基于曲线参数化的成品油管道混油浓度预测方法及系统
本发明涉及石油化工检测,特别是关于一种基于曲线参数化的成品油管道混油浓度预测方法及系统。
背景技术:
1、在满足成品油管道沿线地区对不同种类、牌号成品油需求的基础上,为尽可能地降低管道建设运营成本,成品油管道采用顺序输送工艺,该工艺使用一条管道输送多种油品,两种油品在交界处会产生混油,运营方需要根据混油信息对混油采取一定的处理措施。
2、管道现场现行的混油处理方式主要是先确定两段切割或三段切割的方案,混油到站时根据密度计确定混油浓度,基于混油浓度确定切割点位继而将混油下载至混油罐等待后续处理。因此,混油浓度是混油处理的重要决策信息。然而,仅依靠现场密度计确定混油浓度的方法响应慢,无法做到提前预测,导致混油切割时机及方案常存在不合理的情况。
3、目前,现有技术中公开了一种混油浓度预测方法,主要基于cfd理论,考虑管道运行水热力因素对混油的形成和发展的影响,建立混油发展的数值模型,对混油的形成和发展进行描述。研究人员考虑对流传递作用对混油的影响以及浓度差对流扩散系数的影响,建立混油发展的一维模型。通过预测轴向扩散系数,建立混油发展的二维模型。考虑温度、压力等多种因素对混油的影响,建立混油发展的多维模型。然而,一维混油模型考虑的因素不够全面,因此计算结果不够精确。二维和多维模型虽然考虑因素多,计算结果相对精确,但是计算效率低,无法实现大规模成品油管道混油发展状况的求解,对算力的高要求也限制了其在管道现场的实际应用,同时,由于缺少快速求解算法,基于数值求解的方法无法对混油浓度实现实时计算,难以满足对到站混油浓度的在线监测以制定混油处理方案。
4、现有技术还公开了一种使用数据驱动的方法。基于现场真实数据或模拟数据,采用五点法或二十一点法实现混油浓度曲线参数化后,建立回归模型,利用管道运行数据实现混油浓度曲线的预测。研究人员利用一部分进站混油浓度数据,基于gamma-χ分布函数拟合后续浓度变化趋势,实现到站浓度的预测。利用logistics生长曲线,基于一部分进站浓度数据,对后续浓度分布变化进行预测。还基于某管道真实数据19组,使用一维混油模型衍生出255组数据,基于五点法得到的浓度参数作为输出,使用bp神经网络构建混油浓度预测模型。然而,基于到站数据进行拟合的方式,无法实现到站浓度的提前预知,难以辅助提前制定混油切割方案,且logistics生长曲线关于曲线拐点对称的机制不符合浓度曲线油尾长于油头的机理知识。而混油发展的影响因素多种多样,基于五点法的预测方法并未从机理层面充分考虑输入变量,且输出维度较高,模型易发生过拟合。同时,通过数值模拟衍生数据耗费时间且对算力要求较高,对于5点法等多维输入,少量衍生数据又难以有效提高模型准确性,导致预测精度不高。难以适应现场对于浓度准确预测的需求。
技术实现思路
1、针对上述问题,本发明的目的是提供一种能够实现混油浓度曲线精准预测的基于曲线参数化的成品油管道混油浓度预测方法及系统。
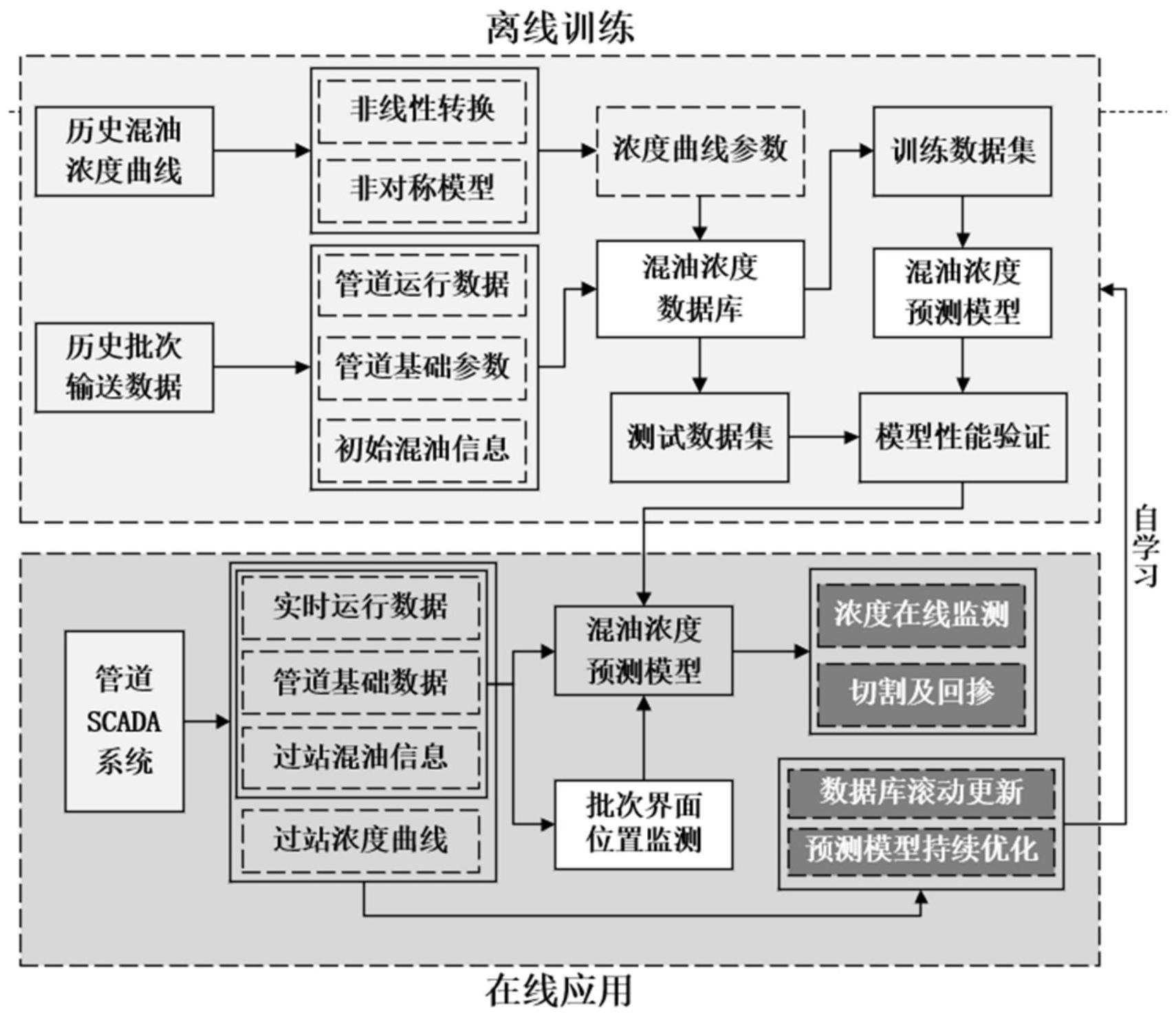
2、为实现上述目的,本发明采取以下技术方案:第一方面,提供一种基于曲线参数化的成品油管道混油浓度预测方法,包括:
3、在上站混油过站后,采集成品油管道的批次输送数据以及混油界面抵达站场时间;
4、在混油界面抵达站场前一段时间,将批次输送数据中的管道运行数据输入至预先构建的混油浓度预测模型中进行混油浓度预测,得到混油浓度曲线;
5、在管道持续运行期间,将采集的批次输送数据以及混油界面抵达站场时间加入至预先构建的混油浓度数据库中,采用自学习机制,对混油浓度预测模型进行更新。
6、进一步地,所述混油浓度预测模型的构建过程为:
7、获取成品油管道的历史批次输送数据和历史混油进站密度数据,其中,历史批次输送数据包括历史运行数据、管道基础参数和初始混油信息,历史混油进站密度数据包括混油到站后不同时刻和历史混油浓度曲线;
8、对历史混油进站密度数据中的历史混油浓度曲线进行参数化,得到混油浓度曲线参数作为混油浓度预测模型的输出值;
9、根据历史批次输送数据和历史混油进站密度数据,构建混油浓度数据库;
10、对混油浓度曲线参数中的待定参数进行非线性转换,将混油浓度曲线参数的输出映射到正态分布;
11、对混油浓度数据库划分测试集和训练集,采用训练集训练混油浓度预测模型,采用测试集验证模型精度,得到满足精度要求的混油浓度预测模型。
12、进一步地,所述对历史混油进站密度数据中的历史混油浓度曲线进行参数化,得到混油浓度曲线参数作为混油浓度预测模型的输出值,包括:
13、对混油浓度曲线拟合函数中需要确定的参数进行随机初始化,并拟合曲线关系式,得到初始混油浓度曲线参数;
14、将混油进站密度数据中的混油到站后不同时刻输入至混油浓度曲线参数中得到当前函数值即拟合的混油浓度曲线;
15、将当前函数值与真实值输入至误差函数中,得到当前误差;
16、根据当前误差,确定参数更新速度,得到更新后的参数,进而得到更新后的混油浓度曲线参数,不断迭代直至误差降低至预先设定的范围内,输出参数,得到最终的混油浓度曲线参数作为混油浓度预测模型的输出值。
17、进一步地,所述混油浓度曲线参数为:
18、
19、其中,β和γ为描述曲线增长率大小的参数,α为曲线的最大y值,σ为控制拐点的x值,x为混油到站后不同时刻,y为混油浓度参数。
20、进一步地,所述误差函数为
21、
22、其中,s(p)为误差值,yi为真实值,f(xi,,,)为代入混油过站时间xi和三个待定参数后得到的当前函数值。
23、进一步地,所述根据历史批次输送数据和历史混油进站密度数据,构建混油浓度数据库,包括:
24、根据成品油管道的历史批次输送数据和历史混油进站密度数据,确定某批次混油在本站的过站混油浓度信息;
25、基于混油在管段内运移起止时间,采集该时间段内的温度压力流量数据,获取雷诺数,并计算该时间段内温度压力流量数据的平均值;
26、采集位于批次界面前后行油品的水热力参数以及混油在上一站的过站初始混油长度;
27、对管段基础信息和雷诺数进行特性变换,得到对应的特征变量;
28、基于管道运行数据、水热力参数、过站初始混油长度、管段基础信息和雷诺数对应的特征变量以及混油浓度曲线参数,构建混油浓度数据库。
29、进一步地,所述非线性转换的计算公式为:
30、
31、其中,x()i为映射后的数据,xi为原始数据,λ为变换参数
32、第二方面,提供一种基于曲线参数化的成品油管道混油浓度预测系统,包括:
33、数据获取模块,用于在上站混油过站后,采集成品油管道的批次输送数据以及混油界面抵达站场时间;
34、预测模块,用于在混油界面抵达站场前一段时间,将批次输送数据中的管道运行数据输入至预先构建的混油浓度预测模型中进行混油浓度预测,得到混油浓度曲线;
35、自学习模块,用于在管道持续运行期间,将采集的批次输送数据以及混油界面抵达站场时间加入至预先构建的混油浓度数据库中,采用自学习机制,对混油浓度预测模型进行更新。
36、第三方面,提供一种处理设备,包括计算机程序指令,其中,所述计算机程序指令被处理设备执行时用于实现上述基于曲线参数化的成品油管道混油浓度预测方法对应的步骤。
37、第四方面,提供一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机程序指令,其中,所述计算机程序指令被处理器执行时用于实现上述基于曲线参数化的成品油管道混油浓度预测方法对应的步骤。
38、本发明由于采取以上技术方案,其具有以下优点:
39、1、成品油管道运行时,需依据到站混油浓度进行到站混油切割,本发明全面考虑对混油发展产生影响的因素,提高预测模型的可解释性和准确性;基于混油浓度曲线参数化和数据非线性转换,降低模型复杂度,保证混油浓度预测模型在数据量少的背景下的预测精度。
40、2、当混油界面即将到站时,本发明可基于管道实时运行数据,实现混油浓度曲线的精准、实时、提前预测,从而指导混油下载和处理方案的制定,有效降低混油处理成本,保证管输成品油质量。
41、3、本发明通过非线性转化将混油浓度曲线参数映射到正态分布,能够提高模型拟合效果及浓度预测准确度。
42、4、本发明在管道运行期间不断采集混油信息,更新混油浓度数据库,实现模型的自学习,预测精度可不断提升直至最优。
43、5、通过提前获取混油浓度以指导混油到站切割,有利于帮助管输企业在应急状况、混油罐裕量不足、人工监测不准确、检测设备出现问题等特殊情况下合理制定混油切割及接收方案。
44、综上所述,本发明可以广泛应用于石油化工检测技术领域中。
- 还没有人留言评论。精彩留言会获得点赞!