基于Android系统的TalkingAvatar手游软件的构建方法与流程
本发明涉及一种人脸识别、玩偶合成、语音录制及调用、手机屏幕的录制及分享等技术领域。
背景技术:
随着移动技术的迅速发展和使用Android操作系统的手机用户的普及,基于移动端的各类手游软件愈发受到了青睐。一个典型的例子是由Outfit7公司推出的手机宠物类应用游戏“会说话的汤姆猫”,该软件是一只可爱的宠物猫玩偶,它可以在用户触摸玩偶不同的身体部位时做出各种反应,并且可以用滑稽的声音完整地复述用户所说的内容。录制汤姆猫复述用户说话的视频,还可以上传至YouTube、Facebook、Sina微博或者是朋友圈,并通过电子邮件发送给亲友,因此受到各个年龄层次的用户的极大喜爱。但是,由于随着用户群体的变化,此类简单的Talking Avater手游软件已不再能满足不同用户群体的需求,比如:用户希望看见屏幕上和他们互动的不是宠物猫,是用户自己的Talking Avatar形象,或者说是其他的新奇的形象,这样才能更好地适用不同用户的需求;用户也希望把很多的简单实用的软件功能也加入进去,这样可以让一个软件具备多样的功能,也可以减少用户手机内存的占用。
技术实现要素:
发明目的:为了弥补现如今此类手机游戏功能覆盖不够全面的不足,本发明提供一种基于Android系统的Talking Avatar手游软件的构建方法。本发明除了具有上述汤姆猫也具有的功能以外,用户还可以通过点击按钮调用前置摄像头拍照或导入自己手机中的照片,然后系统通过面目识别技术生成一个与用户相似的玩偶形象,该玩偶形象可完成用户指定的一系列动作,生成Avatar。之后通过点击界面的图标按钮在所给的服装造型中挑选出自己喜欢的造型即可完成对Avatar的换装。当用户对着Avatar说出一段话时,它会复述出来这段话,并根据不一样的说话内容做出相应的肢体动作以及丰富的面部表情等。当用户完成对Avatar的录音之后,可以将其复述及其动作进行屏幕录制,点击保存即可保存该段视频文件到本地,用户可在保存对应的保存路径中找到该视频文件,并通过点击分享按钮将其进行分享至朋友圈、微博等社交平台。
技术方案:一种基于Android系统的Talking Avatar手游软件的构建方法,其功能特征主要包括如下方面:
功能1:用户导入一张照片,通过人脸识别,得到用户脸部相应特征点的值,然后生成一个和用户相似的玩偶形象,即Talking Avatar;人脸侦测宽松化了对人脸的要求,可多角度对人脸进行侦测,根据对称映射,补全特征点信息,可检测的范围是以正前方为原点正负45度。获取到特征点信息后,对特征点信息进行人脸比列缩放处理,再应用欧式距离相似度算法,分别计算出与人脸库中的各组像的相似度值,对其进行统一比较,冒泡法抉择最大相似度人脸,即最像脸。获取到相关信息记录,发送到Avatar库,与Avatar库对接,然后选择对应的Avatar人脸,合成玩偶人脸;
功能2:该软件可以根据用户喜好,对Talking Avatar进行换装和背景更换;Talking Avatar手机软件提供多样的服饰和背景,供用户选择;
功能3:Talking Avatar会把用户说的话录下来然后进行复述;实现了语音—文本—语音的语音转换算法;
功能4:Talking Avatar会根据用户说的话,进行识别,得到相应的关键词,如“你、我、他等”当语音中发现这些关键词,玩偶会做出相应的肢体表情动作;KMP关键词提取算法从文本中获得关键词,依据关键词的与动画之间的绑定关系。并动态触发动画,字符库之间与动画库之间实现动态绑定,支持同义触发;
功能5:用户可以根据自己的需求,从某个时候选择开始录制视频,并且在任意的时候停止录制,用户还可以将录制的视频分享到微博、朋友圈、QQ空间等社交平台上。调用了Mob移动分享平台对视频进行录制和合成,之后存储在用户账户中。上传视频之后可以分享到各社交平台,也可以查看视频文件。
本发明使用Eclipse开发工具,实现了一个具有多功能的玩偶形象的手机游戏。对于人脸的合成和识别,使用科大讯飞的人脸特征点获取,然后经过人脸识别—合成机制。人脸识别—合成机制分为三个阶段:训练阶段、识别阶段和选择阶段。训练阶段对人脸进行拟定、测试和收集数据。识别阶段经过人脸相似度算法获取最像脸。选择阶段就是读取参数,选取特定的人脸,最后实现玩偶的人脸合成。对于声音的转换,使用的是语音转换算法,实现语音—文本—语音的语音系统;字符库与动画库之间实现动态绑定,中间由文本触发动画;实现动画与语音的同步播放。对于视频分享,引用了Mob游戏分享平台,进行视频的录制和合成。之后分享在不同的社交平台;也可以查看录制合成的视频文件。
主要实现步骤如下:
步骤1:利用了科大讯飞人脸识别接口的调用,通过用户输入一张照片、或者拍摄一张照片,识别出照片上的人脸,获取照片上人脸上特征点的位置,然后通过人脸相似度算法匹配到我们数据库中相应大小的人的特征,生成玩偶;
步骤2:然后根据用户的选择可以选择用户爱好的服装,进行换装功能;
步骤3:玩偶复述语音及肢体表情动作功能则依赖于科大讯飞语义合成接口和语音听写接口的调用,通过调用接口我们能让玩偶录入用户所说的话,通过识别,再经过KMP、BM算法匹配数据库中的数据,看是否存在关键词,若存在关键字,再复述语音的同时还会做出相应的动作,反之,没有动作,但是还是会有语音的复述;
步骤4:利用Mob游戏分享平台的视频录制接口,调用视频合成、视频录制、视频分享接口,录制一段视频,并且我们可以分享到新浪微博、朋友圈等各大社交平台上。
本发明采用上述技术方案,具有以下有益效果:生成与用户相似的玩偶;能实现语音的录制,并且能实现表情和动作;用户体验得到改善;与好友共同分享自己的玩偶游戏。
附图说明
图1为本发明的体系架构图;
图2为软件的功能框架图;
图3为软件的使用流程图。
具体实施方式
下面结合具体实施例,进一步阐明本发明,应理解这些实施例仅用于说明本发明而不用于限制本发明的范围,在阅读了本发明之后,本领域技术人员对本发明的各种等价形式的修改均落于本申请所附权利要求所限定的范围。
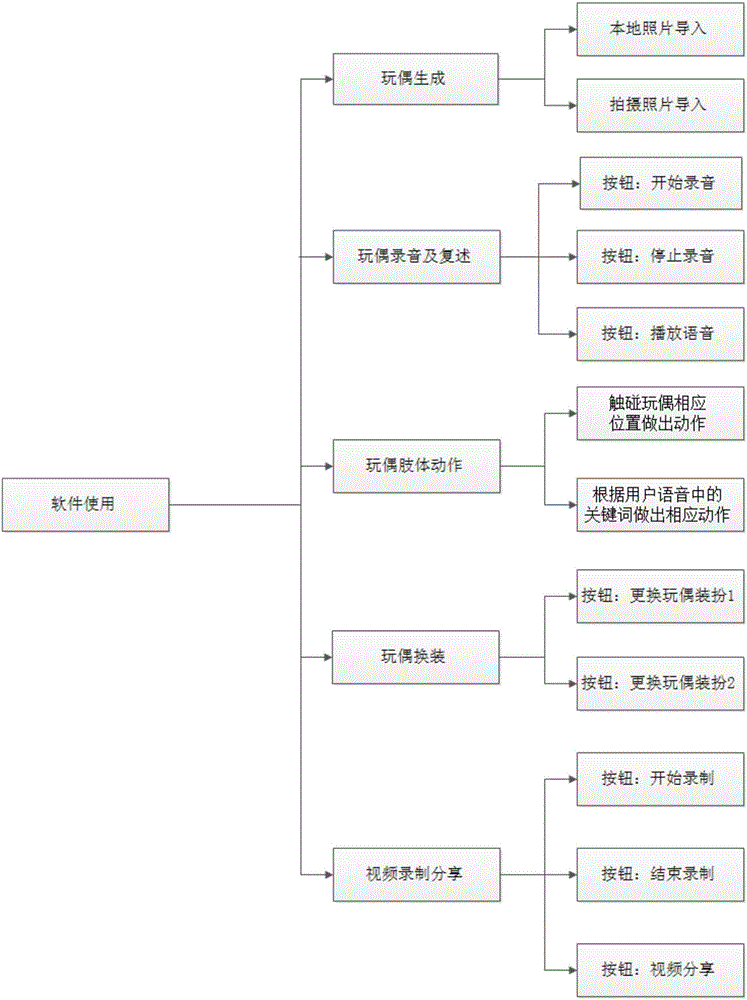
如图2所示,详细介绍了应用的各个模块的具体功能分布,主要分为五个模块:Talking Avatar生成、Talking Avatar录音及复述、Talking Avatar肢体动作、Talking Avatar换装和视频录制分享。
如图3所示,点击进入应用之后进行男女模式的选择,将用户以性别作为区分目的:让用户获得更好的用户体验和更利于资源的管理。进入到不同的模式之中,通过相册导入一张照片,或者调用摄像头接口拍摄照片,经过人脸识别—合成机制合成玩偶形象。还可以根据年龄和地区选择不同的音色,合成比较特色的玩偶,比如广东话、湖南话、老人、小孩等等。人脸识别—合成机制是在讯飞人脸识别和特征点检测的基础上,通过人脸相似度算法,与人脸库中各人脸进行计算,然后冒泡法抉择出最像脸。发送信息到玩偶库,与玩偶库进行对接,匹配玩偶形象。合成玩偶之后,可以根据用户的个人爱好,更换背景和服装。在科大讯飞语音的支持下,用户可以通过文本或者语音两种方式输入信息。玩偶可以播放语音,同时出发相应的肢体表情动作。关于语音实现的是语音转换算法,依赖于科大讯飞语义合成接口和语音听写接口的调用,实现由语音—文本—语音的语音转换,中间文本经再经过KMP、BM算法匹配数据库中的数据,看是否存在关键词,若存在关键字,再复述语音的同时还会做出相应的动作,反之,没有动作,但是还是会有语音的复述;融合KMP、BM算法实现的关键词提取算法,将后台字符库与动画库之间动态绑定,支持同义触发。由关键词获取文本记录向字符库发送信息,字符库匹配之后动态触发动画,实现与语音的同步播放。最后是视频录制分享功能,调用了Mob移动分享平台对视频进行录制和合成,录制一段视频,合成视频并存储在用户账户中。上传视频之后可以分享到各社交平台,比如分享到新浪微博、朋友圈等,也可以查看合成的视频文件。
- 还没有人留言评论。精彩留言会获得点赞!