449]
例如,聚合形成珠粒的前体(例如,单体、交联剂)可包含丙烯酰胺基部分,使得当珠粒生成时,该珠粒也包含丙烯酰胺基部分。可以将丙烯酰胺基部分附接至核酸分子(例如寡核苷酸),所述核酸分子包括一个或多个功能序列(例如tso序列或引物序列(例如,聚t序列,或与靶核酸序列互补和/或用于扩增靶核酸序列的核酸引物序列、随机引物、用于信使rna的引物序列))和/或一个或多个条形码序列。所述一个以上的条形码序列可以包括对于偶联至珠粒的所有核酸分子相同的序列和/或在偶联至珠粒的所有核酸分子中不同的序列。核酸分子可以掺入到珠粒中。
[0450]
在一些情况下,核酸分子可以包含功能序列,例如,用于附接至测序流动池,例如用于测序的p5序列(或其部分)。在一些情况下,核酸分子或其衍生物(例如,由核酸分子产生的寡核苷酸或多核苷酸)可以包含另一功能序列,例如,用于附接至测序流动池以进行illumina测序的p7序列(或其部分)。在一些情况下,核酸分子可以包含条形码序列。在一些情况下,核酸分子还可以包含独特分子标识符(umi)。在一些情况下,核酸分子可以包含用于illumina测序的r1引物序列。在一些情况下,核酸分子可以包含用于illumina测序的r2引物序列。如可与本公开的组合物、装置、方法和系统一起使用的此类核酸分子(例如,寡核苷酸、多核苷酸等)及其用途的实例提供于美国专利公布第2014/0378345号和第2015/0376609号(其各自以引用的方式整体并入本文)中。
[0451]
在一些情况下,核酸分子可以包含一个或多个功能序列。例如,功能序列可以包含用于附接至测序流动池的序列,例如用于测序的p5序列。在一些情况下,核酸分子或其衍生物(例如,由核酸分子产生的寡核苷酸或多核苷酸)可以包含另一功能序列,例如,用于附接至测序流动池以进行illumina测序的p7序列。在一些情况下,功能序列可以包
含一个条形码序列或多个条形码序列。在一些情况下,功能序列可以包含独特分子标识符(umi)。在一些情况下,功能序列可以包含引物序列(例如,用于illumina测序的r1引物序列、用于illumina测序的r2引物序列等)。在一些情况下,功能序列可以包含部分序列,例如部分条形码序列、部分锚定序列、部分测序引物序列(例如,部分r1序列、部分r2序列等)、被配置为附接至测序仪的流动池的部分序列(例如,部分p5序列、部分p7序列等),或本文别处所述的任何其他类型序列的部分序列。例如,部分序列可以包含完整序列的连续或连续部分或区段,但非全部。在一些情况下,下游程序可以延伸部分序列或其衍生物,以实现部分序列或其衍生物的完整序列。
[0452]
此类核酸分子(例如,寡核苷酸、多核苷酸等)及其用途的实例,如可与本公开的组合物、装置、方法和系统一起使用的,提供于美国专利公布第2014/0378345号和第2015/0376609号(其各自以引用的方式整体并入本文)中。
[0453]
图3说明了携带条形码的珠粒的一个实例。核酸分子302,例如寡核苷酸,可以通过可释放连键306例如二硫化物连接子,偶联至珠粒304。同一珠粒304可以与一个或多个其他核酸分子318、320偶联(例如,经由可释放连键)。核酸分子302可以是条形码或包含条形码。如本文别处所述,条形码的结构可以包含许多序列元件。核酸分子302可以包含可用于后续处理的功能序列308。例如,功能序列308可以包括以下中的一者或多者:测序仪专用流动池附接序列(例如,用于测序系统的p5序列)测序引物序列(例如,用于测序系统的r1序列),或其部分序列。核酸分子302可以包含对样品(例如,dna、rna、蛋白质等)进行条形码化的条形码序列310。在一些情况下,条形码序列310可以是珠粒特异性的,使得条形码序列310为偶联至相同珠粒304的所有核酸分子(例如,包括核酸分子302)所共有。可替代地或此外,条形码序列310可以是分区特异性的,使得条形码序列310为偶联至被分配到相同分区中的一个或多个珠粒的所有核酸分子所共有。核酸分子302可以包含特异性引物序列312,例如mrna特异性引物序列(例如,多聚t序列)、靶向引物序列和/或随机引物序列。核酸分子302可以包含锚定序列314以确保特异性引物序列312在序列末端(例如,mrna的序列末端)杂交。例如,锚定序列314可以包括随机的短核苷酸序列,例如1-聚体、2-聚体、3-聚体或更长的序列,其可以确保多聚t区段更有可能在mrna的多聚a尾的序列末端杂交。
[0454]
核酸分子302可以包含独特分子标识序列316(例如,独特分子标识符(umi))。在一些情况下,独特分子标识序列316可以包含约5至约8个核苷酸。可替代地,独特分子标识序列316可以包含少于约5个或多于约8个核苷酸。独特分子标识序列316可以是在偶联至单个珠粒(例如,珠粒304)的单独核酸分子(例如,302、318、320等)间不同的独特序列。在一些情况下,独特分子标识序列316可以是随机序列(例如,随机n-聚体序列)。例如,umi可以提供被捕获的起始mrna分子的独特标识符,以便允许定量原始表达的rna的数量。正如将认识到的,图3示出了偶联至珠粒304的表面的核酸分子302、318、320,单独的珠粒可以偶联至任意数量的单独核酸分子,例如从一到几十到成千上万个或甚至数百万个单独核酸分子。单独核酸分子的相应条形码可以包括在偶联至同一珠粒的不同单独核酸分子之间的共有序列区段或相对共有序列区段(例如,308、310、312等)和可变或独特序列区段(例如,316)两者。
[0455]
在操作时,生物颗粒(例如,细胞、dna、rna等)可以连同带条形码化珠粒304一起共同分配。核酸条形码分子302、318、320可以从分区中的珠粒304中释放。举例而言,在分析样
品rna的情况下,其中一个释放的核酸分子(例如,302)的聚t区段(例如,312)可以与mrna分子的聚a尾杂交。逆转录可产生mrna的cdna转录物,但是该转录物包括核酸分子302的序列区段308、310、316中的每一个。因为核酸分子302包含锚定序列314,所以将更有可能与mrna的多聚-a尾的序列末端杂交并引发逆转录。在任何给定分区中,单独mrna分子的cdna转录物可以包括共有条形码序列区段310。然而,由给定分区内的不同mrna分子产生的转录物可在独特分子标识序列312区段(例如,umi区段)处不同。有利地,甚至在给定分区的内容物的任何后续扩增之后,不同umi的数量可以指示来源于给定分区并因此来源于生物颗粒(例如,细胞)的mrna的量。如上所述,可以对转录物进行扩增、纯化和测序以鉴定mrna的cdna转录物的序列,以及对条形码区段和umi区段进行测序。虽然描述了多聚t引物序列,但是其他靶向或随机引物序列也可以用于引发逆转录反应。同样,尽管描述为将条形码化寡核苷酸释放到分区中,但是在一些情况下,与珠粒(例如凝胶珠粒)结合的核酸分子可用于杂交和捕获珠粒固相上的mrna,例如,以便促进rna与其他细胞内容物的分离。在这种情况下,可以在分区内或分区外(例如,批量)进行进一步的处理。例如,可以使珠粒上的rna分子经受逆转录或其他核酸处理,可以将另外衔接子序列添加到条形码化核酸分子中,或者可以进行其他核酸反应(例如,扩增、核酸延伸)。可以从分区收集珠粒或其产物(例如条形码化核酸分子),并且/或者将其汇集在一起,随后进行清理和进一步表征(例如测序)。
[0456]
本文所述的操作可以在任何有用或方便的步骤中执行。例如,可以在将样品引入分区(例如孔或液滴)之前、期间或之后将包含核酸条形码分子的珠粒引入分区中。可以使样品的核酸分子经受条形码化,这可以发生在珠粒上(在核酸分子保持与珠粒偶联的情况下)或在核酸条形码分子释放到分区中之后。在来自样品的核酸分子保持附接至珠粒的情况下,可以收集、汇集来自不同分区的珠粒并进行进一步处理(例如,逆转录、衔接子附接、扩增、清理、测序)。在其他情况下,处理可能发生在分区中。例如,可以在分区中提供足以进行条形码化、衔接子附接、逆转录或其他核酸处理操作的条件,并在清理和测序之前进行。
[0457]
在一些情况下,珠粒可以包含被配置为与对应捕获序列或结合序列结合的捕获序列或结合序列。在一些情况下,珠粒可以包含多个不同的捕获序列或结合序列,这些不同的捕获序列或结合序列被配置为与不同的各自对应捕获序列或结合序列结合。例如,珠粒可以包含各自被配置为与第一对应捕获序列结合的一个或多个捕获序列的第一子集,各自被配置为与第二对应捕获序列结合的一个或多个捕获序列的第二子集,各自被配置为与第三对应捕获序列结合的一个或多个捕获序列的第三子集,等等。珠粒可以包含任何数量的不同捕获序列。在一些情况下,珠粒可以包含至少2、3、4、5、6、7、8、9、10或更多个不同的捕获序列或结合序列,这些不同的捕获序列或结合序列被配置为分别与不同的相应捕获序列或结合序列结合。可替代地或此外,珠粒可以包含至多约10、9、8、7、6、5、4、3或2个不同的捕获序列或结合序列,这些不同的捕获序列或结合序列被配置为与不同的相应捕获序列或结合序列结合。在一些情况下,不同的捕获序列或结合序列可以被配置以促进对相同类型的分析物的分析。在一些情况下,不同的捕获序列或结合序列可以被配置以促进对不同类型的分析物(具有相同珠粒)的分析。捕获序列可以被设计为附接至相应的捕获序列。有利地,可以将此类对应的捕获序列引入或以其他方式诱导到生物颗粒(例如,细胞、细胞珠粒等)中,用于以各种形式(例如,包含对应捕获序列的条形码化抗体、包含对应捕获序列的条形码化mhc右旋聚体(dextramer)、包含对应捕获序列的条形码化指导rna分子等)进行不同的测
定,使得对应捕获序列随后可以同与珠粒缔合的捕获序列相互作用。在一些情况下,与珠粒(或其他支持物)偶联的捕获序列可以被配置为附接至接头分子,例如夹板分子,其中接头分子被配置为将珠粒(或其他支持物)与其他分子通过接头分子偶联,例如偶联至一种或多种分析物或一种或多种其他接头分子。
[0458]
图4说明了携带条形码的珠粒的另一实例。核酸分子405,例如寡核苷酸,可以通过可释放连键406例如二硫化物连接子,偶联至珠粒404。核酸分子405可以包含第一捕获序列460。同一珠粒404可以与包含其他捕获序列的一个或多个其他核酸分子403、407偶联(例如,经由可释放连键)。核酸分子405可以是条形码或包含条形码。如本文别处所述,条形码的结构可以包含许多序列元件,例如功能序列408(例如,流动池附接序列、测序引物序列等)、条形码序列410(例如,珠粒共有的珠粒特异性序列、分区共有的分区特异性序列等)和独特分子标识符412(例如,附接至珠粒的不同分子内的独特序列),或其部分序列。捕获序列460可以被配置为附接至对应的捕获序列465。在一些情况下,对应捕获序列465可以偶联至另一分子,所述分子可以是分析物或中间载体。例如,如图4所示,对应捕获序列465与包含靶序列464的指导rna分子462偶联,其中靶序列464被配置为附接至分析物。附接至珠粒404的另一寡核苷酸分子407包含第二捕获序列480,其被配置为附接至第二对应捕获序列485。如图4所示,第二对应捕获序列485与抗体482偶联。在一些情况下,抗体482可能对分析物(例如表面蛋白)具有结合特异性。可替代地,抗体482可能不具有结合特异性。附接至珠粒404的另一寡核苷酸分子403包含第三捕获序列470,其被配置为附接至第二对应捕获序列475。如图4所示,第三对应捕获序列475与分子472偶联。分子472可以或可以不被配置为靶向分析物。其他寡核苷酸分子403、407可以包括关于寡核苷酸分子405描述的其他序列(例如,功能序列、条形码序列、umi等)。虽然在图4中示出包含每个捕获序列的单个寡核苷酸分子,但是应当理解,对于每个捕获序列,珠粒可以包含一个或多个寡核苷酸分子的集合,每个寡核苷酸分子包含捕获序列。例如,珠粒可以包含任意数量组的一个或多个不同的捕获序列。可替代地或此外,珠粒404可以包含其他捕获序列。可替代地或此外,珠粒404可以包含更少类型的捕获序列(例如,两个捕获序列)。可替代地或此外,珠粒404可以包含寡核苷酸分子,所述寡核苷酸分子包含引发序列(例如特定引发序列,例如mrna特异性引发序列(例如多聚t序列))、靶向引发序列,和/或随机引发序列,例如,以促进基因表达的测定。
[0459]
在操作时,可以释放条形码化寡核苷酸(例如,在分区中),如本文别处所述。可替代地,结合至珠粒(例如凝胶珠粒)的核酸分子可用于杂交和捕获珠粒固相上的分析物(例如,一种或多种类型的分析物)。
[0460]
在一些情况下,包含具有反应性或能够被活化以使得变得具有反应性的官能团的前体可以与其他前体聚合以生成包含活化或可活化官能团的凝胶珠粒。然后官能团可用于将另外的物质(例如,二硫化物连接子、引物、其他寡核苷酸等)附接至凝胶珠粒。例如,一些包含羧酸(cooh)基团的前体可以与其他前体共聚以形成也包含cooh官能团的凝胶珠粒。在一些情况下,丙烯酸(包含游离cooh基团的物质)、丙烯酰胺和双(丙烯酰基)胱胺可以共聚合在一起以生成包含游离cooh基团的凝胶珠粒。凝胶珠粒的cooh基团可以被活化(例如,经由1-乙基-3-(3-二甲基氨基丙基)碳二亚胺(edc)和n-羟基琥珀酰亚胺(nhs)或4-(4,6-二甲氧基-1,3,5-三嗪-2-基)-4-甲基吗啉盐酸盐(dmtmm)),使得它们具有反应性(例如,当使用edc/nhs或dmtmm活化时,对胺官能团具有反应性)。然后,活化的cooh基团可以与包含待
连接到珠粒上的部分的适当物质(例如,包含胺官能团的物质,其中羧酸基团经活化以与胺官能团具有反应性)反应。
[0461]
在聚合物网络中包含二硫连键的珠粒可以通过将一些二硫连键还原成游离硫醇来用另外的物质官能化。二硫连键可以通过例如还原剂(例如,dtt、tcep等)的作用而还原,以产生游离硫醇基团,而珠粒不会溶解。然后,珠粒的游离硫醇可以与物质或包含另一二硫键的物质的游离硫醇反应(例如,通过硫醇-二硫化物交换),使得该物质可以与珠粒连接(例如,通过产生的二硫键)。在一些情况下,珠粒的游离硫醇可与任何其他适合基团反应。例如,珠粒的游离硫醇可与包含丙烯酰胺基部分的物质反应。珠粒的游离硫醇基团可以通过迈克尔加成化学与丙烯酰胺基反应,使得包含丙烯酰胺基的物质与珠粒连接。在一些情况下,可以通过包含硫醇封端剂(例如n-乙基马来酰胺或碘乙酸)来防止不受控制的反应。
[0462]
可以控制珠粒内二硫连键的活化,使得仅少量二硫连键被活化。例如,可以通过控制用于生成游离硫醇基团的还原剂的浓度和/或用于在珠粒聚合中形成二硫键的试剂的浓度来进行控制。在一些情况下,低浓度的还原剂分子(例如,小于或等于约1:100,000,000,000、小于或等于约1:10,000,000,000、小于或等于约1:1,000,000,000、小于或等于约1:100,000,000、小于或等于约1:10,000,000、小于或等于约1:1,000,000、小于或等于约1:100,000、小于或等于约1:10,000的还原剂分子:凝胶珠粒比率)可用于还原。控制还原为游离硫醇的二硫连键的数量可对确保官能化期间的珠粒结构完整性有用。在一些情况下,光学活性剂例如荧光染料可通过珠粒的游离硫醇基团与珠粒偶联,并用于定量珠粒中存在的游离硫醇的数量和/或跟踪珠粒。
[0463]
在一些情况下,在凝胶珠粒形成之后向凝胶珠粒中添加各部分可能是有利的。例如,在凝胶珠粒形成之后添加寡核苷酸(例如,带条形码的寡核苷酸)可以避免链转移终止期间物质的损失,该损失可在聚合过程中发生。而且,较小的前体(例如,不包含侧链基团和所连接的部分的单体或交联剂)可用于聚合,并且可以由于粘性效应,最小限度地阻碍其生长链端。在一些情况下,在凝胶珠粒合成之后的功能化可以使要负载潜在损伤因子(例如,自由基)和/或化学环境的物质(例如,寡核苷酸)的暴露最小化。在一些情况下,所产生的凝胶可具有上临界溶解温度(ucst),其可容许珠粒受温度驱动溶胀和坍塌。此类功能性可以有助于寡核苷酸(例如,引物)在随后用寡核苷酸对珠粒进行功能化期间渗入珠粒中。产生后的功能化也可用于控制珠粒中物质的负载比,使得例如负载比的可变性最小化。物质负载也可以在分批工艺中进行,使得多个珠粒可以在单一批次中受物质功能化。
[0464]
注入或以其他方式引入到分区中的珠粒可以包含可释放地、可裂解地或可逆地附接的条形码。注入或以其他方式引入到分区中的珠粒可以包含可活化的条形码。注入或以其他方式引入到分区中的珠粒可以是可降解的、可破裂的或可溶解的珠粒。
[0465]
条形码可以可释放地、可裂解地或可逆性地附接至珠粒,使得条形码可以通过条形码分子和珠粒之间的连键的裂解而释放或可释放,或通过基础珠粒本身的降解而释放,从而允许条形码被其他试剂接近或可接近,或两者。在非限制性实例中,裂解可通过以下方式实现:二硫键的还原、限制酶的使用、光活化裂解或通过其他类型的刺激(例如化学、热、ph、酶刺激等)进行的裂解和/或反应,例如本文别处所述的。可释放的条形码有时可以称为是可活化的,因为它们一旦释放就可用于反应。因此,例如,可活化的条形码可以通过使条形码从珠粒(或本文所述的其他合适类型的分区)中释放而活化。在所述方法和系统的上下
文中还设想了其他可活化构造。
[0466]
除了珠粒与缔合分子之间的可裂解连键外,或作为珠粒与缔合分子之间的可裂解连键的替代,所述缔合分子例如为含有核酸分子的条形码(例如,带条形码的寡核苷酸),珠粒可以是自发地或在暴露于一种或多种刺激(例如,温度变化、ph变化、暴露于特定化学物质或相、暴露于光、还原剂等)时可降解的、可破裂的或可溶解的。在一些情况下,珠粒可以是可溶解的,使得当暴露于特定化学物质或环境变化,例如温度变化或ph变化时,珠粒的材料组分被溶解。在一些情况下,凝胶珠粒可在高温和/或碱性条件下降解或溶解。在一些情况下,珠粒可以是可热降解的,使得当珠粒暴露于适当的温度变化(例如,热)时,珠粒降解。与物质(例如,核酸分子,例如,带条形码的寡核苷酸)结合的珠粒的降解或溶解可引起物质从珠粒中释放。
[0467]
从以上公开内容可以理解,珠粒的降解可以指在使物理珠粒本身的结构发生和不发生降解的情况下结合或夹带的物质从珠粒中解离。例如,珠粒的降解可涉及通过本文别处所述的一种或多种物质和/或方法裂解可裂解的连键。在另一个实例中,夹带的物质可以通过由于例如改变化学环境而产生的渗透压差从珠粒中释放。举例而言,由于渗透压差引起的珠粒孔径的改变通常可以在珠粒本身没有结构降解的情况下发生。在一些情况下,由于珠粒的渗透溶胀而引起的孔径增加可容许珠粒内夹带的物质释放。在其他情况下,珠粒的渗透收缩可使珠粒由于孔径收缩而更好地保留夹带的物质。
[0468]
可以将可降解珠粒引入到分区,例如乳液液滴或孔中,使得当施加适当的刺激时,珠粒在分区内降解并且任何缔合的物质(例如,寡核苷酸)都在液滴内释放。游离物质(例如,寡核苷酸、核酸分子)可以与分区中包含的其他试剂相互作用。例如,包含胱胺并通过二硫键与条形码序列连接的聚丙烯酰胺珠粒可以与还原剂在油包水乳液的液滴内组合。在液滴内,还原剂可以破坏各种二硫键,导致珠粒降解并将条形码序列释放到液滴的含水内部环境中。在另一个实例中,加热在碱性溶液中包含结合珠粒的条形码序列的液滴也可导致珠粒降解并将附接的条形码序列释放到液滴的含水内部环境中。
[0469]
任何合适数量的分子标签分子(例如,引物、条形码化寡核苷酸)可以与珠粒缔合,使得在从珠粒中释放后,分子标签分子(例如,引物,例如,条形码化寡核苷酸)以预先定义的浓度存在于分区中。可以选择此类预定浓度以促进在分区内产生测序文库的某些反应,例如扩增。在一些情况下,引物的预定浓度可以通过产生带有核酸分子(例如,寡核苷酸)的珠粒的过程来限制。
[0470]
在一些情况下,珠粒可以非共价地负载有一种或多种试剂。例如,通过使珠粒经受足以使珠粒溶胀的条件,允许有足够的时间使试剂扩散到珠粒的内部,以及使珠粒经受足以使珠粒去溶胀的条件,可以使珠粒非共价地负载。珠粒的溶胀可通过例如将珠粒置于热力学上有利的溶剂中,使珠粒经受更高或更低的温度,使珠粒经受更高或更低的离子浓度和/或使珠粒经受电场来完成。珠粒的溶胀可以通过各种溶胀方法完成。珠粒的去溶胀可通过例如转移热力学上有利的溶剂中的珠粒,使珠粒经受更低的温度或高温,使珠粒经受更低或更高的离子浓度和/或将珠粒从电场中移除来完成。珠粒的去溶胀可以通过各种去溶胀方法完成。转移珠粒可引起珠粒中的孔隙收缩。然后收缩可阻碍珠粒内的试剂从珠粒内部扩散出来。所述阻碍可能是由于试剂与珠粒内部之间的空间相互作用产生的。转移可以用微流体方式来完成。例如,可以通过将珠粒从一个共流溶剂流移动到不同的共流溶剂流
来实现转移。珠粒的可溶胀性和/或孔径可通过改变珠粒的聚合物组成来调节。
[0471]
在一些情况下,与前体连接的丙烯酰胺基部分,与前体连接的另一物质,或前体本身可包含不稳定键,例如化学敏感键、热敏键或光敏键,例如二硫键、uv敏感键等。一旦丙烯酰胺基部分或包含不稳定键的其他部分掺入到珠粒中,则珠粒也可以包含不稳定键。不稳定键可以例如用于将物质(例如,条形码、引物等)可逆性地连接(例如,共价连接)到珠粒上。在一些情况下,热不稳定键可以包括基于核酸杂交的附接,例如,其中寡核苷酸与附接至珠粒的互补序列杂交,使得杂交体的热解链使寡核苷酸(例如含条形码的序列)从珠粒或微囊中释放。
[0472]
向凝胶珠粒中添加多种类型的不稳定键可导致生成能够对不同刺激有反应的珠粒。每种类型的不稳定键可能对相关刺激(例如,化学刺激、光、温度、酶等)敏感,使得可以通过施加适当的刺激来控制经由每种不稳定键附接至珠粒的物质的释放。此类功能性可用于物质从凝胶珠粒的控释中。在一些情况下,包含不稳定键的另一种物质可以在凝胶珠粒形成之后通过例如如上所述的凝胶珠的活化官能团与凝胶珠粒连接。正如将认识到的,可释放地、可裂解地或可逆性地附接至本文所述的珠粒的条形码包括通过条形码分子和珠粒之间的连键的裂解而释放的条形码,或通过基础珠粒本身的降解而释放,从而允许条形码被其他试剂接近或可接近的条形码,或两者。
[0473]
在一些情况下,附接至固体支持物(例如珠粒)的物质(例如,包含条形码的寡核苷酸分子)可以包含允许物质从珠粒中释放的u切除元件。在一些情况下,u切除元件可以包含含有至少一个尿嘧啶的单链dna(ssdna)序列。所述物质可以通过含有至少一个尿嘧啶的ssdna序列附接至固体支持物。所述物质可以通过尿嘧啶-dna糖基化酶(例如,以去除尿嘧啶)和核酸内切酶(例如,以诱导ssdna断裂)的组合来释放。如果核酸内切酶从裂解中产生5’磷酸基团,则可以在下游处理中包括另外酶处理以例如在连接另外的测序柄元件之前(例如,illumina完整p5序列、部分p5序列、完整r1序列和/或部分r1序列)之前消除磷酸基团。
[0474]
如本文所述可释放的条形码有时可被称为可活化的,因为它们一旦释放就可用于反应。因此,例如,可活化的条形码可以通过使条形码从珠粒(或本文所述的其他合适类型的分区)中释放而活化。在所述方法和系统的上下文中还设想了其他可活化构造。
[0475]
除了可热裂解的键、二硫键和uv敏感键之外,可偶联至前体或珠粒的不稳定键的其他非限制性实例包括酯连键(例如,可被酸、碱或羟胺裂解)、邻二醇连键(例如,可经由高碘酸钠裂解)、diels-alder连键(例如,可经由热裂解)、砜连键(例如,可经由碱裂解)、甲硅烷基醚连键(例如,可经由酸裂解)、糖苷连键(例如,可经由淀粉酶裂解)、肽连键(例如,可经由蛋白酶裂解)或磷酸二酯连键(例如,可经由核酸酶(例如,dna酶)裂解)。键可通过其他靶向核酸分子的酶,例如限制酶(例如,限制性内切核酸酶)裂解,如下面进一步描述的。
[0476]
在珠粒产生期间(例如,在前体聚合期间),可以将物质包封在珠粒中。此类物质可以参与或可以不参与聚合。此类物质可以进入聚合反应混合物中,使得在珠粒形成后,产生的珠粒包含所述物质。在一些情况下,可以在形成之后将此类物质添加到凝胶珠粒中。此类物质可以包括例如核酸分子(例如,寡核苷酸),用于核酸扩增反应的试剂(例如,引物、聚合酶、dntp、辅因子(例如,离子辅因子)、缓冲剂)(包括本文所述的那些),用于酶促反应的试剂(例如,酶、辅因子、底物、缓冲剂),用于核酸修饰反应(例如聚合、连接或消化)的试剂,
和/或用于一个或多个测序平台的模板制备(例如,标签化)的试剂(例如,用于的)。此类物质可以包括本文所述的一种或多种酶,包括但不限于聚合酶、逆转录酶、限制酶(例如,内切核酸酶)、转座酶、连接酶、蛋白酶k、dna酶等。此类物质可以包括本文别处所述的一种或多种试剂(例如,溶解剂、抑制剂、灭活剂、螯合剂、刺激物)。此类物质的捕集可以通过在前体聚合期间产生的聚合物网络密度、对凝胶珠粒内离子电荷的控制(例如,通过与聚合物质连接的离子物质)或通过其他物质的释放来控制。可以在珠粒降解时和/或通过施加能够使物质从珠粒中释放的刺激,使包封的物质从珠粒中释放。可替代地或此外,可以在分区形成期间或之后,将物质分配在分区(例如,液滴)中。此类物质可以包括但不限于以上提到的也可以包封在珠粒中的物质。
[0477]
可降解珠粒可以包含一种或多种具有不稳定键的物质,使得当珠粒/物质暴露于适当的刺激时,键断裂并且珠粒降解。不稳定键可以是化学键(例如,共价键、离子键)或者可以是另一种类型的物理相互作用(例如,范德华相互作用、偶极-偶极相互作用等)。在一些情况下,用于产生珠粒的交联剂可以包含不稳定键。暴露于适当条件时,不稳定键可断裂并且珠粒降解。例如,将包含胱胺交联剂的聚丙烯酰胺凝胶珠粒暴露于还原剂时,胱胺的二硫键可断裂并且珠粒降解。
[0478]
与不降解的珠粒相比,当将适当的刺激施加到珠粒上时,可降解的珠粒可用于更快地从珠粒释放附接的物质(例如,核酸分子、条形码序列、引物等)。例如,对于与多孔珠粒的内表面结合的物质,或在包封的物质的情况下,在珠粒降解时,所述物质在溶液中可具有更大的迁移率和与其他物质的可接近性。在一些情况下,物质还可以经由可降解连接子(例如,二硫化物连接子)与可降解珠粒连接。可降解连接子可与可降解珠粒响应于相同的刺激,或者两种可降解物质可响应于不同的刺激。例如,条形码序列可以通过二硫键与包含胱胺的聚丙烯酰胺珠粒连接。带条形码的珠粒暴露于还原剂时,珠粒会降解并且在条形码序列与珠粒之间的二硫连键以及珠粒中的胱胺的二硫连键都断裂时,条形码序列被释放。
[0479]
从以上公开内容可以理解,虽然被称为珠粒的降解,但在如上所述的许多情况下,所述降解可以指在使物理珠粒本身的结构发生和不发生降解的情况下结合或夹带的物质从珠粒中解离。例如,夹带的物质可以通过由于例如改变化学环境而产生的渗透压差从珠粒中释放。举例而言,由于渗透压差引起的珠粒孔径的改变通常可以在珠粒本身没有结构降解的情况下发生。在一些情况下,由于珠粒的渗透溶胀而引起的孔径增加可容许珠粒内夹带的物质释放。在其他情况下,珠粒的渗透收缩可使珠粒由于孔径收缩而更好地保留夹带的物质。
[0480]
在提供可降解珠粒的情况下,可能有益的是避免在给定时间之前将此类珠粒暴露于导致此类降解的刺激或刺激物,以便例如避免珠粒过早降解和由此类降解引起的问题,包括例如较差的流动特性和聚集。举例而言,在珠粒包含可还原的交联基团,例如二硫基团的情况下,期望避免使此类珠粒与还原剂例如dtt或其他二硫化物裂解试剂接触。在此类情况下,将在一些情况下提供不含还原剂(例如dtt)的对本文所述珠粒的处理。因为在商业酶制剂中常常会提供还原剂,所以可能期望在处理本文所述的珠粒时提供不含还原剂(或不含dtt)的酶制剂。此类酶的实例包括例如聚合酶制剂、逆转录酶制剂、连接酶制剂以及许多可用于处理本文所述的珠粒的其他酶制剂。术语“不含还原剂”或“不含dtt”的制剂可以指具有小于约1/10、小于约1/50或甚至小于约1/100下限的用于降解珠粒的此类材料的制剂。
例如,对于dtt,不含还原剂的制剂可以具有小于约0.01毫摩尔(mm)、0.005mm、0.001mm dtt、0.0005mm dtt,或甚至小于约0.0001mm dtt。在许多情况下,dtt的量是不可检测的。
[0481]
可以使用许多化学触发剂来触发珠粒的降解。这些化学变化的实例可以包括ph介导的珠粒内组分完整性的改变、珠粒组分通过交联键断裂进行的降解和珠粒组分的解聚。
[0482]
在一些实施方案中,珠粒可由包含可降解的化学交联剂例如bac或胱胺的材料形成。此类可降解交联剂的降解可以通过许多机制完成。在一些实例中,可以使珠粒与可以诱导氧化、还原或其他化学变化的化学降解剂接触。例如,化学降解剂可以是还原剂,例如二硫苏糖醇(dtt)。还原剂的另外实例可以包括、β-巯基乙醇、(2s)-2-氨基-1,4-二巯基丁烷(二硫代丁胺或dtba)、三(2-羧乙基)膦(tcep)或它们的组合。还原剂可以降解在形成珠粒的凝胶前体之间形成的二硫键,并且因此可以降解珠粒。在其他情况下,溶液ph的变化,例如ph的增加,可触发珠粒的降解。在其他情况下,暴露于水溶液例如水,可触发水解降解,并且因此可以触发珠粒的降解。在一些情况下,刺激的任何组合可以触发珠粒的降解。例如,ph的变化可以使化学试剂(例如,dtt)成为有效的还原剂。
[0483]
在施加热刺激后,还可以诱导珠粒释放其内容物。温度的变化可引起珠粒的各种变化。例如,热量可以引起固体珠粒液化。热量的变化可引起珠粒熔融,使得珠粒的一部分降解。在其他情况下,热量可以增加珠粒组分的内部压力,使得珠粒破裂或爆裂。热量也可作用于用作构造珠粒的材料的热敏聚合物。
[0484]
任何合适的剂都可以降解珠粒。在一些实施方案中,可以使用温度或ph的变化来降解珠粒中的热敏或ph敏感键。在一些实施方案中,可以使用化学降解剂通过氧化、还原或其他化学变化来降解珠粒中的化学键。例如,化学降解剂可以是还原剂,例如dtt,其中dtt可以降解在交联剂与凝胶前体之间形成的二硫键,从而降解珠粒。在一些实施方案中,可以添加还原剂以降解珠粒,这可以引起或可以不引起珠粒释放其内容物。还原剂的实例可以包括二硫苏糖醇(dtt)、β-巯基乙醇、(2s)-2-氨基-1,4-二巯基丁烷(二硫代丁胺或dtba)、三(2-羧乙基)膦(tcep)或它们的组合。还原剂可以约0.1mm、0.5mm、1mm、5mm、10mm的浓度存在。还原剂可以以至少约0.1mm、0.5mm、1mm、5mm、10mm或高于10mm的浓度存在。还原剂可以以至多约10mm、5mm、1mm、0.5mm、0.1mm或更低的浓度存在。
[0485]
任何合适数量的分子标签分子(例如,引物、条形码化寡核苷酸)可以与珠粒缔合,使得在从珠粒中释放后,分子标签分子(例如,引物,例如,条形码化寡核苷酸)以预先定义的浓度存在于分区中。可以选择此类预定浓度以促进在分区内产生测序文库的某些反应,例如扩增。在一些情况下,引物的预定浓度可以通过产生带有寡核苷酸的珠粒的过程来限制。
[0486]
在一些实例中,多个分区中的分区可以包含单个生物颗粒或分析物载体(例如,单个细胞或单个细胞核)。在一些实例中,多个分区中的分区可以包含多个生物颗粒或分析物载体。此类分区可以称为多重占用分区,并且可以包含例如两个、三个、四个或更多个细胞和/或微囊(例如珠粒),其在单个分区内包含条形码化核酸分子(例如寡核苷酸)。因此,如上所述,可以控制含有生物颗粒和/或珠粒的流体和分配流体的流动特征,以提供此类多个占用的分区。具体来说,可以控制流动参数以提供大于约50%的分区、大于约75%,并且在一些情况下大于约80%、90%、95%或更高百分比的给定占用率。
[0487]
在一些情况下,可以使用另外的微囊将另外的试剂递送至分区。在此类情况下,可
能有利的是将不同的珠粒从不同的珠粒源(例如,含有不同的相关试剂)通过通入共用通道或液滴生成接点的不同通道入口引入到此类共用通道或液滴生成接点中。在此类情况下,可以控制不同珠粒流入通道或接点的流量和频率,以提供一定比率的来自每个来源的微囊,同时确保进入分区的此类珠粒与给定数量的生物颗粒的给定配对或组合(例如,每个分区一个生物颗粒和一个珠粒)。
[0488]
本文所述的分区可包括小体积,例如,小于约10微升(μl)、5μl、1μl、900皮升(pl)、800pl、700pl、600pl、500pl、400pl、300pl、200pl、100pl、50pl、20pl、10pl、1pl、500纳升(nl)、100nl、50nl或更低。
[0489]
例如,在基于液滴的分区的情况下,液滴可具有小于约1000pl、900pl、800pl、700pl、600pl、500pl、400pl、300pl、200pl、100pl、50pl、20pl、10pl、1pl或更少的总体积。在与微囊共同分配的情况下,将认识到在分区内的样品流体体积,例如包括共同分配的生物颗粒和/或珠粒,可以小于上述体积的约90%、小于上述体积的约80%、小于上述体积的约70%、小于上述体积的约60%、小于上述体积的约50%、小于上述体积的约40%、小于上述体积的约30%、小于上述体积的约20%或小于上述体积的约10%。
[0490]
如本文别处所述,分区物质可产生分区群体或多个分区。在此类情况下,可以产生或以其他方式提供任意合适数量的分区。例如,可产生或以其他方式提供至少约1,000个分区、至少约5,000个分区、至少约10,000个分区、至少约50,000个分区、至少约100,000个分区、至少约500,000个分区、至少约1,000,000个分区、至少约5,000,000个分区、至少约10,000,000个分区、至少约50,000,000个分区、至少约100,000,000个分区、至少约500,000,000个分区、至少约1,000,000,000个分区或更多个分区。而且,所述多个分区可以包括未占用分区(例如,空分区)和已占用分区。
[0491]
流式分选
[0492]
样品可以源自任何可用的来源,包括任何受试者,例如人类受试者。样品可以包含来自一种或多种不同来源的材料(例如,一种或多种分析物载体),例如一种或多种不同的受试者。多个样品,例如来自单个受试者的多个样品(例如,以相同或不同方式从相同或不同身体位置获得的多个样品,和/或在相同或不同时间(例如,间隔数秒、数分钟、数小时、数天、数周、数月或数年)获得的多个样品),或来自不同受试者的多个样品,可用于如本文所述的分析。例如,可以在第一时间从受试者获得第一样品,并且可以在比第一时间晚的第二时间从该受试者获得第二样品。第一时间可以在受试者经历治疗方案或程序(例如,以解决疾病或疾患)之前,并且第二次可以在受试者经历治疗方案或程序期间或之后。在另一个实例中,可以从受试者的第一身体位置或系统(例如,使用第一收集技术)获得第一样品,并且可以从受试者的第二身体位置或系统(例如,使用第二收集技术)获得第二样品,所述第二身体位置或系统可以不同于第一身体位置或系统。在另一个实例中,可以同时从受试者的相同或不同身体位置获得多个样品。不同样品,例如从同一受试者的不同身体位置、在不同时间、从多个不同受试者和/或使用不同收集技术收集的受试物,可以经历相同或不同的处理(例如,如本文所述)。例如,第一样品可以经历第一处理方案并且第二样品可以经历第二处理方案。
[0493]
样品可以是生物样品,例如细胞样品(例如,如本文所述)。样品可以包括一种或多种分析物载体,例如一种或多种细胞和/或细胞成分,例如一种或多种细胞核。例如,样品可
和250μm3之间的体积。
[0496]
生物样品的细胞可以包括一个或多个相同或不同的横截面。在一些情况下,细胞可以具有不同于第二横截面的第一横截面。细胞可以具有为至少约1μm的第一横截面。例如,细胞可以包括至少约1微米(μm)、2μm、3μm、4μm、5μm、6μm、7μm、8μm、9μm、10μm、11μm、12μm、13μm、14μm、15μm、16μm、17μm、18μm、19μm、20μm、25μm、30μm、35μm、40μm、45μm、50μm、55μm、60μm、65μm、70μm、75μm、80μm、85μm、90μm、100μm、120μm、140μm、160μm、180μm、200μm、250μm、300μm、350μm、400μm、450μm、500μm、550μm、600μm、650μm、700μm、750μm、800μm、850μm、900μm、950μm、1毫米(mm)或更大的横截面(例如第一横截面)。在一些情况下,细胞可以包括在约1μm和500μm之间,例如约1μm和100μm之间、约100μm和200μm之间、约200μm和300μm之间、约300μm和400μm之间或约400μm和500μm之间的横截面(例如第一横截面)。例如,细胞可以包括约1μm和100μm之间的横截面(例如第一横截面)。在一些情况下,细胞可以具有为至少约1μm的第二横截面。例如,细胞可以包括至少约1微米(μm)、2μm、3μm、4μm、5μm、6μm、7μm、8μm、9μm、10μm、11μm、12μm、13μm、14μm、15μm、16μm、17μm、18μm、19μm、20μm、25μm、30μm、35μm、40μm、45μm、50μm、55μm、60μm、65μm、70μm、75μm、80μm、85μm、90μm、100μm、120μm、140μm、160μm、180μm、200μm、250μm、300μm、350μm、400μm、450μm、500μm、550μm、600μm、650μm、700μm、750μm、800μm、850μm、900μm、950μm、1毫米(mm)或更大的第二横截面。在一些情况下,细胞可以包括在约1μm和500μm之间,例如约1μm和100μm之间、约100μm和200μm之间、约200μm和300μm之间、约300μm和400μm之间或约400μm和500μm之间的第二横截面。例如,细胞可以包括在约1μm和100μm之间的第二横截面。
[0497]
横截面(例如第一横截面)可以对应于细胞的直径。在一些情况下,细胞可以是近似球形的。在此类情况下,第一横截面可以对应于细胞的直径。在其他情况下,细胞可以是近似圆柱形的。在此类情况下,第一横截面可以对应于沿近似圆柱形细胞的直径、长度或宽度。在一些情况下,细胞可以包含一个表面。细胞表面可以包含一种或多种特征。例如,细胞可以包括树突接收器、鞭毛、粗糙边界或其他特征。
[0498]
细胞的一个特征或一组特征可以由一个或多个条件改变。适于改变细胞的一个特征或一组特征的条件可以是例如温度、ph、离子或盐浓度、压力或其他条件。例如,细胞可能暴露于可能导致细胞的一种或多种特征发生变化的化学物质。在一些情况下,可以使用刺激来改变细胞的一种或多种特征。例如,在施加刺激后,可以改变细胞的一种或多种特征。刺激可以是例如热刺激、光刺激、化学刺激或其他刺激。在一些情况下,足以改变细胞的一种或多种特征的条件可以包括一种或多种不同的条件,例如温度和压力、ph和盐浓度、化学物质和温度,或任何其他的条件组合。足以改变细胞的一种或多种特征的温度可以是例如至少约摄氏0度(℃)、1℃、2℃、3℃、4℃、5℃、10℃或更高。例如,温度可以是约4℃。在其他情况下,足以改变细胞的一种或多种特征的温度可以是例如至少约25℃、30℃、35℃、37℃、40℃、45℃、50℃或更高。例如,温度可以是约37℃。足以改变细胞的一种或多种特征的ph可以是例如在约5和8之间,例如在约6和7之间。
[0499]
生物样品可以包括具有不同尺寸和特征的多个细胞。在一些情况下,生物样品的处理,例如细胞分离和分选(例如,如本文所述),可以通过消耗具有某些特征和尺寸的细胞和/或分离具有某些特征和尺寸的细胞来影响样品中包括的尺寸和细胞特征的分布。
[0500]
样品可以经历一种或多种准备分析的过程(例如,如本文所述),包括但不限于过
滤、选择性沉淀、纯化、离心、透化、分离、搅拌、加热和/或其他过程。例如,可以过滤样品以除去污染物或其他物质。在一个实例中,过滤过程可以包括使用微流体(例如,以分离具有不同大小、类型、电荷或其他特征的分析物载体)。
[0501]
在一个实例中,可以处理包含一个或多个细胞的样品以将一个或多个细胞与样品中的其他物质分离(例如,使用离心和/或另一种方法)。在一些情况下,可以处理样品的细胞和/或细胞成分以分离和/或分选成细胞和/或细胞成分的组,例如分离和/或分选不同类型的细胞和/或细胞成分。细胞分离的实例包括但不限于白细胞或免疫细胞与其他血细胞和组分的分离,循环肿瘤细胞从血液的分离以及细菌与身体细胞和/或环境物质的分离。分离过程可以包括阳性选择过程(例如,靶向目标细胞类型以保留用于后续下游分析,例如通过使用靶向目标细胞类型的表面标志物的单克隆抗体)、阴性选择过程(例如,除去一种或多种细胞类型并保留一种或多种其他目标细胞类型),和/或消耗过程(例如,从样品中除去单个细胞类型,例如从外周血单核细胞中除去红细胞)。
[0502]
一种或多种不同类型细胞的分离可以包括例如离心、过滤、基于微流体的分选、流式细胞术、荧光活化细胞分选(facs)、磁活化细胞分选(macs)、浮力活化细胞分选(bacs),或任何其他可用的方法。例如,流式细胞术方法可用于基于例如大小、形态或蛋白质表达的参数来检测细胞和/或细胞成分。基于流式细胞术的细胞分选可以包括将样品注入鞘液中,所述鞘液将样品的细胞和/或细胞成分一次一个地输送到测量区域中。在测量区域中,光源例如激光可以询问细胞和/或细胞成分,并且可以检测散射光和/或荧光并将其转换为数字信号。喷嘴系统(例如振动喷嘴系统)可用于产生包含单个细胞和/或细胞成分的液滴(例如水性液滴)。可以用电荷(例如,使用充电环)标记包括目标细胞和/或细胞成分的液滴(例如,如通过光学检测确定),电荷可用于将这些液滴与包括其他细胞和/或细胞成分的液滴分离。例如,facs可以包括用荧光标志物(例如,使用内部和/或外部生物标志物)标记细胞和/或细胞成分。然后可以逐一测量和鉴定细胞和/或细胞成分,并根据标志物的发射荧光或不存在荧光进行分选。macs可以使用微米或纳米级磁性颗粒结合细胞和/或细胞成分(例如,通过抗体与细胞表面标志物的相互作用),以促进目标细胞和/或细胞成分与样品的其他组分的磁性分离(例如,使用基于柱的分析)。bacs可以使用利用抗体标记的微泡(例如,玻璃微泡)来靶向目标细胞。与微泡偶联的细胞和/或细胞组分可以漂浮到溶液的表面,从而将靶细胞和/或细胞组分与样品的其他组分分离。细胞分离技术可用于富集目标细胞群体(例如,在分配之前,如本文所述)。例如,可以对包含多个细胞的样品进行阳性分离处理,所述多个细胞包括给定类型的多个细胞。给定类型的多个细胞可以用荧光标志物(例如,基于表达的细胞表面标志物或其他标志物)进行标记,并进行facs过程以将这些细胞与多个细胞中的其他细胞分开。然后可以对选择的细胞进行后续的基于分区的分析(例如,如本文所述)或其他下游分析。荧光标志物可以在这种分析之前被去除或者可以被保留。荧光标志物可以包括鉴定特征,例如核酸条形码序列和/或独特分子标识符。
[0503]
在另一个实例中,包含包括给定类型的第一多个细胞(例如,表达特定标志物或标志物组合的免疫细胞)的第一多个细胞的第一样品和包含包括给定类型的第二多个细胞的第二多个细胞的第二样品可以进行阳性分离过程。可以使用相同或不同的收集技术从相同或不同的受试者,以相同或不同的类型,从相同或不同的身体位置或系统收集第一样品和第二样品。例如,第一样品可以来自第一受试者并且第二样品可以来自与第一受试者不同
的第二受试者。可以向第一样品的第一多个细胞提供第一多个荧光标志物,所述第一多个荧光标志物被配置为标记给定类型的第一多个细胞。可以向第二样品的第二多个细胞提供第二多个荧光标志物,所述第二多个荧光标志物被配置为标记给定类型的第二多个细胞。第一多个荧光标志物可以包括第一鉴定特征,例如第一条形码,而第二多个荧光标志物可以包括不同于第一鉴定特征的第二鉴定特征,例如第二条形码。第一多个荧光标志物和第二多个荧光标志物可以在用相同的激发源(例如,光源,例如激光)激发时以相同的强度和相同的波长范围发出荧光。然后可以组合第一样品和第二样品并进行facs过程以基于标记给定类型的第一多个细胞的第一多个荧光标志物和标记给定类型的第二多个细胞的第二多个荧光标志物将给定类型的细胞与其他细胞分离。可替代地,第一样品和第二样品可以经历单独的facs过程,然后可以组合来自第一样品的给定类型的阳性选择的细胞和来自第二样品的给定类型的阳性选择的细胞用于后续分析。不同荧光标志物的所编码鉴定特征可用于鉴定源自于第一样品的细胞和源自于第二样品的细胞。例如,第一和第二鉴定特征可以被配置为与核酸条形码分子(例如,如本文所述)相互作用(例如,在分区中,如本文所述)以产生可使用例如核酸测序检测的条形码化核酸产物。
[0504]
多重化
[0505]
本公开提供了用于多重化以及以其他方式增加分析中的通量的方法和系统。例如,单个或集成的过程工作流程可以允许对更多或多种分析物、更多或多种类型的分析物和/或更多或多种类型的分析物表征进行处理、鉴定和/或分析。例如,在本文所述的方法和系统中,一种或多种能够结合或以其他方式偶联至一种或多种细胞特征的标记剂可用于表征分析物载体和/或细胞特征。在一些情况下,细胞特征包括细胞表面特征。细胞表面特征可以包括但不限于受体、抗原、表面蛋白、跨膜蛋白、分化蛋白簇、蛋白通道、蛋白泵、载体蛋白、磷脂、糖蛋白、糖脂、细胞-细胞相互作用蛋白复合物、抗原呈递复合物、主要组织相容性复合物、工程化t细胞受体、t细胞受体、b细胞受体、嵌合抗原受体、间隙连接、粘附连接,或它们的任何组合。在一些情况下,细胞特征可以包括细胞内分析物,例如蛋白质、蛋白质修饰(例如,磷酸化状态或其他翻译后修饰)、核蛋白、核膜蛋白或它们的任何组合。标记剂可以包括但不限于蛋白质、肽、抗体(或其表位结合片段)、亲脂性部分(例如胆固醇)、细胞表面受体结合分子、受体配体、小分子、双特异性抗体、双特异性t细胞衔接子、t细胞受体衔接子、b细胞受体衔接子、亲体、适体、单体、affimer、darpin和蛋白支架,或它们的任何组合。标记剂可以包括(例如,附接至)报告寡核苷酸,其指示结合基团所结合的细胞表面特征。例如,报告寡核苷酸可以包含允许鉴定标记剂的条形码序列。例如,特异于一种类型的细胞特征(例如,第一细胞表面特征)的标记剂可以具有偶联至其的第一报告寡核苷酸,而特异于不同细胞特征(例如,第二细胞表面特征)的标记剂可以具有偶联至其的不同报告寡核苷酸。对于示例性标记剂、报告寡核苷酸和使用方法的描述,参见例如美国专利第10,550,429号;美国专利公布20190177800和20190367969,所述专利各自出于所有目的以引用是方式整体并入本文。
[0506]
在一个具体实例中,可以提供潜在的细胞特征标记剂文库,其中各个细胞特征标记剂与核酸报告分子缔合,使得不同的报告寡核苷酸序列与能够结合至特定细胞特征的各标记剂缔合。在一些方面,文库的不同成员可以通过不同寡核苷酸序列标记的存在来表征。例如,能够与第一蛋白质结合的抗体可能具有与其缔合的第一报告寡核苷酸序列,而能够
与第二蛋白质缔合的抗体可能具有与其缔合的不同的报告寡核苷酸序列。特定寡核苷酸序列的存在可指示特定抗体或可被特定抗体鉴定或结合的细胞特征的存在。
[0507]
能够与一种或多种分析物载体结合或以其他方式偶联的标记剂可用于将分析物载体表征为属于特定的一组分析物载体。例如,标记剂可用于标记细胞或一组细胞的样品。这样,一组细胞可以被标记为与另一组细胞不同。在一个实例中,第一组细胞可以源自于第一样品,而第二组细胞可以源自于第二样品。标记剂可以允许第一组和第二组具有不同的标记剂(或与标记剂缔合的报告寡核苷酸)。例如,这可以促进多重化,其中第一组的细胞和第二组的细胞可以分别标记,然后汇集在一起用于下游分析。标记的下游检测可以指示分析物属于特定组。
[0508]
例如,报告寡核苷酸可以连接至抗体或其表位结合片段,并且标记分析物载体可以包括使抗体连接的条形码分子或表位结合片段连接的条形码分子经受适合抗体结合至分析物载体表面上存在的分子的条件。抗体或其表位结合片段与表面上存在的分子之间的结合亲和力可以在所需范围内,以确保抗体或其表位结合片段保持与分子结合。例如,结合亲和力可以在所需范围内,以确保抗体或其表位结合片段在各种样品处理步骤(例如分配和/或核酸扩增或延伸)期间保持与分子结合。抗体或其表位结合片段与所结合分子之间的解离常数(kd)可以小于约100μm、90μm、80μm、70μm、60μm、50μm、40μm、30μm、20μm、10μm、9μm、8μm、7μm、6μm、5μm、4μm、3μm、2μm、1μm、900nm、800nm、700nm、600nm、500nm、400nm、300nm、200nm、100nm、90nm、80nm、70nm、60nm、50nm、40nm、30nm、20nm、10nm、9nm、8nm、7nm、6nm、5nm、4nm、3nm、2nm、1nm、900pm、800pm、700pm、600pm、500pm、400pm、300pm、200pm、100pm、90pm、80pm、70pm、60pm、50pm、40pm、30pm、20pm、10pm、9pm、8pm、7pm、6pm、5pm、4pm、3pm、2pm或1pm。例如,解离常数可以小于约10μm。
[0509]
在另一个实例中,报告寡核苷酸可以与细胞穿透肽(cpp)偶联,并且标记细胞可以包括将cpp偶联的报告寡核苷酸递送到分析物载体中。标记分析物载体可以包括通过细胞穿透肽将cpp缀合的寡核苷酸递送到细胞和/或细胞珠粒中。可用于本文提供的方法的细胞穿透肽可以包含至少一个非功能性半胱氨酸残基,该残基可以是游离的或衍生的以与寡核苷酸形成二硫连键,已针对这种连键对该寡核苷酸进行了修饰。可用于本文实施方案的细胞穿透肽的非限制性实例包括penetratin、transportan、plsl、tat(48-60)、pvec、mts和map。可用于本文提供的方法的细胞穿透肽可具有诱导细胞群中至少约30%、40%、50%、60%、70%、80%、90%、95%、96%、97%、98%、99%或100%的细胞的细胞穿透的能力。细胞穿透肽可以是富含精氨酸的肽转运蛋白。细胞穿透肽可以是penetratin或tat肽。
[0510]
在另一个实例中,报告寡核苷酸可以与荧光团或染料偶联,并且标记细胞可以包括使荧光团连接的条形码分子经受适合荧光团结合至分析物载体表面的条件。在一些情况下,荧光团可以与脂质双层强烈相互作用,并且标记分析物载体可以包括使荧光团连接的条形码分子经受使得荧光团结合或插入分析物载体膜中的条件。在一些情况下,荧光团是水溶性的有机荧光团。在一些情况下,荧光团是alexa532马来酰亚胺、四甲基罗丹明-5-马来酰亚胺(tmr马来酰亚胺)、bodipy-tmr马来酰亚胺、磺基-cy3马来酰亚胺、alexa 546羧酸/琥珀酰亚胺基酯、atto 550马来酰亚胺、cy3羧酸/琥珀酰亚胺基酯、cy3b羧酸/琥珀酰亚胺基酯、atto 565生物素、磺基罗丹明b、alexa594马来酰亚胺、texas red马来酰亚胺、alexa 633马来酰亚胺、abberior star 635p叠氮化物、atto 647n马来酰亚胺、atto 647se
或磺基-cy5马来酰亚胺。关于有机荧光团的描述,参见例如hughes l d等人plos one.2014年2月4日;9(2):e87649,其出于所有目的特此以引用的方式整体并入。
[0511]
报告寡核苷酸可以与亲脂性分子偶联,并且标记分析物载体可以包括通过亲脂性分子将核酸条形码分子递送到分析物载体的膜或核膜。亲脂性分子可以与脂质膜例如细胞膜和核膜缔合和/或插入其中。在一些情况下,所述插入可以是可逆的。在一些情况下,亲脂性分子与分析物载体之间的缔合可以使得分析物载体在后续处理(例如,分配、细胞透化、扩增、汇集等)期间保留亲脂性分子(例如,及其相关组分,例如核酸条形码分子)。报告核苷酸可以进入细胞内空间和/或细胞核中。
[0512]
报告寡核苷酸可以是核酸分子的一部分,所述核酸分子包含任何数量的功能序列,如本文别处所述,例如靶标捕获序列、随机引物序列等,并且与作为或源自分析物的另一核酸分子偶联。
[0513]
在分配之前,所述细胞可以与标记剂文库一起孵育,所述标记剂可以是针对不同细胞特征(例如,受体、蛋白质等)的大组的标记剂,并且包括所缔合的报告寡核苷酸。未结合的标记剂可以从细胞中洗掉,然后所述细胞可以与如本文别处所述的分区特异性条形码寡核苷酸(例如,附接至支持物,例如珠粒或凝胶珠粒)一起共同分配(例如,至液滴或孔中)。因此,分区可以包括一个或多个细胞,以及结合的标记剂及其缔合的已知的报告寡核苷酸。
[0514]
在其他情况下,例如,为了促进样品多重化,对特定细胞特征具有特异性的标记剂可以具有与第一报告寡核苷酸偶联的第一多个标记剂(例如,抗体或亲脂性部分)以及与第二报告寡核苷酸偶联的第二多个标记剂。例如,第一多个标记试剂和第二多个标记试剂可以与不同的细胞、细胞群体或样品相互作用,允许特定报告寡核苷酸指示特定细胞群体(或细胞或样品)和细胞特征。以此方式,不同的样品或组可以被独立处理,随后合并在一起用于合并分析(例如,如本文别处所述的基于分区的条形码化)。参见例如美国专利公布20190323088,其出于所有目的特此以引用的方式整体并入。
[0515]
如本文别处所述,标记剂文库可以与特定细胞特征相关,以及用于将分析物鉴定为源自特定分析物载体、群体或样品。分析物载体可以与多个文库一起孵育,并且给定分析物载体可以包含多种标记剂。例如,细胞可以包含与其偶联的亲脂性标记剂和抗体。亲脂性标记剂可以表明细胞是特定细胞样品的成员,而抗体可以表明细胞包含特定分析物。以此方式,报告寡核苷酸和标记剂可以允许进行多分析物、多重化分析。
[0516]
在一些情况下,这些报告寡核苷酸可以包含允许鉴定与报告寡核苷酸偶联的标记剂的核酸条形码序列。使用寡核苷酸作为报告物可以提供以下优点:能够产生在序列方面的显著多样性,同时还可容易地附接到大多数生物分子例如抗体等,以及易于被检测,例如,使用测序或阵列技术。
[0517]
报告寡核苷酸与标记剂的附接(偶联)可以通过多种直接或间接、共价或非共价缔合或附接中的任一种来实现。例如,可以使用化学缀合技术(例如,可从innova biosciences获得的抗体标记试剂盒)以及其他非共价附接机制,例如,使用生物素化的抗体和具有抗生物素蛋白或链霉抗生物素蛋白接头的寡核苷酸(或包括一个或多个与寡核苷酸偶联的生物素化接头的珠粒),将寡核苷酸共价附接至标记剂(例如蛋白质,例如抗体或抗体片段)的一部分。抗体和寡核苷酸生物素化技术是可用的。参见例如
fang等人,“fluoride-cleavable biotinylation phosphoramidite for 5
′‑
end-labelling and affinity purification of synthetic oligonucleotides,”nucleic acids res.2003年1月15日;31(2):708-715,其出于所有目的以引用的方式整体并入本文。同样,蛋白质和肽生物素化技术已经被开发并且可易于获得。参见,例如,美国专利第6,265,552号,其出于所有目的以引用的方式整体并入本文。此外,点击反应化学例如甲基四嗪-peg5-nhs酯反应、tco-peg4-nhs酯反应等可以用于将报告寡核苷酸与标记剂偶联。可商购获得的试剂盒例如来自thunderlink和abcam的那些以及本领域中常用的技术可以视情况用于将报告寡核苷酸与标记剂偶联。在另一个实例中,标记剂间接(例如,经由杂交)与包含鉴定标记剂的条形码序列的报告寡核苷酸偶联。例如,标记剂可以直接与杂交寡核苷酸偶联(例如,共价结合),所述杂交寡核苷酸包含与报告寡核苷酸序列杂交的序列。杂交寡核苷酸与报告寡核苷酸的杂交将标记剂与报告寡核苷酸偶联。在一些实施方案中,报告寡核苷酸是可从标记剂释放的,例如在施加刺激后。例如,报告寡核苷酸可以经由不稳定键(例如,化学不稳定、光不稳定、热不稳定等)附接至标记剂,如本文别处针对从支持物释放分子所大体描述。在一些情况下,本文所述的报告寡核苷酸可以包括可以用于后续处理中的一个或多个功能序列,例如衔接子序列、独特分子标识符(umi)序列、测序仪专用流动池附接序列(例如p5、p7或者部分p5或p7序列)、引物或引物结合序列、测序引物或引物结合序列(例如r1、r2或者部分r1或r2序列)。
[0518]
在一些情况下,标记剂可以包含报告寡核苷酸和标记。标记可以是荧光团、放射性同位素、能够进行比色反应的分子、磁性颗粒或能够检测的任何其他合适的分子或化合物。标记可以直接或间接缀合至标记剂(或报告寡核苷酸)(例如,标记可以缀合至可结合标记剂或报告寡核苷酸的分子)。在一些情况下,标记缀合至与报告寡核苷酸的序列互补的寡核苷酸,并且所述寡核苷酸可以被允许与报告寡核苷酸杂交。图11描述了示例性标记剂(1110、1120、1130),其包含附接至其的报告寡核苷酸(1140)。标记剂1110(例如,本文所述的任何标记剂)附接(直接地,例如共价附接,或间接地)至报告寡核苷酸1140。报告寡核苷酸1140可以包含鉴定标记剂1110的条形码序列1142。
[0519]
报告寡核苷酸1140还可以包含可以用于后续处理中的一个或多个功能序列,例如衔接子序列、独特分子标识符(umi)序列、测序仪专用流动池附接序列(例如p5、p7或者部分p5或p7序列)、引物或引物结合序列,或测序引物或引物结合序列(例如r1、r2或者部分r1或r2序列)。
[0520]
参考图11,在一些情况下,缀合至标记剂(例如,1110、1120、1130)的报告寡核苷酸1140包含引物序列1141、鉴定标记剂(例如,1110、1120、1130)的条形码序列和功能序列1143。功能序列1143可以被配置为与互补序列杂交,所述互补序列例如存在于核酸条形码分子1190(未显示)上的互补序列,例如本文别处所述的那些。在一些情况下,核酸条形码分子1190附接至支持物(例如珠粒,例如凝胶珠粒),例如本文别处所述的那些。例如,核酸条形码分子1190可以经由可释放连键(例如,包括不稳定键)附接至支持物,例如本文别处所述的那些。在一些情况下,报告寡核苷酸1140包含一个或多个另外功能序列,例如上文所述的那些。
[0521]
在一些情况下,标记剂1110是包含报告寡核苷酸1140的蛋白质或多肽(例如抗原或预期抗原)。报告寡核苷酸1140包含鉴定多肽1110并且可以用于推断分析物例如多肽
1110的结合配偶体(即,多肽1110可以结合的分子或化合物)的存在的条形码序列1142。在一些情况下,标记剂1110是包含报告寡核苷酸1140的亲脂性部分(例如胆固醇),其中选择所述亲脂性部分使得标记剂1110整合到细胞膜或细胞核膜中。报告寡核苷酸1140包含鉴定亲脂性部分1110的条形码序列1142,所述条形码序列在一些情况下用于对细胞(例如,细胞组、细胞样品等)标签化并且可以用于如本文别处所述的多重分析。在一些情况下,标记剂是包含报告寡核苷酸1140的抗体1120(或其表位结合片段)。报告寡核苷酸1140包含鉴定抗体1120并且可以用于推断例如抗体1120的靶标(即,抗体1120结合的分子或化合物)的存在的条形码序列1142。在其他实施方案中,标记剂1130包含含有肽1132的mhc分子1131和鉴定肽1132的报告寡核苷酸1140。在一些情况下,mhc分子与支持物1133偶联。在一些情况下,支持物1133可以是多肽例如链霉抗生物素蛋白,或多糖例如葡聚糖。在一些情况下,报告寡核苷酸1140可以以任何合适的方式直接或间接地与mhc标记剂1130偶联。例如,报告寡核苷酸1140可以与mhc分子1131、支持物1133或肽1132偶联。在一些实施方案中,标记剂1130包含多个mhc分子(例如,是mhc多聚体,其可以与支持物(例如,1133偶联))。可以与本文公开的组合物、方法和系统一起使用的i类和/或ii类mhc多聚体存在许多可能的构型,例如,mhc四聚体、mhc五聚体(经由卷曲螺旋结构域组装的mhc,例如,mhc i类五聚体(proimmune,ltd.))、mhc八聚体、mhc十二聚体、mhc修饰的葡聚糖分子(例如,mhc(immudex))等。对于示例性标记剂(包括抗体和基于mhc的标记剂)、报告寡核苷酸和使用方法的描述,参见例如美国专利10,550,429和美国专利公布20190367969,其各自出于所有目的以引用的方式整体并入本文。
[0522]
图13示出携带条形码的珠粒的另一实例。在一些实施方案中,对多种分析物(例如,rna和使用本文所述的标记剂的一种或多种分析物)的分析可以包括如图13中大体描绘的核酸条形码分子。在一些实施方案中,核酸条形码分子1310和1320经由如本文别处所述的可释放连键1340(例如,包括不稳定键)附接至支持物1330。核酸条形码分子1310可以包含衔接子序列1311、条形码序列1312和衔接子序列1313。核酸条形码分子1320可以包含衔接子序列1321、条形码序列1312和衔接子序列1323,其中衔接子序列1323包含与衔接子序列1313不同的序列。在一些情况下,衔接子1311和衔接子1321包含相同的序列。在一些情况下,衔接子1311和衔接子1321包含不同的序列。尽管显示支持物1330包含核酸条形码分子1310和1320,但本文考虑了包含共同条形码序列1312的任何合适数量的条形码分子。例如,在一些实施方案中,支持物1330还包含核酸条形码分子1350。核酸条形码分子1350可以包含衔接子序列1351、条形码序列1312和衔接子序列1353,其中衔接子序列1353包含与衔接子序列1313和1323不同的序列。在一些情况下,核酸条形码分子(例如,1310、1320、1350)包含一个或多个另外功能序列,例如umi或本文所述的其他序列。核酸条形码分子1310、1320或1350可以与如本文别处所述的分析物相互作用,例如,如图12a至图12c所描绘。
[0523]
参考图12a,在细胞用标记剂标记的情况下,序列1223可以与报告寡核苷酸的衔接子序列互补。细胞可以与一个或多个报告寡核苷酸1220缀合的标记剂1210(例如,多肽、抗体或本文别处所述的其他物质)接触。在一些情况下,细胞可以在条形码化之前被进一步处理。例如,这样的处理步骤可以包括一个或多个洗涤和/或细胞分选步骤。在一些情况下,与缀合至寡核苷酸1220和包含核酸条形码分子1290的支持物1230(例如,珠粒,例如凝胶珠粒)的标记剂1210结合的细胞被分配到多个分区(例如,液滴乳液的液滴或微孔阵列的孔)
中的分区中。在一些情况下,所述分区包含与标记剂1210结合的至多一个细胞。在一些情况下,缀合至标记剂1210(例如,多肽、抗体、pmhc分子例如mhc多聚体等)的报告寡核苷酸1220包含第一衔接子序列1211(例如,引物序列)、鉴定标记试剂1210(例如,多肽、抗体或者pmhc分子的肽或复合物)的条形码序列1212,和衔接子序列1213。衔接子序列1213可以被配置为与互补序列(例如存在于核酸条形码分子1290上的序列1223)杂交。在一些情况下,寡核苷酸1220包含一个或多个另外功能序列,例如本文别处所述的那些。
[0524]
条形码化核酸可以由图12a至图12c中描述的构建体产生(例如,经由核酸反应,例如核酸延伸或连接)。例如,序列1213然后可以与互补序列1223杂交以产生(例如,经由核酸反应,例如核酸延伸或连接)包含细胞(例如,分区特异性)条形码序列1222(或其反向互补序列)和报告条形码序列1212(或其反向互补序列)的条形码化核酸分子。条形码化核酸分子然后可以如本文别处所述任选地被处理,例如,以扩增所述分子和/或将测序平台专用序列附加到所述片段。参见例如美国专利公布2018/0105808,其出于所有目的特此以引用的方式整体并入。条形码化核酸分子或从其产生的衍生物然后可以在合适的测序平台上进行测序。
[0525]
在一些情况下,可以进行对多种分析物(例如,使用本文所述标记剂的核酸和一种或多种分析物)的分析。例如,工作流程可以包括如图12a至图12c中的任一者大体描绘的工作流程或用于单独分析物的工作流程的组合,如本文别处所述。例如,通过使用如图12a至图12c中大体描绘的工作流程的组合,可以分析多种分析物。
[0526]
在一些情况下,对分析物(例如核酸、多肽、碳水化合物、脂质等)的分析包括如图12a中大体描绘的工作流程。核酸条形码分子1290可以与一种或多种分析物共同分配。在一些情况下,核酸条形码分子1290附接至支持物1230(例如珠粒,例如凝胶珠粒),例如本文别处所述的那些。例如,核酸条形码分子1290可以经由可释放连键1240(例如,包括不稳定键)附接至支持物1230,例如本文别处所述的那些。核酸条形码分子1290可以包含条形码序列1221并且任选地包含其他另外序列,例如umi序列1222(或本文别处所述的其他功能序列)。核酸条形码分子1290可以包含可与另一核酸序列互补的序列1223,使得其可与特定序列杂交。
[0527]
例如,序列1223可以包含多聚t序列并且可以用于与mrna杂交。参考图12c,在一些实施方案中,核酸条形码分子1290包含与来自细胞的rna分子1260的序列互补的序列1223。在一些情况下,序列1223包含对rna分子具有特异性的序列。序列1223可以包含已知或靶向序列或随机序列。在一些情况下,可以进行核酸延伸反应,从而产生包含序列1223、条形码序列1221、umi序列1222、任何其他功能序列和对应于rna分子1260的序列的条形码化核酸产物。
[0528]
在另一实例中,序列1223可以与已附加到分析物的悬突序列或衔接子序列互补。例如,参考图12b的图1201,在一些实施方案中,引物1250包含与来自分析物载体的核酸分子1260(例如编码bcr序列的rna)的序列互补的序列。在一些情况下,引物1250包含与rna分子1260不互补的一个或多个序列1251。序列1251可以是如本文别处所述的功能序列,例如,衔接子序列、测序引物序列或促进与测序仪的流动池偶联的序列。在一些情况下,引物1250包含多聚t序列。在一些情况下,引物1250包含与rna分子中的靶序列互补的序列。在一些情况下,引物1250包含与免疫分子的区域(例如tcr或bcr序列的恒定区)互补的序列。引物
1250与核酸分子1260杂交并产生互补分子1270(参见图1202)。例如,互补分子1270可以是在逆转录反应中产生的cdna。在一些情况下,另外的序列可以附加到互补分子1270。例如,可以选择逆转录酶使得几个未模板化的碱基1280(例如多聚c序列)附加到cdna。在另一实例中,末端转移酶也可以用于附加另外的序列。核酸条形码分子1290包含与未模板化的碱基互补的序列1224,并且逆转录酶对核酸条形码分子1290进行模板转换反应以产生包含细胞(例如,分区特异性)条形码序列1222(或其反向互补序列)和互补分子1270(或其部分)的序列的条形码化核酸分子。在一些情况下,序列1223包含与免疫分子的区域(例如tcr或bcr序列的恒定区)互补的序列。序列1223与核酸分子1260杂交并产生互补分子1270。例如,互补分子1270可以在逆转录反应中产生,所述逆转录反应产生包含细胞(例如,分区特异性)条形码序列1222(或其反向互补序列)和互补分子1270(或其部分)的序列的条形码化核酸分子。适于条形码化从mrna转录物(包括编码免疫细胞受体的v(d)j区域的那些)产生的cdna的另外的方法和组合物和/或包括模板转换寡核苷酸的条形码化方法和组合物描述于国际专利申请wo2018/075693、美国专利公布第2018/0105808号、2015年6月26日提交的美国专利公布第2015/0376609号、以及美国专利公布第2019/0367969号中,其各自出于所有目的以引用的方式整体并入本文。
[0529]
试剂
[0530]
根据某些方面,生物颗粒可以连同溶解试剂一起分配,以释放分区内的生物颗粒的内容物。在此类情况下,可以在将生物颗粒引入到分配接点/液滴生成区(例如接点210)中的同时或就在之前,例如通过通道接点上游的一个或多个另外的通道,使溶解剂与生物颗粒悬浮液接触。根据其他方面,此外或可替代地,生物颗粒可以连同其他试剂一起分配,如下面将进一步描述的。
[0531]
本公开的方法和系统可包括微流体装置及其使用方法,其可用于共同分配分析物载体或分析物载体与试剂。此类系统和方法描述于美国专利公布第us/20190367997号中,所述专利出于所有目的以引用的方式整体并入本文。
[0532]
有利地,当溶解试剂和生物颗粒共同分配时,溶解试剂可以促进分区内生物颗粒内容物的释放。分区中释放的内容物可保持与其他分区的内容物离散。
[0533]
正如将认识到的,本文别处所述的微流体装置的通道区段可联接至多种不同流体源或接收部件(包括储槽、管道、歧管或其他系统的流体部件)中的任一者。正如将认识到的,微流体通道结构可以具有各种几何形状和/或构型。例如,微流体通道结构可以具有多于两个通道汇合点。例如,微流体通道结构可以具有2、3、4、5个通道区段或更多,每个通道区段携带相同或不同类型的珠粒、试剂和/或生物颗粒,这些通道区段在通道接点处会合。可以控制每个通道区段中的流体流动以控制将不同元素分配到液滴中。可以引导流体经由一个或多个流体流动单元沿一个或多个通道或储槽流动。流体流动单元可以包括压缩机(例如,提供正压)、泵(例如,提供负压)、致动器等,以控制流体的流量。流体还可以或以其他方式通过施加的压力差、离心力、电动泵送、真空、毛细管流或重力流等来控制。
[0534]
溶解剂的实例包括生物活性试剂,例如用于溶解不同细胞类型(例如革兰氏阳性或阴性细菌、植物、酵母、哺乳动物等)的溶解酶,例如溶菌酶、无色肽酶、溶葡球菌酶、唇形酶(labiase)、立枯丝核菌裂解酶(kitalase)、溶细胞酶,和多种其他可从例如sigma-aldrich,inc.(st louis,mo)获得的溶解酶,以及其他可商购获得的溶解酶。其他溶解剂可
以另外或可替代地与生物颗粒共同分配,以引起生物颗粒的内容物释放到分区中。例如,在一些情况下,基于表面活性剂的溶解溶液可以用于溶解细胞,但是这些对于基于乳液的体系可能是不太期望的,其中表面活性剂可干扰稳定的乳液。在一些情况下,溶解溶液可包括非离子表面活性剂,例如像tritonx-100和tween 20。在一些情况下,溶解溶液可包含离子表面活性剂,例如十二烷基肌氨酸钠和十二烷基硫酸钠(sds)。在某些情况下也可以使用电穿孔、热、声或机械细胞破坏,例如,非基于乳液的分配,例如可以作为液滴分配的补充或代替的生物颗粒包封,其中包封物的任何孔径都足够小以在细胞破裂后保留给定大小的核酸片段。
[0535]
作为与上述分析物载体共同分配的溶解剂的替代或补充,其他试剂也可与分析物载体共同分配,包括例如dna酶和rna酶灭活剂或抑制剂(例如蛋白酶k)、螯合剂(例如edta),以及用于消除或以其他方式降低不同细胞溶解物组分的负面活性或对核酸后续处理的影响的其他试剂。此外,在包封的分析物载体(例如,聚合物基质中的细胞或细胞核)的情况下,分析物载体可以暴露于适当的刺激以从共同分配的微囊中释放分析物载体或其内容物。例如,在一些情况下,化学刺激可以连同包封的分析物载体一起共同分配,以允许微囊降解以及细胞或其内容物释放到更大的分区中。在一些情况下,这种刺激可以与本文别处所述的用于核酸分子(例如,寡核苷酸)从它们各自的微囊(例如,珠粒)释放的刺激相同。在替代实例中,这可以是不同且不重叠的刺激,以便允许包封的分析物载体在与核酸分子释放到分区中不同的时间释放到同一分区中。对于用于包封细胞(也称为“细胞珠粒”)的方法、组合物和系统的描述,参见例如美国专利10,428,326和美国专利公布20190100632,所述专利各自以引用的方式整体并入。
[0536]
其他试剂也可以与生物颗粒共同分配,例如用于使生物颗粒的dna片段化的内切核酸酶,用于扩增生物颗粒的核酸片段并将条形码分子标签附接至扩增片段的dna聚合酶和dntp。其他酶可以是共同分配的,包括但不限于聚合酶、转座酶、连接酶、蛋白酶k、dna酶等。另外的试剂还可以包括逆转录酶(包括具有末端转移酶活性的酶)、引物和寡核苷酸,以及可以用于模板切换的切换寡核苷酸(本文也称为“切换寡核苷酸”或“模板切换寡核苷酸”)。在一些情况下,模板切换可用于增加cdna的长度。在一些情况下,模板切换可用于将预定核酸序列附加到cdna上。在模板切换的实例中,可由模板例如细胞mrna的逆转录产生cdna,其中具有末端转移酶活性的逆转录酶可以以模板非依赖性方式向cdna添加附加核苷酸,例如聚c。切换寡核苷酸可以包括与附加核苷酸例如聚g互补的序列。cdna上的附加核苷酸(例如,聚c)可以与切换寡核苷酸上的附加核苷酸(例如,聚g)杂交,由此切换寡核苷酸可以被逆转录酶用作模板以进一步延伸cdna。模板切换寡核苷酸可以包含杂交区和模板区。杂交区可以包含能够与靶标杂交的任何序列。在一些情况下,如先前所述,杂交区包含一系列g碱基以与cdna分子的3’末端处突出的c碱基互补。所述系列的g碱基可以包括1个g碱基、2个g碱基、3个g碱基、4个g碱基、5个g碱基或多于5个g碱基。模板序列可以包含待掺入cdna中的任何序列。在一些情况下,模板区包含至少1个(例如,至少2、3、4、5个或更多个)标签序列和/或功能序列。转换寡核苷酸可以包含脱氧核糖核酸;核糖核酸;修饰的核酸,包括2-氨基嘌呤、2,6-二氨基嘌呤(2-氨基-da)、反向dt、5-甲基dc、2
’‑
脱氧肌苷、super t(5-羟基丁炔基-2
’‑
脱氧尿苷)、super g(8-氮杂-7-脱氮杂鸟苷)、锁核酸(lna)、解锁核酸(una,例如una-a、una-u、una-c、una-g)、iso-dg、iso-dc、2’氟碱基(例如,氟c、氟u、氟a和氟g)或任何
组合。
[0537]
在一些情况下,转换寡核苷酸的长度可为至少约2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、31、32、33、34、35、36、37、38、39、40、41、42、43、44、45、46、47、48、49、50、51、52、53、54、55、56、57、58、59、60、61、62、63、64、65、66、67、68、69、70、71、72、73、74、75、76、77、78、79、80、81、82、83、84、85、86、87、88、89、90、91、92、93、94、95、96、97、98、99、100、101、102、103、104、105、106、107、108、109、110、111、112、113、114、115、116、117、118、119、120、121、122、123、124、125、126、127、128、129、130、131、132、133、134、135、136、137、138、139、140、141、142、143、144、145、146、147、148、149、150、151、152、153、154、155、156、157、158、159、160、161、162、163、164、165、166、167、168、169、170、171、172、173、174、175、176、177、178、179、180、181、182、183、184、185、186、187、188、189、190、191、192、193、194、195、196、197、198、199、200、201、202、203、204、205、206、207、208、209、210、211、212、213、214、215、216、217、218、219、220、221、222、223、224、225、226、227、228、229、230、231、232、233、234、235、236、237、238、239、240、241、242、243、244、245、246、247、248、249或250个核苷酸或更长。
[0538]
在一些情况下,转换寡核苷酸的长度可为至多约2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、31、32、33、34、35、36、37、38、39、40、41、42、43、44、45、46、47、48、49、50、51、52、53、54、55、56、57、58、59、60、61、62、63、64、65、66、67、68、69、70、71、72、73、74、75、76、77、78、79、80、81、82、83、84、85、86、87、88、89、90、91、92、93、94、95、96、97、98、99、100、101、102、103、104、105、106、107、108、109、110、111、112、113、114、115、116、117、118、119、120、121、122、123、124、125、126、127、128、129、130、131、132、133、134、135、136、137、138、139、140、141、142、143、144、145、146、147、148、149、150、151、152、153、154、155、156、157、158、159、160、161、162、163、164、165、166、167、168、169、170、171、172、173、174、175、176、177、178、179、180、181、182、183、184、185、186、187、188、189、190、191、192、193、194、195、196、197、198、199、200、201、202、203、204、205、206、207、208、209、210、211、212、213、214、215、216、217、218、219、220、221、222、223、224、225、226、227、228、229、230、231、232、233、234、235、236、237、238、239、240、241、242、243、244、245、246、247、248、249或250个核苷酸。
[0539]
一旦细胞的内容物释放到它们各自的分区中,其中所含的大分子组分(例如,生物颗粒的大分子成分,例如rna、dna或蛋白质)就可以在分区内被进一步处理。根据本文所述的方法和系统,可以为单独的生物颗粒的大分子组分内容物提供独特标识符,使得在表征那些大分子组分时,可以将其归属为源自相同的一个或多个生物颗粒。通过将独特标识符特异性地分配给单独的生物颗粒或多组生物颗粒来提供将特征归属于单独生物颗粒或多组生物颗粒的能力。独特标识符(例如,为核酸条形码形式)可以分配给单独的生物颗粒或生物颗粒群体或与之缔合,以便用独特标识符标注或标记生物颗粒的大分子组分(并因此,标注或标记其特征)。然后,可以使用这些独特标识符将生物颗粒的组分和特征归属于单独的生物颗粒或一组生物颗粒。
[0540]
在一些方面中,这是通过将单独的生物颗粒或多组生物颗粒组与独特标识符共同分配来进行的,例如上文所述(参考图2)。在一些方面中,独特标识符以核酸分子(例如,寡核苷酸)的形式提供,所述核酸分子包含可以与单独的生物颗粒的核酸内容物,或与核酸颗
粒的其他组分,并且尤其是与那些核酸的片段附接或以其他方式缔合的核酸条形码序列。分配核酸分子,使得在给定分区中的核酸分子之间,其中所含的核酸条形码序列相同,但是在不同分区之间,核酸分子可以并且确实具有不同的条形码序列,或者在给定分析中的所有分区中至少呈现出大量不同的条形码序列。在一些方面,仅一个核酸条形码序列可以与给定分区缔合,但是在一些情况下,可以存在两个或更多个不同的条形码序列。
[0541]
核酸条形码序列可以在核酸分子(例如,寡核苷酸)的序列内包括约6至约20个或更多个核苷酸。核酸条形码序列可以包括约6至约20、30、40、50、60、70、80、90、100个或更多个核苷酸。在一些情况下,条形码序列的长度可以是约6、7、8、9、10、11、12、13、14、15、16、17、18、19、20个核苷酸或更长。在一些情况下,条形码序列的长度可以是至少约6、7、8、9、10、11、12、13、14、15、16、17、18、19、20个核苷酸或更长。在一些情况下,条形码序列的长度可以是至多约6、7、8、9、10、11、12、13、14、15、16、17、18、19、20个核苷酸或更短。这些核苷酸可以是完全连续的,即处于单一的相邻核苷酸段中,或者它们可以分离成由1个或更多个核苷酸隔开的两个或更多个分离的子序列。在一些情况下,分开的条形码子序列的长度可为约4至约16个核苷酸。在一些情况下,条形码序列的长度可为约4、5、6、7、8、9、10、11、12、13、14、15、16个核苷酸或更长。在一些情况下,条形码序列的长度可为至少约4、5、6、7、8、9、10、11、12、13、14、15、16个核苷酸或更长。在一些情况下,条形码序列的长度可为至多约4、5、6、7、8、9、10、11、12、13、14、15、16个核苷酸或更短。
[0542]
共同分配的核酸分子还可以包含用于处理来自共同分配的生物颗粒的核酸的其他功能序列。这些序列包括例如,用于扩增来自于分区内单独的生物颗粒生物颗粒的核酸(例如mrna、基因组dna),同时附接相关条形码序列的靶向或随机/通用扩增引物序列,测序引物或引物识别位点,杂交或探测序列(例如用于鉴定序列的存在或用于下拉带条形码的核酸),或许多其他潜在功能序列中的任一种。也可以采用将寡核苷酸共同分配的其他机制,包括例如两个或更多个液滴的聚结,其中一个液滴含有寡核苷酸,或将寡核苷酸(例如,附接至珠粒)微分配到分区(例如微流体系统内的液滴)中。
[0543]
在一个实例中,提供了微囊,例如珠粒,其各自包括大量可释放地附接至珠粒的上述条形码化核酸分子(例如,带条形码的寡核苷酸),其中附接至特定珠粒的所有核酸分子都将包括相同的核酸条形码序列,但其中在所使用的珠粒群体中呈现出大量不同的条形码序列。在一些实施方案中,水凝胶珠粒(例如,包含聚丙烯酰胺聚合物基质)用作固体支持物和将核酸分子递送至分区中的媒介物,因为它们能够携带大量核酸分子,并且可以被配置成如本文别处所述,暴露于特定刺激时,释放核酸分子。在一些情况下,所述珠粒群体提供多样化条形码序列文库,该文库包括至少约1,000个不同的条形码序列、至少约5,000个不同的条形码序列、至少约10,000个不同的条形码序列、至少约50,000个不同的条形码序列、至少约100,000个不同的条形码序列、至少约1,000,000个不同的条形码序列、至少约5,000,000个不同的条形码序列或至少约10,000,000个不同的条形码序列或更多。另外,可以为每个珠粒提供大量附接的核酸(例如,寡核苷酸)分子。具体来说,单独的珠粒上的核酸分子中包括条形码序列的分子数量可以为至少约1,000个核酸分子、至少约5,000个核酸分子、至少约10,000个核酸分子、至少约50,000个核酸分子、至少约100,000个核酸分子、至少约500,000个核酸、至少约1,000,000个核酸分子、至少约5,000,000个核酸分子、至少约10,000,000个核酸分子、至少约50,000,000个核酸分子、至少约100,000,000个核酸分子、至少
约250,000,000个核酸分子并且在一些情况下为至少约10亿个核酸分子或更多。给定珠粒的核酸分子可以包括相同的(或共同的)条形码序列、不同的条形码序列,或两者的组合。给定珠粒的核酸分子可以包括多个集合的核酸分子。给定集合的核酸分子可以包括相同的条形码序列。所述相同的条形码序列可以与另一集合的核酸分子的条形码序列不同。
[0544]
此外,当分配珠粒群体时,所得分区群体还可以包括多样化条形码文库,该文库包括至少约1,000个不同的条形码序列、至少约5,000个不同的条形码序列、至少约10,000个不同的条形码序列、至少至少约50,000个不同的条形码序列、至少约100,000个不同的条形码序列、至少约1,000,000个不同的条形码序列、至少约5,000,000个不同的条形码序列或至少约10,000,000个不同的条形码序列或更多。另外,群体的每个分区可以包括至少约1,000个核酸分子、至少约5,000个核酸分子、至少约10,000个核酸分子、至少约50,000个核酸分子、至少约100,000个核酸分子、至少约500,000个核酸、至少约1,000,000个核酸分子、至少约5,000,000个核酸分子、至少约10,000,000个核酸分子、至少约50,000,000个核酸分子、至少约100,000,000个核酸分子、至少约250,000,000个核酸分子并且在一些情况下至少约10亿个核酸分子。
[0545]
在一些情况下,可能希望将多个不同的条形码掺入给定分区内,或附接至分区内的单个或多个珠粒。例如,在一些情况下,混合但已知的条形码序列集合可以在后续处理中提供更大的识别保证,例如,通过向给定分区提供更强的地址或条形码属性,作为从给定分区输出的重复或独立确认。
[0546]
核酸分子(例如,寡核苷酸)在对珠粒施加特定刺激后可从珠粒中释放。在一些情况下,所述刺激可以是光刺激,例如通过裂解光不稳定性连键释放核酸分子。在其他情况下,可以使用热刺激,其中珠粒环境温度的升高将导致连键的断裂或核酸分子从珠粒的另外释放。在其他情况下,可以使用化学刺激,其裂解核酸分子与珠粒的连键,或以其他方式导致核酸分子从珠粒释放。在一种情况下,此类组合物包括上述用于包封生物颗粒的聚丙烯酰胺基质,并且可以通过暴露于还原剂(例如dtt)而降解,以释放所附接的核酸分子。
[0547]
在一些方面中,提供了用于受控分配的系统和方法。可以通过调节通道结构(例如,微流体通道结构)中的某些几何特征来控制液滴大小。例如,可以调节通道的扩展角、宽度和/或长度以控制液滴大小。
[0548]
图2示出了用于将珠粒在控制下分配至离散液滴中的微流体通道结构的一个实例。通道结构200可以包括在通道接点206(或交叉点)处与储槽204连通的通道区段202。储槽204可以是腔室。如本文所用,任何对“储槽”的提及,也可以指“腔室”。在操作时,包括悬浮珠粒212的水性流体208可以沿通道区段202转运到接点206处,以与储槽204中与水性流体208不可混溶的第二流体210会合,以产生流入储槽204中的水性流体208的液滴216、218。在水性流体208和第二流体210会合的接点206处,可以基于例如接点206处的流体动力、两股流体208、210的流速、流体特性以及通道结构200的某些几何参数(例如,w、h0、α等)的因素而形成液滴。可以通过将水性流体208从通道区段202连续注射通过接点206而将多个液滴收集在储槽204中。
[0549]
产生的离散液滴可包括珠粒(例如,如在已占用液滴216中)。可替代地,生成的离散液滴可以包括多于一个珠粒。可替代地,生成的离散液滴可以不包括任何珠粒(例如,如同在未占用液滴218中)。在一些情况下,生成的离散液滴可以含有一个或多个分析物载体,
如本文别处所述。在一些情况下,生成的离散液滴可以包含一种或多种试剂,如本文别处所述。
[0550]
在一些情况下,水性流体208可以具有浓度或频率基本上均一的珠粒212。可以从单独的通道(图2中未示出)将珠粒212引入到通道区段202中。可以通过控制将珠粒212引入到通道区段202中的频率和/或通道区段202和单独的通道中流体的相对流速来控制通道区段202中的珠粒212的频率。在一些情况下,可以从多个不同的通道将珠粒引入到通道区段202中,并因此而控制频率。
[0551]
在一些情况下,通道区段202中的水性流体208可以包含生物颗粒。在一些情况下,水性流体208可以具有浓度或频率基本上均一的生物颗粒。如同珠粒一样,可以从单独的通道将生物颗粒引入到通道区段202中。可以通过控制将生物颗粒引入到通道区段202中的频率和/或通道区段202和单独的通道中流体的相对流速来控制通道区段202中的水性流体208中的生物颗粒的频率或浓度。在一些情况下,可以从多个不同的通道将生物颗粒引入到通道区段202中,并因此而控制频率。在一些情况下,第一单独通道可以将珠粒引入到通道区段202中并且第二单独通道可以将生物颗粒引入到其中。引入珠粒的第一单独通道可以在引入生物颗粒的第二单独通道的上游或下游。
[0552]
第二流体210可以包含油,例如含氟油,所述油包括用于稳定所得液滴,例如抑制所得液滴的后续聚结的含氟表面活化剂。
[0553]
在一些情况下,第二流体210可以不经受和/或被引导任何流入或流出储槽204。例如,第二流体210在储槽204中可以是基本上静止的。在一些情况下,第二流体210可以经受在储槽204内流动,但不会流入和流出储槽204,例如通过向储槽204施加压力和/或受到接点206处的水性流体208的来流影响时。可替代地,第二流体210可以经受和/或被引导流入或流出储槽204。例如,储槽204可以是将第二流体210从上游引导至下游,从而转运生成的液滴的通道。
[0554]
在接点206处或附近的通道结构200可以具有至少部分地决定了由通道结构200形成的液滴大小的某些几何特征。通道区段202在接点206处或附近可以具有高度h0和宽度w。举例而言,通道区段202可以包括矩形横截面,该矩形横截面通向具有更宽的横截面(例如在宽度或直径方面)的储槽204。可替代地,通道区段202的横截面可以是其他形状,例如圆形、梯形、多边形或任何其他形状。在接点206处或附近的储槽204的顶壁和底壁可以呈扩展角α倾斜。扩展角α使舌部(在液滴形成之前,水性流体208从接点206处离开通道区段202并且进入储槽204的部分)长度增加并且促进中间形成的液滴的曲率减小。液滴大小随着扩展角增大而减小。所得液滴的半径rd可以通过以下针对前述几何参数h0、w和α的方程式来预测:
[0555][0556]
举例而言,对于w=21μm、h=21μm和α=3
°
的通道结构来说,预测的液滴大小为121μm。在另一实例中,对于w=25μm、h=25μm和α=5
°
的通道结构来说,预测的液滴大小为123μm。在另一实例中,对于w=28μm、h=28μm和α=7
°
的通道结构来说,预测的液滴大小为124μm。
[0557]
在一些情况下,扩展角α可以在约0.5
°
至约4
°
、约0.1
°
至约10
°
或约0
°
至约90
°
的范围之间。例如,扩展角可以为至少约0.01
°
、0.1
°
、0.2
°
、0.3
°
、0.4
°
、0.5
°
、0.6
°
、0.7
°
、0.8
°
、0.9
°
、1
°
、2
°
、3
°
、4
°
、5
°
、6
°
、7
°
、8
°
、9
°
、10
°
、15
°
、20
°
、25
°
、30
°
、35
°
、40
°
、45
°
、50
°
、55
°
、60
°
、65
°
、70
°
、75
°
、80
°
、85
°
或更大。在一些情况下,扩展角可以为至多约89
°
、88
°
、87
°
、86
°
、85
°
、84
°
、83
°
、82
°
、81
°
、80
°
、75
°
、70
°
、65
°
、60
°
、55
°
、50
°
、45
°
、40
°
、35
°
、30
°
、25
°
、20
°
、15
°
、10
°
、9
°
、8
°
、7
°
、6
°
、5
°
、4
°
、3
°
、2
°
、1
°
、0.1
°
、0.01
°
或更小。在一些情况下,宽度w可以在约100微米(μm)至约500μm的范围之间。在一些情况下,宽度w可以在约10μm至约200μm的范围之间。可替代地,宽度可以小于约10μm。可替代地,宽度可以大于约500μm。在一些情况下,进入接点206的水性流体208的流速可以在约0.04微升(μl)/分钟(min)至约40μl/min之间。在一些情况下,进入接点206的水性流体208的流速可以在约0.01微升(μl)/分钟(min)至约100μl/min之间。可替代地,进入接点206的水性流体208的流速可以小于约0.01μl/min。可替代地,进入接点206的水性流体208的流速可以大于约40μl/min,例如45μl/min、50μl/min、55μl/min、60μl/min、65μl/min、70μl/min、75μl/min、80μl/min、85μl/min、90μl/min、95μl/min、100μl/min、110μl/min、120μl/min、130μl/min、140μl/min、150μl/min或更高。在更低的流速下,例如大约小于或等于10微升/分钟的流速下,液滴半径可以不依赖于进入接点206的水性流体208的流速。
[0558]
在一些情况下,至少约50%的产生的液滴可具有一致的尺寸。在一些情况下,生成的至少约55%、60%、65%、70%、75%、80%、85%、90%、95%、96%、97%、98%、99%或更多的液滴可以具有均一大小。可替代地,生成的少于约50%的液滴可以具有均一大小。
[0559]
可以通过增加生成点,例如增加水性流体208通道区段(例如,通道区段202)与储槽204之间的接点(例如,接点206)的数量来增加液滴生成的通过量。可替代地或此外,可以通过增加通道区段202中的水性流体208的流速来增加液滴生成的通过量。
[0560]
本文所述的方法和系统可用于大大提高单细胞应用和/或接收基于液滴的输入的其他应用的效率。例如,在分选已占用的细胞和/或适当大小的细胞之后,可以进行的后续操作可以包括产生扩增产物、纯化(例如,通过固相可逆固定(spri))、进一步处理(例如,剪切、连接功能序列及后续扩增(例如,通过pcr))。这些操作可以在本体中(例如,在分区外)进行。在分区是乳液中的液滴的情况下,可以破坏乳液,并且合并液滴的内容物用于另外的操作。可以与带条形码化珠粒一起共同分配的其他试剂可以包括阻断核糖体rna(rrna)的寡核苷酸和消化来自细胞的基因组dna的核酸酶。可替代地,rrna去除剂可应用于另外的处理操作中。通过此类方法产生的构建体的构型可以帮助最小化(或避免)对测序期间的多聚-t序列和/或多核苷酸序列的5’末端的测序。可以对扩增产物,例如第一扩增产物和/或第二扩增产物进行测序以进行序列分析。在一些情况下,可以使用测序用部分发夹扩增(phase)方法进行扩增。
[0561]
多种应用需要生物颗粒群体内不同生物颗粒或生物体类型的存在的评估和其量化,包括例如微生物菌群分析和表征、环境测试、食品安全测试、流行病学分析,例如,追踪污染等。
[0562]
计算机系统
[0563]
本公开提供被编程用于实施本公开的方法的计算机系统。图7示出了经编程或以其他方式配置为实施本文所述的一种或多种方法的计算机系统7。例如,计算机系统701可
以被编程或以其他方式配置用于控制微流体系统(例如流体流动);(ii)将被占用的液滴与未被占用的液滴分类;(iii)使液滴聚合;(iv)进行测序应用;和/或(v)产生和维护测序文库。计算机系统701可以调节本公开的各个方面,例如调节微流体结构中一个或多个通道中的流体流速、调节聚合应用单元等。计算机系统701可以是相对于电子装置远程定位的用户或计算机系统的电子装置。电子装置可以是移动电子装置。
[0564]
计算机系统701包括中央处理单元(cpu,本文中又称为“处理器”和“计算机处理器”)705,它可以是单核或多核处理器,或用于并行处理的多个处理器。计算机系统701还包括存储器或存储位置710(例如随机存取存储器、只读存储器、快闪存储器)、电子存储单元715(例如硬盘)、用于与一个或多个其他系统通信的通信接口720(例如网络适配器)和外围设备725,例如高速缓冲存储器、其他存储器、数据存储和/或电子显示适配器。存储器710、存储单元715、接口720和外围设备725通过通信总线(实线)例如母板与cpu 705通信。存储单元715可以是用于存储数据的存储单元(或数据储存库)。计算机系统701可借助于通信接口720来可操作地耦接至计算机网络(“网络”)730。网络730可以是因特网、内网和/或外网或与因特网通信的内网和/或外网。网络730在一些情况下是无线电通信和/或数据网络。网络730可以包括一个或多个计算机服务器,所述计算机服务器可以实现分布式计算,例如云计算。网络730在一些情况下借助于计算机系统701,可实施对等网络,其可使得耦接至计算机系统701的设备能够作为客户端或服务器来运作。
[0565]
cpu 705可以执行可以在程序或软件中体现的一系列机器可读指令。指令可以存储在存储位置、例如存储器710中。指令可以针对cpu 705,随后可以编程或以其他方式配置cpu 705来实施本公开的方法。通过cpu 705执行的操作的实例可以包括获取指令、解码、执行和回写。
[0566]
cpu 705可以是电路、例如集成电路的一部分。系统701的一个或多个其他部件可以包括在电路中。在一些情况下,电路是专用集成电路(asic)。
[0567]
存储单元715可以存储文件夹,例如驱动器、程序库和保存的程序。存储单元715可以存储用户数据,例如用户偏好和用户程序。在一些情况下,计算机系统701可以包括一个或多个额外的数据存储单元,所述数据存储单元在计算机系统701以外,例如位于远程服务器上,所述远程服务器通过内网或因特网与计算机系统701通信。
[0568]
计算机系统701可以与一个或多个远程计算机系统通过网络730通信。举例来说,计算机系统701可以与用户(例如操作员)的远程计算机系统通信。远程计算机系统的实例包括个人计算机(例如便携式pc)、触屏平板或平板pc(例如ipad、galaxy tab)、电话、智能手机(例如apple iphone、安卓启动装置、blackberry)或个人数字助理。用户可以经由网络730进入计算机系统701。
[0569]
如本文所述的方法可以借助于计算机系统701的电子存储位置上,例如存储器710或电子存储单元715上存储的机器(例如计算机处理器)可执行代码实施。机器可执行或机器可读代码可以呈软件形式提供。在使用期间,代码可以由处理器705执行。在一些情况下,可以从存储单元715撷取代码并存储在存储器710上以由处理器705就绪存取。在一些情形下,可以排除电子存储单元715,并且在存储器710上存储机器可执行指令。
[0570]
代码可以预编译和配置以用于具有被调适成执行所述代码的处理器的机器,或可以在运行时间期间编译。代码可以呈编程语言提供,所述编程语言经过选择,以使代码能够
以预编译或如所编译的方式执行。
[0571]
本文提供的系统和方法、例如计算机系统701的方面可以体现在编程上。这项技术的各个方面可以被认为是“产品”或“制品”,通常呈在一种机器可读介质上携带或体现的机器(或处理器)可执行代码和/或相关数据的形式。机器可执行代码可以存储在电子存储单元、例如存储器(例如只读存储器、随机存取存储器、快闪存储器)或硬盘上。“存储”型介质可以包括计算机、处理器等的任何或所有有形存储器,或其相关模块,例如各种半导体存储器、磁带驱动器、磁盘驱动器等,这些模块可以在任何时候为软件编程提供非暂时性存储。软件整体或部分有时可以通过因特网或各种其他电信网通信。此类通信例如能够将软件从一个计算机或处理器装载至另一个计算机或处理器,例如从管理服务器或主机装载至应用服务器的计算机平台。因此,可以负载软件元件的另一类型介质包括光波、电波和电磁波,例如跨越本地设备之间的物理接口使用,通过有线和光学固定网络和经各种空中链路。携带此类波的物理元件,例如有线或无线链路、光链路等,也可以被认为是负载软件的介质。如本文所用,除非局限于非暂时性有形“存储”介质,否则例如计算机或机器“可读介质”的术语是指参与提供指令给处理器来执行的任何介质。
[0572]
因此,例如计算机可执行代码的机器可读介质可以采取许多形式,包括但不限于有形存储介质、载波介质或人工传输介质。非易失性存储介质包括例如光盘或磁盘,例如图式中所示的任何计算机中的任一存储装置等,例如可以用于实施数据库等。易失性存储介质包括动态存储器,例如这种计算机平台的主存储器。有形传输介质包括同轴电缆;铜丝和光纤,包括包含计算机系统内的母线的电线。载波传输介质可以采取电信号或电磁信号的形式,或声波或光波的形式,例如在射频(rf)和红外线(ir)数据通信期间产生的那些形式。因此,计算机可读介质的常见形式包括例如:软盘、软磁盘、硬盘、磁带、任何其他磁性介质、cd-rom、dvd或dvd-rom、任何其他光学介质、穿孔纸带、具有孔图案的任何其他物理存储介质、ram、rom、prom和eprom、flash-eprom、任何其他存储芯片或存储卡、载波输送数据或指令、输送这种载波的电缆或链路或计算机可以从中读取编程代码和/或数据的任何其他介质。计算机可读介质的这些形式中的许多可能参与将一系列或多个系列的一个或多个指令携带至处理器进行执行。
[0573]
计算机系统701可以包括电子显示器735或与其通信,所述电子显示器包含用户界面(ui)740,用于提供例如测序分析结果等。ui的实例包括但不限于图形用户界面(gui)和基于web的用户界面。
[0574]
本公开的方法和系统可以借助于一种或多种算法实施。算法可以借助于软件在由中央处理单元705执行后来实施。算法可以例如执行核酸测序测定等。
[0575]
本公开的装置、系统、组合物和方法可以用于各种应用,例如处理来自单细胞的单个分析物(例如rna、dna或蛋白质)或多种分析物(例如dna和rna、dna和蛋白质、rna和蛋白质或rna、dna和蛋白质)。例如,生物颗粒(例如细胞或细胞珠粒)被分配在分区(例如液滴)中,并将来自生物颗粒的多种分析物处理以供后续处理。多种分析物可以来自单细胞。这能够对细胞进行例如同时的蛋白质组学、转录物组和基因组分析。
[0576]
用于表征细胞的系统
[0577]
在一些实施方案中,本文公开了用于表征细胞的系统。在一个方面,本公开提供了一种用于表征细胞的系统,所述系统包括:多个分区,所述多个分区包含多个细胞或细胞核
和多个颗粒,其中所述多个分区中的分区包含所述多个细胞或细胞核中的细胞或细胞核和所述多个颗粒中的颗粒,其中(i)所述多个细胞或细胞核包含多个核酸分子,其中所述多个核酸分子包含多个rna分子和多个dna分子;并且(ii)所述多个颗粒包含偶联至所述多个颗粒的多个核酸条形码分子,其中所述多个核酸条形码分子中的核酸条形码分子包含多个核酸条形码序列中的核酸条形码序列,并且其中所述颗粒包含所述多个核酸条形码序列中的独特核酸条形码序列;和一个或多个计算机处理器,所述一个或多个计算机处理器单独地或共同地被编程为:(a)处理使用所述多个核酸条形码分子和所述多个核酸分子或其衍生物在所述多个分区中产生的多个条形码化核酸分子,以产生对应于所述rna分子和所述dna分子的序列信息;并且(b)使用所述序列信息来鉴定所述多个细胞或细胞核的特征。
[0578]
在一些实施方案中,所述多个细胞或细胞核的特征包括细胞类型。在一些实施方案中,所述细胞类型选自由单核细胞、自然杀伤细胞、b细胞、t细胞、粒细胞、树突细胞和基质细胞组成的组。在一些实施方案中,所述b细胞选自由复制b细胞、正常b细胞和肿瘤b细胞组成的组。在一些实施方案中,所述b细胞选自由幼稚b细胞、记忆b细胞、浆母细胞b细胞、淋巴浆细胞样细胞、b-1细胞、调节性b细胞和浆b细胞组成的组。在一些实施方案中,所述t细胞选自由复制t细胞和正常t细胞组成的组。在一些实施方案中,所述t细胞选自由辅助t细胞、细胞毒性t细胞、记忆t细胞、调节性t细胞、自然杀伤t细胞、粘膜相关不变型t(mait)细胞、γδt细胞、效应t细胞和幼稚t细胞组成的组。在一些实施方案中,所述单核细胞选自由以cd14细胞表面受体的高水平表达为特征的单核细胞和以cd16细胞表面受体的高水平表达为特征的单核细胞组成的组。在一些实施方案中,所述树突细胞选自由常规树突细胞和浆细胞样树突细胞组成的组。在一些实施方案中,对应于所述多个dna分子中的所述dna分子的所述序列对应于可接近染色质区域。在一些实施方案中,所述多个rna分子中的所述rna分子包括信使rna(mrna)分子。在一些实施方案中,所述序列信息包含对应于所述dna分子的第一多个测序读段和对应于所述rna分子的第二多个测序读段。在一些实施方案中,所述序列信息包含与所述多个细胞或细胞核中的个别细胞或细胞核相关的多个测序读段。
[0579]
在一些实施方案中,其中在(b)中所述一个或多个计算机处理器单独地或共同地被编程为使用所述序列信息确定所述多个细胞或细胞核中的所述细胞或细胞核的关联特征,所述细胞或细胞核的所述关联特征将包含对应于所述细胞或细胞核的dna分子的序列信息的第一数据集和包含对应于所述细胞或细胞核的rna分子的序列信息的第二数据集关联起来。在一些实施方案中,其中在(b)中所述一个或多个计算机处理器单独地或共同地被编程为使用所述序列信息依据基因表达特征和/或依据可接近染色质区域特征对所述多个细胞或细胞核中的细胞或细胞核进行聚类。在一些实施方案中,其中在(b)中所述一个或多个计算机处理器单独地或共同地被编程为(i)使用所述序列信息依据可接近染色质区域特征对所述多个细胞或细胞核中的细胞或细胞核进行聚类,(ii)使用所述序列信息依据基因表达特征对所述多个细胞或细胞核中的细胞或细胞核进行聚类,并且(iii)使用所述序列信息和依据所述基因表达特征聚类的所述细胞或细胞核进一步表征依据所述可接近染色质区域聚类的所述细胞或细胞核。在一些实施方案中,其中在(b)中所述一个或多个计算机处理器单独地或共同地被编程为(i)使用所述序列信息依据可接近染色质区域特征对所述多个细胞或细胞核中的细胞或细胞核进行聚类,(ii)使用所述序列信息依据基因表达特征对所述多个细胞或细胞核中的细胞或细胞核进行聚类,并且(iii)使用所述序列信息和依
据所述可接近染色质区域特征聚类的所述细胞或细胞核进一步表征依据所述基因表达特征聚类的所述细胞或细胞核。
[0580]
在一些实施方案中,所述多个细胞或细胞核源自包含肿瘤或疑似包含肿瘤的样品。在一些实施方案中,所述一个或多个计算机处理器单独地或共同地被进一步编程为将对应于所述rna分子和所述dna分子的所述序列信息与从对照样品产生的序列信息进行处理。在一些实施方案中,所述样品源自体液。在一些实施方案中,所述样品源自活检物。在一些实施方案中,所述肿瘤是b细胞淋巴瘤肿瘤。在一些实施方案中,所述一个或多个计算机处理器单独地或共同地被进一步编程为使用所述序列信息来鉴定所述样品中肿瘤细胞或细胞核的存在。在一些实施方案中,所述一个或多个计算机处理器单独地或共同地被进一步编程为(c)使用所述序列信息来鉴定所述样品中的细胞类型、细胞状态、肿瘤特异性基因表达模式或肿瘤特异性差异性可接近染色质区域。在一些实施方案中,所述一个或多个计算机处理器单独地或共同地被进一步编程为至少部分地基于(c)确定用于治疗所述样品所源自的受试者的治疗方案。在一些实施方案中,所述治疗方案包括施用治疗有效量的靶向以所述肿瘤特异性基因表达模式或所述肿瘤特异性差异性可接近染色质区域鉴定的一个或多个靶标的剂。
[0581]
在一些实施方案中,所述多个分区包括多个液滴。在一些实施方案中,所述多个细胞或细胞核包括多个转座核。在一些实施方案中,所述多个颗粒包括多个凝胶珠粒。在一些实施方案中,所述多个核酸条形码分子可释放地偶联至所述多个颗粒。在一些实施方案中,所述多个核酸条形码分子中的核酸条形码分子在施加刺激时能够从所述多个颗粒中的所述颗粒释放。在一些实施方案中,所述刺激是化学刺激。在一些实施方案中,所述刺激包括还原剂。在一些实施方案中,所述多个核酸条形码分子通过多个不稳定部分偶联至所述多个颗粒。在一些实施方案中,所述系统还包括产生所述多个分区的微流体装置。
[0582]
用于确定样品的疾患的系统
[0583]
在一些实施方案中,本文公开了用于确定样品的疾患的系统。在一个方面,一种用于确定样品的疾患的系统,所述系统包括:一个或多个数据库,所述一个或多个数据库包含(i)包含对应于所述样品的细胞或细胞核的多个脱氧核糖核酸(dna)分子的可接近染色质区域的测序信息的第一数据集,(ii)包含对应于所述细胞或细胞核的多个核糖核酸(rna)分子的测序信息的第二数据集,和(iii)使用所述第一数据集和所述第二数据集产生的所述细胞或细胞核的关联特征;一个或多个计算机处理器,所述一个或多个计算机处理器可操作地耦合至所述一个或多个数据库,其中所述一个或多个计算机处理器单独地或共同地被编程为使用所述细胞或细胞核的所述关联特征和对照样品的对照细胞或细胞核的对照关联特征来确定指示所述疾患的所述多个dna分子的一个或多个可接近染色质区域或从所述多个rna分子表达的一个或多个基因。
[0584]
在一些实施方案中,所述一个或多个计算机处理器单独地或共同地被编程为确定疑似患有所述疾患的个体的一个或多个样品中的指示所述疾患的所述一个或多个可接近染色质区域和/或所表达的所述一个或多个基因的水平。在一些实施方案中,所述一个或多个计算机处理器单独地或共同地被编程为产生与提供对所述疾患的诊断评估、对所述疾患的预后评估、对所述疾患的监测和/或对所述疾患的管理有关的输出。在一些实施方案中,所述一个或多个计算机处理器单独地或共同地被配置为将与所述一个或多个可接近染色
质区域和/或所表达的一个或多个基因相关的基因鉴定为用于治疗所述疾患的治疗方案的靶标。
[0585]
在一些实施方案中,所述一个或多个计算机处理器单独地或共同地被编程为产生与确定将治疗有效量的靶向所述靶标的剂施用于受试者的方案有关的输出,其中所述样品源自所述受试者。在一些实施方案中,所述一个或多个计算机处理器单独地或共同地被编程为产生与确定靶向所述靶标的剂在施用于受试者时的功效有关的输出,其中所述样品源自所述受试者。在一些实施方案中,所述一个或多个计算机处理器单独地或共同地被编程为产生与检测所述受试者对所述剂的反应的存在或不存在有关的输出,其中所述反应包括在施用所述剂的第一剂量或后续剂量后反应的数量、程度或范围。
[0586]
在一些实施方案中,所述反应包括在施用所述剂前后之间所述靶标的基因表达和/或染色质可接近性的差异。在一些实施方案中,所述样品来自患有肿瘤或疑似患有肿瘤的受试者。在一些实施方案中,所述疾患是肿瘤、癌症、恶性肿瘤、赘生物或其他增生性疾病或病症。在一些实施方案中,所述疾患是b细胞恶性肿瘤。在一些实施方案中,所述b细胞恶性肿瘤是b细胞淋巴瘤。在一些实施方案中,所述样品源自体液。在一些实施方案中,所述样品源自活检物。
[0587]
在一些实施方案中,所述第一数据集和所述第二数据集包含对应于所述多个dna分子和所述多个rna分子的序列的多个测序读段,其中所述测序读段各自通过核酸条形码序列对应于所述细胞或细胞核。在一些实施方案中,所述一个或多个计算机处理器单独地或共同地被编程为依据所述样品的多个细胞或细胞核的各自的可接近染色质区域特征,依据各自的所表达基因,和/或依据各自的关联特征对所述多个细胞或细胞核进行聚类。在一些实施方案中,依据选自由单核细胞、自然杀伤细胞、b细胞、t细胞、粒细胞、树突细胞和基质细胞组成的组的细胞类型对所述多个细胞或细胞核进行聚类。在一些实施方案中,所述b细胞选自由复制b细胞、正常b细胞和肿瘤b细胞组成的组。在一些实施方案中,所述b细胞选自由幼稚b细胞、记忆b细胞、浆母细胞b细胞、淋巴浆细胞样细胞、b-1细胞、调节性b细胞和浆b细胞组成的组。在一些实施方案中,所述t细胞选自由复制t细胞和正常t细胞组成的组。在一些实施方案中,所述t细胞选自由辅助t细胞、细胞毒性t细胞、记忆t细胞、调节性t细胞、自然杀伤t细胞、粘膜相关不变型t(mait)细胞、γδt细胞、效应t细胞和幼稚t细胞组成的组。
[0588]
在一些实施方案中,所述一个或多个计算机处理器单独地或共同地被编程为监测所述个体的指示所述疾患的所述一个或多个可接近染色质区域和/或所表达的所述一个或多个基因的水平。
[0589]
在一些实施方案中,所述多个dna片段是标签化的。在一些实施方案中,用条形码化核酸序列对包含对应于所述样品的细胞或细胞核的多个dna分子的可接近染色质区域的测序信息的第一数据集和包含对应于所述细胞或细胞核的多个rna分子的测序信息的第二数据集进行条形码化。在一些实施方案中,在多个分区内用条形码化核酸序列对包含对应于所述样品的细胞或细胞核的多个dna分子的可接近染色质区域的测序信息的第一数据集和包含对应于所述细胞或细胞核的多个rna分子的测序信息的第二数据集进行条形码化。
[0590]
在一些实施方案中,所述系统还包括被配置为对多个条形码化核酸序列进行测序的装置或测序仪。在一些实施方案中,所述第一数据集是通过对包含对应于所述样品的所
述细胞或细胞核的所述多个脱氧核糖核酸(dna)分子的可接近染色质区域的序列的第一多个条形码化核酸序列进行测序而产生的;并且所述第二数据集是通过对包含所述细胞或细胞核的所述核糖核酸(rna)分子的序列的第二多个条形码化核酸序列进行测序而产生的。
[0591]
在一些实施方案中,所述一个或多个计算机处理器单独地或共同地被编程为处理所述第一数据集和/或所述第二数据集以产生经过滤的第一数据集和/或经过滤的第二数据集。在一些实施方案中,所述经过滤的第一数据集是使用基序富集过滤的。在一些实施方案中,所述经过滤的第二数据集是使用差异表达分析过滤的。在一些实施方案中,所述一个或多个计算机处理器单独地或共同地被编程为处理所述第一数据集和/或所述第二数据集以产生关联显著性。在一些实施方案中,所述一个或多个计算机处理器单独地或共同地被编程为处理所述经过滤的第一数据集和/或所述经过滤的第二数据集以产生富集评分。在一些实施方案中,所述经过滤的第一数据集和所述经过滤的第二数据集用于产生转录因子-靶基因网络。在一些实施方案中,其中来自所述转录因子-靶基因网络的基因被鉴定为用于治疗所述疾患的治疗方案的靶标。在一些实施方案中,所述靶标是转录因子。
[0592]
实施例
[0593]
实施例1:小b细胞淋巴瘤及其信号传导途径的功能表征
[0594]
进行了使用b细胞淋巴瘤的案例研究。图33总结了该案例研究的细节。基因表达和染色质数据由来自cd20+弥漫性小细胞淋巴瘤样品(例如,如本文所述)的9158个单细胞产生。基因表达标志物用于注释样品中包括的免疫细胞类型(例如,如本文所述)。图34示出了基于基因表达数据(左图)和染色质数据(右图)针对细胞的细胞类型注释。如图所示,基因表达分析最初将复制性t细胞、t细胞、单核细胞、复制性b细胞和b细胞鉴定为单独的类别,而染色质分析最初仅将t细胞、单核细胞和b细胞鉴定为单独的类别。b细胞包括肿瘤b细胞和正常b细胞。可以使用基因表达信息、染色质信息或它们的组合来分清肿瘤b细胞和正常b细胞。正交证据线可用于区分肿瘤b细胞和正常b细胞。
[0595]
图35示出了使用基因表达数据从正常b细胞中解析出肿瘤b细胞的示例性正交方法。突变负荷可以使用来自tcga-dllc项目关于弥漫性大b细胞淋巴瘤的公开可用突变数据的单核苷酸变体(snv)进行绘制。对此数据进行过滤以仅保留预计具有有害表型并存在于dbsnp数据库中的279个snv。这些保留的细胞在图35的左侧图中显示为黑点。由于已知肿瘤b细胞是cd20阳性的(在图41中示出),因此使用cd20阳性细胞与snv之间的正相关来鉴定总b细胞中的肿瘤b细胞。还可以使用bank1(具有锚蛋白重复序列的b细胞支架蛋白1)来鉴定b细胞中的肿瘤b细胞。bank1调节b细胞抗原受体(bcr)诱导的钙动员并削弱cd40介导的akt活化以防止b细胞过度活化。因此,受阻抑的bank1表达指示肿瘤b细胞。沿着这条轴,相对于正常b细胞,肿瘤b细胞中的cd40表达可能有所增强。因此,bank1表达和cd40表达之间的负相关指示肿瘤b细胞。图41示出了使用这些正交证据线利用基因表达数据从正常b细胞中解析出肿瘤b细胞的示例性方法。
[0596]
图36示出了从基因表达数据(左图)和染色质数据(右图)产生的细胞类型的聚类表示。对从基因表达数据产生的聚类表示进行注释以显示单独的肿瘤b细胞和正常b细胞群体。基于基因表达分析对从染色质数据产生的聚类表示进行注释。在此表示中,正常b细胞包含在与肿瘤b细胞集群不同的集群中。这指示正常b细胞和肿瘤b细胞具有不同的染色质特征。
[0597]
还使用基因表达数据对肿瘤进行分类。使用基因表达数据,肿瘤被归类为胃malt淋巴瘤。
[0598]
在分离正常b细胞和肿瘤b细胞后,可以进行差异基因表达分析以鉴定这两个细胞群体之间各种基因的差异表达。如图37所示,包括il-4受体(“il4r”)的蛋白质相对于正常b细胞在肿瘤b细胞中过度表达,而包括bank1的蛋白质相对于正常b细胞在肿瘤b细胞中表达不足。所观察到的il4r过度表达与许多癌症相关的细胞因子过度活化一致。
[0599]
上文概述的基因表达可以提供对诊断决策的见解,并可能为潜在的治疗选择提供信息。基因表达分析与染色质分析相结合也可用于鉴定肿瘤特异性信号传导途径。在许多原发性人类肿瘤中观察到jak-stat信号传导途径的失调。信号转导和转录活化因子(stat)蛋白是细胞因子信号传导的关键介质。然而,stat是潜伏的胞质蛋白,使得它们的表达不能很好地代表功能。图38a的右上图示出了stat3和stat6蛋白在包括正常b细胞和肿瘤b细胞在内的所有细胞类型中的相对相似的表达,表明仅基因表达不能良好地代表功能。替代地,可以通过分析染色质数据来评估活性。在jak介导的磷酸化后,活化的stat易位至细胞核并与在细胞因子诱导型基因启动子中的其dna识别基序结合。此活性在图38a的左中图中示出。在七种stat蛋白中,stat6被il-4和il-13活化。如图38a的右下图所示,相对于正常b细胞,肿瘤b细胞中的stat6基序有所增强。该评估提供了对可能在肿瘤细胞中被活化的转录因子的见解。该分析的扩展视图包含在图42中。bcl-2和ige是stat6的已知靶标。stat6活化促进免疫球蛋白类转换为ige并通过诱导抗凋亡基因例如bcl-2而防止细胞凋亡。如图42的右下图所示,对于肿瘤b细胞这些靶标有所增强。
[0600]
基因表达和染色质分析的结合可能有助于鉴定肿瘤特异性差异性可接近染色质区域。图38b示出了肿瘤b细胞、正常b细胞、单核细胞和t细胞的与il4r相关的染色质数据,il4r在肿瘤b细胞中相对于正常b细胞有所增强(例如,如上文所述)。这些细胞类别中的每一类别在图中间左侧都包括对应于il4r启动子的峰。然而,与其他细胞类型不同,肿瘤b细胞在该峰的上游包括一个强度增强的区域(圆圈)。图38c将此染色质数据(左上图)与公开可用的遗传数据(左下图)进行了比较。肿瘤b细胞的包含强度增强区域的灰色突出显示区域与h3k4me1(与增强子相关的差异甲基化区域)的强度重叠。这种所谓的“关联峰”可能可用于预测il4r表达。图38c的右图示出了具有针对不同细胞类型的各种特征的信号的细胞的比率。用基因表达数据分析的il4r表达在肿瘤b细胞中相较于其他细胞类型存在差异表达,而用染色质数据分析的il4r启动子峰不能预测细胞类型。然而,“关联峰”(例如,使用染色质数据鉴定的增强子)相较于其他细胞类型与肿瘤b细胞密切相关,因此可以预测il4r表达。该评估表明,在染色质数据中可观察到的增强子可能比启动子更好地预测基因表达。
[0601]
实施例2:小b细胞淋巴瘤的进一步表征和关联分析
[0602]
对来自实施例1的b细胞淋巴瘤案例研究的基础文库进行测序以进一步深入并处理以确定特征关联。如图45a和图45b所示的数据证实了实施例1的发现并鉴定了在其他细胞(例如,正常b细胞、t细胞和单核细胞/树突细胞)中未观察到的在肿瘤b细胞中驱动il4r表达的开放染色质区域。在图45b中,轮廓框突出显示了在其他细胞中未观察到的在肿瘤b细胞中驱动il4r表达的开放染色质区域。
[0603]
实施例3:不同b细胞淋巴瘤的细胞类型和异质性
[0604]
进行了使用b细胞淋巴瘤的案例研究。使用关联的单细胞基因表达和染色质特征
鉴定b细胞淋巴瘤的细胞类型异质性和恶性程度。对来自健康个体和疑似罹患某种b细胞淋巴瘤的个体的淋巴结源性淋巴细胞进行单细胞基因表达和染色质可接近性分析。测定来自每组个体的淋巴样组织的单细胞悬液以产生单细胞基因表达测序数据和单atac测序数据。
[0605]
通过用不同的表面和细胞内抗体染色以及流式细胞术分析来自这些样品的淋巴结源性细胞。例如,使用针对免疫球蛋白轻链κ或λ表达的染色来区分恶性和恶性b细胞。恶性b细胞与非恶性b细胞的区别在于它们仅表达κ或λ免疫球蛋白轻链之一。例如,恶性b细胞仅表达κ轻链。
[0606]
使用降维技术分析单细胞基因表达和染色质可接近性数据,这些技术包括但不限于t分布随机邻域嵌入(tsne)、主成分分析(pca)或统一流形逼近与投影(umap)。将每个单细胞的基因表达和染色质分析的所有数据点都降至低维,例如二维,并在二维散点图中可视化。标志物表达、样品来源、淋巴瘤亚型、恶性程度和其他数据可以施加在散点图上,以帮助鉴定不同的细胞类型。比较每种类型的淋巴瘤中每种细胞类型的相对频率,以揭示基于不同标准(包括但不限于淋巴瘤的恶性程度或淋巴瘤的亚型)细胞异质性如何发生变化。
[0607]
实施例4:使用机器学习诊断b细胞淋巴瘤亚型和恶性程度
[0608]
使用关联的基因表达和染色质可接近性特征来诊断b细胞淋巴瘤的亚型或恶性程度。基于癌症亚型和恶性程度对每组b细胞淋巴瘤的单细胞基因表达和染色质可接近性进行分析。至少包括基于癌症亚型和恶性程度的每组b细胞淋巴瘤的此数据集的一个子集用作使用机器学习算法(例如但不限于随机森林树或k均值聚类)的训练集。使用该数据的其余子集对训练后的模型进行测试和验证。基于预测结果的准确度和敏感度对算法的参数进行优化。准确度或灵敏度为至少70%。
[0609]
一旦建立模型,就可以根据亚型和恶性程度来诊断具有未表征的b细胞淋巴瘤组的个体的b细胞淋巴瘤的亚型或恶性程度。不同的算法返回不同类型的预测。例如,k均值聚类将每个测试样品鉴定为一组特定的b细胞淋巴瘤,而随机森林树提供了测试样品所属的每组b细胞淋巴瘤的概率。其他测试,例如标志物表达,也可用于鉴定b细胞淋巴瘤组。
[0610]
实施例5:b细胞淋巴瘤亚型与恶性程度的相似性
[0611]
使用关联基因表达和染色质可接近性特征的相似性来确定基于亚型和恶性程度的不同b细胞淋巴瘤组的相似性。基于亚型和恶性程度对每组b细胞淋巴瘤的单细胞基因表达和染色质可接近性进行分析。生成这些谱的图。为了基于亚型或恶性程度诊断患有未表征b细胞淋巴瘤组的个体,生成该个体淋巴细胞的单细胞基因表达和染色质可接近性。使用基因表达和染色质可接近性分析的每个数据点计算相似性评分。相似性评分是使用距离度量例如欧几里得距离或曼哈坦距离计算的。在计算相似性之前,将每组数据点(例如每个基因的表达或染色质可接近性)通过归一化方法(例如但不限于z评分)进行归一化。在所测试的所有谱对中,两个最相似的谱具有最小的距离。这种分析用于指导治疗选择。例如,对基于b细胞淋巴瘤亚型和恶性肿瘤的一种谱的有效治疗表明,相同的治疗对最相似的谱也有效。
[0612]
实施例6:肿瘤中表达与正常鉴定的bcr活化特征的分析
[0613]
对从分类为弥漫性小b细胞淋巴瘤组织的肿瘤的人类b细胞淋巴瘤样品中收集的14,000个细胞进行了分析。虽然细胞来自与实施例1和2中所述相同的活检样品,但此样品是单独处理和分析的。对从快速冷冻的腹内淋巴结肿瘤中分离出的细胞核进行批量流动分
选、透化和转座,然后将单细胞核包封在液滴中,在液滴中对dna片段和mrna的3’末端进行条形码化。从总共14,000个细胞核中产生了配对的atac和基因表达文库。基于淋巴结中免疫和基质细胞的已知基因表达标志物来分析和注释主要细胞类型,包括b细胞、t细胞、单核细胞/树突细胞、成纤维细胞和其他基质细胞类型。有两个主要的集群表达b细胞标志物cd19和ms4a1。两个集群中有一个高表达cd40,cd40是b细胞淋巴瘤中恶性细胞的已知标志物。此外,观察到bank1在此b细胞集群中受到强烈阻抑。bank1是bcr活化途径的已知弱化子,并且在淋巴瘤肿瘤发生中经常受到阻抑。因此,该b细胞集群被注释为肿瘤b细胞。还检查了有丝分裂细胞标志物例如mki67的表达,并注释了循环肿瘤b细胞和t细胞的不同集群。
[0614]
选定的最高程度差异表达的免疫基因、转录因子和细胞周期基因在正常b细胞、肿瘤b细胞和循环肿瘤b细胞中的平均表达的热图在图46a中示出。图46b示出了肿瘤b细胞中上调基因的富集功能基因集,其是使用enrichr(chen等人,“enrichr:interactive and collaborative html5 gene list enrichment analysis tool”bmc bioinformatics.2013;128(14);kuleshov等人,“enrichr:a comprehensive gene set enrichment analysis web server 2016update”nucleic acids research.2016;gkw377)计算的。
[0615]
实施例7:转录因子(tf)网络分析
[0616]
设计用于构建转录网络的三步策略并用于分析来自实施例6的数据。使用此方法,在异质样品中区分肿瘤细胞与非肿瘤细胞并重建细胞类型特异性基因调控网络。首先,鉴定了肿瘤细胞中的差异表达基因。通过设置p值《10^-20的阈值,确定在肿瘤细胞中上调的198个基因的列表。接下来,将基因列表与推断的特征关联相交,以找到与肿瘤特异性基因有关的峰。最后,执行基序富集分析以鉴定肿瘤细胞中出现富集基序的转录因子。具有关联靶基因的富集转录因子限定了tf调控网络的边缘。tf基因网络构建的分析工作流程描绘于图47中,该图示出从峰-基因特征关联开始,峰和基因分别使用基序富集和差异表达分析进行过滤。将其余的峰进一步映射到基序,将最高程度差异表达的基因连接为推断的tf靶基因调控网络。
[0617]
由于mrna和atac数据是从相同的细胞生成的,因此细胞类型注释可以从一种模态转移到另一种模态。除了使用如b细胞标志物ms4a1等常规细胞标志物鉴定b细胞、单核细胞和t细胞亚型外,还能够基于cd40表达上调和bank1减少区分肿瘤b细胞与正常b细胞。pax5相对于正常b细胞在肿瘤b细胞中显著上调,其此前已被鉴定为慢性淋巴细胞白血病(cll)的核心调节因子(ott等人,(2018).cancer cell,34(6),982-995.e7)。
[0618]
超级增强子分析
[0619]
据报告,超级增强子在cll b细胞肿瘤发生中是必不可少的(ott等人,(2018).cancer cell,34(6),982-995.e7),其中pax5本身受近端超级增强子调节。将肿瘤富集关联与cll中注释的超级增强子进行比较,并观察到超级增强子的高显著性关联的强富集(图48a)。与cll超级增强子重叠的前3个最显著的关联是pax5,这与pax5基因座是肿瘤b细胞中的主要超级增强子的观察结果一致。图48a示出了肿瘤富集特征关联的关联显著性分布(由cll注释的超增强子的重叠分隔开),并且前3个最显著的关联是pax5和zcchc7,zcchc7是pax5的附近基因。图48b在左侧示出了pax5基因座处的atac切割位点覆盖和推断的特征关联。过滤掉相关性《0.8的关联以提高可视化效果,并且最显著的关联在图48b以虚线框突出
显示,pax5的每细胞类型表达和关联的峰显示在右侧。正相关的特征关联由顶部的弧表示。虚线框突出显示的是pax5和cll超级增强子之间的高度显著的特征关联(ott等人,(2018).cancer cell,34(6),982-995.e7)。在图示的特征关联下方是在0.3mb区域中针对每个细胞集群鉴定的开放染色质峰。右侧是显示所有细胞集群中pax5的表达水平和细胞集群中所选特征的峰高(每个细胞的平均切割位点数量)的图。与正常b细胞相比,肿瘤b细胞具有升高的pax5表达,并在此超级增强子处具有开放染色质(图48b中虚线框的位置)。
[0620]
基序富集分析
[0621]
以两种不同的方式进行基序富集分析。第一种方式旨在寻找相对于正常b细胞在肿瘤b细胞中的可接近性增加的转录因子基序。在这种全局富集方法中,使用两个细胞群体之间的所有峰来估计富集。为此,使用chromvar和双样本t检验计算肿瘤细胞和正常b细胞之间每个基序的tf偏差z评分。将两个群体之间的推断平均差进一步z评分为富集评分。第二种和替代方法是仅在与最高肿瘤上调基因相关联的峰中鉴定基序富集。在此背景依赖性富集中,通过将潜在的肿瘤特异性增强子与肿瘤细胞中共享gc和可接近性谱的背景峰集进行比较,在肿瘤背景下估计富集。为此,使用与chromvar类似的策略计算一组背景峰,改动是匹配每个细胞的gc含量和峰大小,而不是gc含量和切割位点。通过增强子峰和背景峰中基序出现的超几何检验来确定基序富集。
[0622]
富集基序的最终列表被定义为全局分析中排名前10的基序和背景特异性分析中排名前10的基序的联合。为了提高可解释性并克服tf基序序列的冗余,基于jaspar 2020脊椎动物基序聚类结果将tf基序分组到tf家族中(fornes等人,(2020)nucleic acids research,48(d1):d87
–
d92)。pax5基序被重新注释到pax/cux/onecut家族,其中包括pax1、pax2、pax3、pax4、pax6、pax7和pax9,因为pax5是b细胞中充分表征的转录因子,并且与其他pax转录因子具有高度同源性。
[0623]
全局富集分析将tcf3/tcf4基序鉴定为可接近性上调最多的转录因子家族。这与tcf3/4在b细胞淋巴瘤肿瘤发生中的充分表征的功能一致(basso等人,(2015).nature reviews immunology,15(3),172
–
184)。此外,tcf4也是肿瘤细胞中检测到的最丰富的转录因子。myc家族转录因子的几个成员被鉴定为在肿瘤与正常以及增强子与背景中强富集。最丰富的myc家族tf(基础螺旋-环-螺旋和亮氨酸拉链,或bhlhz基序)包括hif1a、max和myc。
[0624]
在分析中配对盒(pax)转录因子家族被鉴定为在肿瘤细胞中相对于可接近区域在肿瘤特异性增强子中的前1个富集基序,其中pax5是在肿瘤细胞中表达最丰富的pax家族tf。有趣的是,与正常细胞相比,未观察到pax基序在肿瘤细胞中的可接近性差异,这表明pax具有特定的调节模式。分析表明,pax tf的整体可接近性在肿瘤和正常b细胞之间保持在稳定水平。然而,pax tf更有可能结合肿瘤特异性增强子。在cll患者中报告了类似的富集模式,其中pax5在cll患者的正常b细胞和肿瘤b细胞中同样富集,但在肿瘤细胞的背景下,pax5是中央调节转录因子(ott等人,(2018).cancer cell,34(6),982-995.e7)。如图49a所示,基序富集分析工作流程从两种分析策略产生富集基序的聚合列表。图49b示出了所有基序(左)和最高富集命中(右)的基序富集评分。
[0625]
肿瘤细胞中的转录因子网络
[0626]
确定了myc、pax和tcf转录因子的几个关键自身和交叉调节。在图50中,基于特征关联显著性,用热图颜色比例尺绘制tf-靶基因调节。目标基因为列,并基于基因本体注释
进行分组。转录因子基因为行,并被分组为tf家族。将靶基因差异表达p值绘制为附加列注释以及在肿瘤细胞中检测到的总umi。类似地,在线图中绘制了tf基序富集评分(es_峰用于背景特异性分析,es_细胞用于全局分析),以及用于行注释的肿瘤umi。具体而言,观察到pax和tcf基因均受相同的tf家族调节,例如tcf4-tcf4、pax5-pax5和tcf4-pax5。b细胞发育和肿瘤发生中的其他已知tf也在myc、pax和tcf转录因子的靶基因中,例如tp63、lef1、irf8和mef2b。其他潜在的靶基因还包括bcr活化途径的几个关键成员,例如bcl2、iglc1、il4r和syk。
[0627]
为了鉴定肿瘤b细胞特异性基因调控网络,通过在肿瘤b细胞中上调的基因过滤特征关联,并将与这些特征关联相关的开放染色质峰中出现的基序与肿瘤b细胞中所有峰的基序进行比较。使用这种方法,观察到pax1基序是最富集的(图50)。pax1和pax5基序高度相似,但pax1在肿瘤b细胞中不表达,而pax5高度表达。因此,pax5转录因子很可能与已鉴定的pax1基序结合。在b细胞和肿瘤b细胞之间差异表达且已知是b细胞淋巴瘤的关键调节因子的pax5基因座上,pax5的表达与先前鉴定的超级增强子中的开放pax5基序位点高度相关,指示自身调节(图48b,虚线框)。从全基因组来看,显著特征关联的存在表明pax5可能还调节免疫转录因子nfatc1、tcf4、ikzf1和irf8(图50),表明pax5调节肿瘤b细胞特异性网络。敲除cll细胞系中的147种不同的转录因子表明,pax5的缺失对细胞增殖的影响最大,这证实了其重要性(ott等人,(2018).cancer cell,34(6),982-995.e7)。虽然确认预测的基因调控网络中的个别关联可能需要功能测试,但通过联合mrna和atac数据测量,调控连接的置信度大大增加。在此实施例中,特征关联通过提供基因组中相关的基因表达和开放染色质区域,帮助建立了假定的基因调控网络。
[0628]
虽然本文已经展示和描述了本发明的优选实施方案,但是本领域技术人员显而易见此类实施方案仅仅是为了举例而提供。不意图本发明受本说明书内所提供的特定实例限制。尽管已经参考上述说明书描述本发明,但本文中的实施方案的描述和说明不意图以限制意义解释。在不偏离本发明的情况下本领域技术人员现将进行各种变型、变化和取代。此外,应当理解,本发明的所有方面均不限于本文所述的具体描述、配置或相对比例,其取决于多种条件和变量。应当理解,可以采用本文所述的本发明的实施方案的各种替代方案实施本发明。因此,预期本发明还将涵盖任何此类替代方案、修改、变型或等效方案。意图所附权利要求书界定本发明的范围,并且因此涵盖在这些权利要求书范围内的方法和结构和它们的等效方案。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1