策略预测方法、装置、电子设备和计算机可读存储介质与流程
本公开涉及人工智能领域,更具体地,涉及一种策略预测方法、装置、电子设备和计算机可读存储介质。
背景技术:
1、随着现代社会中人们对于个性化和多样性的追求,在产品或服务中提升用户的多样性体验可以帮助提高产品或服务的竞争力。然而,在目前的产品或服务中多还是重在关注使用户能够实现预期目标或完成预期任务,而忽略了用户在实现预期目标或完成预期任务的过程中的多样性体验需求。例如,在游戏场景中,如果智能体只有一种策略,会让游戏玩家感到模式单一,而多样性的游戏策略会提升玩家的游戏体验。不仅在游戏场景,在很多其他场景(例如,无人驾驶场景、搜索推荐场景等),策略多样性也是提升产品或服务质量的重要因素。
技术实现思路
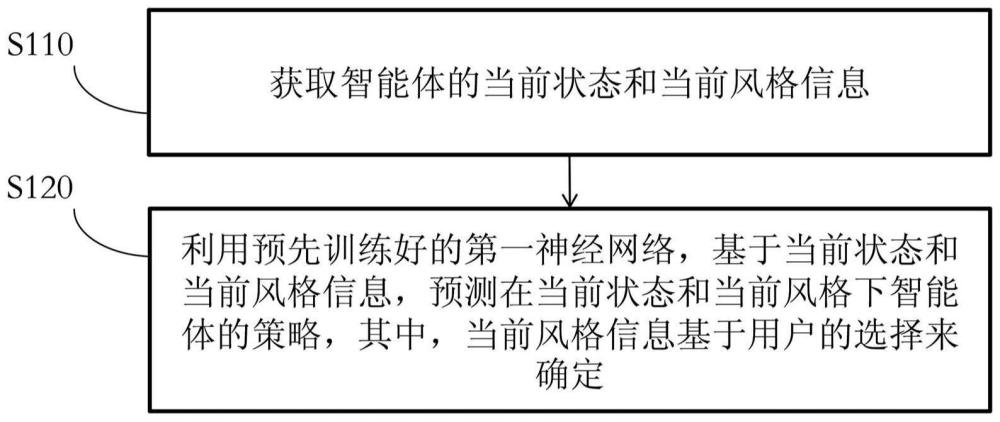
1、根据本公开实施例的第一方面,提供了一种策略预测方法,所述策略预测方法包括:获取智能体的当前状态和当前风格信息;利用预先训练好的第一神经网络,基于所述当前状态和所述当前风格信息,预测在当前状态和当前风格下所述智能体的策略,其中,所述当前风格信息基于用户的选择来确定。
2、可选地,所述策略预测方法,还包括:训练第一神经网络;所述训练第一神经网络的过程包括:获取历史当前时刻智能体的历史当前状态和多种风格信息;分别利用第一神经网络,基于历史当前状态和每种风格信息预测在历史当前状态和每种风格下所述智能体的策略,得到多个策略;调整第一神经网络的参数,使得第一神经网络预测出的多个策略是多个彼此不同的策略。
3、可选地,所述训练第一神经网络的过程还包括:利用第二神经网络,基于所述历史当前状态预测所述历史当前状态下智能体的风格是历史当前时刻的风格的概率;根据预测出的概率确定第一神经网络预测出的多个策略是否是多个彼此不同的策略。
4、可选地,第二神经网络的参数基于智能体的历史当前时刻的风格信息以及所述历史当前状态被调整。
5、可选地,所述调整第一神经网络的参数,包括:利用第三神经网络,基于智能体的历史当前状态、历史当前时刻的风格信息估计预定时间段的累计环境奖励;利用第四神经网络,基于智能体的历史当前状态、历史当前时刻的风格信息估计预定时间段的累计多样性奖励;根据估计的累计环境奖励和累计多样性奖励,调整第一神经网络的参数。
6、可选地,所述训练第一神经网络的过程还包括:根据所述预测出的概率,计算历史当前时刻的多样性奖励;根据所述历史当前状态和第一神经网络预测出的策略,计算历史当前时刻的环境奖励,其中,所述多样性奖励被用于调整第三神经网络的参数,所述环境奖励被用于调整第四神经网络的参数。
7、可选地,所述训练第一神经网络的过程还包括:获取预设的累计环境奖励目标;根据估计的累计环境奖励和所述累计环境奖励目标,确定环境奖励所对应的环境奖励掩膜和多样性奖励所对应的多样性奖励掩膜,其中,所述环境奖励掩膜被用于调整第三神经网络的参数,所述多样性奖励掩膜被用于调整第四神经网络的参数。
8、可选地,所述根据估计的累计环境奖励和累计多样性奖励,调整第一神经网络的参数,包括:根据估计的累计环境奖励和累计多样性奖励确定总累计奖励;根据总累计奖励,调整第一神经网络的参数。
9、可选地,所述智能体对应游戏应用中的角色,所述当前风格信息为当前游戏的玩法,所述策略包括所述角色根据当前游戏的玩法在当前游戏状态下执行的动作。
10、可选地,所述智能体对应无人驾驶场景中的行驶的车辆,所述当前风格信息为当前车辆的运行模式,所述策略包括所述车辆根据当前车辆的运行模式在当前行驶环境下执行的行驶动作。
11、可选地,所述智能体对应搜索推荐场景中的搜索推荐算法,所述当前风格信息为当前搜索推荐风格,所述策略包括所述搜索推荐算法根据当前搜索推荐风格在当前搜索推荐场景下生成的推荐内容。
12、根据本公开实施例的第二方面,提供了一种策略预测装置,所述策略预测装置包括:获取单元,被配置为获取智能体的当前状态和当前风格信息;预测单元,被配置为利用预先训练好的第一神经网络,基于所述当前状态和所述当前风格信息,预测在当前状态和当前风格下所述智能体的策略,其中,所述当前风格信息基于用户的选择来确定。
13、可选地,所述策略预测装置还包括:训练装置,被配置为训练第一神经网络;所述训练第一神经网络的过程包括:获取历史当前时刻智能体的历史当前状态和多种风格信息;分别利用第一神经网络,基于历史当前状态和每种风格信息预测在历史当前状态和每种风格下所述智能体的策略,得到多个策略;调整第一神经网络的参数,使得第一神经网络预测出的多个策略是多个彼此不同的策略。
14、可选地,所述训练第一神经网络的过程还包括:利用第二神经网络,基于所述历史当前状态预测所述历史当前状态下智能体的风格是历史当前时刻的风格的概率;根据预测出的概率确定第一神经网络预测出的多个策略是否是多个彼此不同的策略。
15、可选地,第二神经网络的参数基于智能体的历史当前时刻的风格信息以及所述历史当前状态被调整。
16、可选地,所述调整第一神经网络的参数,包括:利用第三神经网络,基于智能体的历史当前状态、历史当前时刻的风格信息估计预定时间段的累计环境奖励;利用第四神经网络,基于智能体的历史当前状态、历史当前时刻的风格信息估计预定时间段的累计多样性奖励;根据估计的累计环境奖励和累计多样性奖励,调整第一神经网络的参数。
17、可选地,所述训练第一神经网络的过程还包括:根据所述预测出的概率,计算历史当前时刻的多样性奖励;根据所述历史当前状态和第一神经网络预测出的策略,计算历史当前时刻的环境奖励,其中,所述多样性奖励被用于调整第三神经网络的参数,所述环境奖励被用于调整第四神经网络的参数。
18、可选地,所述训练第一神经网络的过程还包括:获取预设的累计环境奖励目标;根据估计的累计环境奖励和所述累计环境奖励目标,确定环境奖励所对应的环境奖励掩膜和多样性奖励所对应的多样性奖励掩膜,其中,所述环境奖励掩膜被用于调整第三神经网络的参数,所述多样性奖励掩膜被用于调整第四神经网络的参数。
19、可选地,所述根据估计的累计环境奖励和累计多样性奖励,调整第一神经网络的参数,包括:根据估计的累计环境奖励和累计多样性奖励确定总累计奖励;根据总累计奖励,调整第一神经网络的参数。
20、可选地,所述智能体对应游戏应用中的角色,所述当前风格信息为当前游戏的玩法,所述策略包括所述角色根据当前游戏的玩法在当前游戏状态下执行的动作。
21、可选地,所述智能体对应无人驾驶场景中的行驶的车辆,所述当前风格信息为当前车辆的运行模式,所述策略包括所述车辆根据当前车辆的运行模式在当前行驶环境下执行的行驶动作。
22、可选地,所述智能体对应搜索推荐场景中的搜索推荐算法,所述当前风格信息为当前搜索推荐风格,所述策略包括所述搜索推荐算法根据当前搜索推荐风格在当前搜索推荐场景下生成的推荐内容。
23、根据本公开实施例的第三方面,提供了一种电子设备,所述电子设备包括:至少一个处理器;存储计算机可执行指令的至少一个存储器,其中,所述计算机可执行指令在被所述至少一个处理器运行时,促使所述至少一个处理器执行上述策略预测方法。
24、根据本公开实施例的第四方面,提供了一种存储指令的计算机可读存储介质,当所述指令被至少一个处理器运行时,促使所述至少一个处理器执行如上所述的策略预测方法。
25、根据本公开实施例的策略预测方法、装置、电子设备和计算机可读存储介质,由于除了智能体的当前状态之外还将基于用户的选择确定的当前风格信息作为预先训练的第一神经网络的输入,因此,可以利用第一神经网络预测在当前状态和当前风格下智能体的策略,而不是针对当前状态仅预测出单一策略,因而提升了用户的多样性体验。
- 还没有人留言评论。精彩留言会获得点赞!