跨被试情绪识别模型及其训练方法、情绪识别方法、设备
本发明涉及脑电情绪识别,特别涉及一种跨被试情绪识别模型及其训练方法、情绪识别方法、设备。
背景技术:
1、在脑电跨被试情绪识别中,主要难点是脑电数据存在基于被试的个体差异性。这将导致两方面问题:1、特定于被试的模型在新被试上表现差;2、被试通用模型预测效果不佳。目前,这方面的研究最常用的解决办法是在神经网络中引入域适应。域适应目的是将源域中学到的知识可以应用到不同但相关的目标域中,通过对齐源域和目标域的边缘分布或条件分布,将模型推广到不同分布的不同领域。在域适应中度量源域和目标域的分布距离一般采用最大均值差异(mmd)。在神经网络训练过程中,通过不断最小化mmd损失函数来降低源域和目标域的分布差异,提高模型在目标域的泛化能力。
2、在现有技术ms-mda中,采用多源域适应的方法进行脑电跨被试情绪识别,但该方法的模型结果会随着被试的增多而增大,在被试较多的数据集中,如deap数据集(含32被试)需要构建32个dsfe和dsc,极大增加了模型的参数量,降低模型运行效率;另外,该方法仅考虑了对齐源域和目标域的边缘分布而忽视了条件分布,降低了域不变特征的情感识别能力。
技术实现思路
1、针对上述问题,本发明旨在提供一种跨被试情绪识别模型及其训练方法、情绪识别方法、设备。
2、本发明的技术方案如下:
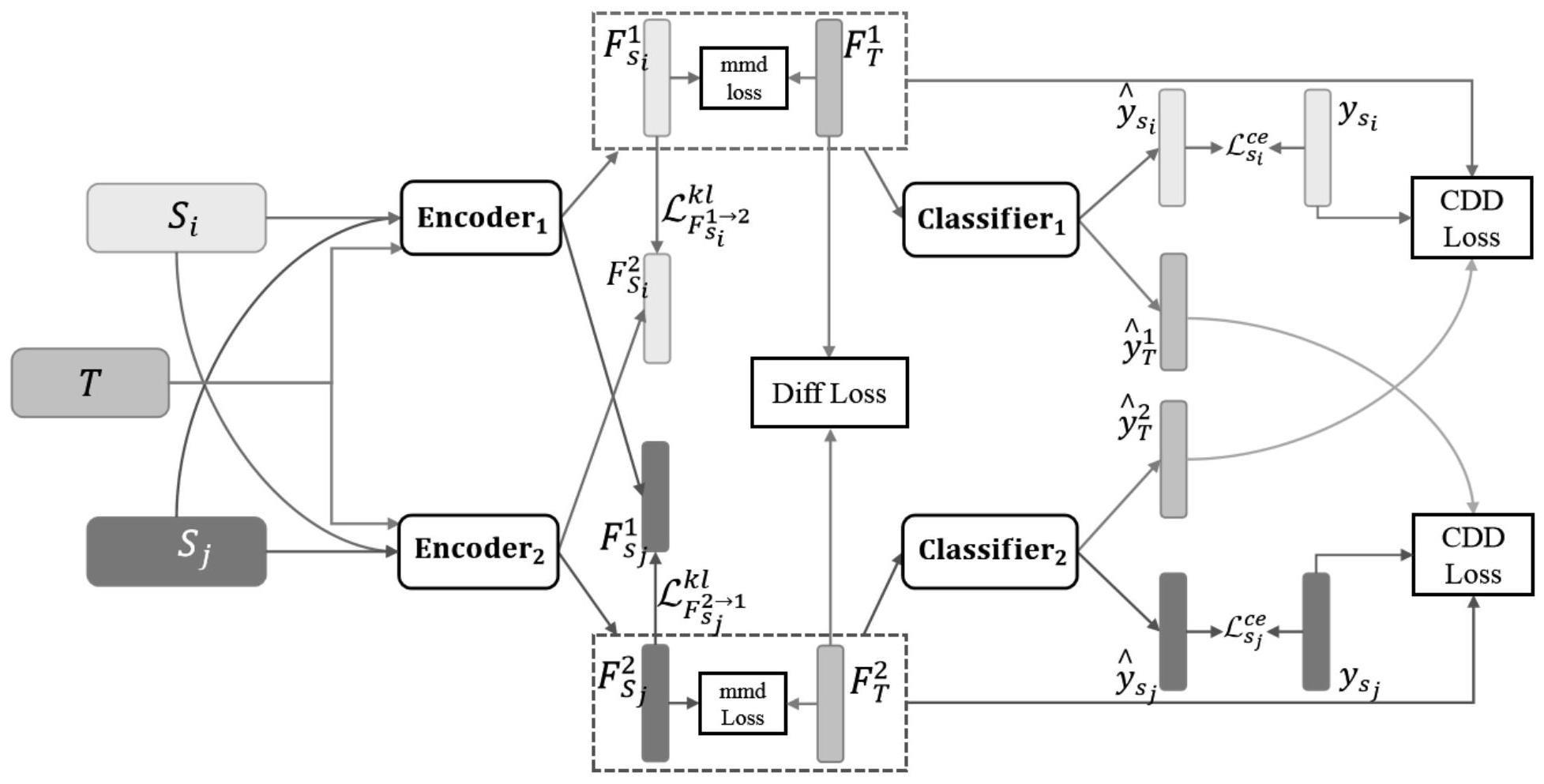
3、本发明提供了一种跨被试情绪识别模型的训练方法,所述训练方法基于神经网络结构实现,所述神经网络结构包括两个独立且结构相同的子神经网络一和子神经网络二,两个子神经网络均包括一个编码器和一个分类器,所述编码器用于进行特征提取,并将提取的特征输入到所述分类器中,所述分类器用于完成预测;
4、所述训练方法包括以下步骤:
5、s1:获取脑电原始信号,并根据所述脑电原始信号提取微分熵特征;
6、s2:将提取获得的微分熵特征根据被试个数划分为多个数据组,并将其中一个数据组作为目标域数据,剩余的其他数据组作为源域数据;
7、s3:假设当前源域数据分别为si和sj,目标域数据为t,其中,所述si为子神经网络一的输入,所述sj为子神经网络二的输入;
8、s4:以相同的方法建立所述子神经网络一的目标函数一和所述子神经网络二的目标函数二;
9、s5:根据所述目标函数一和所述目标函数二建立跨被试情绪识别模型的损失函数;
10、s6:对所述神经网络结构进行神经网络训练,直至所述跨被试情绪识别模型的损失函数最小化,此时获得的神经网络结构即为能够进行跨被试情绪识别的跨被试情绪识别模型。
11、作为优选,步骤s4中,所述子神经网络一的目标函数一为:
12、
13、式中:为子神经网络一的目标函数一;为子神经网络一关于源域数据si上的交叉熵损失函数;为子神经网络二指导子神经网络一产生的协作损失函数;为动态对齐目标域数据和源域数据之间的边缘分布和条件分布的函数;
14、步骤s5中,所述跨被试情绪识别模型的损失函数为:
15、
16、式中:为跨被试情绪识别模型的损失函数;为子神经网络二的目标函数二。
17、作为优选,所述子神经网络一关于源域数据si上的交叉熵损失函数为:
18、
19、式中:k为批大小;yi为源域数据的真实标签;为源域数据由子神经网络一的分类器经过softmax得到的预测标签。
20、作为优选,所述子神经网络二指导子神经网络一产生的协作损失函数为:
21、
22、式中:为源域数据sj经过子神经网络二的编码器得到的特征;为源域数据sj经过子神经网络一的编码器得到的特征;为目标域数据t经过子神经网络二的编码器得到的特征;为目标域数据t经过子神经网络一的编码器得到的特征。
23、作为优选,所述动态对齐目标域数据和源域数据之间的边缘分布和条件分布的函数为:
24、
25、式中:α为关于训练轮数的单调递减函数;为减少目标域数据和源域数据的边缘分布;为减少目标域数据和源域数据的条件分布。
26、作为优选,所述关于训练轮数的单调递减函数α为:
27、
28、式中:e为自然常数;epoch为当前训练轮数;n为总训练轮数;
29、作为优选,所述减少目标域数据和源域数据的边缘分布通过下式进行计算:
30、
31、式中:n和m分别为源域样本量和目标域样本量;k(·,·)为核函数;对应编码器的作用;和分别为源域第i个和第j个样本数据,和分别为目标域第i和第j个样本数据;
32、所述减少目标域数据和源域数据的条件分布通过下式进行计算:
33、
34、式中:m为标签类别的数量;dcc(·,·)和dcc‘(·,·)分别表示相同标签的跨域差异和不同标签的跨域差异。
35、本发明还提供了一种跨被试情绪识别模型,采用上述任意一项所述的跨被试情绪识别模型的训练方法训练而成。
36、本发明还提供了一种跨被试情绪识别方法,采用上述所述的跨被试情绪识别模型进行跨被试情绪识别。
37、本发明还提供了一种电子设备,包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述任一项所述的跨被试情绪识别模型的训练方法或上述所述的跨被试情绪识别方法。
38、本发明的有益效果是:
39、本发明通过采用两个独立且结构相同的子神经网络,使两者互为对方的teacher网络,相互指导和学习,通过协作学习关联提升两个网络的泛化能力;本发明在建立目标函数时,通过考虑动态对齐目标域数据和源域数据之间的边缘分布和条件分布的函数,减小相同类别的分布差异,增大不同类别的分布差异,利用动态分布自适应实现对齐每个类别内的分布;综上使得本发明跨被试情绪识别模型相较于多源域适应的方法,不会随着被试的增多而增大,且模型本身的参数量较少,能够实现模型轻量化,且预测准确率高,能够为脑电跨被试情绪识别提供技术支持。
技术特征:
1.一种跨被试情绪识别模型的训练方法,其特征在于,所述训练方法基于神经网络结构实现,所述神经网络结构包括两个独立且结构相同的子神经网络一和子神经网络二,两个子神经网络均包括一个编码器和一个分类器,所述编码器用于进行特征提取,并将提取的特征输入到所述分类器中,所述分类器用于完成预测;
2.根据权利要求1所述的跨被试情绪识别模型的训练方法,其特征在于,步骤s4中,所述子神经网络一的目标函数一为:
3.根据权利要求2所述的跨被试情绪识别模型的训练方法,其特征在于,所述子神经网络一关于源域数据si上的交叉熵损失函数为:
4.根据权利要求2所述的跨被试情绪识别模型的训练方法,其特征在于,所述子神经网络二指导子神经网络一产生的协作损失函数为:
5.根据权利要求2所述的跨被试情绪识别模型的训练方法,其特征在于,所述动态对齐目标域数据和源域数据之间的边缘分布和条件分布的函数为:
6.根据权利要求5所述的跨被试情绪识别模型的训练方法,其特征在于,所述关于训练轮数的单调递减函数α为:
7.根据权利要求5或6所述的跨被试情绪识别模型的训练方法,其特征在于,所述减少目标域数据和源域数据的边缘分布通过下式进行计算:
8.一种跨被试情绪识别模型,其特征在于,采用权利要求1-7中任意一项所述的跨被试情绪识别模型的训练方法训练而成。
9.一种跨被试情绪识别方法,其特征在于,采用权利要求8所述的跨被试情绪识别模型进行跨被试情绪识别。
10.一种电子设备,包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,其特征在于,所述处理器执行所述计算机程序时实现权利要求1-7中任一项所述的跨被试情绪识别模型的训练方法或权利要求9所述的跨被试情绪识别方法。
技术总结
本发明公开了一种跨被试情绪识别模型及其训练方法、情绪识别方法、设备,训练方法基于神经网络结构实现,神经网络结构包括两个独立且结构相同的子神经网络;训练方法包括以下步骤:S1:获取脑电原始信号,并对其进行微分熵特征提取;S2:将提取的微分熵特征划分为多个数据组,并将其中一个作为目标域数据,剩余的作为源域数据;S3:假设当前源域数据分别为S<subgt;i</subgt;和S<subgt;j</subgt;,目标域数据为T,其中,S<subgt;i</subgt;为子神经网络一的输入,S<subgt;j</subgt;为子神经网络二的输入;S4:建立子神经网络的目标函数;S5:建立跨被试情绪识别模型的损失函数;S6:进行神经网络训练,直至跨被试情绪识别模型的损失函数最小化。本发明获得的跨被试情绪识别模型更加轻量化、识别准确率更高。
技术研发人员:顾瑾,龚新皓,李天瑞
受保护的技术使用者:西南交通大学
技术研发日:
技术公布日:2024/1/16
- 还没有人留言评论。精彩留言会获得点赞!