简并测序的索引序列集的设计方法与流程
1.本发明涉及简并测序的索引序列集的设计方法及索引序列集,属于基因测序领域。
背景技术:
2.高通量测序技术又被称为下一代测序技术(ngs),是近年发展起来的新型测序技术。高通量测序技术是对于传统的测序技术的一次革命性改变,可以对几万到几百万的核酸分子进行同时测序。在高通量测序技术中,实际测序应用时,为了充分利用测序仪庞大的通量,常常将多个dna样品混合(pool)在一起测序。为了将不同样品的测序数据拆分开,每个样品往往被标记上特有的索引序列(index)。不同测序仪所使用的索引序列应当依据其测序原理的特点进行设计。目前,还没有适用于简并测序原理的索引序列集的设计方法,本发明提供了针对简并测序原理的索引序列集的设计方法。
技术实现要素:
3.本发明提供了针对简并测序的索引序列集的设计方法以及对应的索引序列集。
4.一方面,本发明提供一种对称索引序列集的设计方法,其特征在于:
5.所述对称索引序列集用于在简并测序中鉴定目标多核苷酸的来源;所述索引序列集是由索引序列为元素构成的集合;所述简并测序指的是3’端不封闭的测序反应;简并测序中,包括两种不同的测序试剂:第一测序试剂和第二测序试剂;两种测序试剂循环加入;其中所述第一测序试剂包含具有可检测标记的两种不同的核苷酸单体;其中所述第二测序试剂包含具有可检测标记的与第一测序试剂不同的两种核苷酸单体,并且其中所述第二测序试剂是在提供了所述第一测序试剂随后提供的,将所述核苷酸单体掺入所述多核苷酸之后检测所述可检测标记生成的信号;
6.所述对称索引序列集中,任意两条索引序列是可区分的,所述可区分的指的是索引序列的mk序列不同且ry序列不同且ws序列不同;所述mk序列指的是使用字母m、k表示的简并碱基序列,ry序列指的是使用字母r、y表示的简并碱基序列,ws序列指的是使用字母w、s表示的简并碱基序列;
7.通过枚举法获得低阶对称索引序列集,再以所述低阶对称索引序列集为基础通过直积法或陪集合并扩展法得到高阶对称索引序列集,所述高阶对称索引序列集中的索引序列的长度为5~20nt;
8.所述陪集合并扩展法包括:获得两个完全不同的同阶对称索引序列集,将所述两个同阶对称索引序列集中的索引序列在指定位置各添加一个特定的碱基,合并后得到一个高阶对称索引序列集;所述“完全不同”指的是两个索引序列集没有公共索引序列,所述“阶”指的是索引序列集中索引序列的长度。
9.根据优选的实施方式,所述对称索引序列集的索引序列的长度为6~10nt。
10.根据优选的实施方式,一次简并测序反应中所用的索引序列的长度相同。
11.根据优选的实施方式,所述索引序列取自n阶对称索引序列集,该集合中任意两条索引序列是可区分的,所有索引序列的长度均为n,5≤n≤20。
12.根据优选的实施方式,所述获得两个完全不同的同阶对称索引序列集,可以通过枚举法。示例性的,可以穷举出所有的2阶对称索引序列集,再从中挑选出两个完全不同的对称索引序列集。
13.根据优选的实施方式,所述获得两个完全不同的同阶对称索引序列集,可以通过将一个已知对称索引序列集通过dna的加法变换为另一个完全不同的同阶对称索引序列集实现,所述dna的加法指的是将一个对称索引序列集中的每条dna序列分别与同一条dna序列相加,所述相加指的是两条dna序列对应位置的每个碱基按照下列公式分别相加:
14.a+a=a,a+c=c,a+t=t,a+g=g,
15.c+a=c,c+c=a,c+t=g,c+g=t,
16.t+a=t,t+c=g,t+t=a,t+g=c,
17.g+a=g,g+c=t,g+t=c,g+g=a;
18.所述同一条dna序列不属于所述已知的对称索引序列集。
19.根据优选的实施方式,所述陪集合并扩展法包括:
20.设xn是一个n阶对称索引序列集,vn为所有长为n的dna序列组成的集合:任选整数i∈[0,n]。在mk、ry和ws三种比特序列中任选一种,记为p,剩下两种记为q和s;所述比特序列是将含a的简并碱基m/r/w转换为逻辑1,不含a的简并碱基k/y/s转换为逻辑0;
[0021]
1)任选z∈vn,计算yn=z+xn,所述加法遵守上述dna的加法,这样就有或利用枚举法得到yn,满足
[0022]
2)写下xn和yn的mk、ry和ws三种比特序列;
[0023]
3)在xn所有p比特序列的第i位之后都加上逻辑字符1,在yn所有p比特序列的第i位之后都加上逻辑字符0;或者反过来,在xn所有p比特序列的第i位之后都加上逻辑字符0,在yn所有p比特序列的第i位之后都加上逻辑字符1;(若i=0,则意为在第1位之前添加)
[0024]
4)把xn和yn中所有序列都标记为“未延伸”;
[0025]
5)任选逻辑字符l1∈{0,1},在xn中任选一条标记为“未延伸”的序列a,在其q比特序列的第i位之后加上l1,然后根据序列a的p和q比特序列第i位之后添加的逻辑字符,确定其s比特序列第i位之后应添加的逻辑字符l2,序列a标记为“已延伸”;
[0026]
6)在yn中找到序列b,其中b和a的s比特序列相同(在添加新逻辑字符前),在序列b的s比特序列的第i位之后加上逻辑字符然后确定其q比特序列第i位之后应添加的逻辑字符l4,序列b标记为“已延伸”;
[0027]
7)在xn中找到序列c,其中c和b的q比特序列相同(在添加新逻辑字符前),在序列c的q比特序列的第i位之后加上逻辑字符然后确定其s比特序列第i位之后应添加的逻辑字符l6,序列c标记为“已延伸”;
[0028]
8)在yn中找到序列d,其中d和c的s比特序列相同(在添加新逻辑字符前),在序列d的s比特序列的第i位之后加上逻辑字符然后确定其q比特序列第i位之后应添加的逻辑字符l8,序列d标记为“已延伸”;
[0029]
9)若xn和yn中还有标记为“未延伸”的序列,则回到第5步,否则执行下一步;
[0030]
10)根据xn和yn各比特序列添加的逻辑字符,确定其第i位后添加的碱基类型,则添
加完碱基后的集合xn∪yn是一个(n+1)阶对称索引序列集。
[0031]
另一方面,本发明提供一种非对称索引序列集的设计方法,其特征在于:所述非对称索引序列集用于在简并测序中鉴定目标多核苷酸的来源;所述索引序列集是由索引序列为元素构成的集合;所述简并测序指的是3’端不封闭的测序反应;简并测序中,包括两种不同的测序试剂:第一测序试剂和第二测序试剂;两种测序试剂循环加入;其中所述第一测序试剂包含具有可检测标记的两种不同的核苷酸单体;其中所述第二测序试剂包含具有可检测标记的与第一测序试剂不同的两种核苷酸单体,并且其中所述第二测序试剂是在提供了所述第一测序试剂随后提供的,将所述核苷酸单体掺入所述多核苷酸之后检测所述可检测标记产生的信号;
[0032]
所述非对称索引序列集中,在mk序列、ry序列、ws序列三种简并序列中,任意两条索引序列的指定的两种简并序列不同;所述索引序列的长度为5~20nt;所述mk序列指的是使用字母m、k表示的简并碱基序列,ry序列指的是使用字母r、y表示的简并碱基序列,ws序列指的是使用字母w、s表示的简并碱基序列。
[0033]
根据优选的实施方式,任意索引序列的所述指定的两种简并序列的简并多聚物长度均小于4。
[0034]
根据优选的实施方式,任意两条索引序列的所述指定的两种简并序列各至少有2个对应的简并多聚物长度不相同。
[0035]
根据优选的实施方式,任意两条索引序列的所述指定的两种简并序列各至少有3个对应的碱基不相同。
[0036]
根据优选的实施方式,所述指定的两种简并序列指的是mk序列和ry序列。
[0037]
根据优选的实施方式,所述指定的两种简并序列指的是mk序列和ws序列。
[0038]
根据优选的实施方式,所述指定的两种简并序列指的是ry序列和ws序列。
[0039]
又一方面,本发明提供一种简并测序使用的索引序列集,包括对称索引序列集和非对称索引序列集;所述对称索引序列集的序列包括表2中的索引序列,所述非对称索引序列集包括表3中的索引序列;所述索引序列集是由索引序列为元素构成的集合;所述简并测序指的是3’端不封闭的测序反应;简并测序中,包括两种不同的测序试剂:第一测序试剂和第二测序试剂;两种测序试剂循环加入;其中所述第一测序试剂包含具有可检测标记的两种不同的核苷酸单体;其中所述第二测序试剂包含具有可检测标记的与第一测序试剂不同的两种核苷酸单体,并且其中所述第二测序试剂是在提供了所述第一测序试剂随后提供的,将所述核苷酸单体掺入所述多核苷酸之后检测所述可检测标记产生的信号。
[0040]
本发明的有益之处
[0041]
本发明提供的索引序列集的设计方法,相比于现有技术,具有如下有益效果:
[0042]
1.适应了简并测序的测序原理,能够保证利用不同的简并底物对多个核酸样品进行测序时,可以将不同的样品准确区分开;
[0043]
2.设计方法较为简洁,计算量小,计算速度快;
[0044]
3.在进行ecc测序(需要至少两轮2+2测序)时,可以在第一轮测序结束后就开始拆分样品,而不必等到ecc测序结束,节省了下游生物信息学分析的时间。
附图说明
[0045]
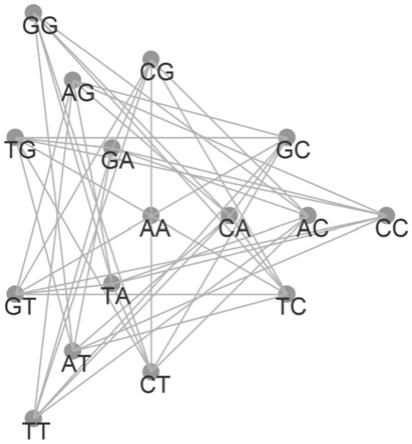
图1.n=2时的可区分图g(v2,e2)。图中共包含42=16个节点,每个节点代表v2中的一条dna序列,每条dna序列的长度为2。
具体实施方式
[0046]
下面结合具体的实施例做出相应的讨论和描述。可以理解的是,申请人为了更加清楚地描述发明的内容,使用了特定的描述方式或者数据。具体的实施方式的描述并不应该理解为对于本发明的内容的限制。本发明要求保护的具体技术方案,应该结合本发明的全部内容以及权利要求书进行整体性的解释。
[0047]
除非另有定义,否则本发明使用的所有技术术语和科学术语均具有与本领域普通技术人员通常所理解的含义相同的含义。在本发明提供的术语存在多个定义的情况下,除非另有说明,否则以所述这些定义为准。
[0048]
术语解释
[0049]
简并测序
[0050]
简并测序为多碱基测序,区别于单碱基测序每轮反应只延伸一个核苷酸分子,多碱基测序每轮反应延伸的核苷酸可能是多个,测序反应释放的荧光信号强度与释放的荧光基团数目成正相关,在没有衰减和失相的理想条件下,每轮反应释放的荧光信号反映了该轮延伸的碱基数,被称为简并多聚物长度(degenerate polymer length,dpl)。以序列aagctgtccagg的mk流程为例,每一轮反应所延伸的碱基分别为(aa,g,c,tgt,cca,gg),因此dpl为(2,1,1,3,3,2)。本发明所述的简并测序指的是3’端不封闭的测序反应;简并测序中,包括两种不同的测序试剂:第一测序试剂和第二测序试剂;两种测序试剂循环加入;其中所述第一测序试剂包含具有可检测标记的两种不同的核苷酸单体;其中所述第二测序试剂包含具有可检测标记的与第一测序试剂不同的两种核苷酸单体,并且其中所述第二测序试剂是在提供了所述第一测序试剂随后提供的,将所述核苷酸单体掺入所述多核苷酸之后检测所述可检测标记生成的信号;第一测序试剂和第二测序试剂的核苷酸单体包括3种可能的组合,即ac/gt,ag/ct,at/cg;或按照标准简并碱基标识,写作mk,ry,ws。具体可参照表1。
[0051]
表1.表示简并碱基的字母
[0052]
字母所代表的碱基ma/ckg/tra/gyc/twa/tsc/gbc/g/tda/g/tha/c/tva/c/g
[0053]
索引序列
[0054]
索引序列或称index或barcode,是连接到测序文库中的片段,它们允许在同一测序运行中对不同样品进行后验分选和鉴定,为了准确拆分测序所得数据,需要满足每个样品对应的索引序列是可区分的,因为相互不可区分的索引序列无法将测序数据对应到其来源的样品中。对于简并测序而言,可区分的索引序列指的是当且仅当索引序列的mk序列不同且ry序列不同且ws序列不同。例如,序列aacc与gtgt是可区分的,因为它们的mk、ry和ws序列分别是mmmm和kkkk、rryy和ryry、wwss和swsw,均不相同。而序列aacc与aaaa不是可区分的,因为它们的mk序列均为mmmm。
[0055]
比特序列
[0056]
比特序列是将含a的简并碱基(m/r/w)转换为逻辑1,不含a的简并碱基(k/y/s)转换为逻辑0。以序列aagctgtccagg的mk流程为例,其比特序列为110100011100。比特序列相比于用字母表示的简并序列,更为简洁直观。
[0057]
核酸样品
[0058]
本文中所使用的核酸样品指的是经过处理以用于生成加标签的dna片段(例如,5
’‑
和3
’‑
加标签或加双标签的线性ssdna或dsdna片段或者加标签的环状ssdna片段)的文库的任何感兴趣的dna。
[0059]
索引序列集和对称索引序列集
[0060]
本发明中所用的索引序列集,是一个集合,集合中的元素是索引序列。对称索引序列集是本发明独创性提出的一个术语,该集合内的所有索引序列的长度(即核苷酸数量)相同,所有序列长度均为n的对称索引序列集称为n阶对称索引序列集;集合中任意两条索引序列的mk序列、ry序列、ws序列都是互不相同的,也就是说任意两条序列是两两可区分的。对于n阶对称索引序列集,其内最多有2n条索引序列。
[0061]
枚举法
[0062]
枚举法,或称穷举法,其思想是将问题的所有可能的答案一一列举,然后根据条件判断此答案是否合适,保留合适的,舍弃不合适的。例如,通过枚举法发现2阶对称索引序列集(aa,cg,gt,tc),该集合共有22条序列,3阶对称索引序列集(aaa,acg,cga,ctg,gat,gcc,tgt,ttc),该集合共有23条序列。枚举法的最大缺点是运算量比较大,效率不高,如果枚举范围太大,在时间上就难以承受。因此,枚举法适用于获得低阶对称索引序列集,例如的,2阶、3阶、4阶索引序列集,并作为得到高阶对称索引序列集的基础。
[0063]
直积法
[0064]
集合a与集合b的直积(或笛卡尔乘积)是由a的元素x和b的元素y组成的有序对(x,y)的集合。本发明中将直积法用于将两个低阶对称索引序列集合并得到高阶对称索引序列集,该低阶对称索引序列集可以是完整的n阶对称索引序列集,也可以是n阶对称索引序列集的子集,也就是说利用枚举法得到n阶对称索引序列集或其子集,再利用直积法得到更高阶的索引序列集。例如一个2阶的对称索引序列集和一个3阶的对称索引序列集通过直积法,可以得到一个5阶的对称索引序列集;再以此5阶对称索引序列集和2阶对称索引序列集通过直积法,可以得到7阶对称索引序列集,以此类推,可以得到更高阶的对称索引序列集。
[0065]
dna的加法
[0066]
dna的加法是本发明提出的一个具有特殊意义的术语,所述dna的加法指的是对于任意两条dna序列,二者相加是通过将两条dna序列对应位置的每个碱基按照下列公式分别
相加得到的:
[0067]
a+a=a,a+c=c,a+t=t,a+g=g,
[0068]
c+a=c,c+c=a,c+t=g,c+g=t,
[0069]
t+a=t,t+c=g,t+t=a,t+g=c,
[0070]
g+a=g,g+c=t,g+t=c,g+g=a;
[0071]
以dna序列atcg和tcga相加为例,可以将其分解为4个对应的碱基分别相加,即:第一位的a+t=t,第二位的t+c=g,第三位的c+g=t,第四位的g+a=g,因此atcg+tcga=tgtg。
[0072]
陪集合并扩展法
[0073]
陪集合并扩展法是本发明首次公开的一种设计索引序列集的方法,该方法的核心是提供一种由已知的或易于获取的低阶对称索引序列集得到高阶对称索引序列集的独创性的算法,将2个完全不同的同阶对称索引序列集中每条序列增加一个特定的碱基,合并后得到一个高阶对称索引序列集;且此高阶对称索引序列集比通过直积法得到的对称索引序列集具有更高的复杂性。此处,“完全不同”指的是两个对称索引序列集没有公共索引序列(交集为空),“同阶”指的是两个对称索引序列集的索引序列长度相同。
[0074]
发明详述
[0075]
具体的,一方面,本发明提供了一种对称索引序列集的设计方法,其特征在于:
[0076]
所述对称索引序列集用于在简并测序中鉴定目标多核苷酸的来源;所述索引序列集是由索引序列为元素构成的集合;所述简并测序指的是3’端不封闭的测序反应;简并测序中,包括两种不同的测序试剂:第一测序试剂和第二测序试剂;两种测序试剂循环加入;其中所述第一测序试剂包含具有可检测标记的两种不同的核苷酸单体;其中所述第二测序试剂包含具有可检测标记的与第一测序试剂不同的两种核苷酸单体,并且其中所述第二测序试剂是在提供了所述第一测序试剂随后提供的,将所述核苷酸单体掺入所述多核苷酸之后检测所述可检测标记生成的信号;
[0077]
所述对称索引序列集中,任意两条索引序列是可区分的,所述可区分的指的是索引序列的mk序列不同且ry序列不同且ws序列不同;所述mk序列指的是使用字母m、k表示的简并碱基序列,ry序列指的是使用字母r、y表示的简并碱基序列,ws序列指的是使用字母w、s表示的简并碱基序列;
[0078]
通过枚举法获得低阶对称索引序列集,再以所述低阶对称索引序列集为基础通过直积法或陪集合并扩展法得到高阶对称索引序列集,所述高阶对称索引序列集中的索引序列的长度为5~20nt;
[0079]
所述陪集合并扩展法包括:获得两个完全不同的同阶对称索引序列集,将所述两个同阶对称索引序列集中的索引序列在指定位置各添加一个特定的碱基,合并后得到一个高阶对称索引序列集;所述“完全不同”指的是两个索引序列集没有公共索引序列,所述“阶”指的是索引序列集中索引序列的长度。
[0080]
根据优选的实施方式,所述简并测序为2+2简并测序,2+2简并测序每一round测序只能得到待测碱基序列一半的序列信息,例如mk round只能得到mk序列信息,无法具体得到4碱基序列信息。当测序的准确率为100%时,可以只进行两个round的测序反应,便可推得该待测核酸的序列信息,例如某条待测dna在mk round得到的序列为mmmkmk,ry round测
得的序列为rryyyr,则可推得待测核酸的碱基序列为aactcg,但实际测序反应的准确率并不能达到100%,所以有必要进行3个round的测序反应,即:mk、ry、ws。可以理解的,对于两个或多个混合在一起进行测序的核酸样品,为了能够在测序结束后将序列准确分选出来对应到正确的样品,需要保证每个样品的索引序列能够互相区分开来,对应于2+2简并测序,即需要满足:任意两条索引序列的mk序列不同且ry序列不同且ws序列不同。
[0081]
根据优选的实施方式,一次简并测序反应中所用的索引序列的长度相同。在实际测序的时候,若待测序核酸样品数n=2n,则本次测序的索引序列可直接取自一个n阶对称索引序列集;若待测序核酸样品数n《2n,则从一个n阶对称索引序列集中任选n个索引序列作为此次测序的索引序列即可,n为大于等于5小于等于20的整数;优选的,选择dpl短的、gc含量均衡的、无二级结构的序列作为此次测序的索引序列。例如,将36个不同来源的核酸样品pool到一起放在同一块芯片上进行测序反应,则共需要36个可区分的索引序列,以6阶索引为例,6阶对称索引序列集的一个集合中最多有26=64个索引,则从中任意选取36个索引分配给待测的36个样品即可。
[0082]
根据优选的实施方式,n阶对称索引序列集的设计非常类似编码理论中的求最大码字问题,而该问题常常借助图论的方法。记vn为所有长为n的dna序列组成的集合:
[0083]vn
={b1b2...bn|bi∈a,c,g,t,i=1,2,...,n}
[0084]
显然vn的大小为|vn|=4n。可区分图g(vn,en)按如下方式构造。其包含4n个节点,每个节点代表vn中的一条dna序列。对节点v1,v2∈vn,存在无向边v1v2∈en,当且仅当v1和v2所代表的dna序列是可区分的。图1为n=2时的一个可区分图。
[0085]
本文从vn构建一个可区分图,然后对称索引序列集的设计便转化为求可区分图的最大集团问题,作为图论中的经典问题,已经有求图的极大集团的成熟的算法。然而,对一般的图而言,求最大集团是np困难问题,因此,本发明需要找到适用于求可区分图g(vn,en)的最大集团的专门算法。
[0086]
根据优选的实施方式,求对称索引序列集的一种算法是枚举法,此方法原理简单,通过枚举法获得低阶索引序列集,所述低阶索引序列集包括长度为2nt、3nt或4nt的低阶索引序列。利用枚举法找出vn中2n条序列的所有组合,检查每个组合是否组成对称索引序列集,方式是检查该组合中是否任意两条序列都是可区分的。通过枚举法,本文搜索了455个不同的含有序列aa的组合,共得2个对称索引序列集:
[0087]
·
(aa,cg,gt,tc)
[0088]
·
(aa,ct,gc,tg)
[0089]
由此也可以看出,每个2阶对称索引序列集共有4条索引序列,即22。
[0090]
而对于3阶对称索引序列集,本文搜索了553,270,671个不同的含有序列aaa的组合,共得48个对称索引序列集。包括,例如:
[0091]
·
(aaa,acg,cga,ctg,gat,gcc,tgt,ttc)
[0092]
·
(aaa,acg,cga,ctg,ggc,gtt,tac,tct)
[0093]
·
(aaa,acg,cgc,ctt,gac,gct,tga,ttg)
[0094]
·
(aaa,acg,cgc,ctt,ggt,gtc,tag,tca)
[0095]
·
(aaa,acg,cgg,cta,gac,gct,tgt,ttc)
[0096]
…
[0097]
上述每个3阶对称索引序列集均有8条序列,即23。
[0098]
如果搜索4阶对称索引序列集,则将有约6.3*10
23
个不同的组合,该数值与阿伏伽德罗常数相当,计算上不可完成,也就是当索引序列的长度在4及4以上时,通过枚举法获得可用的索引序列是非常低效的,通过不断的试验只能得到很少的可用的对称索引序列集,且低阶的对称索引序列集并不能作为测序时使用的索引序列集,因此需要以低阶索引序列集为基础得到可以用于实际测序的高阶索引序列集。所述低阶索引序列指的是长度在5nt以内(不包括5nt)的索引序列。
[0099]
根据优选的实施方式,在使用枚举法得到低阶对称索引序列集后,可以采用直积法来求高阶的对称索引序列集。直积法是由枚举法提供的低阶对称索引序列集导向的一个高效而简单的算法。具体来讲:设xn={x1,x2,
…
,x
2n
}是n阶对称索引序列集,ym={y1,y2,
…
,y
2m
}是m阶对称索引序列集。构造集合z={z|z=xi yj,xi∈xn;yj∈ym},则z是(n+m)阶对称索引序列集。在直积法中,xn和ym可以是完全相同的两个对称索引序列集。同时,直积法也很容易从合并两个对称索引序列集推广到合并多个对称索引序列集,一个(i+j)阶对称索引序列集可以由i阶对称索引序列集和j阶对称索引序列集通过直积法合并得到。例如,xn为3阶对称索引序列集,ym为4阶对称索引序列集,则二者直积可得一个7阶对称索引序列集。
[0100]
根据优选的实施方式,在使用枚举法得到低阶对称索引序列集后,利用陪集合并扩展法得到高阶对称索引序列集。所述陪集合并扩展法包括:获得两个完全不同的同阶对称索引序列集,将所述两个同阶对称索引序列集中的索引序列在指定位置各添加一个特定的碱基,合并后得到一个高阶对称索引序列集;所述“完全不同”指的是两个对称索引序列集没有公共序列,所述“同阶”指的是两个对称索引序列集的序列长度相同。
[0101]
根据优选的实施方式,所述获得两个完全不同的同阶对称索引序列集,可以通过枚举法。示例性的,可以穷举出所有的2阶对称索引序列集,然后从里面挑出2个完全不同的对称索引序列集。
[0102]
根据优选的实施方式,所述获得两个完全不同的同阶对称索引序列集,可以通过将一个已知对称索引序列集通过dna的加法变换为另一个完全不同的同阶对称索引序列集实现,所述dna的加法指的是将一个对称索引序列集中的每条dna序列分别与同一条dna序列相加,所述相加指的是两条dna序列对应位置的每个碱基按照下列公式分别相加:
[0103]
a+a=a,a+c=c,a+t=t,a+g=g,
[0104]
c+a=c,c+c=a,c+t=g,c+g=t,
[0105]
t+a=t,t+c=g,t+t=a,t+g=c,
[0106]
g+a=g,g+c=t,g+t=c,g+g=a;
[0107]
所述同一条dna序列不属于所述已知对称索引序列集。
[0108]
具体的,以2阶对称索引序列集(aa,cg,gt,tc)为例,集合中的每一条dna序列都分别与同一条dna序列tt进行dna的加法运算,对于相加的两条dna序列,将两条dna序列对应位置的每个碱基分别按照上述公式相加,可以得到一个完全不同的2阶对称索引序列集(tt,gc,ca,ag),对称索引序列集(aa,cg,gt,tc)和(tt,gc,ca,ag)即为得到的两个完全不同的同阶(2阶)对称索引序列集。需要注意的是,所述同一条dna序列不属于所述已知对称索引序列集。
[0109]
根据优选的实施方式,陪集合并扩展法的具体算法如下:
[0110]
设xn是一个n阶对称索引序列集,vn为所有长为n的dna序列组成的集合:任选整数i∈[0,n]。在mk、ry和ws三种比特序列中任选一种,记为p,剩下两种记为q和s;所述比特序列是将含a的简并碱基m/r/w转换为逻辑1,不含a的简并碱基k/y/s转换为逻辑0;
[0111]
1)任选z∈vn,计算yn=z+xn,所述加法遵守上述dna的加法,这样就有或利用枚举法得到yn,满足
[0112]
2)写下xn和yn的mk、ry和ws三种比特序列;
[0113]
3)在xn所有p比特序列的第i位之后都加上逻辑字符1,在yn所有p比特序列的第i位之后都加上逻辑字符0;或者反过来,在xn所有p比特序列的第i位之后都加上逻辑字符0,在yn所有p比特序列的第i位之后都加上逻辑字符1;(若i=0,则意为在第1位之前添加)
[0114]
4)把xn和yn中所有序列都标记为“未延伸”;
[0115]
5)任选逻辑字符l1∈{0,1},在xn中任选一条标记为“未延伸”的序列a,在其q比特序列的第i位之后加上l1,然后根据序列a的p和q比特序列第i位之后添加的逻辑字符,确定其s比特序列第i位之后应添加的逻辑字符l2,序列a标记为“已延伸”;
[0116]
6)在yn中找到序列b,其中b和a的s比特序列相同(在添加新逻辑字符前),在序列b的s比特序列的第i位之后加上逻辑字符然后确定其q比特序列第i位之后应添加的逻辑字符l4,序列b标记为“已延伸”;
[0117]
7)在xn中找到序列c,其中c和b的q比特序列相同(在添加新逻辑字符前),在序列c的q比特序列的第i位之后加上逻辑字符然后确定其s比特序列第i位之后应添加的逻辑字符l6,序列c标记为“已延伸”;
[0118]
8)在yn中找到序列d,其中d和c的s比特序列相同(在添加新逻辑字符前),在序列d的s比特序列的第i位之后加上逻辑字符然后确定其q比特序列第i位之后应添加的逻辑字符l8,序列d标记为“已延伸”;
[0119]
9)若xn和yn中还有标记为“未延伸”的序列,则回到第5步,否则执行下一步;
[0120]
10)根据xn和yn各比特序列添加的逻辑字符,确定其第i位后添加的碱基类型,则添加完碱基后的集合xn∪yn是一个(n+1)阶对称索引序列集。
[0121]
另一方面,本发明提供一种非对称索引序列集的设计方法,其特征在于:
[0122]
所述非对称索引序列集用于在简并测序中鉴定目标多核苷酸的来源;所述索引序列集是由索引序列为元素构成的集合;所述简并测序指的是3’端不封闭的测序反应;简并测序中,包括两种不同的测序试剂:第一测序试剂和第二测序试剂;两种测序试剂循环加入;其中所述第一测序试剂包含具有可检测标记的两种不同的核苷酸单体;其中所述第二测序试剂包含具有可检测标记的与第一测序试剂不同的两种核苷酸单体,并且其中所述第二测序试剂是在提供了所述第一测序试剂随后提供的,将所述核苷酸单体掺入所述多核苷酸之后检测所述可检测标记产生的信号;
[0123]
所述非对称索引序列集中,在mk序列、ry序列、ws序列三种简并序列中,任意两条索引序列的指定的两种简并序列不同;所述索引序列的长度为5~20nt;所述mk序列指的是使用字母m、k表示的简并碱基序列,ry序列指的是使用字母r、y表示的简并碱基序列,ws序列指的是使用字母w、s表示的简并碱基序列。
[0124]
根据优选的实施方式,任意索引序列的所述指定的两种简并序列的简并多聚物长
度均小于4。例如,对于索引序列aactg,当指定的两种简并序列为mk序列和ry序列时,mk序列的dpl分别是(3,2),满足dpl小于4的要求;ry序列的dpl分别是(2,2,1),满足dpl小于4的要求。
[0125]
根据优选的实施方式,任意两条索引序列的所述指定的两种简并序列各至少有2个对应的简并多聚物长度不相同。以序列ttacta和cagacg为例说明,当指定的两种简并序列为mk序列和ry序列时,序列ttacta的mk序列的dpl分别是(2,2,1,1),cagacg的mk序列的dpl分别是(2,1,2,1),有2个对应的简并多聚物长度不相同;序列ttacta的ry序列的dpl分别是(2,1,2,1),cagacg的ry序列的dpl分别是(1,3,1,1),有3个对应的简并多聚物长度不相同,满足上述要求。
[0126]
根据优选的实施方式,任意两条索引序列的所述指定的两种简并序列各至少有3个对应的碱基不相同。
[0127]
根据优选的实施方式,所述指定的两种简并序列指的是mk序列和ry序列。
[0128]
根据优选的实施方式,所述指定的两种简并序列指的是mk序列和ws序列。
[0129]
根据优选的实施方式,所述指定的两种简并序列指的是ry序列和ws序列。
[0130]
本发明在可区分图的基础上提出退化可区分图:退化可区分图h(un,fn)按如下方式构造:un中每个节点代表一条n bp的dna序列,且其mk和ry的dpl均小于4。边uiuj∈fn当且仅当ui和uj的至少有两个dpl不相同(对mk序列和ry序列均成立,但ws序列不必成立;或者对mk序列和ws序列均成立,但ry序列不必成立;或者对ws序列和ry序列均成立,但mk序列不必成立),或ui和uj至少有3个碱基不相同。
[0131]
又一方面,本发明提供一种简并测序使用的索引序列集,包括对称索引序列集和非对称索引序列集;所述对称索引序列集的序列包括表2中的索引序列,所述非对称索引序列集包括表3中的索引序列;所述索引序列集是由索引序列为元素构成的集合;所述简并测序指的是3’端不封闭的测序反应;简并测序中,包括两种不同的测序试剂:第一测序试剂和第二测序试剂;两种测序试剂循环加入;其中所述第一测序试剂包含具有可检测标记的两种不同的核苷酸单体;其中所述第二测序试剂包含具有可检测标记的与第一测序试剂不同的两种核苷酸单体,并且其中所述第二测序试剂是在提供了所述第一测序试剂随后提供的,将所述核苷酸单体掺入所述多核苷酸之后检测所述可检测标记产生的信号。
[0132]
表2.对称索引序列集
[0133]
[0134]
[0135]
[0136]
[0137][0138]
表3.非对称索引序列集
[0139][0140]
实施例1
[0141]
直积法
[0142]
以枚举法得到的2阶对称索引序列集(aa,cg,gt,tc)和3阶对称索引序列集(aaa,acg,cga,ctg,gat,gcc,tgt,ttc)为例,来说明如何利用直积法求得高阶对称索引序列集,本实施例得到5阶对称索引序列集。
[0143]
表4展示了具体的合并过程。
[0144]
表4
[0145][0146]
本实施例中的5阶对称索引序列集为(aaaaa,aaacg,aaagt,aaatc,acgaa,acgcg,acggt,acgtc,cgaaa,cgacg,cgagt,cgatc,ctgaa,ctgcg,ctggt,ctgtc,gataa,gatcg,gatgt,gattc,gccaa,gcccg,gccgt,gcctc,tgtaa,tgtcg,tgtgt,tgttc,ttcaa,ttccg,ttcgt,ttctc),共包括25=32个索引序列。容易理解的,2个相同的上述2阶对称索引序列集可通过直积法扩展至4阶对称索引序列集。
[0147]
实施例2
[0148]
陪集合并扩展法
[0149]
本实施例以枚举法得到的2阶对称索引序列集(aa,cg,gt,tc)为例,来说明如何利用陪集合并扩展法求得3阶对称索引序列集。从x2={aa,cg,gt,tc}出发,通过与序列cc相加得到完全不同的对称索引序列集y2={cc,at,tg,ga},然后依次给这8条序列的三种比特序列的末尾添加逻辑字符,最后得到一个3阶对称索引序列集。
[0150]
表5展示的是陪集合并扩展法的具体过程,通过10个步骤的计算,最终得到一个3阶对称索引序列集(aaa,cga,gtc,tcc,ccg,atg,tgt,gat)。
[0151]
表5
[0152]
[0153][0154]
实施例3
[0155]
非对称索引序列集设计(枚举法)
[0156]
本实施例使用python的networkx包搜索了106次h(un,fn)的极大集团,并输出其中最大的一个。用此方法得到的6阶至8阶非对称索引序列集,具体序列见表6。
[0157]
表6
[0158]
[0159][0160]
从表6中可以看出,6阶非对称索引序列集共有10条索引序列,7阶非对称索引序列集共有18条索引序列,8阶非对称索引序列集共有31条索引序列。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1