一种基于机器学习的甲状腺疾病分类预测方法
本发明涉及医疗预测,具体涉及一种基于机器学习的甲状腺疾病分类预测方法。
背景技术:
1、甲状腺功能紊乱是一系列涉及甲状腺激素水平异常的疾病,其对人体健康可能带来严重影响。甲状腺功能亢进(甲亢)和甲状腺功能减退(甲减)是最常见的两种情况。甲亢会导致身体新陈代谢过快,可能引发心跳加快、体重下降、焦虑、多汗等症状。而甲减则使代谢率下降,可能出现体重增加、疲劳、皮肤干燥、情绪低落等表现。此外,亚临床甲状腺功能异常是一种较为隐匿的状态,表现为甲状腺激素水平轻微偏离正常范围,但尚未出现典型的甲亢或甲减症。尽管症状不太明显,但却可能对患者心血管健康、骨质密度以及生活质量产生一定影响。
2、现有的甲状腺疾病分类研究,大多的accuracy较低(低于0.95),模型效果较差;并且部分研究所用的数据量非常小(500以下),即使能达到较高的评估分数,但由于数据量小、且未经过独立验证,因此其模型的评估不具有说服力。此外,还有一部分效果较好的模型,采用了大量的指标进行预测,成本较高。
3、此外,在甲状腺疾病的分类预测过程中,ft3、ft4和tsh三种物质的血液含量对判断分类结果具有显著影响,然而目前临床使用的这三种物质的参考体系相对陈旧,未能提供足够精确的判断依据。
技术实现思路
1、针对现有技术中的上述不足,本发明提供了一种基于机器学习的甲状腺疾病分类预测方法。
2、为了达到上述发明目的,本发明采用的技术方案为:
3、一种基于机器学习的甲状腺疾病分类预测方法,包括如下步骤:
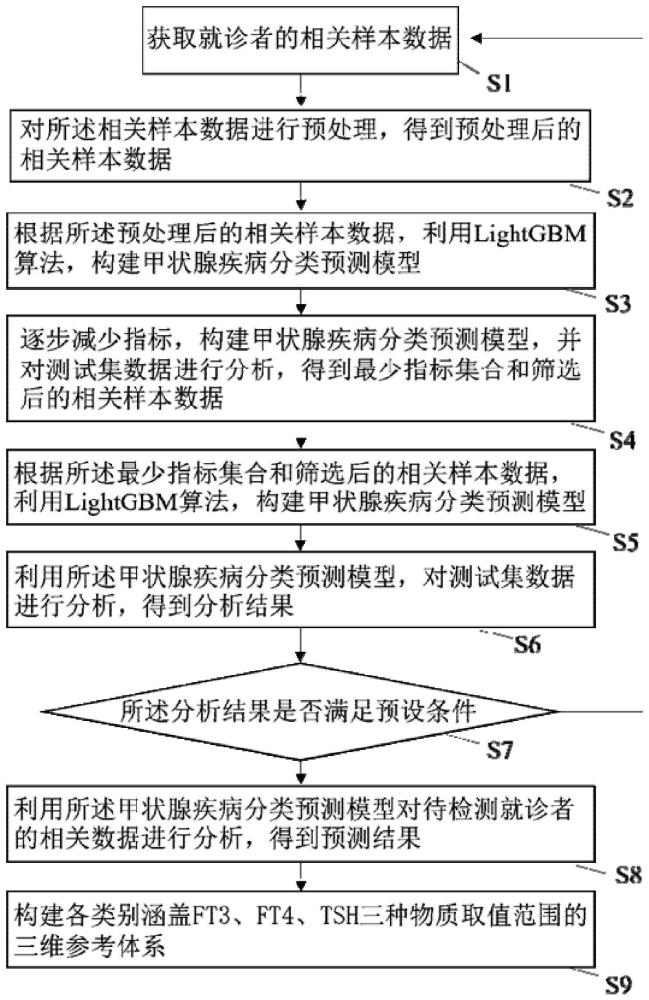
4、s1:获取就诊者的相关样本数据;
5、s2:对所述相关样本数据进行预处理,得到预处理后的相关样本数据;
6、s3:根据所述预处理后的相关样本数据,利用lightgbm算法,构建甲状腺疾病分类预测模型;
7、s4:逐步减少指标,构建甲状腺疾病分类预测模型,并对测试集数据进行分析,得到最少指标集合和筛选后的相关样本数据;
8、s5:根据所述最少指标集合和筛选后的相关样本数据,利用lightgbm算法,构建甲状腺疾病分类预测模型;
9、s6:利用所述甲状腺疾病分类预测模型对测试集数据进行分析,得到分析结果;
10、s7:判断所述分析结果是否满足预设条件,若是,进入步骤s8,否则,返回步骤s1;
11、s8:利用所述甲状腺疾病分类预测模型对待检测就诊者的相关数据进行分析,得到预测结果;
12、s9:构建各类别涵盖ft3、ft4、tsh三种物质取值范围的三维参考体系。
13、进一步的,所述步骤s2包括:
14、s21:对所述相关样本数据进行数据清洗及整理,得到诊疗数据;
15、s22:利用smote算法对所述诊疗数据进行过采样,得到过采样后的诊疗数据;
16、s23:利用方差阈值法对所述诊疗数据的连续型指标进行筛选,得到筛选后的连续型指标数据;
17、s24:利用kruskal-wallis检验对所述诊疗数据的连续型指标进行筛选,得到存在类间显著差异的连续型指标数据;
18、s25:利用卡方检验对所述诊疗数据的分类型指标进行筛选,得到与类别显著相关的分类型指标数据,并与所述筛选后的连续型指标数据进行合并,得到筛选后的指标数据;
19、s26:利用互信息得分引入与甲状腺疾病分类预测具有较高相关性的指标数据。
20、进一步的,所述步骤s21包括:
21、s211:对所述相关样本数据中的逻辑判断对结果显然无影响的列、缺失值超过50%的列进行删除操作,得到删除后的相关样本数据;
22、s212:将所述删除后的相关样本数据中的分类型特征转换为数值型表示,得到转换后的相关样本数据;
23、s213:对所述转换后的相关样本数据,利用同类别样本数据的中位数填充缺失值,得到诊疗数据。
24、进一步的,所述步骤s22包括:
25、s221:将所述诊疗数据输入至smote算法中,根据当前smote算法的k_neighbors参数,生成新的合成样本,增加少数类样本的数量;
26、s222:随机抽样检查合成样本是否满足临床经验的判断结果,若是,则输出合成后的相关样本数据;否则,逐步调整smote算法的k_neighbors参数,并返回步骤s221。
27、进一步的,所述步骤s23包括:
28、s231:计算所述诊疗数据的连续型指标中的当前指标的方差;
29、s232:判断所述方差是否小于预设阈值,若是,删除所述诊疗数据的连续型指标中的当前指标,否则,保留所述诊疗数据的连续型指标中的当前指标,得到筛选后的连续型指标数据。
30、进一步的,所述步骤s26包括:
31、s261:计算所述筛选后的指标数据与类别标签间的互信息得分,并将结果降序排列;
32、针对连续型变量,互信息的计算公式为:
33、
34、针对分类型变量,互信息的计算公式为:
35、
36、s262:选择排名靠前的m个指标数据,m为预设的指标阈值,以作为所述预处理后的相关样本数据输出。
37、进一步的,所述步骤s4包括:
38、s41:利用lightgbm算法所述预处理后的相关样本数据进行训练,得到甲状腺疾病分类预测模型;
39、s42:利用所述甲状腺疾病分类预测模型对测试集数据进行分析,得到分析结果;
40、s43:判断所述分析结果是否满足预设条件,若是,删除现有指标中互信息得分最低的指标,得到筛选后的指标数据,进而得到相应处理后的相关样本数据,重新进入步骤s41,否则,保留上一步删除的指标数据,剔除现有剩余指标中互信息得分次低的指标,得到筛选后的指标数据,进而得到相应处理后的相关样本数据,重新进入步骤s41直至剩余指标均为需要保留的指标数据,即为所述的最少指标集合,并得到由最少指标集合筛选后的相关样本数据。
41、进一步的,所述步骤s9包括:
42、s91:利用排序统计量方法,调整百分位数位置,对样本数据中ft3、ft4、tsh三种物质的取值范围进行估计,构建三维参考体系;
43、s92:利用核密度估计方法和高斯混合模型拟合方法,,调整高密度概率区域的筛选阈值,利用样本数据中ft3、ft4、tsh三种物质的取值范围估计总体,构建三维参考体系;
44、s93:利用测试集数据检验所述的三维参考体系,判断检验结果是否满足预设条件,若是,进入步骤s95,否则,逐步调整各方法关键参数的数值,并返回步骤s91;
45、s94:比较测试集数据在各方法得出的三维参考体系的区间概率,分别选择ft3、ft4、tsh的最佳参考体系。
46、进一步的,所述步骤s91包括:
47、s911:对筛选后的样本数据按照标签分类,并在类内进行排序;
48、s912:设定百分位数位置为2.5%和97.5%,在排序后的样本数据中确定所述位置,构建ft3、ft4、tsh的95%置信区间。
49、10.根据权利要求1所述的基于机器学习的甲状腺疾病分类预测方法,其特征在于,所述步骤s92包括:
50、s921:对筛选后的样本数据按照标签分类,利用核密度估计方法及高斯混合模型分别对各类别的ft3、ft4、tsh分别计算其概率密度估计;
51、s922:设定高密度概率区域的筛选阈值,得到筛选后的高密度概率区域,即为ft3、ft4、tsh的三维参考体系。
52、本发明具有以下有益效果:
53、(1)本发明基于就诊者的基本信息、血液检测和生化指标及甲状腺功能指标对甲状腺疾病类别进行预测,在数据上具有创新性,所建立的预测模型能够为甲状腺疾病预测结果提供准确的更多的数据支持,本发明具有智能化、预测精度高的优点。
54、(2)本发明将预测所用变量筛选到2个,显著地降低了获取相关指标的成本。
55、(3)本发明利用smote算法,一定程度上解决了数据类别不平衡所带来的模型训练误差,提高了模型训练的精确度。
- 还没有人留言评论。精彩留言会获得点赞!