一种基于多模态融合的心血管疾病风险预测方法
本发明属于数据分类与预测,具体涉及一种基于多模态融合的心血管疾病风险预测方法。
背景技术:
1、目前针对心血管疾病的预测一般可以分为以下两类:其一是医学指南中的风险预测方法来预测,如美国心脏病学会指南推荐的framingham risk score,欧洲指南推荐的系统冠状动脉风险评估(score)算法,然而这些风险预测算法通常使用多元回归模型开发,模型结合了有限数量的既定风险因素的信息,并且通常假设所有这些因素都以线性方式与cvd结果相关,不同因素之间的相互作用有限或没有相互作用,因此实际效果不佳。其二是基于机器学习的心血管疾病预测方法,随着机器学习技术的不断发展,越来越多的医疗领域科研人员开始探索使用数据驱动的机器学习方法来辅助医生进行疾病诊断。在心血管疾病预测方向,大多数研究都是基于医学数据集中的病患体征检测数据,应用各种机器学习模型对病患是否患有心血管疾病进行诊断。如ahmed等人基于uk biobank数据集提出了autoprognosis模型,该模型集成了各种传统机器学习模型,集权集成后的模型具有更高的鲁棒性,因此效果优于单个模型。ajay等人致力于心血管风险预测的可解释性和应用上的可操作性,在特征选择上加以创新,考虑了多种特征,包括病患家族病史、生活方式、多组学血液数据和环境数据等,之后使用xgboost等机器学习模型对病患是否患有心血管疾病进行更全面的评估。
技术实现思路
1、本发明提供一种基于多模态融合的心血管疾病风险预测方法,针对医学文本数据集存在的文本报告过长,难以在不损失全文信息的同时有效提取语义特征的问题。
2、本发明通过以下技术方案实现:
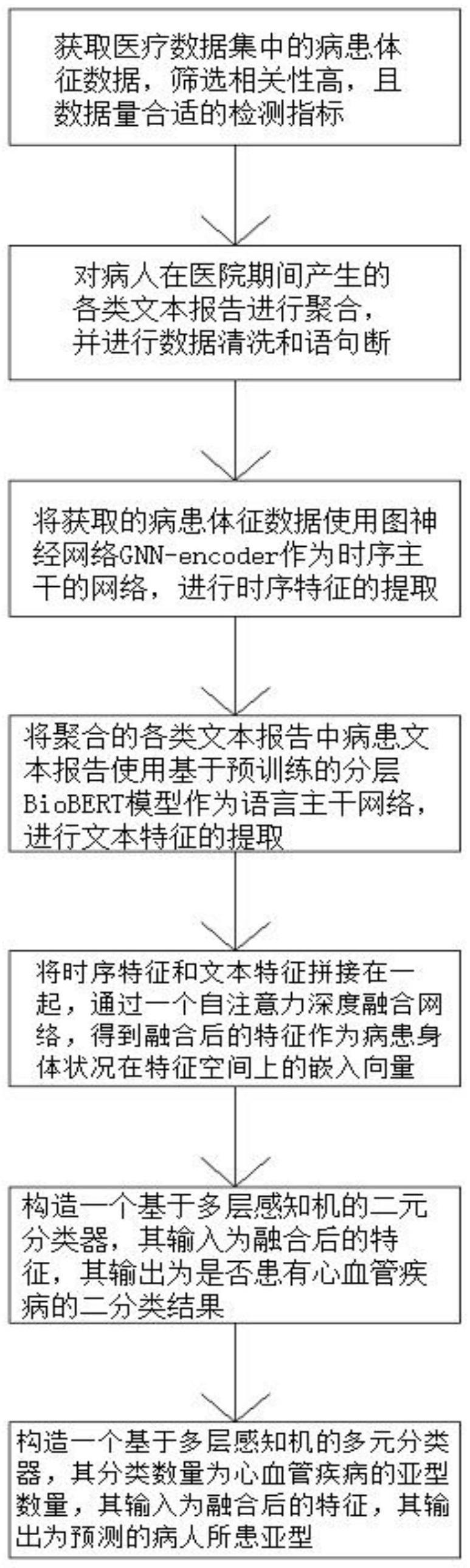
3、一种基于多模态融合的心血管疾病风险预测方法,所述心血管疾病风险预测方法具体包括以下步骤:
4、步骤一:获取医疗数据集中的病患体征数据,筛选相关性高,且数据量合适的检测指标;
5、步骤二:对病人在医院期间产生的各类文本报告进行聚合,并进行数据清洗和语句断句;
6、步骤三:将步骤一获取的病患体征数据使用图神经网络gnn-encoder作为时序主干的网络,进行时序特征的提取;
7、步骤四:将步骤二聚合的各类文本报告中病患文本报告使用基于预训练的分层biobert模型作为语言主干网络,进行文本特征的提取;
8、步骤五:将步骤三的时序特征和步骤四的文本特征拼接在一起,通过一个自注意力深度融合网络,得到融合后的特征作为病患身体状况在特征空间上的嵌入向量;
9、步骤六:构造一个基于多层感知机的二元分类器,其输入为融合后的特征,其输出为是否患有心血管疾病的二分类结果;
10、步骤七:构造一个基于多层感知机的多元分类器,其分类数量为心血管疾病的亚型数量,其输入为融合后的特征,其输出为预测的病人所患亚型。
11、进一步的,所述步骤四基于预训练的分层biobert模型具体为,专门基于医学大数据预训练的语言模型编码器,用于提取文本报告特征。
12、进一步的,使用pubmed 200k和pmc 270k数据集上训练分层biobert模型;
13、给定代表每份报告最多有s个句子,每个句子最多包含z个token,则在输入到分层biobert模型前,每篇报告先被编码为矩阵h,
14、经过分层biobert模型处理后,取最后一个隐藏层的输出作为结果,用平均处理的方式聚合每个句子中的所有token的embedding,得到句子层级的embedding q公式如下,
15、
16、之后使用分层biobert模型进一步编码每个句子的初步编码特征,使得每个句子层级的编码同样学习到前后句子的语义信息
17、
18、继续使用平均聚合的方式得到报告层级的嵌入pi,表示模型从病人文本报告中提取的集成了其患有心血管情况的特征,
19、
20、进一步的,分层biobert模型注意力部分的时间复杂度为token层级的编码复杂度加上句子层级的编码复杂度,即考虑到z2>>s,可以得到其时间复杂度大约是原来的1/s;
21、
22、进一步的,所述步骤五自注意力深度融合网络是一个基于transformer的自注意力网络,将来自不同模态的特征堆叠在一起,再通过自注意力网络学习彼此之间的注意力权重,进行特征间的深度融合。
23、进一步的,在步骤三与步骤四分别使用gnn-encoder和cvdhierbert提取不规则采样的时序特征和医学长文本特征后,对其进行多模态融合,融合算法分别是特征融合单塔结构、双塔结构和拼接方法;
24、在单塔结构中,时序特征和文本特征简单地连接在一起,然后输入单个transformer编码器自注意力模块中;
25、在双塔结构中,时序特征和文本特征独立地输入不同的transformer编码器自注意力模块中,并使用交叉注意力实现跨模态交互,基于另一特征的信息进行学习;
26、拼接融合方式则是直接将不同模态骨干网络提取到的特征直接拼接在一起,直接用于下游任务中。
27、进一步的,运用对比学习损失函数,该损失函数旨在最小化同一病患的不同模态特征之间的距离,并最大化与其他病患的特征之间的距离;能够促进模型学习到同一病患的特征在特征空间中的相似性和差异性,即,
28、
29、
30、
31、式中,xi和yi分别代表第i对时序数据和文本数据归一化后特征,使用余弦相似度来度量样本特征间的距离,并且使用类似softmax的处理得到其相对距离;
32、其中n是batch的大小,σ表示温度系数,σ是对相似度度量进行缩放的因子;通过将相似度值除以温度系数,可以调整损失函数的形状和敏感度。
33、进一步的,多标签分类损失函数,损失函数公式如下所示;
34、
35、多标签分类损失函数能够处理样本同时属于多个类别的情况,并对心血管疾病进行准确的分型预测;
36、在对比学习损失函数和多标签分类损失函数中,引入放缩因子β,用于控制梯度下降过程中两个损失函数对梯度大小的影响权重;通过调整β的取值,可以平衡对比学习损失和多标签分类损失之间的重要性;较大的β值会加强对比学习损失的影响,而较小的β值则会增加多标签分类损失的权重。
37、本发明的有益效果是:
38、本发明基于医疗大数据中的体征数据和文本报告数据,充分利用信息,更加全面地评估病人患有心血管疾病的风险;同时对预测为患有心血管疾病的病人,进一步对其所患亚型进行预测。
39、本发明基于医学数据集,复现了多个疾病预测领域内的方法模型,我们提出的多模态模型tetra性能与msmn相比在p@1、r@1两个重要指标上分别高出0.29和0.91个百分点,心血管疾病分型预测准确率更高。
40、本发明提出的模型是多模态模型,充分利用了医学数据集中的各类数据,在特征提取方面做得更好。
- 还没有人留言评论。精彩留言会获得点赞!