优化蛋白生产的方法与流程
本发明涉及优化蛋白生产的新方法。这些方法包括:优化正交mrna的方法,设计和产生包含外源trna的最佳操纵子的方法,以及设计和产生包含外源基因(例如编码正交氨酰基-trna合成酶(o-aars)的外源基因)的最佳操纵子的方法。本发明还涉及所述方法的产物。作为本发明的一部分还提供了包含这些发明的产物的宿主细胞、使用所述细胞的方法及其产物。本发明的宿主细胞可用于包含遗传掺入的非经典氨基酸的蛋白和多肽的改进生产。
背景技术:
0、发明背景
1、将多个不同的非经典氨基酸(ncaa)引入到蛋白中的基因编码能力将为蛋白功能的工程化和定向进化提供新的机会,将为生物学发现和理解生物学过程提供新的策略,并且将为非经典氨基酸生物聚合物的编码细胞合成提供基础1,2。除了用于编码天然蛋白合成的那些密码子外,同一细胞中将多种不同的ncaa编码到在细胞内合成的蛋白中还需要正交密码子,其包括四联体密码子3-5、有义密码子压缩(sense codon compression)产生的密码子6,7和掺入非经典氨基酸碱基的密码子8-11。正交密码子必须使用共同工程化的正交氨酰基-trna合成酶(aars)/trna对将其分配给ncaa。相对于宿主生物体进行自然翻译所使用的合成酶和trna,和相对于在同一细胞中指导ncaa所使用的其他正交aars和trna,这些正交氨酰基-trna合成酶(aars)/trna对应该在它们的氨酰化特异性方面是正交的;此外,它们应该特异性识别不同的ncaa单体并解码不同的正交密码子3,12-18。
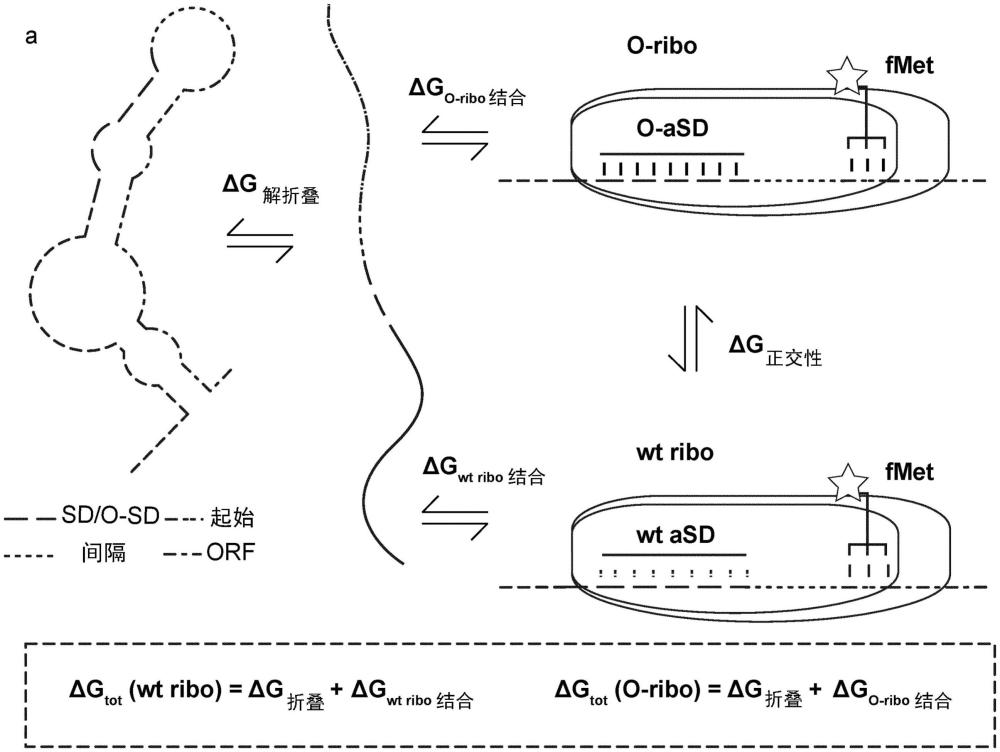
2、正交核糖体(o-核糖体)是被引导至正交mrna(o-mrna)的非天然核糖体,所述正交mrna不是大肠杆菌(e.coli)中野生型(wt)核糖体的底物。这些核糖体与天然核糖体并行工作,但在其核糖体rna中含有改变,将它们引导至正交信息的5'非翻译区(5'utr)内的o-核糖体结合位点(o-rbs)19。由于o-核糖体不负责合成蛋白质组,因此它们可以被工程改造为执行天然核糖体无法访问的新功能,包括新的解码和新的内在聚合功能3,20,21。o-riboq1(进化的o-核糖体)使用同源trna有效解码o-mrna上的琥珀密码子和四联体密码子,从而提供在正交信息上选择性解码的正交密码子3,20。
3、共同工程化的正交aars/trna对(可识别不同的ncaa并解码不同的密码子)已被用于将两个或三个不同的ncaa掺入蛋白中3,4,14,15,18,22。同源的马氏甲烷八叠球菌(methanosarcina mazei,mm)或巴氏甲烷八叠球菌(methanosarcina barkeri,mb)吡咯赖氨酰-trna(pyrrolysyl-trna)是广泛使用的用于遗传密码扩展的正交aars/trna对2,23。发明人最近研究了来自不同生物体的pylrs/trnapyl对,并发现天然pylrs和trnapyl序列聚类成具有不同特异性的几个亚类。这一发现使发明人能够工程改造双重和三重正交pylrs/trnapyl对,识别不同的ncaa并解码不同的密码子14,15。
4、利用工程化的三重正交pylrs/trnapyl对通过组合o-riboq1介导的o(trans)-strepgfp的翻译(40tag,136agga或150agta)his6(strepgfphis6开放阅读框(orf)的o-mrna,从之前描述的5'utr翻译,其包含o-核糖体结合位点(o(trans))并包含两个四联体密码子(agga和agta)和一个琥珀密码子(tag)),发明人证明了将三种ncaa掺入重组strepgfp(40bock,136nmh,150cbzk)his615。然而,发明人指出14,15,该表达系统的蛋白产量较低且未经优化。附加实验使用o(trans)-strepgfphis6和strepgfphis6开放阅读框(具有包含wt rbs的5'utr),证明了o(trans)-strepgfphis6通过o-核糖体进行翻译导致产生的strepgfphis6蛋白比使用wt核糖体要少31倍。此外,将o(trans)5'utr转移至其他orf也会导致蛋白合成水平显著降低(图1和补充图1)。o(trans)5'utr序列衍生自用于产生gst融合蛋白的构建体,其中它指导o-核糖体依赖性翻译的水平与来自包含wt rbs的5'utr的o-核糖体非依赖性翻译相当3,20。这些观察结果表明,尽管o(trans)序列指导某些orf的高效正交翻译,但它并没有为orf的高效翻译提供通用解决方案。
5、因此,需要用于创建o-mrna的通用解决方案,以最大化正交翻译中的蛋白产量。
技术实现思路
1、发明人在此提供了优化蛋白生产的高效方法。
2、在本发明的一个方面,提供了一种设计信使rna(mrna)的方法,所述信使rna是适合于由正交核糖体(o-核糖体)翻译的正交信使rna(o-mrna),其中所述mrna包含5’非翻译区(5’utr)和开放阅读框(orf),所述方法包括:
3、(a)预测mrna的自由折叠状态和mrna的结合o-核糖体的能起始状态(o-ribosome-bound initiation-competent state)之间的自由能差异(δgtot(o-ribo));
4、(b)在5'utr中引入修饰;
5、(c)预测修饰后的新δgtot(o-ribo)(δgtot新(o-ribo));
6、(d)如果所述δgtot新(o-ribo)比先前的δgtot(o-ribo)更负,则接受修饰,和
7、如果所述δgtot新(o-ribo)比先前的δgtot(o-ribo)更正,则根据概率分布接受或拒绝修饰;和
8、(e)产生包含含有所接受的修饰的5'utr的o-mrna序列。
9、δgtot(o-ribo)可以是解折叠mrna所需的自由能(δg解折叠)和mrna结合o-核糖体以形成结合o-核糖体的能起始状态时释放的自由能(δgo-ribo结合)的总和。
10、o-核糖体可以包含正交16s rrna并且mrna可以包含shine dalgarno序列,并且δgtot(o-ribo)可以根据以下进行预测:
11、δgtot(o-ribo)=(δgmrna-o-rrna+δg起始+δg间距–δg备用)+δg解折叠;
12、其中
13、δgmrna-o-rrna是正交16s rrna最后9个核苷酸与mrna的所预测共折叠二级结构的自由能;
14、δg起始是起始trna与orf起始密码子结合时释放的能量;
15、δg间距是shine dalgarno序列和起始密码子之间非最佳间隔长度的能量惩罚(energy penalty);
16、δg备用(δgstandby)是解折叠二级结构所需的能量,所述二级结构隔离shinedalgarno序列上游的四个核苷酸;和
17、δg解折叠是解折叠mrna中二级结构所需的能量。
18、如果δgtot新(o-ribo)比先前的δgtot(o-ribo)更正,则所述δgtot新(o-ribo)和所述δgtot(o-ribo)之间的差异的量值(magnitude)决定了接受的概率(probability ofacceptance),其中与较大的量值相比,较小的量值与较高的接受机会(chance ofacceptance)相关联。
19、接受或拒绝修饰所依据的概率分布(probability distribution)可以是:
20、
21、其中tsa是模拟退火温度。
22、tsa可以调节以维持5-20%的接受率(acceptance rate)。
23、在一个实施方案中,所述方法用于设计mrna,该mrna是适合于由细胞中的o-核糖体翻译的o-mrna,所述细胞中还包含第二核糖体(2nd-核糖体),其中
24、步骤(a)包括预测mrna的自由折叠状态和mrna的结合第二核糖体的能起始状态之间的自由能差异(δgtot(2nd-ribo));
25、步骤(c)包括预测修饰后的新δgtot(2nd-ribo)(δgtot新(2nd-ribo));
26、步骤(d)为:如果所述δgtot新(o-ribo)比先前的δgtot(o-ribo)更负并且所述δgtot新(2nd-ribo)比先前的δgtot(2nd-ribo)更正,则接受修饰,和
27、如果所述δgtot新(o-ribo)比先前的δgtot(o-ribo)更正,或者如果所述δgtot新(2nd-ribo)比先前的δgtot(2nd-ribo)更负,则根据概率分布接受或拒绝修饰。
28、在一个具体的实施方案中,提供了一种设计mrna的方法,该mrna是适合于由细胞中的o-核糖体翻译的o-mrna,所述细胞还包含第二核糖体(2nd-核糖体),其中所述mrna包含5'utr和orf,其中所述方法包括:
29、(a)预测mrna的自由折叠状态和o-mrna的结合o-核糖体的能起始状态之间的自由能差异(δgtot(o-ribo)),并预测mrna的自由折叠状态和mrna的结合第二核糖体的能起始状态之间的自由能差异(δgtot(2nd-ribo));
30、(b)在5'utr中引入修饰;
31、(c)预测修饰后的新δgtot(o-ribo)(δgtot新(o-ribo))和新δgtot(2nd-ribo)(δgtot新(2nd-ribo));
32、(d)如果所述δgtot新(o-ribo)比先前的δgtot(o-ribo)更负并且所述δgtot新(2nd-ribo)比先前的δgtot(2nd-ribo)更正,则接受修饰,和
33、如果所述δgtot新(o-ribo)比先前的δgtot(o-ribo)更正,或者如果所述δgtot新(2nd-ribo)比先前的δgtot(2nd-ribo)更负,则根据概率分布接受或拒绝修饰;和
34、(e)产生包含含有所接受的修饰的5'utr的o-mrna序列。
35、δgtot(2nd-ribo)可以是解折叠mrna所需的自由能(δg解折叠)和mrna结合至第二核糖体以形成结合第二核糖体的能起始状态时释放的自由能(δg2nd ribo结合)之和。
36、第二核糖体可以包含16s rrna,mrna可以包含shine dalgarno序列,并且δgtot(2nd-ribo)可以根据以下进行预测:
37、δgtot(2nd-ribo)=(δgmrna-2nd-rrna+δg起始+δg间距–δg备用)+δg解折叠;
38、其中
39、δgmrna-2nd-rrna是16s rrna最后9个核苷酸与mrna的预测的共折叠二级结构的自由能;
40、δg起始是起始trna与orf的起始密码子结合所释放的能量;
41、δg间距是shine dalgarno序列和起始密码子之间非最佳间隔长度的能量惩罚;
42、δg备用是解折叠二级结构所需的能量,所述二级结构隔离shine dalgarno序列上游的四个核苷酸;和
43、δg解折叠是解折叠mrna中二级结构所需的能量。
44、在一个实施方案中,当δgtot新(o-ribo)比先前的δgtot(o-ribo)更正或者δgtot新(2nd-ribo)比先前的δgtot(2nd-ribo)更负时,所述δgtot新(o-ribo)与所述δgtot(o-ribo)之间或所述δgtot新(2nd-ribo)和所述δgtot(2nd-ribo)之间的差异的量值决定了接受的概率,其中与较大的量值相比,较小的量值与较高的接受机会相关联。
45、在一个实施方案中:
46、步骤(a)包括根据下式计算δgtot(opt):δgtot(opt)=δgtot(o-ribo)–x*δgtot(2nd-ribo);
47、步骤(c)包括根据下式计算δgtot新(opt):δgtot新(opt)=δgtot新(o-ribo)–x*δgtot新(2nd-ribo);和
48、步骤(d)为:如果所述δgtot新(opt)比先前的δgtot(opt)更负,则接受修饰,和
49、如果所述δgtot新(opt)比先前的δgtot(opt)更正,则根据概率分布接受或拒绝修饰;
50、其中x为0.1至2,或x为0.5。
51、在一个实施方案中,当δgtot新(opt)比先前的δgtot(opt)更正时,所述δgtot新(opt)与所述δgtot(opt)之间的差异的量值决定了接受概率,其中与较大的量值相比,较小的量值与较高的接受机会相关联。
52、接受或拒绝修饰所依据的概率分布可以是:
53、
54、其中tsa是模拟退火温度。
55、可以调节tsa以维持5-20%的接受率。
56、修饰可以是或可以包括单核苷酸改变、插入或缺失。
57、在一个实施方案中,步骤(b)包括向5'utr中引入修饰,或者将orf内的密码子2至20、2至15、2至12、2至10或2至5中的任意一个交换为同义密码子;并且步骤(e)包括生成包含含有所接受的修饰的5'utr和orf的o-mrna序列。
58、在一个实施方案中,步骤(b)包括将包含单核苷酸改变、插入或缺失的修饰引入到5'utr中,或者将orf内的密码子2至12中的任一个交换为同义密码子。
59、在实施方案中,步骤(b)至(d)重复至少200、300、400、500、1000、5000或10000次;或者重复步骤(b)至(d)直到至少10、50、100、250或500次连续重复,连续重复不会导致更负的δgtot新(o-ribo);或者重复步骤(b)至(d),直到至少10、50、100、250或500次连续重复,连续重复不会导致更负的δgtot新(o-ribo)或更正的δgtot新(2nd-ribo);或者重复步骤(b)至(d)直到至少10、50、100、250或500次连续重复,连续重复不会导致更负的δgtot新(opt)。
60、在一个实施方案中,步骤(a)的5'utr长度为35个核苷酸;或者其中修饰位于5'utr的最接近起始密码子的35个核苷酸中的任一个处。步骤(a)的5'utr可以依据随机产生的核酸序列。步骤(a)的5'utr可以包含野生型shine dalgarno序列。
61、o-核糖体可以包含正交抗-shine dalgarno序列,并且步骤(a)的5'utr可以包含正交shine dalgarno序列(o-sd),其被预测与正交抗-shine dalgarno序列完美互补。
62、在一些实施方案中,步骤(b)不包括将修饰引入o-sd五核苷酸核心(o-sd five-nucleotide core)中。
63、shine dalgarno序列可以距离orf的起始密码子为5个核苷酸。
64、在一个实施方案中,第二核糖体是野生型核糖体或者第二核糖体是不同于第一o-核糖体的o-核糖体。
65、设计o-mrna的方法可以在计算机上实施。
66、在本发明的一个方面,提供了一种产生编码由o-核糖体翻译的外源蛋白的核酸序列的方法,其中o-mrna的序列是根据本文公开的任何设计o-mrna的方法设计的,然后产生编码所述序列的核酸分子。
67、在本发明的一个方面,提供了一种用于设计由正交核糖体(o-核糖体)翻译的正交信使rna(o-mrna)的系统,该系统包括:
68、处理器;和
69、一个或多个计算机可读存储介质,其上存储有用于在所述处理器上执行指令以实施本文公开的任何设计o-mrna的方法。
70、在本发明的一个方面,提供了一种计算机程序产品,其包括存储程序代码的非暂时性机器可读介质,当由计算机系统的一个或多个处理器执行时,使得计算机系统实施本文公开的任何设计o-mrna的方法。
71、在本发明的另一个方面,提供了一种设计编码用于在宿主细胞中表达的至少两种外源trna的操纵子的方法,所述宿主细胞包含编码内源trna的内源基因组,所述方法包括:
72、(i)产生所述至少两种外源trna的放置的排列(permutation of arrangement);
73、(ii)在内源基因组内鉴定与所述至少两种外源trna的每个排列内的每个相邻外源trna对具有最高水平的序列同一性的相邻内源trna对;
74、(iii)鉴定内源基因组中每个所鉴定的相邻内源trna对之间的基因间区域;
75、(iv)产生多个序列,其编码所述至少两种外源trna的每种排列并且包含位于每个相关的相邻外源trna对之间的所鉴定的基因间区域;和
76、(v)从所述多个序列中选择序列以包含在编码至少两种外源trna的操纵子中。
77、步骤(v)的选择可以从所述多个序列的排序列表中进行,其中排序列表是通过基于所述至少两种外源trna与用于定义基因间区域的相应内源trna之间的序列同一性之和对多个序列中的每一个进行排序来创建的。
78、步骤(ii)的序列同一性可以通过比较内源trna的受体茎序列与外源trna的受体茎序列(acceptor stem sequence)来计算。可以比较trna的前7个和后8个核苷酸(不包括cca末端)。
79、要考虑的最小基因间区域可以是5、10、15、20或25个碱基对,最大可以是50、75、100、125或150个碱基对。在一个实施方案中,要考虑的最小基因间区域是10个碱基对并且最大是100个碱基对。
80、所述方法可以用于设计编码至少三种、至少四种、至少五种或至少六种外源trna的操纵子。
81、设计编码至少两种外源trna的操纵子的任何方法可以在计算机上实施。
82、在本发明的一个方面,提供了一种用于产生编码包含至少两种外源trna的操纵子的核酸序列的方法,其中所述核酸的序列是根据本文所述的设计编码至少两种外源trna的操纵子的方法中的任一种来设计的,然后产生编码所述序列的核酸。
83、在本发明的一个方面,提供了用于设计包含至少两种外源trna的操纵子的系统,所述系统包含:
84、处理器;和
85、一个或多个计算机可读存储介质,其上存储有用于在所述处理器上执行的指令以实施本文公开的任何设计编码至少两种外源trna的操纵子的方法。
86、在本发明的一个方面,提供了一种计算机程序产品,其包括存储程序代码的非暂时性机器可读介质,当由计算机系统的一个或多个处理器执行时,使得计算机系统实施本文公开的任何设计编码至少两种外源trna的操纵子的方法。
87、在本发明的一个方面,提供了核酸,其中核酸包含操纵子,所述操纵子通过本文公开的任何设计编码至少两种外源trna的操纵子的方法获得或可通过本文公开的任何设计编码至少两种外源trna的操纵子的方法获得。
88、在本发明的一个方面,提供了包含内源基因组的宿主细胞,其中所述宿主细胞包含编码操纵子的核酸,所述操纵子包含至少两种外源trna,并且其中每个外源trna对之间的核酸序列是源自内源基因组的基因间序列。
89、宿主细胞可以包含操纵子,所述操纵子通过本文公开的任何设计编码至少两种外源trna的操纵子的方法获得或可通过本文公开的任何设计包含至少两种外源trna的操纵子的方法获得。
90、宿主细胞可以是原核细胞,例如细菌细胞。细菌细胞可以是大肠杆菌并且内源基因组可以是大肠杆菌基因组。
91、在本发明的另一个方面,提供了一种设计包含用于在宿主细胞中表达的至少两个外源orf的操纵子的方法,其中该方法包括:
92、(i)针对所述至少两个外源orf中的每一个产生多个5'utr序列,其中每个5'utr序列针对包含所述5'utr序列和外源orf的mrna的自由折叠状态和所述mrna的结合核糖体的能起始状态之间的负的预测自由能差异(δgtot(ribo))进行优化;
93、(ii)当位于针对其优化5’utr的外源orf的5’时并且位于剩余的至少两个外源orf中的每一个的3’时,预测所述5’utr序列中每一个的δgtot(ribo);和
94、(iii)选择5'utr序列和所述至少两个外源orf的放置(arrangement)。
95、步骤(iii)可以包括选择5'utr序列和所述至少两个外源orf的放置,其中:
96、所有5'utr/外源orf对的δgtot(ribo)之和是最负的;和/或
97、所有5'utr/外源orf对的δgtot(ribo)平均值是最负的;和/或
98、每个5'utr/外源orf对都具有比目标δgtot(ribo)更负的δgtot(ribo)。
99、步骤(i)可以包括针对所述至少两个外源orf中的每一个生成两个、三个、四个、五个或更多个5'utr序列。
100、在一个实施方案中,所述至少两个外源orf中的至少一个或全部是氨酰基-trna合成酶。
101、所述方法可以用于设计编码至少三个、至少四个、至少五个或至少六个外源orf的操纵子。
102、δgtot(ribo)可以是解折叠mrna所需的自由能(δg解折叠)和mrna与核糖体结合以形成结合核糖体的能起始状态时释放的自由能(δgribo结合)之和。
103、δgtot(ribo)可以根据以下公式预测:
104、δgtot(ribo)=(δgmrna-rrna+δg起始+δg间距–δg备用)+δg解折叠;
105、其中
106、δgmrna-rrna是16s rrna最后9个核苷酸和mrna的预测的共折叠二级结构的自由能;
107、δg起始是起始trna与编码外源orf的序列的起始密码子结合所释放的能量;
108、δg间距是shine dalgarno序列和编码外源orf的序列的起始密码子之间的非最佳间隔长度的能量惩罚;
109、δg备用是解折叠二级结构所需的能量,所述二级结构隔离shine dalgarno序列上游的四个核苷酸;和
110、δg解折叠是解折叠mrna中二级结构所需的能量。
111、在一个实施方案中,其中步骤(i)包括:
112、(a)在5’utr中引入修饰;
113、(b)预测修饰后的新δgtot(ribo)(δgtot新(ribo));
114、(c)如果所述δgtot新(ribo)比先前的δgtot(ribo)更负,则接受修饰,和
115、如果所述δgtot新(ribo)比先前的δgtot(ribo)更正,则根据概率分布接受或拒绝修饰;和
116、(d)生成包含所接受的修饰的5'utr序列。
117、在一个实施方案中,当δgtot新(ribo)比先前的δgtot(ribo)更正时,所述δgtot新(ribo)和所述δgtot(ribo)之间的差异的量值决定了接受概率,其中与较大的量值相比,较小的量值与较高的接受机会相关联。
118、接受或拒绝修饰所根据的概率分布可以是:
119、
120、其中tsa是模拟退火温度。
121、可以调节tsa以维持5-20%的接受率。
122、修饰可以是或可以包括单核苷酸改变、插入或缺失。在一个实施方案中,步骤(a)包括向5'utr中引入修饰,或者在编码外源orf的序列内将密码子2至20、2至15、2至12、2至10或2至5中的任一个交换为同义密码子;步骤(d)包括生成包含含有所接受的修饰的5'utr和orf的序列。在特定的实施方案中,步骤(a)包括将包含单核苷酸改变、插入或缺失的修饰引入到5'utr中,或者将orf内的密码子2至12中的任一个交换为同义密码子。
123、步骤(a)至(c)可以重复至少200、300、400、500、1000、5000或10000次。或者,可以重复步骤(a)至(c),直到至少10、50、100、250或500次连续重复,连续重复不导致更负的δgtot新(ribo)。
124、本文公开的设计包含至少两个外源orf的操纵子的任何方法都可以在计算机上实施。
125、在本发明的一个方面,提供了一种用于产生编码包含至少两个外源orf的多顺反子操纵子的核酸序列的方法,其中该核酸的序列是根据本文公开的设计包含至少两个外源orf的操纵子的任何方法设计的,然后根据所述序列产生核酸。
126、在本发明的一个方面,提供了一种用于设计包含至少两个外源orf的多顺反子操纵子的系统,该系统包含:
127、处理器;和
128、一个或多个计算机可读存储介质,其上存储有用于在所述处理器上执行的指令以实施本文公开的设计包含至少两个外源orf的操纵子的任何方法。
129、在本发明的一个方面,提供了一种计算机程序产品,其包括存储程序代码的非暂时性机器可读介质,当由计算机系统的一个或多个处理器执行时,使得计算机系统实施本文公开的设计包含至少两个外源orf的操纵子的任何方法。
130、在本发明的一个方面,提供了一种核酸,其中核酸包含操纵子,所述操纵子通过本文公开的设计包含至少两个外源orf的操纵子的任何方法获得或可通过本文公开的设计包含至少两个外源orf的操纵子的任何方法获得。
131、在本发明的一个方面,提供了包含编码操纵子的核酸的宿主细胞,所述操纵子通过本文公开的设计包含至少两个外源orf的操纵子的任何方法获得或可通过本文公开的设计包含至少两个外源orf的操纵子的任何方法获得。
132、宿主细胞可以是原核细胞,例如细菌细胞。细菌细胞可以是大肠杆菌并且内源基因组可以是大肠杆菌基因组。
133、在本发明的一个方面,提供了一种宿主细胞,其包含:
134、编码o-mrna的核酸序列,所述o-mrna编码外源蛋白,其中所述o-mrna通过本文公开的设计o-mrna的任何方法获得或可通过本文公开的设计o-mrna的任何方法获得,并且其中所述o-mrna包含至少两种类型的正交密码子;
135、包含编码至少两种正交trna的o-trna操纵子的核酸序列,其中所述至少两种正交trna能够解码所述至少两种类型的正交密码子,其中所述操纵子通过本文公开的设计o-trna操纵子的任何方法获得或可通过本文公开的设计o-trna操纵子的任何方法获得;
136、包含编码至少两种o-aars的正交氨酰基-trna合成酶(o-aars)操纵子的核酸序列,其中所述至少两种o-aars与所述至少两种正交trna形成o-aars-o-trna对,其中所述操纵子通过本文公开的设计编码至少两个外源基因的操纵子的任何方法获得或可通过本文公开的设计编码至少两个外源基因的操纵子的任何方法获得;和
137、正交核糖体。
138、在一个实施方案中,
139、o-mrna包含至少三种类型的正交密码子;
140、o-trna操纵子编码至少三种正交trna,其能够解码所述至少三种正交密码子;
141、o-aars操纵子编码至少三种o-aars,其与所述至少三种正交trna形成o-aars-o-trna对。
142、在一个实施方案中,
143、o-mrna包含至少四种类型的正交密码子;
144、o-trna操纵子编码至少四种正交trna,其能够解码所述至少四种正交密码子;
145、o-aars操纵子编码至少四种o-aars,其与所述至少四种正交trna形成o-aars-o-trna对。
146、宿主细胞可以是原核细胞,例如细菌细胞。细菌细胞可以是大肠杆菌并且内源基因组可以是大肠杆菌基因组。
147、在本发明的一个方面,提供了一种产生多肽的方法,包括:
148、提供包含本文公开的o-核糖体、o-trna操纵子和o-aars操纵子的宿主细胞;
149、在第一非经典氨基酸的存在下孵育宿主细胞,其中所述第一非经典氨基酸是其中一种o-aars的底物;和
150、孵育宿主细胞,以允许第一非经典氨基酸通过o-aars–o-trna对掺入多肽中。
151、在一个实施方案中,所述方法包括:
152、在第二非经典氨基酸的存在下孵育宿主细胞,其中所述第二非经典氨基酸是其中一种o-aars的底物;和
153、孵育宿主细胞,以允许第二非经典氨基酸通过o-aars–o-trna对掺入多肽中。
154、在一个实施方案中,所述方法包括:
155、在第三非经典氨基酸的存在下孵育宿主细胞,其中所述第三非经典氨基酸是其中一种o-aars的底物;和
156、孵育宿主细胞,以允许第三非经典氨基酸通过o-aars–o-trna对掺入多肽中。
157、在一个实施方案中,所述方法包括:
158、在第四非经典氨基酸的存在下孵育宿主细胞,其中所述第四非经典氨基酸是其中一种o-aars的底物;和
159、孵育宿主细胞,以允许第四非经典氨基酸通过o-aars–o-trna对掺入多肽中。
160、在本发明的另一个方面,提供了通过本文公开的产生多肽的任何方法获得或可通过本文公开的产生多肽的任何方法获得的多肽。
- 还没有人留言评论。精彩留言会获得点赞!