一种医学影像报告的生成方法及装置
本申请涉及医学领域,尤其涉及一种医学影像报告的生成方法及装置。
背景技术:
1、随着医学技术的发展,医学影像技术的快速发展大大提高了医疗水平,医生可以通过各种医学影像设备对人体进行扫描,根据医学影像视图生成医学放射学影像报告,医学影像报告已成为病情诊断的重要依据之一。
2、现有技术中在使用卷积神经网络提取医学影像特征时,欠缺融合高级语义信息的能力。因此,使用卷积神经网络提取图像特征用于报告生成,缺少了高级语义特征,由于视觉和文本模态天然的语义鸿沟,在生成医学影像报告时,缺乏语言表达的灵活性,并会导致医学影像报告准度低。
技术实现思路
1、本申请实施例提供了一种医学影像报告的生成方法及装置,可以使医学影像报告的语言表达具有灵活性,提高医学影像报告的准度。
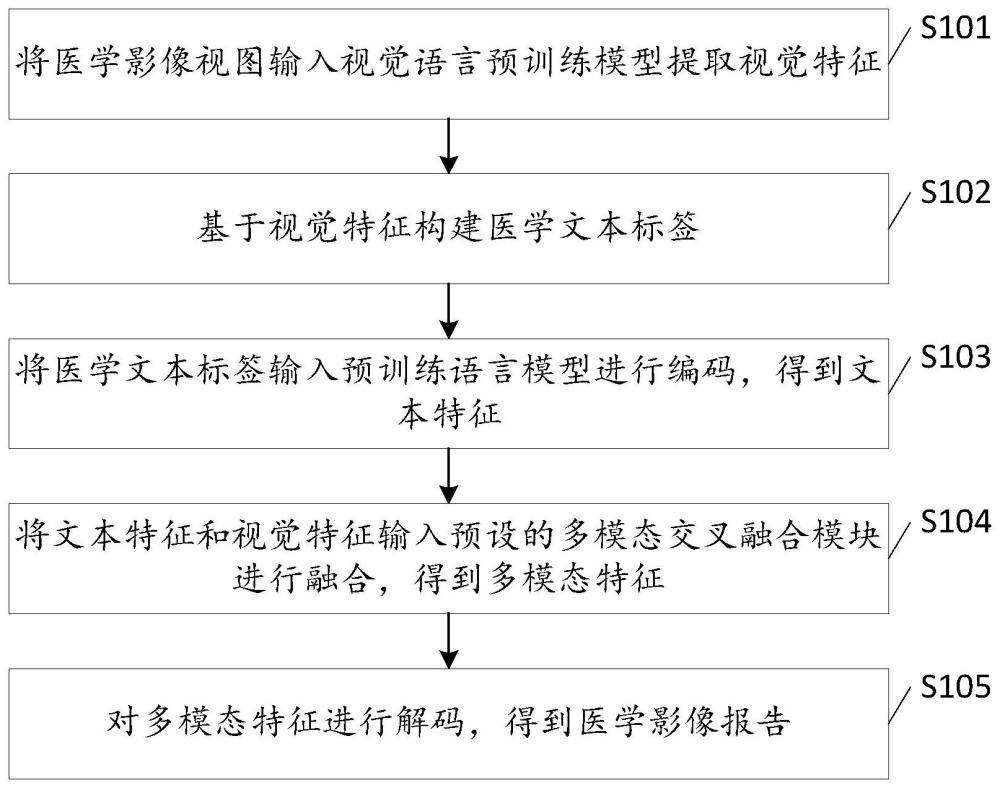
2、本申请第一方面提供了一种医学影像报告的生成方法,包括:
3、将医学影像视图输入视觉语言预训练模型提取视觉特征;
4、基于所述视觉特征构建医学文本标签;
5、将所述医学文本标签输入预训练语言模型进行编码,得到文本特征;
6、将所述文本特征和所述视觉特征输入预设的多模态交叉融合模块进行融合,得到多模态特征:
7、对所述多模态特征进行解码,得到医学影像报告。
8、可选地,所述基于所述视觉特征构建医学文本标签,包括:
9、基于所述视觉特征进行医学分类任务,得到分类结果;
10、根据所述分类结果诊断病灶,得到疾病关键词;
11、根据所述疾病关键词构建所述医学文本标签。
12、可选地,所述通过预设的多模态交叉融合模块将文本特征和视觉特征进行融合前,所述方法,还包括:
13、将所述文本特征和所述视觉特征通过线性投影层映射到多模态特征空间,得到特征维度相同的映射后的文本特征和映射后的视觉特征;
14、将所述映射后的文本特征和所述映射后的视觉特征作为源序列输入所述多模态交叉融合模块。
15、可选地,所述通过预设的多模态交叉融合模将文本特征和视觉特征进行融合,得到多模态特征,包括:
16、通过多模态交叉融合模块将所述映射后的视觉特征与与所述映射后的文本特征对齐,得到融合后的特征;
17、采用前馈神经网络对所述融合后的特征进行额外处理,得到处理后的特征;
18、利用残差连接和层归一化,基于所述处理后的特征生成所述多模态特征。
19、可选地,所述对所述多模态特征进行解码,得到医学影像报告,包括:
20、将所述多模态特征作为输入解码器的隐状态,通过所述解码器对所述隐状态进行解码,得到所述医学影像报告。
21、本申请第二方面提供了一种医学影像报告的生成装置,包括:
22、提取单元,用于将医学影像视图输入视觉语言预训练模型提取视觉特征;
23、构建单元,用于基于所述视觉特征构建医学文本标签;
24、编码单元,用于将所述医学文本标签输入预训练语言模型进行编码,得到文本特征;
25、融合单元,用于将所述文本特征和所述视觉特征输入预设的多模态交叉融合模块进行融合,得到多模态特征:
26、生成单元,用于对所述多模态特征进行解码,生成医学影像报告。
27、可选地,所述构建单元,具体用于:
28、基于所述视觉特征进行医学分类任务,得到分类结果;
29、根据所述分类结果诊断病灶,得到疾病关键词;
30、根据所述疾病关键词构建所述医学文本标签。
31、可选地,所述装置,还包括:
32、映射单元,用于将所述文本特征和所述视觉特征通过线性投影层映射到多模态特征空间,得到特征维度相同的映射后的文本特征和映射后的视觉特征;将所述映射后的文本特征和所述映射后的视觉特征作为源序列输入所述多模态交叉融合模块。
33、可选地,所述融合单元,具体用于:
34、通过多模态交叉融合模块将所述映射后的视觉特征与与所述映射后的文本特征对齐,得到融合后的特征;
35、采用前馈神经网络对所述融合后的特征进行额外处理,得到处理后的特征;
36、利用残差连接和层归一化,基于所述处理后的特征生成所述多模态特征。
37、可选地,所述生成单元,具体用于:
38、将所述多模态特征作为输入解码器的隐状态,通过所述解码器对所述隐状态进行解码,得到所述医学影像报告。
39、本申请实施例公开了一种医学影像报告的生成方法及装置。在该方法中,将医学影像视图输入视觉语言预训练模型提取视觉特征;基于视觉特征构建医学文本标签;将医学文本标签输入预训练语言模型进行编码,得到文本特征;将文本特征和视觉特征输入预设的多模态交叉融合模块进行融合,得到多模态特征:对多模态特征进行解码,得到医学影像报告。由此可见,利用本申请实施例提供的方案,采用多模态预训练模型提取视觉特征,实现高级语义信息的捕捉,从而提高医学影像报告的准度;采用预训练语言模型对医学文本标签进行编码,能够提供医学影像报告中医学术语的充实性和准确度;采用多模态交叉融合模块弥补特征间差异,从而提高生成的医学影像报告的质量。
技术特征:
1.一种医学影像报告的生成方法,其特征在于,所述方法包括:
2.根据权利要求1所述的方法,其特征在于,所述基于所述视觉特征构建医学文本标签,包括:
3.根据权利要求1所述的方法,其特征在于,所述通过预设的多模态交叉融合模块将文本特征和视觉特征进行融合前,所述方法,还包括:
4.根据权利要求3所述的方法,其特征在于,所述通过预设的多模态交叉融合模将文本特征和视觉特征进行融合,得到多模态特征,包括:
5.根据权利要求1所述的方法,其特征在于,所述对所述多模态特征进行解码,得到医学影像报告,包括:
6.一种医学影像报告的生成装置,其特征在于,所述装置包括:
7.根据权利要求6所述的方法,其特征在于,所述构建单元,具体用于:
8.根据权利要求6所述的方法,其特征在于,所述装置,还包括:
9.根据权利要求8所述的方法,其特征在于,所述融合单元,具体用于:
10.根据权利要求6所述的方法,其特征在于,所述生成单元,具体用于:
技术总结
本申请实施例公开了一种医学影像报告的生成方法及装置。在该方法中,将医学影像视图输入视觉语言预训练模型提取视觉特征;基于视觉特征构建医学文本标签;将医学文本标签输入预训练语言模型进行编码,得到文本特征;将文本特征和视觉特征输入预设的多模态交叉融合模块进行融合,得到多模态特征:对多模态特征进行解码,得到医学影像报告。由此可见,利用本申请实施例提供的方案,采用多模态预训练模型提取视觉特征,实现高级语义信息的捕捉,从而提高医学影像报告的准度;采用预训练语言模型对医学文本标签进行编码,能够提供医学影像报告中医学术语的充实性和准确度;采用多模态交叉融合模块弥补特征间差异,从而提高生成的医学影像报告的质量。
技术研发人员:余龙龙,曲昭伟,王晓茹,马晨阳,邓博文,刘明时,李梅芳,卞德昕
受保护的技术使用者:北京邮电大学
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!