一种神经康复训练装置
本发明涉及神经系统康复,具体是指一种神经康复训练装置。
背景技术:
1、一种神经康复训练装置旨在为患有神经功能障碍的患者提供个性化、实时的康复训练,促进康复进展,有望在康复医学领域产生积极的影响,传统的神经康复训练装置存在因特征提取方法的不足导致对语义信息的理解不准确的问题,进一步导致装置无法正确识别和解释患者的动作或意图,从而影响康复训练的效果;传统的神经康复训练装置需要较长时间才能达到理想效果,患者可能需要更多的时间来完成康复训练,同时训练装置的性能在不同的训练迭代中出现波动,使得康复训练的效果不一致或不可预测。
技术实现思路
1、针对上述情况,为克服现有技术的缺陷,本发明提供了一种神经康复训练装置,针对传统的神经康复训练装置存在因特征提取方法的不足导致对语义信息的理解不准确的问题,本方案通过采用多尺度特征提取和融合方法对图像特征表征和文本信息表示部分进行特征提取,提供更全面、鲁棒和语义丰富的特征表示,从而提高模型的性能和表达能力;针对传统的神经康复训练装置需要较长时间才能达到理想效果,患者可能需要更多的时间来完成康复训练,同时训练装置的性能在不同的训练迭代中出现波动,使得康复训练的效果不一致或不可预测,本方案通过计算和选择不同特征组合,选择最具代表性的特征,提高特征的准确度和表达能力,并对人体姿态进行补偿,使结构更准确可靠;针对一般的标注方法存在考虑因素过多导致算法复杂度过高而运行效率低,考虑因素过少导致对人体姿态标注的准确率低而影响后续的评估及预警的矛盾性问题,本方案使用具有统一动量的加权adagrad算法调整训练样本的学习率和参数更新策略,提高算法的稳定性和收敛速度,并且通过自适应地调整学习率,更好地适应不同特征的梯度分布情况,提高了泛化性能。
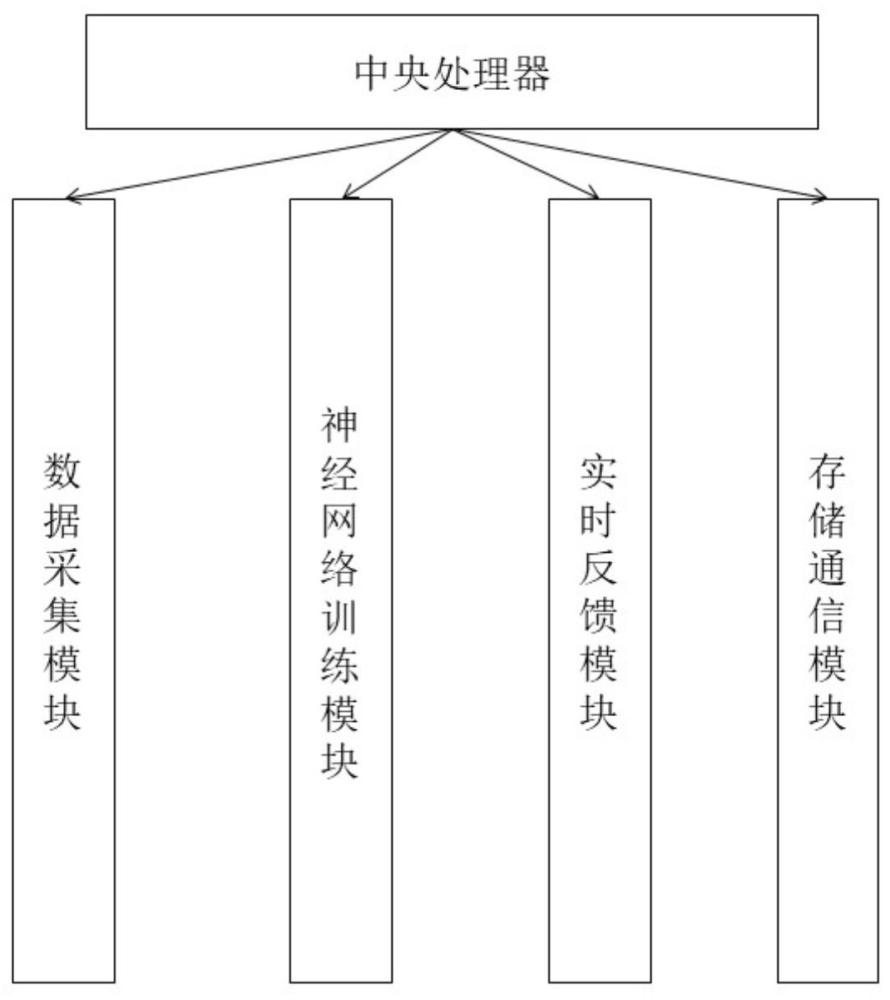
2、本发明采取的技术方案如下:本发明提供的一种神经康复训练装置,该装置包括主机、数据采集贴片和训练贴片,数据采集贴片和主机电性连接,主机和训练贴片电性连接,主机内部设有中央处理器,中央处理器包括数据采集模块、神经网络训练模块、实时反馈模块和存储通信模块,数据采集模块通过数据采集贴片采集康复目标的数据,实时反馈模块通过训练贴片执行训练操作,并根据神经网络训练模块的输出提供实时的反馈信号给康复目标,存储通信模块用于存储和传输数据采集模块采集到的康复目标的数据,神经网络训练模块使用构建神经网络的方法,所述方法包括以下步骤:
3、步骤s1:数据采集,收集数据采集模块采集到的康复目标的数据,包括患者的运动数据、脑电图数据、生理数据、神经影像数据;
4、步骤s2:数据预处理,对采集到的康复目标的数据进行预处理,包括数据清洗、去除噪声和标准化操作,得到预处理后的数据;
5、步骤s3:特征提取,从预处理后的数据中提取有用的特征,采用多尺度特征提取和融合方法对图像特征表征部分和文本信息表示部分进行特征提取;
6、步骤s4:神经网络设计,选择lstm网络进行设计,构建lstm模型;
7、步骤s5:训练与优化,使用步骤s2中预处理后的数据对神经网络进行训练,将预处理后的数据分为训练集、验证集和测试集,并使用适当的优化算法来更新神经网络的权重和偏置。
8、进一步的,在步骤s3中,采用多尺度特征提取和融合方法对图像特征表征部分进行特征提取,具体包括以下步骤:
9、步骤 k11:使用高斯滤波器对图像进行平滑处理后,进行下采样,得到不同尺度的图像数据;
10、步骤 k12:构建金字塔模型;
11、步骤 k13:在图像数据的每个尺度上,使用图像数据特征提取方法来提取特征,包括sift、hog和lbp;
12、步骤 k14:将上述提取到的特征在不同尺度上进行融合,形成一个综合的多尺度特征表示;
13、进一步的,在步骤 s3中,采用多尺度特征提取和融合方法对文本信息表示部分进行特征提取,具体包括以下步骤:
14、步骤 k21:使用文本特征提取方法提取文本特征,包括词袋模型、tf-idf、word2vec和bert;
15、步骤 k22:将从不同方法提取的文本特征进行融合。
16、进一步地,在步骤s4中,选择lstm网络进行设计,构建lstm模型,具体包括以下步骤;
17、步骤s41:设置网络层数,lstm网络包含多个堆叠的lstm层,包含数据输入层、多个堆叠的lstm层、全连接层和输出层,具体包括以下内容:
18、数据输入层:定义神经康复训练装置的输入数据为训练样本,其中包括运动序列数据,将输入的数据序列称为输入序列,根据输入序列生成的预测序列为输出序列;
19、lstm层:康复神经网络的核心部分,学习和记忆运动序列中的长期依赖关系,设置多个堆叠的lstm层增加网络的深度;
20、全连接层:将lstm层的输出映射到康复任务的标签或预测结果;
21、输出层:输出康复任务的预测结果;
22、步骤s42:设置lstm模型的单元数量,每个lstm层由多个lstm单元组成,lstm模型的单元的数量决定了网络的容量和记忆能力;
23、步骤s43:确定训练样本的输入和输出维度,设置输入序列的长度和特征维度,以及输出序列的长度和目标维度;
24、步骤s44:确定激活函数,选择tanh激活函数对于lstm单元的门控和状态进行更新操作;
25、步骤s45:确定损失函数,选择均方误差函数和交叉熵损失函数衡量lstm模型预测值与真实值之间的差异,具体包括以下内容:
26、对于回归任务,即预测连续值,包括运动轨迹、肌肉活动,使用均方误差函数作为损失函数,均方误差函数衡量了预测值与真实值之间的差异的平方,并求取平均值,通过最小化均方误差,使lstm模型准确的拟合训练数据;
27、对于分类任务,即预测离散的类别,包括动作识别、病情评估,则使用交叉熵损失函数作为损失函数,交叉熵损失衡量预测类别与真实类别之间的差异,通过最小化交叉熵损失,使lstm学习类别之间的区分特征;
28、步骤s46:选择优化算法,使用具有统一动量的加权adagrad算法调整训练样本的学习率和参数更新策略;
29、进一步的,在步骤s46中,使用具有统一动量的加权adagrad算法,具体包括以下步骤:
30、步骤s461:初始化参数,设置学习率、统一动量因子和初始权重向量,并设置初始梯度累计平方和为0;
31、步骤s462:定义每一个训练样本为(),计算预测值,所用公式如下:
32、;
33、其中,为lstm的预测函数;
34、步骤s463计算损失函数的梯度,所用公式如下:
35、;
36、其中,是损失函数;
37、步骤s464:更新梯度累积平方和,所用公式如下:
38、;
39、步骤s465计算学习率调整因子,所用公式如下:
40、;
41、其中,取le-8,用于避免除0;
42、步骤s466:更新权重向量,所用公式如下:
43、;
44、步骤s467:重复步骤s462至步骤s466,直至损失函数收敛;
45、步骤s47:正则化,使用l2正则化技术防止过拟合。
46、采用上述方案本发明取得的有益效果如下:
47、(1)针对一般的特征提取方法存在受限于特定任务和缺乏鲁棒性,在在语义理解、通用性、鲁棒性和上下文信息捕捉等方面都存在一些不足,本方案通过图像特征表征和文本信息表示部分分别采用多尺度特征提取和融合方法,捕捉多尺度信息、提高鲁棒性、提升分类性能、增强语义表征,多尺度特征提取和融合方法在图像和文本领域中提供更全面、鲁棒和语义丰富的特征表示,从而提高模型的性能和表达能力。
48、(2)针对一般的adagrad算法存在在训练初期可能会过度关注稀疏特征的更新,导致收敛速度变慢的问题,本方案使用具有统一动量的加权adagrad算法调整训练样本的学习率和参数更新策略,提高算法的稳定性和收敛速度,并且通过自适应地调整学习率,更好地适应不同特征的梯度分布情况,提高了泛化性能。
- 还没有人留言评论。精彩留言会获得点赞!