一种基于深度集成学习的NMIBC术后决策支持系统的构建方法
一种基于深度集成学习的nmibc术后决策支持系统的构建方法
技术领域
1.本发明涉及决策支持系统技术领域,具体涉及一种基于深度集成学习的nmibc术后决策支持系统的构建方法。
背景技术:
2.膀胱癌是泌尿外科最常见的恶性肿瘤之一,也是我国重要的疾病负担。nmibc(非肌层浸润性膀胱癌)是膀胱癌中最常见的类型,占初发膀胱癌的70%。虽然大多数nmibc患者在接受手术治疗+膀胱灌注治疗后可以得到缓解甚至完全治愈,但仍有接近一半的患者在1年内复发,少数患者甚至出现肿瘤进展。评估肿瘤复发与进展的风险关乎患者的临床实际需求,也是医生选择治疗方式和随访策略的重要依据。
3.现有多种方法可对nmibc术后的复发进展风险进行评估,这些方法主要依据多种危险因素对nmibc进行危险度分组(低危、中危、高危和极高危)。当前各国泌尿外科诊疗指南对于nmibc的危险度分组并不一致,基于该方法对nmibc术后复发和进展的预测效果仍不够准确。因此,为解决nmibc临床诊疗中的实际问题,亟需开发出一种能够辅助nmibc术后临床决策的系统,通过识别复发和进展风险来进行临床决策。
技术实现要素:
4.本发明所要解决的技术问题是提供一种基于深度集成学习的nmibc术后决策支持系统的构建方法,以克服上述现有技术中的不足。
5.本发明解决上述技术问题的技术方案如下:一种基于深度集成学习的nmibc术后决策支持系统的构建方法,包括如下步骤:
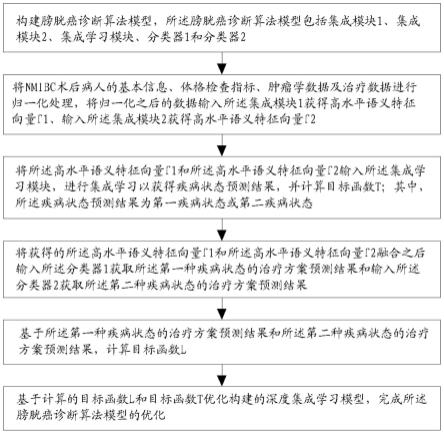
6.步骤s1,构建膀胱癌诊断算法模型,膀胱癌诊断算法模型包括分支结构1、分支结构2、集成学习模块、分类器1和分类器2;
7.步骤s2,将nmibc术后病人的基本信息、体格检查指标、肿瘤学数据及治疗数据进行归一化处理,将归一化之后的数据输入分支结构1获得高水平语义特征向量f1、输入分支结构2获得高水平语义特征向量f2;
8.步骤s3,将高水平语义特征向量f1和高水平语义特征向量f2输入集成学习模块,进行集成学习以获得疾病状态预测结果,并计算目标函数t;其中,疾病状态预测结果为第一疾病状态或第二疾病状态;
9.步骤s4,将获得的高水平语义特征向量f1和高水平语义特征向量f2融合之后输入分类器1获取第一种疾病状态的治疗方案预测结果和输入分类器2获取第二种疾病状态的治疗方案预测结果;
10.步骤s5,基于第一种疾病状态的治疗方案预测结果和第二种疾病状态的治疗方案预测结果,计算目标函数l;
11.步骤s6,基于计算的目标函数l和目标函数t优化构建的膀胱癌诊断算法模型,完
成膀胱癌诊断算法模型的优化。
12.本发明的有益效果是:能够根据nmibc患者的病况来预测术后复发或进展的风险,具有简单实用、准确度和区分度高的优点,可提高患者对疾病预后的认识也可以辅助医师做出医疗决策。该方法在深度融合病人基本信息、体格检查指标、肿瘤学数据及治疗数据的基础上,通过神经网络建立不同信息之间潜在的关系,构建不同的网络结构学习多样化的病人特征,并设计集成学习在多样化的病人特征中探索更具稳定性的特征,避免因某一个异常值导致学习的特征失效,从而能够进一步提升病人特征的鲁棒性。此外,通过本方法所构建的nmibc术后决策支持系统可提高基层医疗服务能力,改善基层医疗机构医疗资源匮乏的情况。
13.在上述技术方案的基础上,本发明还可以做如下改进。
14.进一步,分支结构1包括4个全连层,分支结构2包括3个transformer结构,高水平语义特征向量f1和高水平语义特征向量f2的特征维度均为128。
15.进一步,步骤s2中数据归一化的方式为计算每一类数据的均值和方差,之后所有数据减去对应均值并除以方差进行归一化处理。
16.进一步,步骤s3包括以下步骤:
17.步骤s31,构建集成学习模块;
18.步骤s32,基于集成学习模块,将获得的高水平语义特征向量f1输入集成学习模块的第一层,获得维度为2的特征向量,并利用softmax函数计算高水平语义特征向量f1所对应得到疾病状态的概率,其中高水平语义特征向量f1对应获得的每种疾病状态的概率为:
[0019][0020]
其中,表示基于高水平语义特征向量f1获得的第i个神经元的激活值,2表示病人疾病状态数;
[0021]
步骤s33,基于集成学习模块,将获得的高水平语义特征向量f2输入集成学习模块的第一层,获得维度为2的特征向量,并利用softmax函数计算高水平语义特征向量f2所对应得到疾病状态的概率,其中高水平语义特征向量f2对应获得的每种疾病状态的概率为:
[0022][0023]
其中,表示基于高水平语义特征向量f2获得的第i个神经元的激活值,2表示病人疾病状态数;
[0024]
步骤s34,将基于高水平语义特征向量f1获得的两个预测概率和基于高水平语义特征向量f2获得的两个预测概率串联,获得维度为4的特征向量,将维度为4的特征向量输入集成学习模块的第二层,获得维度为64的特征向量,将维度为64的特征向量输入集成学习模块的第三层,获得维度为2的特征向量。
[0025]
步骤s35,基于维度为2的特征向量,同时利用softmax函数计算最后每种疾病状态的概率,获得疾病状态预测结果;最后利用交叉熵损失作为目标函数计算目标函数t:
[0026][0027]
其中,tm表示第m类的预测概率,g表示真实标签,如果该病人属于第m类,则g等于1,否则g等于0。
[0028]
进一步,步骤s4包括以下步骤:
[0029]
步骤s41,基于高水平语义特征向量f1和高水平语义特征向量f2,将两者相加,生成融合的病人特征;
[0030]
步骤s42,将融合的病人特征输入分类器1预测面向第一种疾病状态应使用的第j种治疗方案概率:
[0031][0032]
其中,tj表示分类器1中第j个神经元的激活值,j表示治疗第一种疾病状态的治疗方案总数;
[0033]
步骤s43,将融合的病人特征输入分类器2预测面向第二种疾病状态应使用的第n种治疗方案的概率:
[0034][0035]
其中,tn表示分类器2中第n个神经元的激活值,n表示治疗第二种疾病状态的治疗方案总数。
[0036]
进一步,步骤s5中构建的目标函数l表示为:
[0037]
l=-(1-s)logpj+slogqn[0038]
其中,如果病人的真实状态为第一种疾病状态,则s=0;如果病人的真实状态为第二种疾病状态,则s=1。
[0039]
进一步,步骤s6中优化构建的膀胱癌诊断算法模型的损失函数为目标函数t和目标函数l之和。
[0040]
一种基于深度集成学习的nmibc术后决策支持系统的构建装置,包括存储器和处理器;
[0041]
存储器,用于存储计算机程序;
[0042]
处理器,用于当执行计算机程序时,实现如权利要求1至7任一项的构建方法。
[0043]
一种基于深度集成学习的nmibc术后决策支持系统,由权利要求1至7任一的构建方法所获得;其中,
[0044]
分支结构1,用于输入归一化处理的nmibc术后待诊断病人的基本信息、体格检查指标、肿瘤学数据及治疗数据,获得高水平语义特征向量f1;
[0045]
分支结构2,用于输入归一化处理的nmibc术后待诊断病人的基本信息、体格检查指标、肿瘤学数据及治疗数据,获得高水平语义特征向量f2;
[0046]
集成学习模块,用于根据高水平语义特征向量f1和高水平语义特征向量f2,进行集成学习以获得疾病状态预测结果,其中,疾病状态预测结果为第一疾病状态或第二疾病状态;
[0047]
分类器1,用于当疾病状态预测结果为第一疾病状态时,根据高水平语义特征向量f1和高水平语义特征向量f2的融合,获取第一种疾病状态的治疗方案预测结果;
[0048]
分类器2,用于当疾病状态预测结果为第二疾病状态时,根据高水平语义特征向量f1和高水平语义特征向量f2的融合,获取第二种疾病状态的治疗方案预测结果。
附图说明
[0049]
图1为本发明的流程示意图;
[0050]
图2为本发明的结构框架图。
[0051]
附图中,各标号所代表的部件列表如下:
具体实施方式
[0052]
以下结合附图对本发明的原理和特征进行描述,所举实例只用于解释本发明,并非用于限定本发明的范围。
[0053]
实施例1,如图1~图2所示,一种基于深度集成学习的nmibc术后决策支持系统的构建方法,包括如下步骤:
[0054]
步骤s1,构建膀胱癌诊断算法模型,膀胱癌诊断算法模型包括分支结构1、分支结构2、集成学习模块、分类器1和分类器2;
[0055]
步骤s2,将nmibc术后病人的基本信息、体格检查指标、肿瘤学数据及治疗数据进行归一化处理,将归一化之后的数据输入分支结构1获得高水平语义特征向量f1、输入分支结构2获得高水平语义特征向量f2;
[0056]
步骤s3,将高水平语义特征向量f1和高水平语义特征向量f2输入集成学习模块,进行集成学习以获得疾病状态预测结果,并计算目标函数t;其中,疾病状态预测结果为第一疾病状态或第二疾病状态;
[0057]
步骤s4,将获得的高水平语义特征向量f1和高水平语义特征向量f2融合之后输入分类器1获取第一种疾病状态的治疗方案预测结果和输入分类器2获取第二种疾病状态的治疗方案预测结果;
[0058]
步骤s5,基于第一种疾病状态的治疗方案预测结果和第二种疾病状态的治疗方案预测结果,计算目标函数l;
[0059]
步骤s6,基于计算的目标函数l和目标函数t优化构建的膀胱癌诊断算法模型,完成膀胱癌诊断算法模型的优化。
[0060]
能够根据nmibc患者的病况来预测术后复发或进展的风险,具有简单实用、准确度和区分度高的优点,可提高患者对疾病预后的认识也可以辅助医师做出医疗决策。该方法在深度融合病人基本信息、体格检查指标、肿瘤学数据及治疗数据的基础上,通过神经网络建立不同信息之间潜在的关系,构建不同的网络结构学习多样化的病人特征,并设计集成学习在多样化的病人特征中探索更具稳定性的特征,避免因某一个异常值导致学习的特征失效,从而能够进一步提升病人特征的鲁棒性。此外,通过本方法所构建的nmibc术后决策支持系统可提高基层医疗服务能力,改善基层医疗机构医疗资源匮乏的情况;治疗数据如turbt膀胱灌注治疗、turbt+膀胱灌注治疗、保留膀胱的综合治疗、根治性膀胱切除方案。
[0061]
实施例2,如图1~图2所示,本实施例为在实施例1的基础上所进行的进一步改进,
其具体如下:
[0062]
分支结构1包括4个全连层,分支结构2包括3个transformer结构,高水平语义特征向量f1和高水平语义特征向量f2的特征维度均为128。通过构建不同的分支结构,可学习多样化的数据类型,提高模型的鲁棒性。
[0063]
实施例3,如图1~图2所示,本实施例为在实施例1的基础上所进行的进一步改进,其具体如下:
[0064]
步骤s2中数据归一化的方式为计算每一类数据的均值和方差,之后所有数据减去对应均值并除以方差进行归一化处理。数据归一化可消除数据偏差过大问题,并加速模型收敛。
[0065]
实施例4,如图1~图2所示,本实施例为在实施例1的基础上所进行的进一步改进,其具体如下:
[0066]
步骤s3包括以下步骤:
[0067]
步骤s31,构建集成学习模块;通过集成学习多样化的病人特征信息,其可避免因某个数据异常导致模型特征失效,从而确保学习的特征具有更好的稳定性;
[0068]
步骤s32,基于集成学习模块,将获得的高水平语义特征向量f1输入集成学习模块的第一层,获得维度为2的特征向量,并利用softmax函数计算高水平语义特征向量f1所对应得到疾病状态的概率,其中高水平语义特征向量f1对应获得的每种疾病状态的概率为:
[0069][0070]
其中,表示基于高水平语义特征向量f1获得的第i个神经元的激活值,2表示病人疾病状态数;
[0071]
步骤s33,基于集成学习模块,将获得的高水平语义特征向量f2输入集成学习模块的第一层,获得维度为2的特征向量,并利用softmax函数计算高水平语义特征向量f2所对应得到疾病状态的概率,其中高水平语义特征向量f2对应获得的每种疾病状态的概率为:
[0072][0073]
其中,表示基于高水平语义特征向量f2获得的第i个神经元的激活值,2表示病人疾病状态数;
[0074]
步骤s34,将基于高水平语义特征向量f1获得的两个预测概率和基于高水平语义特征向量f2获得的两个预测概率串联,获得维度为4的特征向量,将维度为4的特征向量输入集成学习模块的第二层,获得维度为64的特征向量,将维度为64的特征向量输入集成学习模块的第三层,获得维度为2的特征向量。
[0075]
步骤s35,基于维度为2的特征向量,同时利用softmax函数计算最后每种疾病状态的概率,获得疾病状态预测结果,从而在多样化的病人特征中学习稳定有效的病人信息,进而判断病人的类型,具体实施中,疾病状态为两种,复发和进展,哪种疾病状态的概率高,疾病状态的预测结果则对应此种疾病状态;最后利用交叉熵损失作为目标函数计算目标函数t:
[0076][0077]
其中,tm表示第m类的预测概率,g表示真实标签,如果该病人属于第m类,则g等于1,否则g等于0;具体实施过程中,m取值1、2表示疾病状态分为两种,分别是:1.复发,2.进展。
[0078]
集成学习是在不同类型的特征中学习有效的信息,避免某个数据异常导致结果变化过大,使结果更加稳定。
[0079]
实施例5,如图1~图2所示,本实施例为在实施例1的基础上所进行的进一步改进,其具体如下:
[0080]
步骤s4包括以下步骤:
[0081]
步骤s41,基于高水平语义特征向量f1和高水平语义特征向量f2,将两者相加,生成融合的病人特征;
[0082]
步骤s42,将融合的病人特征输入分类器1预测面向第一种疾病状态应使用的第j种治疗方案概率:
[0083][0084]
其中,tj表示分类器1中第j个神经元的激活值,j表示治疗第一种疾病状态的治疗方案总数,具体实施中第一种疾病状态的治疗方案总数为3,包括:1:turbt、2:膀胱灌注治疗、3:turbt+膀胱灌注治疗;
[0085]
步骤s43,将融合的病人特征输入分类器2预测面向第二种疾病状态应使用的第n种治疗方案的概率:
[0086][0087]
其中,tn表示分类器2中第n个神经元的激活值,n表示治疗第二种疾病状态的治疗方案总数;具体实施中第二种疾病状态的治疗方案总数为2,包括:1:保留膀胱的综合治疗、2:根治性膀胱切除方案。
[0088]
将多样化特征相加融合之后分别输入两个独立的分类器,可分别对不同的疾病状态作出治疗方案预测,之后根据集成学习的结果筛选最后的治疗方案,使可信度更高。
[0089]
实施例6,如图1~图2所示,本实施例为在实施例1的基础上所进行的进一步改进,其具体如下:
[0090]
步骤s5中构建的目标函数l表示为:
[0091]
l=-(1-s)logpj+slogqn[0092]
其中,如果病人的真实状态为第一种疾病状态,则s=0;如果病人的真实状态为第二种疾病状态,则s=1。
[0093]
可加快模型收敛,寻找全局最优值。
[0094]
实施例7,如图1~图2所示,本实施例为在实施例1的基础上所进行的进一步改进,其具体如下:
[0095]
步骤s6中优化构建的膀胱癌诊断算法模型的损失函数为目标函数t和目标函数l
之和。联合两种损失共同优化所述基于集成学习的深度模型,可提高模型的鲁棒性,加速模型收敛。
[0096]
实施例8,如图1~图2所示,一种基于深度集成学习的nmibc术后决策支持系统的构建装置,
[0097]
包括存储器和处理器;
[0098]
存储器,用于存储计算机程序;
[0099]
处理器,用于当执行计算机程序时,实现如实施例1至7任一项实施例的构建方法。
[0100]
实施例9,如图1~图2所示,一种基于深度集成学习的nmibc术后决策支持系统,由权利要求1至7任一的构建方法所获得;其中,
[0101]
分支结构1,用于输入归一化处理的nmibc术后待诊断病人的基本信息、体格检查指标、肿瘤学数据及治疗数据,获得高水平语义特征向量f1;
[0102]
分支结构2,用于输入归一化处理的nmibc术后待诊断病人的基本信息、体格检查指标、肿瘤学数据及治疗数据,获得高水平语义特征向量f2;
[0103]
集成学习模块,用于根据高水平语义特征向量f1和高水平语义特征向量f2,进行集成学习以获得疾病状态预测结果,其中,疾病状态预测结果为第一疾病状态或第二疾病状态;
[0104]
分类器1,用于当疾病状态预测结果为第一疾病状态时,根据高水平语义特征向量f1和高水平语义特征向量f2的融合,获取第一种疾病状态的治疗方案预测结果;
[0105]
分类器2,用于当疾病状态预测结果为第二疾病状态时,根据高水平语义特征向量f1和高水平语义特征向量f2的融合,获取第二种疾病状态的治疗方案预测结果。
[0106]
尽管上面已经示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制,本领域的普通技术人员在本发明的范围内可以对上述实施例进行变化、修改、替换和变型。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1