一种快速批量可自动下载高通量测序数据的方法、数据下载系统及应用与流程
本发明属于高通量测序,涉及一种快速批量可自动下载高通量测序数据的方法、数据下载系统及其应用。
背景技术:
1、高通量测序又称“下一代测序”,是对传统测序的一次变革,与传统的一代sanger测序相比,新一代测序技术的通量提高了一到两个数量级,能够经济地对基因组/转录组进行高倍率的序列覆盖。随着高通量测序仪器的性能的逐渐稳定和价格的不断下降,其应用也越来越广泛,因此基于高通量测序数据的研究将会在数量上和应用上呈现井喷式的快速发展趋势。
2、由于高通量测序产出的数据量很大,单个文件大小从几m到几十g不等;数据下载一般是由人工操作,并受下机数据的完成时间限制,人工并不总能及时的介入做下载操作,这就导致数据下载的过程耗费相当长的时间,并且需要人为监控,消耗了大量的人工参与其中。因此高通量测速数据高效、顺畅的下载是必须的关键步骤之一。
3、由于高通量测序数据具有数据量大,样本数多等特点,所以对应于高通量测序数据的下载,必须具有多样本批量处理、单样本下载顺畅、实时监测单样本的数据下载状态、快速反馈多样本的数据下载汇总信息等特点。目前常规的数据下载方法是借助通用的数据下载工具人工处理,只能一批一批的处理,大样本量的高通量测序数据下载可能需要几个小时到几天不等,人工不好监控下载状态,且不能对下载结果做出快速准确的反馈,没有任务监控机制,使高通量测序数据的下载成为相关研究中的一大瓶颈。
4、现有高通量测序数据下载流程在如下缺陷:(1)流程处理效率低:从接收到流程到最终下载完成中间可能会存在大段的空白等待期;(2)不能批量处理样本:每次只能进行单批样本的下载操作,不能同时对多批样本做处理;(3)下载结果反馈不及时:流程跑完需要人工核对,不能及时做邮件反馈;(4)无错误检测机制:没有单样本是否下载完成/成功的检测机制;(5)无实时监控机制:不能对数据下载的状态做实时监控,只能人工核对。
技术实现思路
1、为了解决现有技术存在的不足,本发明的目的是提供一种基于snakemake语言和mysql数据库快速批量可自动下载高通量测序数据的方法、数据下载系统及应用。
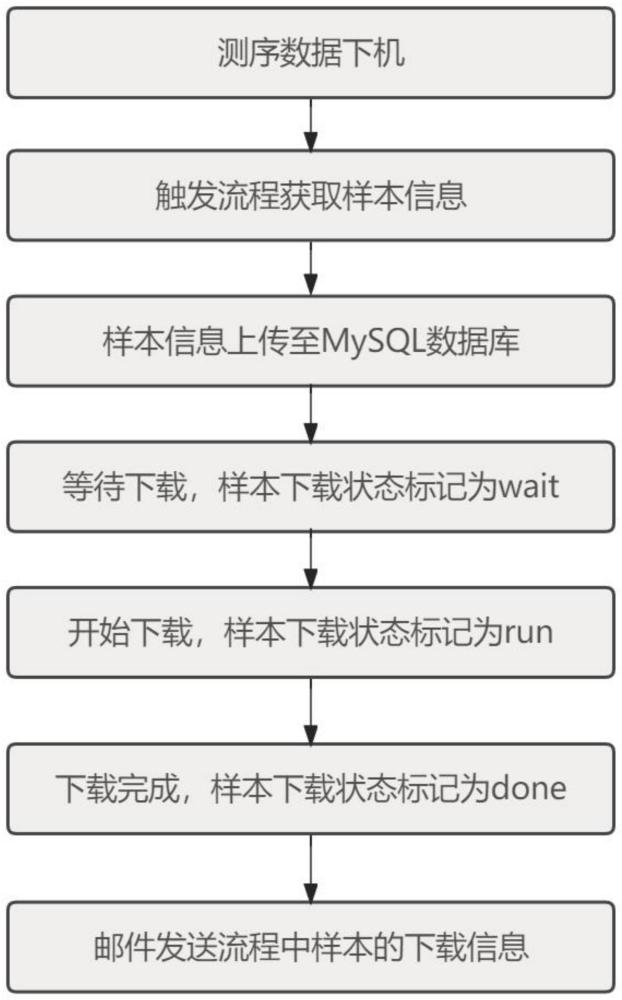
2、所述方法具体包括如下步骤:
3、步骤一、流程触发:
4、第一次启动python脚本立刻检索第一次启动开始时间至前4个小时内流程中录入样本下机数据库中的下机样本信息,同时记录第一次启动开始时间t0。
5、此外,挂载在服务器后台的python脚本还会根据预设的时间间隔,在每个运行周期中对流程状态进行扫描,当识别到新的高通量测序数据下机流程后,录入样本下机数据库中的下机样本信息,同时记录本次启动开始时间tn,同时还会自动触发将样本信息同步至数据库的任务;所述每个运行周期是指从前一次启动开始时间tn-1到本次启动开始时间tn,无前一次启动开始时间tn-1时,则获取本次启动开始时间tn至前4个小时;
6、步骤二、抓取流程中的样本信息:
7、使用python脚本抓取步骤一从样本下机数据库中获取的新下机样本信息,每个样本信息都包括:下机名称、分析名称、项目编号,项目类型、服务名称,下载路径等。
8、所述下机名称是指样本在送测时的名称;
9、所述分析名称是指样本在分析时的名称;
10、所述项目编号是指样本对应的项目编号;
11、所述项目类型是指样本项目编号对应的类型(与后续分析调用的流程对应,例如字典中记录全转录组测序:全转录组测序git,通过字典明确后续分析使用的流程,通过流程中的设定获取流程预计消耗的cpu及mem,获取当前运行节点(多个节点)实时cpu和mem判断后续下载路径和分析路径);
12、所述服务名称是指样本项目编号对应的服务名称(与该项目签订的合同相关);
13、所述下载路径是指合作方提供的该样本对应的下载地址(一般仅提供到目录层级);
14、将抓取获得的下机样本信息实例化为项目,以项目为单位,获取对应的项目类型,多个节点实时的cpu及mem信息,判断后续进行下载分析的节点路径。
15、步骤三、上传样本信息至mysql数据库:
16、将步骤二中抓取的样本信息整理成固定表格的形式,使用python连接mysql数据库,在触发数据库同步任务后,将整理好的样本信息以表格的形式上传到mysql数据库中,并通过python脚本标记下载状态为等待下载wait;所述表格为自建表格,根据实际科研生产流程中的需求,确定表格中需要包含的信息。
17、所述mysql数据库中包括2张表格:rawdata表格和projects_download表格,rawdata表格用于记录已下机数据信息以及样本下载状态,表头包括序号、样本、项目分析目录、样本下载数据路径、下载命令、下载状态等,projects_download表格用于记录项目相关信息,表头包括项目分析目录、运行状态信息记录文件、下载开始时间、下载结束时间、完工时间、删除状态等。
18、步骤四、自动下载数据库中标记为wait的样本:
19、流程中设定的自动下载任务以固定时间间隔循环扫描一次数据库,当扫描到mysql数据库中的样本信息的状态为wait时,则自动触发该样本的自动下载;所述固定时间间隔可以根据实际需要设定,一般可以设置为每30min扫描一次;
20、根据样本下机信息中的下载路径生成对应的下载命令,更新至数据库,通过snakemake流程投递命令行,使用镜像实现同时调用不同下载工具进行下载,并且不产生冲突,最大可同时容纳10个下载命令并行运行。在此步骤中,针对一些需要特殊处理的样本,如需要进行拆分的样本,可通过识别数据库中对应的‘需要拆分’(yes或no)字段来生成对应的拆分代码进行snakemake投递拆分;所述镜像是指不同的下载命令运行环境,具体包含了传输数据软件和进行数据预处理拆分后的多个python环境。
21、步骤五、修改数据库中下载开始后的样本状态:
22、在触发样本下载的同时python脚本通过sql语句将数据库中对应的已触发下载的样本的下载状态修改为run。
23、步骤六、修改下载完成的样本在数据库中的状态
24、样本的高通量测序数据下载任务完成后python脚本连接mysql数据库并将该样本的下载状态改为done,并等待触发后续的分析。
25、步骤七、发送归并、下载的汇总邮件:
26、当某一个操作流程中的所有样本都下载完成后,python脚本自动的将本次样本归并、下载的状态汇总邮件发给任务监控人,汇总信息包括:样本数量,下载消耗时间、下载数据所占用的存储等。
27、步骤八、一次步骤二至步骤七的循环结束后,暂停30秒启动下一次循环,下一循环的起始时间为tn,读取上一次的启动开始时间tn-1,查询tn-1至tn时间内录入样本下机数据库中的下机样本信息,若该时间段无新录入信息,则不记录tn,若该时间段内有新录入数据,则更新tn-1为tn,以此类推。
28、样本数据下载完成后,可以用于后续对样本数据的分析,项目分析完毕后上传完工时间信息至数据库,识别到完工信息后删除已完工项目的样本数据。
29、在本发明的一个优选实施例中,所述流程触发通过python脚本监控流程状态全程自动化无需人工介入。
30、在本发明的一个优选实施例中,上传样本信息至mysql数据库使用python脚本连接数据,并将汇总好的流程中样本信息同步至数据库。
31、本发明还提供了上述方法在高通量测序数据下载中的应用。
32、本发明还提供了一种实现上述快速批量可自动下载高通量测序数据的方法的数据下载系统,所述数据下载系统包括:实例化样本和项目属性调用模块、下载核查模块、下载实施模块、样本信息获取模块、下载复核模块、邮件发送模块、日志生成模块;
33、所述实例化样本和项目属性调用模块通过sample功能和project功能实现,sample,project分别为实例化样本和项目属性,更方便快捷的在整个流程中调用需要的属性,通过多进程(concurrent.futures.threadpoolexecutor)加快循环周期;
34、所述下载核查模块通过check功能实现,在流程中核查样本下载状况;
35、所述下载实施模块通过deliver功能实现,在流程中生成下载命令并投递snakemake进行下载;
36、所述样本信息获取模块通过organize功能实现,在流程中获取样本下机信息并规范其数据内容和类型;
37、所述下载复核模块通过download_check功能实现,在流程中每隔固定时间间隔(例如24小时)遍历一遍样本下机数据库和样本下载数据库信息的一致性,防止由于服务器卡顿等原因导致的样本遗漏;
38、所述邮件发送模块通过emailsender功能实现,在流程中发送邮件到对应的负责人,所述邮件发送模块调用时指定不同的收件人和邮件正文;
39、所述日志生成模块通过log功能实现,在流程中输出运行成功或报错log文件,以上模块调用时可以根据当前时间输出到指定路径下‘年-月-日.log’文件中。
40、本发明还提供了上述自动下载高通量测序数据的方法,或上述数据下载系统在高通量测序质控分析、测序仪数据下载传输等有关于数据文件归并整理的场合中的应用,并可灵活判断节点剩余运行资源,使资源得到最大化的运用。
41、本发明的有益效果包括:
42、本发明采用snakemake代码结合mysql数据库对高通量测序数据的归并下载流程进行整合,通过python脚本实时传输信息至mysql数据库,并根据下载任务运行情况包括等待下载、正在下载和下载完成实时的将数据库中样本的下载状态更新为wait、run和done,通过自动化任务保证了流程运行的无缝衔接。利用snakemake镜像投递同时运行多个不同或相同的下载命令,保证下载互不干扰的同时加快了运行效率;同时能够利用多线程对多个流程里的样本进行批量处理,数据下载完毕后基于python包smtplib自动发邮件快速反馈下载汇总信息,结合mysql数据库中的样本下载状态可以快速获取任务运行状态和异常信息。
43、本发明运行的效率高,整个过程包括流程触发、信息上传数据库、数据下载、下载状态更新以及发送汇总文件等等一系列处理都是完全自动化的,无需人为参与。
44、本发明可实时查看项目进度,及时删除已完工数据,无需人工参与,避免误删、删除不及时等情况产生的额外成本。
45、本发明所述各个步骤都是自动触发的,各步骤间没有等待时间,极大的缩短了整个流程的运行周期。
46、本发明所有操作步骤可以溯源,如果数据下载报错或者异常,snakemake会输出对应步骤的报错日志信息,通过查询报错日志信息可以获取样本状态信息。
47、同时,本发明中使用的多流程、多样本的并行下载方法的运行速度比常规的单流程多样本的下载时间缩短了近10倍。
- 还没有人留言评论。精彩留言会获得点赞!